一,查询
1.按关键字排序
1.1用 **ORDER BY** 语句来实现排序:
- `ORDER BY` 语句用于对查询结果进行排序。可以根据一个或多个字段的值进行升序(ASC)或降序(DESC)排序。1.2排序可针对一个或多个字段:
- 可以指定一个字段或者多个字段进行排序。如果是多个字段,查询结果会首先按第一个字段排序,在第一个字段相同时再按第二个字段排序,依此类推。1.3 **ASC**:升序,默认排序方式:
- `ASC` 是升序排序,从小到大排序。如果不指定排序方式,默认使用升序排序。1.4 **DESC**:降序:
- `DESC` 是降序排序,从大到小排序。需要在 `ORDER BY` 语句后明确指定。1.5 **ORDER BY**** 的语法结构**:
plain
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;2.按关键字排序操作
创建一个表
plain
CREATE TABLE student_courses (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
score DECIMAL(4, 2),
address varchar(20),
hobbyid INT
);
INSERT INTO student_courses (id, name, score, hobbyid) VALUES
(1, 'Li Ming', 85.5,'beijing', 1),
(2, 'Wang Xiao', 92.0,'shengzheng', 2),
(3, 'Zhang San', 75.0,'shanghai', 1),
(4, 'Li Hua', 91.0,'huangshan' 3),
(5, 'Zhao Lei', 87.0,'nanjing', 2);
(6,'hanmeimei',10,'nanjing',3);
(7,'lilei',11,'nanjing',5);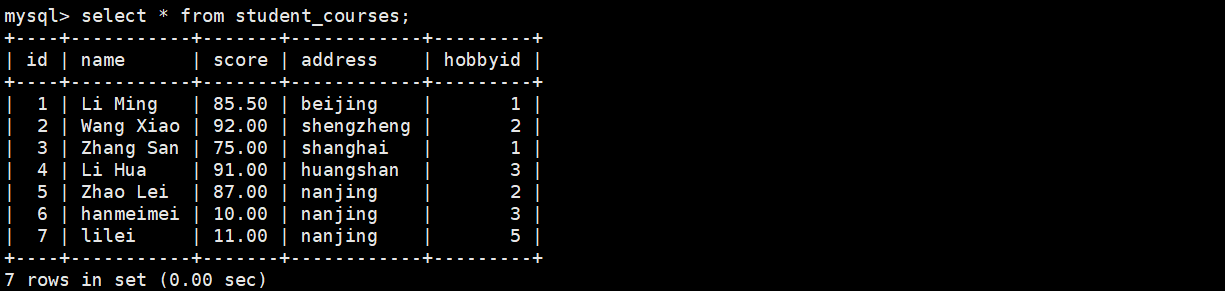
2.1 按分数排序查询(不加asc默认为升序)
plain
select id,name,score from student_courses order by score;
2.2按分数降序查询
plain
select id,name,score from student_courses order by score desc;
2.3使用where进行条件查询
过滤出南京并且按降序查询
plain
select id,name,score from student_courses where address='nanjing' order by score desc;
2.4使用ORDER BY语句对多个字段排序
ORDER BY 语句可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但是order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
(1)查询学生信息先按兴趣id降序排列,相同分数的,id也按降序排列
plain
select id,name,hobbyid from student_courses order by hobbyid desc,ind desc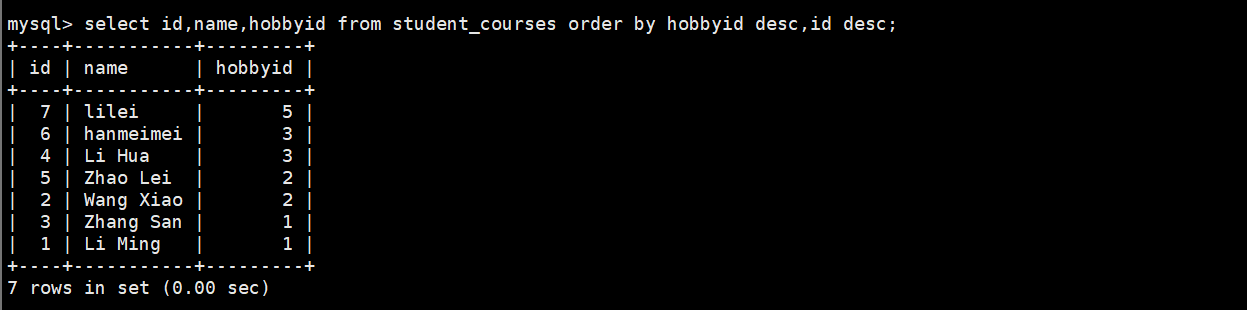
(2)查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
plain
select id,name,hobbyid from student_courses order by hobbyid desc,id;
2.5使用区间判断查询(and/or 且和或)
(1)and
plain
select * from student_courses where score >80 and score <=90;
(2)or
plain
select * from student_courses where score >80 or score =10;
2.6嵌套多个条件
plain
select * from student_courses where score >70 or (score >75 and score <90 );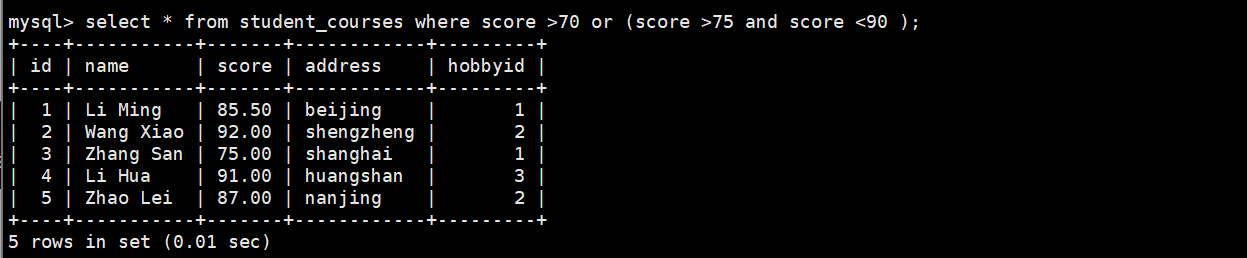
2.7 distinct 查询不重复记录
plain
select distinct hobbyid from student_courses;
2.8对查询结果进行分组
SQL 查询出来的结果,可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
(1)count
统计hobbyid相同的分组,计算相同hobbyid的个数
plain
select count(name),hobbyid from student_courses group by hobbyid;
结合where语句,筛选分数大于等于80的分组,计算有几个学生
plain
select count(name),hobbyid from student_courses where score >=80 group by hobbyid;
结合order by把计算出的学生个数按升序排列
plain
select count(name),score,hobbyid from student_courses where score >80 group byhobbyid order by count(name)2.9限制结果条目(limit重要)
limit 限制输出的结果记录
使用MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,此刻就需要用到 LIMIT 子句
(1)查询所有信息只显示前2行记录
plain
select * from student_courses limit 2;
(2)查询所有信息只显示从第4行开始,往后的2行内容
plain
select * from student_courses limit 4,2;
(2)结合order by语句,查询id的大小升序排列显示前2行
plain
select id,name from student_courses order by id desc limit 2;
(3)查询信息只显示最后3行按降序显示出来(重要)
plain
select id,name from student_courses order by id desc limit 3;
(4)查询并显示出第一行开始的后两行
plain
SELECT * FROM student_courses LIMIT 2 OFFSET 1;
2.10设置别名
别名的作用和特点
简化查询语句:当表名或列名较长时,使用别名可以减少代码长度,使查询语句更简洁、易于书写和维护。
增强可读性:通过使用别名,尤其是在涉及多个表的复杂查询中,能够使查询语句更加清晰直观,便于理解。
临时性:别名仅在当前查询中有效,它不会改变数据库中实际的表名或列名。换句话说,别名是查询语句执行过程中的临时名称,用于替代表或列的原始名称。
使用别名的语法,列的别名 :使用AS关键字为列设置别名。别名可以是任何合法的标识符,并且可以用于后续的查询中。
别名使用场景:
1.对复杂的表进行查询的时候,别名可以缩短查询语句的长度
2.多表相连查询的时候(通俗易懂、减短sql语句)
3.可以作为连接语句的操作符,可以将一个表的查询的结果插入新表中
格式
plain
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;(1)统计表内的字段有多少个,以数字形式显示(不加as也可以)

或
plain
select count(*) as 总行数 from student_courses;
(2)将查询出的结果插入新表中
plain
mysql> create table cheshi01 as select * from student_courses;
或
plain
create table cheshi02 select * from student_courses;
或
plain
create table cheshi03 as select * from student_courses where score >=70; as创建了一个新表并定义表结构,插入表数据(与student_courses表相同)
as创建了一个新表并定义表结构,插入表数据(与student_courses表相同)
但是"约束"没有被完全"复制"过来
如果原表设置了主键,附表的default字段会默认设置一个0
(3)使用别名查询
plain
select name as 姓名,score as 分数,address as 地址 from student_courses;()
或
plain
select x.name as 姓名,x.score as 分数,x.address as 地址 from student_courses as x;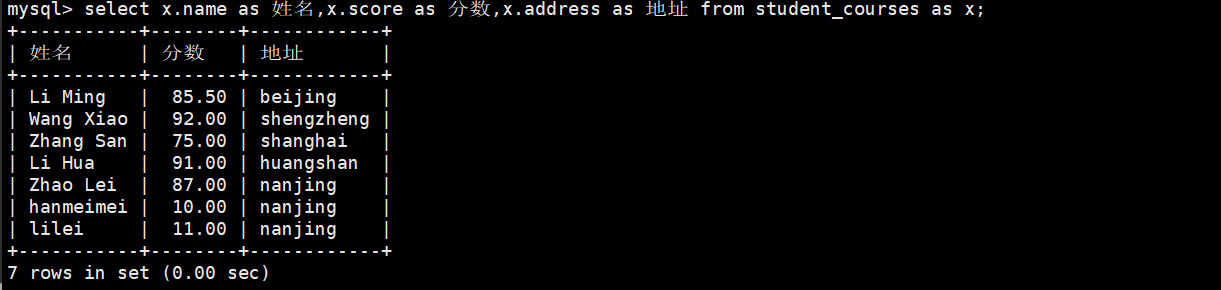
2.11通配符
通配符主用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通配符通常都是与LIKE使用的,并协同 WHERE 子句共同来完成查询任务。
常用的通配符(重要)
% 百分号表示零个,一个或多个字符
_ 下划线表示单个字符
(1)查询c开头的
plain
select id,name from student_courses where name like 'z%';
(2)查询l开头和i结尾的
plain
select id,name from student_courses where name like 'l___i';
(3) 查询中间是g的
plain
select id,name from student_courses where name like '%n%';
(4)查询以o结尾的
plain
select id,name from student_courses where name like '%o';
(5)查询以开头中间有的
plain
select id,name from student_courses where name like 'h%e%';

未完待续