AI图像放大工具,如ESRGAN,对于提高由Stable Diffusion生成的AI图像质量至关重要。它们被广泛使用,以至于许多Stable Diffusion的图形用户界面(GUI)都内置了支持。
在这里,我们将学习什么是图像放大器,它们如何工作,以及如何使用它们。
为什么我们需要图像放大器?
Stable Diffusion v1的默认图像大小是512×512像素。**按照今天的标准来看,这相当低。**以iPhone 12为例。它的相机可以产生1200万像素的图像------即4032×3024像素。它的屏幕显示2532×1170像素,所以一个没有被放大的Stable Diffusion的质量是比较差的,不适合在现代的应用中使用。
另外,如果图片的分辨率太低的话,图片就缺少很多细节,使用起来也有诸多不便。
为什么我们不能使用传统的放大器?
传统放大器当然可以使用,但结果不会那么好。
用于调整图像大小的传统算法,如最近邻插值和Lanczos插值,因为仅使用图像的像素值而受到批评。它们通过仅使用图像的像素值执行数学运算来扩大画布并填充新的像素。然而,如果图像本身有损坏或扭曲,这些算法就无法准确填充缺失的信息。
AI放大器是如何工作的?
AI放大器是使用大量数据训练的神经网络模型。它们可以在放大图像的同时填充细节。
在训练过程中,图像被人为地损坏以模拟现实世界的退化。然后训练AI放大器模型以恢复原始图像。
大量的先验知识被嵌入到模型中。它可以填充缺失的信息。这就像人类不需要详细研究一个人的面孔就能记住它一样。我们主要关注几个关键特征。
如何使用AI放大器?
让我们来了解如何在AUTOMATIC1111 WebUI for Stable Diffusion中使用AI放大器。
转到Extras 页面,并选择Single Image。
上传你想要放大的图像到source。
设置Resize因子。许多AI放大器可以原生地将图像放大4倍。所以4是一个很好的选择。如果你不希望图像那么大,可以将其设置为较低的值,比如2。
如果你的图像是512×512像素,2倍放大是1024×1024像素,4倍放大是2048×2048像素。
选择R-ESRGAN 4x+,这是一个适用于大多数图像的AI放大器。
按Generate开始放大。
完成后,放大后的图像将出现在右侧的输出窗口中。右键单击图像以保存。
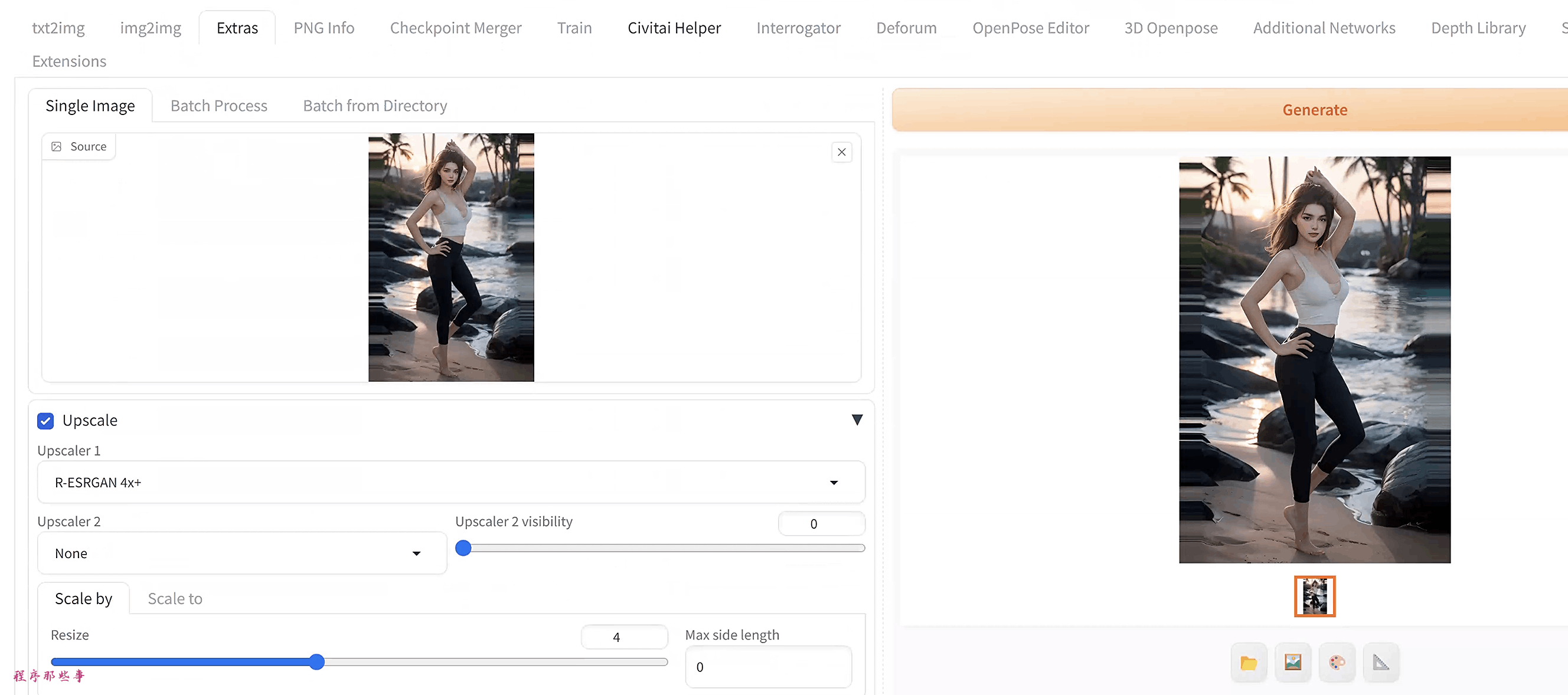
可以看到页面上还有一个upscaler 2的选项,这意味着你可以把两个放大器混合使用。
后面的Upscaler 2 visibility是用来控制使用upscaler 2模型进行放大的比例。
0表示完全不是用,1表示只使用upscaler 2。
AI放大器选项
让我们来了解一些值得注意的AI放大器选项。
LDSR
Latent Diffusion Super Resolution (LDSR)放大器最初与Stable Diffusion 1.4一起发布。它是一个训练用于执行放大任务的潜在扩散模型。尽管它提供了卓越的质量,但它非常慢。我不建议使用它。
ESRGAN 4x
Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN)是一个放大网络,赢得了2018年感知图像恢复和操作挑战赛。它是之前SRGAN模型的增强版。它倾向于保留细节并产生清晰锐利的图像。ESRGAN是许多其他放大器的基础模型。
R-ESRGAN 4x
Real-ESRGAN (R-ESRGAN)是对ESRGAN的增强,可以恢复各种现实世界的图像。它模拟了从相机镜头和数字压缩的各种扭曲程度。
与ESRGAN相比,它倾向于产生更平滑的图像。
R-ESRGAN在处理现实照片图像时表现最佳。
安装新的放大器
要在AUTOMATIC1111 GUI中安装新的放大器,只需要从放大模型数据库下载一个模型并将其放入文件夹中。
stable-diffusion-webui/models/ESRGAN
重新启动GUI。你的放大器现在应该可以在放大器下拉菜单中选择。
放大图像的例子
使用AUTOMATIC1111中的Extras只是一个非常简单的图片放大的例子。
如果你想是用放大的同时来进行一些细节增强,那么我们可以考虑使用SD Upscale来进行这种复杂案例的修改。
SD Upscale是AUTOMATIC1111附带的一个脚本,它使用放大器进行放大,然后使用图像到图像来增强细节。
下面具体的使用步骤:
第1步。 导航到Img2img页面。
第2步。 将图像上传到img2img画布上。(或者,使用Send to Img2img按钮将图像发送到img2img画布)
第3步。 在底部的Script 下拉菜单中,选择SD Upscale。
第4步。 将Scale factor设置为4以放大到原始大小的4倍。
第5步。 将去噪强度设置在0.1和0.3之间。越高,图像变化越大。
第6步。 将sampling steps的数量设置为100。更高的步骤可以改善细节。
第7步。 你可以使用原始提示和负面提示。如果没有,使用"highly detailed"作为提示。
第8步。 按Generate。
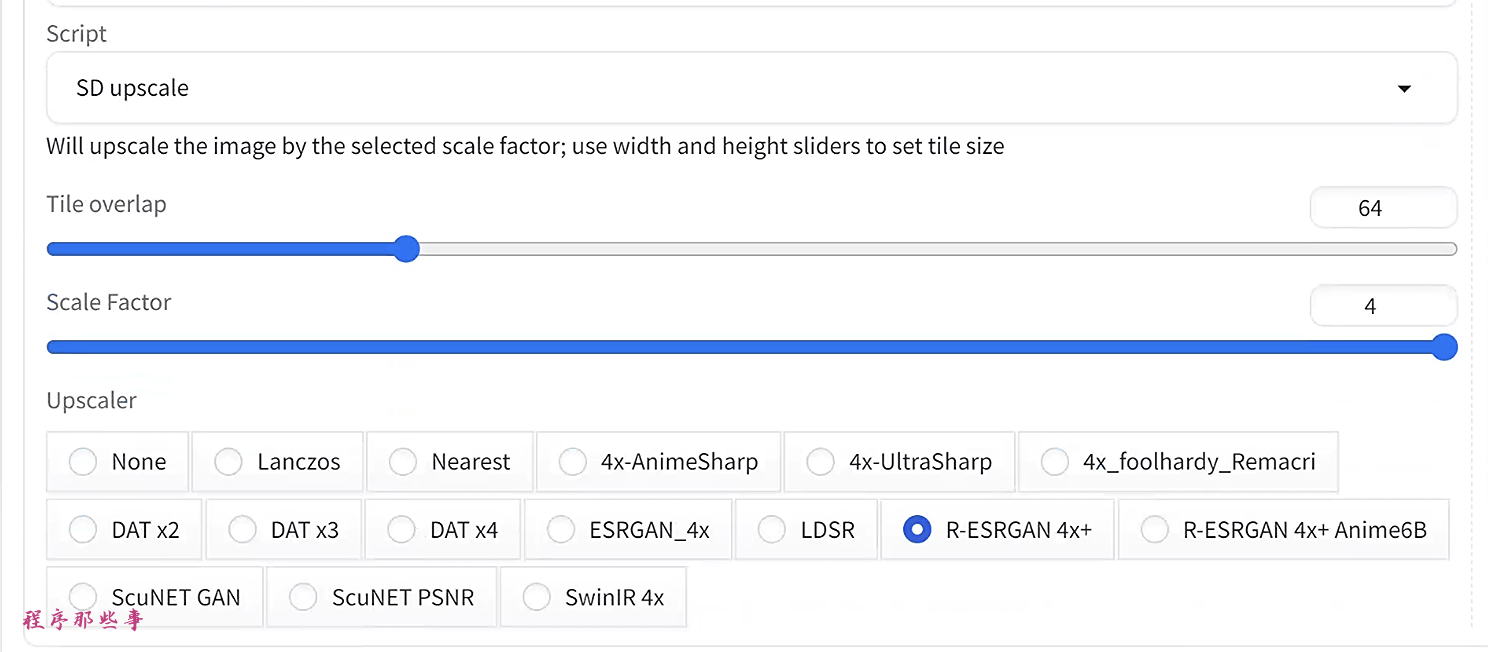
再来看下对比效果:
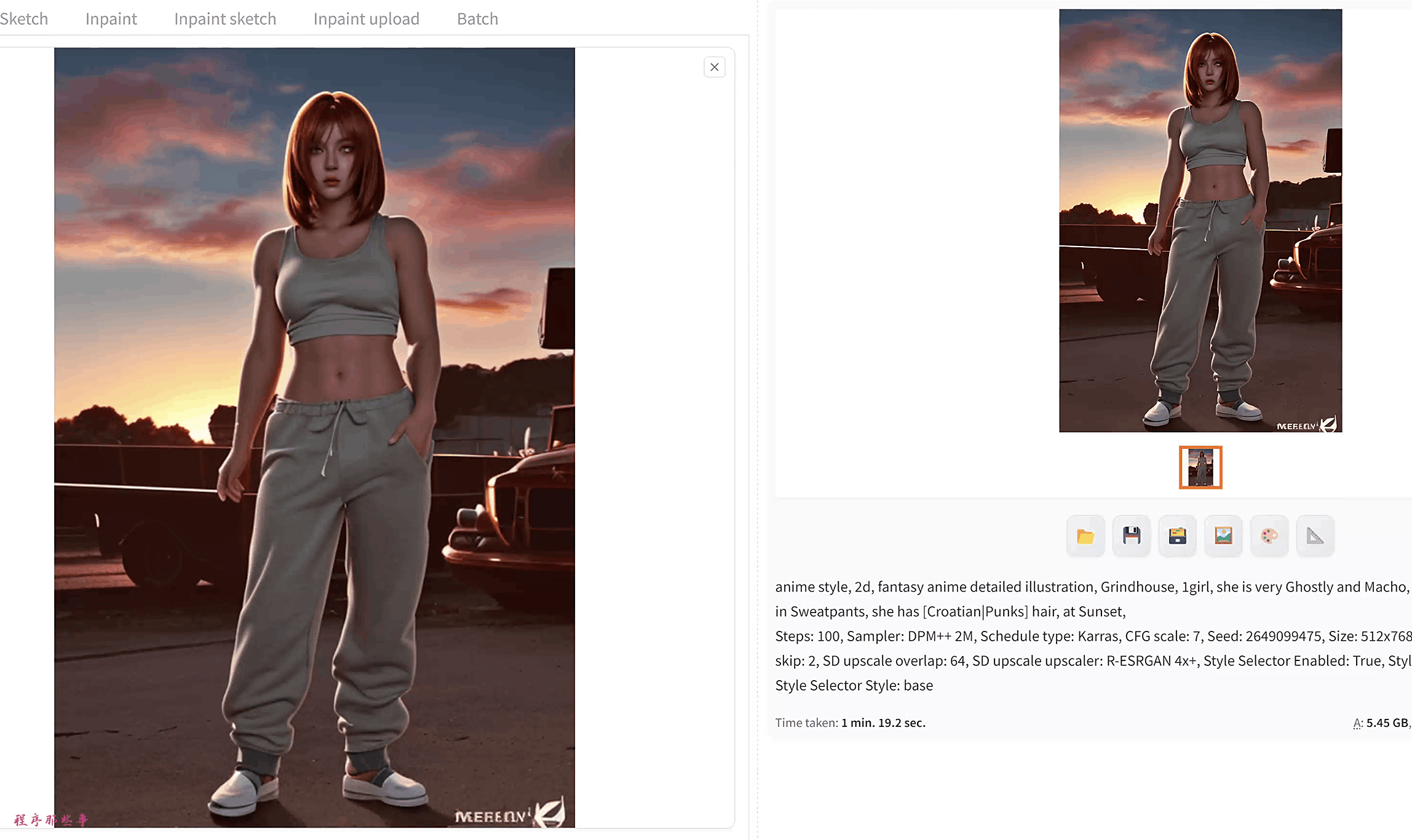
效果不错,还增加了一些细节效果。
SD Upscale脚本有助于改善细节并减少放大伪影。
txt2img页面上的Hires Fix
还有一种图像放大的方式就是在txt2img中的Hires Fix。
你可以在txt2img页面上选择放大每个生成的图像。为此,你只需要勾选Hires fix。
勾选框下将出现额外的选项。这些选项类似于使用SD Upscale脚本。
整个Hires. fix过程你可以理解为我们在图像进行放大后,再基于该图像进行了二次生成。
这个Hires steps就是我们二次生成时的步数,如果数值保持为0,就代表和原有图像生成时的步数相同。
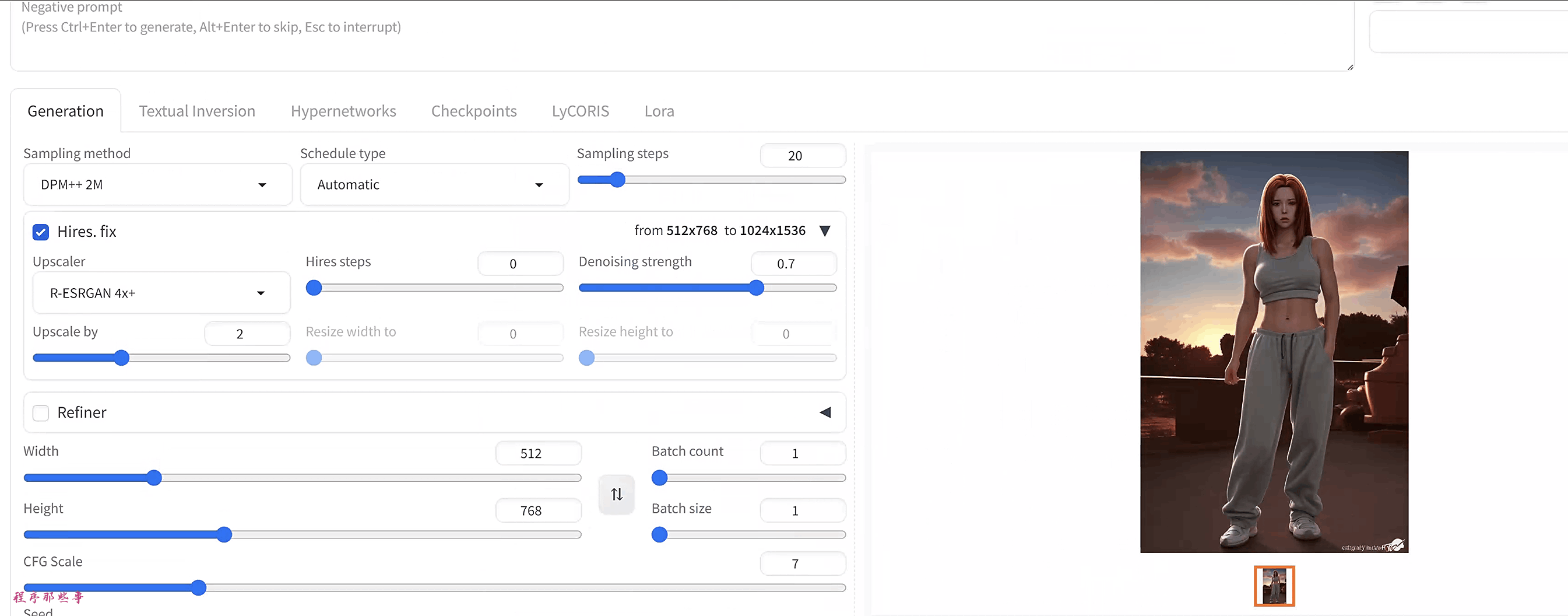
Hires fix会在你生成图片的同时放大所有生成的图片。
所以它会减慢图像的生成速度。
建议的做法先生成图片,然后把挑选好的图片发到img2img进行SD放大。
ControlNet Tile Upscale
上面的SD Upscale还可以跟ControlNet Tile一起使用,从而达到在放大的过程中得到更好的细节。
具体而言,就是在img2img中开启controlNet:
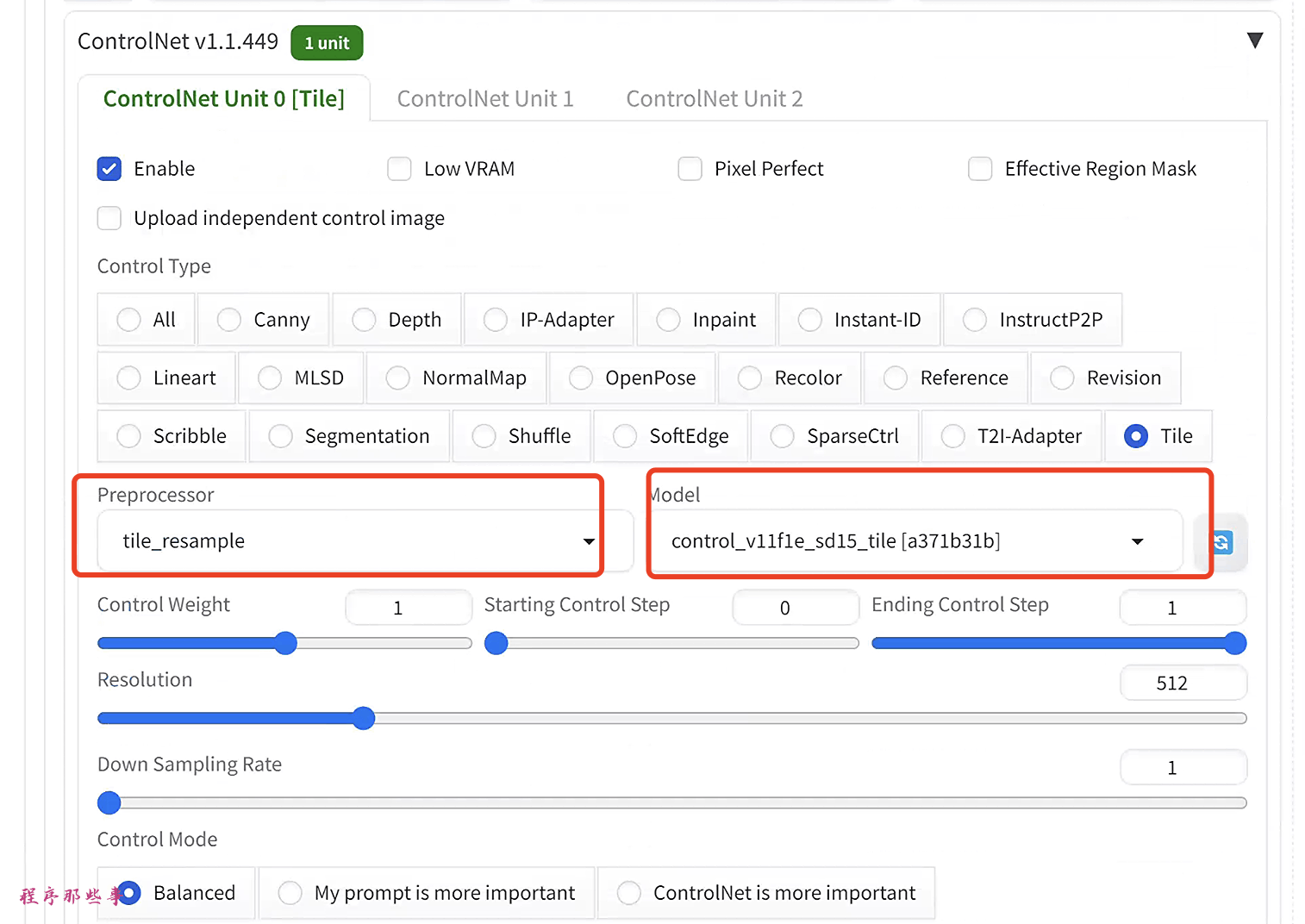
Control type选择Tile。
preprocessor选择tile_resample。
Model选择control_***tile。
同时开启SD Upscale,点击生成即可。
可能会耗时比较久,但是效果应该是最好的。