Title
题目
CCSI: Continual Class-Specific Impression for data-free class incremental learning
CCSI: 用于无数据类别增量学习的持续类别特定印象
01
文献速递介绍
当前用于医学图像分类任务的深度学习模型表现出了令人鼓舞的性能。然而,这些模型大多要求在训练之前收集所有的训练数据并指定所有的类别。它们在部署时对深度学习模型进行一次性训练,并期望其能够在随后的所有数据上执行。然而,这种要求在实际的临床环境中具有局限性,因为医学图像数据是不断收集且随时间变化的,*例如*,当出现新疾病类型时。
一种有前途的解决这一机器学习挑战的方法是使系统具备持续或终身学习的能力,即部署的模型能够适应新数据,同时保持从先前数据中获得的信息。将这些学习技术整合到模型中,将使深度学习模型更能适应医疗数据集的不断扩展。在各种增量场景中,医学持续学习已经被广泛应用(van de Ven等,2022),这些场景考虑到了新数据的非平稳性。这些场景包括任务增量学习(González等,2023;Liao等,2022;Xu等,2022;Kaustaban等,2022;Chakraborti等,2021),即引入新的医学任务,*例如*,将分割网络扩展到另一身体区域;类别增量学习(Chee等,2023;Yang等,2021a;Li等,2020b),即在模型中添加新类别,*例如*,在分类任务中引入一种新疾病类型;以及领域增量学习(Yang等,2023;Srivastava等,2021;Bayasi等,2021),即模型面临其未经过训练的新医学领域。这些增量学习场景的大多数假设是能够访问先前模型的所有训练数据或其中的一部分,这些数据被存储在内存系统中。然后,重新训练过程在保存的数据和新数据上进行。
Abatract
摘要
In real-world clinical settings, traditional deep learning-based classification methods struggle with diagnosingnewly introduced disease types because they require samples from all disease classes for offline training. Classincremental learning offers a promising solution by adapting a deep network trained on specific disease classesto handle new diseases. However, catastrophic forgetting occurs, decreasing the performance of earlier classeswhen adapting the model to new data. Prior proposed methodologies to overcome this require perpetualstorage of previous samples, posing potential practical concerns regarding privacy and storage regulationsin healthcare. To this end, we propose a novel data-free class incremental learning framework that utilizesdata synthesis on learned classes instead of data storage from previous classes. Our key contributions includeacquiring synthetic data known as Continual Class-Specific Impression (CCSI) for previously inaccessible trainedclasses and presenting a methodology to effectively utilize this data for updating networks when introducingnew classes. We obtain CCSI by employing data inversion over gradients of the trained classification modelon previous classes starting from the mean image of each class inspired by common landmarks sharedamong medical images and utilizing continual normalization layers statistics as a regularizer in this pixelwise optimization process. Subsequently, we update the network by combining the synthesized data with newclass data and incorporate several losses, including an intra-domain contrastive loss to generalize the deepnetwork trained on the synthesized data to real data, a margin loss to increase separation among previousclasses and new ones, and a cosine-normalized cross-entropy loss to alleviate the adverse effects of imbalanceddistributions in training data. Extensive experiments show that the proposed framework achieves state-of-theart performance on four of the public MedMNIST datasets and in-house echocardiography cine series, withan improvement in classification accuracy of up to 51% compared to baseline data-free methods.
在现实世界的临床环境中,传统的基于深度学习的分类方法在诊断新出现的疾病类型时面临挑战,因为这些方法需要从所有疾病类别中获取样本进行离线训练。类增量学习提供了一种有前景的解决方案,通过适应已训练的特定疾病类别的深度网络来处理新的疾病。然而,在适应新数据时会发生灾难性遗忘,导致早期类别的性能下降。此前提出的克服这一问题的方法需要永久存储先前的样本,这在医疗保健中可能会带来隐私和存储法规方面的实际问题。为此,我们提出了一种新的无数据类增量学习框架,该框架利用已学习类别的数据合成来代替先前类别的数据存储。我们的主要贡献包括获取称为"持续类特异性印象"(CCSI)的合成数据,这些数据用于以前无法访问的已训练类别,并提出了一种有效利用这些数据在引入新类别时更新网络的方法。
我们通过对以前类别的训练分类模型的梯度进行数据反演,从每个类别的平均图像开始,获取CCSI,这受到医学图像中常见标志物的启发,并利用持续归一化层的统计数据作为这一像素级优化过程的正则化项。随后,我们通过将合成数据与新类别数据结合来更新网络,并引入多种损失函数,包括域内对比损失以将深度网络从合成数据训练推广到真实数据,边缘损失以增加旧类别和新类别之间的区分度,以及余弦归一化交叉熵损失以减轻训练数据分布不平衡带来的不利影响。大量实验表明,该框架在四个公开的MedMNIST数据集和内部的超声心动图动态序列上达到了最先进的性能,与基线的无数据方法相比,分类准确率提高了多达51%。
Method
方法
This section is structured as follows. We begin by explaining theproblem setting of data-free incremental learning in Section 3.1. Next,in Section 3.2, we identify the challenges in the setting and give anoverview of our proposed pipeline, emphasizing three crucial factors that drive our design: (1) normalization layer, (2) data synthesis, and (3)loss functions. Furthermore, we elaborate on the techniques suggestedto tackle the first two factors in Section 3.3. Finally, we present the newloss terms utilized to address the third factor in Section 3.4.
本节结构如下:首先,我们在第3.1节解释无数据增量学习的问题设定。接下来,在第3.2节中,我们识别了这一设定中的挑战,并概述了我们提出的流程,重点强调推动我们设计的三个关键因素:(1)归一化层,(2)数据合成,以及(3)损失函数。此外,我们在第3.3节中详细说明了应对前两个因素的技术。最后,我们在第3.4节介绍了用于解决第三个因素的新损失项。
Conclusion
结论
In this work, we propose CCSI, a novel data-free class incrementallearning framework for medical image classification. In CCSI, we synthesize class-specific images by inverting from the trained model withclass-mean image initialization. We explore a recently introduced normalization layer -- CN, to reduce overwriting moments during continualtraining and propose a novel statistic regularization using the frozenCN moments for image synthesis. Subsequently, we continue trainingon new classes and synthesized images using the proposed novel lossesto increase the utility of synthesized data by mitigating domain shiftbetween new synthesized and original images of old classes and alleviating catastrophic forgetting and imbalanced data issues among newand past classes. Experimental results for four MedMNIST datasets asbenchmark public datasets and in-house echocardiography cines as thelarge-scale and more complex dataset validate that CCSI outperformsthe state-of-the-art methods in data-free class incremental learningwith an improbable gap of up to 51% accuracy in the final task andget comparable results with the state-of-the-art data-saving rehearsalbased methods. Our proposed method shows the potential to applyincremental learning in many healthcare applications that cannot savedata due to memory constraints or private issues.
在本研究中,我们提出了CCSI,这是一种用于医学图像分类的创新性无数据类别增量学习框架。在CCSI中,我们通过使用类别均值图像初始化,从训练好的模型进行反演来合成类别特定的图像。我们探索了一种新近引入的归一化层------CN,以减少在持续训练过程中重写统计信息的情况,并提出了一种利用冻结的CN统计数据进行图像合成的统计正则化方法。随后,我们在新类别和合成图像上继续训练,使用提出的新损失函数,通过减轻新合成图像与旧类别原始图像之间的域迁移问题,缓解灾难性遗忘和新旧类别之间数据不平衡的问题,从而提高合成数据的效用。
在四个MedMNIST数据集(作为基准公共数据集)和内部超声心动图序列(作为大规模和更复杂的数据集)上的实验结果表明,CCSI在无数据类别增量学习中显著优于最先进的方法,在最终任务中的准确率提升了高达51%的差距,并且与最先进的数据保存排练方法取得了可比的结果。我们提出的方法显示出在许多因内存限制或隐私问题而无法保存数据的医疗应用中应用增量学习的潜力。
Figure
图
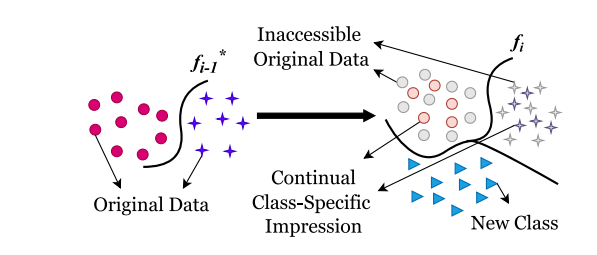
Fig. 1. Representation of data-free class incremental learning. 𝑓𝑖 −1 is the model trainedon previous data, while 𝑓𝑖 is the updated model with new classes. This approach enablesthe incremental learning of new classes added to a previously trained model withouthaving access to previous data. We propose to tackle this problem by synthesizingsamples of previous classes as the continual class-specific impression and adding themto the continual training paradigm. Best viewed in coloured print.
图1. 无数据类别增量学习的表示。𝑓𝑖 −1 是在先前数据上训练的模型,而 𝑓**𝑖 是包含新类别的更新模型。该方法使得在不访问先前数据的情况下,将新类别增量学习添加到先前训练的模型中成为可能。我们提出通过合成先前类别的样本作为持续类别特定印象,并将其添加到持续训练范式中,以解决这一问题。建议在彩色打印时查看最佳效果。
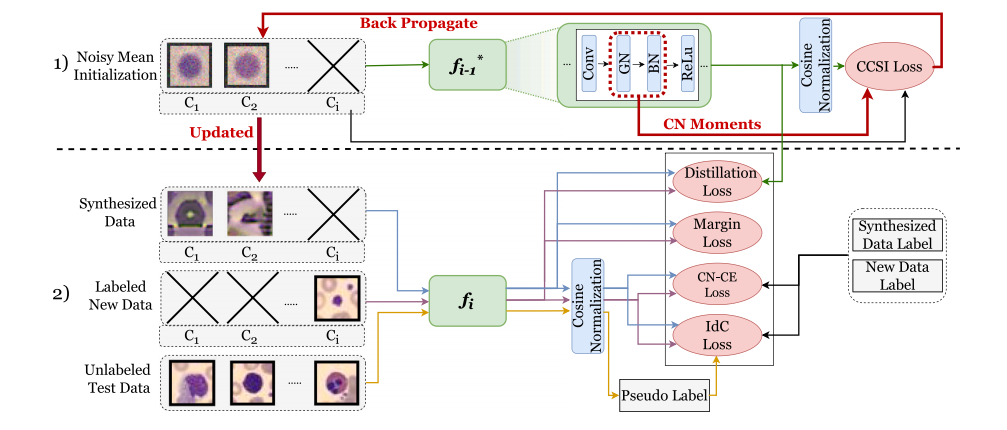
Fig. 2. The class incremental learning pipeline of CCSI. Two main steps of CCSI contain: (1) Continual class-specific data synthesis (Section 3.3): Initialize a batch of images withthe mean of each class to synthesize images using a frozen model trained on the previous task, 𝑓**𝑖 ∗ −1. Update the batch by back-propagating with Eq. (1) and using the statisticssaved in the CN as a regularization term (Eq. (4)); (2) Model update on new tasks (Section 3.4): Leverage information from the previous model using the distillation loss. Toprevent catastrophic forgetting of past tasks, we mitigate domain shift between synthesized and original data with a novel intra-domain conservative (IdC) loss (Section 3.4.1), asemi-supervised domain adaptation technique and encourage robust decision boundaries and overcome data imbalance with the margin loss (Section 3.4.2) and cosine-normalizedcross-entropy (CN-CE) loss (Section 3.4.3). Best viewed in coloured print.
图2. CCSI的类别增量学习流程。CCSI的两个主要步骤包括:(1) 持续类别特定数据合成(第3.3节):使用每个类别的均值初始化一批图像,通过冻结的先前任务模型 𝑓**𝑖 ∗ −1 来合成图像。通过反向传播更新批次(使用公式(1))并将CN中保存的统计数据作为正则化项(公式(4));(2) 模型在新任务上的更新(第3.4节):利用蒸馏损失从先前模型中获取信息。为了防止对过去任务的灾难性遗忘,我们通过一种新的域内保守(IdC)损失(第3.4.1节)来缓解合成数据与原始数据之间的域迁移,这是一个半监督领域适应技术,同时通过边缘损失(第3.4.2节)和余弦归一化交叉熵(CN-CE)损失(第3.4.3节)鼓励稳健的决策边界并克服数据不平衡问题。建议在彩色打印时查看最佳效果。
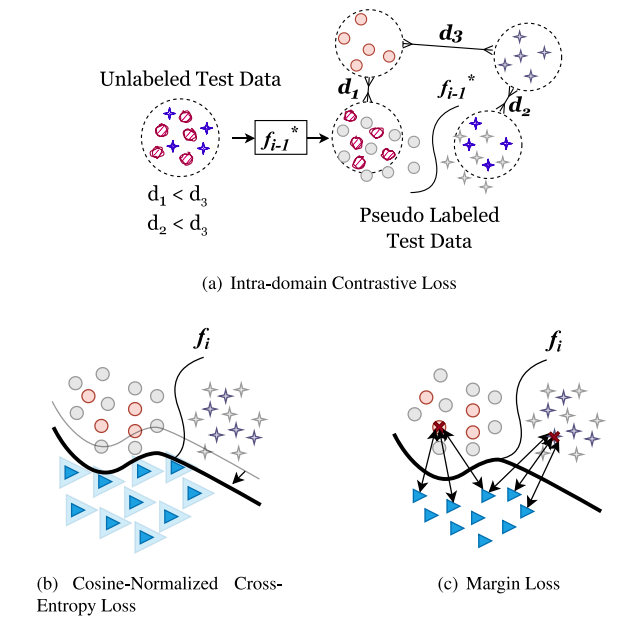
Fig. 3. Schematic diagram of TEDS-Net, illustrated for multi-structure segmentation with 𝑐 channels. Two deformation fields are learnt through a series of convolutions appliedto an input image, before being encouraged to be topology-preserving through our topology-preserving layers (shown in the green box).
图3. TEDS-Net的示意图,展示了用于多结构分割的 𝑐 个通道。通过对输入图像应用一系列卷积学习到两个变形场,然后通过我们的拓扑保持层(绿色框中所示)进行调整,以保持拓扑结构。
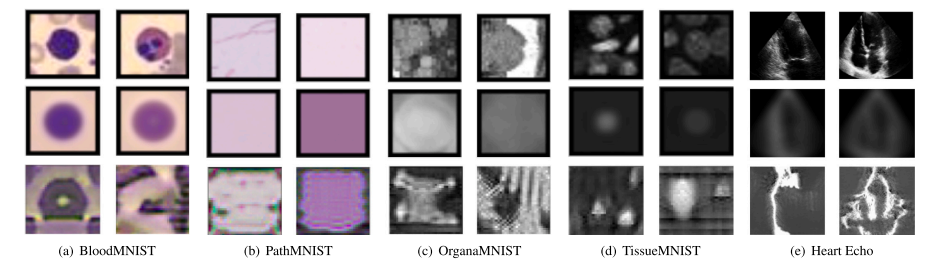
Fig. 4. Datasets' samples. Each dataset's first row shows samples from two different classes, the second row is the mean initialization of the respective class, and the third row is the synthesized images. Best view in coloured.
图4. 数据集样本展示。每个数据集的第一行显示了来自两个不同类别的样本,第二行是相应类别的均值初始化,第三行是合成图像。建议在彩色状态下查看效果最佳。
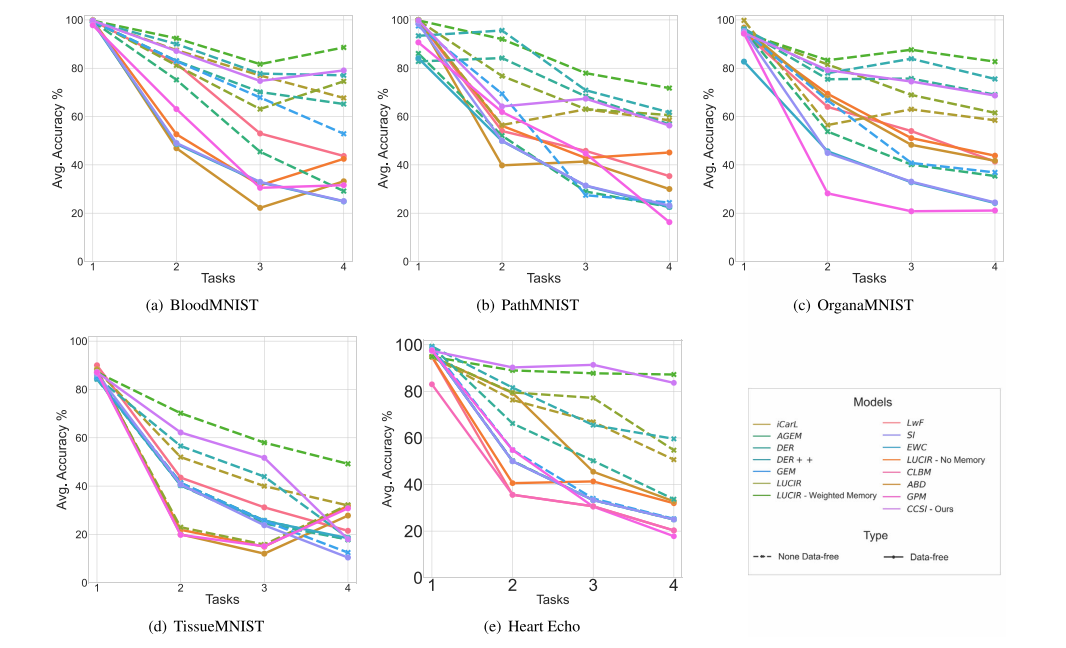
Fig. 5. Testing accuracies on all tasks compared with state-of-the-art class-incremental learning. Dashed lines represent non-data-free methods, while straight lines representdata-free methods. We outperform all data-free methods on all datasets except TissueMNIST. While we surpass some non-data-free methods, we achieve comparable results withothers..
图5. 所有任务的测试准确率与最先进的类别增量学习方法的比较。虚线表示非无数据方法,而实线表示无数据方法。我们在所有数据集上都优于所有无数据方法,除了TissueMNIST。在某些情况下,我们超过了一些非无数据方法,并在其他情况下取得了可比的结果。
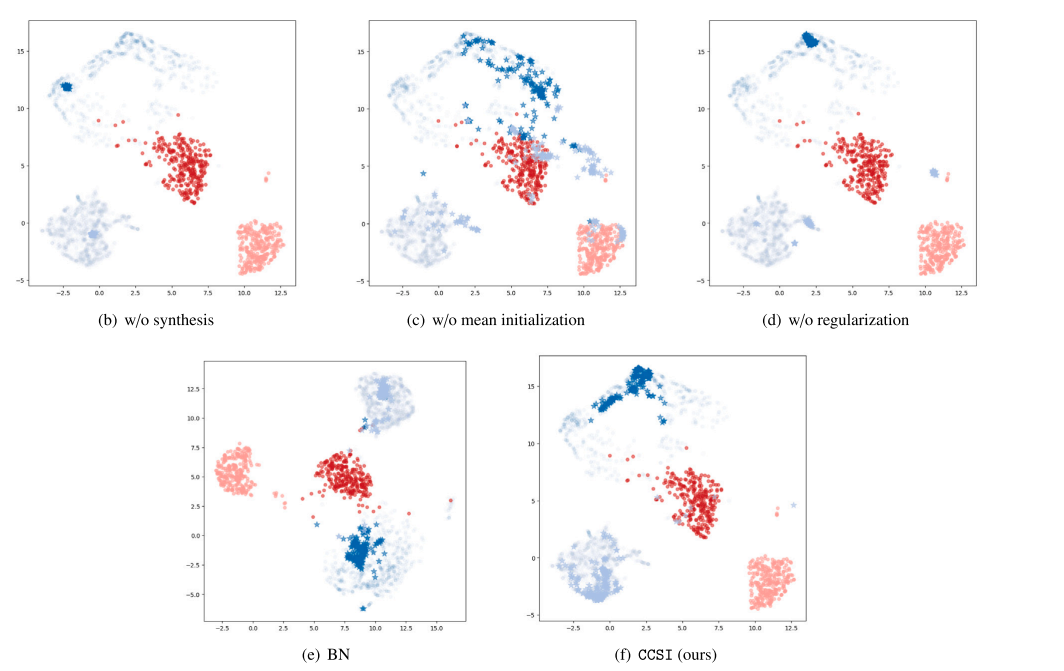
Fig. 6. Visual representations of both original and synthesized images for the BloodMNIST dataset in the latent space, utilizing various methods for the synthesis step usingUMAP (McInnes et al., 2018). We aim to show that the synthetic data generated via CCSI has the closest distribution with the original ones compared with alternatives. Wepresent the latent space representation of original samples from previous classes: the initial two classes (1 and 2), and current classes: the two most recently added classes (7 and in the final task, using circle markers (∙). In addition, we showcase synthesized samples for the initial two classes, represented by star markers (), which serve as exemplarsof original samples that are no longer available.
图6. 使用UMAP(McInnes等,2018)在潜在空间中展示了BloodMNIST数据集的原始图像和合成图像的可视化表示。我们旨在展示通过CCSI生成的合成数据与原始数据相比,具有最接近的分布。图中展示了先前类别(最初的两个类别,1和2)和当前类别(在最终任务中最近添加的两个类别,7和8)的原始样本的潜在空间表示,使用圆形标记(∙)表示。此外,我们展示了使用星形标记(⋆)表示的最初两个类别的合成样本,这些样本作为不再可用的原始样本的代表。
Table
表
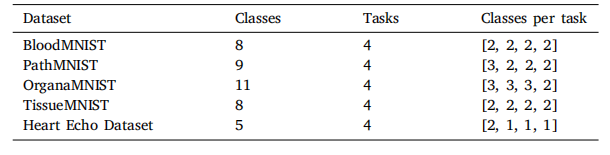
Table 1Class division for MedMNIST and Heart Echo datasets. In each task, we introducedifferent classes than previously learned tasks. Our goal is to have a model performingwell in all of the introduced classes.
表1MedMNIST和心脏超声数据集的类别划分。在每个任务中,我们引入了与先前学习任务不同的类别。我们的目标是使模型在所有引入的类别中表现良好。
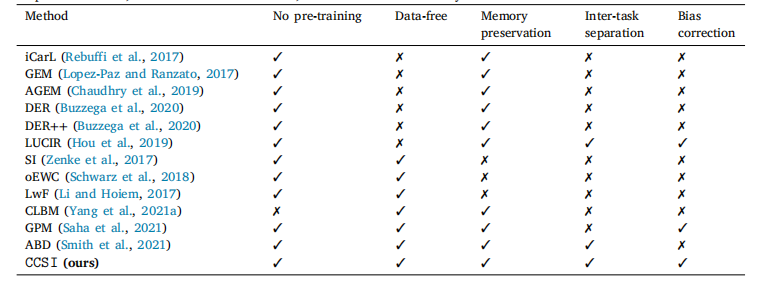
Table 2Conceptual comparison of CCSI and state-of-the-art class incremental learning methods. CCSI is a data-free approach thatsynthesizes data without pre-training using additional data. Moreover, we leverage the synthesized data to retain the memoryof previous classes, address inter-task confusion, and overcome task-recency bias.
表2 CCSI与最先进的类别增量学习方法的概念比较。CCSI是一种无数据的方法,通过无需使用额外数据进行预训练来合成数据。此外,我们利用合成的数据来保留先前类别的记忆,解决任务间的混淆问题,并克服任务新近性偏差。

Table 3Testing accuracies of final task over MedMNIST and Heart Echo datasets compared with data-free baselines of class-incremental learning. CCSI shows consistently higher accuracy,up to 51% increase compared to the state-of-the-art data-free methods.
表3 MedMNIST和心脏超声数据集上最终任务的测试准确率,与无数据类别增量学习基线方法的比较。CCSI表现出持续更高的准确率,相较于最先进的无数据方法,准确率最高提升了51%。

Table 4Testing accuracies of final task over MedMNIST and Heart Echo datasets compared with non-data-free baselines of class-incremental learning.
表4 MedMNIST和心脏超声数据集上最终任务的测试准确率,与非无数据类别增量学习基线方法的比较。
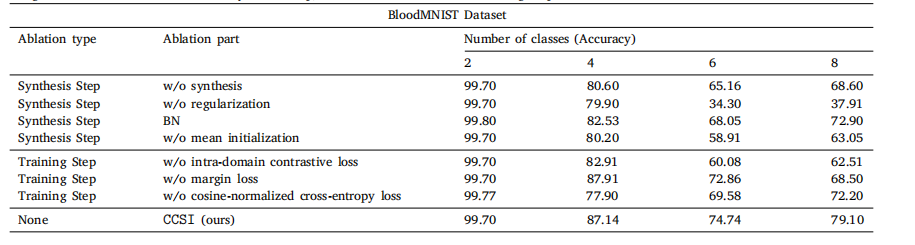
Table 5Testing accuracy of ablation studies done on different configurations of the proposed framework. These experiments are divided into two maincategories: (1) Modifications over the synthesis Step; (2) Modifications over the training Step.
表5 不同配置下对所提框架进行消融研究的测试准确率。这些实验分为两大类:(1) 合成步骤的修改;(2) 训练步骤的修改。