list 类型
-
- [一 . 常见命令](#一 . 常见命令)
-
- [1.1 lpush、lrange](#1.1 lpush、lrange)
- [1.2 lpushx](#1.2 lpushx)
- [1.3 rpush](#1.3 rpush)
- [1.4 rpushx](#1.4 rpushx)
- [1.5 lpop、rpop](#1.5 lpop、rpop)
- [1.6 lindex](#1.6 lindex)
- [1.7 linsert](#1.7 linsert)
- [1.8 llen](#1.8 llen)
- [1.9 lrem](#1.9 lrem)
- [1.10 ltrim](#1.10 ltrim)
- [1.11 lset](#1.11 lset)
- [1.12 blpop 和 brpop](#1.12 blpop 和 brpop)
- 小结
- [二 . 内部编码](#二 . 内部编码)
- [5.3 应用场景](#5.3 应用场景)
-
- [5.3.1 作为 "数组" 这样的结构来存储多个元素](#5.3.1 作为 "数组" 这样的结构来存储多个元素)
- [5.3.2 消息队列](#5.3.2 消息队列)
- [5.3.3 微博的文章列表](#5.3.3 微博的文章列表)
Hello , 大家好 , 这个专栏给大家带来的是 Redis 系列 ! 本篇文章给大家讲解的是 Redis 中 list 类型的相关内容 , 我们会从常见命令、底层编码方式、应用场景三方面给大家介绍 . list 类型比较特殊的是 , list 提供了阻塞式的命令 , 这是我们第一次遇见 , 大家请耐心研究 .
本专栏旨在为初学者提供一个全面的 Redis 学习路径,从基础概念到实际应用,帮助读者快速掌握 Redis 的使用和管理技巧。通过本专栏的学习,能够构建坚实的 Redis 知识基础,并能够在实际学习以及工作中灵活运用 Redis 解决问题 .
专栏地址 : Redis 入门实践

正文开始
list 我们可以理解成我们之前学习过的数组 / 顺序表的结构
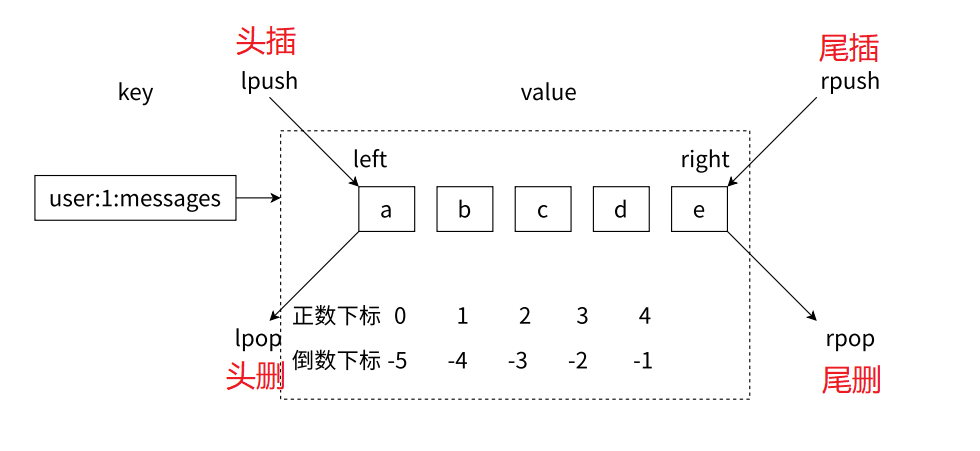
key 依然是 string 类型 , value 就是我们的列表类型了
此处我们约定最左侧元素下标为 0 , 另外 Redis 的下标也支持负数下标
那 list 虽然类似于数组的结构 , 但是他底层并不是由数组去实现的 , 而是通过一个双端队列来去维护的
那我们再来看一下 list 的特点
- 列表中的元素允许重复
我们之前学习过的 hash 类型 , field 是不能重复的 , 如果重复就会覆盖掉原有的 value
后续学到的集合以及有序集合也都是不能重复的
- list 的头部和尾部都能高效的插入和删除元素 , 那就可以把 list 当做一个 栈 / 队列 来使用
我们之前就介绍过 , Redis 有一个典型的应用场景就是作为消息队列
一 . 常见命令
1.1 lpush、lrange
lpush 的作用是将一个或者多个元素从左侧插入到 list 中 (头插法)
语法 : lpush key element1 element2 ...
注意 : 我们依次插入 1 2 3 4 , 因为是头插法 , 那全部插入完毕之后 , 元素的顺序就是 4 3 2 1
返回值 : list 插入成功之后的 list 的长度
要注意 , 如果 key 已经存在 , 并且 key 对应的 value 类型并不是 list , 那使用 lpush 命令就会报错
Redis 中所有的这些数据结构的操作 , 都是这样的要求 , 都要求相对应的命令只能执行相对应的操作
lrange 的作用是查看 start , end 范围内的数据 (闭区间) , 下标也是支持负数的
语法 : lrange key start end
lrange key 0 -1 就是获取整个 list 的元素
bash
127.0.0.1:6379> lpush key 1 2 3 4 # 头插法向 list 中插入元素
(integer) 4 # 返回值代表插入成功之后 list 的长度
127.0.0.1:6379> lpush key 5 6 7 8
(integer) 8
127.0.0.1:6379> lrange key 0 -1 # 获取 list 中所有元素
1) "8" # 头插法, 最后插入的 8 在最前面
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"那如果说我们给定了一个不合法的下标 , 那 Redis 会怎样处理呢 ? 报错 ?
bash
127.0.0.1:6379> lrange key 0 10000000000 # 我们设置了一个不合法的下标
1) "8"
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"那我们通过这个结果可以看到 , Redis 的做法就是尽可能的获取到给定区间的元素 , 如果给定区间非法的话 , 就会尽可能的获取到对应的元素
那如果左右区间都不合法呢
bash
127.0.0.1:6379> lrange key 10000 10000000000
(empty list or set)那他尽可能的获取到对应的元素 , 但是他尽力了 , 所以就找不到返回空表的信息
1.2 lpushx
lpushx 要求 key 存在才能将一个或者多个元素头插到 list 中 . 如果 key 不存在 , 直接返回 0 代表插入失败 .
语法 : lpushx key element1 element2 ...
时间复杂度 : O(1)
返回值 : 插入成功之后 list 的长度
bash
127.0.0.1:6379> lrange key 0 -1 # 此时 key 是存在的
1) "8"
2) "7"
3) "6"
4) "5"
5) "4"
6) "3"
7) "2"
8) "1"
127.0.0.1:6379> lpushx key 9 10 11 12 # 存在才去插入
(integer) 12 # 返回值代表插入成功之后 list 的长度
127.0.0.1:6379> lpushx key2 1 2 3 4 # 不存在就会插入失败
(integer) 0
127.0.0.1:6379> lrange key 0 -1 # key 是插入成功的
1) "12"
2) "11"
3) "10"
4) "9"
5) "8"
6) "7"
7) "6"
8) "5"
9) "4"
10) "3"
11) "2"
12) "1"
127.0.0.1:6379> lrange key2 0 -1 # key2 插入失败
(empty list or set)
127.0.0.1:6379> exists key2 # key2 也是不存在的
(integer) 01.3 rpush
将一个 / 多个元素从右侧插入 (尾插法)
语法 : rpush key element1 element2 ...
时间复杂度 : O(1)
返回值 : 插入成功后的 list 的长度
注意 : 如果 key 存在才能插入成功
bash
127.0.0.1:6379> rpush key 1 2 3 4 # 尾插法
(integer) 4 # 返回值代表插入成功之后 list 的长度
127.0.0.1:6379> rpush key 5 6 7 8
(integer) 8
127.0.0.1:6379> lrange key 0 -1 # 查看 list 所有元素
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"那我们 lpush 对应 rpush , lpop 对应 rpop . 那 lrange 有没有对应的 rrange 呢 ?
注意 : lpush、lpop 中的 l 指的是 left , 而 lrange 中的 l 指的是 list 而不是 left , 所以 lrange 并没有相对的命令
1.4 rpushx
与我们刚才的 lpushx 类似 , rpushx 的作用也是尾插 , 只不过存在才会插入 , 不存在就会直接返回
语法 : rpushx key element1 element2 ...
时间复杂度 : O(1)
返回值 : 插入成功之后 list 的长度
bash
127.0.0.1:6379> rpushx key 9 10 11 12 # 存在才去尾插
(integer) 12
127.0.0.1:6379> lrange key 0 -1 # 9 10 11 12 尾插成功
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
10) "10"
11) "11"
12) "12"
127.0.0.1:6379> rpushx key2 1 2 3 4 # 但是 key2 不存在, 就会尾插失败
(integer) 0
127.0.0.1:6379> lrange key2 0 -1 # 此时就获取不到 key2 的相关元素了
(empty list or set)
127.0.0.1:6379> exists key2 # key2 也不存在
(integer) 01.5 lpop、rpop
lpop 的作用是从 list 左侧取出元素 (头删)
语法 : lpop key
时间复杂度 : O(1)
返回值 : 如果列表中有元素 , 返回取出的元素 ; 如果没有元素 , 返回 nil
bash
127.0.0.1:6379> rpush key 1 2 3 4 # 尾插法插入元素
(integer) 4
127.0.0.1:6379> lrange key 0 -1 # 获取列表中所有元素
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> lpop key # 头删
"1" # 返回值代表取出的元素
127.0.0.1:6379> lpop key
"2"
127.0.0.1:6379> lpop key
"3"
127.0.0.1:6379> lpop key
"4"
127.0.0.1:6379> lrange key 0 -1 # 此时所有元素已被弹出, 列表为空
(empty list or set)
127.0.0.1:6379> lpop key # 此时再去弹出元素, 就会返回 nil
(nil)rpop 的作用是从 list 右侧取出元素 (尾删)
语法 : rpop key count
那相较于 lpop , rpop 这里增加了一个 count , 这是怎么回事 ?
lpop 和 rpop 在当前的 Redis 5.x 系列中 , 是没有 count 参数的 . count 参数是在 Redis 6.2 版本后引进的 , 表示这次要删除几个元素
bash
127.0.0.1:6379> rpush key 1 2 3 4 # 尾插法插入元素
(integer) 4
127.0.0.1:6379> lpop key 4 # Redis 5.x 没有此命令
(error) ERR wrong number of arguments for 'lpop' command
127.0.0.1:6379> rpop key 4 # Redis 5.x 没有此命令
(error) ERR wrong number of arguments for 'rpop' command
127.0.0.1:6379> rpop key # 尾删法
"4"
127.0.0.1:6379> rpop key
"3"
127.0.0.1:6379> rpop key
"2"
127.0.0.1:6379> rpop key
"1"
127.0.0.1:6379> lrange key 0 -1 # 此时 list 中没有元素了
(empty list or set)
127.0.0.1:6379> rpop key # 再去尾删就会返回 nil
(nil)那我们目前也清楚了 , Redis 是一个双端队列 , 从两侧插入 / 删除的时间复杂度都是 O(1) 的
所以我们就可以搭配 rpush 和 lpop 就相当于队列
搭配 rpush 和 rpop 就相当于栈了
1.6 lindex
lindex 用来获取从左数第 index 位置的元素
就相当于顺序表的 get 方法 , 比如 : list.get(i)
语法 : lindex key index
时间复杂度 : O(N) , N 指的是 list 中的元素个数
内部并不是完全按照数组进行实现的 , 所以时间复杂度并不是 O(1)
返回值 : 返回该位置的元素 ; 如果下标非法 , 返回的是 nil
bash
127.0.0.1:6379> rpush key 1 2 3 4 5 6 7 8 # 尾插法插入元素
(integer) 8
127.0.0.1:6379> lindex key 3 # 获取 3 位置的元素
"4" # 返回值代表该位置的元素
127.0.0.1:6379> lindex key -1 # lindex 支持负数下标, -1 就代表最后一个元素
"8"
127.0.0.1:6379> lindex key 99 # 下标非法返回 nil
(nil)1.7 linsert
在指定元素的位置插入元素 (不是按照下标添加元素)
语法 : linsert key <before | after> pivot element
<before | after> 指的是插入到 pivot 之前还是之后
pivot 表示插入到哪
element 表示插入啥
时间复杂度 : O(N) , N 为列表的长度
我们也需要遍历找到 pivot 的位置
返回值表示插入成功之后 list 的长度
bash
127.0.0.1:6379> linsert key before 4 100 # 在 4 之前插入 100
(integer) 9 # 返回值表示插入成功之后 list 的长度
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "100" # 在 4 之前插入 100
5) "4"
6) "5"
7) "6"
8) "7"
9) "8"
127.0.0.1:6379> linsert key after 4 200 # 在 4 之后插入 200
(integer) 10
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "100"
5) "4"
6) "200" # 在 4 之后插入 200
7) "5"
8) "6"
9) "7"
10) "8"那我们也介绍了 , 它是按照具体的元素来去决定在前面还是在后面插入的 , 他并不是根据下标来去插入的
那假如我们的 list 中有重复元素 , 这该怎么搞 ?
bash
127.0.0.1:6379> rpush key 1 2 3 4 5 6 7 8 4 # 此时 list 中有两个 4
(integer) 9
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "4" # 第一个 4
5) "5"
6) "6"
7) "7"
8) "8"
9) "4" # 第二个 4
127.0.0.1:6379> linsert key before 4 300 # 在元素 4 之前插入 300
(integer) 10
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "300" # 那插入到了第一个 4 的前面
5) "4"
6) "5"
7) "6"
8) "7"
9) "8"
10) "4"通过这个例子 , 我们能看出来 , linsert 进行插入的时候 , 要根据给定的具体元素找到对应的位置 , 他是从左往右找的 , 找到第一个符合基准值的位置即可
1.8 llen
它的作用是获取列表的长度
语法 : llen key
bash
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "300"
5) "4"
6) "5"
7) "6"
8) "7"
9) "8"
10) "4"
127.0.0.1:6379> llen key
(integer) 101.9 lrem
lrem 的作用是删除元素
rem -> remove
语法 : lrem key count element
count 表示要删除的个数
element 表示要删除的值
时间复杂度 : O(N + M) , N 指的是 list 的长度 , M 指的是现在有多少个元素要被删除 (也就是 count)
那我们再来看 count :
- count > 0 : 从左往右找 , 删除 count 个 element
- count < 0 : 从右往左找 , 删除 count 个 element
- count == 0 : 删除所有 element
比如 : list 有 16 个元素 , 为 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
- count 为 2 , element 为 1 : 比如 lrem key 2 1 , 那就代表从左往右找 2 个 1 进行删除 , 得到的结果就是 2 3 4 2 3 4 1 2 3 4 1 2 3 4
- count 为 -2 , element 为 1 : 比如 lrem key -2 1 , 那就代表从右往左找 2 个 1 进行删除 , 得到的结果就是 1 2 3 4 1 2 3 4 2 3 4 2 3 4
- count 为 0 , element 为 1 : 比如 lrem key 0 1 , 那就代表删除所有 1 , 得到的结果就是 2 3 4 2 3 4 2 3 4 2 3 4
我们具体通过命令来看一眼
bash
127.0.0.1:6379> rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 # 构造出四组 1 2 3 4
(integer) 16
# count > 0 -> 从左往右删除 count 个 element
127.0.0.1:6379> lrem key 2 1 # 从左往右删除 2 个 1
(integer) 2 # 返回值代表删除成功的个数
127.0.0.1:6379> lrange key 0 -1
1) "2" # 第一组的 1 被删除了
2) "3"
3) "4"
4) "2" # 第二组的 1 被删除了
5) "3"
6) "4"
7) "1"
8) "2"
9) "3"
10) "4"
11) "1"
12) "2"
13) "3"
14) "4"
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
(integer) 16
# count < 0 -> 从右往左删除 count 个 element
127.0.0.1:6379> lrem key -2 1 # 从右往左删除 2 个 1
(integer) 2
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "1"
6) "2"
7) "3"
8) "4"
9) "2" # 第三组的 1 被删了
10) "3"
11) "4"
12) "2" # 第四组的 1 被删了
13) "3"
14) "4"
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush key 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
(integer) 16
# count == 0 -> 删除所有 element
127.0.0.1:6379> lrem key 0 1 # 删除所有的 1
(integer) 4
127.0.0.1:6379> lrange key 0 -1
1) "2" # 第一组的 1 被删除了
2) "3"
3) "4"
4) "2" # 第二组的 1 被删除了
5) "3"
6) "4"
7) "2" # 第三组的 1 被删了
8) "3"
9) "4"
10) "2" # 第四组的 1 被删了
11) "3"
12) "4"1.10 ltrim
ltrim 也是删除元素 , 他可以删除指定范围区间之外的元素
语法 : ltrim key start stop
注意 : 他是保留 start 和 stop 之间区间内的元素 , 区间外的两侧的元素就直接被删除了
时间复杂度 : O(N) , N 指的是要删除的元素个数
bash
127.0.0.1:6379> rpush key 1 2 3 4 5 6 7 8 # 尾插法插入元素
(integer) 8
127.0.0.1:6379> ltrim key 2 5 # 只保留 [2,5] 之间的元素
OK
127.0.0.1:6379> lrange key 0 -1 # [2,5] 下标之外的元素就被删除了
1) "3"
2) "4"
3) "5"
4) "6"1.11 lset
与之前的 lindex 类似 , lset 的作用是根据下标来去修改元素
语法 : lset key index element
时间复杂度 : O(N)
需要找到对应的下标然后再去修改元素
bash
127.0.0.1:6379> lset key 2 666 # 修改 2 号下标为 666
OK
127.0.0.1:6379> lrange key 0 -1
1) "1"
2) "2"
3) "666" # 2 号下标就被修改成了 666
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"如果下标不合法会直接报错
bash
127.0.0.1:6379> lset key 222 666
(error) ERR index out of range1.12 blpop 和 brpop
原理
blpop 和 brpop 是阻塞版本的弹出元素
阻塞就是当前的线程干不了活了 , 不能继续往下执行了 . 只有满足一定条件之后才能被唤醒
那 Redis 中的 list 也相当于阻塞队列 , 但是 Redis 中只需要考虑队列为空的情况 , 不需要考虑队列满的情况
也就是如果 list 中存在元素 , blpop、brpop 就和 lpop、rpop 作用完全相同 ;

如果 list 为空 , blpop 和 brpop 就会产生阻塞 , 一直阻塞到队列不空为止 .
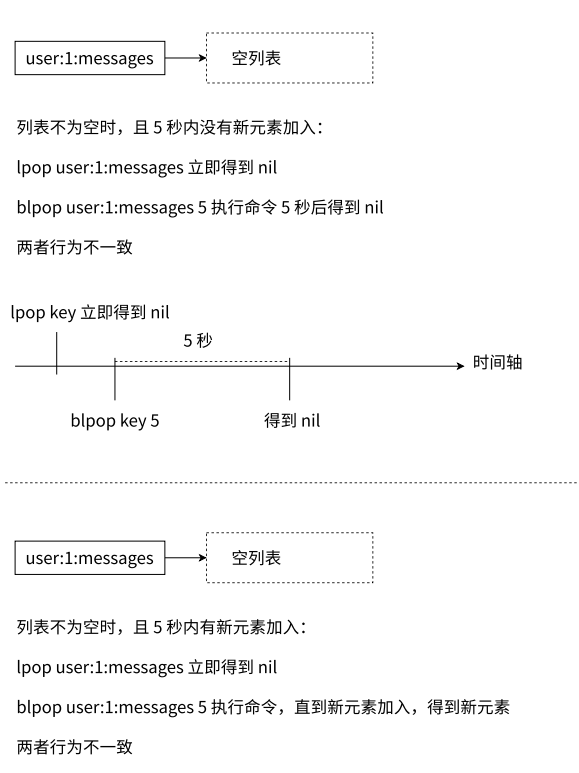
那关于 blpop 和 brpop , 我们还需要额外关注这几点
- 使用 blpop 和 brpop 的时候 , 我们是可以显式的设置阻塞时间的 , 不一定是无休止的等待 , 在这期间 Redis 可以执行其他的命令
此处的 blpop 和 brpop 实际上不会对 Redis 服务器产生太大的影响 , 是被特殊处理过的
- 命令中如果设置了多个 key , 那么会从左向右进行遍历 , 一旦有某一个 key 对应的列表中被添加了元素 , 那这个 key 对应的列表就可以弹出元素 , 则命令立即返回
也就是 blpop 和 brpop 都是可以同时去尝试获取多个 key 的列表的元素的 , 也就是多个 key 会对应多个 list , 这几个 key 中哪个 list 有元素了 , 就会返回哪个元素
- 如果多个客户端同时对一个键进行 pop 操作 , 那最先执行到命令的客户端就会先得到弹出的元素
使用
blpop 的语法 : blpop key1 key2 ... timeout
此处可以指定多个 key , 每个 key 都对应一个 list
- 如果这些 list 有任何一个非空 , 那就会把这个 list 中的元素给获取到 , 就会立即返回
- 如果这些 list 都为空 , 此时就需要阻塞等待 , 等待其他客户端往这些 list 中插入元素了
我们还可以指定超时时间 , 单位是 s (Redis 6 中超时时间允许设置成小数)
首先 , 我们针对一个非空的列表进行操作

bash
127.0.0.1:6379> rpush key 1 2 3 4
(integer) 4
127.0.0.1:6379> blpop key 0 # 设置超时时间为 0
# 返回结果是一对
1) "key" # 当前数据来自于哪个 key
2) "1" # 取到的数据是什么针对一个空列表进行操作
bash
127.0.0.1:6379> rpush key 1 2 3 4
(integer) 4
127.0.0.1:6379> del key
(integer) 1
127.0.0.1:6379> blpop key 100此时我们也能看到光标正在闪烁
这时候就需要我们额外的客户端往 key 中添加数据 , 当我们其他客户端往 list 中添加数据之后 , 左侧被阻塞的客户端立马就通了
那左边的客户端就返回了新的结果
bash
127.0.0.1:6379> blpop key 100
1) "key"
2) "1"
(14.23s)
针对多个 key 进行操作
客户端 1
bash
127.0.0.1:6379> flushdb # 此时我们清空了数据库
OK
127.0.0.1:6379> blpop key key2 key3 key4 500 # 那现在 key key2 key3 key4 都不存在, 就会在这里进行阻塞当我们其他的客户端去创建 list 并且插入元素的时候
bash
# key key2 key3 key4 都不存在
127.0.0.1:6379> lrange key 0 -1
(empty list or set)
127.0.0.1:6379> lrange key2 0 -1
(empty list or set)
127.0.0.1:6379> lrange key3 0 -1
(empty list or set)
127.0.0.1:6379> lrange key4 0 -1
(empty list or set)
# 此时我们创建一个 list, 客户端 1 就会立即返回数据左侧的客户端会立马感知到数据并且返回

还有一种多个客户端同时监听一个 key 的情况 , 我们不太好进行模拟 , 就不演示了
那这两个命令主要的用途就是来作为 "消息队列" , 但是这两个命令功能还是比较有限 , 就比较鸡肋了
小结

二 . 内部编码
列表类型的内部编码有两种
- ziplist (压缩列表) : 把数据按照更紧凑的压缩形式来表示的 , 它的特点就是节省空间 , 但是如果元素过多 , 操作数据效率就会降低
- linkedlist (链表) : 当元素过多 , 就会从 ziplist 升级成链表
但是这是老版本 Redis 的实现 , 现在主要采用的是 quicklist (quicklist = ziplist + linkedlist)
quicklist 整体还是一个链表 , 但是链表的每个节点都是一个压缩列表 , 它的特点就是每个压缩列表都不会让他太大 , 同时再把多个压缩列表通过链式结构压缩起来
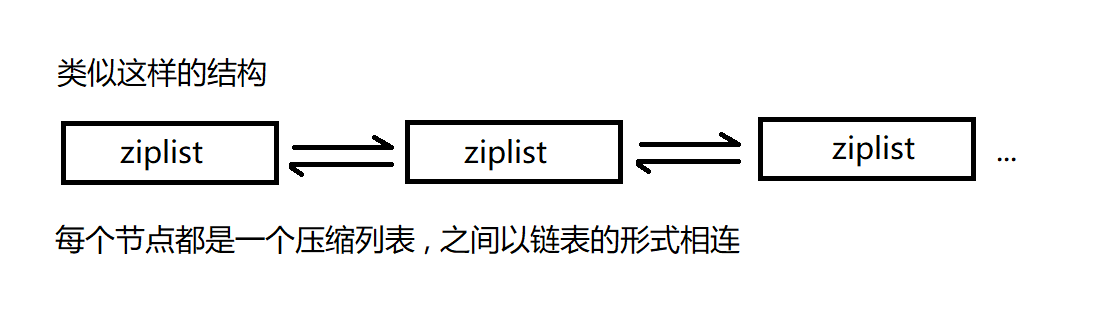
我们可以看一下 quicklist 的底层配置

他表示我们每个压缩列表体积设置成多少合适 , 也就是说我们压缩列表体积到达一定程度就会分裂成多个压缩列表
那他也给出了我们几个档位 , -2 代表 8 kb , 也就是说压缩列表达到 8 kb 就会进行分裂
5.3 应用场景
5.3.1 作为 "数组" 这样的结构来存储多个元素
比如我们有这样的一个场景 : 学生和班级信息
那在 MySQL 中 , 是这样处理的
stu (stuId , stuName , age , score , classId)
class (classId , className)
那在这样的表结构中 , 就很容易查询出指定班级中有哪些同学
但是在 Redis 中查询数据并没有 MySQL 那样灵活 , 他的处理方式是这样的

那我们还需要指定学生和班级的关系
| classStudents:1 | 1,2 |
|---|---|
| classStudents:2 | 1 |
Redis 查询数据只能通过 key 去查询 value , 所以就需要我们将班级信息构造成 key , 班级成员构造成 value
具体 Redis 中的数据如何组织 , 都需要按照业务具体来去决定
5.3.2 消息队列
虽然 Redis 作为消息队列比较少见 , 但是这也是 Redis 实现的初衷之一
那在消息队列中最核心的概念就是 "生产者-消费者" 模型
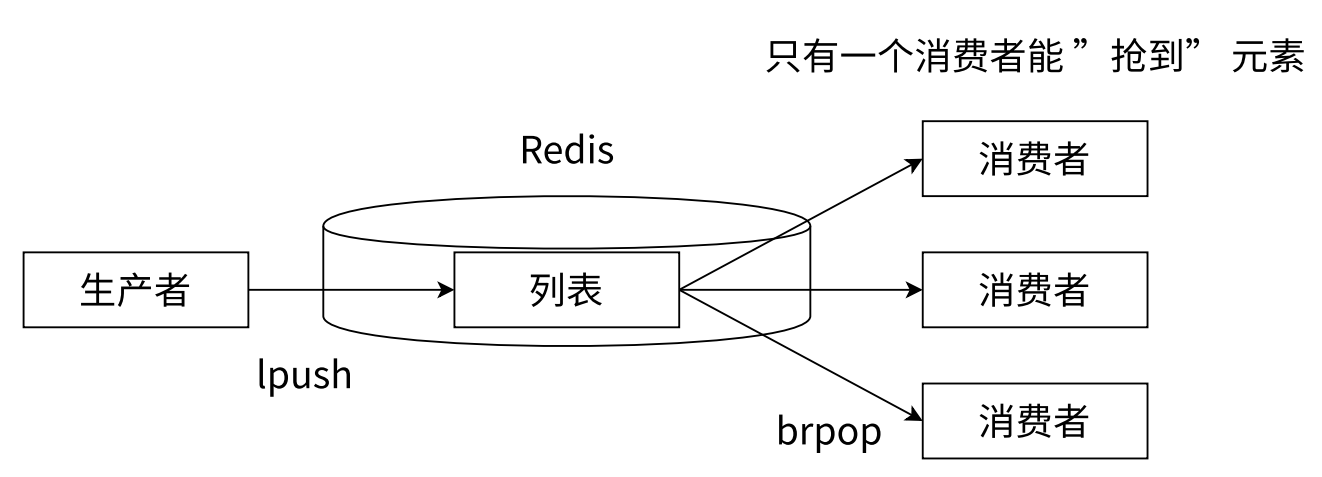
生产者就可以使用 lpush 添加元素 , 消费者就可以使用 brpop 来去获取元素
brpop 是阻塞的操作 , 当列表为空的时候 , brpop 就会阻塞等待 , 需要一直等到其他客户端添加元素
那多个消费者之间 , 谁先执行 brpop , 谁就能获取到新添加的元素
那根据这个特性 , 就能实现一个 "轮询" 的效果
假设消费者执行 brpop 命令的顺序为 1 2 3 , 那当新元素到达之后 , 首先是消费者 1 获取到元素 , 然后他就会从 brpop 中返回了 (相当于这个命令就执行完了) , 如果消费者 1 还想继续消费 , 就需要重新执行 brpop
此时再来一个新元素 , 那就是消费者 2 会获取到新的元素
那这样就构成了一个 "轮询" 的效果
那这样实现的消息队列 , 是比较简陋的 , 再给大家介绍一种 "分频道" 的消息队列
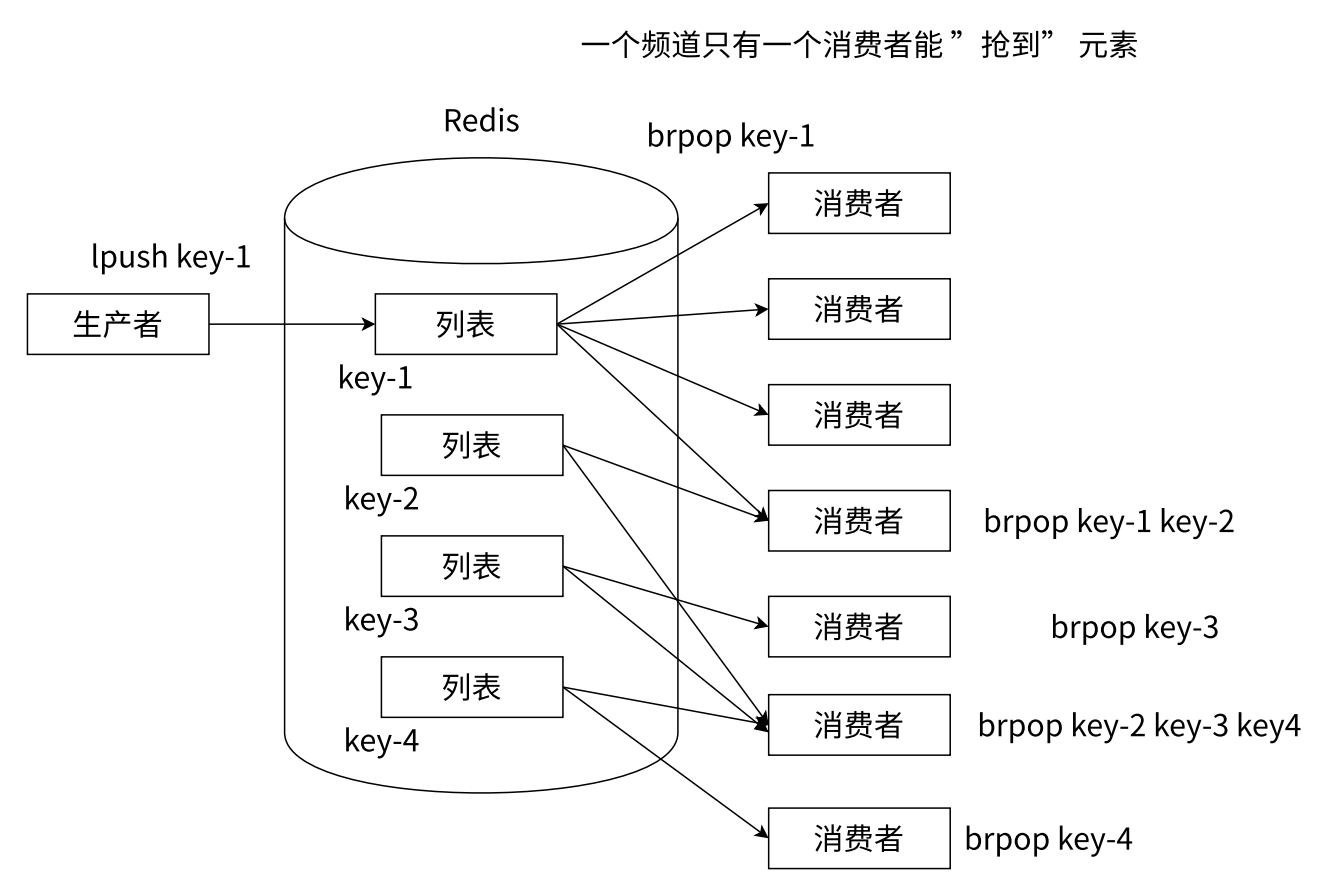
我们 Redis 中存储了多个列表 , 同时也具有多个消费者
那这种场景也非常常见 , 比如我们日常使用的一些程序 , 比如我们刷 B 站 , 我们既可以看视频 , 还可以看弹幕
那就有一个通道 , 来去传输短视频数据 , 还可以有一个通道来传输弹幕 , 还可以有频道来去传输其他的信息 , 比如 : 点赞、评论 ...
那我们搞多个频道 , 就可以在某种数据发生问题的时候 , 不会影响到其他频道 , 这也就是解耦合 .
那根据 Redis 来说 , 每个列表就可以认为是一个频道 , 那我们的消费者也可以从多个列表中读取数据
brpop 是可以读取多个 key 的
5.3.3 微博的文章列表
每个用户都有自己的 Timeline , 也就是微博列表 , 用户可以看到自己什么时候发了什么微博
那他的实现原理跟场景一一样 , 都是将 list 当做数组使用了
那我们可以模拟一下微博是怎样存储用户数据的
那每篇微博使用哈希结构去存储 , 比如我们存储三个属性 : title、timestamp、content
bash
hmset mblog:1 title xx timestamp 1314520 content xxx
...
hmset mblog:n title xx timestamp 521521 content xxx那用户添加微博 , 我们使用 user::mblogs 作为微博的键
bash
# value 使用上面的 key, 也就是类似 mblog:1 这样的结构
lpush user:1:mblogs mblog:1 mblog:3 # 代表插入了 1 号文章和 3 号文章
...
lpush user:k:mblogs mblog:9那我们就能通过 mblog:1 来去 hash 中查询文章的具体内容了
那我们要想实现分页 , 也很简单 , 使用 lrange 指定区间范围即可
bash
keylist = lrange user:1:mblogs 0 9 # 获取 [0,9] 之间的文章, 也就是获取前 10 篇文章
for key in keylist {
hgetall key
}但是这种方案可能存在两个问题
- 如果每次分页获取的微博个数较多 , 那就需要执行多次 hgetall 命令 , 就涉及到许多次网络交互了

那我们解决策略是使用 "流水线" ("管道") , 虽然我们是多个 hgetall 命令 , 但是使用管道就可以把这些命令合并成一个请求进行网络通信 , 这就会大大降低客户端和服务器之间的交互次数
- lrange 获取列表两端元素效率较高 , 但是获取列表中间的元素表现就会很差
意思就是我们的 lrange 需要传入两个下标作为检索的区间 , 那这两个下标如果在列表两端 , 直接从链表头部 / 链表尾部遍历就好 , 但是如果在中间 , 那就需要花更多的时间
那我们解决的策略就是对用户的文章进行切分 , 假如一个用户发了 1w 个微博 , 那 list 的长度就是 1w , 那就可以把这 1w 个微博拆成 10 份 , 每份就是 1k , 这样虽然业务层代码实现可能复杂一点 , 但是就能够解决一定的效率问题
那今天 list 类型的分享就结束了 , 如果对你有帮助的话还请一键三连~
