PLUTO: Pushing the Limit of Imitation Learning-based Planning for Autonomous Driving
PLUTO: 推动基于模仿学习的自动驾驶规划的极限
https://arxiv.org/abs/2404.14327


Abstract
We present PLUTO, a powerful framework that Pushes the Limit of imitation learning-based planning for aUTOnomous driving. Our improvements stem from three pivotal aspects: a longitudinal-lateral aware model architecture that enables flexible and diverse driving behaviors; An innovative auxiliary loss computation method that is broadly applicable and efficient for batch-wise calculation; A novel training framework that leverages contrastive learning, augmented by a suite of new data augmentations to regulate driving behaviors and facilitate the understanding of underlying interactions. We assessed our framework using the large-scale real-world nuPlan dataset and its associated standardized planning benchmark. Impressively, PLUTO achieves state-of-the-art closed-loop performance, beating other competing learning-based methods and surpassing the current top-performed rule-based planner for the first time. Results and code are available at https://jchengai.github.io/pluto.
我们介绍了PLUTO,一个强大的框架,它推动了基于模仿学习的自动驾驶规划的极限 。我们的改进源于三个方面 :一个纵向-横向感知的模型架构 ,它能够实现灵活多样的驾驶行为 ;一种创新的辅助损失计算方法 ,它广泛适用且对批量计算高效 ;一个新颖的训练框架 ,利用对比学习 ,并辅以一系列新的数据增强技术 来规范驾驶行为 ,促进对底层交互的理解 。我们使用大规模的真实世界 nuPlan 数据集 及其相关的标准化规划基准来评估我们的框架。令人印象深刻的是,PLUTO实现了最先进的闭环性能 ,首次超越了其他竞争的学习基础方法 ,并超越了当前表现最佳的基于规则的规划器 。结果和代码可在 https://jchengai.github.io/pluto 上找到。

I. INTRODUCTION
LEARNING-based planning has emerged as a potentially scalable approach for autonomous driving, attracting significant research interest 1. Imitation-based planning, in particular, has demonstrated noteworthy success in simulations and real-world applications. Yet, the efficacy of learning-based planning remains unsatisfactory. As indicated in 2, conventional rule-based planning outperforms all learning-based alternatives, winning the 2023 nuPlan planning challenge. This paper delineates the principal challenges inherent in learningbased planning and presents our novel solutions, aimed at pushing the boundaries of what is achievable with learningbased planning.
基于学习的规划已经成为自动驾驶领域一种潜在的可扩展方法,吸引了显著的研究兴趣1。特别是模仿式规划,在仿真和实际应用中已经显示出显著的成功。然而,基于学习的规划的有效性仍然不尽人意。正如2所指出的,传统的基于规则的规划在2023年的nuPlan规划挑战赛中超越了所有基于学习的替代方案 。本文概述了学习式规划固有的主要挑战,并提出了我们的新颖解决方案,旨在推动基于学习规划的可实现边界 。
The first challenge lies in acquiring multi-modal driving behaviors. It is observed that while learning-based planners are good at learning longitudinal tasks such as lane following, they struggle with lateral tasks 3, for instance, executing lane changes or navigating around obstacles, even when space permits. We attribute this deficiency to the absence of explicit lateral behavior modeling within the architectural design of the model. Our previous work 4 attempted to address this issue by generating plans that are explicitly conditioned on nearby reference lines, though it was restricted to producing a maximum of three proposals and did not effectively integrate lateral and longitudinal behavior modeling. In the present study, we enhance this approach through the adoption of a query-based architecture capable of generating an extensive array of proposals by fusing longitudinal and lateral queries. The advanced model design enables our planner to demonstrate diverse and flexible driving behaviors, which we believe is a crucial step toward practical learning-based planning.
第一个挑战在于获取多模态驾驶行为 。观察到,尽管基于学习的规划器擅长学习纵向任务 ,例如车道跟随 ,但在横向任务上却存在困难 3,例如执行变道或绕过障碍物 ,即使在空间允许的情况下也是如此。我们将这种不足归因于 模型的架构设计中缺乏明确的横向行为建模 。我们之前的工作 4试图通过生成明确依赖于附近参考线的规划来解决这个问题,尽管它仅限于产生最多三个提案,并没有有效地整合横向和纵向行为建模 。在本研究中,我们通过采用基于查询的架构来增强这种方法,该架构能够通过融合纵向和横向查询来生成广泛的提案 。先进的模型设计使我们的规划器能够展示多样化和灵活的驾驶行为,我们认为这是迈向实用的基于学习规划的关键一步。
Beyond the model architecture, it is recognized that pure imitation learning encompasses inherent limitations, including the propensity for learning shortcuts 5--8, distribution shift 3, 5, 9, and causal confusion 10, 11 issues. This paper addresses these pervasive challenges across three dimensions:
除了模型架构之外,人们认识到纯粹的模仿学习包含固有的局限性,包括倾向于学习捷径5-8、分布偏移3、5、9和因果混淆10、11问题。本文从三个维度来解决这些普遍存在的挑战:
- 学习捷径:模仿学习可能导致智能体学习到完成任务的非最优或非预期的捷径,而不是学习到正确的行为策略。
- 分布偏移:当智能体在仿真环境或特定数据集上训练后,在实际应用中可能会遇到与训练数据分布不同的新情况,导致性能下降。
- 因果混淆 :模仿学习可能无法正确理解行为与结果之间的因果关系,从而在决策时产生混淆。
(1) Learning beyond pure imitation loss. We concur with previous studies 5, 9, 12 that solely relying on imitation loss is insufficient for learning desired driving behaviors. It is imperative to impose explicit constraints during the training phase, particularly within the safety-critical realm of autonomous driving. A prevalent approach is to add auxiliary losses to penalize adverse behaviors, such as collisions and offroad driving, as previously demonstrated in 5, 9. However, their methods are either designed for heatmap-based output 5 or need a differentiable rasterizer 9 that renders each trajectory point into an image. As a result, the output resolution is restricted to reduce the computation burden. It remains unclear how to realize these losses efficiently for the more modern vector-based models. To bridge this gap, we introduce a novel auxiliary loss calculation methodology predicated on differentiable interpolation. This method not only spans a broad spectrum of auxiliary tasks but also facilitates batchwise computation within modern deep-learning frameworks, thereby enhancing its applicability and efficiency.
(1) 超越纯粹模仿损失的学习 。我们同意先前的研究5、9、12,仅仅依赖模仿损失是不足以学习期望的驾驶行为的 。在自动驾驶的安全关键领域,特别是在训练阶段施加明确的约束是必要的 。一种普遍的方法是添加辅助损失来惩罚不良行为 ,例如碰撞和驶离道路 ,正如之前5、9所展示的。然而,他们的方法要么是为基于热图的输出设计的5,要么需要一个可微分的栅格器9,将每个轨迹点渲染成图像。结果,输出分辨率受到限制以减少计算负担。对于更现代的基于向量的模型 ,如何高效实现这些损失仍然不明确 。为了弥合这一差距,我们引入了一种新的辅助损失计算方法 ,该方法基于可微分插值 。这种方法不仅涵盖了广泛的辅助任务,而且促进了现代深度学习框架中的批量计算,从而增强了其适用性和效率。
(2) New data augmentations. Issues arise when the model undergoes open-loop training and closed-loop testing. For instance, the accumulation of errors over time may lead to input data deviating from the training distribution; the model may rely on unintended shortcuts rather than acquiring knowledge. Data augmentations have been extensively employed to alleviate these problems and have demonstrated effectiveness, e.g., perturbation-based augmentations 3, 5, 9 teach the model to learn to recover from small deviations and dropoutbased augmentations prevent learning shortcuts 3. In addition to these two augmentations, we introduce further augmentation techniques aimed at regulating driving behavior and enhancing interaction learning.
(2) 新的数据增强技术 。当模型在开环训练和闭环测试中出现问题时,例如,随着时间的推移,累积的错误可能导致输入数据偏离训练分布;模型可能依赖于非预期的捷径而不是获取知识。数据增强已被广泛用于缓解这些问题,并已证明其有效性,例如,基于扰动的增强 3、5、9教会模型从小偏差中恢复 ,基于丢弃的增强3防止学习捷径 。除了这两种增强技术外,我们引入了进一步的增强技术,旨在规范驾驶行为和增强交互学习。
(3) Learning by constrast. Imitation learning-based models often struggle to recognize underlying causal relationships due to the absence of interactive feedback with the environment 10. This issue can significantly hinder performance; for instance, a planner may decelerate by mimicking the behavior of nearby agents rather than responding to a red light. Our goal is to address this issue without substantially complicating the training process, as would be the case with reinforcement learning or employing a data-driven simulator. Drawing inspiration from the effectiveness of contrastive learning 13, which enhances representation by differentiating between similar and dissimilar examples, we recognize an opportunity to infuse the model with causal understanding. This is achieved by enabling the model to differentiate between original and modified input data---for example, by excluding the leading vehicles from the autonomous vehicle's (AV's) perspective. Building on this approach and the two previously mentioned strategies, we introduce a novel unified framework termed Contrastive Imitation Learning (CIL).
(3) 对比学习 。基于模仿学习的模型 常常因为缺乏与环境的交互反馈 而难以识别潜在的因果关系 10。这个问题可能会显著阻碍性能 ;例如,规划器可能通过模仿附近代理的行为来减速,而不是对红灯做出反应。我们的目标是解决这个问题,而不会显著复杂化训练过程,正如强化学习或使用数据驱动的模拟器所可能发生的那样。从对比学习的有效性13中汲取灵感,对比学习通过区分相似和不相似的例子来增强表示 ,我们认识到有机会将因果理解注入模型中。这是通过使模型能够区分原始和修改后的输入数据来实现的------例如,通过从自动驾驶汽车(AV)的角度排除领头车辆。在这种方法和前两种提到的策略的基础上,我们引入了一个新颖的统一框架,称为对比模仿学习(CIL:Contrastive Imitation Learning) 。
In summary, this study introduces a comprehensive, datadriven planning framework named PLUTO, designed to Push the Limit of imitation learning-based planning for aUTOnomous driving. PLUTO incorporates innovative solutions in model architecture, data augmentation, and the learning framework. It has been evaluated using the large-scale real-world nuPlan 14 dataset, where it has demonstrated superior closed-loop performance. Notably, PLUTO surpasses the existing state-of-the-art rule-based planner PDM 2 for the first time, marking a significant milestone in the field. Our main contributions are:
总结来说,本研究介绍了一个全面的、数据驱动的规划框架,名为PLUTO,旨在推动基于模仿学习的自动驾驶规划的极限。PLUTO在模型架构、数据增强和学习框架方面融入了创新的解决方案。它已经使用大规模的真实世界nuPlan数据集14进行了评估,在那里它展示了卓越的闭环性能。值得注意的是,PLUTO首次超越了现有的最先进的基于规则的规划器PDM2,这在该领域标志着一个重要的里程碑。我们的主要贡献包括:
回头学习一下这个PDM
• We introduce a query-based model architecture that simultaneously addresses lateral and longitudinal planning maneuvers, enabling flexible and diverse driving behaviors.
• We propose a novel method for calculating auxiliary loss based on differential interpolation. This method is applicable to a broad spectrum of auxiliary tasks and allows for efficient batch-wise computation in vector-based models.
• We present the Contrastive Imitation Learning (CIL) framework, accompanied by a new set of data augmentations. The CIL framework is aimed at regulating driving behaviors and enhancing interaction learning, without significantly increasing the complexity of training.
• Our evaluation on the large-scale nuPlan dataset demonstrates that PLUTO achieves state-of-the-art performance in closed-loop planning. Our model and benchmark are publicly available.
- 我们引入了一种基于查询的模型架构 ,同时解决了横向和纵向规划操作,实现了灵活多样的驾驶行为。
- 我们提出了一种基于微分插值的新颖辅助损失计算方法。这种方法适用于广泛的辅助任务,并允许在基于向量的模型中进行高效的批量计算。
- 我们展示了对比模仿学习(CIL)框架 ,并伴随一套新的数据增强技术 。CIL框架旨在规范驾驶行为和增强交互学习 ,同时不会显著增加训练的复杂性。
- 我们在大规模的 nuPlan 数据集上的评估表明,PLUTO在闭环规划中实现了最先进的性能。我们的模型和基准测试是公开可用的。
II. RELATED WORK
A. Imitation-based Planning
Learning to drive by cloning the policies of experienced drivers is likely the most direct and scalable solution to autonomous driving, considering the abundance and affordability of data today. One of the popular methods is end-toend (E2E) driving 15. This approach directly learns driving policies from raw sensor data and has made significant strides in a relatively short period. Initially, the focus was on convolutional neural network (CNN)-based models 16, 17 that mapped camera inputs to control policies. This evolved to incorporate more sophisticated methods 18--21 that utilized multi-sensor fusion. More recently, developments spearheaded by entities such as LAV 22 and UniAD 23 have shifted towards a module-based E2E architecture. This approach integrates the processes of perception, prediction, and planning within a unified model 24, 25. Despite their potential, most E2E strategies extensively depend on highfidelity simulation environments like CARLA 26 for both training and evaluation. Consequently, these methodologies are plagued by several issues, including a lack of realism and diversity in simulated agents, reliance on imperfect rule-based experts, and the imperative need to bridge the simulation-toreality gap for applicability in real-world scenarios.
学习驾驶的一种直接且可能具有扩展性的方法是模仿经验丰富的驾驶员的策略,考虑到今天数据的丰富性和可负担性。一种流行的方法是端到端(E2E)驾驶15。这种方法直接从原始传感器数据中学习驾驶策略,并在相对较短的时间内取得了显著进展。最初,重点是使用基于卷积神经网络(CNN)的模型16、17,这些模型将摄像头输入映射到控制策略。这发展到了使用更复杂的方法18-21,这些方法利用了多传感器融合。最近,由LAV22和UniAD23等实体引领的发展转向了基于模块的E2E架构。这种方法在一个统一的模型中整合了感知、预测和规划的过程24、25。尽管它们有潜力,但大多数E2E策略在很大程度上依赖于高保真度仿真环境,如CARLA26,用于训练和评估。因此,这些方法存在几个问题,包括仿真代理的现实性和多样性不足,依赖不完美的基于规则的专家,以及迫切需要弥合仿真与现实之间的差距,以便在现实世界场景中应用。
This paper focuses on another research direction, commonly referred to as the mid-to-mid approach, which employs postperception results as input features. The primary advantage of this method is that the model can concentrate on learning to plan and be trained with real-world data, eliminating sim-to-real transfer concerns. Pioneering approaches such as ChauffeurNet 5, SafetyNet 27, and UrbanDriver 28 have demonstrated the ability to operate autonomous vehicles in real-world environments, with subsequent works building upon these foundations 3, 4, 29--31. These approaches benefit significantly from advancements in the motion forecasting community, including the adoption of vector-based models 4, 28 that excel in prediction tasks, replacing early planning models based on rasterized bird's-eye-view images 5, 9. However, many of these models overlook the inherent characteristics of planning tasks, such as the need for closed-loop testing and active decision-making capabilities. In contrast, our proposed framework is specifically designed for planning from the outset. Our network jointly models longitudinal and lateral driving behaviors through a query-based architecture, enabling a flexible and diverse driving style.
本文专注于另一种研究方法,通常称为"中到中"方法 ,它使用后感知结果作为输入特征 。这种方法的主要优势是模型可以专注于学习规划 ,并且可以用真实世界的数据进行训练 ,消除了从仿真到现实转移的担忧 。像ChauffeurNet5、SafetyNet27和UrbanDriver28这样的开创性方法已经证明了在真实世界环境中操作自动驾驶车辆的能力,随后的工作在这些基础上进行了构建3、4、29-31。这些方法从运动预测社区的进步中受益匪浅,包括采用基于向量的模型4、28,这些模型在预测任务中表现出色,取代了基于光栅化的俯视图图像的早期规划模型5、9。然而,许多这些模型忽视了规划任务的固有特性,例如需要闭环测试和主动决策能力。与此相反,我们提出的框架从一开始就专门设计用于规划。我们的网络通过基于查询的架构联合模拟纵向和横向驾驶行为,实现了灵活多样的驾驶风格。
Prior studies 5, 9--11 have demonstrated the limitations of basic imitation learning and suggested methods for enhancement. In order to address compounding errors, an early solution can be traced back to DAgger 32, which interactively refines the trained model by incorporating additional expert demonstrations. Subsequently, ChauffeurNet 5 introduced perturbation-based augmentation, enabling the model to recover from minor deviations and establishing a standard practice for later research. Adding auxiliary losses such as collision loss and off-road loss 5, 9, 28 is another important aspect to improve the overall performance. However, their method is either designed for heatmap output 5 or requires a differentiable rasterizer 9 that converts the trajectory into a sequence of images with kernel functions. These approaches are not efficiently applicable to vector-based methods. Our research contributes to this field by introducing a novel technique that employs differentiable interpolation to bridge this gap.
先前的研究5、9-11已经展示了基本模仿学习的局限性,并提出了增强方法。为了解决累积误差问题,可以追溯到DAgger32 ,它通过结合额外的专家演示来交互式地细化训练模型 。随后,ChauffeurNet5引入了基于扰动的增强 ,使模型能够从小偏差中恢复 ,并为后续研究建立了标准实践。增加辅助损失,如碰撞损失和驶离道路损失5、9、28,是提高整体性能的另一个重要方面。然而,这些方法要么是为热图输出设计的5,要么需要一个可微分的光栅化器9,它使用核函数将轨迹转换为一系列图像。这些方法不能有效地应用于基于向量的方法。我们的研究通过引入一种使用可微分插值的新技术来填补这一空白。
学一下ChauffeurNet
B. Contrastive Learning
Contrastive learning 33 is a framework that learns representation by comparing similar and dissimilar pairs, achieving significant success in computer vision 13, 34 and natural language processing 35. Within the context of autonomous driving, a few attempts have been made for motion prediction. Social NCE 36 introduced a social contrastive loss to guide goal generation in pedestrian motion forecasting. Marah et al. 37 utilized action-based contrastive learning loss to refine learned trajectory embeddings. FEND 38 employed this approach to recognize long-tail trajectories. These studies underscore the potency of contrastive learning in incorporating domain-specific knowledge into models through the careful selection of positive and negative examples. In our research, we extend its application to the planning domain, aiming to improve driving behavior predictions and facilitate the understanding of implicit interactions among vehicles. As generating negative samples is crucial to contrastive methods, we also introduce a new set of data augmentation functions that defines the contrastive task.
对比学习 33是一个通过比较相似和不相似的对来学习表示的框架,在计算机视觉13、34和自然语言处理35领域取得了显著成功。在自动驾驶的背景下,已经有一些尝试用于运动预测。Social NCE36引入了一种社交对比损失来指导行人运动预测中的目标生成。Marah等人37利用基于动作的对比学习损失来细化学习到的轨迹嵌入。FEND38采用这种方法来识别长尾轨迹。这些研究表明,通过仔细选择正例和负例,对比学习在将领域特定知识整合到模型中的强大潜力。在我们的研究中,我们将对比学习的应用扩展到规划领域,旨在改进驾驶行为预测并促进对车辆之间隐含交互的理解。由于生成负样本对于对比方法至关重要,我们还引入了一组新的数据增强函数,定义了对比任务。
III. METHODOLOGY
A. Problem Formulation
In this study, we explore the task of autonomous driving within dynamic urban settings, considering the autonomous vehicle (AV), NA dynamic agents, NS static obstacles, a highdefinition map M, and other traffic-related contexts C such as traffic light status. We define the features of agents as A = A0:NA, where A0 represents the AV, and static obstacles are denoted by O = O1:NS . Additionally, we denote the future state of agent a at time t as yat , with the historical and future horizons represented by TH and TF , respectively. Our proposed system, PLUTO, is designed to simultaneously generate NT multi-modal planning trajectories for the AV and a prediction for each dynamic agent. The selection of the final output trajectory, τ∗, is executed by a scoring module, S, which integrates learning-based outcomes with all scene contexts. PLUTO is formulated as follows:
在这项研究中,我们探索了在动态城市环境中的自动驾驶任务,考虑了自动驾驶汽车( A V AV AV)、 N A N_A NA 个动态代理、 N S N_S NS 个静态障碍物、高清晰度地图 M M M 以及其他与交通相关的上下文 C C C ,例如交通灯状态。我们定义代理的特征为 A = A 0 : N A A = A_{0:N_A} A=A0:NA,其中 A 0 A_0 A0 代表 A V AV AV,静态障碍物由 O = O 1 : N S O = O_{1:N_S} O=O1:NS 表示。此外,我们表示代理 a a a 在时间 t t t 的未来状态为 y a t y_a^t yat,历史和未来的时间范围分别由 T H T_H TH 和 T F T_F TF 表示。我们提出的系统 PLUTO 旨在同时为 A V AV AV 生成 N T N_T NT 条多模态规划轨迹 ,并为每个动态代理生成预测 。最终输出轨迹 τ ∗ τ^∗ τ∗ 的选择由评分模块 S S S 执行 ,该模块将基于学习的成果与所有场景上下文整合。PLUTO的公式化如下:

where f denotes the neural network of PLUTO, ϕ is the model parameters, (T0, π0) = {(y01: ,iTF , πi) | i = 1 . . . NT} is AV's planning trajectories and corresponding confidence scores, P1:NA = {ya1:TF | a = 1 . . . NA} are agents' predictions.
The subsequent sections provide a detailed illustration of each component within the PLUTO framework.
在这个公式中, f f f 表示 PLUTO 的神经网络, ϕ \phi ϕ 是模型参数。 ( T 0 , π 0 ) = { ( y 0 , i 1 : T F , π i ) ∣ i = 1... N T } (T_0, \pi_0) = \{ (y_{0,i}^{1:T_F}, \pi_i) | i = 1 ... N_T\} (T0,π0)={(y0,i1:TF,πi)∣i=1...NT} 表示自动驾驶汽车(AV)的规划轨迹和相应的置信度分数,其中 y 0 , i 1 : T F y_{0,i}^{1:T_F} y0,i1:TF 代表在时间 T F T_F TF 时 AV 的第 i i i 条规划轨迹, π i \pi_i πi 是对应这条轨迹的置信度分数。 P 1 , N A = { y a 1 : T F ∣ a = 1... N A } P_{1,N_A} = \{ y_{a}^{1:T_F} | a = 1 ... N_A \} P1,NA={ya1:TF∣a=1...NA} 表示其他动态代理的预测,其中 y a , 1 T F y_{a,1}^{T_F} ya,1TF 代表代理 a a a 在时间 T F T_F TF 的预测状态。
在接下来的部分中,PLUTO框架的每个组成部分将得到详细说明。
B. Input Representation and Scene Encoding
Agent History Encoding. The observational state of each agent at any given time t is denoted as st i = (pt i, θit, vit, bt i, It i), where p and θ represent the agent's position coordinates and heading angle, respectively; v refers to the velocity vector, b defines the dimensions (length and width) of the perception bounding box; and I is a binary indicator signifies the observation status of this frame. We convert the history sequence into vector form by calculating the difference between consecutive time steps: sˆt i = pt i − pt i−1, θit − θit−1, vit − vit−1, bt i, It i, resulting in agent's feature vector FA ∈ RNA×(TH−1)×8. To extract and condense these historical features, we employ a neighbor attention-based Feature Pyramid Network (FPN) 39, which produces an agent embedding EA ∈ RNA×D, with D representing the dimensionality of the hidden layers used consistently throughout this paper.
在这段描述中,我们了解到PLUTO框架如何对每个代理(包括自动驾驶汽车和其他动态代理)的历史状态进行编码 :

Static Obstacles Encoding. In contrast to motion forecasting tasks where static obstacles are often overlooked, the presence of static obstacles is crucial for ensuring safe navigation. Static obstacles encompass any entities that an AV must not traverse, such as traffic cones or barriers. Each static obstacle within the drivable area is represented by oi = (pi, θi, bi). We use a twolayer multi-layer-perceptron (MLP) to encode static objects features FO ∈ RNS×5, resulting in embedding EO ∈ RNS×D.
静态障碍物编码 。与运动预测任务不同,在这些任务中静态障碍物经常被忽视 ,静态障碍物的存在对于确保安全导航至关重要。静态障碍物包括任何自动驾驶车辆( A V AV AV)不得穿越的实体,如交通锥或障碍物 。在可行驶区域内的每个静态障碍物由 o i = ( p i , θ i , b i ) o_i = (p_i, θ_i, b_i) oi=(pi,θi,bi) 表示。我们使用一个双层多层感知器(MLP)来编码静态对象特征 F O ∈ R N S × 5 F_O ∈ \mathbb R^{N_S×5} FO∈RNS×5,从而得到嵌入 E O ∈ R N S × D E_O ∈ \mathbb R^{N_S×D} EO∈RNS×D。
AV's State Encoding. Drawing on insights from previous studies 3, 8 that imitation learning tends to adopt shortcuts from historical states, thereby detrimentally affecting performance, our approach only utilize the current state of AV as the input feature. This current state encompasses the AV's position, heading angle, velocity, acceleration, and steering angle. To encode the state feature while avoiding the generation of trajectories based on extrapolated kinematic states, we employ an attention-based state dropout encoder (SDE), as suggested in 3. The encoded AV's embedding is EAV ∈ R1×D.
自动驾驶车辆(AV)的状态编码 。借鉴之前研究3、8的见解,模仿学习倾向于采用历史状态的捷径 ,从而对性能产生不利影响 ,我们的方法仅使用AV的当前状态 作为输入特征。这种当前状态包括AV的位置、航向角、速度、加速度和转向角 。为了避免基于外推运动状态生成轨迹 ,我们采用了基于注意力的状态丢弃编码器(SDE) ,如3中建议的。编码后的AV嵌入是 E A V ∈ R 1 × D E_{AV} ∈ \mathbb R^{1×D} EAV∈R1×D。
Vectorized Map Encoding. The map consists of NP polylines. These polylines undergo an initial subsampling process to standardize the quantity of points, followed by the computation of a feature vector for each point. Specifically, for each polyline, the feature of the i-th point encompasses eight channels: (pi − p0, pi − pi−1, pi − pleft i , pi − pright i ). Here, p0 denotes the initial point of the polyline, while pleft i and p right i represent the left and right boundary points of the lane, respectively. Incorporating the boundary feature is crucial as it conveys information about the drivable area, essential for planning tasks. The features of the polylines are represented as FP ∈ RNP ×np×8, where np denotes the number of points per polyline. To encode the map features, a PointNet-like 40 polyline encoder is employed, resulting in an encoded feature space EP ∈ RNP ×D.
矢量化地图编码 。 地图由 N P N_P NP 条折线组成 。 这些折线首先经过一个初步的子采样过程 ,以标准化点的数量 ,然后计算每个点的特征向量 。具体来说,对于每条折线,第 i i i 个点的特征包括八个通道 : ( p i − p 0 , p i − p i − 1 , p i − p i l e f t , p i − p i r i g h t ) (p_i - p_0, p_i - p_{i-1}, p_i - p^{left}_i, p_i - p^{right}_i) (pi−p0,pi−pi−1,pi−pileft,pi−piright)。这里,p 0 p_0 p0 表示折线的起始点 ,而 p i l e f t 和 p i r i g h t p^{left}_i 和 p^{right}_i pileft和piright 分别代表车道的左侧和右侧边界点。包含边界特征是至关重要的 ,因为它传达了关于可行驶区域的信息 ,这对于规划任务至关重要。折线的特征表示为 F P ∈ R N P × n p × 8 F_P ∈ \mathbb R^{N_P×n_p×8} FP∈RNP×np×8,其中 n p n_p np 表示每条折线的点数。为了编码地图特征,采用了类似PointNet40的折线编码器,得到编码后的特征空间 E P ∈ R N P × D E_P ∈ R^{N_P×D} EP∈RNP×D。
Scene Encoding. To effectively capture the intricate interactions among various modal inputs, we concatenate different embeddings into a single tensor E0 ∈ R(NA+NS+NP +1)×D. This tensor is subsequently integrated using a series of Lenc Transformer encoders. Due to the vectorization process, the input features are stripped of their global positional information. To counteract this loss, a global positional embedding, denoted as PE, is introduced to each embedding. Following 41, PE represents the Fourier embedding of the global position (p, θ), utilizing the most recent positions of agents and static obstacles as well as the initial point of polylines. Additionally, to encapsulate inherent semantic attributes such as agent types, lane speed limits, and traffic light statuses, learnable embeddings Eattr are incorporated alongside the input embeddings. E0 is initialized as
场景编码 。为了有效地捕捉各种模态输入之间的复杂交互 ,我们将不同的嵌入连接成一个单一的张量 E 0 ∈ R ( N A + N S + N P + 1 ) × D E_0 ∈ \mathbb R^{(N_A+N_S+N_P+1)×D} E0∈R(NA+NS+NP+1)×D。然后,使用一系列 L e n c L_{enc} Lenc Transformer编码器整合这个张量。由于向量化过程,输入特征失去了它们的全局位置信息 。为了抵消这种损失 ,我们向每个嵌入引入了一个全局位置嵌入 ,记为 P E PE PE。根据41, P E PE PE 表示全局位置 ( p , θ ) (p, θ) (p,θ) 的傅里叶嵌入 ,利用代理和静态障碍物的最新位置以及折线的初始点。此外,为了包含固有的语义属性,如代理类型、车道速度限制和交通灯状态,可学习的嵌入 E a t t r E_{attr} Eattr 与输入嵌入一起被纳入。 E 0 E_0 E0 初始化为:

这里的 E A V E_{AV} EAV 是 A V AV AV 的嵌入, E O E_O EO 是静态障碍物的嵌入, E P E_P EP 是地图的嵌入, P E PE PE 是全局位置嵌入, E a t t r E_{attr} Eattr 是语义属性的可学习嵌入。通过这种方式,场景编码能够综合考虑来自不同源的信息,为后续的决策和规划任务提供丰富的上下文。
kimi
感觉好像是类似原始transformer的位置嵌入的编码方式

The i-th layer of the Transformer encoder is formulated as
第 i 层的Transformer编码器可以用以下公式来描述:

前馈神经网络(Feed-Forward Neural Network, FFN)
MHA 通常指的是 "Multi-Head Attention",即多头注意力机制,它是 Transformer 架构中的核心组件之一。在多头注意力机制中,自注意力(Self-Attention)被扩展到多个不同的表示子空间中,允许模型在不同的表示子空间中并行学习信息
where MHA(q, k, v) is the standard multi-head attention 42 function, FFN is the feedforward network layer. We denote Eenc as the output of the final layer of the enoder.
其中 M H A ( q , k , v ) MHA(q, k, v) MHA(q,k,v) 是标准的多头注意力42函数, F F N FFN FFN 是前馈网络层。我们将 E e n c E_{enc} Eenc 表示为编码器最后一层的输出。
C. Multi-modal Planning Trajectory Decoding
The task of planning in autonomous driving is inherently multimodal, as there are often multiple valid behaviors that could be adopted in response to a given driving scenario. For instance, a vehicle might either continue to follow a slower vehicle ahead or opt to change lanes and overtake it. To address this complex issue, we utilize a query-based, DETRlike 43 trajectory decoder. However, directly implementing the learned anchor-free queries has been found to result in mode collapse and training instability, as evidenced in 44. Drawing inspiration from the observation that driving behaviors can be decomposed into combinations of lateral (e.g., lane changing) and longitudinal (e.g., braking and accelerating) actions, we introduce a semi-anchor-based decoding structure. An illustrative overview of our decoding pipeline is presented in Fig. 1, with subsequent paragraphs detailing the individual components.
自动驾驶中的规划任务本质上是多模态的 ,因为在给定的驾驶场景下,通常有多种有效的行为可以采用 。例如,车辆可能会选择继续跟随 前方较慢的车辆,或者选择变道超车 。为了解决这个复杂问题,我们采用了基于查询的、类似DETR43的轨迹解码器。然而,直接实现学习到的无锚点查询被发现会导致模式崩溃和训练不稳定 ,这一点在44中有证据支持。受到驾驶行为可以分解为横向(例如,变道)和纵向(例如,刹车和加速)动作组合的观察启发,我们引入了一种半锚点基础的解码结构。我们的解码流程的说明性概览如 图1 所示,随后的段落详细说明了各个组件。


图1. 本节介绍了PLUTO模型的架构概览 。该模型使用基于相邻参考线的折线编码器初始化横向查询 Q l a t Q_{lat} Qlat。同时,纵向查询 Q l o n Q_{lon} Qlon 被建立为可学习的嵌入。这些查询通过分解的横向-纵向自注意力层进行融合过程。这种整合作为后续轨迹解码及其相关分数的基础。
Reference Lines as Lateral Queries. Following the methodology outlined in 4, this study employs reference lines as a high-level abstraction for lateral queries. Reference lines, typically derived from the autonomous vehicle's surrounding lanes on its route, serve as a critical component in conventional vehicle motion planning, guiding lateral driving behaviors. Initially, we identify lane segments within a radius of Rref from the AV's current position. Starting from each identified lane segment, a depth-first search is conducted to explore all potential topological connections, linking their respective lane centerlines. Subsequently, these connected centerlines are truncated to a uniform length and are resampled to maintain a consistent number of points. The approach for representing and encoding the features of reference lines mirrors that of vectorized map encoding, as outlined in Section III-B. Ultimately, the embedded reference lines are utilized as the lateral query Qlat ∈ RNR×D, where NR represents the number of reference lines.
参考线作为横向查询 。本研究遵循4中概述的方法,使用参考线作为横向查询的高级抽象 。参考线通常来源于自动驾驶车辆在其路线周围车道上,是传统车辆运动规划中的关键组成部分,指导横向驾驶行为。最初,我们从自动驾驶车辆当前位置的 R r e f R_{ref} Rref 半径内识别车道段。从每个识别出的车道段开始,进行深度优先搜索以探索所有潜在的拓扑连接 ,将它们各自的车道中心线连接起来 。随后,这些连接的中心线被截断到统一的长度 ,并重新采样以保持一致的点数 。表示和编码参考线特征的方法与第三章节B中概述的矢量化地图编码相似。最终,嵌入的参考线被用作横向查询 Q l a t ∈ R N R × D Q_{lat} ∈ \mathbb R^{N_R×D} Qlat∈RNR×D,其中 N R N_R NR 代表参考线的数量。
Factorized Lateral-longitudinal Self-Attention. In addition to Qlat, we employ NL anchor-free, learnable queries Qlon ∈ RNL×D to encapsulate the multi-modal nature of longitudinal behaviors. Following this, Qlat and Qlon are combined to create the initial set of lateral-longitudinal queries, denoted as Q0 ∈ RNR×NL×D:
分解的横向-纵向自注意力。除了 Q l a t Q_{lat} Qlat 之外,我们采用 N L N_L NL 个无锚点、可学习的查询 Q l o n ∈ R N L × D Q_{lon} ∈ \mathbb R^{N_L×D} Qlon∈RNL×D 来封装纵向行为的多模态特性。随后, Q l a t Q_{lat} Qlat 和 Q l o n Q_{lon} Qlon 被结合起来,创建初始的横向-纵向查询集合,记作 Q 0 ∈ R N R × N L × D Q_0 ∈ R^{N_R×N_L×D} Q0∈RNR×NL×D:

where Projection refers to either a simple linear layer or a multilayer perceptron. Since each query within Q0 captures only the local region information pertaining to an individual reference line, we utilize self-attention mechanisms on Q0 to integrate global lateral-longitudinal information across various reference lines. Nonetheless, applying self-attention directly to Q0 results in computational complexity of O NR2NL2, which becomes prohibitively high as NR and NL increase. Drawing inspiration from similar approaches in the literature 45, we adopt a factorized attention strategy across each axis of Q, effectively reducing the computational complexity to O NR2NL + NRNL2.
这里的"Projection"指的是一个简单的线性层或者是一个多层感知机 。由于 Q 0 Q_0 Q0 中的每个查询只捕捉到与单个参考线相关的局部区域信息,我们利用自注意力机制对 Q 0 Q_0 Q0 进行操作,以整合不同参考线之间的全局横向-纵向信息。然而,直接对 Q 0 Q_0 Q0 应用自注意力会导致计算复杂度达到 O ( N R 2 , N L 2 ) O(N_R^2,N_L^2) O(NR2,NL2),随着 N R N_R NR 和 N L N_L NL 的增加,这变得非常高。借鉴文献45中的类似方法,我们采用了一种在 Q Q Q 的每个轴上分解注意力的策略 ,有效地将计算复杂度降低 到 O ( N R 2 N L + N R N L 2 ) O(N_R^2N_L + N_RN_L^2) O(NR2NL+NRNL2)。
Trajectory Decoding. The trajectory decoder consists of a sequence of Ldec decoding layers, each comprising three types of attention mechanisms: lateral self-attention, longitudinal selfattention, and query-to-scene cross-attention. These processes are mathematically represented as follows:
轨迹解码 。轨迹解码器由 L d e c L_{dec} Ldec 个解码层组成,每个解码层包括三种类型的注意力机制 :横向自注意力 、纵向自注意力 和查询到场景的交叉注意力。这些过程可以用以下数学公式表示:
- 横向自注意力:这种机制允许解码器在横向维度上关注轨迹的不同部分,以理解车辆如何在车道内移动。
- 纵向自注意力:这种机制使解码器能够在纵向维度上关注轨迹的不同部分,以理解车辆如何在时间上加速或减速。
- 查询到场景的交叉注意力:这种机制允许解码器将车辆的轨迹预测与周围环境(如其他车辆、行人、障碍物等)的信息结合起来,以生成更安全、更准确的轨迹。
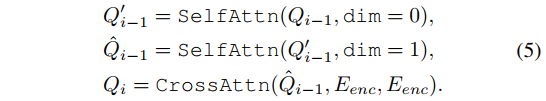
Here, SelfAttn(X, dim = i) indicates the application of self-attention across the i-th dimension of X, and CrossAttn(Q, K, V ) incorporates layer normalization, multi-head attention, and a feed-forward network, analogous to the structure defined in Eq. 3. The decoder's final output, Qdec, is then employed to determine the AV's future trajectory points and their respective scores using two MLPs:
在这里, S e l f A t t n ( X , d i m = i ) SelfAttn(X, dim = i) SelfAttn(X,dim=i) 表示在 X X X 的第 i i i 维度上应用自注意力机制,而 C r o s s A t t n ( Q , K , V ) CrossAttn(Q, K, V) CrossAttn(Q,K,V) 包含了层归一化、多头注意力和前馈网络,类似于在公式 3 中定义的结构。解码器的最终输出, Q d e c Q_{dec} Qdec,随后被用来通过两个多层感知机(MLPs)确定自动驾驶车辆(AV)的未来轨迹点及其相应的分数:

Each decoded trajectory point has six channels: px, py, cos θ, sin θ, vx, vy. Furthermore, to accommodate scenarios lacking reference lines, an additional MLP head is introduced to directly decode a single trajectory from the encoded features of the AV:
每个解码的轨迹点包含六个通道: p x , p y , c o s θ , s i n θ , v x , v y p_x, p_y, cosθ, sinθ, v_x, v_y px,py,cosθ,sinθ,vx,vy。此外,为了适应缺乏参考线的场景 ,引入了一个额外的多层感知机(MLP)头 ,直接从自动驾驶车辆(AV)的编码特征中解码单一轨迹 :

Imitation Loss. To avoid mode collapse, we employ the teacher-forcing 46 technique during the training process. Firstly, the endpoint of the ground truth trajectory τ gt is projected relative to reference lines, with the selection of the reference line closest in lateral distance serving as the target reference line. This target reference line is subsequently divided into NL−1 equal segments by distance. Each segment corresponds to the region managed by each longitudinal query, with the final query accounting for regions extending beyond the target reference line. The query encompassing the projected endpoint is designated as the target query. By integrating the target reference line with the target longitudinal query, we derive the target supervision trajectory, τˆ. For trajectory regression, we employ the smooth L1 loss 47, and for score classification, we utilize the cross-entropy loss, expressed as follows:
模仿损失 。为了避免模式崩溃 ,我们在训练过程中采用46中提到的教师强制技术 。首先,将真实轨迹 τ g t τ^{gt} τgt 的终点相对于参考线进行投影,选择横向距离最近的参考线作为目标参考线 。然后,目标参考线被距离等分为 N L − 1 N_{L−1} NL−1 个相等的段。每个段对应于每个纵向查询管理的区域,最后一个查询负责超出目标参考线区域的区域。包含投影终点的查询被指定为目标查询。通过将目标参考线与目标纵向查询相结合,我们得出目标监督轨迹 τ ^ \hat τ τ^。对于轨迹回归,我们采用平滑 L1 损失47,对于分数分类,我们使用交叉熵损失,表达如下:

where π∗ 0 signifies the one-hot distribution derived from the index of τˆ. The overall imitation loss is formulated as the sum of these two components, each weighted equally:
其中 π 0 ∗ π^∗_0 π0∗ 表示从 τ ^ \hat τ τ^ 的索引派生的独热分布 。总体模仿损失被制定为这两个组成部分的和,每个部分权重相等:

Prediction Loss. A simple two-layer MLP is used to generate a single modal prediction for each dynamic agent from the encoded agents' embeddings:
预测损失 。使用一个简单的两层多层感知器 (MLP)从编码后的代理嵌入中为每个动态代理生成单个模态预测 :

Firstly, this provides dense supervision which benefits the training 39, 48. Secondly, the generated predictions play a crucial role in eliminating unsuitable planning proposals during the post-processing stage, as detailed in Section III-F. Denote agent's ground truth trajectory as P1: gtNA, the prediction loss is
首先,这提供了密集的监督,这对训练是有益的 39,48。其次,生成的预测在后处理阶段消除不合适的规划提案中起着至关重要的作用,如第三部分 F 节详细说明的。将代理的真实轨迹表示为 P 1 : N A g t P^{gt}_{1:N_A} P1:NAgt,预测损失 是:

D. Efficient Differentiable Auxiliary Loss
As highlighted by earlier studies 5, 12, pure imitation learning does not suffice to preclude undesired outcomes, such as collisions with stationary obstacles or deviations from the drivable path. Therefore, it is essential to incorporate these constraints as auxiliary losses in the model during its training phase. Nevertheless, the integration of these constraints in a manner that is differentiable and enables end-to-end training of the model presents a significant challenge. A frequently adopted method for this purpose is differentiable rasterization. For instance, Zhou et al. 9 demonstrates a technique where each trajectory point is converted into rasterized images, using a differentiable kernel function, and subsequently calculates the loss using obstacle masks within the image space. This method, however, is limited by its computational and memory demands, which in turn limits the output resolution (e.g., it permits only large time intervals and short planning horizons). To mitigate these limitations, we propose a novel approach based on differentiable interpolation. This method facilitates the concurrent calculation of auxiliary loss for all trajectory points. We take the drivable area constraint an example to elucidate our proposed method.
正如早期研究5、12所强调的,纯粹的模仿学习不足以排除不希望的结果 ,例如与静止障碍物的碰撞或偏离可行驶路径 。因此,在模型的训练阶段 将这些约束作为辅助损失 纳入模型中是至关重要 的。然而,以一种可微分的方式整合这些约束 ,并使得模型能够进行端到端训练,这是一个重大挑战。为此目的经常采用的方法是可微分光栅化。例如,周等人9展示了一种技术,其中每个轨迹点被转换为光栅化图像,使用可微分的核函数,并随后在图像空间内使用障碍物掩码计算损失。然而,这种方法受到其计算和内存需求的限制,这反过来又限制了输出分辨率(例如,它只允许较大的时间间隔和短的规划视野)。为了减轻这些限制,我们提出了一种基于可微分插值的新方法 。这种方法便于同时计算所有轨迹点的辅助损失。我们以可行驶区域约束为例来阐明我们提出的方法。
Cost Map Construction. The first step of our methodology involves transforming the constraint into a queryable cost-map representation. Specifically, for the drivable area constraint, we employ the widely recognized Euclidean Signed Distance Field (ESDF) for cost representation. This process encompasses mapping the non-drivable areas (e.g., off-road regions) onto an H ×W rasterized binary mask, followed by executing distance transforms on this mask. A distinctive advantage of our approach over existing methods is its elimination of the need to render the trajectory into a series of images, thereby significantly reducing computational demands.
成本图构建 。我们方法的第一步涉及将约束转换为可查询的成本图表示 。具体来说,对于可行驶区域约束,我们采用广泛认可的欧几里得有符号距离场(ESDF)进行成本表示 。这个过程包括将不可行驶区域(例如,越野区域)映射到一个 H × W 像素的光栅化二进制掩码上 ,然后对这个掩码执行距离变换。我们的方法与现有方法的一个显著优势是它消除了将轨迹渲染成一系列图像的需求 ,从而显著降低了计算需求。
Loss Calculation In accordance with established methodologies in optimization-based vehicle motion planning 49, we model the vehicle's shape using Nc covering circles. The trajectory point determines the centers of these circles, which can be derived in a differentiable manner. As illustrated in Fig. 2, for each covering circle i associated with a trajectory point, we obtain its signed distance value di through projection and bilinear interpolation. To ensure adherence to the drivable area constraint, we apply a penalty to the model when di falls below the circle's radius Rc. The auxiliary loss is:
损失计算 。根据基于优化的车辆运动规划中建立的方法49,我们使用 N c N_c Nc 个覆盖圆来模拟车辆的形状 。轨迹点决定了这些圆的中心,这些中心可以通过可微分的方式推导出来 。如图 2 所示,对于与轨迹点相关联的每个覆盖圆 i i i,我们通过投影和双线性插值获得其有符号距离值 d i d_i di。为确保遵守可行驶区域约束,当 d i d_i di 低于圆的半径 R c R_c Rc 时,我们对模型施加惩罚 。辅助损失 是:

图 2. 提出的辅助损失 计算方法的示意图。首先,神经网络产生的轨迹被映射到与成本图相关联的图像空间 。随后,通过双线性插值获得成本值 ,并用于形成损失函数 。鉴于所有涉及的过程都是可微分的,将辅助任务直接纳入框架是可行的,允许进行端到端训练。
在这个过程中,轨迹点首先被映射到成本图的图像空间中。然后,通过双线性插值计算出每个轨迹点在成本图上的值。这些值随后被用于计算辅助损失,以确保轨迹满足特定的约束条件,例如保持在可行驶区域内。通过将这些辅助损失整合到主损失函数中,可以确保在训练过程中同时优化轨迹预测和遵守约束条件,从而提高模型的泛化能力和实际应用的安全性。
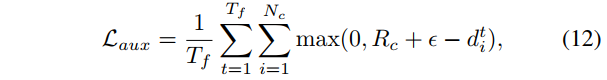
where ϵ is a safety threshold. Eq. 12 is also applicable to punish collisions with a slight change to the cost map construction.
这里的 ϵ 表示一个安全阈值。方程 12 也适用于惩罚碰撞,只需对成本图构建进行轻微的修改即可。
在这种情况下,成本图构建会考虑碰撞的可能性,并将碰撞区域标记为高成本值 。当轨迹点的投影距离值 d i d_i di 小于安全阈值 ϵ 时,意味着车辆可能会与障碍物发生碰撞,因此模型会受到惩罚。这种惩罚可以通过修改辅助损失函数来实现,确保轨迹保持在安全距离内,避免与障碍物发生碰撞。
在这个函数中,如果 d i d_i di 小于 ϵ,那么损失项将增加,从而在训练过程中鼓励模型避免生成可能导致碰撞的轨迹。这种方法允许模型在考虑安全性的同时进行优化,提高自动驾驶系统的可靠性和安全性。
In practice, di and Laux can be differentiably and efficiently calculated batch-wise with the modern deep learning framework as shown in Algorithm 1. It is important to note that our approach is versatile and not confined to ESDF-based representations alone. Any cost representation that allows for continuous querying, such as potential fields, can be incorporated with an appropriately designed loss function.
在实践中, d i d_i di 和 L a u x L_{aux} Laux 可以通过现代深度学习框架以批处理方式进行可微分和高效计算 ,如算法 1 所示。重要的是要注意,我们的方法具有通用性,并不局限于基于 ESDF 的表示。任何允许连续查询的成本表示,如势场,都可以与适当设计的损失函数结合使用。
这种方法的优势在于其灵活性和可扩展性,能够适应不同的成本表示和约束条件。通过设计适当的损失函数,可以轻松地将新类型的成本表示集成到模型中,从而扩展模型的应用范围和适应性。这种设计允许研究人员和工程师根据特定的应用需求和环境条件定制和优化模型,以实现最佳的性能和安全性。
在算法 1 中,可能会展示如何使用深度学习框架(如 TensorFlow 或 PyTorch)来实现这种批处理计算,包括数据的预处理、损失函数的计算以及梯度的反向传播。这种实现不仅提高了计算效率,还使得模型训练过程更加直观和易于管理。
E. Contrastive Imitation Learning Framework
We introduce the Contrastive Imitation Learning (CIL) framework, designed to effectively address the challenges of distribution shift and causal confusion within a coherent and straightforward structure. Illustrated in Fig. 3, the CIL framework comprises four essential steps:
我们引入了对比模仿学习(Contrastive Imitation Learning, CIL)框架 ,旨在在一个连贯且直接的结构中有效地解决分布偏移和因果混淆的挑战。如图 3 所示,CIL 框架包括四个基本步骤:
- 数据预处理:在这一步中,原始数据被清洗和格式化,以便后续处理。这可能包括归一化、去噪、特征提取等操作。
- 代理模型训练:使用模仿学习的方法训练一个代理模型,该模型能够从专家数据中学习行为策略。这个步骤通常涉及监督学习,其中代理模型尝试复制专家的行为。
- 对比学习:在这一步中,代理模型生成的行为与专家数据进行对比。通过这种方式,模型学习区分哪些行为是有效的,哪些是无效的。这通常涉及到构建一个损失函数,该函数能够惩罚模型生成与专家行为不一致的行为。
- 端到端优化:最后一步是将对比学习的结果反馈到模型训练过程中,以进行端到端的优化。这意味着模型会不断地调整其参数,以减少生成行为与专家行为之间的差异。
CIL 框架通过这四个步骤,不仅能够模仿专家的行为,还能够理解行为背后的因果关系,从而在面对新的、未见过的情况时,能够做出更加合理和有效的决策。这种框架特别适用于那些需要模型能够理解和泛化专家行为的场景,如自动驾驶、机器人控制等领域。

图 3. 提出的对比模仿学习(Contrastive Imitation Learning, CIL)框架的示意图 。对于任何输入数据,我们从不同的增强模块应用两个数据增强函数 t ∼ T + 和 t ′ ∼ T − t \sim T^+ 和 t' \sim T^- t∼T+和t′∼T− 来获得一个正样本和一个负样本 。投影的潜在嵌入 z ( ⋅ ) z^{(\cdot)} z(⋅) 被用来计算保守损失,该损失最大化 z + 和 z z^+ 和 z z+和z 之间的一致性,并最小化 z − 和 z z^- 和 z z−和z 之间的一致性。
• Given a training scenario data sample, denoted as x, we apply both a positive data augmentation module, T +, and a negative one, T −, to generate a positive sample x+ and a negative sample x−. Positive augmentations are those that preserve the validity of the original ground truth (e.g., see Fig. 4a), while negative augmentations alter the original causal structure, rendering the original ground truth inapplicable.
• The Transformer encoder, as detailed in Sect. III-B, is utilized to derive the latent representations h(·) of both the original and augmented data samples. Subsequently, these representations are mapped to a new space, represented as z, z+, z−, by a two-layer MLP projection head.
• A triplet contrastive loss is calculated to enhance the agreement between z and z+ while decreasing the similarity between z and z−.
• Finally, trajectories for the original and positively augmented data samples are decoded, and both the imitation loss and an auxiliary loss are computed.
在对比模仿学习(CIL)框架中,对于给定的训练场景数据样本 x x x,我们采取以下步骤:
- 数据增强 :
- 应用正数据增强模块 T + T^+ T+ 和负数据增强模块 T − T^- T− 来生成正样本 x + x^+ x+ 和负样本 x − x^- x−。
- 正增强保留原始真实标签的有效性 (例如,见图 4a ),而负增强改变原始的因果结构,使得原始真实标签不再适用。
- 潜在表示提取 :
- 使用在第三节 III-B 中详细描述的 Transformer 编码器来派生原始和增强数据样本的潜在表示 h ( ⋅ ) h^{(\cdot)} h(⋅)。
- 然后,这些表示通过一个两层的多层感知器(MLP)投影头被映射到一个新的空间,表示为 z z z, z + z^+ z+, z − z^- z−。
- 对比损失计算 :
- 计算一个三元组对比损失,以增强 z z z 和 z + z^+ z+ 之间的一致性,同时减少 z z z 和 z − z^- z− 之间的相似性。
- 轨迹解码和损失计算 :
- 对原始数据样本和正向增强数据样本的轨迹进行解码。
- 计算模仿损失和辅助损失。
"正数据增强模块 "通常指的是在机器学习和深度学习领域中,用于提高模型泛化能力和性能的一种技术。它通过在训练数据上应用一系列变换,生成新的、略微修改过的样本,从而增加数据的多样性。这些变换可以是旋转、缩放、裁剪、颜色调整等,目的是让模型在面对不同的、未见过的数据时也能表现出良好的识别和预测能力。简而言之,正数据增强有助于模型学习到更加鲁棒的特征表示,减少过拟合的风险。
"负数据增强模块"通常是指在机器学习或深度学习中,用于生成或选择负样本(即非目标类样本)以增强训练数据集的模块。在许多监督学习任务中,如分类问题,数据集往往包含正样本(即目标类样本)和负样本。通过增加负样本的数量或质量,可以提高模型对不同类别的区分能力,从而提升模型的性能。这种技术尤其在数据不平衡的情况下非常重要,因为它有助于减少模型对多数类(正样本)的偏见,使模型更加公平和准确。
In practice, we randomly sample a minibatch of Nbs samples. Each sample undergoes positive and negative augmentation, executed by augmentors randomly chosen from the sets T + and T −, respectively. This augmentation triples the total number of samples to 3Nbs. All samples are processed by the same encoder and projection head. Let sim(u, v) = uT v/ ∥u∥ ∥v∥ denote the dot product between the l2 normalized u and v, the softmax-based triple contrastive loss 50 is defined as:
在实践中,我们随机抽取一个包含 N b s N_{bs} Nbs 个样本的小批量。每个样本都会经历正向和负向增强,分别由从集合 T + T^+ T+ 和 T − T^− T− 中随机选择的增强器执行。这种增强将样本总数增加到 3 N b s 3N_{bs} 3Nbs。所有样本都由同一个编码器和投影头处理。设 s i m ( u , v ) = u T v / ∥ u ∥∥ v ∥ sim(u, v) = u^T v / ∥u∥ ∥v∥ sim(u,v)=uTv/∥u∥∥v∥ 表示经过 L2 归一化的 u 和 v 之间的点积,基于softmax的三重对比损失50定义为:

where σ denotes the temperature parameter. The contrastive loss is computed across all triplets in the mini-batch. Besides this, we provide supervision to both the original and positively augmented samples using the unmodified ground truth trajectory. Note that negatively augmented samples are only used to calculate the contrastive loss as their origin ground truth may be invalid after augmentation. The overall training loss comprises four components: imitation loss, prediction loss, auxiliary loss, and contrastive loss, represented as:
其中 σ σ σ 表示温度参数。对比损失是在整个小批量中的所有三元组上计算的。除此之外,我们使用未修改的真实轨迹对原始样本和正向增强样本提供监督。请注意,负向增强样本仅用于计算对比损失 ,因为增强后它们的原始真实轨迹可能无效 。整体训练损失包括四个组成部分:模仿损失 、预测损失 、辅助损失 和对比损失 ,表示为:

在这段文本中,"temperature"指的是温度参数(σ) ,它在机器学习,尤其是深度学习中,常用于控制对比损失(contrastive loss)的计算 。在对比损失的上下文中,温度参数用于调整损失函数的敏感性 ,即通过调整温度参数,可以控制模型对样本间差异的敏感程度。温度参数较低时,模型对样本间的差异更加敏感;温度参数较高时,模型对样本间的差异则不那么敏感。这有助于模型在训练过程中更好地区分正样本和负样本,从而优化模型的性能。
Data augmentations. Data augmentation is the key for contrastive learning to work. While perturbation-based augmentations are prevalent, alternative augmentation strategies remain insufficiently explored. In this context, we present six carefully crafted augmentation functions that defines the contrastive task, with illustrative examples provided in Fig. 4.
数据增强 。数据增强是对比学习工作的关键。虽然基于扰动的增强非常普遍,但其他替代增强策略尚未得到充分探索。在这种情况下,我们提出了六个精心设计的增强函数,这些函数定义了对比任务,并在 图4 中提供了说明性示例。

图4. 所提出数据增强的示例场景 。在每组中,左边的图表示原始场景,右边的图显示增强后的场景。自动驾驶车辆(AV)用橙色标记,其他车辆代理用蓝色表示,车道上的虚线表示交通灯状态。(a)-(b) 属于正向增强 T + T^+ T+,而(c )-(f) 是负向增强 T − T^- T−。
(1) State Perturbation ∈ T + (Fig. 4a): introduces minor, randomly generated disturbances to the autonomous vehicle's current position, velocity, acceleration, and steering angle. This augmentation is intended to enable the model to learn recovery strategies for slight deviations from the training distribution. The CIL framework aims to maximize the similarity between the latent representations of original and augmented samples, thereby enhancing the model's resilience to error accumulation.
(2) Non-interactive Agents Dropout ∈ T + (Fig. 4b): omits agents from the input scenario that do not interact with the AV in the near future. Interactive agents are identified through the intersection of their future bounding boxes with the AV's trajectory. This augmentation prevents the model from learning behaviors by mimicking noninteractive agents, thereby encouraging the model to discern genuine causal relationships with interactive agents.
(3) Leading Agents Dropout ∈ T − (Fig. 4c): removes all agents located ahead of the AV. Special consideration is given to leading-following dynamics, a prevalent situation in real-world driving. This augmentation trains the model on leading-following behaviors to prevent rear-end collisions.
(4) Leading Agent Insertions ∈ T − (Fig. 4d): introduces a leading vehicle into the AV's original path, at a position where the AV's expected trajectory becomes invalid (e.g., would result in a collision). The inserted vehicle's trajectory data is sourced from a randomly selected agent in the current mini-batch to maintain data realism.
(5) Interactive Agent Dropout ∈ T − (Fig. 4e): excludes agents that have direct or indirect interactions with the AV. Identification of interactive agents follows the methodology outlined in Non-interactive Agents Dropout. This function aims to train the model on less intuitive interactions within complex scenarios, such as unprotected left turns and lane changes.
(6) Traffic Light Inversion ∈ T − (Fig. 4f): in scenarios where the AV approaches an intersection governed by traffic lights without a leading vehicle, the traffic light status is reversed (e.g., from red to green). This function teaches the model to adhere to basic traffic light rules.
- 状态扰动 ∈ T+(图4a):对自动驾驶车辆的当前位置 、速度 、加速度 和转向角 度引入轻微的、随机生成的扰动 。这种增强旨在使模型能够学习从训练分布的轻微偏差中恢复的策略。CIL框架的目标是最大化原始样本和增强样本的潜在表示之间的相似性,从而增强模型对误差累积的韧性。
- 非交互代理丢弃 ∈ T+(图4b):从输入场景中省略在不久的将来不会与自动驾驶车辆(AV)交互的代理 。通过它们未来的边界框与AV的轨迹相交来识别交互代理。这种增强防止模型通过模仿非交互代理来学习行为 ,从而鼓励模型辨别与交互代理的真实因果关系。
- 前导代理丢弃 ∈ T-(图4c):移除所有位于自动驾驶车辆前方的代理。特别考虑了前导-跟随动态,这是现实世界驾驶中普遍存在的情况。这种增强训练模型学习前导-跟随行为,以防止追尾碰撞。
- 前导代理插入 ∈ T-(图4d):在AV的原始路径中引入一个前导车辆,位于AV预期轨迹变得无效的位置(例如,会导致碰撞)。插入车辆的轨迹数据来自当前小批量中随机选择的代理,以保持数据的真实性。
- 交互代理丢弃 ∈ T-(图4e):排除与AV有直接或间接交互的代理。识别交互代理的方法遵循非交互代理丢弃中概述的方法。这个功能旨在训练模型在复杂场景中处理不太直观的交互,如无保护的左转和变道。
- 交通灯反转 ∈ T-(图4f):在AV接近没有前导车辆的交通灯控制的交叉口时,交通灯状态被反转(例如,从红色变为绿色)。这个功能教会模型遵守基本的交通灯规则。
这些增强策略有助于提高模型在面对各种驾驶场景时的鲁棒性和适应性,特别是在处理不常见或复杂的交互时。通过这些方法,模型可以更好地理解和预测其他代理的行为,从而做出更安全和有效的驾驶决策。
These augmentation functions are designed with minimal inductive bias to ensure broad applicability. The contrastive learning task facilitates an implicit feedback mechanism, providing implicit reward signals. These signals reinforce adherence to fundamental driving principles.
这些增强函数设计时尽量保持最小的归纳偏好,以确保它们的广泛适用性。对比学习任务促进了一种隐式反馈机制,提供隐式的奖励信号。这些信号加强了对基本驾驶原则的遵守。
- 最小归纳偏好:设计增强函数时,尽量减少对特定类型数据或场景的偏好,使得模型能够更好地泛化到各种不同的实际驾驶情况。
- 对比学习任务 :通过对比学习,模型可以学习区分不同样本之间的差异,从而更好地理解和预测其他代理的行为。这种学习方式不需要显式的标签,而是通过比较样本之间的相似性和差异性来提供隐式的反馈。
- 隐式反馈机制:在对比学习中,模型通过比较增强前后的样本来学习,这种比较过程本身就是一种隐式的反馈。模型通过这种方式学习如何更好地处理各种驾驶场景,而不需要显式的奖励或惩罚信号。
- 强化基本驾驶原则:通过这些隐式奖励信号,模型被引导去学习和遵守基本的驾驶原则,如保持安全距离、遵守交通规则等。这有助于提高模型在实际驾驶中的安全性和合规性。
这种设计方法使得自动驾驶模型能够在没有大量显式标注数据的情况下,通过隐式的学习机制来提高其性能和适应性。这对于自动驾驶技术的发展和应用具有重要意义。
F. Planning and Post-processing
In the context of trajectory planning, our objective is to select a deterministic future trajectory from the diverse outcomes provided by the multi-modal outputs, as discussed in Section III-C. Rather than merely selecting the most likely trajectory, we integrate a post-processing module to serve as an additional safety verification mechanism, as illustrated in Algorithm 2.
在轨迹规划的背景下,我们的目标是从多模态输出提供的多样化结果中选择一个确定性的未来轨迹 ,如第三部分C节所讨论。我们不仅仅选择最有可能的轨迹 ,而是集成了一个后处理模块作为额外的安全验证机制 ,如 算法2 所示。

Upon extracting the scenario's features, the model is executed to generate multi-modal planning trajectories T0 ∈ RNRNL×TF ×6, associated confidence scores π0 ∈ RNRNL, and predictions for the agents' movements P1:NA ∈ RNA×TF ×2. Given that the total trajectory count NRNL for T0 can be extensive, an initial filtering step retains only the top K trajectories, ranked by their confidence scores, to streamline subsequent computations.
在提取场景特征后,模型被执行以生成多模态规划轨迹 T 0 ∈ R N R N L × T F × 6 T_0 \in \mathbb{R}^{N_RN_L \times T_F \times 6} T0∈RNRNL×TF×6,相关置信度分数 π 0 ∈ R N R N L \pi_0 \in \mathbb{R}^{N_RN_L} π0∈RNRNL,以及对代理运动的预测 P 1 : N A ∈ R N A × T F × 2 P_{1:N_A} \in \mathbb{R}^{N_A \times T_F \times 2} P1:NA∈RNA×TF×2。考虑到 T 0 T_0 T0 的总轨迹计数 N R N L N_RN_L NRNL 可能非常庞大,一个初始的过滤步骤保留了按置信度分数排名的前 K K K 条轨迹,以简化后续计算。
Following 2, a closed-loop forward simulation is performed on T0 to obtain simulated rollouts Te0, utilizing a linear quadratic regulator (LQR) for trajectory tracking and a kinematic bicycle model for state updates. It has been noted 3 that trajectory-based imitation learning may not fully account for the dynamics of the underlying system, potentially leading to discrepancies between the model's planned trajectory and its actual execution. To mitigate this issue, our assessment relies on the simulated rollouts rather than the model's direct output, thus narrowing the gap.
根据文献2,对 T 0 T_0 T0 进行闭环前向仿真以获得模拟的展开轨迹 T ~ 0 \tilde T_{0} T~0,使用线性二次调节器(LQR)进行轨迹跟踪,并使用运动学自行车模型进行状态更新。文献3指出,基于轨迹的模仿学习可能没有完全考虑底层系统的动力学,这可能导致模型计划的轨迹与实际执行之间存在差异 。为了缓解这个问题,我们的评估依赖于模拟的展开轨迹而不是模型的直接输出,从而缩小了这一差距。
"展开轨迹 " 通常指的是在某个系统或模型中,随着时间的推移,系统状态或行为的演变路径。在评估模型时,如果依赖于模拟的展开轨迹,意味着评估不是基于模型的即时输出,而是通过观察模型在模拟过程中随时间变化的行为和结果来进行的。这种方法可以帮助评估者更全面地理解模型的动态性能和长期稳定性。
Subsequently, a rule-based evaluator assigns scores πrule to each simulated rollout based on criteria such as progress,driving comfort, and adherence to traffic regulations, in alignment with the framework established in 2. This evaluation also incorporates predictions of agents' trajectories P1:Na to calculate the time-to-collision (TTC) metric, excluding rollouts that result in at-fault collisions. The ultimate score combines the initial learning-based confidence score π0 with the rulebased score πrule via the equation:
随后,一个基于规则的评估器根据进度、驾驶舒适性和遵守交通规则等标准为每个模拟展开轨迹分配分数 π rule \pi_{\text{rule}} πrule,这与文献2中建立的框架一致。这种评估还结合了代理轨迹的预测 P 1 : N A P_{1:N_A} P1:NA 来计算碰撞时间(TTC)指标,排除那些导致有责任碰撞的展开轨迹。最终分数通过以下公式将初始基于学习的置信度分数 π 0 \pi_0 π0 与基于规则的分数 π rule \pi_{\text{rule}} πrule 结合起来 :

where α represents a fixed weighting factor. The selection of the final trajectory τ∗ is based on maximizing π. Unlike the post-processing step described in 30, 31, which typically utilizes an optimizer to refine the trajectory, our postprocessing module acts solely as a trajectory selector, leaving the original planning trajectory unaltered. We regard the postprocessing step as a proxy to inject human preference or control into the black-boxed neural network, acknowledging its current limitations, and providing a lower-bound safety assurance to mitigate the risk of catastrophic accidents.
其中 α \alpha α 代表一个固定的权重因子 。最终轨迹 τ ∗ \tau^* τ∗ 的选择是基于最大化 π \pi π 来进行的 。与文献30、31中描述的后处理步骤不同,这些步骤通常使用优化器来细化轨迹 ,我们的后处理模块仅作为轨迹选择器,不改变原始规划轨迹 。我们认为后处理步骤是将人类偏好或控制注入到黑箱神经网络中的代理,承认其当前的局限性,并提供最低限度的安全保障以减轻灾难性事故的风险。
IV. EXPERIMENTS
A. Experiment Setup
nuPlan. Our model was trained and evaluated using the nuPlan dataset 14. This dataset comprises 1,300 hours of real-world driving data, encompassing up to 75 labeled scenario types. It introduces the first publicly accessible, large-scale planning benchmark for autonomous driving through its associated closed-loop simulation framework. Each simulation conducts a 15-second rollout at a frequency of 10 Hz, during which the autonomous vehicle is managed by a planner and tracker. Traffic agents within these simulations are controlled in two distinct manners: non-reactive, wherein agents' states are determined based on logged trajectories, and reactive, wherein agents are governed by an Intelligent Driver Model 51 planner.
我们的模型使用 nuPlan 数据集14进行训练和评估。该数据集包含 1300 小时的真实世界驾驶数据,涵盖了多达 75 种标记的场景类型。它通过其相关的闭环仿真框架,首次引入了自动驾驶的大规模规划基准,可供公众访问。每次仿真进行 15 秒的展开 ,频率为 10 Hz,在这期间,自动驾驶车辆由规划器和跟踪器管理。这些仿真中的交通代理以两种截然不同的方式被控制:非反应性,其中代理的状态是基于记录的轨迹确定的;反应性,其中代理由智能驾驶模型51规划器控制。
Benchmark and Metrics. For all experiments, we use a standardized training split of 1M frames sampled from all scenario types. For evaluation, we use the Val14 benchmark 2, which contains up to 100 scenarios from the 14 scenario types specified in the nuPlan planning challenge, resulting in a total number of 1090 scenarios (we filter out a few scenarios that initialized as failed in the reactive simulations).
基准测试和指标 。在所有实验中,我们使用从所有场景类型中采样的 100 万帧的标准训练分割。对于评估,我们使用 Val14 基准测试2,它包含 nuPlan 规划挑战中指定的 14 种场景类型的多达 100 个场景,总共有 1090 个场景(我们过滤掉了一些在反应性仿真中初始化失败的场景)。
NuPlan employs three principal evaluation metrics: the open-loop score (OLS), the non-reactive closed-loop score (NR-score), and the reactive closed-loop score (R-score). Given that previous studies have demonstrated a minimal correlation between open-loop prediction performance and closed-loop planning effectiveness, we only focus on closedloop performance in this paper. The closed-loop score is calculated as a weighted average of several key metrics:
NuPlan 使用三个主要的评估指标 :开环分数(OLS) 、非反应性闭环分数(NR-score)和反应性闭环分数(R-score) 。鉴于先前的研究已经证明开环预测性能与闭环规划有效性之间的相关性很小,我们在本文中只关注闭环性能 。闭环分数是几个关键指标的加权平均值:
(1) No ego at-fault collisions: A collision is identified when the autonomous vehicle's (AV) bounding box intersects with that of other agents or static obstacles. However, collisions initiated by other agents, such as rear-end collisions, are disregarded.
(2) Time to collision (TTC) within bound: The TTC is defined as the time it would take for the AV and another entity to collide if they continue on their current trajectories and speeds. This metric mandates that the TTC exceeds a specified threshold.
(3) Drivable area compliance: This criterion requires that the AV remains within the boundaries of the drivable roadway at all times, ensuring adherence to the designated driving area.
(4) Comfortableness: The comfort of the AV is quantified by examining the minimum and maximum values of its longitudinal and lateral accelerations and jerks, as well as its yaw rate and acceleration. These parameters are assessed against established thresholds derived from empirical data.
(5) Progress: Progress is evaluated by comparing the distance covered by the AV along its planned route to that achieved by an expert driver, expressed as a percentage.
(6) Speed limit compliance: This metric checks whether the AV's speed falls within the legal limits prescribed for the roadway it is traversing.
(7) Driving direction compliance: This measure penalizes deviations from the correct driving direction, particularly incidents where the AV is found traveling against the flow of traffic.
以下是对自动驾驶车辆(AV)在NuPlan评估体系中使用的七个关键指标的详细解释:
- 无自我责任碰撞 :当自动驾驶车辆(AV)的边界框与其他代理或静态障碍物的边界框相交时,会被识别为发生碰撞。然而,由其他代理引发的碰撞,如追尾碰撞,不予考虑。
- 碰撞时间(TTC)在界限内 :TTC 定义为如果AV和其他实体继续按当前轨迹和速度行驶,它们相撞所需的时间。这一指标要求TTC超过一个特定的阈值。
- 可行驶区域合规性 :这一标准要求AV始终在可行驶道路的边界内,确保遵守指定的驾驶区域。
- 舒适性:通过检查AV的纵向和横向加速度和急动度(jerk)、偏航率和加速度的最小值和最大值来量化AV的舒适性。这些参数根据来自经验数据的既定阈值进行评估。
- 进度 :通过比较AV沿其计划路线行驶的距离与专家驾驶员实现的距离来评估进度,以百分比表示。
- 速度限制合规性 :这一指标检查AV的速度是否在其行驶的道路的法定限制范围内。
- 驾驶方向合规性 :这一措施对偏离正确驾驶方向的行为进行惩罚 ,特别是当发现AV逆向行驶时。
A more detailed description and calculation of the metrics can be found at 52. We use the non-reactive closed-loop score (denoted as score if not specified) as our primary overall performance evaluation metric.
更详细的指标描述和计算可以在文献52中找到。我们使用非反应性闭环分数(如果没有特别说明,记为分数)作为我们主要的总体性能评估指标。
Baselines. In this study, we conduct a comparative analysis between PLUTO and both existing and state-of-the-art (SOTA) methodologies utilizing the nuPlan benchmark to demonstrate the efficacy of our proposed method. The baselines for comparison are categorized into three groups: rule-based, pure learning, and hybrid approaches. Rule-based methods rely on manually engineered rules without incorporating learning processes. In contrast, pure learning methods employ neural networks to directly generate the final planned trajectory, omitting any refinement or post-processing stages. Hybrid methods, however, include a post-processing module to refine or adjust outcomes derived from learning-based techniques. The benchmarked methods are outlined as follows:
基线 。在这项研究中,我们通过使用nuPlan基准对PLUTO与现有和最先进的(SOTA)方法进行比较分析,以证明我们提出的方法的有效性。比较的基线分为三组:基于规则的方法 、纯学习方法 和混合方法 。基于规则的方法依赖于手动设计的规则,不包含学习过程。相比之下,纯学习方法使用神经网络直接生成最终的规划轨迹,省略了任何细化或后处理阶段。然而,混合方法包括一个后处理模块,用于细化或调整基于学习技术得出的结果。基准测试的方法概述如下:
(1) Intelligent Driver Model (IDM) 51: This is a classic, time-continuous car-following model extensively utilized in traffic simulations. We employ the official implementation as referenced in the literature 14.
(2) PDM-Closed 2: Identified as the winning entry in the 2023 nuPlan planning challenge, this method generates a series of proposals by integrating IDM policies with varying hyperparameters, subsequently selecting the optimal one through a rule-based scoring system. Despite its simplicity, it has proven effective in practice and currently holds the SOTA performance. Its open-source implementation is utilized in our study.
(3) PDM-Open 2: This approach, centered around a predictive model that conditions on the centerline and utilizes MLPs, is implemented through an available open-source version.
(4) GC-PGP 53: A predictive model that focuses on goalconditioned lane graph traversals.
(5) RasterModel: A CNN-based model that interprets the input scenario as a multi-channel image, as described in referenced literature 14.
(6) UrbanDriver 28: A learning-based planner that leverages vectorized inputs through PointNet-based polyline encoders and Transformers. This model is assessed through its open-loop re-implementation, incorporating historical data perturbation during its training phase.
(7) PlanTF 3: A strong pure imitation learning baseline that leverages a Transformer architecture to explore efficient design in imitation learning. Despite its simplicity, it stands as the current SOTA among pure learning models.
(8) GameFormer 31: Modeled on DETR-like interactive planning and prediction based on level-k games, the output from this model serves as an initial estimate, which is further refined through a nonlinear optimizer. The official open-source code is used for implementation purposes.
(9) PlanTF-H: This method enhances PlanTF by integrating a post-processing module as described in Sect. III-F, thereby converting it into a hybrid approach.
(1) 智能驾驶模型(IDM) 51:这是一个经典的、时间连续的车辆跟随模型,在交通模拟中广泛使用。我们采用了文献14中引用的官方实现。
(2) PDM-Closed 2:被认定为2023年nuPlan规划挑战的获胜者 ,这种方法通过整合具有不同超参数的IDM策略生成一系列提议 ,然后通过基于规则的评分系统选择最优的提议。尽管它很简单 ,但在实践中已经证明是有效的 ,并且目前保持着最先进的性能 。我们在研究中使用了它的开源实现。
(3) PDM-Open 2:这种方法以一个预测模型为中心,该模型依赖于中心线并使用多层感知器(MLPs),通过可用的开源版本实现。
(4) GC-PGP 53:一个专注于目标条件车道图遍历的预测模型。
(5) RasterModel :一个基于CNN的模型,将输入场景解释为多通道图像,如参考文献14中所述。
(6) UrbanDriver 28:一个基于学习的规划器,通过基于PointNet的多边形编码器和Transformers利用矢量化输入。该模型通过其开环重新实现进行评估,在其训练阶段结合历史数据扰动。
(7) PlanTF 3:一个强大的纯模仿学习基线 ,利用Transformer架构探索模仿学习中的高效设计。尽管它很简单,但它目前是纯学习模型中的最先进的 。
(8) GameFormer 31:基于DETR类交互式规划和基于level-k游戏的预测,该模型的输出作为初始估计,然后通过非线性优化器进一步细化。用于实现目的的官方开源代码。
(9) PlanTF-H:这种方法通过整合第III-F节中描述的后处理模块来增强PlanTF,从而将其转换为混合方法。
学习一下PDM-Closed
B. Implementation Details
We present two variations PLUTO† and PLUTO, differing only in that PLUTO† omits the post-processing step. Feature extraction focuses on map elements and agents within a 120-meter radius of the autonomous vehicle. We adhere to the nuPlan challenge by setting the planning and historical data horizons at 8 seconds and 2 seconds, respectively. The model incorporates auxiliary tasks designed to penalize offroad driving and collisions. Training was conducted using 4 RTX3090 GPUs, with a batch size of 128 over 25 epochs. We utilized the AdamW optimizer, applying a weight decay of 1e−4. The learning rate is linearly increased to 1e−3 over the first three epochs and then follows a cosine decay pattern throughout the remaining epochs. The loss weights w1−4 are uniformly assigned a value of 1.0. The training finishes in 45 hours with CIL and 22 hours without it. Details on further parameter settings can be found in Table I.
我们介绍了两种变体 P L U T O † PLUTO^† PLUTO† 和 P L U T O PLUTO PLUTO,它们的区别仅在于 P L U T O † PLUTO^† PLUTO† 省略了后处理步骤。特征提取专注于自动驾驶车辆周围120米半径内的地图元素和代理。我们遵循nuPlan挑战,将规划和历史数据的时间范围分别设置为8秒和2秒 。模型包含了辅助任务,旨在惩罚偏离道路驾驶和碰撞。训练使用了4个RTX3090 GPU ,批量大小为128 ,进行了25个周期。我们使用了AdamW优化器,应用了1e-4的权重衰减。学习率在前三个周期内线性增加到1e-3,然后在剩余的周期内遵循余弦衰减模式。损失权重w1-4统一分配值为1.0。训练在45小时内完成 ,使用CIL(上下文感知学习)时为22小 时。更多参数设置的详细信息可以在 表I 中找到。

V. RESULTS AND DISSCUSION
A. Comparison with State of the Art
The comparative analysis with other methods on the Val14 benchmark is detailed in Table II. Initially, our purely learningoriented variant, PLUTO†, surpasses all prior baselines dedicated to pure learning. Significantly, when compared to the leading model, PlanTF, PLUTO† demonstrates marked improvements across nearly all evaluated metrics, with particular enhancements observed in metrics pertinent to safety (e.g., Collisions improved from 94.13 to 96.18, TTC from 90.73 to 93.28, and Drivable from 96.79 to 98.53). These results highlight the constraints of models based solely on imitation and underscore the effectiveness of incorporating auxiliary loss and the design of the CIL framework.
在Val14基准上的比较分析详细列在 表II 中。最初,我们纯粹面向学习的变体 P L U T O † PLUTO^† PLUTO† 超过了所有之前专门用于纯学习的基线。值得注意的是,与领先的模型 PlanTF 相比, P L U T O † PLUTO^† PLUTO† 在几乎所有评估指标上都显示出显著的改进,特别是在与安全性相关的指标上观察到的增强(例如,碰撞从94.13提高到96.18,TTC从90.73提高到93.28,可行驶区域从96.79提高到98.53)。这些结果突出了仅基于模仿的模型的局限性,并强调了结合辅助损失和CIL框架设计的效能。

Furthermore, our hybrid model, PLUTO, attains the highest scores across all baselines, surpassing the current state-ofthe-art rule-based model, PDM-Closed, for the first time. This achievement emphasizes the promise of learning-based approaches in planning. Remarkably, the performance of our methods closely aligns with that of the log-reply expert (scoring 93.68 vs. 93.21), indicating a significant stride towards expert-level planning.
此外,我们的混合模型PLUTO在所有基线中获得了最高分,首次超过了当前最先进的基于规则的模型PDM-Closed。这一成就强调了基于学习的方法在规划中的潜力。值得注意的是,我们的方法的性能与日志回复专家(得分分别为93.68和93.21)非常接近,这表明在向专家级规划迈出了重要的一步。
B. Qualitative Results
Fig. 5 presents selected scenarios from the nuPlan test set, showcasing the robust performance of our framework in complex, interactive urban driving situations through the exhibition of diverse, human-like behaviors. The scenarios are detailed as follows:
(a) The autonomous vehicle navigates to an adjacent empty lane to enhance efficiency and subsequently halts at a red light at the intersection. Observations from sequences a-2 and a-3 reveal that PLUTO concurrently evaluates multiple potential plans for different behaviors (illustrated by gray candidate trajectories), enhancing the planning process's flexibility and resemblance to human driving.
(b) In a scenario requiring the AV to maneuver around a roundabout, its path is narrowed by a parked vehicle. Our planning system adeptly navigates around this obstacle while yielding to an oncoming vehicle in a constrained space, exemplifying our method's competence in managing static obstacles and interacting with other vehicles.
© Encountering a stationary vehicle within its lane, the AV executes a left lane change to bypass the obstacle, subsequently returning to its original lane to adhere to the intended route. This scenario underscores the planner's dynamic decision-making capabilities and its adeptness in route adherence and road topology comprehension.
(d) During a left-turn maneuver in heavy traffic, the AV patiently waits for an opportune moment to execute the turn, illustrating our method's effectiveness in navigating intersections in high-density traffic conditions.
(e) Upon following a slower vehicle, the AV opts to accelerate and overtake, showcasing a behavior that aligns closely with natural human driving and highlighting our proposed method's adaptability.
图5 展示了来自nuPlan测试集的选定场景,通过展示多样化、类似人类的行为,展示了我们的框架在复杂的、互动的城市驾驶情况下的稳健性能。这些场景详细如下:
(a) 自动驾驶车辆导航到相邻的空车道以提高效率,随后在交叉路口的红灯处停下 。从序列a-2和a-3的观察中发现,PLUTO同时评估了不同行为的多种潜在规划(由灰色候选轨迹表示),增强了规划过程的灵活性和类似人类驾驶的相似性 。
(b) 在一个需要自动驾驶车辆绕过环岛 的场景中,其路径被一辆停放的车辆 所限制。我们的规划系统巧妙地绕过这个障碍物 ,同时在有限的空间内向迎面而来的车辆让路 ,展示了我们方法在管理静态障碍物和与其他车辆互动方面的能力 。
( c) 遇到车道内的静止车辆时,自动驾驶车辆执行左侧变道以绕过障碍 物,随后返回原车道以遵守预定路线 。这一场景强调了规划器的动态决策能力 ,以及其在路线遵守和道路拓扑理解方面的熟练程度。
(d) 在高密度交通条件下进行左转时,自动驾驶车辆耐心等待合适的时机执行转弯,展示了我们方法在高密度交通条件下导航交叉路口的有效性 。
(e) 在跟随一辆较慢的车辆时,自动驾驶车辆选择加速超车 ,展示了与自然人类驾驶非常接近的行为,并突出了我们提出方法的适应性。

图5 . 来自测试集的五个代表性场景的闭环规划 的定性结果。每个场景(每行)持续15秒 ,我们每隔5秒拍摄4张快照 。紫色虚线箭头表示参考线 ,浅蓝色车道表示全局路线规划,其他重要的图例在图a-1中标出。建议访问我们的项目网站查看更生动的视频。
In summary, PLUTO exhibits advanced and varied driving behaviors unattainable through simplistic speed-planning methods (e.g., PDM-Closed). Its ability to execute natural lane changes, navigate around obstacles, and dynamically modify decisions in interactive scenarios marks a significant advancement towards the realization of practical learningbased planning. For further insights, including videos, we direct interested readers to our project website.
总结来说,PLUTO展示了通过简单的速度规划方法(例如,PDM-Closed)无法实现的先进和多样化的驾驶行为 。它能够执行自然的变道 、绕过障碍物 ,以及在互动场景中动态修改决策,这标志着向实现实用的基于学习的规划迈出了重要一步。为了获得更多见解,包括视频,我们引导感兴趣的读者访问我们的项目网站。
C. Ablation Studies
For all ablation studies, we evaluate on a subset of nuPlan (non-overlapping with the Val14 benchmark), which contains 20 scenarios for each of the 14 scenarios types.
在所有消融研究中,我们在nuPlan的一个子集上进行评估(不与Val14基准重叠),该子集包含14种场景类型中每种类型的20个场景。
Influence of Each Component. Table II shows the trajectory from a base model to the top-performing learning-based planner. The initial model, denoted as M0, is constructed on the architecture depicted in Sect. III-B and III-C, employing solely imitation loss for training. M0 demonstrates performance on par with the previous SOTA pure learning-based method, PlanTF, an achievement we ascribe to the enhanced querybased architecture.
在所有消融研究中,我们在nuPlan的一个子集上进行评估(不与Val14基准重叠),该子集包含14种场景类型中每种类型的20个场景。
表II展示了从基础模型到顶尖的基于学习规划器的轨迹。最初的模型,记为 M 0 M_0 M0,是构建在第三部分B和C中描述的架构上,仅使用模仿损失进行训练。 M 0 M_0 M0 展示了与之前的最先进的纯基于学习的方法PlanTF相当的性能,我们将这一成就归因于增强的基于查询的架构 。

The introduction of the state dropout encoder (SDE) in M1, which randomly masks the autonomous vehicle's kinematic states during training to avert the generation of shortcut trajectories by state extrapolation, results in marked improvements over M0 across almost all metrics.
在 M 1 M_1 M1 中引入的状态丢弃编码器(SDE),在训练期间随机遮盖自动驾驶车辆的运动状态 ,以避免通过状态外推生成捷径轨迹 ,这在几乎所有指标上都比 M 0 M_0 M0 带来了显著的改进。
M2 incorporates an auxiliary loss designed to penalize deviations from the drivable area and collisions. This modification leads to enhancements in both the Collision metric (from 97.37 to 97.98) and the Drivable metric (from 95.92 to 98.38). We would like to highlight that despite the seemingly minor difference in total scores between M2 and M1, the disparity in their actual performance is substantial. We direct interested readers to the project website for the model ablation results. The M3 model underscores the importance of integrating a reference line-free decoding head to effectively handle scenarios where reference lines are absent, such as in parking lots.
M 2 M_2 M2 加入了一个辅助损失 ,旨在惩罚偏离可行驶区域和发生碰撞的行为 。这一修改在碰撞指标(从97.37提高到97.98)和可行驶指标(从95.92提高到98.38)上都带来了提升。我们想强调的是,尽管 M 2 M_2 M2 和 M 1 M_1 M1 在总分上的差异看似微小,但它们实际性能的差异是相当大的 。我们引导感兴趣的读者访问项目网站查看模型消融结果。M 3 M_3 M3 模型强调了整合一个无参考线解码头的重要性 ,以有效处理参考线缺失的场景 ,例如在停车场中。
Further, M4 is trained using the proposed contrastive imitation learning framework, achieving a significant uplift in performance from 90.69 to 91.66. This improvement is noteworthy, particularly as it is already approaching the expert's performance.
此外, M 4 M_4 M4 使用所提出的对比模仿学习框架 进行训练,性能从90.69显著提升到91.66。这一改进值得注意,特别是因为它已经接近专家的性能。
Ultimately, M5 attains the best overall performance, though at a minor trade-off in the Comfort metric. This compromise stems from the increased incidence of emergency stops triggered by the safety checker, thereby enhancing safety-related metrics.
最终, M 5 M_5 M5 实现了最佳的总体性能 ,尽管在舒适度指标上有轻微的妥协 。这种妥协源于安全检查器触发的紧急停车事件 增加,从而提高了与安全相关的指标。
Number of Longitudinal Queries. Table IV presents the outcomes associated with various quantities of longitudinal queries NL (utilizing model M4). The results indicate that a setting of NL = 12 yields the most favorable performance among four tested variants. This suggests an appropriate number of queries is necessary to cover all the longitudinal behaviors for a planning horizon of 8s. An increase in NL beyond this point detracts from performance. This decline can likely be attributed to the sufficiency of NL = 12 in capturing a diverse array of behaviors; additional queries become redundant, potentially increasing the training difficulty.
纵查询数量。 表IV 展示了与不同数量的纵向查询 N L N_L NL 使用模型 M 4 M_4 M4)相关的结果。结果表明, N L = 12 N_L = 12 NL=12 的设置在四个测试变体中产生了最有利的性能。这表明适当数量的查询是必要的,以覆盖8秒规划范围内的所有纵向行为 。超过这个点增加 N L N_L NL 会降低性能。这种下降可能归因于 N L = 12 N_L = 12 NL=12 足以捕捉多样化的行为;额外的查询变得冗余,可能增加了训练难度 。

Top-K in Coarse Selection. In the planning cycle, PLUTO generates a total of NR × NL trajectories. Empirical evidence suggests that trajectories associated with low confidence scores often exhibit inferior quality. Consequently, employing a preliminary selection process based on confidence scores proves advantageous in eliminating such trajectories, thereby expediting subsequent post-processing. As illustrated in Table V, setting K = 20 turns out to be appropriate.
粗略选择中的Top-K。 在规划周期中,PLUTO生成总共 N R × N L N_R \times N_L NR×NL 条轨迹。经验证据表明,与低置信度分数相关的轨迹通常表现出较差的质量 。因此,基于置信度分数的初步选择过程在消除这些轨迹方面是有利的 ,从而加快了后续的后处理。正如 表V 所展示的,设置 K = 20 K = 20 K=20 被证明是合适的。

Weight of the Learning-based Score. As demonstrated in Equation 15, the final score is derived from the combined weighted contributions of the rule-based and the learningbased scores. This study examines the impact of the weight parameter α, with the findings detailed in Table VI. Firstly, it is observed that incorporating the learning-based score significantly enhances performance compared to relying solely on the rule-based score (i.e., α = 0). The limitation of the rule-based score lies in its hand-crafted nature, which may not accurately represent all possible scenarios, whereas the learning-based score offers greater generalizability by dynamically adapting to the input features. Furthermore, a combined approach proves superior to using a purely learningbased score (M4), indicating that the current model, while advanced, still benefits from the inclusion of a rule-based component as a form of safety assurance. Based on optimal performance, α = 0.3 has been selected as the default setting.
基于学习的分数权重。 如方程15 所示,最终分数是从基于规则和基于学习的分数的加权 贡献中得出的。本研究考察了权重参数 α 的影响 ,发现结果详细列在 表VI 中。首先,观察到将基于学习的分数纳入显著提高了性能 ,与仅依赖基于规则的分数(即α = 0)相比。基于规则的分数的局限性在于其手工制作的性质,可能无法准确代表所有可能的场景,而基于学习的分数通过动态适应输入特征提供了更大的泛化能力 。此外,结合使用的方法优于仅使用纯基于学习的分数 ( M 4 M_4 M4),这表明当前模型虽然先进,但仍然从包含基于规则的组件作为安全保障中受益。基于最佳性能,α = 0.3被选为默认设置。

Prediction method. In this study, we contrast the performance of our learned prediction model against the constant velocity prediction employed in PDM-Closed and presented in Table VII. It is evident that employing learned predictions for planning yields superior results compared to the simplistic constant velocity prediction, as it can more accurately discern the behaviors of the agents. Despite our prediction model producing only a singular modal trajectory for each agent, it works well in practice.
预测方法。 在这项研究中,我们对比了我们的学习型预测模型与 PDM-Closed 中使用的恒定速度预测的性能 ,结果呈现在 表VII 中。显然,使用学习型预测进行规划比简单的恒定速度预测产生更优的结果 ,因为它能更准确地识别代理的行为。尽管我们的预测模型只为每个代理产生单一模态的轨迹,但在实践中表现良好。

VI. CONCLUSION
In this study, we introduce PLUTO, a pioneering datadriven planning framework that extends the capabilities of imitation learning within the autonomous driving domain. We propose innovative solutions concerning model architecture, data augmentation, and the learning framework, effectively addressing enduring challenges in imitation learning. The query-based model architecture furnishes the planner with the capacity for adaptable driving behaviors across both longitudinal and lateral dimensions. Our novel method for computing auxiliary loss, based on differentiable interpolation, offers a new approach for integrating constraints into the model. Additionally, the employment of a contrastive imitation learning framework, coupled with an advanced set of data augmentation techniques, enhances the acquisition of desired behaviors and comprehension of intrinsic interactions. Experimental evaluations utilizing real-world driving datasets demonstrate that our approach sets a new benchmark for closed-loop performance in the field. Notably, PLUTO surpasses the previously best-performing rule-based planner, establishing a significant breakthrough in autonomous driving research.
在这项研究中,我们介绍了PLUTO,这是一个开创性的、数据驱动的规划框架,它扩展了自动驾驶领域内模仿学习的能力。我们提出了关于模型架构、数据增强和学习框架的创新解决方案,有效地解决了模仿学习中长期存在的挑战。基于查询的模型架构为规划器提供了在纵向和横向两个维度上适应性驾驶行为的能力 。我们基于可微插值计算辅助损失的新方法 ,为将约束集成到模型中提供了一种新的方法。此外,采用对比模仿学习框架 ,结合先进的数据增强技术 ,增强了对期望行为的获取和对内在交互的理解。利用现实世界驾驶数据集进行的实验评估表明,我们的方法为该领域的闭环性能树立了新的基准。值得注意的是,PLUTO超越了之前表现最好的基于规则的规划器,为自动驾驶研究树立了重要的突破。
Limitations and Future Work. In our approach, we predict a single trajectory for each dynamic agent. This methodology yields satisfactory outcomes in practical applications; nevertheless, the generation of meaningful joint multimodal predictions and their efficient incorporation into planning strategies represent significant areas for future research. The addition of a post-processing module has been demonstrated to improve overall performance effectively. However, it cannot handle scenarios where all generated trajectories are unusable. Transitioning the post-processing function to an intermediary role that directly influences trajectory generation could present a more advantageous strategy.
在我们的方法中,我们为每个动态代理预测单一轨迹 。这种方法在实际应用中产生了令人满意的结果;然而,生成有意义的联合多模态预测及其有效整合到规划策略中,代表着未来研究的重要领域。已经证明,添加后处理模块可以有效地提高整体性能 。然而,它无法处理所有生成的轨迹都不可用的场景 。将后处理功能转变为直接影响轨迹生成的中介角色,可能会呈现出更有利的策略。


