本文是github上的大模型教程LLMs-from-scratch的学习笔记,教程地址:教程链接
Chapter 2: Working with Text

这一章节包括了数据的准备和采样阶段。
1. Tokenizer
大模型通过将token转变为embedding(词嵌入)运作。
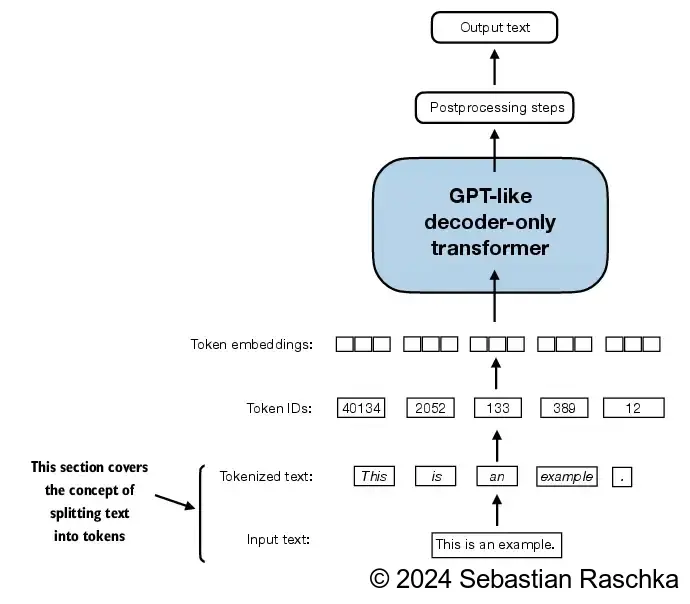
首先通过tkenizer,将输入拆分成一个一个的单元。
我们可以自己写一个简单的tokenizer,例如通过空格划分
python
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
>>>
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']如果再包括上标点符号,那么最终我们自制的tokenizer如下:
python
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)2. Token IDs
有了Tokenizer后,我们需要一个词汇表(vocabulary),为每一个token分配一个索引,方便之后进行矩阵运算。

在这里,我们使用简单的字典序,将在训练集中出现的每一个token分配一个token ID。在使用大量数据训练得到了较为完备的词汇表后,对于之后的输入,我们只需要查表,得到对应的下标即可。

于是我们就可以写出一个简单的Tokenizer,包括了encode和decode
python
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return textencode负责把文本转换成token IDs
decode负责把token IDs转换成文本

我们首先使用tokenizer,将文本转换成token IDs,然后使用token IDs提取出对应的embeddings输入模型。
3. 特殊符号
加入一些特殊的token是很有必要的,他可以标记文本的结束,也可以标记没有见过的tgoken等。
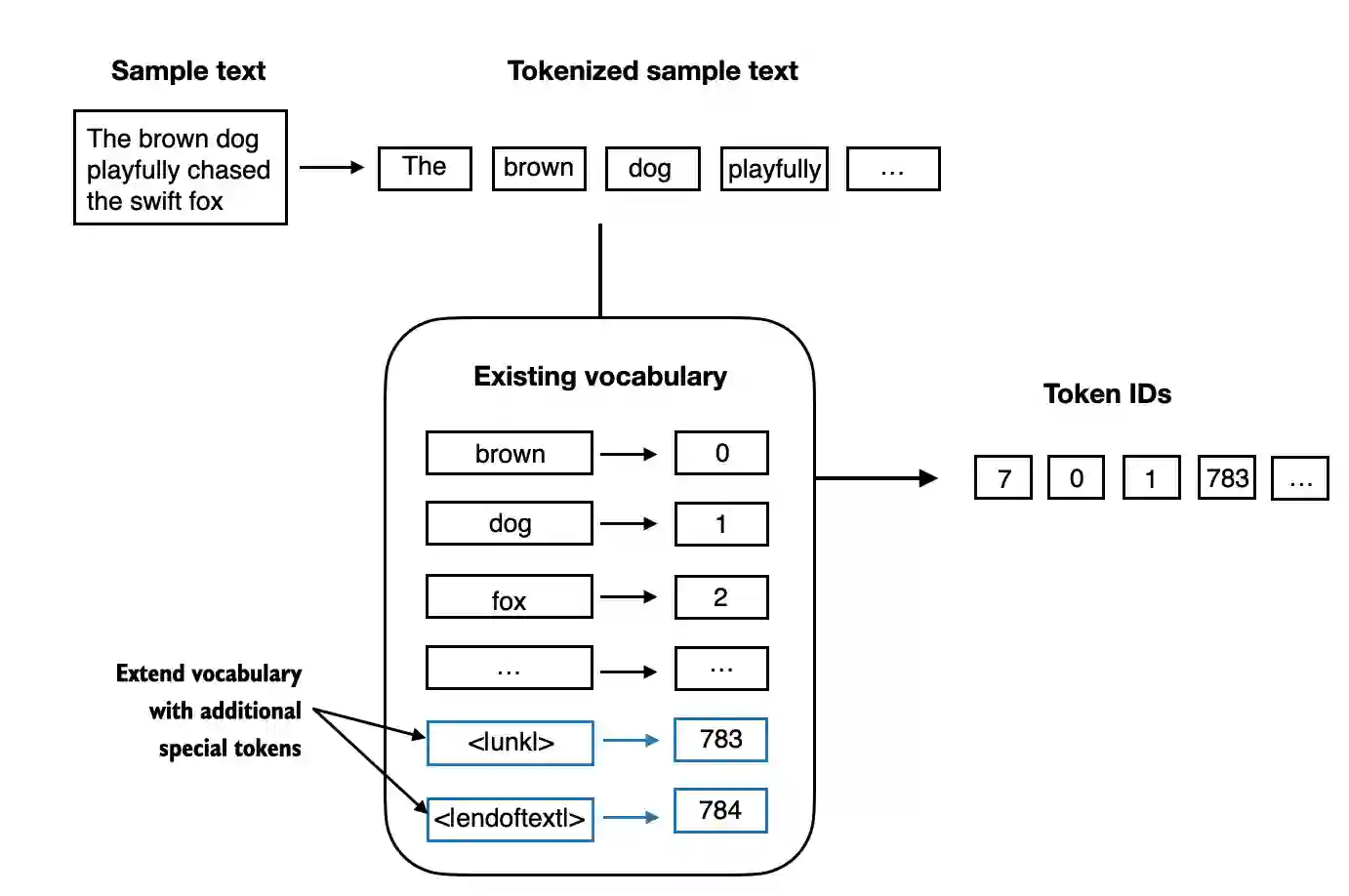
下面举几个简单的例子:
- BOS (beginning of sequence)表示文本的开头
- EOS (end of sequence) 表示文本的结束
- PAD (padding) 如果LLM的batch_size大于1,那么使用PAD标记来讲每一段文本扩充到相同的长度。
- UNK 表示没在词汇表里的token
GPT 没有使用 UNK,因为GPT使用的BPE分词器包含了很小的单元,不会有UNK的情况存在。
于是我们在我们的tokenizer代码上进行修改,当识别到没有见过的token时,转换为UNK。
python
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return textencode包含了两个功能:一是将文本拆分成token,二是用token去词汇表中找到token对应的索引,第一步不会出错,第二步有可能找不到。
4. BytePair encoding(BPE)
GPT使用的是BPE分词器,它允许模型将不在预定义词汇表中的单词分解为更小的子单词单元甚至单个字符,使其能够处理未登录词汇表的单词。例如,如果GPT-2的词汇表中没有单词"unfamiliarword",它可能会将其标记为"unfaml","iliar","word"或其他子单词分解。
我们下载tiktoken来使用GPT开源的分词器 pip install tiktoken
python
tokenizer = tiktoken.get_encoding("gpt2")
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)BPE tokenizer将没见过的单词拆分成子单词或者单个字符,从而解决UNK的问题

5 滑动窗口数据采样
我们训练llm每次生成一个单词,因此我们希望相应地准备训练数据,其中序列中的下一个单词表示要预测的目标:

使用滑动窗口的方式来组织数据,每一段数据的长度都是上下文长度context_length,其中target是input向右偏移一位得到的。输入是input[:i+1]的话,预测值就是target[i]。

于是我们构建一个数据集:
python
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]max_length是上下文长度,stride是滑动窗口的步长,如果max_length==stride,那么滑动窗口之间就没有重叠的文本,如果max_length > stride,那么就存在重叠的文本部分。一篇文章会被拆分为多个max_length那么长的输入,stride决定了这些输入之间是否会有重叠,这些输入片段的预测标签就是其右移1位的片段。
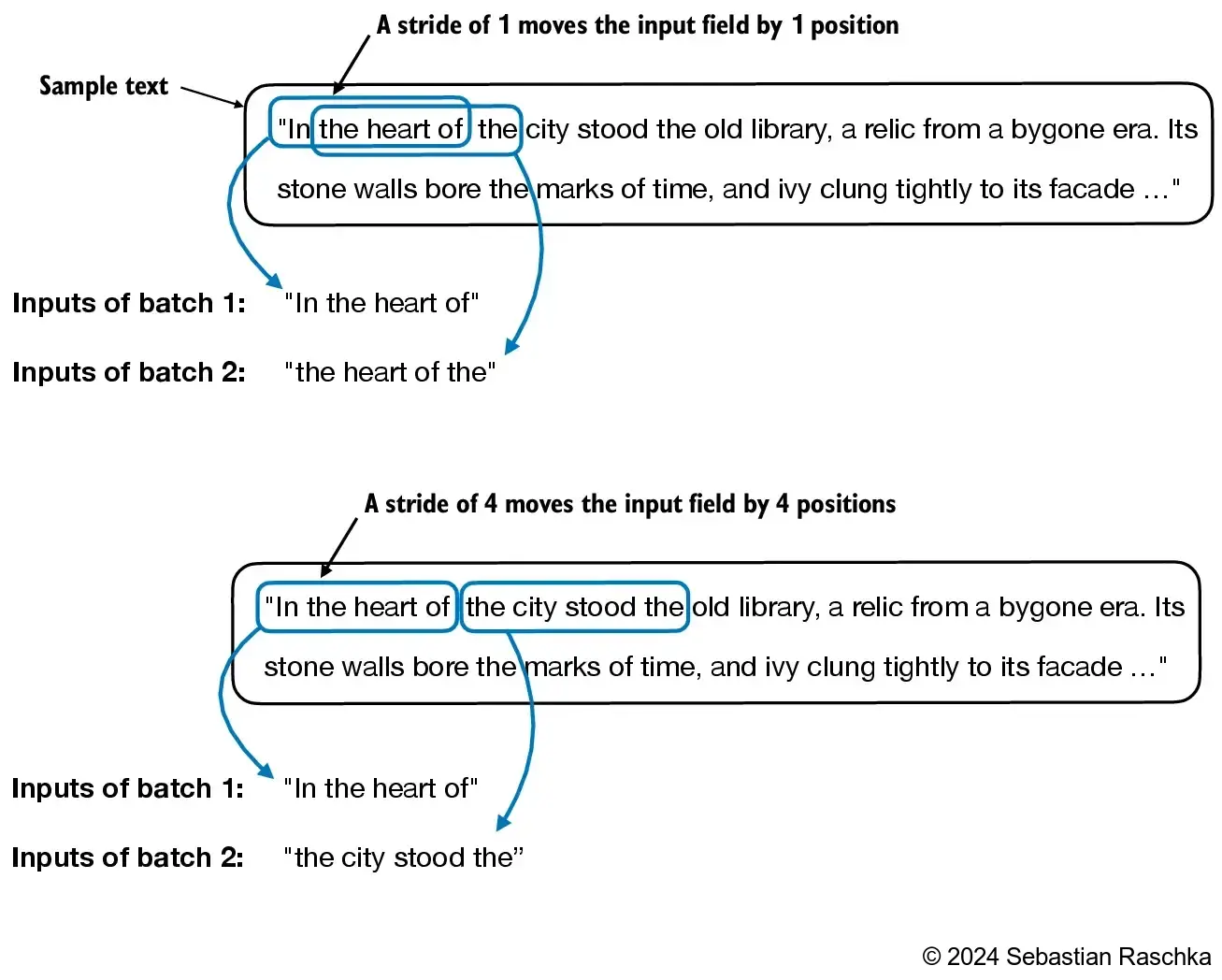
一个没有重叠的输入是这样的:

6 创建token embeddings
现在我们组织完成了输入的数据集,但是我们的输入仍然是token IDs,现在我们需要把这些token IDs转换成embeddings(嵌入),转换为高维的向量表示,并且这些embedding在大模型中也是可训练的参数。
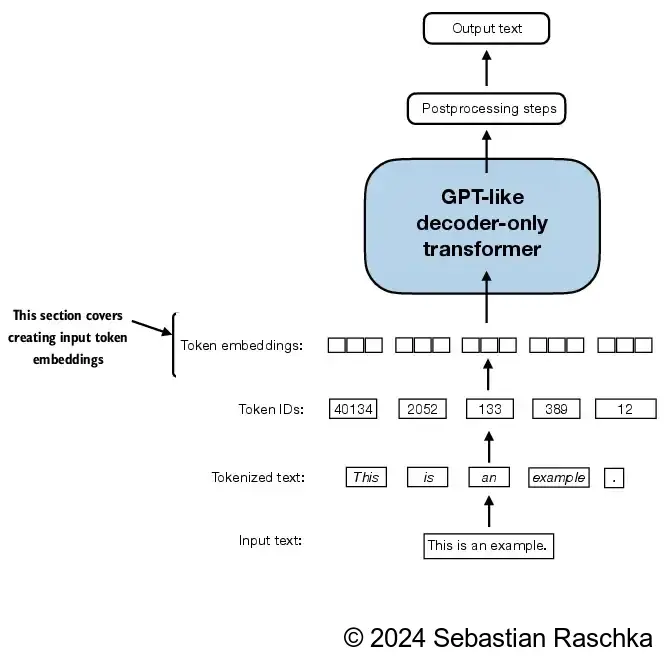
方法很简单,我们有token IDs后,我们就可以创建一个词嵌入矩阵,维度为词汇表大小 * 嵌入维度
之后我们只需要使用token IDs,就可以从这个词嵌入矩阵中取出对应行内保存的向量。本质上还是独热编码,假设我们有一个6*3的矩阵,我们使用0,0,0,1,0,0的矩阵去左乘词嵌入矩阵,就可以取出第4行的内容,OK。
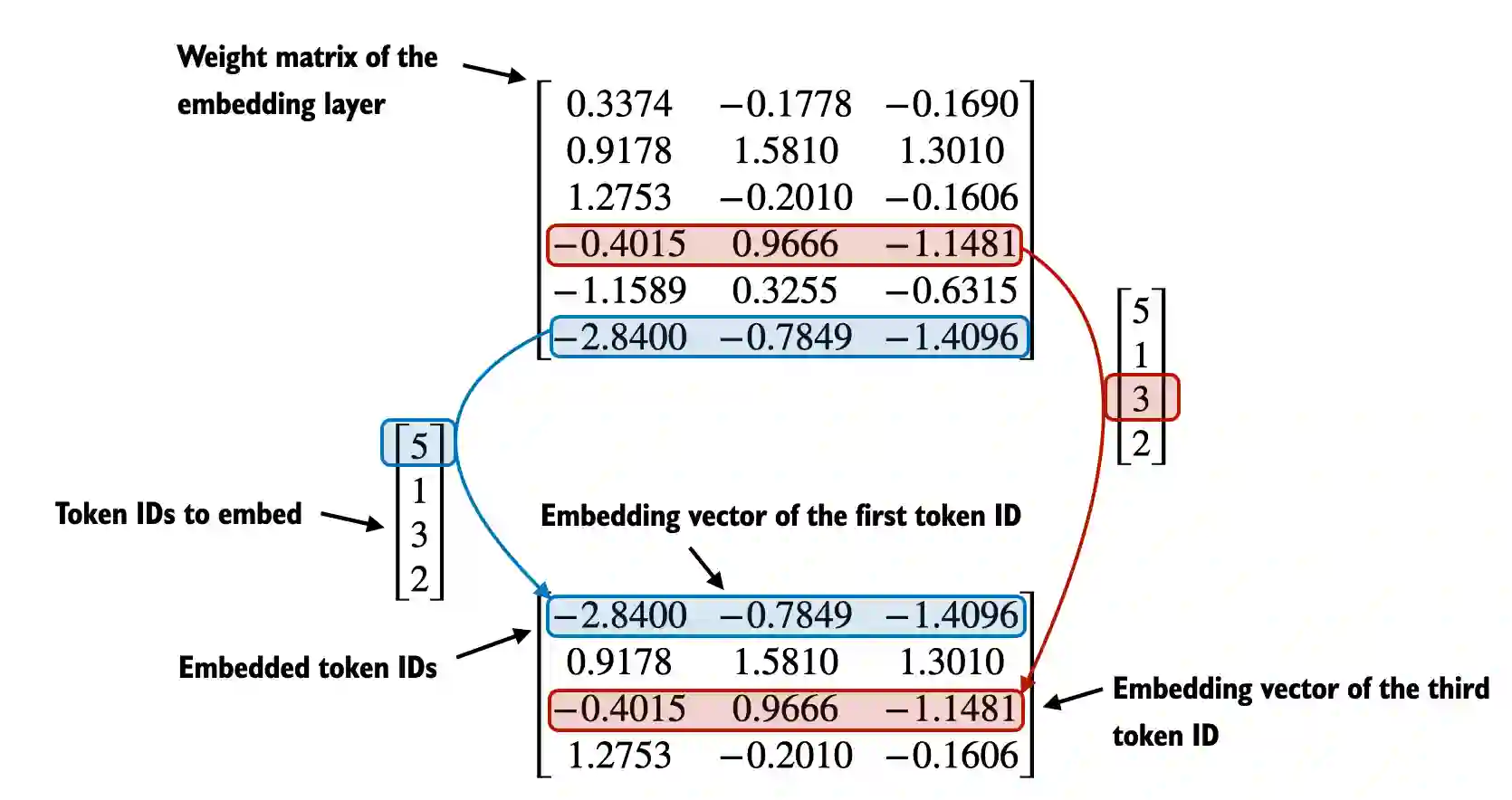
在Python中很容易实现
python
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
print(embedding_layer(torch.tensor([3])))
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)torch.nn.Embedding自动帮我们将3转换为了独热编码,取出了下标为3的向量。
7 加入位置编码
将token转换为词嵌入后,仍然存在一个问题,一个输入中如果有两个相同的token,那么他们的嵌入一致,但是他们的位置并不同,我们还需要加入位置信息。
位置编码和token编码结合作为输入,喂给大模型。
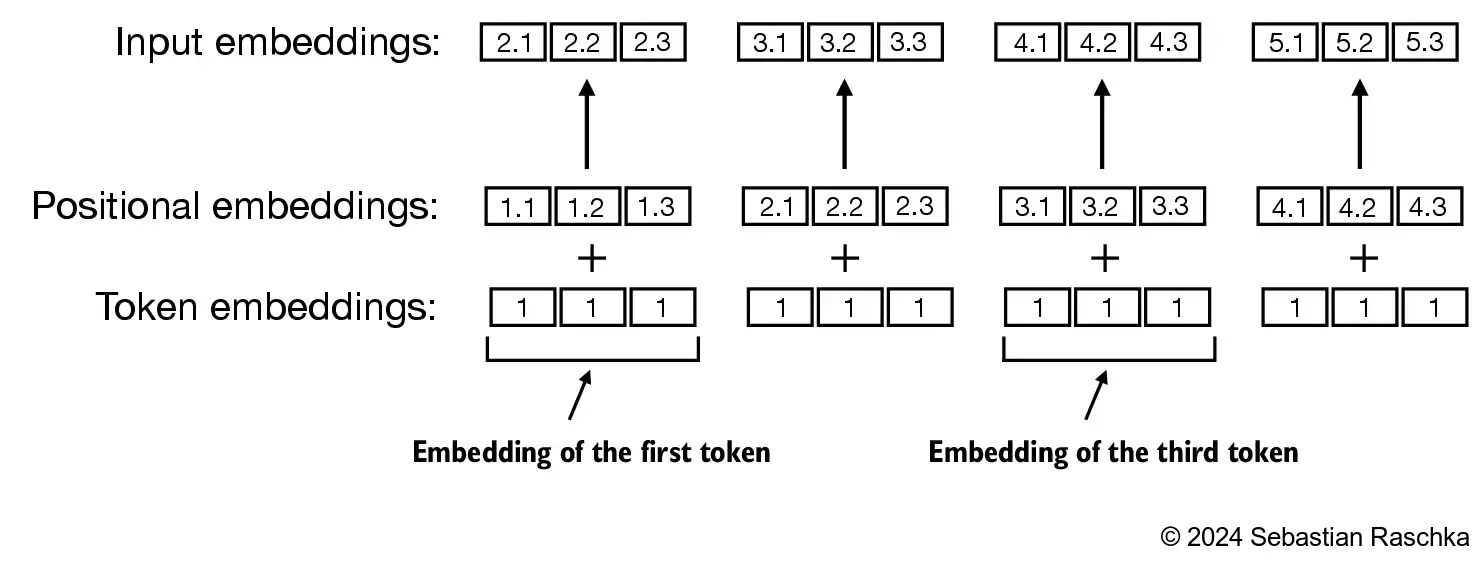
GPT-2使用绝对位置编码,所以我们创建另一个embedding层:
python
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))最后,我们将token embedding简单加上位置embedding后,就得到了LLM的输出
input_embeddings = token_embeddings + pos_embeddings