安装ELK日志分析服务
前言
ELK是一个用于处理和分析日志数据的开源技术栈,由三个主要组件组成,E即Elasticsearch,L即Logstash,K即Kibana。
- Elasticsearch是一个分布式搜索和分析引擎,用于存储、搜索和分析大量数据,提供实时搜索功能。
- Logstash是一个数据收集和处理管道,能够从各种来源获取日志数据,进行过滤、转换,并将数据传输到 Elasticsearch。
- Kibana是一个数据可视化工具,提供图形化界面,用于创建和展示来自 Elasticsearch 的数据可视化,帮助我们分析和探索数据。
三个工具结合使用,让ELK 堆栈可以处理复杂的日志数据,进行深度分析和可视化,广泛应用于监控、故障排查和数据洞察。
题目要求如下:
使用提供的sepb_elk_latest.tar镜像安装ELK服务。
自行配置YUM源安装Docker服务,然后使用提供的sepb_elk_latest.tar镜像安装ELK服务,安装完成后,进行添加数据操作,将ELK监控目标节点所需安装的RPM安装包下载到本地云主机的/root目录下。
这道题只需要用到一台Linux作为服务器和一台带桌面的机子进行操作,所以在那个培训平台里就可以直接做,直接申请那个堡垒机的实验,会给台Centos7和带桌面的Windows。
操作过程
配置YUM源安装Docker服务
shell
#先获取需要用到的软件包
[root@localhost ~]# curl -O \
http://mirrors.douxuedu.com/new-competition/docker-repo.tar.gz
#将其解压至/opt目录
[root@localhost ~]# tar -zxf docker-repo.tar.gz -C /opt
#将系统源移走
[root@localhost ~]# mv /etc/yum.repos.d/* /media/
#编写新的仓库文件
[root@localhost ~]# vi /etc/yum.repos.d/local.repo
[centos]
name=centos
baseurl=http://mirrors.douxuedu.com/centos
gpgcheck=0
enabled=1
[Docker]
name=Docker
baseurl=file:///opt/docker-repo
gpgcheck=0
enabled=1
#检查可用性
[root@localhost ~]# yum clean all && yum repolist
#安装Docker服务
[root@localhost ~]# yum install -y docker-ce
#开启Docker服务并设置开机自启
[root@localhost ~]# systemctl start docker && systemctl enable docker部署ELK服务
shell
#先获取需要用到的软件包
[root@localhost ~]# curl -O http://mirrors.douxuedu.com/new-competition/sepb_elk_latest.tar
#加载镜像
[root@localhost ~]# docker load -i sepb_elk_latest.tar
#vm.max_map_count是Linux中的一个内核参数,它控制了每个进程可以拥有的内存映射区域的最大数量。
#而Elasticsearch需要在内存中维护大量的数据结构。为了提高性能,Elasticsearch使用了大量的内存映射区域,用于存储倒排索引等数据结构。
#Linux系统的默认vm.max_map_count通常较低,所以我们要修改它的值,否则后续启动时会报错
[root@localhost ~]# vi /etc/sysctl.conf
vm.max_map_count = 262144
#生效配置
[root@localhost ~]# sysctl -p
#启动容器
[root@localhost ~]# docker run -itd -p 5601:5601 -p 9200:9200 -p 5044:5044 \
#这里映射的端口应该都知道吧,5601是Kibana的默认端口,9200是 Elasticsearch的默认端口,5044则是Logstash的默认端口
--name elk -e ES_MIN_MEN=512m -e ES_MAX_MEM=1024m sebp/elk:latest
#-e那里是设置环境变量,指定Elasticsearch的最小和最大内存为512MB和1024MB
#安装filebeat,它用于将日志文件中的数据发送到Logstash或 Elasticsearch,减轻Logstash的负担并使ELK能够有效地处理和分析日志信息
[root@localhost ~]# curl -O http://mirrors.douxuedu.com/new-competition/filebeat-7.13.2-x86_64.rpm
[root@localhost ~]# yum -y install filebeat-7.13.2-x86_64.rpm
#修改配置文件,启动功能
[root@localhost ~]# vi /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true #原false
paths:
- /var/log/yum.log #原/var/log/*.log
...
#日志的输出默认就是连接Elasticsearch的,不需要修改
output.elasticsearch:
hosts: ["localhost:9200"]
#开启filebeat服务并设置开机自启
[root@localhost ~]# systemctl start filebeat && systemctl enable filebeat 控制台操作
来到Windows机,在浏览器输入服务器ip:5601登录
点击左上角三横杠折叠按钮打开菜单→划至底部找到【Management】管理栏→点击【Stack Management】进入栈管理页面
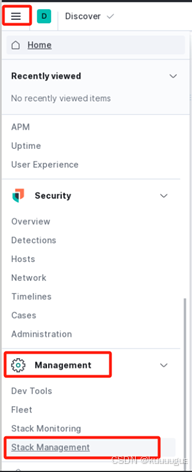
在跳出的新页面中点击【Index Management】进入索引管理页面
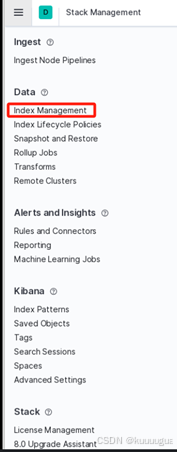
查看filebeat服务是否添加
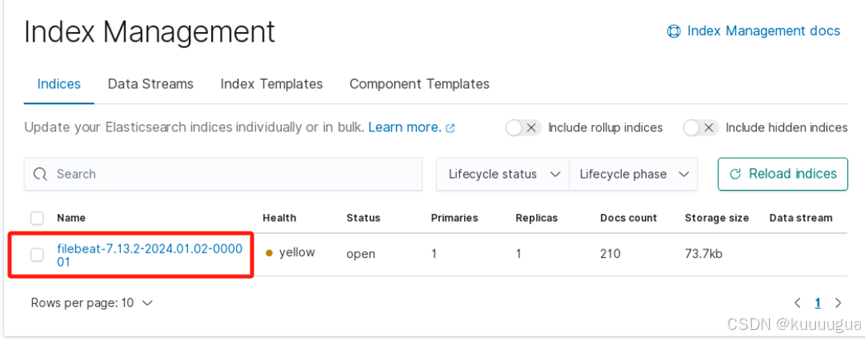
最后我们测试一下服务的可用性
从左边菜单栏找到【Kibana】栏→点击下方的【Index Patterns】索引方式
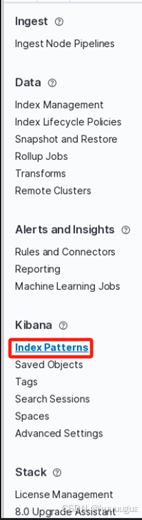
在跳转的页面中点击【Create index pattern】,创建一个索引方式
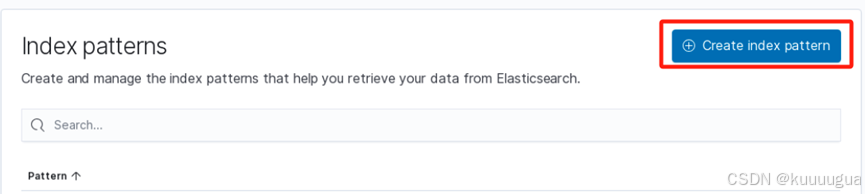
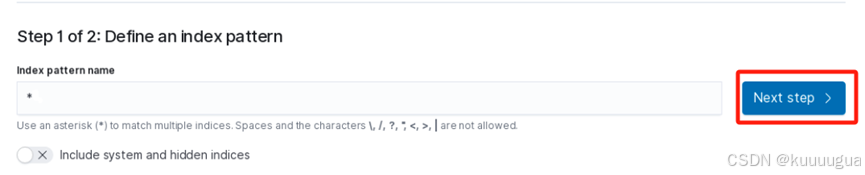
输入*号通配符代表索引全部()→点击【Next step】进入下一步
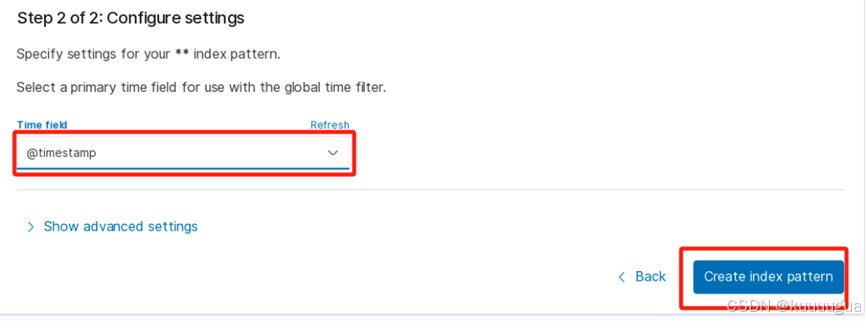
在下一步中,【Time field】选择【@timestamp】,设置索引时间为全部时间。然后点击【Create index pattern】创建这个索引
再次打开折叠菜单栏,找到【Analytics】分析栏,点击下方的【Discover】发现项目
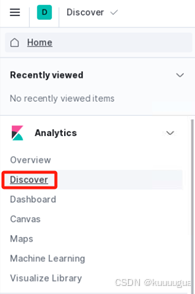
在新页面下方的搜索框搜索"file"
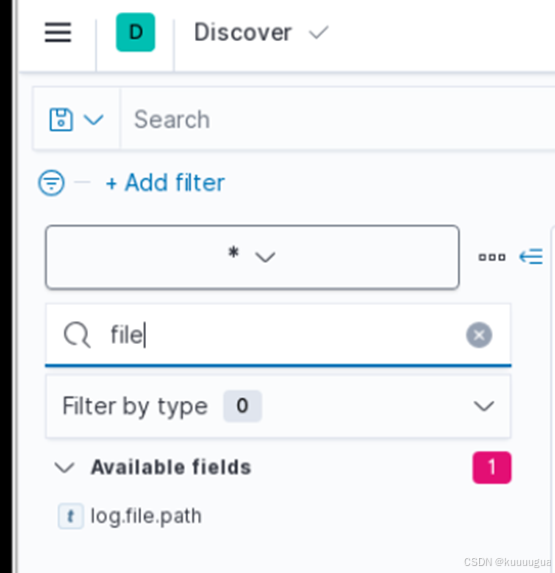
在查询的结果中出现了【log.file.path】,点击右边的+号添加
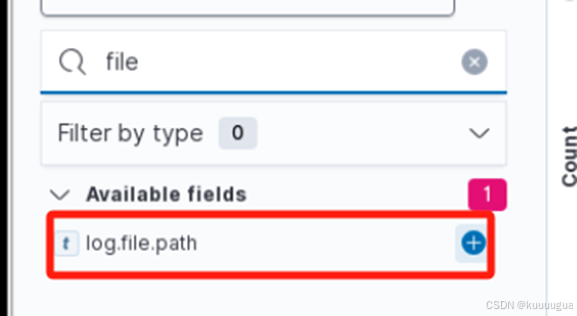
就可以发现被收集的数据了

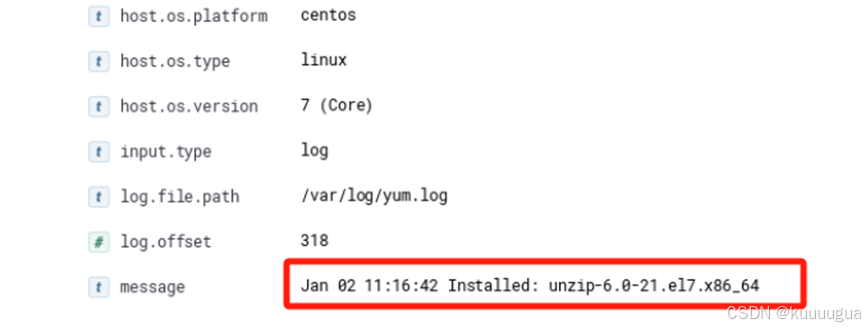
我们回到docker节点,随便安装一个软件
shell
[root@localhost ~]# yum -y install unzip再回到Discover发现面板,就可以发现刚刚进行安装的信息了
CSMU4Lv-1724775901588)]
我们回到docker节点,随便安装一个软件
shell
[root@localhost ~]# yum -y install unzip再回到Discover发现面板,就可以发现刚刚进行安装的信息了