文章目录
-
- 前言
- 数据预处理------sklearn.preprocessing
- [numpy 相关用法](#numpy 相关用法)
-
- [跳过 nan 值的方法------nansum和nanmean](#跳过 nan 值的方法——nansum和nanmean)
- 展开多维数组(变成类似list列表的形状)
- 重复一个数组------np.tile
- 分组聚集------pandas.DataFrame.groupby()
- 表格合并------pandas.merge()
- [数据库关系型表格 → 二维表------pandas.DataFrame.pivot()](#数据库关系型表格 → 二维表——pandas.DataFrame.pivot())
- 序列极值的获取------scipy.signal.argrelextrema
前言
使用 Python 进行数学建模时,需要进行各种各样的数据预处理。因此熟练掌握 Python 的一些库可以帮助我们更好的进行数学建模。
数据预处理------sklearn.preprocessing
数据标准化
数据标准化的目的是,通过线性缩放,使得一组数据的均值变成 0 0 0,方差变成 1 1 1。使用scale方法:
py
from sklearn import preprocessing
import numpy as np
data = np.array([[1.,1.,4.,5.],
[1.,4.,1.,9.],
[1.,9.,8.,1.]])
# 默认按列标准化(axis = 0),如需按行标准化需要指定 axis = 1
print(preprocessing.scale(data))
# 结果如下,原本方差为 0 的数据,标准化后方差仍然是 0(因为无法变成1)
#[[ 0. -1.1111678 -0.11624764 0. ]
# [ 0. -0.20203051 -1.16247639 1.22474487]
# [ 0. 1.31319831 1.27872403 -1.22474487]] 我们知道标准化的实质是减去均值、除以标准差。StandarScalar可以用一组数据的均值、方差去标准化另一组数据。比如:
py
from sklearn import preprocessing
import numpy as np
data = np.array([[1.,1.,4.,5.],
[1.,4.,1.,9.],
[1.,9.,8.,1.]])
scaler = preprocessing.StandardScaler().fit(data)
new_data = np.array([[9.,2.,3.,4.]])
# 用 data 的均值、标准差去标准化 new_data
print(scaler.transform(new_data))
# 结果为 [[ 8. -0.80812204 -0.46499055 -0.30618622]]数据归一化
数据归一化指的是,通过线性缩放,使得一组数据的最小值为 0 0 0,最大值为 1 1 1。**实质是全体减去最小值,然后除以减法过后的最大值。**可以使用MinMaxScaler类:
py
from sklearn import preprocessing
import numpy as np
data = np.array([[1.,1.,4.,5.],
[1.,4.,1.,9.],
[1.,9.,8.,1.]])
# 创建 scaler
scaler = preprocessing.MinMaxScaler()
print(scaler.fit_transform(data))
# 结果是
#[[0. 0. 0.42857143 0.5 ]
# [0. 0.375 0. 1. ]
# [0. 1. 1. 0. ]]
# 同样可以用 data 的缩放方式来归一化 new_data
new_data = np.array([[1,0,3,7]])
print(scaler.transform(new_data))
# 结果为 [[ 0. -0.125 0.28571429 0.75 ]]另一种数据预处理
还有一种数据预处理是,对初始数据 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,\cdots,x_n\} {x1,x2,⋯,xn} 都除以 max 1 ≤ i ≤ n ∣ x i ∣ \max\limits_{1\leq i\leq n}|x_i| 1≤i≤nmax∣xi∣,使得所有数据都落在 − 1 , 1 -1,1 −1,1 范围内。MaxAbsScaler类可以完成这种预处理,其用法和前面的MinMaxScaler类似。这个方法对那些已经中心化均值为 0 0 0 或者稀疏的数据有意义。
数据二值化
数据二值化设置一个阈值threshold,小于等于它的变成 0 0 0,大于它的变成 1 1 1。
py
from sklearn import preprocessing
import numpy as np
data = np.array([[1.,1.,4.,5.],
[1.,4.,1.,9.],
[1.,9.,8.,1.]])
# Binarizer 无参数默认 threshold = 0
print(preprocessing.Binarizer(threshold = 1).transform(data))
# 结果为
#[[0. 0. 1. 1.]
# [0. 1. 0. 1.]
# [0. 1. 1. 0.]]参考文献:预处理数据的方法总结(使用sklearn-preprocessing)_from sklearn import preprocessing-CSDN博客
异常值处理
四分位法清除异常值:首先计算出序列的第一四分位数、第三四分位数 Q 1 , Q 3 Q_1,Q_3 Q1,Q3,然后计算四分位数间距 I Q R = Q 3 − Q 1 \mathit{IQR}=Q_3-Q_1 IQR=Q3−Q1。认为可接受的数据范围是 Q 1 − 1.5 I Q R , Q 3 + 1.5 I Q R {{Q}_{1}}-1.5\\mathit{IQR},{{Q}_{3}}+1.5\\mathit{IQR} Q1−1.5IQR,Q3+1.5IQR。如下图:

图源来自图片水印所示博客。
py
import pandas as pd
# 直接把数据从这里输入进来
data = pd.Series([1,1,4,5,1,4,1,9,1,9,8,1,0])
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
# 根据条件筛选和删除异常值,输出的 data 就是处理后的结果
data = data[~((data < (Q1 - 1.5 * IQR)) | (data > (Q3 + 1.5 * IQR)))]numpy 相关用法
跳过 nan 值的方法------nansum和nanmean
py
import numpy as np
arr = np.array([1, 2, 3, 4, np.nan])
print(arr.sum(),arr.mean()) # nan nan
print(np.nansum(arr),np.nanmean(arr)) # 10.0 2.5,相当于删除所有 nan 值再操作展开多维数组(变成类似list列表的形状)
py
import numpy as np
arr = np.array(range(16)).reshape(4,-1)
print(arr)
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
"""
# 下面三种方法任选其一即可
print(arr.ravel())
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
print(arr.flatten())
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
print(arr.reshape(-1))
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]重复一个数组------np.tile
py
import numpy as np
# 只描述对于 2 维数组的情况,其他详情见参考文献
data = np.array([[1,1,4],[5,1,4]])
# 只传一个参数 x,那么行方向重复 x 次
print(np.tile(data,3))
"""
[[1 1 4 1 1 4 1 1 4]
[5 1 4 5 1 4 5 1 4]]
"""
# 传一个含有两个参数的元组 (x,y),那么列方向重复 x 次,行方向重复 y 次
print(np.tile(data,(2,4)))
"""
[[1 1 4 1 1 4 1 1 4 1 1 4]
[5 1 4 5 1 4 5 1 4 5 1 4]
[1 1 4 1 1 4 1 1 4 1 1 4]
[5 1 4 5 1 4 5 1 4 5 1 4]]
"""参考文献:numpy.tile()_np.tile-CSDN博客
分组聚集------pandas.DataFrame.groupby()
对于一个表格进行类似 MySQL 聚集函数的处理,该方法的参数及默认值:
py
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False,
observed=False, dropna=True) 如何使用
直接使用聚集函数
方法得到的是一个对象,对于该对象可以使用聚集函数。比如下面的例子:
py
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
'C': ['X', 'X', 'Y', 'Y']
})
# 聚集函数------均值mean(),还可以是最大值max(),最小值min(),
# 求和sum(),求积prod(),计数count(),标准差std(),各种统计数据describe()等。
print(df.groupby('C').mean()) # 即参数 by = 'C'
# 结果如下所示
# A B
# C
# X 1.5 5.5
# Y 3.5 7.5
print(df.groupby('C').rank())
# 结果如下所示
# A B
# 0 1.0 1.0
# 1 2.0 2.0
# 2 1.0 1.0
# 3 2.0 2.0Agg
agg 在基于相同的分组情况下,可以对不同列分别使用不同的聚集函数,如:
py
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': [5, 6, 7, 8],
'C': ['X', 'X', 'Y', 'Y']
})
# 对 'A' 列分组求最小值,对 'B' 列分组求最大值
print(df.groupby('C').agg({'A':'min','B':'max'}))
# 结果如下所示
# A B
# C
# X 1 6
# Y 3 8 也可以传入自定义函数,比如上面的'B':'max'也可以等价地改为'B':lambda x : max(x),其中参数x是由 agg 分组形成的元组。
直接解析分组结果
有时候希望根据分组结果,一组显示一张表格。直接打印 groupby 后的对象是不行的:
py
import pandas as pd
df = pd.DataFrame({
'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],
'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],
'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],
'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})
print(df.groupby('category'))
# 结果只是类名 + 内存地址
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000025D2D49B6D8> 但是我们可以按照下面的方式遍历,其中循环变量name为str类型,group为DataFrame类型:
py
import pandas as pd
df = pd.DataFrame({
'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],
'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],
'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],
'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})
result = df.groupby('category')
for name, group in result:
print(f'group name: {name}')
print('-' * 30)
print(group)
print('=' * 30, '\n')
"""
group name: 水果
------------------------------
name category price count
0 香蕉 水果 3.5 2
6 柑橘 水果 3.2 5
7 苹果 水果 8.0 3
==============================
group name: 米面
------------------------------
name category price count
2 糯米 米面 2.8 3
3 糙米 米面 9.0 6
==============================
group name: 粮油
------------------------------
name category price count
8 橄榄油 粮油 18.0 2
==============================
group name: 蔬菜
------------------------------
name category price count
1 菠菜 蔬菜 6.0 1
4 丝瓜 蔬菜 3.0 4
5 冬瓜 蔬菜 2.5 8
==============================
"""参数说明------by
上面使用都是by = 'C'等传入某一个属性列的方式。
传入属性列列表
如果要按照多个属性列 分组,可以传入属性列列表如下所示:
py
import pandas as pd
df = pd.DataFrame({
'x':[1,1,1,1,2,2,2,2],
'y':[3,3,4,4,3,3,4,4],
'value':[1,1,4,5,1,4,1,9]
})
# 按照 (x,y) 分组并求取最大值
print(df.groupby(['x','y']).max())
"""
结果是:
value
x y
1 3 1
4 5
2 3 4
4 9
""" groupby 接收多个属性,会将这些属性全部变成索引。之后可以接上reset_index操作,传入参数level,可以将第level列索引变成属性。
传入字典 dict
要求字典是int到str的映射。这种情况下,将不会按照df中原有的列进行分组,而是根据字典的内容,将原来df中的某一行映射到字典对应的类中。例如:
py
import pandas as pd
df = pd.DataFrame({
'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],
'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],
'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],
'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})
# 下面这 5 行是为了自动化地得到字典:
# {0: '蔬菜水果', 1: '蔬菜水果', 2: '米面粮油', 3: '米面粮油', 4: '蔬菜水果',
# 5: '蔬菜水果', 6: '蔬菜水果', 7: '蔬菜水果', 8: '米面粮油'}
category_dict = {'水果': '蔬菜水果', '蔬菜': '蔬菜水果', '米面': '米面粮油', '粮油': '米面粮油'}
the_map = {}
for i in range(len(df.index)):
the_map[i] = category_dict[df.iloc[i]['category']]
grouped = df.groupby(the_map)
# 按照 the_map 进行分组,那么原 df 中第 0,1,4,5,6,7 行被归为"蔬菜水果",
# 第 2,3,8 行被归为"米面粮油"
result = df.groupby(the_map)
# 按照不同类别进行打印
for name, group in result:
print(f'group name: {name}')
print('-' * 30)
print(group)
print('=' * 30, '\n')
"""
结果为:
group name: 米面粮油
------------------------------
name category price count
2 糯米 米面 2.8 3
3 糙米 米面 9.0 6
8 橄榄油 粮油 18.0 2
==============================
group name: 蔬菜水果
------------------------------
name category price count
0 香蕉 水果 3.5 2
1 菠菜 蔬菜 6.0 1
4 丝瓜 蔬菜 3.0 4
5 冬瓜 蔬菜 2.5 8
6 柑橘 水果 3.2 5
7 苹果 水果 8.0 3
==============================
"""参考文献:深入理解 Pandas 中的 groupby 函数_observed=false-CSDN博客
表格合并------pandas.merge()
这个merge和 MySQL 的 join 是有几分相似的。该方法的参数和默认值:
py
DataFrame.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)- 其中
how还可以是left,right,outer,对应 MySQL 中的左、右、外连接;MySQL 中连接产生的 null 在 Python 中变成 nan。 on可以指定链接的时候参照那些属性列。默认情况下on = None,即自然连接。- (不常用)
indicator参数在最终合并形成的表格中加入一个_merge列,值域为{left_only,both,right_only},描述每一条结果是如何连接形成的。例子如下:
py
import pandas as pd
df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
print(pd.merge(df1, df2, on='col1', how='outer', indicator=True))
"""
结果如下所示:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
"""参考文献:【python】详解pandas库的pd.merge函数-CSDN博客
数据库关系型表格 → 二维表------pandas.DataFrame.pivot()
标题的意思是这样的:已有一个关系型数据库,可以指定两个索引(行索引、列索引)以及对应的值索引,转化为一个二维表格。如下图所示。
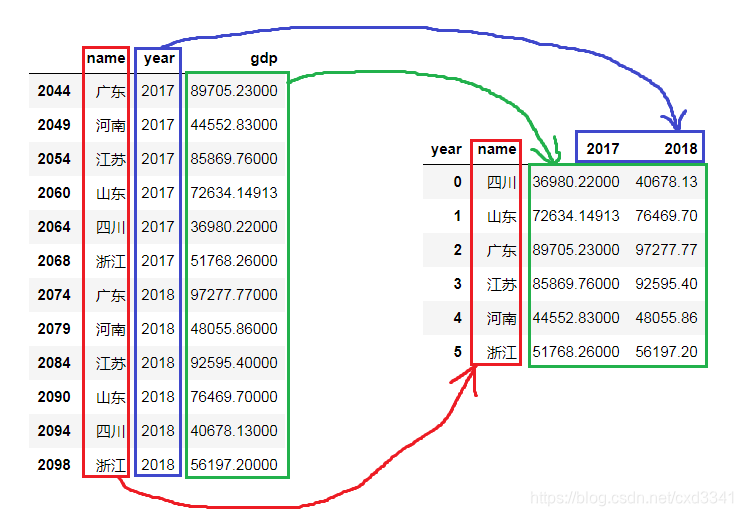
如果图片左边的 DataFrame 是变量 data,通过下面的语句实现到右边表格的转换:
py
data.pivot('name','year','gdp') 函数原型是:
py
DataFrame.pivot(index=None, columns=None, values=None) 右边二维表行列索引的生成机制是 index 和 columns 的笛卡尔积。笛卡尔积集合中可能有不存在的 (index, columns) 组合,经过pivot处理变成 nan,如:
py
import pandas as pd
data = pd.DataFrame({
'name':['原神','原神','星铁','星铁','星铁'],
'year':[2022,2023,2022,2023,2024],
'income':[11,21,31,41,51]
})
print(data,'\n','-' * 24)
print(data.pivot('name','year','income'))
"""
name year income
0 原神 2022 11
1 原神 2023 21
2 星铁 2022 31
3 星铁 2023 41
4 星铁 2024 51
------------------------
year 2022 2023 2024
name
原神 11.0 21.0 NaN
星铁 31.0 41.0 51.0
"""不能存在相同的 (index, columns) 组合:
py
import pandas as pd
data = pd.DataFrame({
'name':['原神','原神'],
'year':[2022,2022],
'income':[11,21]
})
print(data.pivot('name','year','income'))
# ValueError: Index contains duplicate entries, cannot reshape参考文献:Python dataframe.pivot()用法解析_dataframe pivot-CSDN博客
序列极值的获取------scipy.signal.argrelextrema
已知一个序列,可以用这个库方便地求极大值 和极小值。代码示例如下:
py
from scipy.signal import argrelextrema
import numpy as np
# y 是待求序列
y = np.array([1,9,6,8,2,5,8,3,2,7,3,2,7,5])
# np.greater_equal 表示求极大值,order = 1 表示和左边、右边的 1 个数字对比(是极大值的定义)
peak_index = argrelextrema(y,np.greater_equal,order=1)
print(peak_index)
"""
结果: (array([ 1, 3, 6, 9, 12], dtype=int64),)
peak_index[0] 给出了极大值点的数组
""" 上面使用np.greater_equal求极大值点,同样地我们可以使用np.less_equal求极小值点。甚至可以自定义函数,将上面代码第 7 行改为:
py
peak_index = argrelextrema(y,lambda a,b: a - b > 3,order=1) 这将返回比左、右两边元素都大 3 3 3 的所有元素(此例中只有y[9])的索引(此例为9)。
参考文献:数据分析------scipy.signal.argrelextrema求数组中的极大值和极小值-CSDN博客