本文介绍基于Python 语言,针对一个文件夹 下大量的Excel 表格文件,基于其中每一个文件 ,首先依据某一列数据 的特征截取 我们需要的数据,随后对截取出来的数据逐行求差 ,并基于其他多个文件夹 中同样大量的Excel 表格文件,进行数据跨文件合并的具体方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹 ,其中有大量的Excel 表格文件(在本文中我们就以.csv格式的文件为例),且每一个文件 的名称 都表示该文件对应的数据源点的ID;如下图所示。
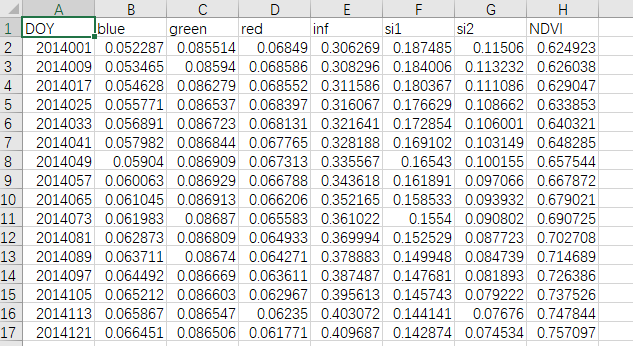
其中,每一个Excel 表格文件都有着如下图所示的数据格式;其中的第1列,是表示天数 的时间数据,每一行数据之间的时间跨度是8天。
我们希望实现的是,首先对于这个文件夹中的每一个文件,都截取出其中天数在2022001(也就是2022年第1天)及之后的部分;随后,对截取出来的数据的各列(除了第1列,因为第1列是表示时间的数据)加以逐行求差------例如,用2022009的数据减去2022001的数据,随后用2022017的数据减去2022009的数据,并将差值作为新的几列放在原有的几列后面;还有,我们还希望从当前文件的文件名、以及第1列的天数中,提取出一些关键信息,作为新的列放在后面(我这里是希望生产一个深度神经网络回归的训练数据,所以就需要组合各类的数据)。此外,我们还有2个文件夹,其中有着同样大量、同样文件命名规则、同样数据格式的数据,我们希望将这2个文件夹中与当前文件夹 中每一个同名的文件 中的同一天的数据合并。
了解了需求,我们就可以开始代码的书写。本文用到的代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Thu May 18 11:36:41 2023
@author: fkxxgis
"""
import os
import numpy as np
import pandas as pd
original_path = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/17_HANTS"
era5_path = "E:/01_Reflectivity/99_Model_Training/00_Data/03_Meteorological_Data/02_AllERA5"
history_path = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/18_AllYearAverage_2"
output_path = "E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/19_2022Data"
era5_files = os.listdir(era5_path)
history_files = os.listdir(history_path)
for file in os.listdir(original_path):
file_path = os.path.join(original_path, file)
if file.endswith(".csv") and os.path.isfile(file_path):
point_id = file[4 : -4]
df = pd.read_csv(file_path)
filter_df = df[df["DOY"] >= 2022001]
filter_df = filter_df.reset_index(drop = True)
filter_df["blue_dif"] = filter_df["blue"].diff()
filter_df["green_dif"] = filter_df["green"].diff()
filter_df["red_dif"] = filter_df["red"].diff()
filter_df["inf_dif"] = filter_df["inf"].diff()
filter_df["si1_dif"] = filter_df["si1"].diff()
filter_df["si2_dif"] = filter_df["si2"].diff()
filter_df["NDVI_dif"] = filter_df["NDVI"].diff()
filter_df["PointType"] = file[4 : 7]
filter_df["days"] = filter_df["DOY"] % 1000
for era5_file in era5_files:
if point_id in era5_file:
era5_df = pd.read_csv(os.path.join(era5_path, era5_file))
rows_num = filter_df.shape[0]
for i in range(rows_num):
day = filter_df.iloc[i, 0]
row_need_index = era5_df.index[era5_df.iloc[ : , 1] == day]
row_need = row_need_index[0]
sola_data_all = era5_df.iloc[row_need - 2 : row_need, 2]
temp_data_all = era5_df.iloc[row_need - 6 : row_need - 2, 3]
prec_data_all = era5_df.iloc[row_need - 5 : row_need - 1, 4]
soil_data_all = era5_df.iloc[row_need - 6 : row_need - 2, 5 : 7 + 1]
sola_data = np.sum(sola_data_all.values)
temp_data = np.sum(temp_data_all.values)
prec_data = np.sum(prec_data_all.values)
soil_data = np.sum(soil_data_all.values)
filter_df.loc[i, "sola"] = sola_data
filter_df.loc[i, "temp"] = temp_data
filter_df.loc[i, "prec"] = prec_data
filter_df.loc[i, "soil"] = soil_data
break
for history_file in history_files:
if point_id in history_file:
history_df = pd.read_csv(os.path.join(history_path, history_file)).iloc[ : , 1 : ]
history_df.columns = ["blue_h", "green_h", "red_h", "inf_h", "si1_h", "si2_h", "ndvi_h"]
break
filter_df_new = pd.concat([filter_df, history_df], axis = 1)
output_file = os.path.join(output_path, file)
filter_df_new.to_csv(output_file, index = False)代码中首先定义了几个文件夹路径,分别是原始数据文件夹(也就是本文开头第1张图所示的文件夹)、ERA5 气象数据文件夹、历史数据文件夹和输出文件夹。然后,通过 os.listdir() 函数获取了ERA5气象数据文件夹和历史数据文件夹中的所有文件名,并在后续的循环中使用。
接下来是一个 for 循环,遍历了原始数据文件夹中的所有.csv文件,如果文件名以 .csv 结尾并且是一个合法的文件,则读取该文件。然后,根据文件名提取了点ID,并使用Pandas 中的 read_csv() 函数读取了该文件的数据。接着,使用Pandas 中的 loc[] 函数对数据进行了处理,包括筛选出DOY大于等于2022001 的行,将其重置索引,并计算了反射率数据的差值。然后,将一些元数据添加到筛选后的数据中,包括点类型和天数。
接下来是两个 for 循环,分别用于处理ERA5 气象数据和历史数据。在处理ERA5 气象数据时,首先找到与当前点ID匹配的ERA5 气象数据文件,并使用Pandas 中的 read_csv() 函数读取了该文件的数据。然后,使用 iloc[] 函数根据当前日期找到了ERA5气象数据中对应的行,并从该行及其前两行中提取了太阳辐射、温度、降水和土壤湿度数据。最后,将这些数据添加到筛选后的数据中。
在处理历史数据时,首先找到与当前点ID匹配的历史数据文件,并使用Pandas 中的 read_csv() 函数读取了该文件的数据。然后,使用 iloc[] 函数删除了第一列,并将剩余列重命名为blue_h、green_h、red_h、inf_h、si1_h、si2_h 和 ndvi_h。最后,使用Pandas 中的 concat() 函数将筛选后的数据和历史数据合并成一个新的DataFrame。
最后,使用Pandas 中的 to_csv() 函数将新的DataFrame保存到输出文件夹中。
运行上述代码,我们即可得到无数个组合后的Excel表格文件,其中每一个文件的列都如下图所示,已经是我们合并了各类信息之后的了。

这样,就完成了我们神经网络训练数据集的生产过程。
至此,大功告成。
文章转载自: 疯狂学习GIS