问题背景
为了帮助开发者更好地识别其代码中潜在的涉及主线程序列化/反序列化的耗时点,以及推动开发者在跨线程传递对象时改用Sendable对象的方式,方舟调优和DevEco Studio联合开发并上线了应用主线程序列化/反序列化超时检测工具。该工具集成在DevEco Profiler中,并可在开发者进行应用调优录制时同步开启。开发者可以在录制结果中的Anomaly泳道内查看到主线程序列化/反序列化超时的Tag点和相关超时信息,并通过与ArkTS Callstack泳道中当前调用栈的时间对齐,定位到序列化/反序列化耗时较长的代码,然后通过Sendable改造或者通信数据改造的方式(例如文件buffer改为文件path+偏移)进行优化,提升应用性能。
工具介绍
DevEco Studio新增主线程序列化和反序列化检测能力,同时支持配置序列化/反序列化超时阈值。对于超过阈值的序列化和反序列化操作,在泳道中给出告警提示,并可以关联该时刻的调用栈信息,更好地帮忙开发者定位性能问题。
功能说明
当前DevEco Profiler工具具备的序列化/反序列化检测包含三个子功能:
-
支持配置序列化/反序列化超时阈值。
-
通过泳道可以直观查看发生序列化/反序列化的执行耗时。
-
可以通过框选序列化/反序列化的执行耗时时间段,在ArkTS Callstack泳道中直观查看发生序列化/反序列化时间段的调用栈信息。
实现原理
图1 主线程序列化/反序列化开销检测流程图
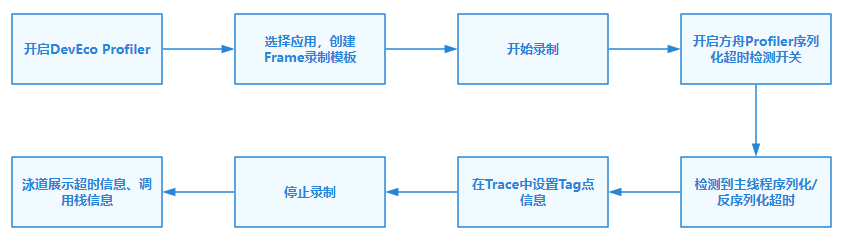
其中超时检测部分的使能和关闭是通过方舟Profiler提供的一组CDP协议来控制(默认处于关闭状态,在使用DevEco Profiler进行录制时开启):
| 协议名称 | 传入参数 | 协议说明 |
|---|---|---|
| Profiler.enableSerializationTimeoutCheck | threshold: int | 开启超时检测工具,并设置超时阈值(单位ms) |
| Profiler.disableSerializationTimeoutCheck | / | 关闭超时检测工具 |
当开启超时检测工具协议被调用后,方舟Profiler会在录制时实时计算每次主线程调用序列化和反序列化接口,进行序列化/反序列化操作的耗时,并将该耗时与设定的超时阈值(默认为8ms)进行比较。如果该耗时超过设定检测阈值,Profiler则会生成一条超时信息,其中包含下列字段:
| 字段名 | 字段名称 | 字段说明 |
|---|---|---|
| tid | 线程id | 线程id,指示当前超时的线程 |
| task | 操作类型 | serialization/deserialization 标记当前操作为序列化或反序列化 |
| startTime | 开始时间 | 标记当前操作的开始时间 |
| duration | 持续时间 | 标记本次序列化/反序列化的实际耗时 |
该超时信息生成后,Profiler会将该条信息通过设置Trace接口设置到Trace中,并标记Tag为Ark,至此,一条主线程序列化/反序列化超时的Trace信息就通过方舟Profiler成功生成并记录。
使用方法
序列化/反序列化性能检测
-
打开DevEco Studio,确认设备已连接,待录制应用已安装。
-
启动应用,点击Profiler,选择Frame模板,选择当前应用进程,点击Create Session,然后开始录制Frame insight场景数据,录制过程中可正常操作应用。
图2 录制Frame insight场景数据
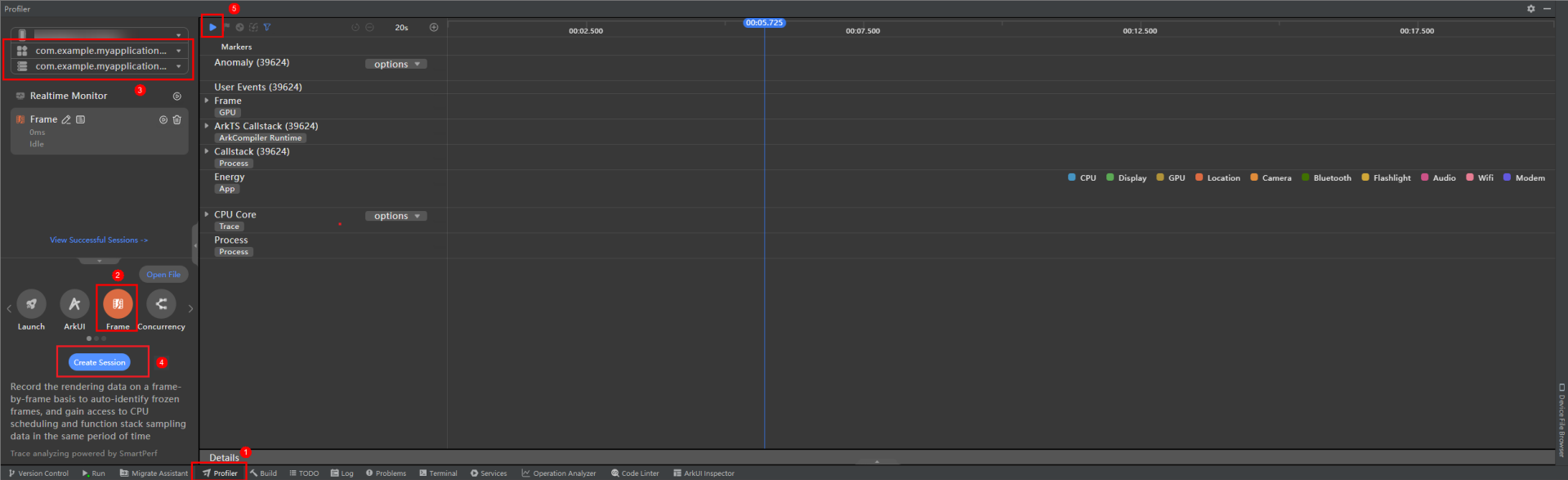
-
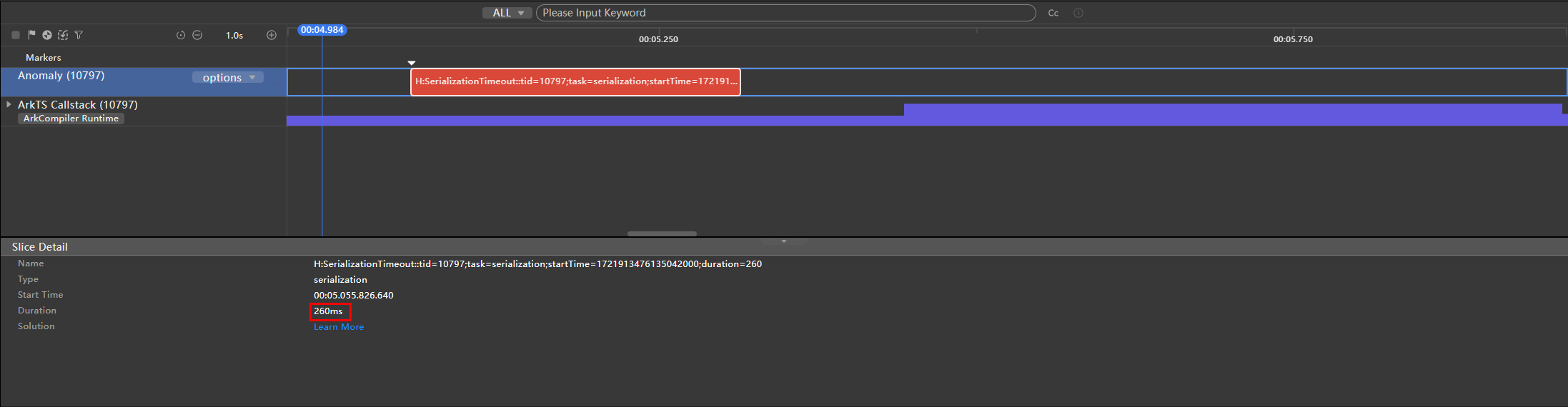
停止录制,待录制结果显示后,如有检测到主线程序列化/反序列化超时的情况,Anomaly泳道会显示序列化/反序列化耗时打点检测结果,提示信息包含线程id、startTime、duration、操作类型等。
图3 主线程序列化/反序列化超时情况
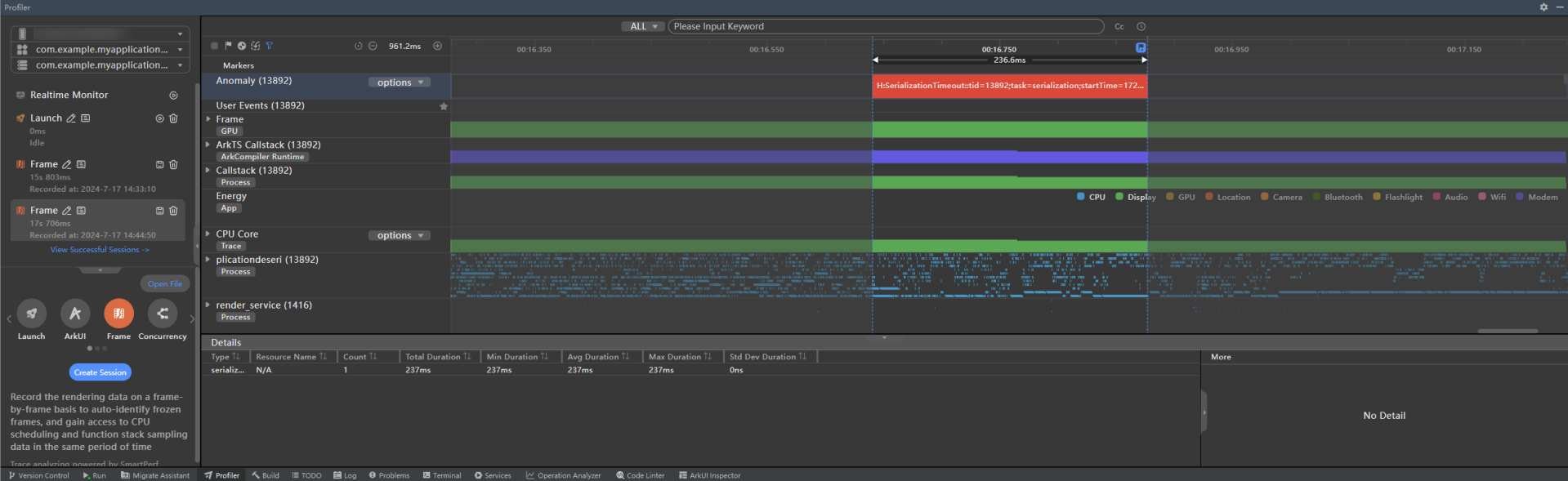
-
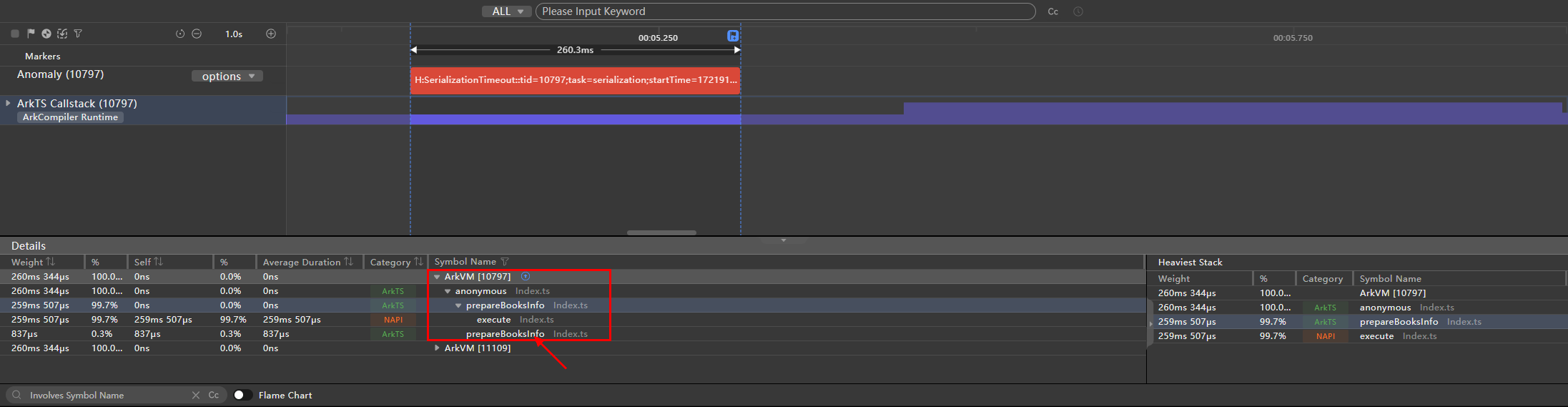
框选这段序列化/反序列化超时时间段,点击ArkTS Callstack,会显示这段时间内的调用栈信息,通过查看其中的Symbol Name信息可以定位到当前耗时的调用栈,双击对应调用栈即可跳转到对应源码。
图4 序列化/反序列化耗时阶段调用栈
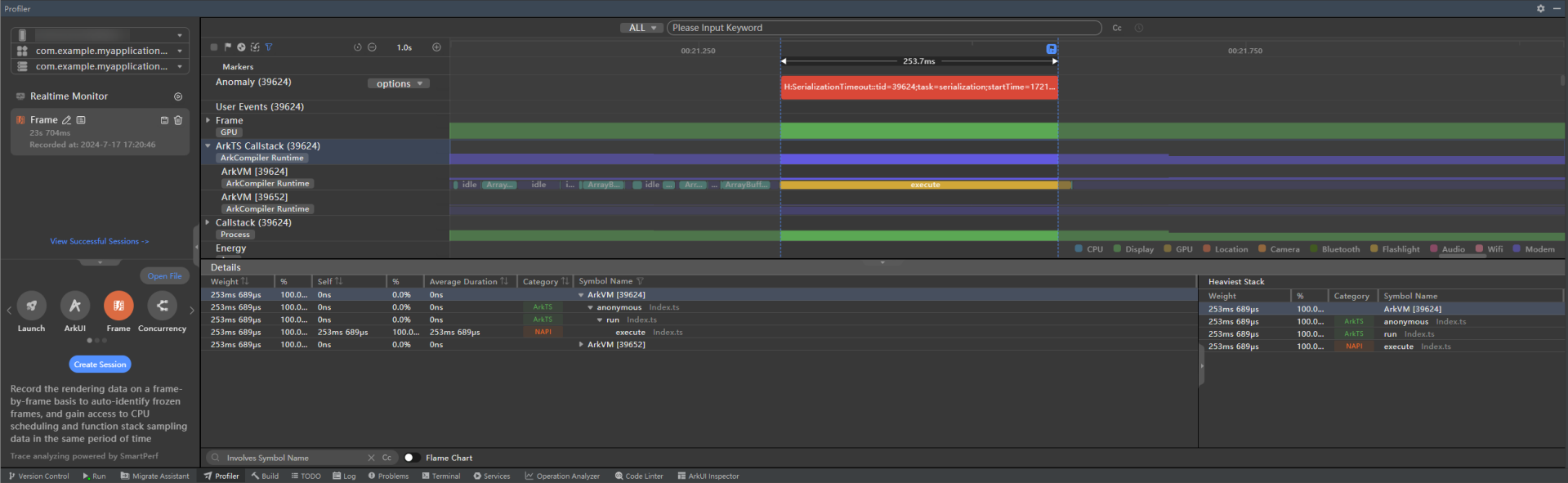
-
开发者通过上述第4步的方式可以更快地定位到序列化/反序列化耗时长的源代码,并且可以参照Sendable改造或者通信数据改造的方式进行优化,进一步优化和提升应用性能。
序列化/反序列化阈值配置
-
打开DevEco Studio,确认设备已连接,待录制应用已安装。
-
启动应用,点击Profiler,选择Frame模板,点击Anomaly泳道中的options,在弹出的输入框中输入超时阈值。
图5 序列化、反序列化阈值配置
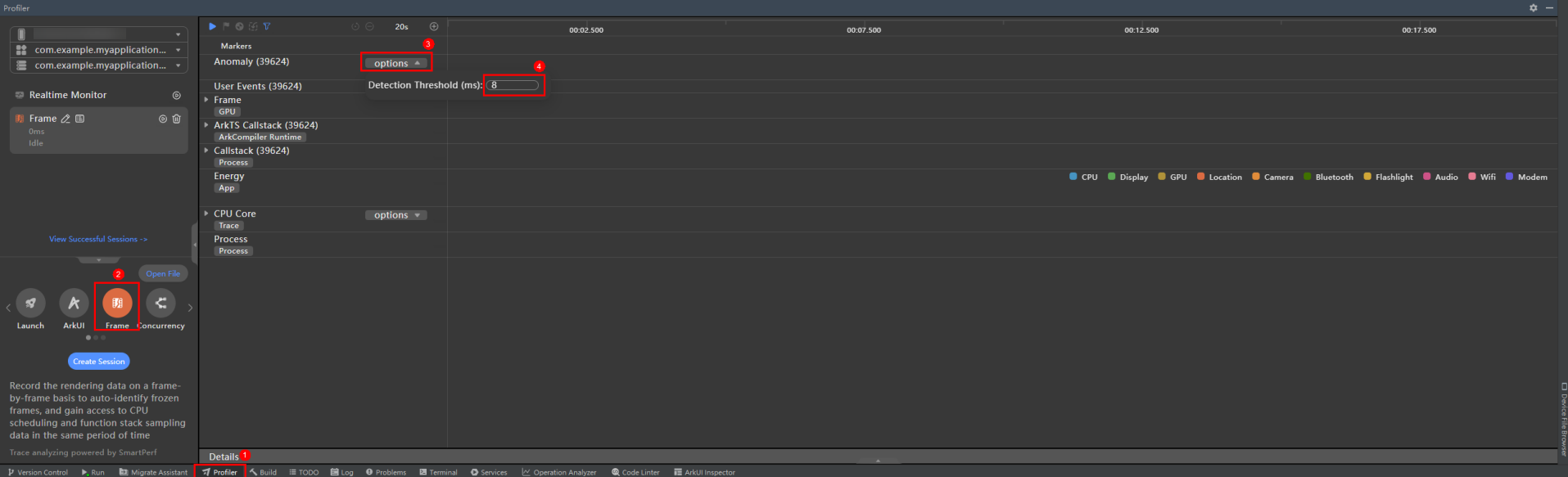
-
参照上述序列化/反序列化性能检测步骤开始录制,此时新设置的超时阈值已经被成功设置和使用。
案例分析
在应用开发过程中,序列化/反序列化通常发生在跨并发实例传输较大数据的场景,由于在此场景下,序列化/反序列化的时间开销会随着传递的数据量线性增长,所以在传输数据量大的情况下序列化/反序列化的时间开销较大。特别当序列化/反序列化发生在应用主线程时,会影响应用整体的运行性能和流畅程度。
Sendable对象通过引用传递的方式在不同的并发实例间传递,相比于序列化效率更高,可以更高效地进行跨实例的数据交互,解决跨并发实例传递大数据和跨并发实例传递含有成员方法的示例对象。下面以图书类应用将大量书本信息跨并发实例传递,存储进数据库的场景为例,介绍通过超时检测工具分析和定位序列化耗时点的过程,以及对该场景进行Sendable改造前后序列化耗时结果的分析对比。该案例主要由下列步骤组成:
-
定义大量书本信息(示例中为5w个)。
-
组装书本信息的class实例。
-
通过Taskpool跨并发实例传递,并进行相关数据库操作。
通常情况下,单个图书信息会被定义成class Book,通过组装该实例填充数据,最后将包含所有Book实例的BookDBInfo对象通过Taskpool传递给子线程。源码参考
import { taskpool } from '@kit.ArkTS';
class Book {
recordId_: string = '';
title_: string = '';
content_: string = '';
authorList_: Array<string> | null = null;
constructor() {
// 初始化Book相关静态信息
// ...
}
// 省略其余成员方法
// ...
}
class BookDBInfo {
dbName_: string = '';
seq_: number = 0;
tableName_: string = '';
books_: Array<Book> | null = null;
constructor(dbName: string, tableName: string) {
this.dbName_ = dbName;
this.tableName_ = tableName;
}
}
function prepareBooksInfo() {
let dbInfo = new BookDBInfo('database1', 'books');
dbInfo.books_ = new Array<Book>();
for (let i = 0; i < 50000; i++) {
let book = new Book();
book.authorList_ = new Array<string>();
// 组装书本信息
// ...
dbInfo.books_?.push(book);
}
let res = taskpool.execute(doDBOperations, dbInfo); // 通过Taskpool跨并发实例传递
}
@Concurrent
function doDBOperations(info: BookDBInfo) {
// 进行数据库相关操作
// ...
}通过序列化超时检测工具检测录制后,在Anomaly泳道可以看到这个场景下的序列化耗时超出默认阈值(8ms),达到了260ms。
图6 未使用Sendable时序列化耗时结果
通过点击下方ArkTS Callstack泳道,选取这个序列化超时发生的时间段后,可以通过下方的Callstack信息定位到此时正在执行Index.ts文件中的prepareBooksInfo方法,由上方伪代码可知该方法内调用了taskpool.execute方法,向子线程中传递对象dbInfo,触发了主线程序列化过程。
图7 未使用Sendable时序列化超时阶段ArkTS Callstack调用栈
为了解决该场景的序列化超时问题,将上述示例中dbInfo相关的class进行Sendable改造,将单个书本信息的类型定义为Sendable类型,并改造内部成员属性类型为Sendable类型。
优化后再次通过序列化超时检测工具检测录制,发现该场景下序列化耗时已小于默认阈值(8ms),在Anomaly泳道中已经没有对应超时的Trace点。
图8 使用Sendable方式优化后序列化耗时
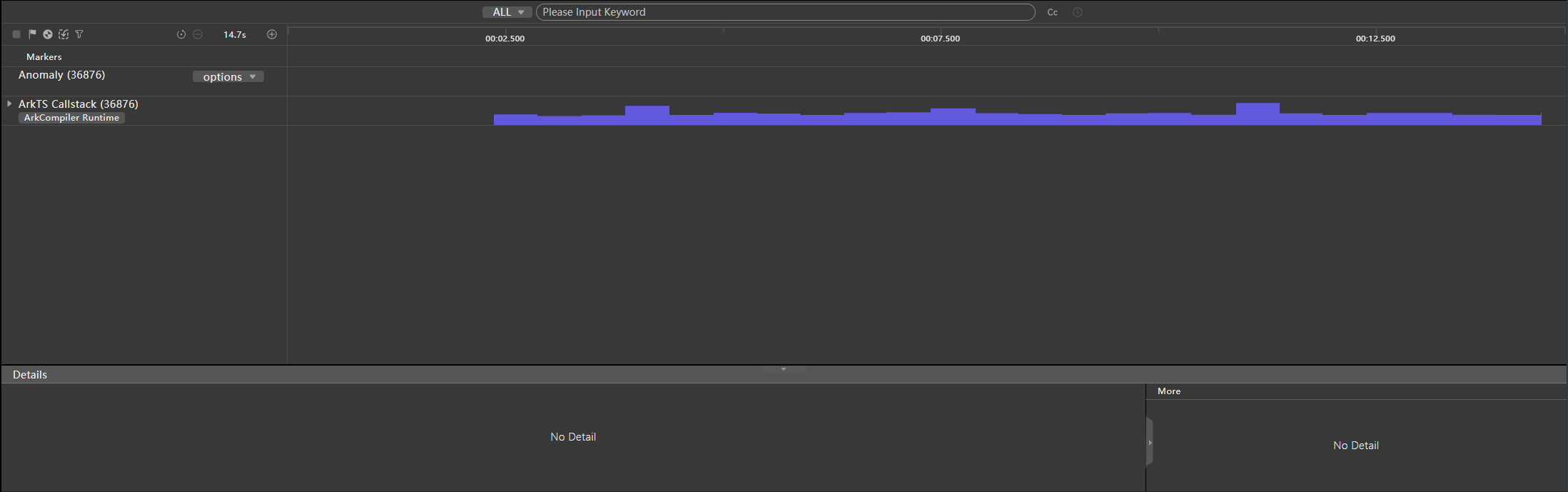
表1 序列化耗时对比
| 实现方案 | 耗时情况 |
|---|---|
| 未使用Sendable | 260ms |
| 使用Sendable方式优化后 | <8ms |
对比分析使用工具获取到的优化前后序列化耗时可以看出,跨线程传输数据量较大时,使用Sendable引用传递方式可以有效减少序列化耗时,提升应用性能。
通过实践案例可以得出结论,使用序列化超时检测工具可以有效检测出应用主线程序列化/反序列化耗时较长的情况,帮助开发者定位序列化耗时点。在找到问题后,开发者可以结合代码层面的改造,例如Sendable改造或者通信数据改造,解决应用跨线程序列化/反序列化耗时过久的性能问题。
最后
小编在之前的鸿蒙系统扫盲中,有很多朋友给我留言,不同的角度的问了一些问题,我明显感觉到一点,那就是许多人参与鸿蒙开发,但是又不知道从哪里下手,因为资料太多,太杂,教授的人也多,无从选择。有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(HarmonyOS NEXT)文档用来跟着学习是非常有必要的。
为了确保高效学习,建议规划清晰的学习路线,涵盖以下关键阶段:
鸿蒙(HarmonyOS NEXT)最新学习路线

该路线图包含基础技能、就业必备技能、多媒体技术、六大电商APP、进阶高级技能、实战就业级设备开发,不仅补充了华为官网未涉及的解决方案
路线图适合人群:
IT开发人员: 想要拓展职业边界
零基础小白: 鸿蒙爱好者,希望从0到1学习,增加一项技能。
**技术提升/进阶跳槽:**发展瓶颈期,提升职场竞争力,快速掌握鸿蒙技术
2.视频学习教程+学习PDF文档
HarmonyOS Next 最新全套视频教程
纯血版鸿蒙全套学习文档(面试、文档、全套视频等)

总结
参与鸿蒙开发,你要先认清适合你的方向,如果是想从事鸿蒙应用开发方向的话,可以参考本文的学习路径,简单来说就是:为了确保高效学习,建议规划清晰的学习路线
