持续更新中
| 模块 | 序号 | 目录 | 链接 |
|---|---|---|---|
| 前言介绍 | 1 | 前言 | 地址 |
| 2 | 介绍 | 地址 | |
| 基础知识 | 3 | 计算机网络 | 地址 |
| 4 | 操作系统 | 地址 | |
| 5 | Java基础 | 地址 | |
| 6 | Java并发 | 地址 | |
| 7 | Java虚拟机 | 地址 | |
| 中间件 | 8 | Mysql | 地址 |
| 9 | Redis | 地址 | |
| 10 | Elasticsearch | 地址 | |
| 11 | RabbitMQ | 地址 | |
| 12 | RocketMQ | 地址 | |
| 框架 | 13 | 分布式系统 | 地址 |
| 14 | MyBatis | 地址 | |
| 15 | Dubbo | 地址 | |
| 16 | Spring | 地址 | |
| 17 | Spring MVC | 地址 | |
| 18 | Spring Boot | 地址 | |
| 19 | Spring Cloud | 地址 | |
| 20 | Spring Cloud Alibaba Nacos | 地址 | |
| 21 | Spring Cloud Alibaba Sentinel | 地址 | |
| 22 | Spring Cloud Alibaba Seata | 地址 | |
| 23 | Tomcat | 地址 | |
| 24 | Netty | 地址 | |
| 容器 | 25 | Docker | 地址 |
| 26 | Kubernetes | 地址 | |
| 架构设计 | 27 | 场景架构设计 | 地址 |
| 28 | 领域驱动设计 | 地址 | |
| 29 | 设计模式 | 地址 | |
| 数据结构与算法 | 30 | 数据结构与算法 | 地址 |
| 31 | LeetCode题解 | 地址 |
自我介绍
你先做一下自我介绍吧
:::tips
面试者自我介绍:
你好,我叫你的名字,是一名有例如:5年开发经验的Java软件工程师。我毕业于你的大学的你的专业,在过去的几年里,我一直专注于Java开发和相关技术的应用。
在工作中,我参与并主导了多个项目的开发,包括Web应用、企业级系统和微服务架构。我擅长使用Java及其生态系统中的各种工具和框架,如Spring、Hibernate、Maven等。
我的主要技能包括:
- Java核心技术:熟练掌握Java基础、面向对象编程(OOP)、多线程编程、集合框架等。
- Web开发:熟悉Spring全家桶(Spring Boot, Spring MVC, Spring Security等),并且有丰富的RESTful API设计和实现经验。
- 数据库:熟悉关系型数据库(如MySQL, PostgreSQL)和非关系型数据库(如MongoDB, Redis),具备良好的SQL调优能力。
- 前端技术:了解HTML, CSS, JavaScript, 以及相关框架如Angular或React,能够进行基础的前后端联调。
- 版本控制:熟练使用Git进行代码管理和协作。
- 测试:掌握单元测试(JUnit)、集成测试和测试驱动开发(TDD)的方法。
- 云服务:有使用AWS或其他云服务的经验,包括部署和管理。
- 敏捷开发:熟悉敏捷开发流程(Scrum 或 Kanban),并在实际项目中应用。
工作中,我注重代码质量和可维护性,擅长撰写文档和代码评审。我有较强的团队合作精神,善于沟通和解决问题。同时,我也有一定的项目管理经验,能够推动项目顺利进行。
在未来的职业生涯中,我希望能够继续提升技术能力,并且在大型复杂系统的设计和架构领域有所突破。我对贵公司在例如:技术创新、行业前沿等方面的成就和未来发展充满期待,期望能加入你们的团队,贡献自己的力量。
非常感谢你们给我这次面试机会,我非常期待能和你们进一步交流。
:::
项目介绍
简要介绍一下自己的项目吧
:::tips
当然可以!以下是一个简要介绍项目的示例:
在过去的几年里,我参与并主导了多个Java开发项目。这里简要介绍其中两个具有代表性的项目:
项目1:在线购物系统
项目背景:
这是一个全栈开发项目,目标是建立一个功能全面的在线购物平台。平台包括用户注册、商品浏览、购物车、订单管理和支付功能。
技术栈:
- 后端:使用Spring Boot框架,结合Spring MVC和Spring Data JPA实现业务逻辑和数据持久化。
- 数据库:MySQL用于关系型数据存储,Redis用于缓存热点数据,提高系统响应速度。
- 前端:使用Thymeleaf模板引擎进行页面渲染,结合Bootstrap进行前端界面美化。
- 版本控制:使用Git进行代码管理,搭配GitFlow工作流程。
- 部署:采用Docker进行容器化部署,并托管在AWS云平台上。
责任和贡献:
- 设计并实现了核心的业务模块,包括用户管理、商品管理、订单处理和支付集成。
- 优化数据库查询性能,通过使用索引和优化SQL语句,使关键查询的响应时间减少了近40%。
- 实现了基于角色的访问控制(RBAC),增强了系统安全性。
- 撰写了详细的技术文档和API文档,便于团队协作和后续维护。
项目2:企业级即时通讯系统
项目背景:
该项目为一个大中型企业开发内部即时通讯系统,主要目标是提高团队沟通效率,支持文字、图片、文件传输等多种消息类型,并集成企业的LDAP认证。
技术栈:
- 后端:使用Spring Boot和WebSocket构建双向通信服务,消息持久化部分使用MongoDB。
- 前端:使用Vue.js构建单页面应用(SPA),提升用户体验。
- 消息队列:使用RabbitMQ处理消息广播和传递,提高系统的吞吐量和稳定性。
- 认证:集成LDAP服务器进行用户认证和权限管理。
- 测试:使用JUnit和Mockito进行单元测试,保证代码的稳定性。
责任和贡献:
- 负责WebSocket服务的设计与实现,确保高并发下的消息传递性能。
- 设计了高可用的消息存储和检索方案,保证历史消息的高效查询和回溯。
- 实现与现有企业系统的集成,包括LDAP认证和企业通讯录同步。
- 配合前端开发,提供API支持并参与部分前端组件的开发。
- 进行系统的负载测试与优化,确保在高并发场景下的稳定运行。
这些项目让我积累了丰富的实践经验,提升了技术能力和团队合作能力。如果需要更详细的项目介绍或代码示例,非常乐意进一步分享。
:::
工作问题
找一个你比较熟悉的项目,工作中遇到了什么问题,通过什么技术来解决的
:::tips
好的,我来分享一个我比较熟悉的在线购物系统项目中的一个具体问题及解决方案。
项目背景:
我主导开发了一个功能全面的在线购物平台,支持用户注册、商品浏览、购物车管理、订单处理和支付等功能。
遇到的问题:
在系统上线后,随着用户数量的增多,我们发现商品详情页面的访问量急剧上升,导致数据库查询压力过大,出现了响应变慢的情况,影响了用户体验。具体问题表现为,当大量用户同时访问某个热门商品时,系统的响应时间明显增加,有时甚至会出现超时错误。
解决方案:
为了缓解数据库的压力并提高系统的响应速度,我们决定引入缓存机制。具体步骤如下:
- 确定缓存策略 :
根据商品详情页面的特点,确定将商品详情数据缓存起来,减少对数据库的频繁访问。采用Redis作为缓存服务器,利用其高效的内存读写特性来提升性能。 - 缓存设计 :
商品详情数据相对稳定,因此可以设置较长的缓存有效期。每次用户请求商品详情时,先从Redis缓存中获取数据,如果缓存中没有对应的数据,则从数据库查询并存入缓存。 - 实现缓存逻辑 :
- 在Spring Boot项目中集成Redis,使用Spring Data Redis进行操作。
- 编写代码实现缓存读取和存储逻辑。
- 缓存失效策略 :
设置缓存的有效期为1小时(具体时间根据业务需要调整),并实现定时同步或主动失效机制,保证数据的及时性。 - 性能测试与优化 :
- 通过JMeter等工具对缓存机制进行性能测试,验证其有效性。
- 监控缓存命中率和数据库查询压力,确认问题得到解决。
结果:
引入Redis缓存后,商品详情页面的响应速度有了显著提升,数据库查询压力大幅减小。测试结果显示,缓存命中率达到了90%以上,系统整体性能提高了近70%,用户体验得到了显著改善。
这个解决方案有效地解决了高并发情况下系统响应变慢的问题,通过缓存技术大大提升了系统的性能和稳定性。
如果你有其他问题或需要更深入的技术细节,欢迎继续交流!
:::
线上问题
有没有遇到过什么线上问题
:::tips
当然,有线上问题是开发和运维过程中常见的挑战。下面我分享一个项目中遇到的具体线上问题和解决方案,这个问题涉及到系统在高并发情况下的稳定性问题。
项目背景:
在我们开发的在线购物系统上线后,遇到了促销活动期间流量激增的情况。一次重大促销活动期间,我们的服务器出现了长时间的响应延迟和偶发的宕机情况,用户体验严重受影响。
遇到的问题:
- 高并发请求导致服务器负载过高:大量用户同时访问系统,导致服务器CPU和内存使用率飙升,甚至触发了系统的保护性宕机机制。
- 数据库连接耗尽:数据库的连接池在高并发请求下快速被耗尽,导致应用无法及时获取数据库连接,出现大量连接超时和失败。
- 缓存击穿:某些热门商品的数据在缓存失效后,大量请求直接打到了数据库,引发了一系列数据库性能问题。
解决方案:
- 增加服务器资源,调整负载分布 :
- 水平扩展:通过增加应用服务器的实例数量来分担负载。
- 负载均衡:使用负载均衡器(如NGINX或AWS ELB),将请求均匀分发到不同的服务器上。
- 优化数据库连接池配置 :
- 增大连接池大小:调整数据库连接池的最小和最大连接数以应对高并发场景。
- 连接池使用监控:引入数据库连接池监控工具(如HikariCP的监控功能),实时监控并调整连接池配置。
- 引入限流和熔断机制 :
- 限流:在流量高峰期,通过工具(如RateLimiter、Guava RateLimiter)限制单个用户的请求频率,保护系统资源。
- 熔断:使用熔断器(如Hystrix),当某个服务不可用或响应时间过长时,及时熔断请求,避免连锁反应。
- 加强缓存策略 :
- 热点缓存:对热点数据设置较长的缓存时间,并在缓存失效前主动刷新缓存,防止缓存击穿。
- 分布式缓存:采用分布式缓存方案(如Redis Cluster),提高缓存的可用性和扩展性,确保即使在高并发情况下缓存也能稳定工作。
- 监控和报警系统 :
- 部署实时监控工具(如Prometheus + Grafana、ELK Stack),监控服务器和数据库的性能表现。
- 设置合理的报警阈值,及时检测并处理异常情况,确保系统在高负载时依然稳定运行。
结果:
通过以上措施,我们成功提高了系统在高并发情况下的稳定性。促销活动期间,系统响应时间显著降低,负载均衡后服务器和数据库运行稳定,避免了宕机和过载问题,用户体验得到明显改善。
如果还有其他问题或需要进一步的解释,欢迎继续提问
:::
OOM问题
线上有没有遇到过OOM问题怎么解决的
:::tips
是的,线上系统在某些情况下会遇到内存溢出(Out of Memory, OOM)问题,这是一个常见且严重的故障。下面是一个关于线上遇到OOM问题的实际案例和解决方案:
项目背景:
在一个电商平台项目中,系统在高流量时段偶尔会出现内存溢出 (OOM) 错误,导致应用程序崩溃和服务中断。
遇到的问题:
系统在高并发访问情况下,对象创建和内存消耗过高,导致Java堆内存被耗尽,抛出java.lang.OutOfMemoryError: Java heap space异常。
解决方案:
- 问题定位:
使用Java的内存分析工具(如VisualVM、jmap、jstack、MAT)对内存使用情况进行诊断。- Heap Dump分析:生成堆内存的快照(Heap Dump),通过分析找到哪些对象消耗了大量内存。
- 线程分析:观察线程的堆栈,找出哪部分代码存在内存泄漏或大量对象未被及时回收。
- 代码优化:
- 查找和修复内存泄漏 :在一些情况下,内存泄漏是由于对象被意外地持有引用,导致无法被GC回收。通过Heap Dump分析,找到这些持有引用的地方并进行修复。
- 例如:关闭未使用的数据库连接、输入输出流等资源,确保在finally块中释放资源。
- 优化数据结构和算法 :审查代码,使用更高效的算法和数据结构,减少内存占用。
- 例如 :避免使用过大的集合如
HashMap、ArrayList等,并定期清理不再使用的元素。
- 例如 :避免使用过大的集合如
- 查找和修复内存泄漏 :在一些情况下,内存泄漏是由于对象被意外地持有引用,导致无法被GC回收。通过Heap Dump分析,找到这些持有引用的地方并进行修复。
- 优化JVM参数配置:
- 调整堆内存大小:通过调整JVM启动参数,增加堆内存大小,确保有足够的内存可供使用。例如,将Xmx调大:-Xmx4G
- 调整垃圾回收参数 :选择合适的垃圾回收器(GC)和参数,以提高垃圾回收效率,减缓内存增长速度。
- 例如:使用G1 GC,并调整相关参数: -XX:+UseG1GC -XX:MaxGCPauseMillis=200
- 加强监控和日志:
- 实时监控内存使用:使用监控工具(如Prometheus、Grafana),实时监控JVM的内存使用情况和GC频率。
- 日志记录:在关键部分增加日志记录,跟踪内存使用情况,方便后期分析和定位问题。
结果:
通过以上措施,系统的内存使用情况得到了显著改善,OOM问题得到有效解决。高并发访问时的内存消耗大幅减少,垃圾回收频率和响应时间也更加稳定,确保了系统的可靠性和稳定性。
面对OOM问题,关键在于通过详细的分析找到内存消耗的根本原因,并采取针对性的优化措施,从代码、配置和运行监控等多个角度进行综合解决。
希望这个案例对你有所帮助。如果还有其他问题或需要进一步的解释,欢迎继续提问!
:::
死锁问题
有没有遇到过Java死锁问题,怎么进行排查解决的
:::tips
是的,Java应用中确实可能遇到死锁问题。以下是一个实际案例,描述了如何排查和解决Java中的死锁问题。
背景:
我们在开发一个企业级应用时,偶尔会在生产环境中遇到线程挂起的情况。通过用户报告和日志初步分析,怀疑存在死锁问题。
遇到的问题:
应用在高并发情况下,某些操作会导致线程永久等待,最终导致应用服务部分功能不可用。这通常是由多个线程相互持有对方需要的资源锁而产生的死锁。
排查步骤:
- 收集线程堆栈信息 :
使用Java提供的工具来捕捉线程的堆栈信息。例如使用jstack工具,生成线程堆栈快照:

这里<pid>是Java进程的ID。
- 分析线程堆栈信息 :
在生成的线程快照中,查找"deadlock"或"found one JVM-level deadlock"等字样,并分析相关线程的状态。
通常死锁的线程会显示"BLOCKED"状态,并且会看到类似的堆栈信息:

- 这样的日志表明Thread-1持有对象<0x00000000f0a1a1c0>的锁并等待对象<0x00000000f0a1a1b8>的锁,而Thread-2持有对象<0x00000000f0a1a1b8>的锁并等待对象<0x00000000f0a1a1c0>的锁,导致互相等待而死锁。
- 识别和修复代码 :
通过分析线程堆栈信息,定位死锁发生的位置和原因。通常,死锁是由于多个线程以不同的顺序申请锁造成的。解决思路主要有以下几种:- 调整锁的顺序:确保所有线程在申请多个锁时,以相同的顺序申请。
- 使用
**tryLock**:如果使用ReentrantLock,可以使用tryLock方法来申请锁,并设定超时时间或失败处理逻辑,避免死锁。 - 减小锁的粒度:合理规划锁的范围,尽量减小锁的持有时间和范围,避免过多的锁嵌套。
- 锁的细化:将大锁拆分为几个细粒度的锁,降低锁之间的竞争。
解决方案:
在我们的案例中,经过分析和重构代码,应用了以下解决措施:
-
调整锁的顺序 :
确保所有线程在获取资源A和资源B的锁时,始终先申请资源A的锁,再申请资源B的锁。
 -
使用
**tryLock**:在使用
ReentrantLock时,采用tryLock方法来申请锁,避免长时间的等待。
-
减少锁的粒度 :
优化需要同步的代码块,减少锁的范围,尽量缩短锁的持有时间,提高并发性能。
结果:
通过以上措施,我们有效解决了生产环境中的死锁问题。系统的稳定性显著提高,线程间的竞争和等待情况减小,大幅提升了系统的并发处理能力和响应速度。
如果你有其他问题或需要进一步的解释,欢迎继续提问!
:::
CPU飙升
有没有遇到过CPU飙升的问题,怎么解决的
:::tips
是的,CPU飙升问题在生产环境中也是常见的故障之一。以下是一个实际案例,描述了如何排查和解决Java应用中CPU飙升的问题。
项目背景:
在一个高并发的电商平台项目的生产环境中,我们发现服务器的CPU使用率突然飙升到近100%,导致系统响应速度下降,用户体验受到严重影响。
遇到的问题:
在高并发访问下,某些情况会导致程序逻辑消耗大量CPU资源,长时间占用CPU,导致服务器负载过高。
排查步骤:
- 初步调查和监控:
- 使用监控工具(如Nagios、Prometheus、New Relic)观察系统资源的使用情况,确认CPU飙升的具体时段和频率。
- 查看系统日志和应用日志,寻找可能的异常提示和错误信息。
- 定位问题线程:
- 使用
top或htop命令查看系统中占用CPU资源较高的进程和线程。 - 使用
ps命令获取具体线程的ID:这里<PID>是Java进程的ID。 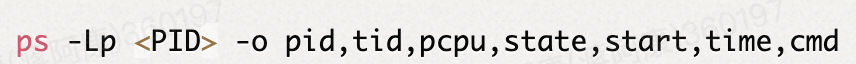
- 使用
- 获取线程的堆栈信息:
使用jstack工具获取当前所有线程的堆栈信息,并保存到文件中:

将线程ID转换为十六进制格式(因为jstack输出中的线程ID是十六进制的): 这里<TID>是线程的ID。

- 分析线程堆栈信息:
在生成的堆栈信息中,查找对应的线程ID,并查看该线程当前执行的代码位置。
重点关注"RUNNABLE"状态的线程,尤其是那些反复出现的线程堆栈,可能存在消耗大量CPU资源的问题代码。
- 识别和修复问题:
- 根据堆栈信息,定位到高CPU消耗的具体代码段,分析其逻辑并进行优化。
- 常见的问题和优化措施包括:
- 死循环 :确认程序中是否存在意外的死循环,导致线程长时间占用CPU。
- 解决方法:修正循环条件,确保循环能够正常退出。
- 频繁对象创建和销毁 :大量创建和销毁临时对象,导致频繁的垃圾回收。
- 解决方法:优化代码逻辑,减少不必要的对象创建,采用对象池等方式复用对象。
- 锁竞争 :多个线程争用一个锁,导致频繁的上下文切换。
- 解决方法:优化同步代码块,缩小锁的粒度,减少不必要的同步操作。
- IO操作阻塞 :频繁的IO操作导致CPU等待时间增加。
- 解决方法:优化IO处理逻辑,使用异步IO或增加缓存减少阻塞。
案例实例:
在我们的案例中,我们通过以上步骤,定位到如下问题:
存在一个循环条件失误的死循环,导致线程长时间占用CPU:

我们修正了条件判断,使得循环能够正常退出。
另一个问题是频繁的垃圾回收导致CPU飙升。我们通过分析发现,大量的临时对象被频繁创建和GC回收:

解决方法是优化对象的复用,减少不必要的对象创建。
结果:
通过定位和修复高CPU消耗的代码问题,应用程序的CPU使用率显著降低,系统的响应速度大幅提升,用户体验得到明显改善。
如果你有其他问题或需要进一步的解释,欢迎继续提问!
:::