引言
前面我们已经花了一定的篇幅详细介绍了Python中基于高阶函数、闭包的底层机制,所实现的装饰器的语法糖的使用。其实,除了我们可以自己定义满足业务需要的装饰器,还有些内部装饰器,我们可以拿来直接使用。
本文的主要内容有:
1、Python中类定义相关的装饰器
2、其他实用内部装饰器
Python中类定义的装饰器
在我们介绍Python中面向对象的内容中,其实我们已经使用了Python的几个内部装饰器。在当时,我们把这些只是简单地当做特定的语法规范,就得这么着的感觉。
通过对装饰器内容的介绍,我们应该对他们有了更深入的理解。接下来,就简单回顾一下这些装饰器。
由于我们已经比较自然地使用这些内部装饰器了,我们接下来只是回顾,并看下这些内部装饰器的定义,不再演示装饰器的使用。
1、@staticmethod
这个装饰器用于在类中定义一个静态方法。静态方法的使用不需要访问实例对象或者类对象,因此,不需要self或者cls参数。静态方法类似于普通函数,但是,在类的命名空间中。
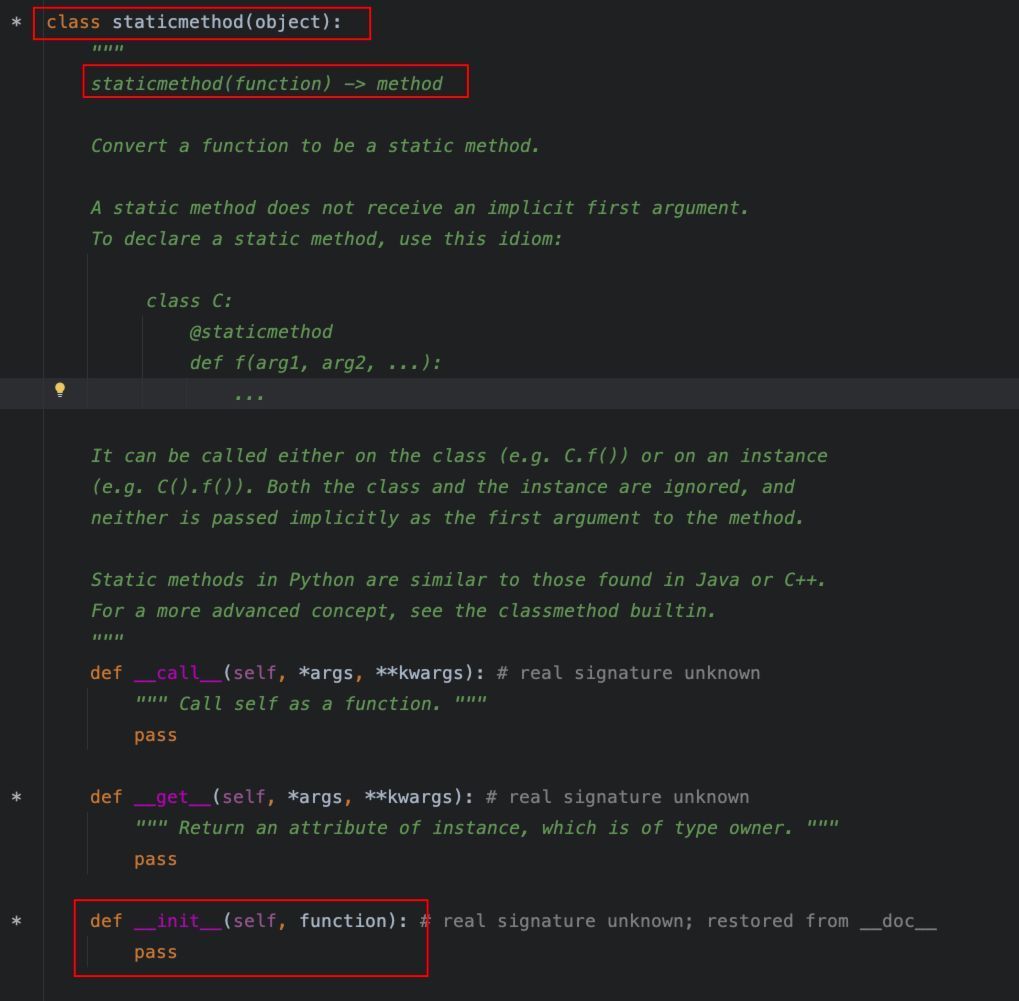
从这个定义可以看出,@staticmethod是我们之前已经学到的类装饰器的实现。
2、@classmethod
用于定义一个类方法,类方法的第一个参数是类本身,通常命名为cls。类方法可以访问和修改类对象的状态(注意,非实例对象的状态)。
同样看一下@classmethod的定义:
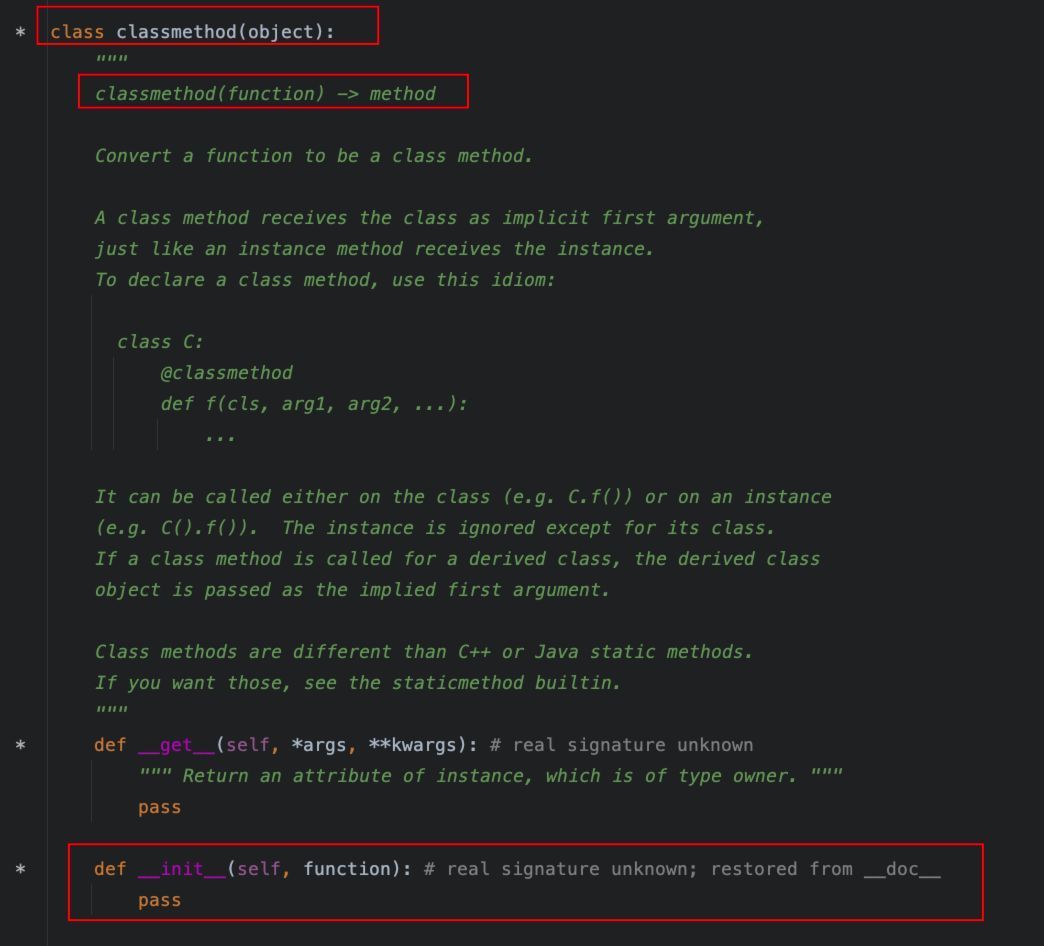
同样是类装饰器的实现。
3、@property
用于将一个方法转化为属性,允许像访问属性一样来调用该方法。
@property的定义如下:
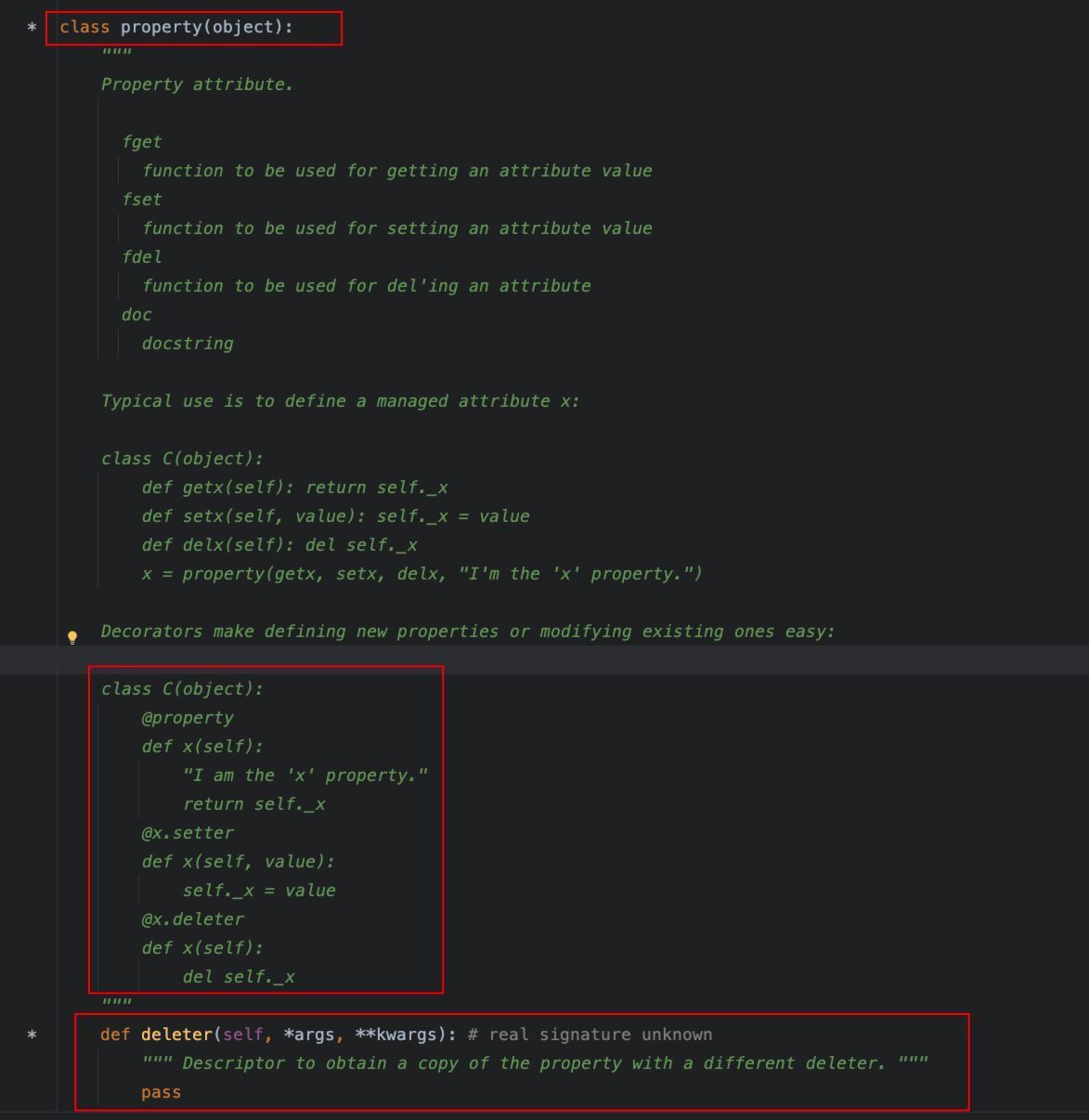
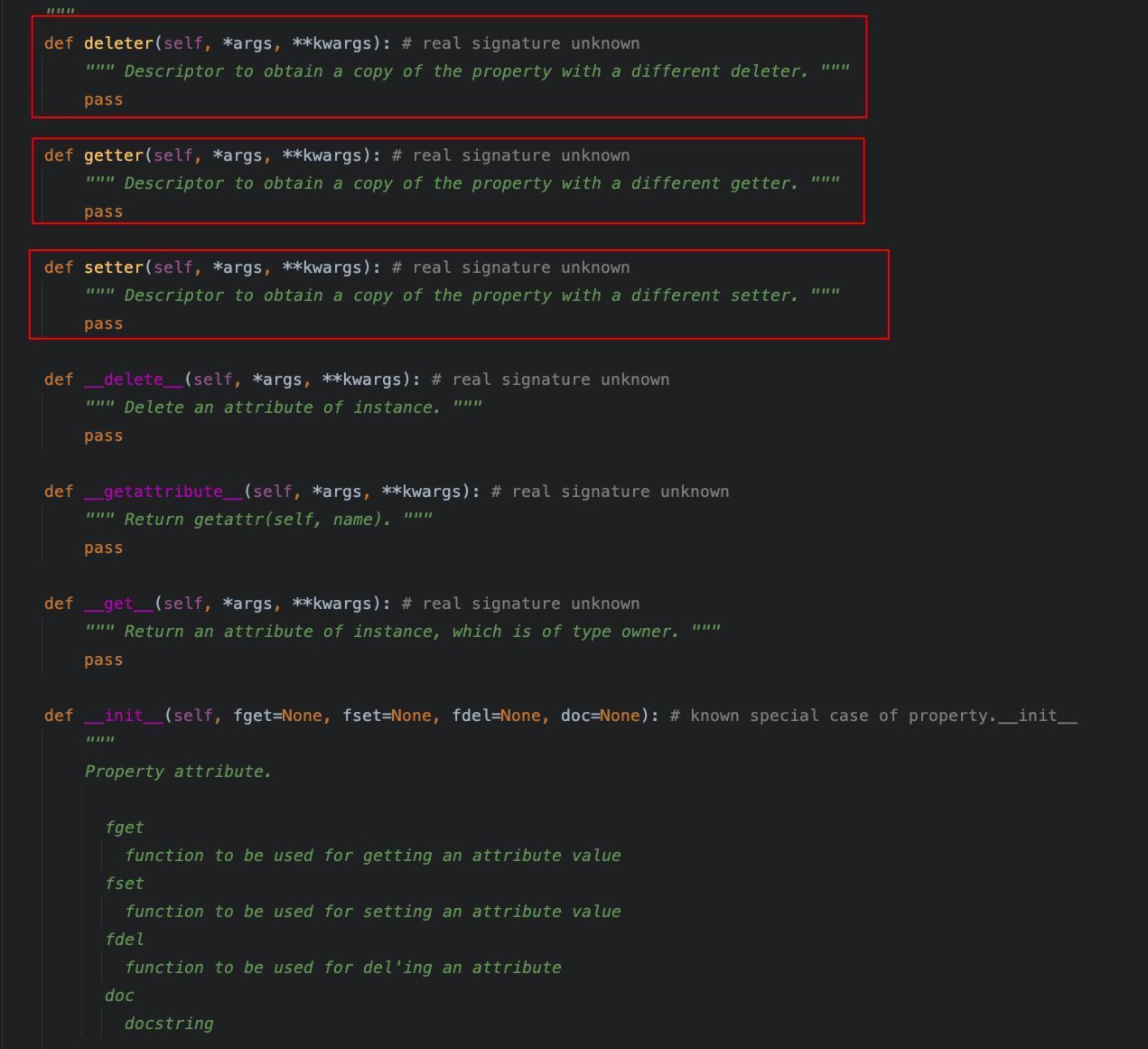
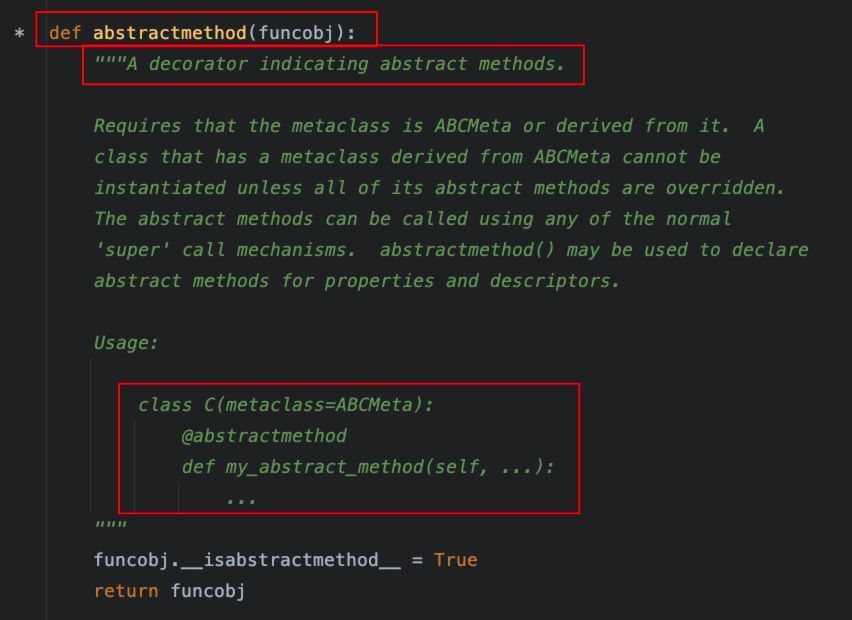
4、@abstractmethod
用于定义抽象方法,必须在子类中实现,属于abc模块。
其他实用的内部装饰器
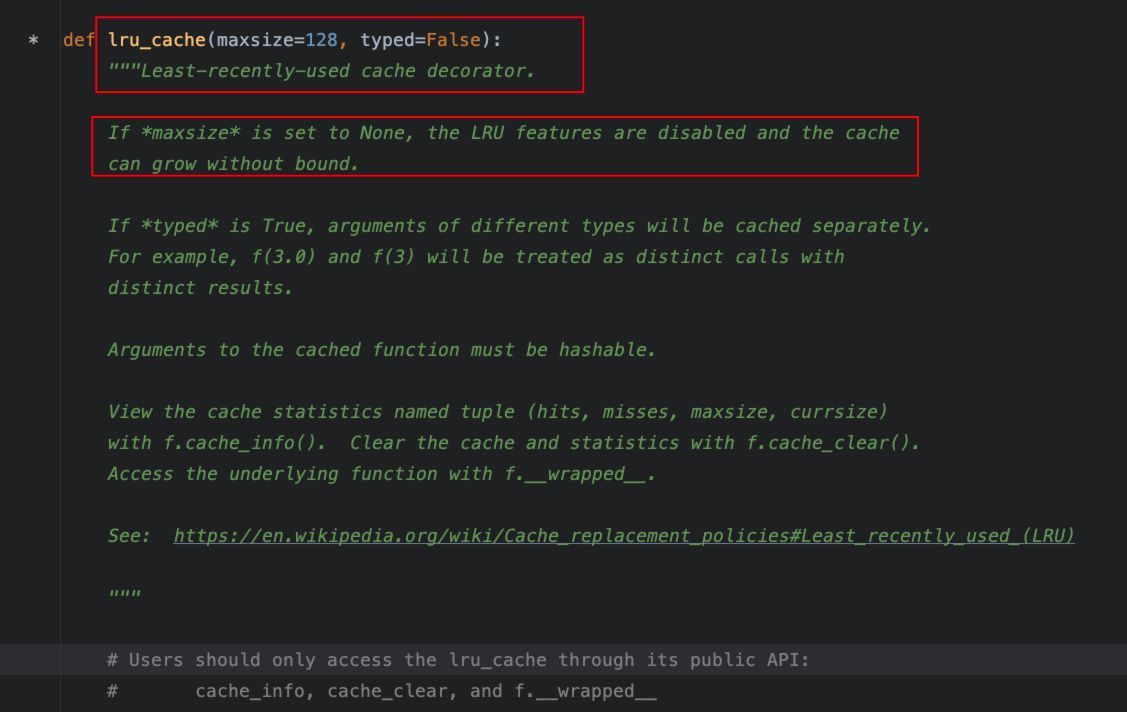
1、@lru_cache
之前我们通过装饰器实现过一个比较简陋的动态缓存功能,虽然在计算斐波那契等递归函数时确实比较有效,但是,确实是态简陋了。
其实,Python提供了缓存的装饰器实现,就是functools模块中的lru_cache。简单看下定义:
接下来,我们还是以斐波那契的计算简单用下lru_cache,直接看代码:
python
import time
from functools import lru_cache
@lru_cache(maxsize=None)
def fibonacci(n):
if n == 1:
return 0
if n == 2:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
if __name__ == '__main__':
for i in range(30, 40):
start = time.time()
res = fibonacci(i)
end = time.time()
print(f"Fib({i}) = {res} 耗时:{round(end - start, 4)} 秒")2、@singledispatch
在其他语言,比如Java、C++中,有个"函数重载"的概念,可以通过定义不通参数列表的同名函数,来实现,根据函数调用的实参,动态进行函数的调用。
Python中,虽然在语法上不支持同名函数的定义,但是,通过装饰器@singledispatch也能间接实现"函数重载"的行为。
首先看下@singledispatch的定义:
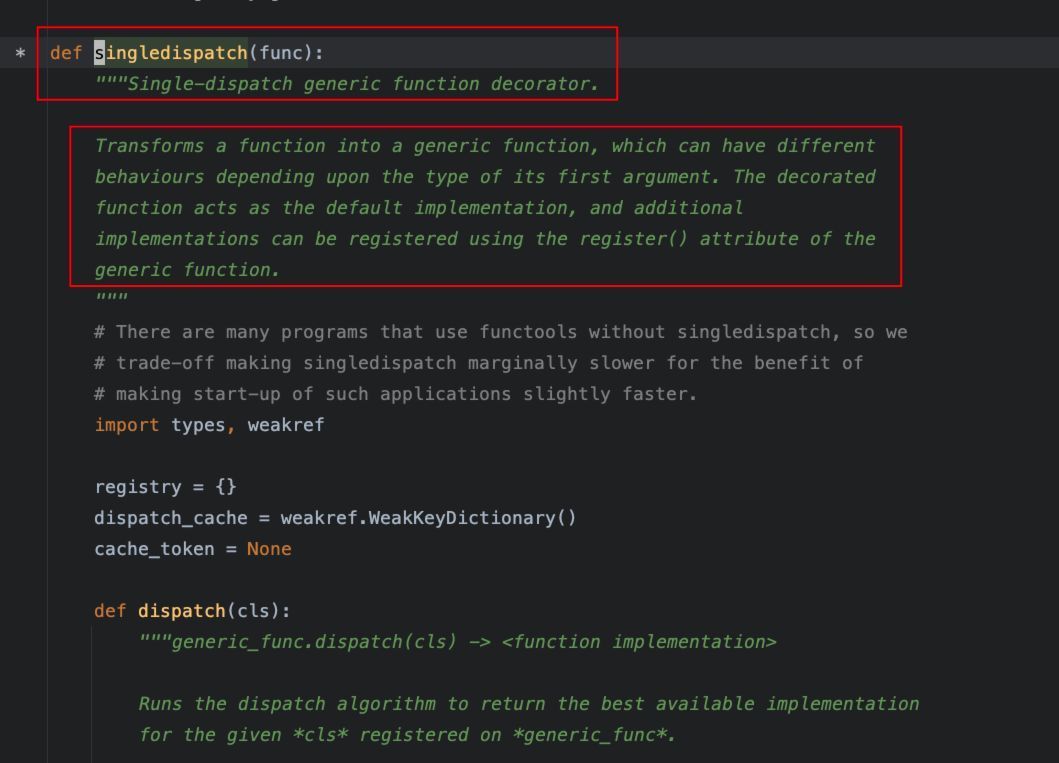
从定义中,也可以看出,该装饰器基于函数的第一个参数的类型进行函数的不同实现的调用,从而可以减少if-else等分支判断的写法。
以实际代码简单举例一下:
python
from functools import singledispatch
import json
@singledispatch
def serialize(obj):
raise NotImplementedError(f'类型{type(obj)},暂不支持序列化')
@serialize.register(int)
def _(obj):
print(f'序列化类型{type(obj)}')
return json.dumps({'type': 'int', 'value': obj})
@serialize.register(str)
def _(obj):
print(f'序列化类型{type(obj)}')
return json.dumps({'type': 'str', 'value': obj})
if __name__ == '__main__':
print(serialize(10))
print(serialize('hello python'))
print(serialize(['a', 'b']))执行结果:
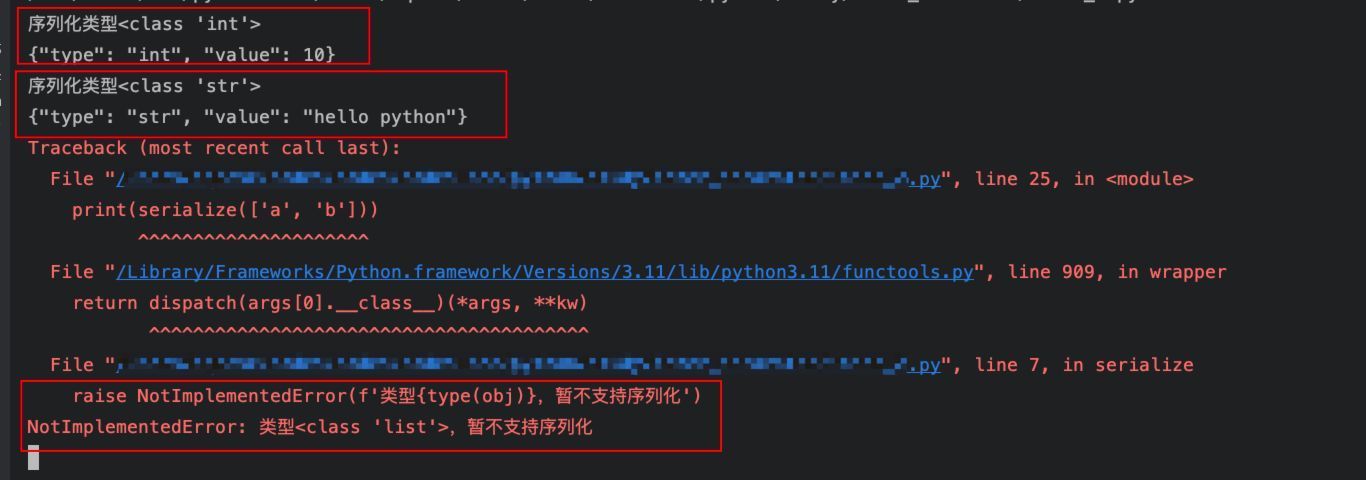
以上代码实现了一个根据不同类型执行不同的序列化的函数的动态调用。
该装饰器除了用于对象的序列化,也可以用于一些自定类型的处理中,感兴趣的可以自行探索、尝试。
3、@dataclass
这是一个特别重要的内部装饰器,用于简化Python中数据类的定义。
使用@dataclass装饰器,可以自动生成某些特定的方法,比如__init__、repr、__eq__等,从而减少重复的样板式代码的编写,进一步提高代码的可读性和可维护性。
下面,简单举个例子:
python
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
if __name__ == '__main__':
p1 = Point(0, 0)
p2 = Point(10, 20)
p3 = Point(0, 0)
print(p1)
print(p2)
print(p3)
print(p1 == p2)
print(p1 == p3)执行结果:
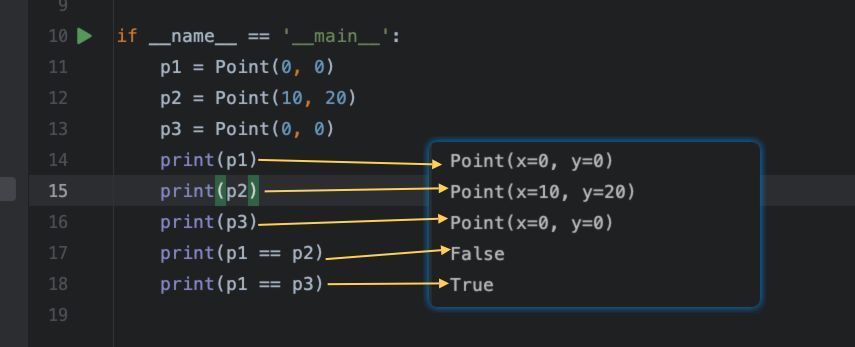
可以看到,我们定义了一个Point类,有两个属性x,y分别表示点的坐标,然后就定义完成了。
对象的打印输出、对象的比较等功能,已经自动实现了。显然,能够大大降低重复的代码的编写,提升开发效率。
关于@dataclass的内容,其实还有很多,我们后面单独写一篇文章介绍@dataclass更多的内容。
总结
本文回顾了Python中在面向对象中类的定义中用到过的内置装饰器,并进一步看了他们的定义,从而对这些固定的用法有了更深入的理解。此外,介绍了3个相对实用的内部装饰器,分别在LRU缓存、函数重载、数据类的快速定义等方面的应用。
感谢您的拨冗阅读,希望对您有所帮助。
