PVE虚拟机搭建K8s集群
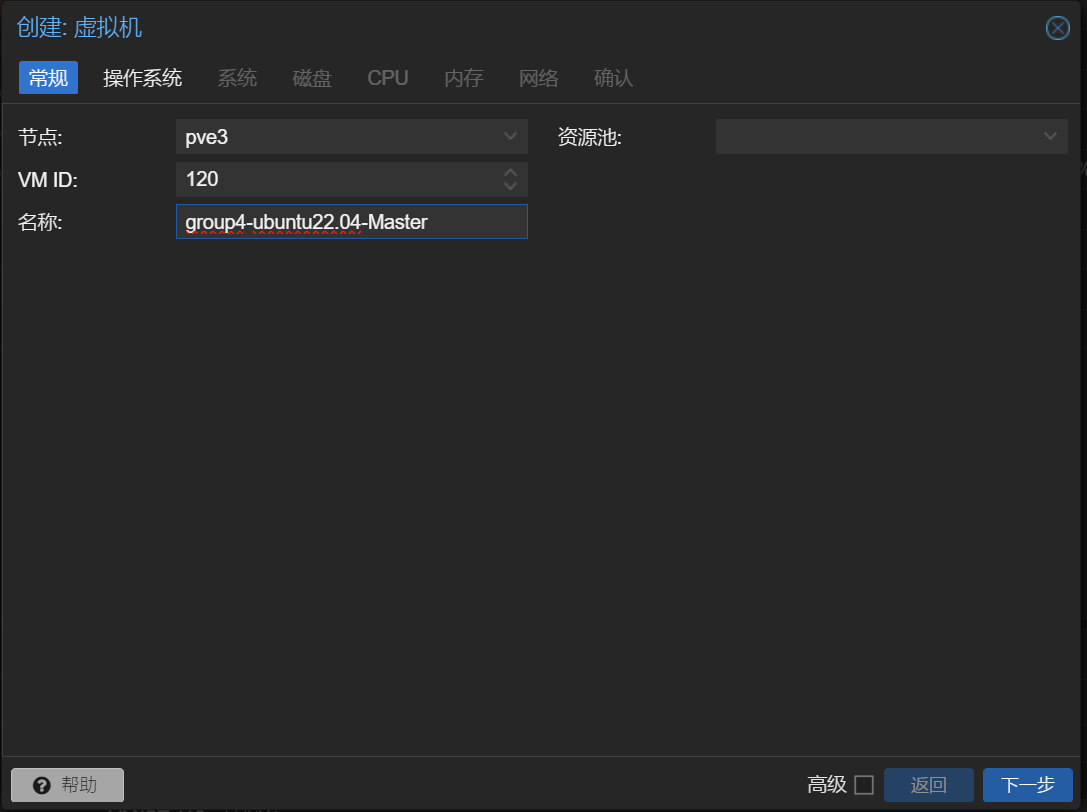
创建虚拟机
选择 pve3节点安装虚拟机,此节点的内网网段为 172.110.0.0,在不同的局域网段
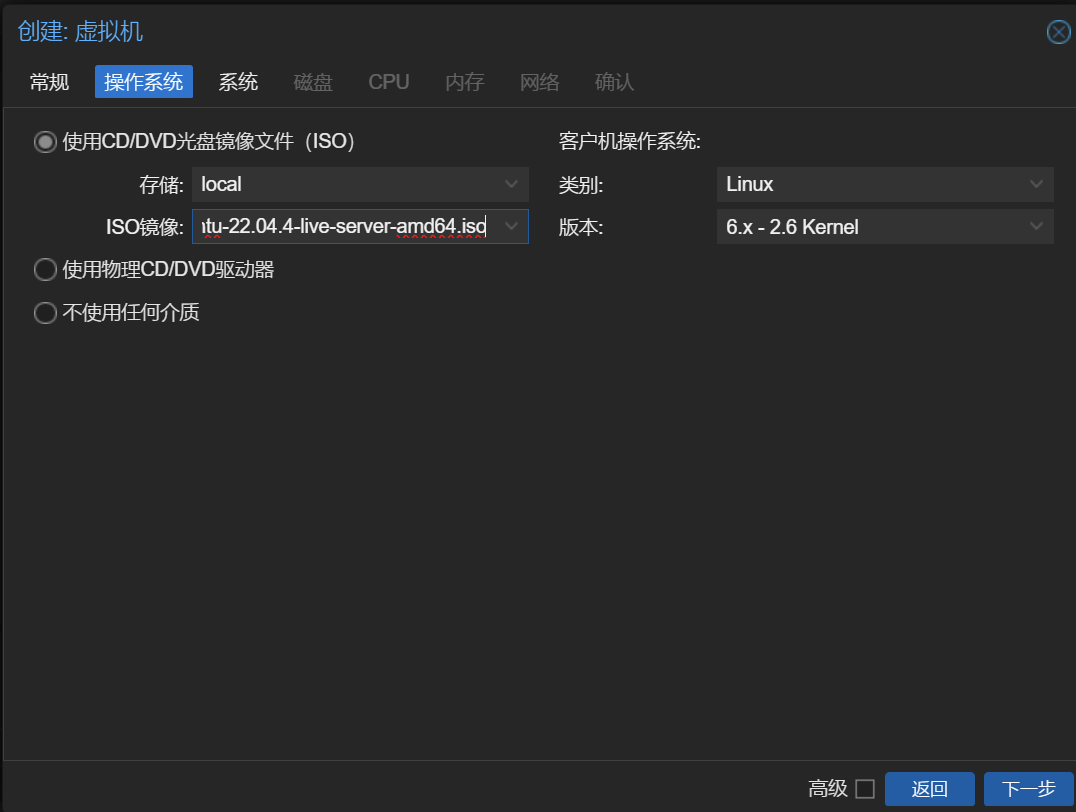
选择本地提供的镜像
存储页磁盘总线选择SATA,存储选择HDD卷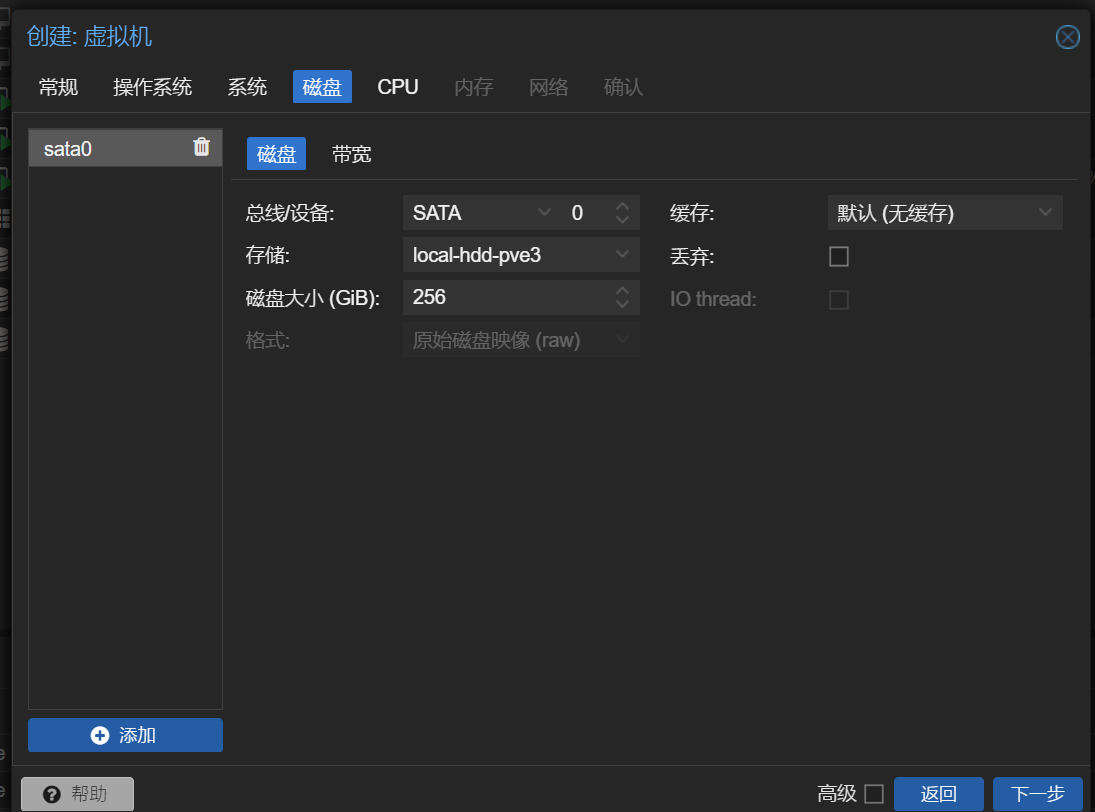
Master 节点设置的CPU数量为16(不能超过20)
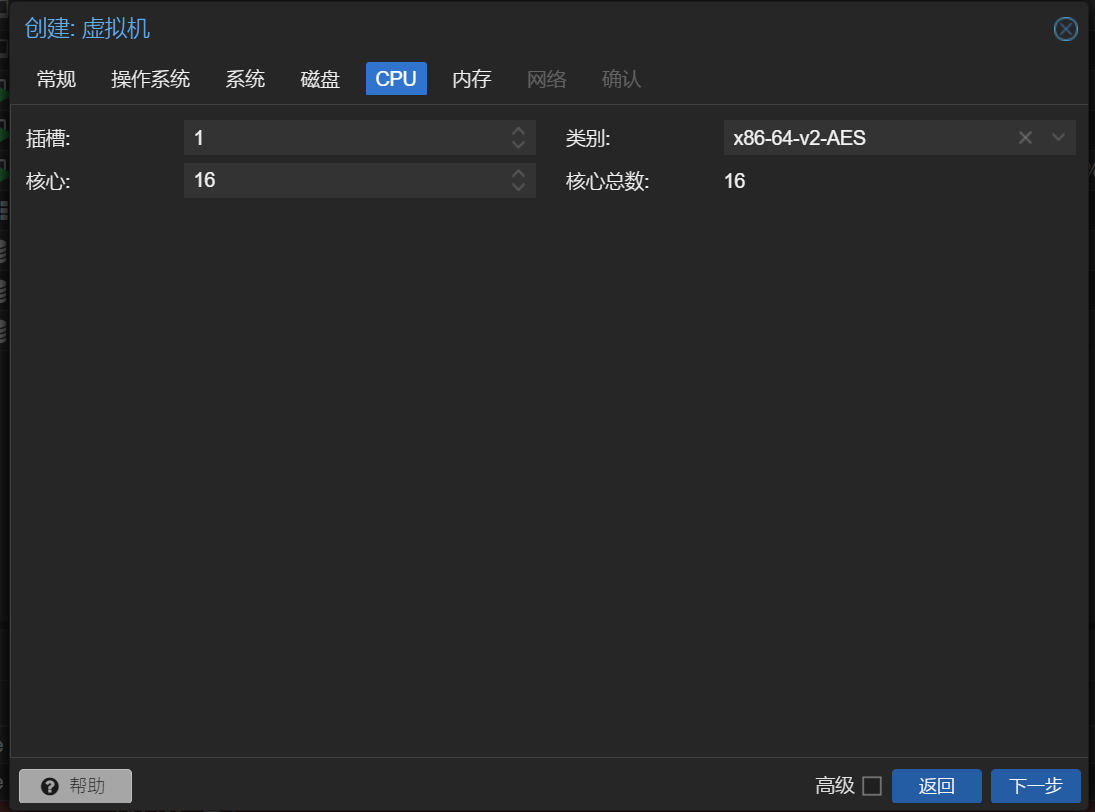
这里的内存应该给的再多一点,因为发现内存的使用率一直在 90%左右
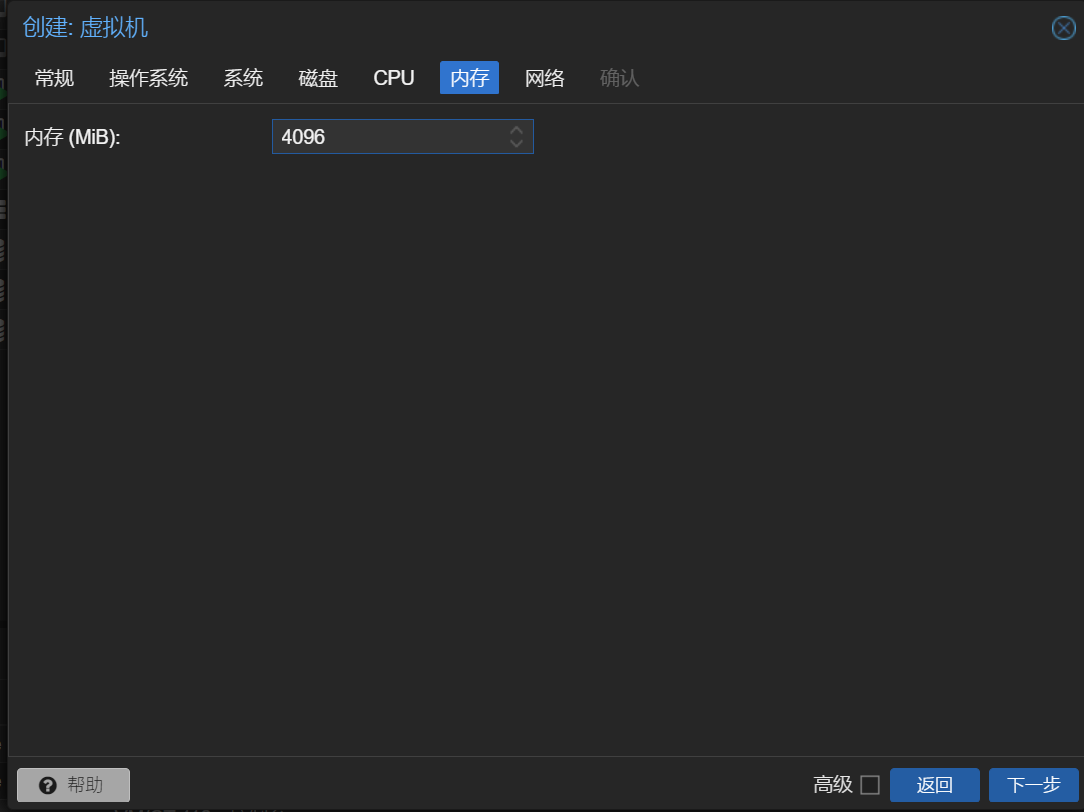
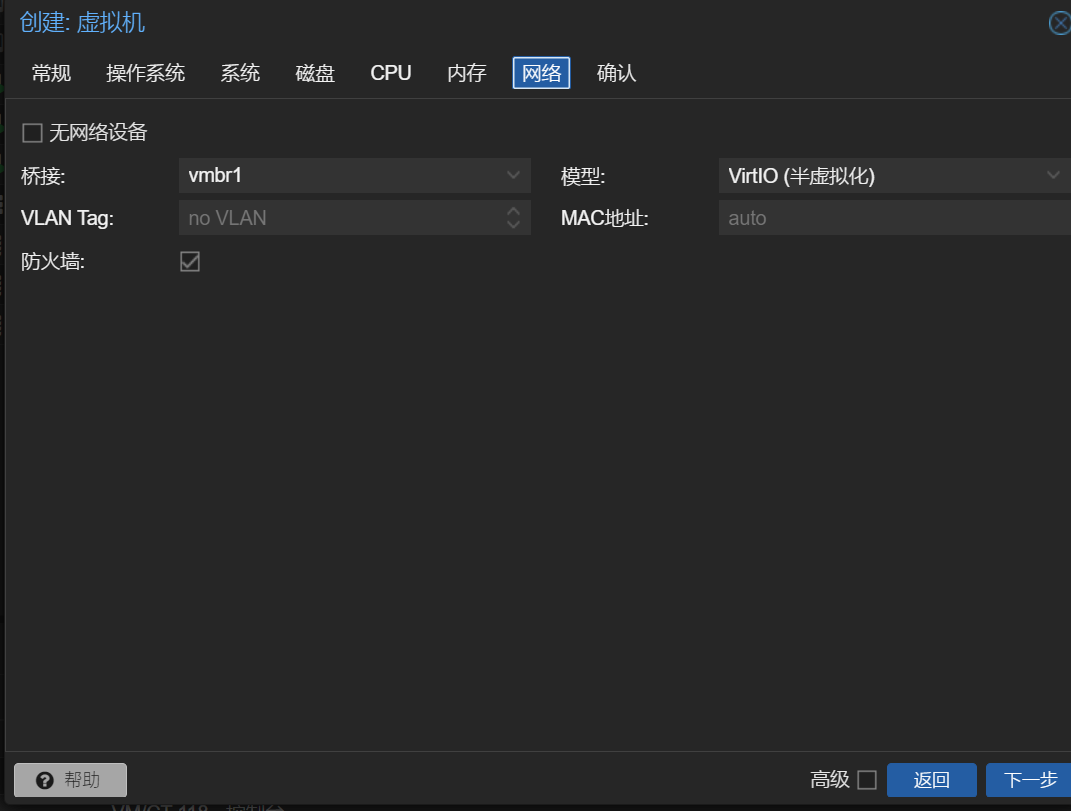
选择vmbr1网卡,这个网卡只能在内网网段使用
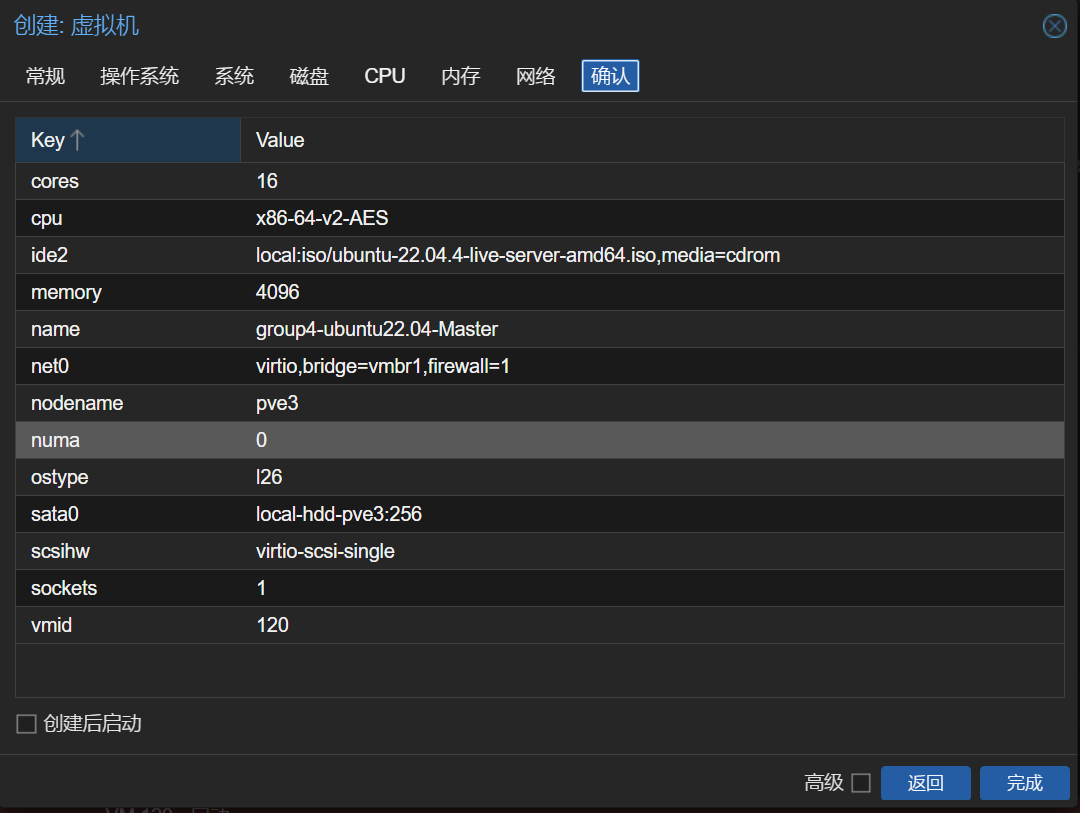
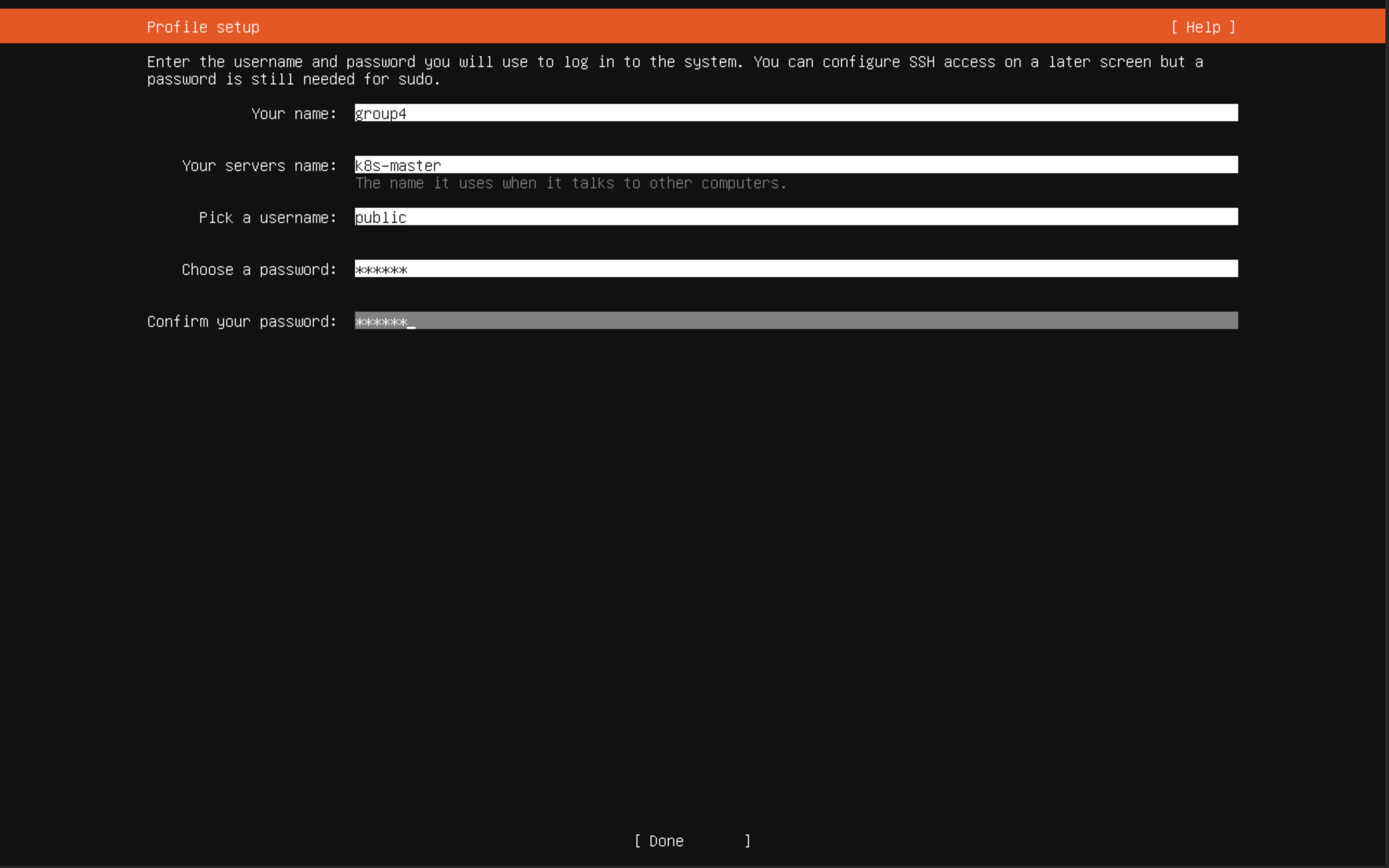
创建的虚拟机相关配置
| 虚拟机名称 | IP地址 | 主机名称 | 用户名 | 用途 |
|---|---|---|---|---|
| 120(group4-ubuntu22.04-Master) | 172.100.0.106 | k8s-master | public | K8S控制平面接点(主节点) |
| 118(group4-ubuntu22.04-node1) | 172.100.0.104 | node1 | public | K8S工作节点1 |
| 119(group4-ubuntu22.04-node2) | 172.100.0.105 | node2 | public | K8S工作节点2 |

搭建集群
安装前准备
关闭防火墙
shell
sudo systemctl disable --now ufw设置服务器时区
Ubuntu安装完成之后默认不是中国时区,需要执行以下命令设置为中国上海时区,因为关系到集群机器之间的通信,需要一个时间同步大家的行为。
shell
# 设置为亚洲的上海时区
sudo timedatectl set-timezone Asia/Shanghai
# 重启时间同步服务
sudo systemctl restart systemd-timesyncd.service
# 确保时间同步服务正常运行
timedatectl status 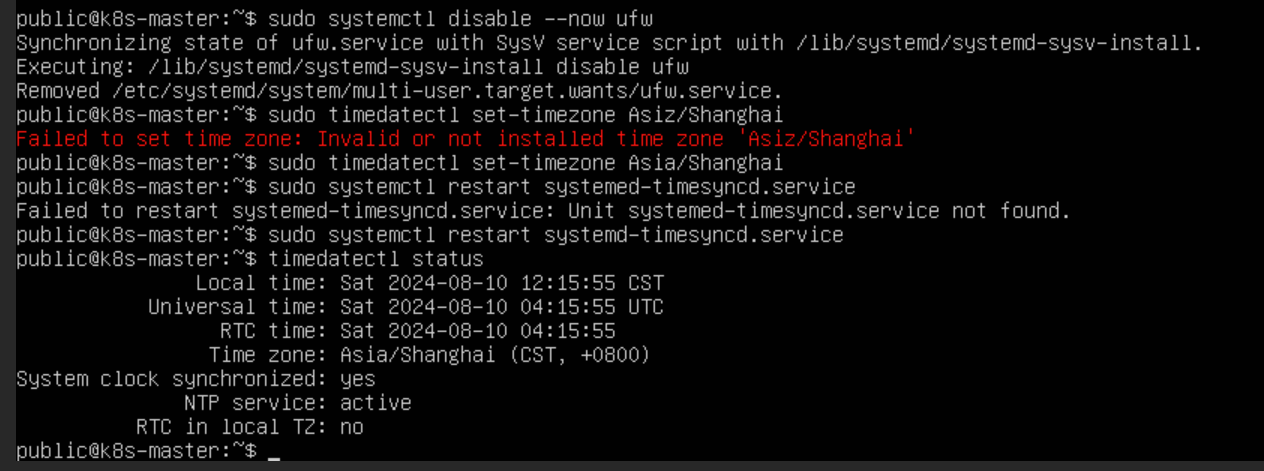
关闭swap分区
需要关闭所有swap分区,可以修改 /etc/fstab 文件:
shell
sudo vi /etc/fstab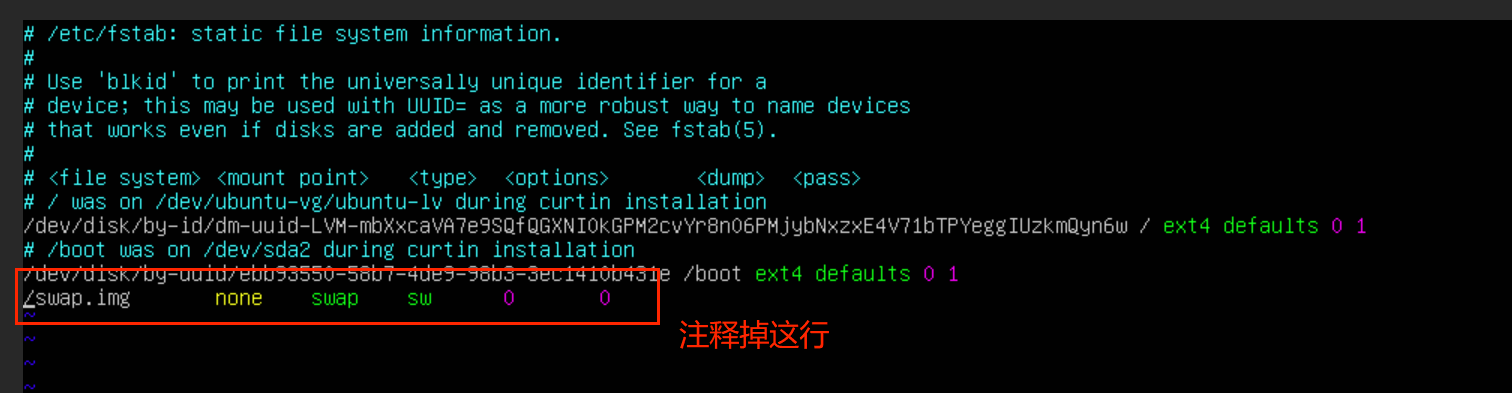
上面是永久关闭,下面可以执行这行命令临时关闭:
shell
sudo swapoff -a关闭SELinux
Ubuntu默认关闭了selinux,通过以下命令确保selinux已关闭
shell
# 安装policycoreutils软件包
sudo apt install -y policycoreutils
# 检查selinux关闭状态
sestatus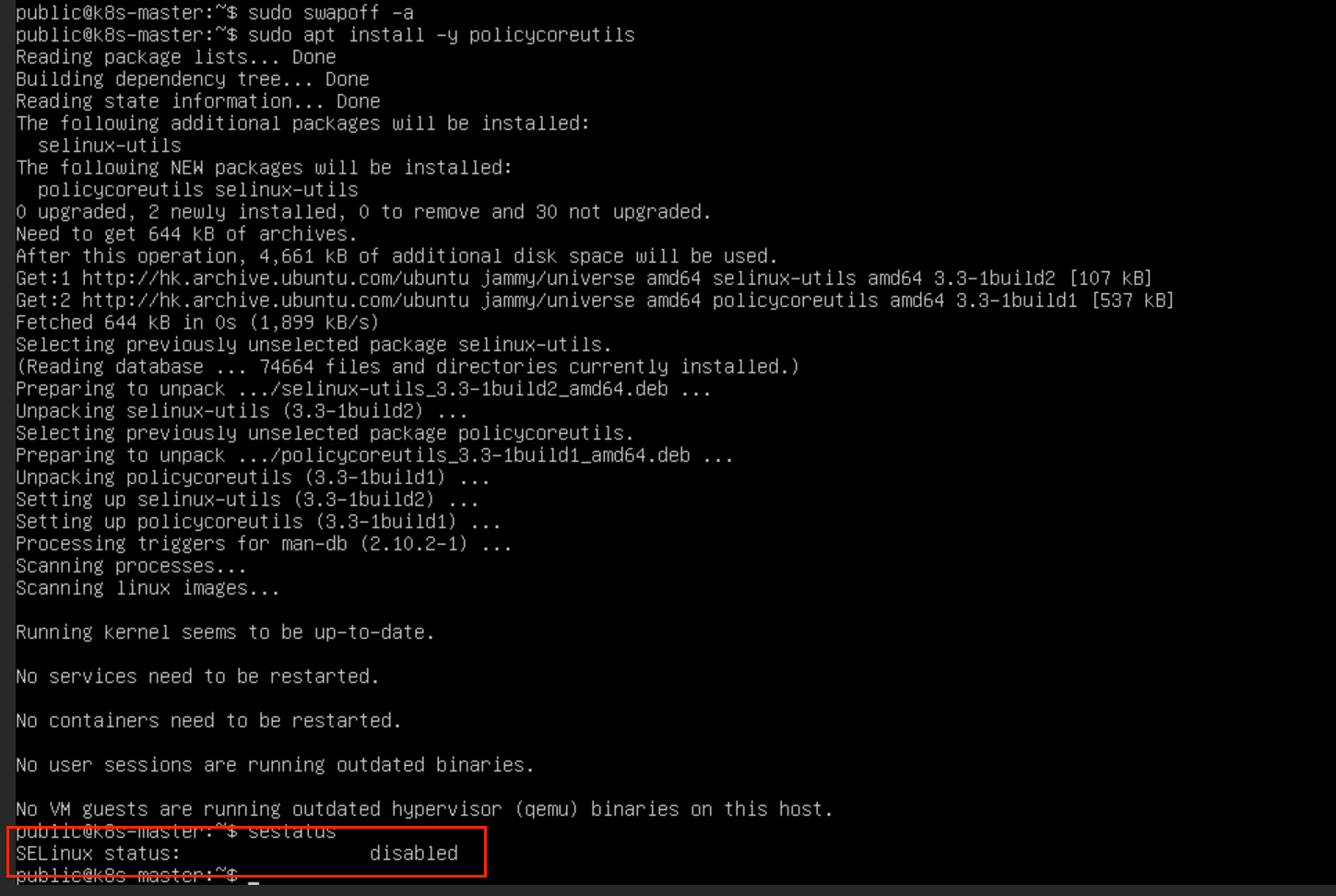
配置hosts配置文件
需要修改 /etc/hosts 配置文件,通过下面命令:
这里文件修改的主要意义是,当工作节点加入集群时,可以通过这个文件,将工作节点的IP映射为名称
bash
sudo vi /etc/hosts然后注释掉原来的主机名称配置,并将下面这几行解析添加到文件最后(注意修改为自己的IP地址):
bash
172.100.0.106 k8s-master
172.100.0.104 node1
172.100.0.105 node2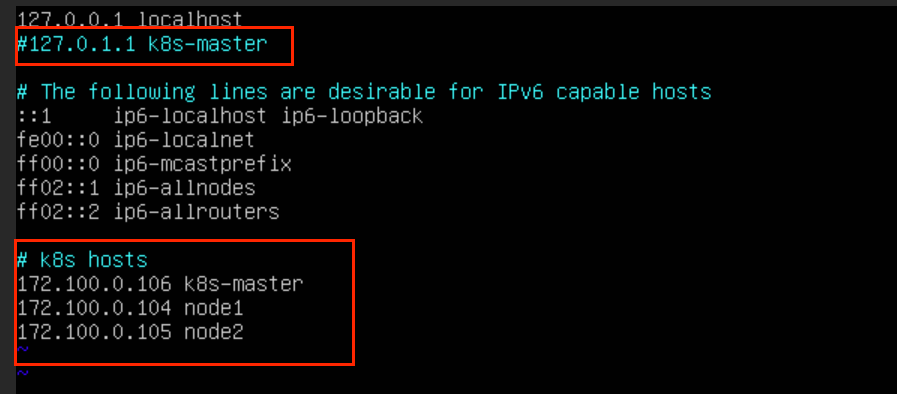
转发 IPv4 并让 iptables 看到桥接流量
开这个的原因是让各个主机承担起网络路由的角色,因为后续还要安装网络插件,要有一个路由器各个 Pod 才能互相通信。
执行下述指令:
shell
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system通过运行以下指令确认 br_netfilter 和 overlay 模块被加载:
shell
lsmod | grep br_netfilter
lsmod | grep overlay 通过运行以下指令确认 net.bridge.bridge-nf-call-iptables、net.bridge.bridge-nf-call-ip6tables 和 net.ipv4.ip_forward 系统变量在你的 sysctl 配置中设置为 1:
shell
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
安装容器运行时
Kubernetes-1.24 版本移除了 dockershim 的支持,所以之前的先安装 docker 再安装 Kubernets 的方式已经不可行了,可能会导致 Kubelet 报错退出,所以要先安装 containerd 运行时环境。
虽然安装 Docker 时带有 containerd ,安装 Docker 时确实是 apt install -y docker-ce docker-ce-cli containerd.io ,确实安装了 containerd ,但是这是 Docker 的 containerd 啊,这么安装的 containerd 是由 Docker 管理的,k8s 无法管理,所以就会导致报错
如果使用
k8s1.24版本以上,那么containerd一定要单独安装,不要想着安装Docker了会自带,k8s启动会报错去
GitHub上下载二进制包,想要其他版本的话替换两处1.7.17为你想要的版本即可:
安装containerd的容器运行时,下载地址:https://github.com/containerd/containerd/releases/download/v1.7.13/cri-containerd-cni-1.7.13-linux-amd64.tar.gz,可以通过下面命令进行下载:
shell
curl -L --output cri-containerd-cni-1.7.13-linux-amd64.tar.gz https://github.com/containerd/containerd/releases/download/v1.7.13/cri-containerd-cni-1.7.13-linux-amd64.tar.gz
解压到根目录:
shell
sudo tar -zxvf cri-containerd-cni-1.7.13-linux-amd64.tar.gz -C /启动 containerd 并且开机自启:
shell
sudo systemctl start containerd
sudo systemctl enable containerd查看安装的版本
containerd -v
通过下面命令创建配置文件目录:
shell
sudo mkdir /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml然后修改一下这个文件
shell
sudo vi /etc/containerd/config.toml修改 sandbox_image 值为 registry.aliyuncs.com/google_containers/pause:3.9
修改 SystemdCgroup 为 true(这个配置指定是否使用 systemd 来管理 cgroup,如果 etcd 一直重启的话就开启这个选项试试)
这两个地方不修改,会导致在初始化时,创建沙箱 pod 镜像拉取失败
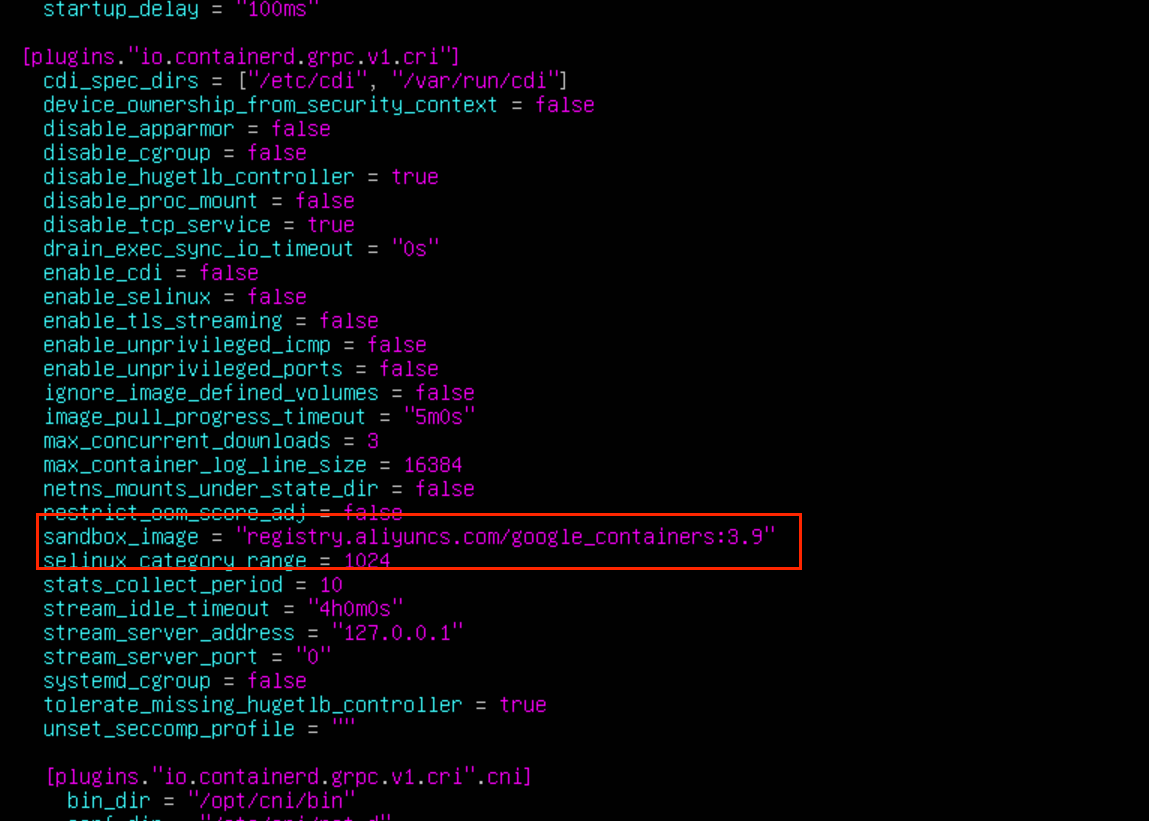
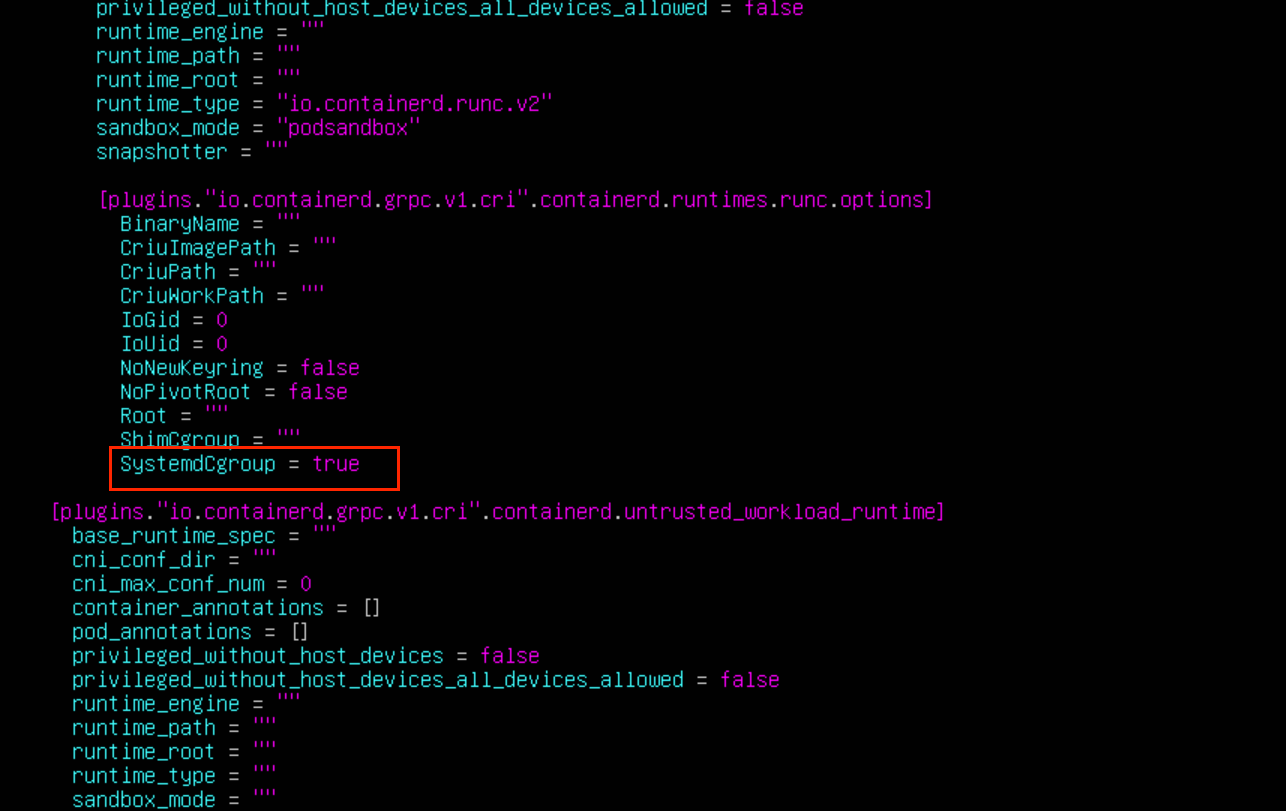
保持退出之后通过下面命令启动 containerd:
shell
# 重启
sudo systemctl restart containerd
# 设置开机自启动
sudo systemctl enable --now containerd安装Kubernetes
kubeadm 是自动引导整个集群的工具,本质上 k8s 就是一些容器服务相互配合完成管理集群的任务,如果你知道具体安装哪些容器那么可以不用这个。
kubalet 是各个节点的总管,它上面都管,管理Pod、资源、日志、节点健康状态等等,它不是一个容器,是一个本地软件,所以必须得安装
kubectl 是命令行工具,给我们敲命令与 k8s 交互用的,必须得安装
出现问题的重灾区
在正常的官网的下载安装流程是这样的
更新 apt 包索引并安装使用 Kubernetes apt 仓库所需要的包:
shell
# 保证源都是新的
sudo apt-get update
sudo apt upgrade -y
# 安装一些必要工具
sudo apt-get install -y apt-transport-https ca-certificates curl gpg下载用于 Kubernetes 软件包仓库的公共签名密钥。所有仓库都使用相同的签名密钥,因此你可以忽略URL中的版本:
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg添加 Kubernetes apt 仓库。 请注意,此仓库仅包含适用于 Kubernetes 1.28 的软件包; 对于其他 Kubernetes 次要版本,则需要更改 URL 中的 Kubernetes 次要版本以匹配你所需的次要版本
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list在这一步中,由于服务器无法访问外网,导致密钥无法下载,后续的工具更无法安装,网上有提到使用这个仓库地址,但是,使用后更新 sudo apt-get update 会报错
shell
deb http://apt.kubernetes.io/ kubernetes-xenial main
shell
sudo apt-get update
Hit:1 http://us.archive.ubuntu.com/ubuntu jammy InRelease
Hit:2 http://us.archive.ubuntu.com/ubuntu jammy-updates InRelease
Hit:3 http://us.archive.ubuntu.com/ubuntu jammy-backports InRelease
Hit:4 http://security.ubuntu.com/ubuntu jammy-security InRelease
Ign:5 https://packages.cloud.google.com/apt kubernetes-xenial InRelease
Err:6 https://packages.cloud.google.com/apt kubernetes-xenial Release
404 Not Found [IP: 74.125.142.139 443]
Reading package lists... Done
E: The repository 'https://apt.kubernetes.io kubernetes-xenial Release' does not have a Release file.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.在这里使用国内阿里云的镜像网站,并添加 apt 仓库(这里的仓库地址我也是找了比较久,实测仓库密钥没有问题,但是下载的k8s的版本似乎是固定的,目前还没尝试成功调整成为其他的版本,不过v1.28倒也可以用,要注意的是注意其他工具的版本兼容问题)
shell
curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# 要注意kubernetes-xenial main和前面的斜杠之间是有一个空格的,这个空格是必须的
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main' | sudo tee /etc/apt/sources.list.d/kubernetes.list最后!!终于可以更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本,防止软件更新(这里直接 -y 只会下载最新版本的,如果要注意不同k8s的版本要求,不兼容的话会出现问题):
shell
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl启动 kubelet ,并且设置开机自启(这里如果不设置开机启动的话,重启服务器的时候,会有kube-system 的一些 pod 出现问题,比如不是Running,变成了Pending等):
shell
sudo systemctl enable --now kubelet查看版本
kubeadm version
初始化集群
这一步,只在主节点上做,上面的步骤,在工作节点都是需要执行的
提前拉取镜像
上一步已经确定了安装了v1.28.2 的版本,接下来可以在主节点上执行这行命令将主节点的镜像提前拉取下来:
shell
sudo kubeadm config images pull \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.28.2 \
--cri-socket=unix:///run/containerd/containerd.sock
这里也可以使用 yaml 文件拉取
生成文件
shell
kubeadm config print init-defaults > init.default.yaml编辑文件内容
vi init.default.yaml
yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 1.2.3.4
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}主要修改imageRepository:
k8s.gcr.io -> registry.aliyuncs.com/google_containers
修改完后,要记得重启
systemctl restart kubelet 通过配置下载镜像
sudo kubeadm config images pull --config=init.default.yaml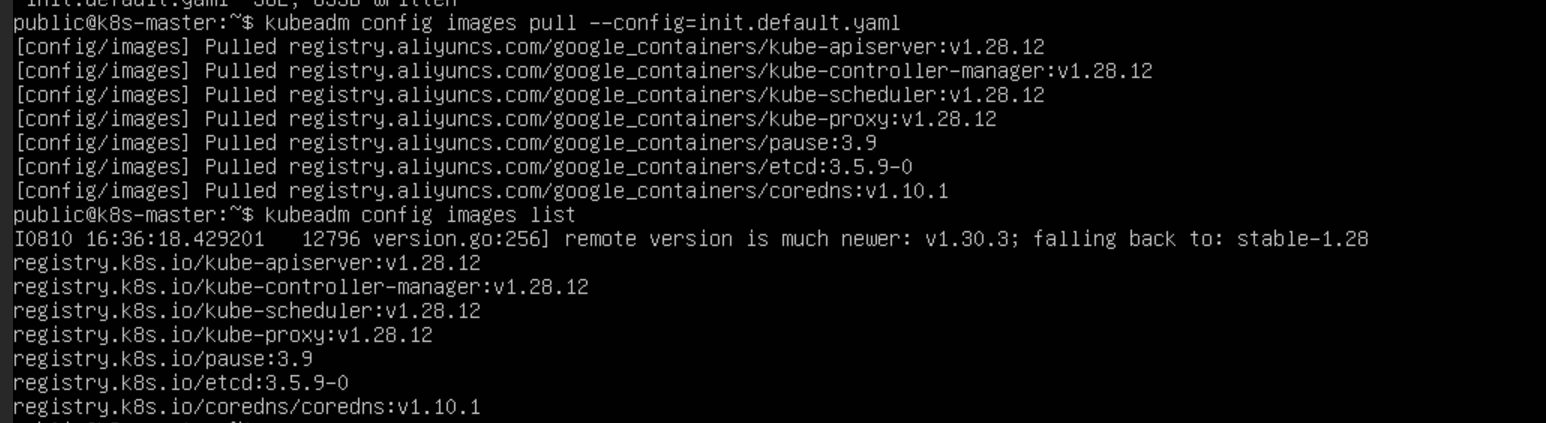
可以使用
kubeadm config images list来查看相关的镜像配置版本是否兼容
初始化节点
shell
sudo kubeadm init \
--apiserver-advertise-address=172.100.0.106 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.28.2 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--cri-socket=unix:///run/containerd/containerd.sock
# --control-plane-endpoint=k8s-master \apiserver-advertise-address 填主节点的IP地址,注意一定要是内网的IP,如果使用公网IP初始化会报错
control-plane-endpoint ,在 /etc/hosts 文件中配置的映射关系,填主节点的地址或者主机名(有帖子说使用这个命令偶尔会出现超时问题,可加可不加)
kubernetes-version 版本service-cidr 这是 Service 负载均衡的网络,就是运行了一堆容器后有一个将它们统一对外暴露的地址,并且将对它们的请求统一收集并负载均衡的网络节点,得为它配置一个网段
pod-network-cidr 每个 Pod 所在的网段
cri-socket ,指定容器化环境
最后的三个选项,我看了大部分的帖子的配置均为如此,没有特殊情况应该为常规配置
特别注意,apiserver-advertise-address、service-cidr、pod-network-cidr 三者的IP网段 不能重叠 不能重叠 不能重叠,不但三者之间不能重叠,三者每个也不能与互联网上的地址重叠,不然会出问题,后两个一般用 10.x.x.x 网段,这个网段是留给内网的
在这一步,也会出现很多问题,比如[kubelet-check] Initial timeout of 40s passed等等
详细错误信息参考
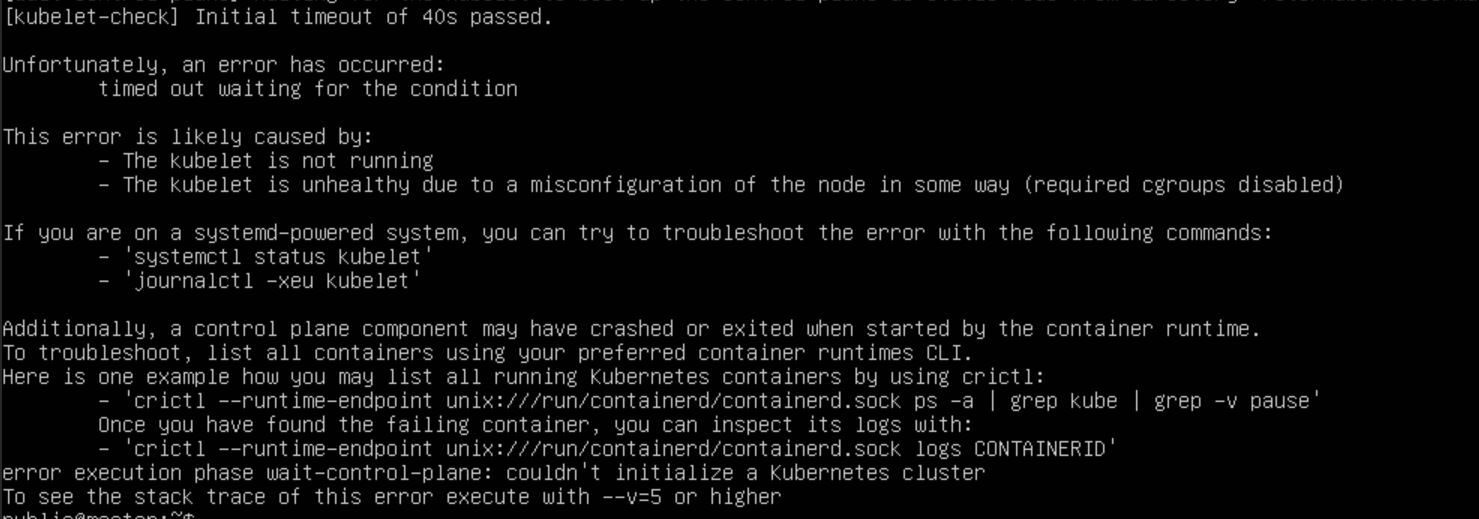
wait-control-plane Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
kubelet-check Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
如果出现了问题,就查看日志,排查问题,这里我卡了很久
journalctl -xeu kubelet要注意每次排查完问题,重新初始化的时候,要重置 kubeadm
sudo kubeadm reset 如果遇到一些 preflight errors ,比如一些文件已经存在,这时候要看, 每次更新时,一些文件的配置是否变化,如当工作节点加入集群时,如果证书内容发生变化,那么相应的文件内容都是需要删除的,如果排查的问题不涉及一些文件的变化改动,则可以忽略,如果遇到 10250 端口被占用的情况时,用命令去查看使用端口的工具,如果是 kubelite ,则kill掉,因为他会占用 kubelet 的端口导致,kubelet 无法启动,如果是 kubelet 则可以忽略掉(还有很多问题,在解决的过程中忘记留记录了,最常见的是这几种)每次排查完问题,要注意重启相关工具,如 kubelet,kubeadm,containerd 等等
有时候,重启kubelet时,端口10250会被kubelite占据,要注意排查
还有一些问题是文件权限导致的,这些在日志中可以看出来,但也是比较常见的,要注意多查看日志排查问题
sudo lsod -i:10250 sudo killall kubelite sudo systemctl restart kubelet sudo systemctl restart containerd sudo kebuadm reset


如果,你非常的幸运,又或者排除万errors,最终会走到初始化成功这一步
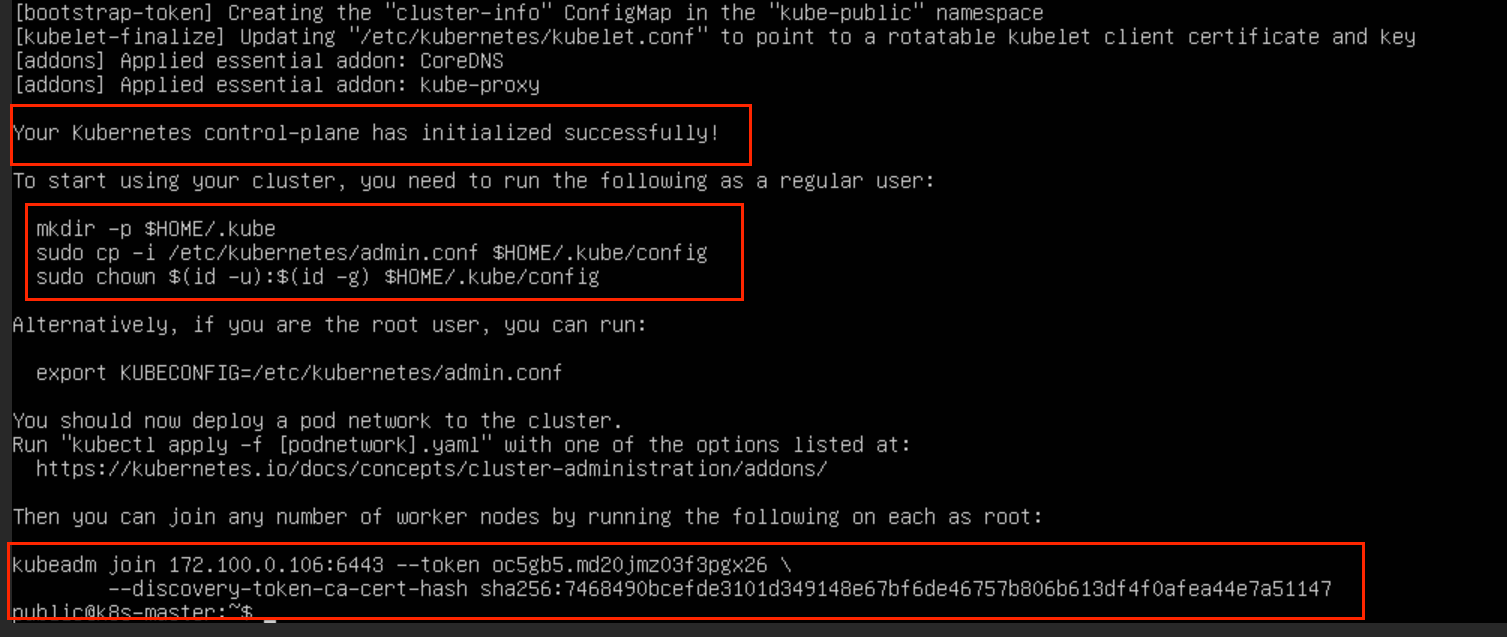
首先需要在本机上执行这三条命令,(这里应该是建立环境变量,没有执行的话,在主节点没办法与API server通信(error图片忘记留了),使用kubectl get 等命令时是得不到响应的)
shell
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config同时,这里的 token 是需要保存一下的,因为工作节点加入集群是需要这个token的,同时 token 的有效期大概是24h
shell
# 如果忘记了 Master 的 Token,可以在 Master 上输入以下命令查看
kubeadm token list
# 默认token的有效期为24小时,当过期之后,该token就不可用了。解决方法如下:
# 重新生成新的token
kubeadm token create
# --discovery-token-ca-cert-hash 的查看方法,在 Master 运行以下命令查看 要注意有空格
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'然后在所有工作节点上执行这行命令(注意修改为自己的token),注意后面拼接上 --cri-socket=unix:///var/run/containerd/containerd.sock 参数:(这里我忘了自己的token了,随便粘贴一个网上的例子,大概样子是这样的)
sudo kubeadm join 172.100.0.106:6443 --token jkw9gq.wdjmxylrghz23r3d \
--discovery-token-ca-cert-hash sha256:4fb1b85884d63cd5773ad14822567cd62b4dc5c3b45b6f8f8cfc41a202667f66 \
--cri-socket=unix:///run/containerd/containerd.sock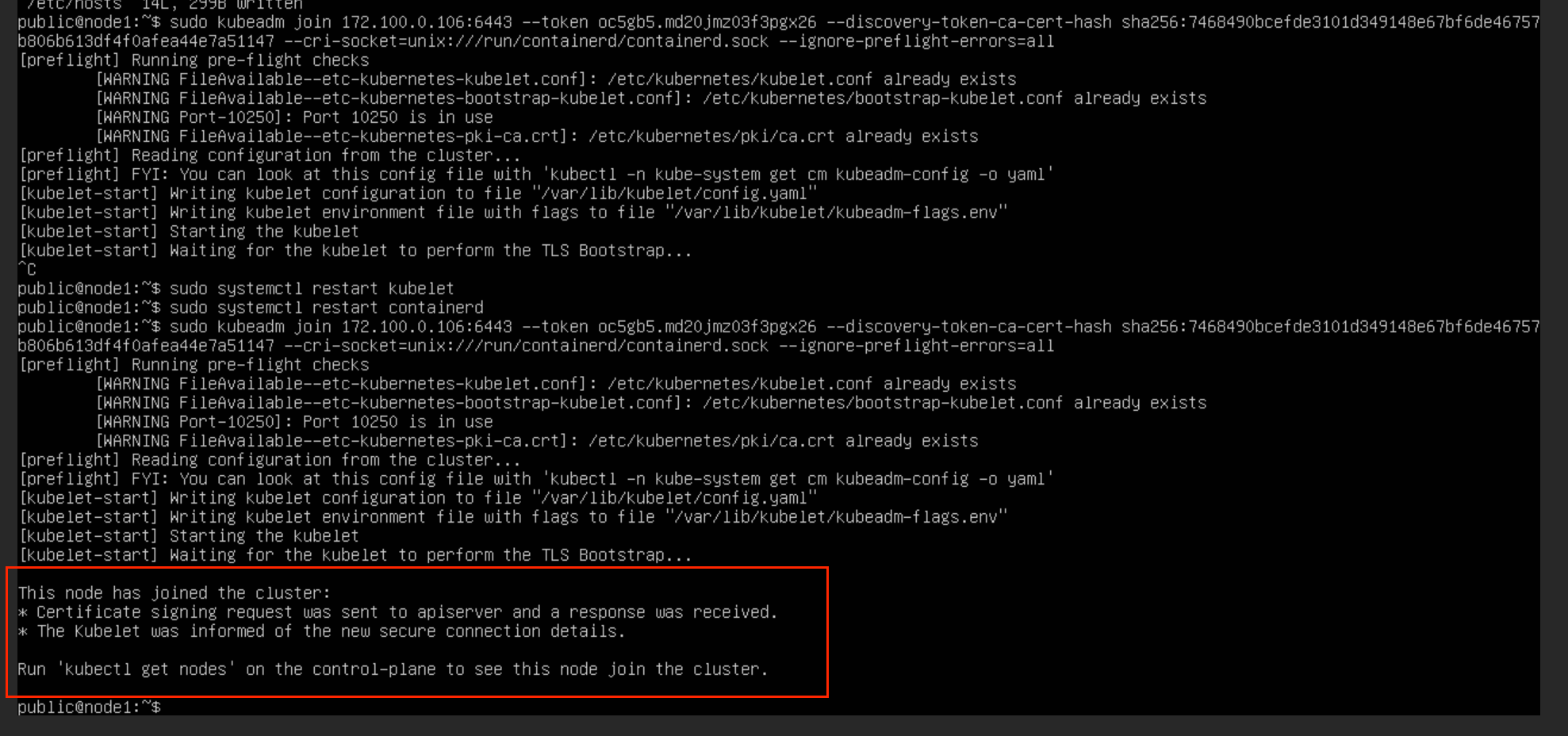
安装网络插件
本来呢,我觉得,到了上面一步,就已经结束了,但是我发现,我的集群中的节点的状态,全部都是 NotReady ,查了一下原因是因为没有网络插件,因为集群只是在主节点上初始化了,其他机器要想加入集群,还得使用网络插件将它们连接起来,所以得安装一个网络插件,主流的网络插件有很多个,常见的是 Calico 和 flannel,但是这两个插件在安装的时候,出现了各种问题,最后换用了 Cilium 插件
安装 helm
shell
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh安装cilium
shell
helm repo add cilium https://helm.cilium.io
helm install cilium cilium/cilium --namespace kube-system --set hubble.relay.enabled=true --set hubble.ui.enabled=true --set prometheus.enabled=true --set operator.prometheus.enabled=true --set hubble.enabled=true --set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,http}"
kubectl rollout restart daemonset cilium -n kube-system安装成功

节点均变为 Ready,系统 Pod 也均正常运行

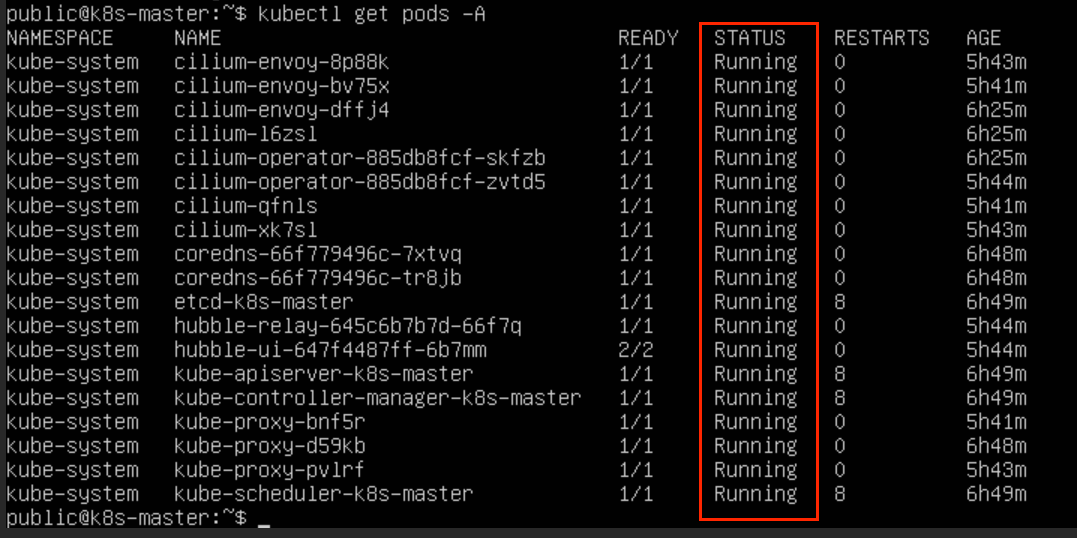
这里如果出现某个 pod 状态异常,包括但不限于一直处于容器创建中或者Pending 或者比较明显的镜像拉取失败等等问题,如果查询 kubelet 未果,使用命令 kubectl describe pod <pod名称> <命名空间> 可以查到问题,如果出现加入的节点的相关 pod 有问题,但是 master 本身没什么问题,重点查看一下节点的镜像地址等相关配置问题
关于 Calico 和 flannel 安装的一些问题
Calico安装
calico官网地址:https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
安装Tigera Calico操作符和自定义资源定义:
shell
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/tigera-operator.yaml如果报错连接不上的话将文件手动下载下来再执行
shell
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
# 或者
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
kubectl create -f tigera-operator.yaml 下载下来后不能用 kubectl apply -f 来执行,会报错
The CustomResourceDefinition "installations.operator.tigera.io" is invalid: metadata.annotations:
Too long: must have at most 262144 bytes
意思是annotation长度过长了,原因是apply和create的处理不同改配置文件中这个选项的长度就不改了,不用
apply使用create:
这里没有报错就没有问题
但运行完之后要查看一下 tigera-operator 运行是否正常,如果状态为Running 则继续执行下面的步骤
这里可能会出现 容器创建失败 的情况,查看日志一般是因为镜像拉取失败,查看配置文件关于镜像的部分,这里需要单独拉取镜像

shell
sudo ctr images pull quay.io/tigera/operator:v1.32.5拉取之后,重新创建配置,一般就没有问题了
shell
kubectl delete -f tigera-operator.yaml
kubectl create -f tigera-operator.yaml 第二步将配置文件下载下来,因为要改内容:
shell
# 下载客户端资源文件
curl -LO https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/custom-resources.yaml这个文件中的 192.168.0.0 为你刚才 init 时指定的 --pod-network-cidr:
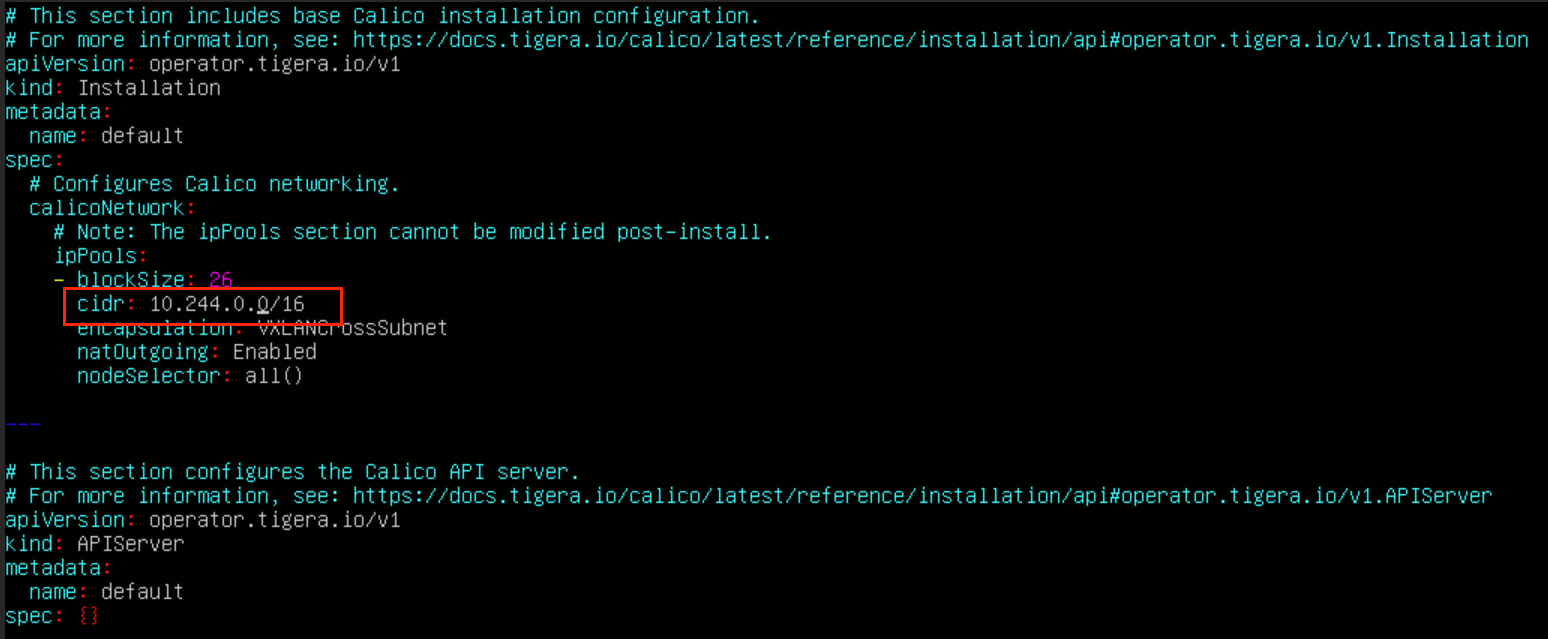
shell
# 修改pod的网段地址
sed -i 's/cidr: 192.168.0.0/cidr: 10.244.0.0/g' custom-resources.yaml最后根据这个文件创建资源,执行下面这行命令:
shell
kubectl create -f custom-resources.yaml但是,在最后这部分,初始化的网络插件,总会出现镜像拉取失败的问题,但是相关的配置文件中,并没有找到镜像相关的配置,且日志中也没有提到拉取哪个镜像失败,至此 Calico 安装失败
Flannel 安装
Flannel 安装,参考K8S安装网络插件flannel
shell
# 下载配置文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 执行配置文件安装
kubectl apply -f kube-flannel.yml但是同样镜像拉取,会出现问题,这里需要查看配置文件所需要的镜像,然后在国内的源拉取,打上配置文件的标签(当然也可以直接去配置文件中,更改镜像源地址,但是配置文件非常多,一行一行找效率并不高)

这里粘贴一下源地址https://docker.aityp.com/r/docker.io/flannel/flannel?page=1
shell
ctr images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel:v0.25.5
ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel:v0.25.5 docker.io/flannel/flannel:v0.25.5
ctr images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1
ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1 docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1镜像拉取之后,删除文件配置并重新创建
shell
kubectl delete -f kube-flannel.yml
kubectl create -f kube-flannel.yml至此,flannel 创建没有问题,但是查看网络插件发现,仅有主节点的 flannel pod是Running状态,工作节点的状态均有问题,只有主节点的状态变为了 Ready,工作节点仍未 NotReady ,查日志并没查到问题,没有解决。
/flannel:v0.25.5
ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel:v0.25.5 docker.io/flannel/flannel:v0.25.5
ctr images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1
ctr images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1 docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1
镜像拉取之后,删除文件配置并重新创建
```shell
kubectl delete -f kube-flannel.yml
kubectl create -f kube-flannel.yml至此,flannel 创建没有问题,但是查看网络插件发现,仅有主节点的 flannel pod是Running状态,工作节点的状态均有问题,只有主节点的状态变为了 Ready,工作节点仍未 NotReady ,查日志并没查到问题,没有解决。