Opus 4.8 的 Effort Control 怎么选:Low 到 Max 五档策略
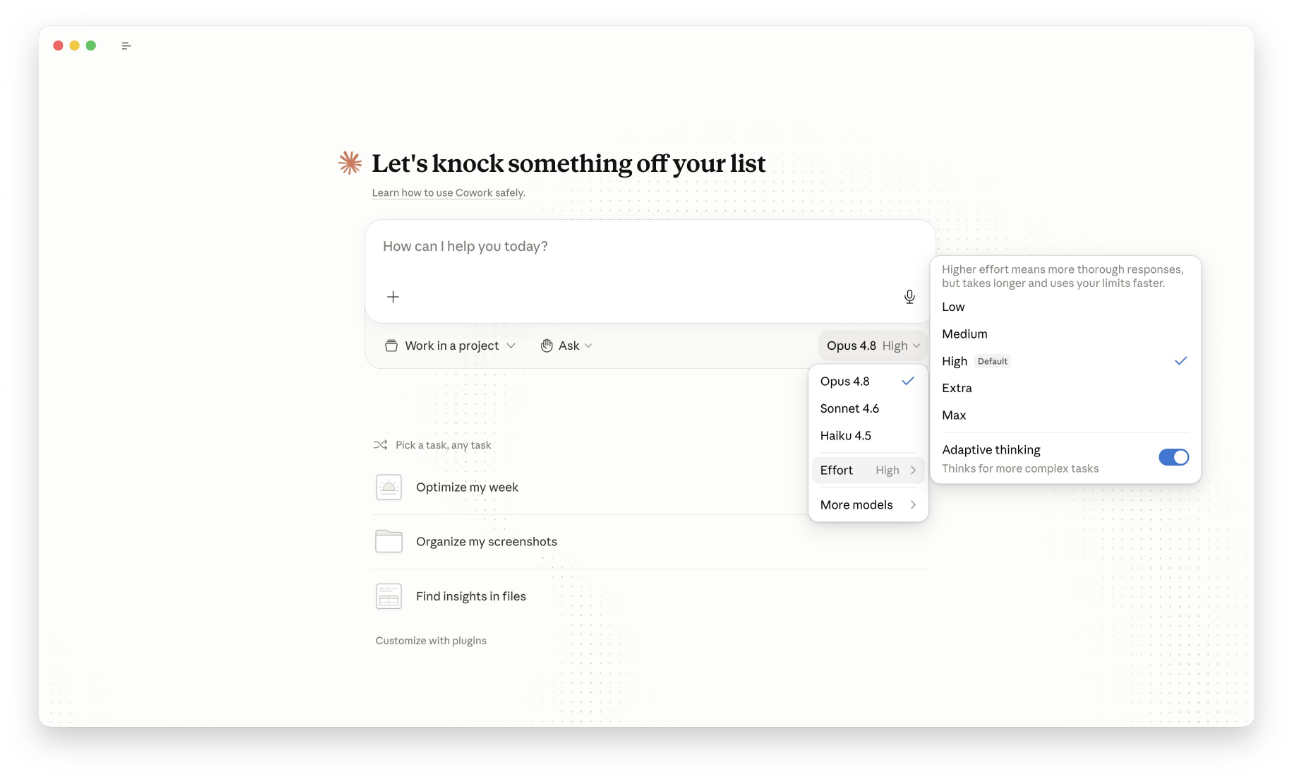
Opus 4.8 上线之后,Anthropic 做了一件比模型本身还更影响日常使用体验的事:把 Effort Control(思考强度)开放给所有用户。
过去只有 Claude Code 和 Cowork 用户比较熟悉这个能力;现在网页版 Chat 里也能直接调,从 Low → Medium → High → xHigh → Max 五档全开放,免费用户也能看到。
问题是:有档位并不等于会用。这篇文章不讲概念,直接讲在不同任务里应该怎么选。
一句话理解 Effort
Effort 不是"回答长短",而是 Claude 愿意花多少推理预算去思考、拆解、检查、回看自己答案。
可以粗暴理解为:
| 档位 | 本质 |
|---|---|
| Low | 快速直答,尽量少想 |
| Medium | 稍微组织结构,但不深挖 |
| High | 默认工程档,会做一定自检 |
| xHigh | 明显更细致,会多轮内部推演 |
| Max | 把能做的都做一遍,优先正确率 |
Effort 越高,通常意味着延迟更高、token 消耗更高、答案更完整、自检更充分,但并不意味着所有场景都值得开 Max。
五档最直接的使用建议
Low:给"错了也没关系"的任务
适合:
- 分类、标签、情感判断
- 简单翻译
- 短摘要
- 常见问答
- 大量批处理里的单步操作
判断标准:如果错了只需要重新来一遍,Low 就够。
Medium:给结构化但不复杂的内容生成
适合:
- 写邮件、写周报
- 整理会议纪要
- 生成大纲
- 改写一段文案
- 从长文里提炼若干要点
Medium 和 Low 的差别不是"更聪明",而是更会组织输出结构。
High:绝大多数开发任务的默认档
适合:
- 写函数、修 bug
- 解释报错
- 做接口设计
- 审文档、审 SQL
- 多文件但范围可控的改动
如果你没有特别理由,High 就是 Opus 4.8 最稳的默认档。
xHigh:给复杂推理与重要改动
适合:
- 跨文件重构
- 长上下文分析
- 多方案权衡
- agent 工具调用链较长的任务
- 要求严格遵守多条约束的输出
xHigh 的意义不是把 Max 平替掉,而是在正确率和成本之间补了一档真正可用的中间位。
Max:给"错一次就很贵"的任务
适合:
- 生产事故排查
- SQL / 配置 / 迁移脚本审查
- 安全敏感改动
- 合同/政策/合规文档分析
- 需要反复自检的长链 agent 任务
判断标准:不是因为任务难,而是因为任务一旦错,代价很高。
按任务类型选档位
| 任务类型 | 推荐 Effort | 原因 |
|---|---|---|
| FAQ / 客服 / 简单问答 | Low | 追求吞吐与速度 |
| 内容改写 / 提纲 / 摘要 | Medium | 需要结构,但不需要深推理 |
| 普通编码 / 调接口 / 改 bug | High | 工程默认档,综合最稳 |
| 架构设计 / 多文件重构 / 长文审查 | xHigh | 需要更强的前后约束一致性 |
| 生产故障 / 安全评估 / 合规审查 | Max | 自检收益最大 |
一个非常实用的判断问题
每次调 effort 前,先问自己:
如果这次回答错了,重新来一遍的成本高不高?
- 低 → Low / Medium
- 中 → High
- 高 → xHigh / Max
很多人一上来就开 Max,本质是在用最贵的方式解决最便宜的问题。
和 Opus 4.8 行为变化一起看,才真正有意义
Opus 4.8 比 4.7 一个很明显的变化是:更精确、更诚实,但主动性更弱。
这意味着 Effort Control 的价值被放大了:
- 旧版 4.7:有时即便 effort 不高,也会凭主观性"多做一些"
- 新版 4.8:你不给足 effort,它真的就只做你要求的那一点
所以 4.8 的正确用法不是"默认 Low 然后看心情",而是:
- 明确任务边界
- 选择足够的 effort
- 把必要约束说清楚
在 Claude API 里怎么用
Anthropic SDK 调用时,effort 通常通过 thinking / effort 相关参数控制(具体字段取决于 SDK 与模型版本)。如果你只是想快速落地,最简单的方式是先在 Claude Code / Chat 里试出合适档位,再复制到产品逻辑里。
Python 示例:
python
from anthropic import Anthropic
client = Anthropic(
api_key="sk-xxx",
base_url="https://gw.claudeapi.com"
)
resp = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
messages=[
{"role": "user", "content": "请审查这段数据库迁移脚本,重点看锁表风险和回滚路径。"}
]
)
print(resp.content[0].text)Node.js:
typescript
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
baseURL: "https://gw.claudeapi.com"
});
const resp = await client.messages.create({
model: "claude-opus-4-8",
max_tokens: 4096,
messages: [
{ role: "user", content: "帮我评估这个改动是否会引起缓存雪崩" }
]
});如果你在自己的产品里做路由策略,建议把模型与 effort 一起路由:
| 任务 | 模型 | Effort |
|---|---|---|
| 批量分类/抽取 | Haiku 4.5 | Low |
| 日常业务问答 | Sonnet 4.6 | Medium / High |
| 常规开发任务 | Sonnet 4.6 / Opus 4.8 | High |
| 长链 agent / 高风险审查 | Opus 4.8 | xHigh / Max |
Claude Code 里的一套实战策略
- 普通需求实现 → High
- 改 5 个文件以上 / 涉及数据库 → xHigh
- 生产 bug / 安全相关 / 发布前 review → Max
升档信号
- Claude 开始遗漏你前面说过的约束
- 需要跨多个文件来回跳
- 有工具调用,而且要结合日志/数据库/API 结果一起判断
- 你已经问了第二遍,它还在答非所问
降档信号
- 任务只是改个 copy / 小函数 / 文案
- 你更在乎响应速度而不是边角正确率
- 你在批量做几十上百个相似任务
不要把 Effort 当作万能补丁
Effort 再高,也不能替代以下三件事:
- 清晰的任务描述
- 正确的工具与上下文
- 必要时的人类确认
尤其在 Opus 4.8 这一代,模型更少越界揣测,所以"描述不清靠它自己悟"会越来越难走。
写在最后
如果你只记一条规则,记这个:
High 是默认档,xHigh 是复杂档,Max 是高代价容错档。
Low 和 Medium 不是没用,而是适合那类"快比完美更重要"的任务。真正的问题从来不是哪个档最强,而是你有没有把昂贵推理预算用在值得的地方。
如果你的项目已经用 Anthropic SDK 接入,把 base_url 设为 https://gw.claudeapi.com 即可沿用现有方式;后续再按任务路由不同模型与 effort 档位。
参考:Anthropic Opus 4.8 发布说明、Effort Control 公开介绍、Claude Code 实际使用经验。