1. redis为什么这么快
- 数据存内存,读写速度快。
- 有高效的数据结构,操作便捷。
- 单线程模型,避免多线程竞争和上下文切换开销。
- 采用非阻塞I/O,和I/O多路复用,可同时处理多个连接:linux上用epoll,其他系统上可能用select或poll,看操作系统支持。
- 持久化机制在保证数据安全同时尽量减少对性能影响。
2. redis为什么用单线程?后来为啥用多线程?
redis的"网络请求+kv处理"一直是单线程,因为redis的瓶颈在内存而不是CPU,用多线程帮不了忙,还需要处理线程同步的问题,用单线程的话,还不用考虑上下文切换的性能开销。
随着互联网业务发展,用户多了,"网络请求"也多了,redis在"网络请求"方面快不行了,所以它让"网络请求"可以在多线程里跑了。
3. redis持久化机制有哪些
3.1. RDB
- 即快照模式,存储redis的压缩数据,体量比较小。
- 定时持久化到硬盘,有两种持久化模式:
- 【默认】异步持久化,启动一个子进程去持久化。
- 同步持久化,会阻塞redis主线程。
- 因为是定时的持久化,所以会存在数据丢失问题,比如还没来得及持久化,redis就挂了。
- 用RDB持久化的文件来重启redis比AOF快。
3.2. AOF
- 存储的日志就是命令本身的文本,日志体量较大。
- AOF是命令执行完后记日志(与mysql不一样,执行前记日志),所以也会存在数据丢失问题,比如命令执行了还没来得及持久化,redis就挂了。为啥要执行完后再记日志?为了执行命令快。等不急了,先斩后奏。
3.2.1. AOF有3种持久化频率可以设置
正常write系统调用写硬盘,只会写入到内核缓冲区,调用fsync才会写到硬盘上。
- 1次缓存变动fsync持久化1次:是同步的,主线程write后,后台线程马上fsync到硬盘,这种模式较慢。
- 1秒fsync持久化1次:是异步的,主线程write后,后台线程每隔1秒fsync到硬盘,这种模式很快,但可能丢失1秒数据。
- 不fsync(等操作系统30秒自动写到硬盘):也相当于是异步的了,write后就可以执行下一个命令,写硬盘是操作系统自己去调度,所以可能丢失30秒的数据。
3.2.2. AOF的文件重写
当AOF文件很大之后,会在一个子进程里进行rewrite,相当于做了压缩,rewrite的同时会正常write,这样会产生两个文件:rewrite的压缩小文件和正常write的文件,当rewrite完成后,就把正常write的文件覆盖,新的日志写入到rewrite完后的文件中。
3.3. 选哪个?
- 容忍几分钟的数据丢失,可以只选RDB
- 如果要用AOF,建议同时开启RDB,隔一段时间快照一下
默认开启了RDB
4. redis线程模型
redis的线程模型可以概括为1个主线程+3个后台线程。
- redis4之前是单线程:网络请求+kv操作都在主线程里。
- redis4后加了3个后台线程处理异步持久化、释放大对象、关闭文件。
- redis6后网络请求有专门的线程处理,kv操作在主线程里。
下图是6以后未开启(默认就是未开启的)多线程的线程模型(蓝色的框代表一个线程):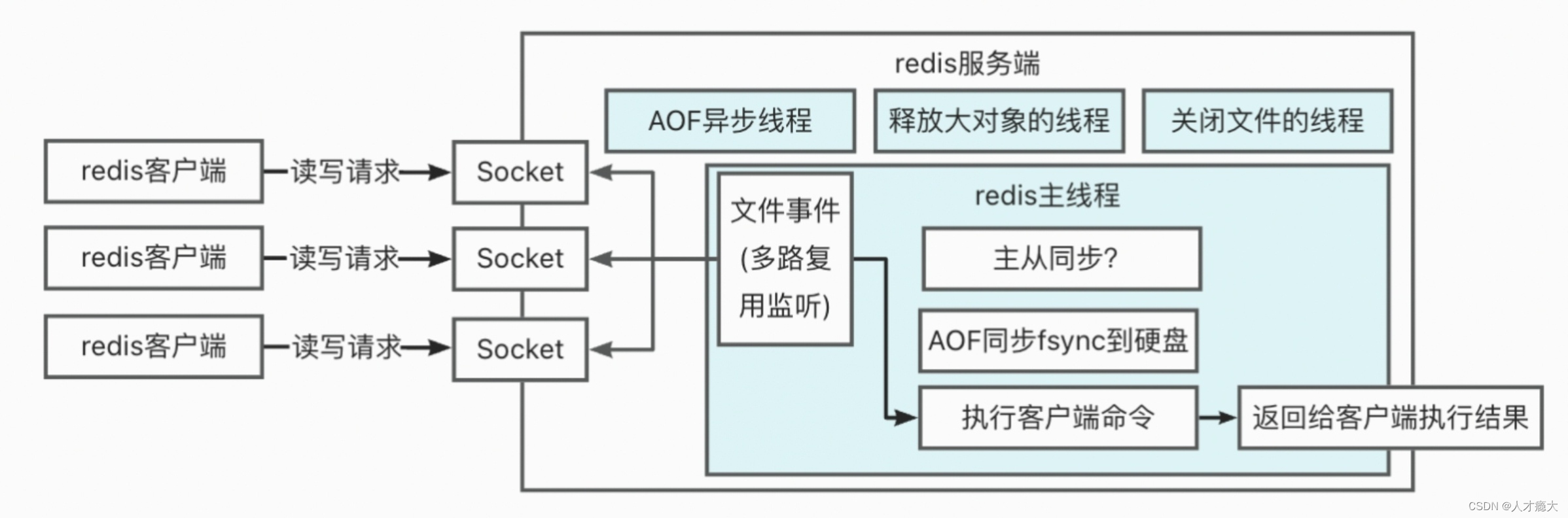
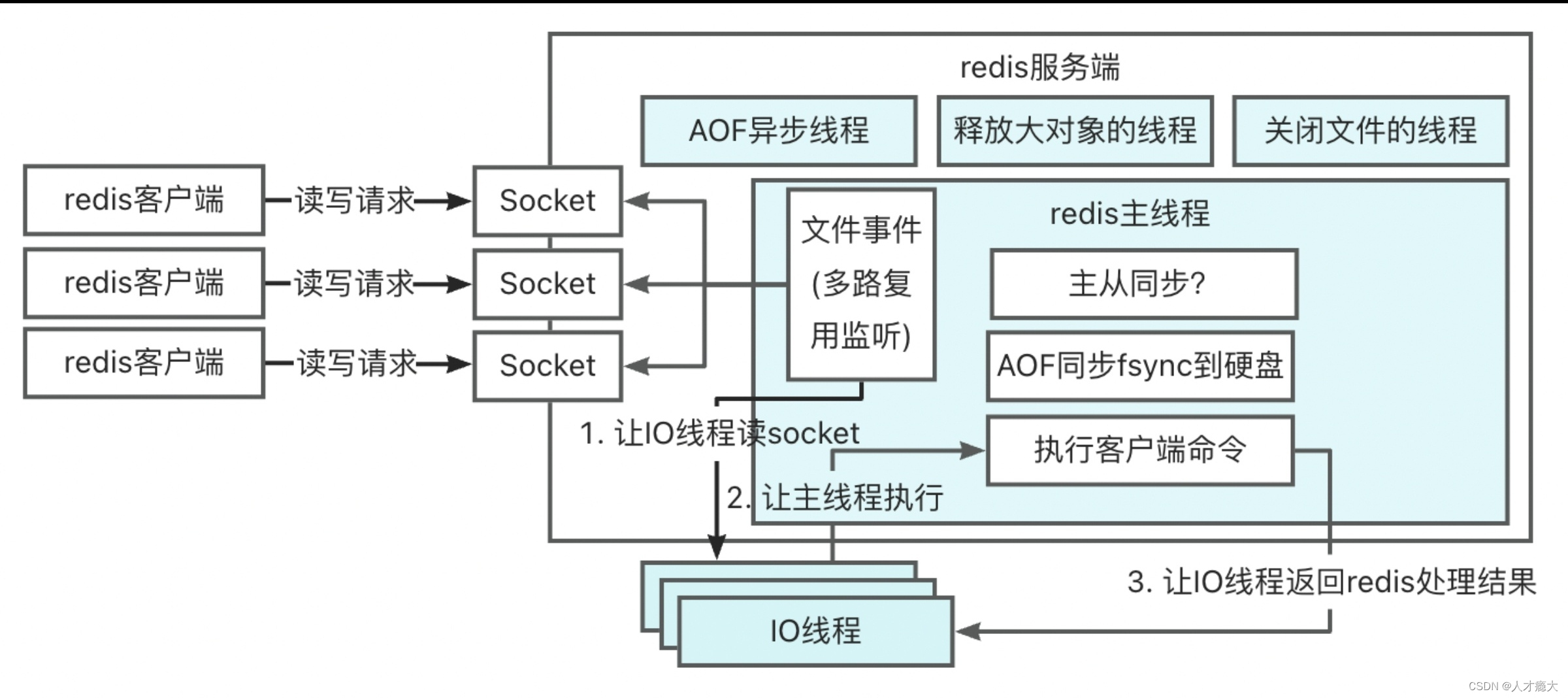
下图是6以后开启多线程的线程模型(蓝色的框代表一个线程):
4.1. 主线程
一般说redis是单线程,是指它的网络请求和key-value的操作是单线程,即都在主线程里执行。
4.2. 后台线程
4.2.1. AOF异步线程
将AOF写入到内核缓冲区后,还未写入硬盘的数据,用fsync写入到硬盘。
4.2.2. 释放大对象的线程
redis4可以用unlink来异步删除缓存的大对象。
4.2.3. 关闭文件的线程
释放AOF/RDB过程中的临时文件。
4.3. IO线程
这是redis6以后加的,帮助环节网络IO太多搞不过来的问题,因为单线程模型可以支持10w QPS,所以默认不开启,除非你的业务请求量很大。
5. redis过期策略和缓存淘汰策略
- "过期"是指key失效,跟内存大小没关系;
- "淘汰"是在内存满的时候才会触发。
5.1. 过期策略
过期策略都是去检查key是否过期,如果是,则清除。
检查key有没有过期的时机有两种:定时检查、访问key的时候检查。
所以有两种过期策略:定期删除和惰性删除,redis是这两种一起用的,因为一个对内存好、一个对CPU好,一起用,就对内存和CPU都好了。
5.1.1. 定期删除
一般是1秒扫描10次,进行删除,每次删除耗时控制在25ms内,随机选择一些过期key进行删除。
每轮扫描删除的停止条件有两个:
- 超过25ms就停止删除了,因为这个删除过程是在主线程里的,删太久就阻塞主线程了。
- 如果过期key只有10%了,就不删了,因为太少了,为这点数据执行一次删除动作不划算。
这种策略需要消耗CPU较多,但可以释放大量内存。
5.1.2. 惰性删除
访问key的时候检查key是否过期,过期就删除它。
这种策略消耗CPU较少,但可能导致内存里有大量过期没删除的key。
5.2. 淘汰策略

- LRU:最近最少用,即没被使用的时间最长的。
- LFU:最近不经常用,即最近访问频率最低的。
- TTL:将要过期的。
6. redis中删除一个大缓存对象会有什么问题
redis的工作线程是单线程的,删除一个大的缓存时耗时会比较久,其他客户端请求可能会被阻塞,导致响应延迟增加。
解决办法有两个:
- 分批删除:将大对象拆分成较小的部分,分批次删除。例如,如果是一个大的哈希表,可以每次删除一部分键值对,而不是一次性删除整个哈希表。
- 异步删除:redis4可以用unlink来异步删除大缓存。
7. redis和memcached的区别
7.1. 相同
- 都是内存数据库
- 都是高性能
- 都有过期策略
7.2. 区别
- 数据类型:redis支持多种类型;memcached只支持简单k/v
- 持久化:redis支持持久化到硬盘;memcached只能内存
- 编程语言:redis支持的编程语言更多
- 过期数据删除:redis支持惰性删除和定期删除;memcached只支持惰性删除
- 特性:redis支持lua脚本、事务;memcached不支持
8. redis集群机制
完整的一个集群如下图所示(示例了3个节点):
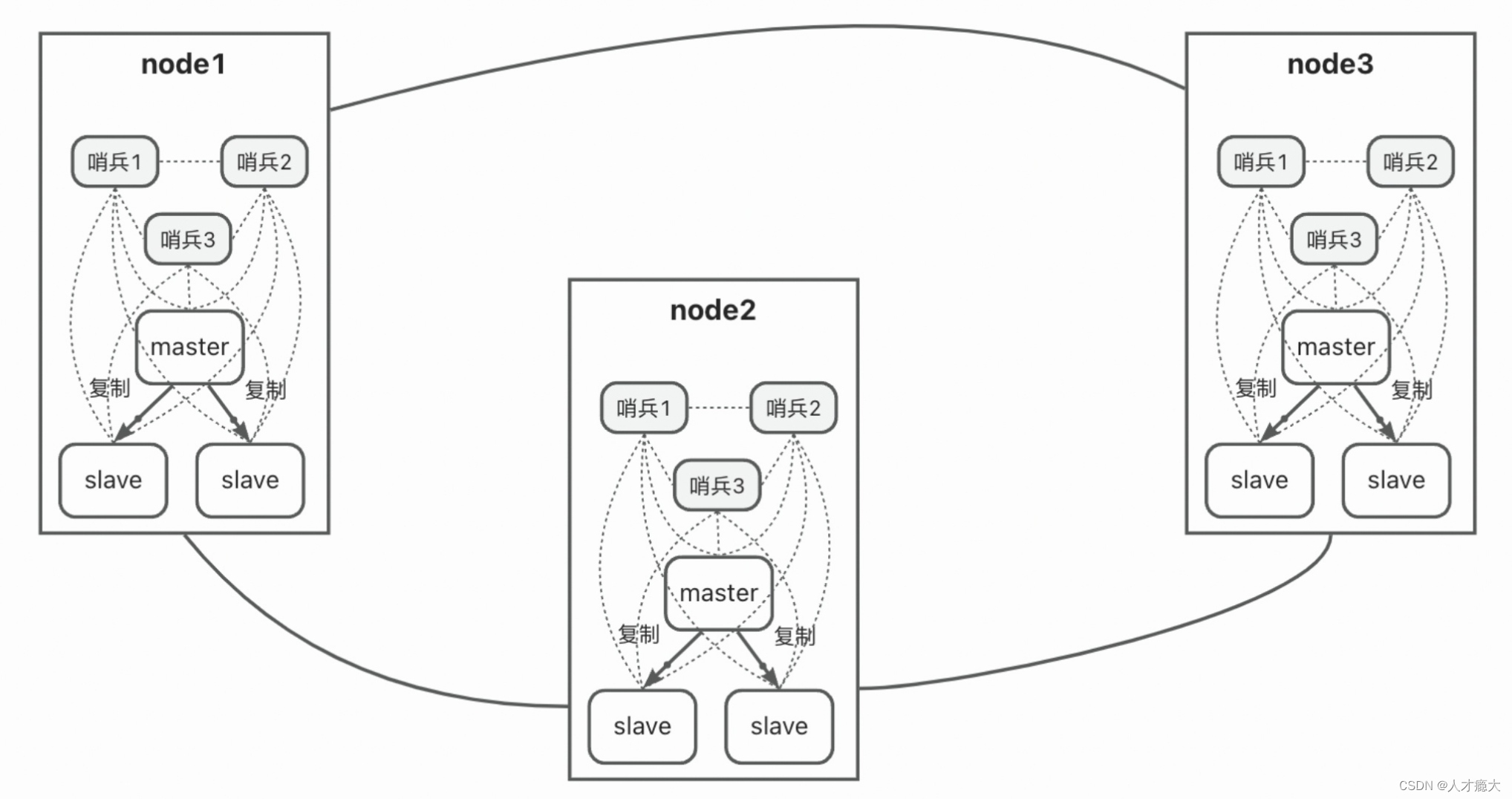
- 多个节点组成一个redis集群。
- 一个节点由3种角色组成:哨兵、master和slave,这种其实就是redis的主从结构。
8.1. 哈希槽算法
redis集群用的哈希槽算法,总共16384个槽(0~16383),集群中每个节点维护平均分配槽,比如上图所示有3个节点,可能分配的槽分别是:node1是0-5460,node2是5461-10922,node3是10923-16383。
key的哈希值按CRC16规则运算,然后跟16384取余,就算出具体的槽位,然后看这个槽在哪个节点上(比如槽6666就在node2上)。
8.2. redis的主从结构
由哨兵、master和slave组成,master和slave其实就是做读写分离。
- 哨兵只负责监视:是一种运行在特殊模式下的redis服务器,它启动的时候不会用AOF或RDB初始化。它监视master和slave,如果master挂了,它们会从slave中选一个出来做master。另外他们也会互相监视。
- master:负责缓存的写。
- slave:负责缓存的读。
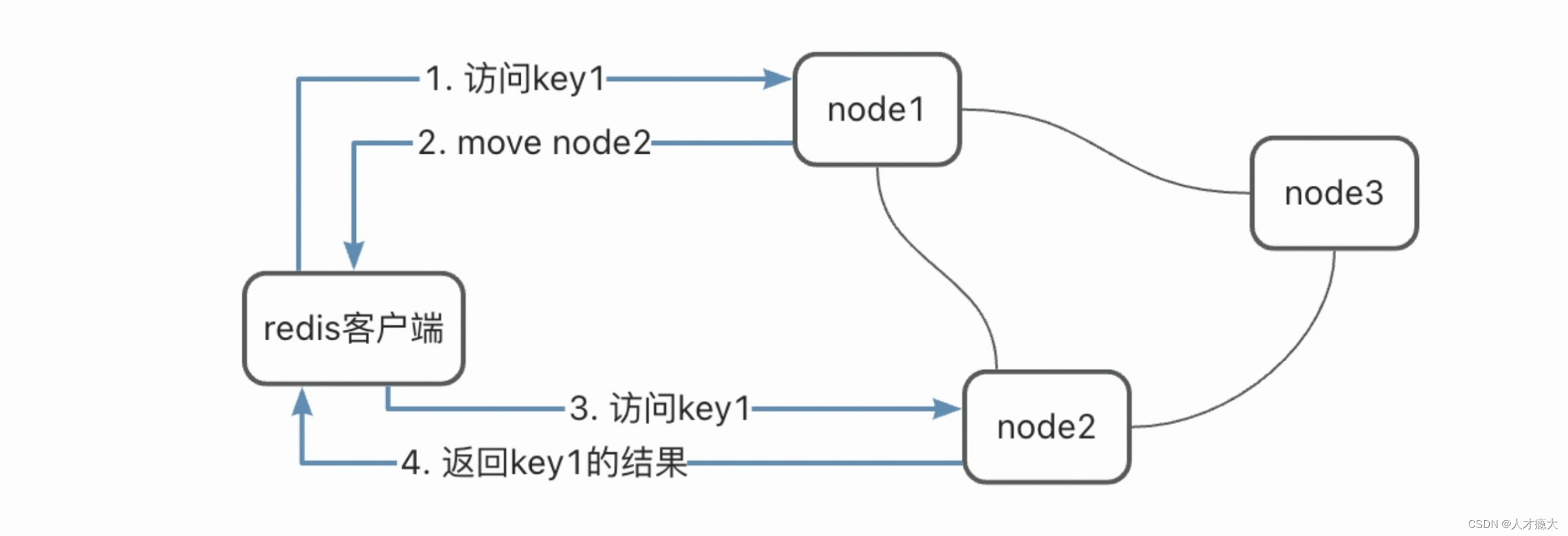
8.3. 客户端访问某个key的过程
redis集群是去中心化的,所以客户端访问的时候可能访问到任何一个节点。比如要取key1,访问到node1,node1就会根据key1来计算它所在的槽,进而找到其所在的节点,比如所在节点是node2,node1就会发一个move命令客户端,让客户端去node2取它要的key1,交互流程如下图所示: