基础概念
[1. YOLO简介](#1. YOLO简介 "1. YOLO简介")
YOLO(You Only Look Once):是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
[2. 目标检测算法](#2. 目标检测算法 "2. 目标检测算法")
-
RCNN:该系列算法实现主要为两个步骤:先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右;然后对每个候选区进行对象识别。检测精度较高,但速度慢。
-
YOLO:将筛选候选区域与目标检测合二为一,大大加快目标检测速度,但准确度相对较低。
[3. 评价指标](#3. 评价指标 "3. 评价指标")
3.1. IOU
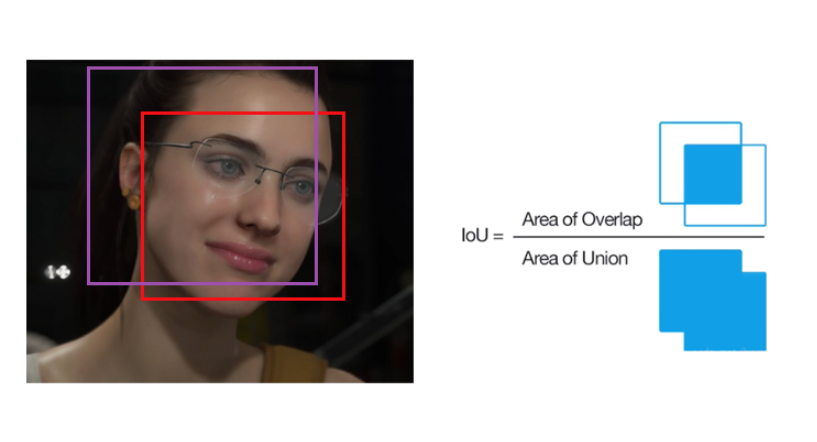
IOU(Intersection over Union):交并比,候选框(candidate bound,紫色框)与原标记框(ground truth bound,红色框)的交叠率,IOU值越高,说明算法对目标的预测精度越高。
- Area of overlap:原标记框与候选框的交集面积
- Area of union:原标记框与候选框的并集面积
[3.2. 置信度](#3.2. 置信度 "3.2. 置信度")

confidence:预测框里存在检测目标的可信度,当置信度大于设定阈值时,就认为该预测框内有检测目标, 即通过「置信度」来实现对「待检测目标」与「背景」的划分。
confidence=Pr(Object)∗IOUpredtruthconfidence=Pr(Object)∗IOUpredtruth
- Pr(Object)Pr(Object),候选框里存在物体的概率;
- IOUpredtruthIOUpredtruth,「预测框」与原标记框的交叠率。
- 预测框: 从一堆「候选框」中,选择了一个效果最好的当作「预测框」,一般取最值IOUpredtruth=max(IOU0,IOU1,⋯ ,IOUB)IOUpredtruth=max(IOU0,IOU1,⋯,IOUB)
[3.3. 二分类指标](#3.3. 二分类指标 "3.3. 二分类指标")
在「二分类」任务中,对样本的描述:
- Position:正例,二分类中的一类样本,一般是想要的
- Negative:负例,二分类中另一类样本,一般是不想要的
- TP(True Position):在拿出样本中,正确识别为正例
- FP(False Position) :在拿出样本中,错误识别为正例,即本身是负例(误判)
- TN(True Negative) :未拿出样本中,正确当负例舍弃
- FP(False Negative) :未拿出样本中,错误当负例舍弃,即本身是正例(遗漏)
二分类结果的评判指标:
- 精度(Accuracy):正确分类样本占总样本的比列Accuracy=TP+TNTP+FP+TN+FNAccuracy=TP+FP+TN+FNTP+TN
- 准确度(Precision):识别正确的样本占被拿出样本的比列Precision=TPTP+FPPrecision=TP+FPTP
- 查准度(Recall):识别正确的样本占目标样本总数的比列Recall=TPTP+FNRecall=TP+FNTP
3.4. AP
[3.4.1. 问题](#3.4.1. 问题 "3.4.1. 问题")
!tip 由于 Precision 与 Recall 只适用于「二分类问题」。当存在多样本分类时,对每一类样本单独考虑其「二分类问题」,即目标样本与其他样本的分类问题。
当确认的样本越少,出错的风险也就越小;当选择出的样本量越大,得到全部目标样本的可能性越大。因此 Precision 与 Recall 是一度矛盾的关系
- Precision 较大时,Recall 较小:当要分辨 10 个苹果时,我只拿出一个苹果,那么 Precision 就是
100 %,而 Recall 确是10 % - Precision 较大时,Recall 较小:若选择出 100 个水果,10 个苹果我们都拿出来了,但是还有 90 个其他水果。Precision 就是
10 %,而 Recall 是100 %
[3.4.2. Precision-Recall曲线](#3.4.2. Precision-Recall曲线 "3.4.2. Precision-Recall曲线")
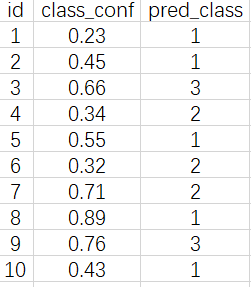
假设模型的任务为从图片中,检测出三类物体:(1,2,3)。「一张图片」的模型预测结果如下所示
现在对每一类别分别绘制 Precision-Recall曲线:
-
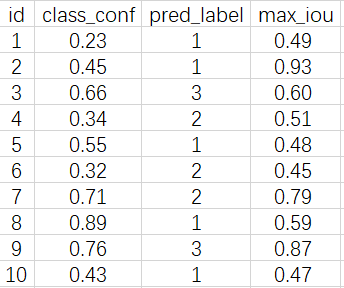
每个预测的 box 与其分类对应的所有 Ground True box 进行 IOU 计算,并选择出最大的 IOU 作为输出结果。 认为当前预测 box 就是 IOU 最大的这个 Ground True box 的预测结果。(若多个预测box 与同一个 Ground True box 相对应,则只记录一个)
-
将
max_iou与给定阈值thresh = 0.5进行比较,大于阈值就标记1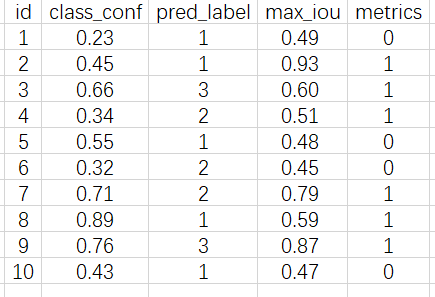
-
数据根据「分类置信度
class_conf」 进行排序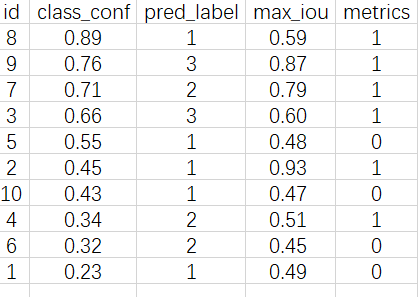
-
取出分类 1
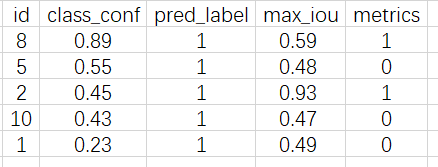
-
假设在当前图片中,存在
3个 1 类目标,计算其 Precision 与 Recall。根据上面的结果,假设只找出 1 个 1 类目标时:

假设只找出 2 个 1 类目标时
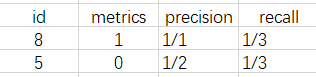
假设只找出 3 个 1 类目标时
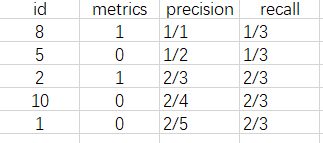
以此类推,找出全部时
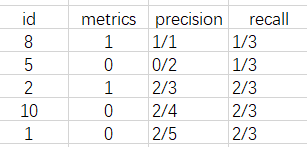
-
根据上述 Precision 与 Recall 序列绘制出的曲线,就是 1 类别目标对应的Precision-Recall曲线,重复上述步骤,就是绘制出 2, 3 类别的曲线。 根据Precision-Recall曲线就能计算 AP 值了。
!note\|style:flat
- 根据上述阈值
thresh_50 = 0.5的不同取值,就能计算得到不同的 AP 类型,例如thresh = 0.5就是 AP50;thresh = 0.75就是 AP75。计算多个 AP 类型,然后取均值,就是 「mAP」。例如mAP=AP50+AP75+AP80+⋯nmAP=nAP50+AP75+AP80+⋯- 上述计算流程只是处理了「一张图片」的预测结果。对于多张图片的处理,则是对每张图片分别进行步骤1、步骤2,最后将所有的图片结果全部堆叠起来,进行后续步骤处理。
[3.4.3. AP 计算](#3.4.3. AP 计算 "3.4.3. AP 计算")
AP(Average Precision):Precision-Recall曲线下方的面积。结合 Precision 与 Recall ,更加全面的对模型的好坏进行评价。
-
绘制完整的 Precision-Recall曲线:将 Precision 与 Recall 绘制成曲线。
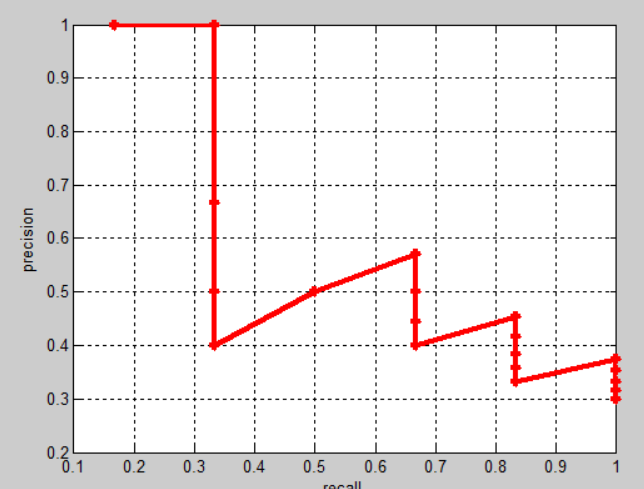
-
查找 precision 突然变大的点
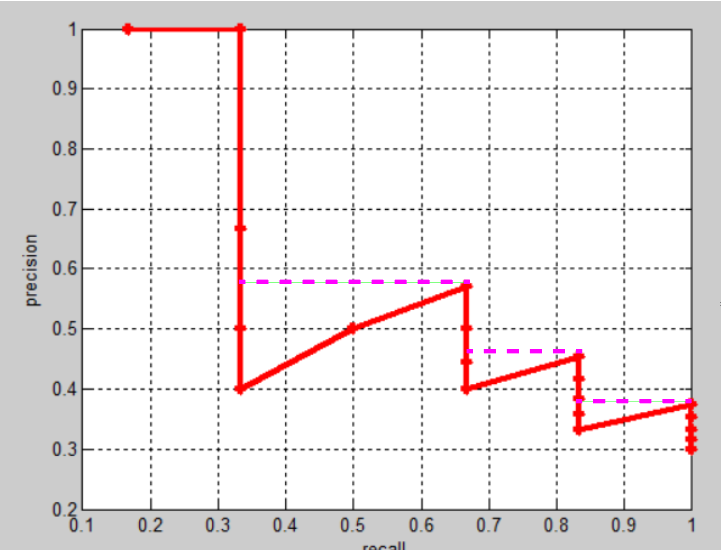
-
利用这个突变点来代表这个区间内的 Precision

-
最后计算彩色矩形区域的面积,该值就是 AP
YOLO - V1
1. 网络模型
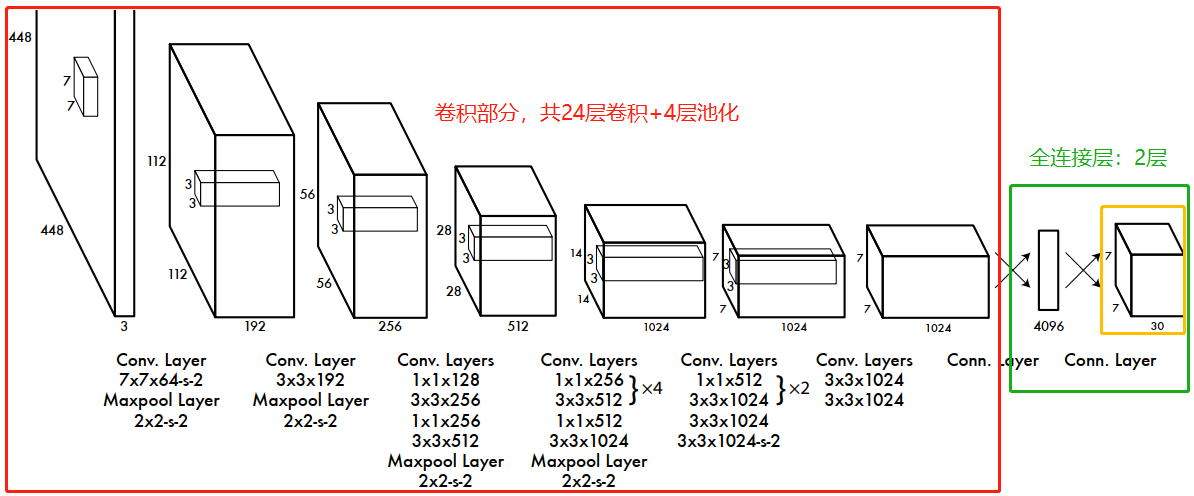
对于第一版 YOLO 的网络模型就两个部分:卷积层、全连接层。
-
输入: 尺寸为
448x448x3的图片, 图片尺寸定死 -
输出: 图片中被检测目标的位置(矩形框坐标)与被检测物体的分类。
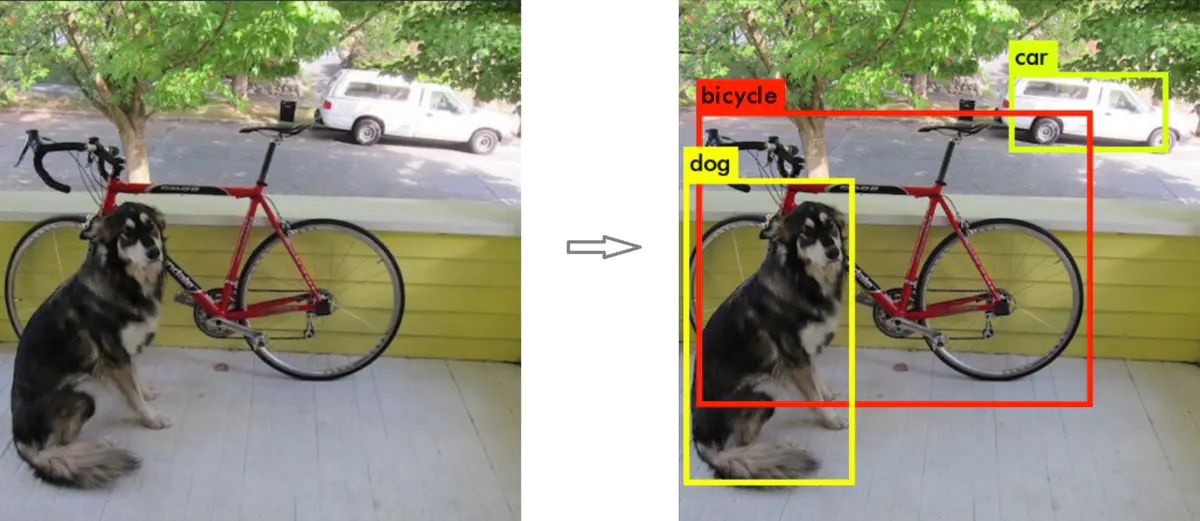
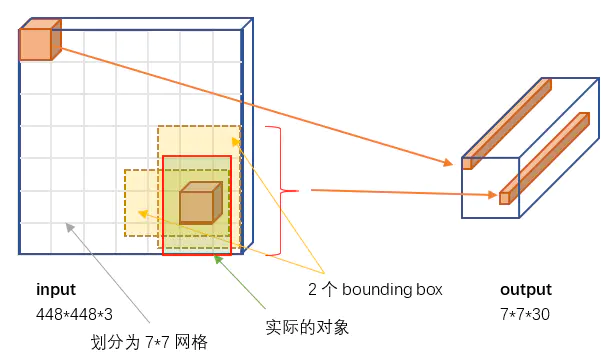
2. 目标检测原理

-
将输入图片通过
7x7网格,划分为49个单元格 -
每个单元格负责一个检测目标:存储检测目标外接矩形的「中心点坐标」、长宽;存储检测目标的类型。 即当检测目标的外接矩形「中心点坐标」位于该单元格内时,就让该单元格全权负责储存这个检测目标的信息。
-
每个单元格持有
2个候选矩形框,会通过置信度选择一个最好的当作预测结果输出
3. 模型输出
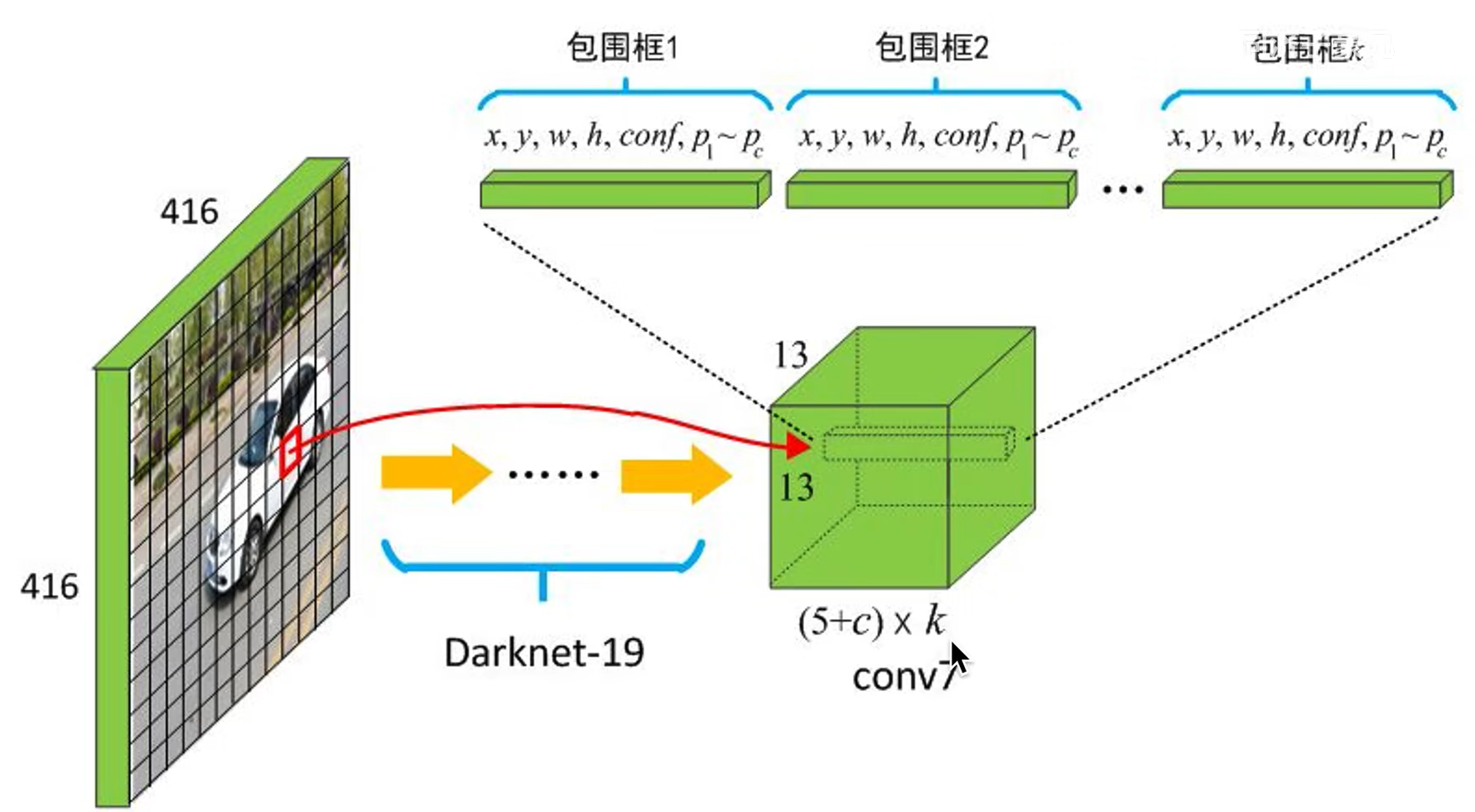
V1 版本的输出结果为 7x7x30 的一个向量,对该向量进行维度转换得到
其中 7x7 表示利用 7x7 的网格,将输入图片划分为 49 个单元格;30 表示对每个单元格预测结果的描述:两个目标位置候补框、置信度、目标的分类

- bounding box 1 :第一个候补框的参数,外接矩形中心坐标 (x1,y1)(x1,y1) ;长宽 (w1,h1)(w1,h1)
- confidence 1 :第一个候补框是待检测目标的置信度
- bounding box 2 :第二个候补框的参数,外接矩形中心坐标 (x1,y1)(x1,y1) ;长宽 (w1,h1)(w1,h1)
- confidence 2 :第二个候补框是待检测目标的置信度
- 分类:检测目标为
20个分类的概率
Note
其中,对于中心坐标 (x,y)(x,y) 、长宽 (w,h)(w,h) 值的存储是一个百分比。
- 中心坐标 (x,y)(x,y) :相对单元格长宽的比值
- 长宽 (w,h)(w,h):相对于输入图片长宽的比值
4. 损失函数
4.1. 定义
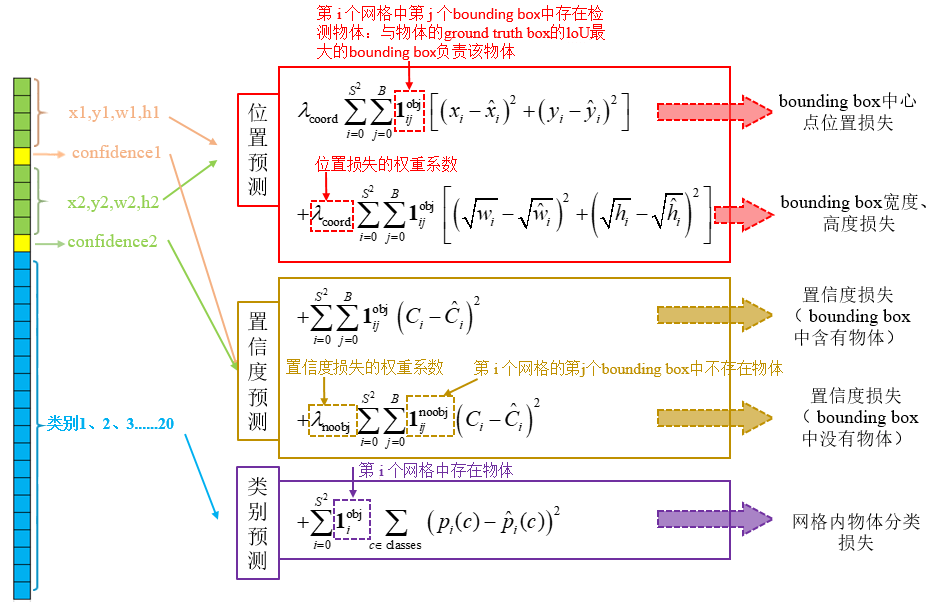
-
ii:表示对
SxS的单元格的索引,将二维数组将维为一维数组进行处理 -
jj:对
B个候补矩形的索引 -
1iobj1iobj:标记单元格中是否存在检测目标,存在值为
1,不存在值为0。 -
1ijobj1ijobj:标记单元格的「候补框」中是否存在检测目标,存在值为
1,不存在值为0 -
1ijnoobj1ijnoobj:标记单元格的「候补框」中是否存在检测目标,存在值为
0,不存在值为1 -
C^C^:期望输出的置信度
-
存在目标时:
C^=Pr(Object)∗IOUpredtruthC^=Pr(Object)∗IOUpredtruth
都认为是存在目标了,那么 Pr(Object)=1Pr(Object)=1
-
不存在目标时:
C^=0C^=0
-
4.2. 位置预测

当预测外接框与目标外接框的宽度、高度的差值一样时,对于较大的物体而言相对误差小,而对于较小物体而言相对误差较大。因此为了让损失函数对小物体的外接矩形的宽度、高度更敏感一些,在 YOLO V1 中采用了 「根号」: 自变量在0,1取值时,根号的斜率变化比直线要大。
5. 模型预测
5.1. 思路
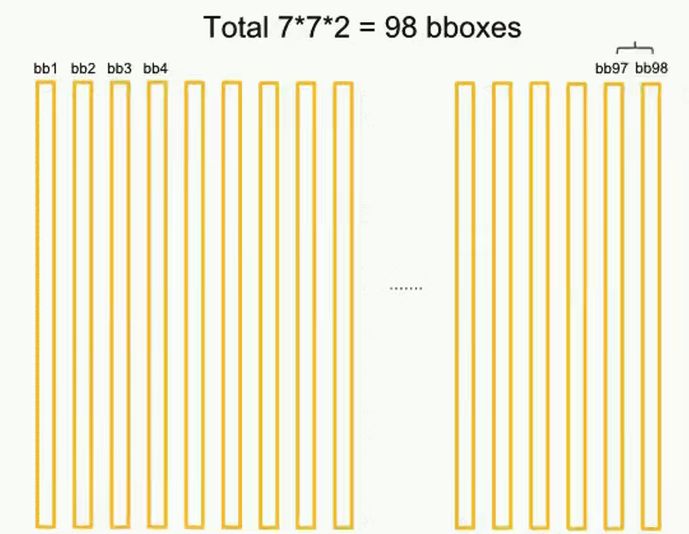
训练好的 YOLO 网络,输入一张图片,将输出一个 7x7x30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。每个单元格有两个 bounding box ,一共有 7x7 个单元格,现在将所有的 7x7x2=98 个 bounding box 绘制出来

可以看见图上到处都是 bounding box,现在就需要从这些 bounding box 中,筛选出能正确表示目标的 bounding box。
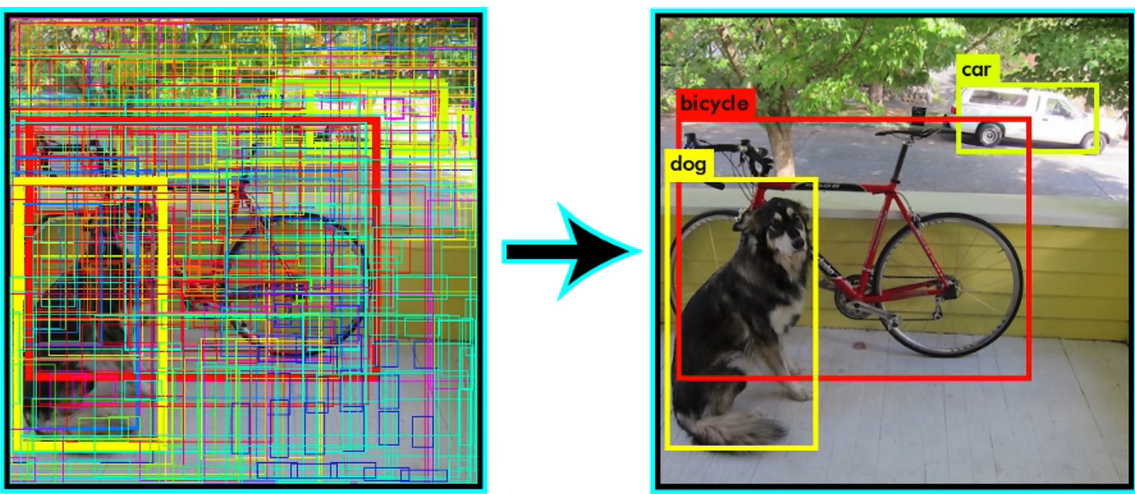
为了实现该目的, YOLO 采用 NMS(Non-maximal suppression,非极大值抑制)算法。
5.2. 筛选步骤
-
计算每个 bounding box 对应分类的得分
Scoreij=Pi(C)∗CjScoreij=Pi(C)∗Cj
其中 CjCj 是 bounding box 置信度;Pi(C)Pi(C) 不同分类对应的概率。将计算结果写成矩阵形式
-
对 Score 矩阵里面的所有得分进行检测,将得分小于阈值的全部设置为零
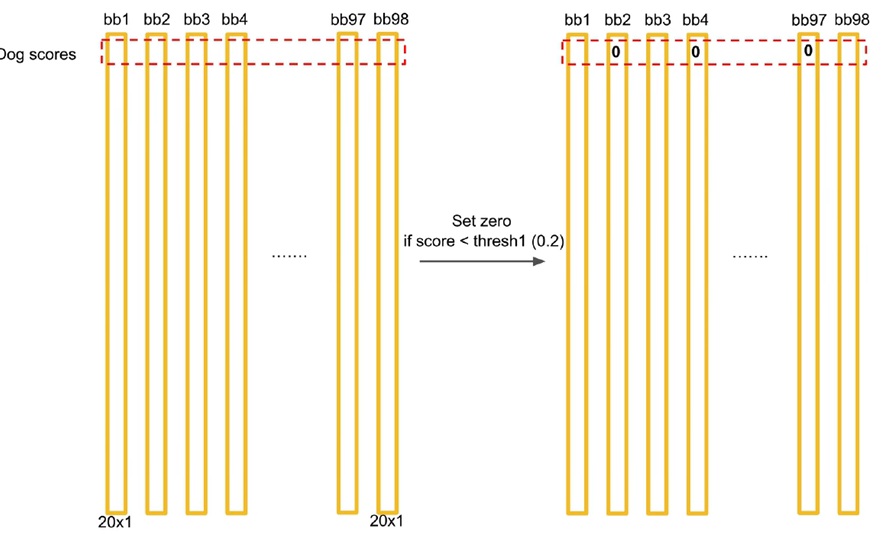
-
由于这里存在
20个分类,因此需要对不同的分类进行分开处理。在得分矩阵中,每一行就对应一个分类。 -
对一行分类的 Score 进行排序,并对排序好的类型进行极大值抑制处理。
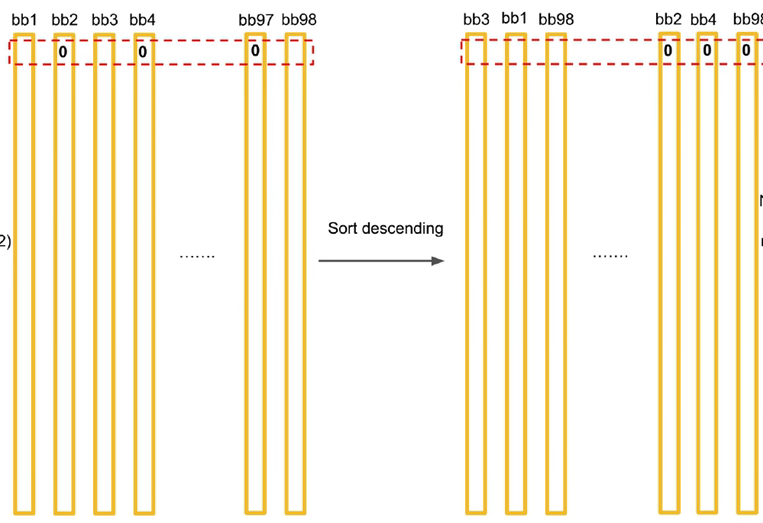
-
重复步骤4,完成对所有分类的处理。
5.3. 极大值抑制
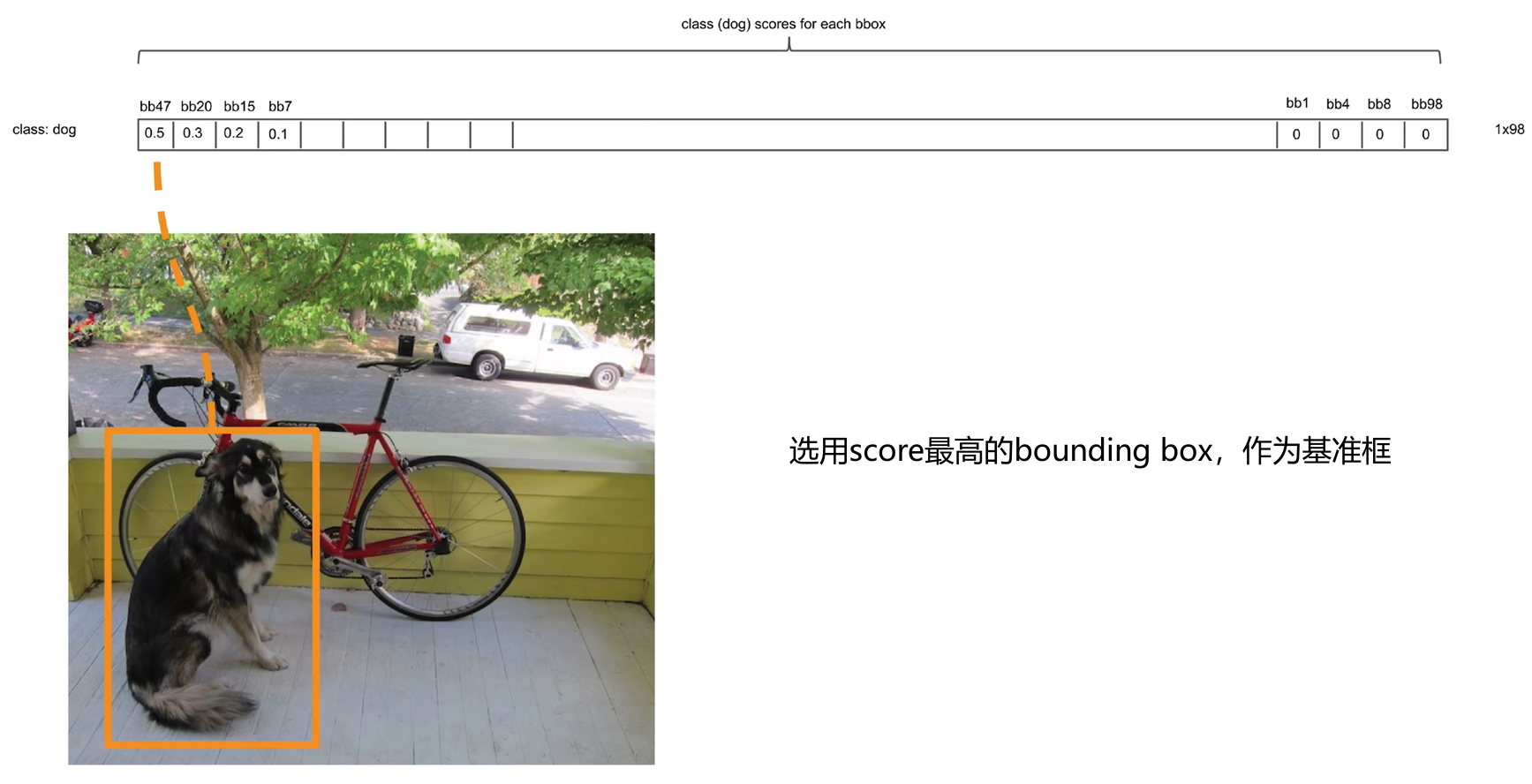
2. 之后 Score 不为零的 bounding box 都要与「基准框」计算 IOU。然后对这些 bounding box 进行过滤
IOU>0.5IOU>0.5
- 不等式成立:认为当前的 bounging box 与「基准框」都是标记的同一目标,重复了,因此就需要将当前 bounding box 的 Score 置为 0
- 不等式不成立:认为当前的 bounging box 与「基准框」标记的是不同目标,当前 bounding box 需要保留
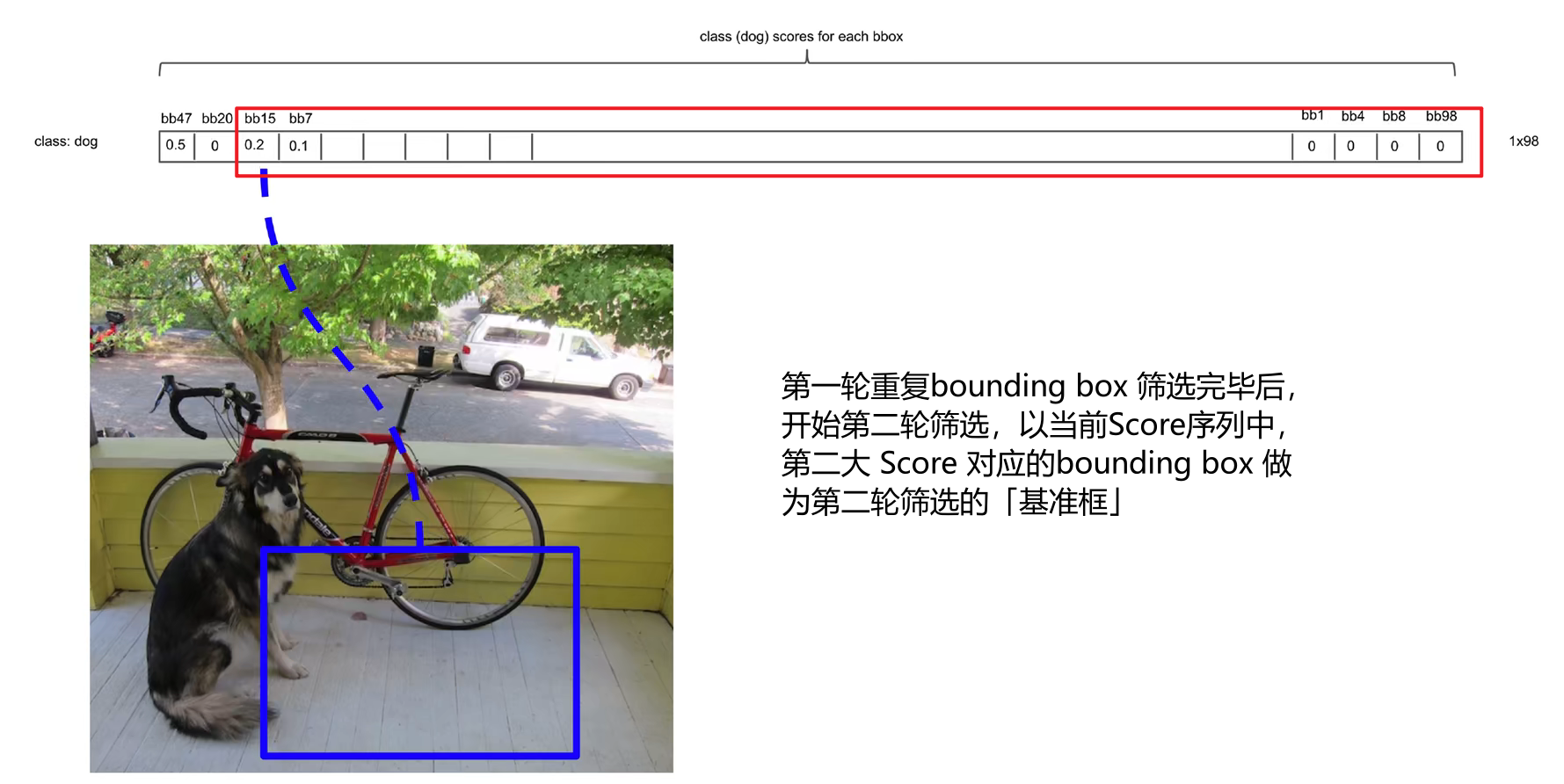
4. 重复步骤 2 ,消除与当前「基准框」重合的 bounding box 。
- 重复上述步骤,直到所有的重复 bounding box 都消除。
YOLO - v2
1. 模型改进
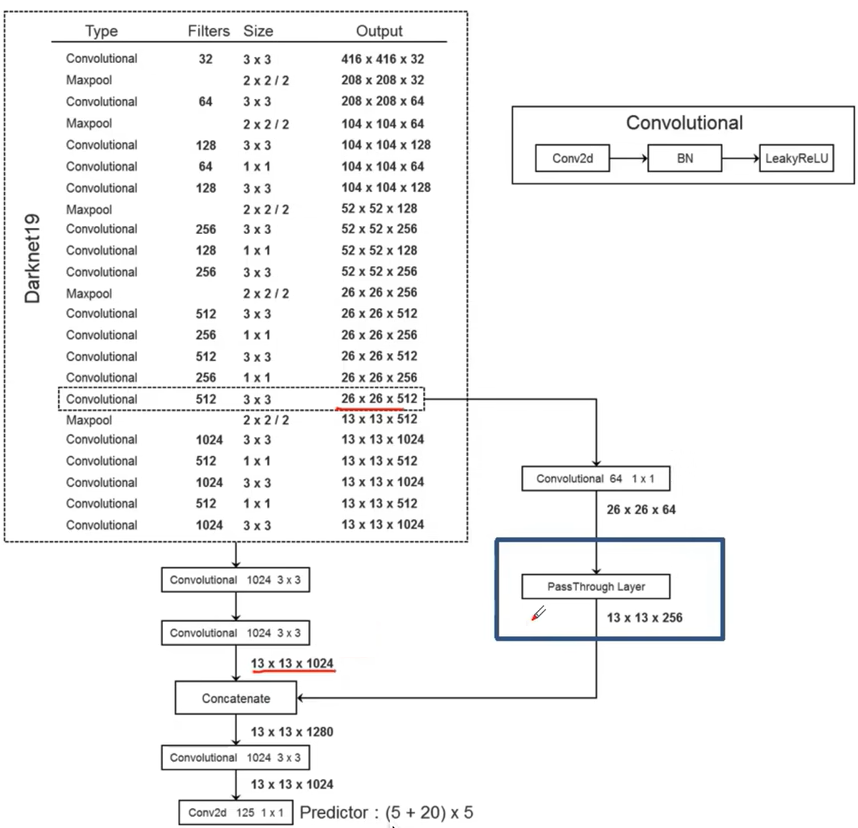
1.1. 卷积化
在 V1 中,最后的输出结果是靠「全连接层」得到的,这也就限制了输入图片的尺寸。因此在 V2 将所有的全连接层转为了卷积层,构造了新的网络结果 DarkNet19,其中还利用 1x1 卷积对模型进行优化。
1.2. Batch Nomalization
在 DarkNet19 网络中,对于卷积层加入了 Batch Normalization,并删除了 dropout。
由于 DarkNet19 做了 5 次池化且卷积均进行了padding,所以输入图片将会被缩放 25=3225=32 倍,即 448x448 的输入,输出结果应当是 448/32=14,但是14x14的结果没有特定的中心点,为了制造一个中心点,模型的输入图片尺寸就更改为了416x416,输出结果就变为了13x13。
1.3. Fine-Grained Features
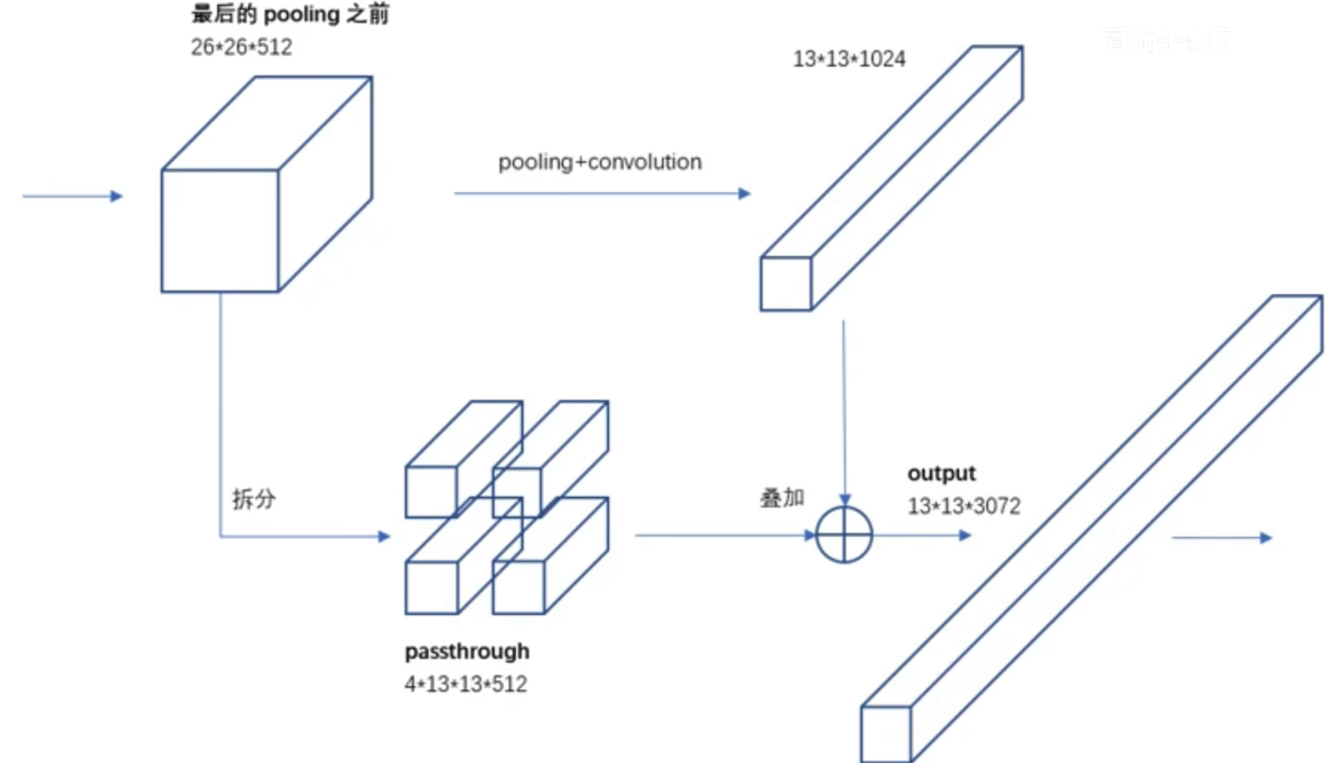
在 DarkNet19 模型中,存在一个 PassThrough Layer 的操作,该操作就是将之前阶段的卷积层结果与模型输出结果进行相加。根据 感受野可知,越靠前的网络层对细节的把握越好,越靠后的网络更注重于目标整体,为了使得输出结果对小物体有更好的把握,就可以利用 PassThrough Layer 来提升结果特征图对小物体的敏感度。
1.4. 图片输入
由于历史原因,ImageNet分类模型基本采用大小为 224x224 的图片作为输入,所以 YOLO V1 模型训练使用的输入图片大小其实为 224x224,在模型预测时,又使用的是 448x448 的图片作为输入,这样就导致模型的训练和模型的预测,输入其实是有差异的。为了弥补这个差异,模型训练的最后几个 epoch 采用 448x448 的图片进行训练。
2. Anchor Box
YOLO V1 的 bounding box 缺陷:
- 一个单元格只能负责一个目标检测的结果,如果该单元格是多个目标的中心点区域时,V1 版本将不能识别。
- V1 中,对于 bounding box 的预测结果并未加限制,这就会导致 bounding box 的中心点可能会跑到其他单元格内
- bounging box 的宽度与高度是靠模型自己学习的,这就可能走很多弯路。
2.1. Anchor
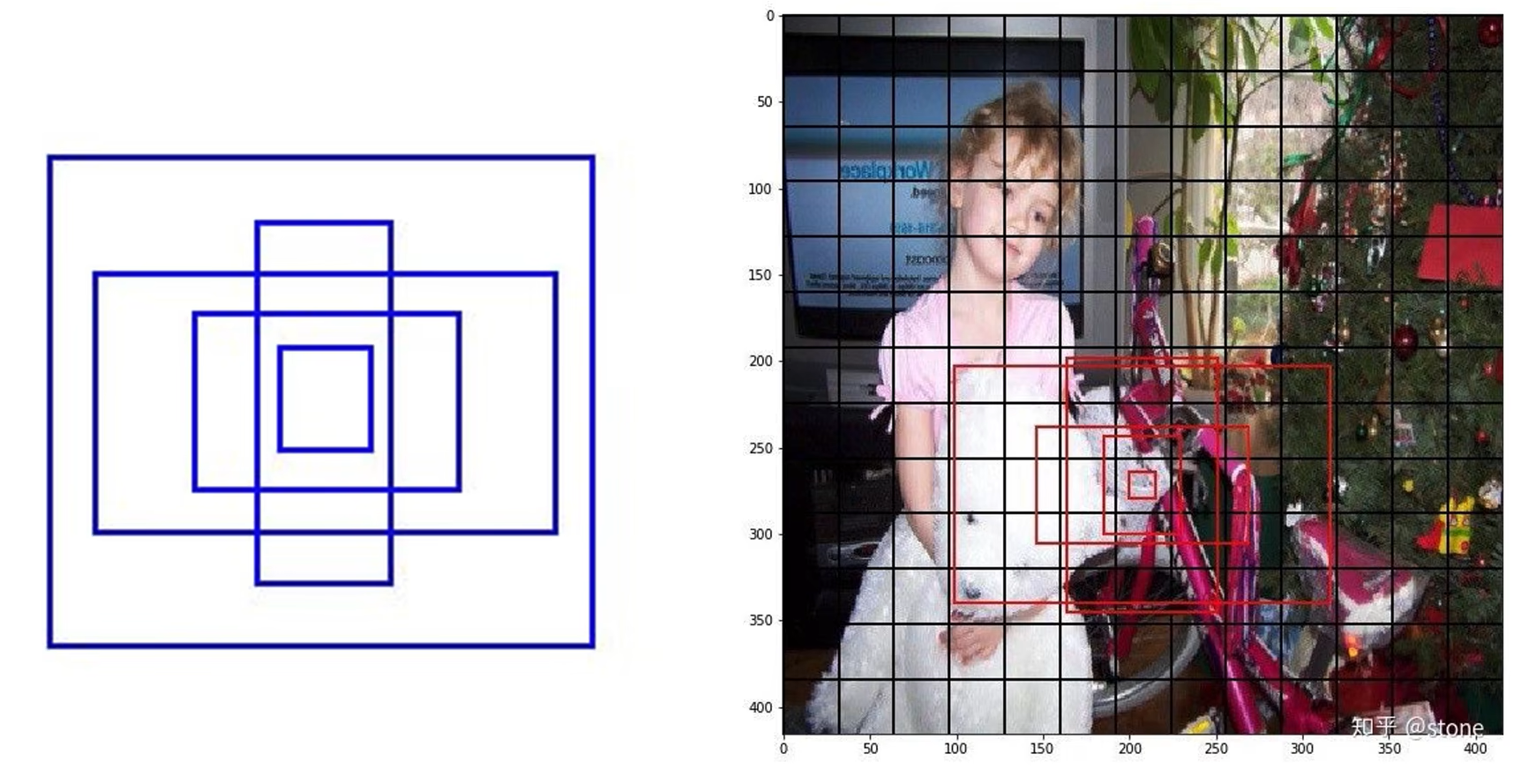
-
模型训练开始前,人为为每个单元格预定义几个不同大小的 Anchor Box,这样从训练开始,每个单元格的bounding box就有了各自预先的检测目标,例如瘦长的 bounging box 就适合找人,矮胖的 bounging box 就适合找车等。
-
模型训练就是调整这些预定义的bounding box 的中心点位置与长宽比列。
2.2. Box 数据结构
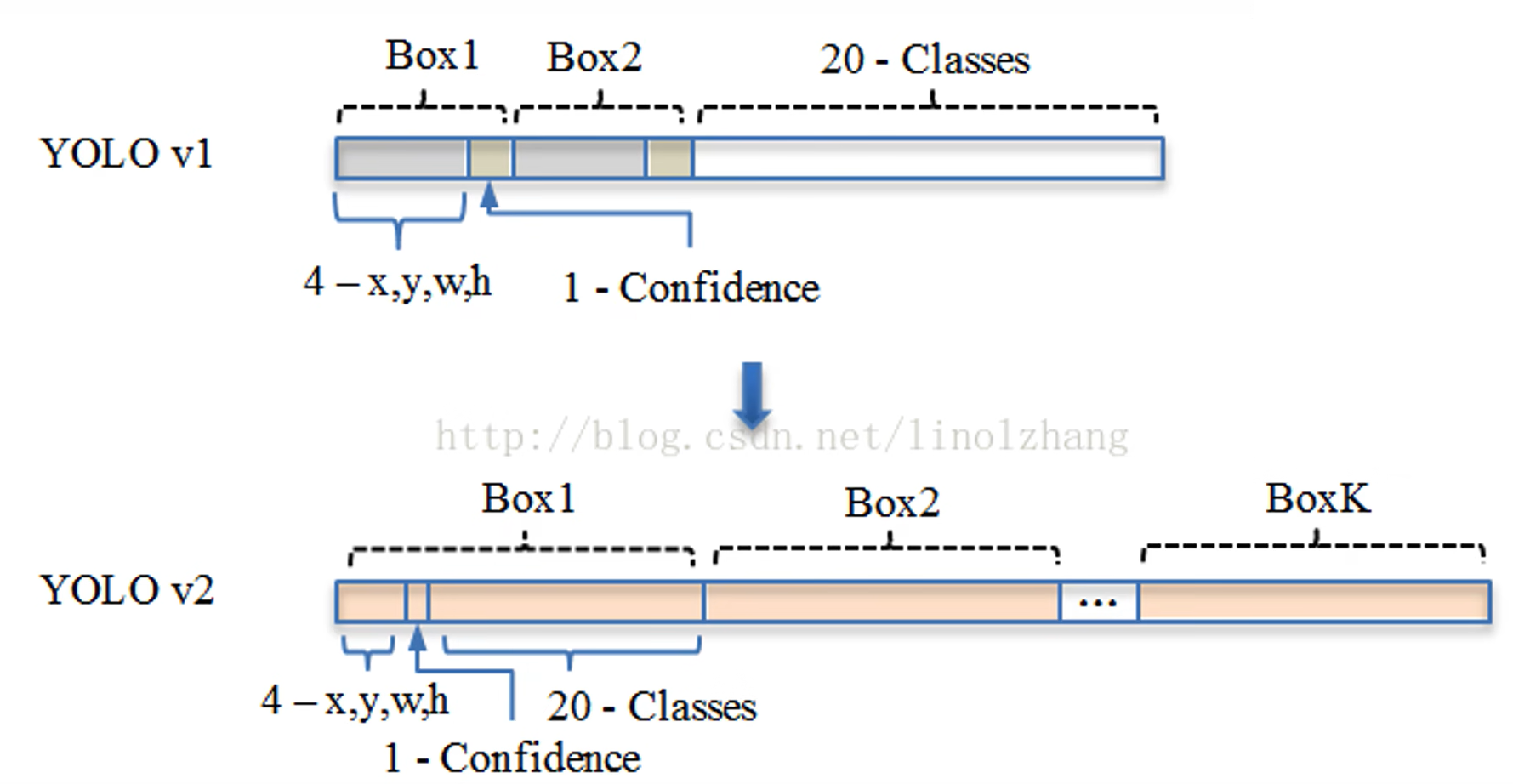
在引入 Anchor box 后, YOLO V2 对于一个 bounging box 的数据结构为:
- 中心点坐标 (x,y)(x,y),相对于单元格宽度的比列值
- 相对于 Anchor box 宽高的偏移量 (w,h)(w,h)
- 当前 bounging box 存在检测目标的置信度 ConfidenceConfidence
- 检测目标对应各个类型的概率 pipi
一个单元格能检测多少目标,就输出多少个上述 Box 数据结构。
2.3. Box 解析
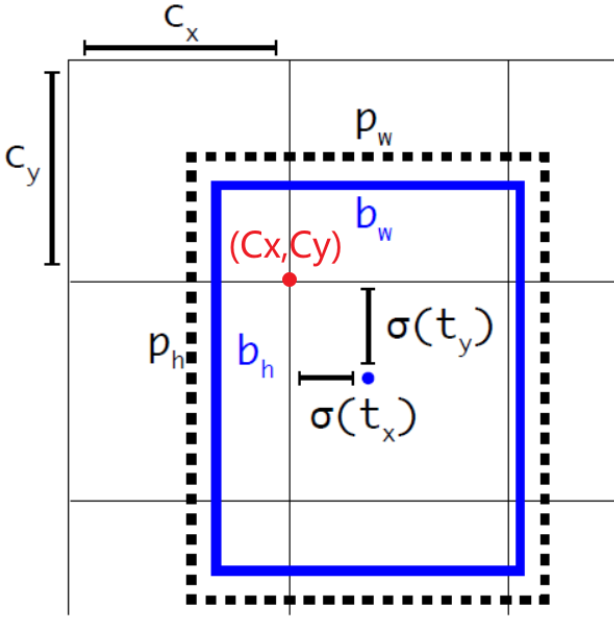
假设一个 bounding box 的输出结果为
tx,ty,th,tw,to\]\[tx,ty,th,tw,to
-
bounding box 的中心点坐标
bx=σ(tx)+Cxby=σ(ty)+Cybx=σ(tx)+Cxby=σ(ty)+Cy
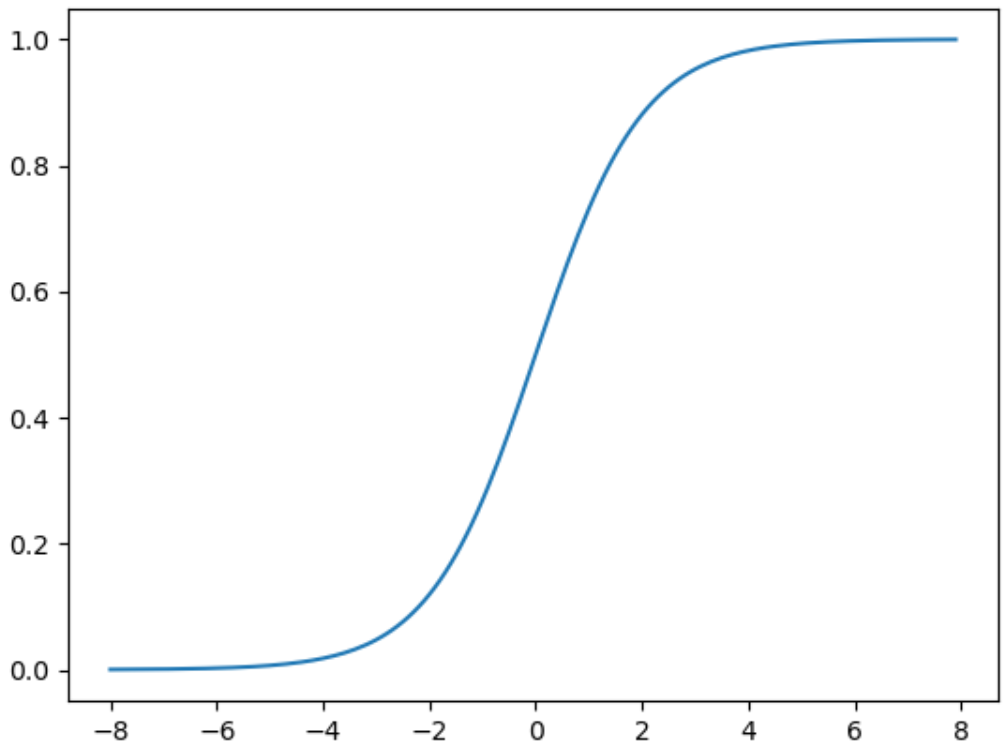
(Cx,Cy)(Cx,Cy) 为单元格在输出网格中,左上角的坐标; σ()σ() 为 sigmod 函数,为了将中心点限制在当前单元格内 。
-
bounding box 的宽度
bw=Pwetwbh=Phethbw=Pwetwbh=Pheth
(Pw,Ph)(Pw,Ph) 为该 bounding box 对应的 Anchor box 的大小;e()e() 的目的和 YOLO V1 一样,只是将原来的 ()() 替换成了 ln()ln()。
-
bounding box 的置信度
Confidence=σ(to)Confidence=σ(to)
2.4. 确定 Anchor
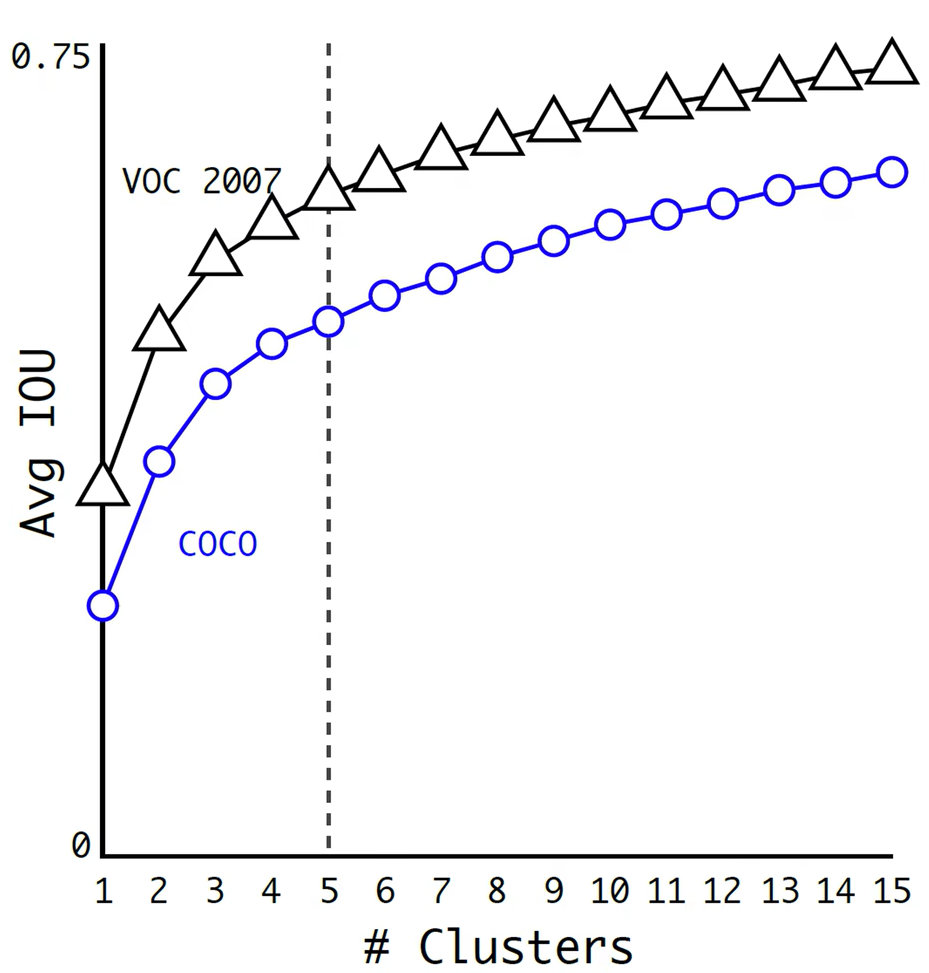
-
K类聚:
- 收集所有训练样本图片中检测目标的期望 bounding box, 只要宽度、高度;不要中心点坐标
- 利用 K-means 类聚算法将上述样本框划分为 k 类,距离计算公式为dcenter=1−IOU(center,box)dcenter=1−IOU(center,box)
- 选择每个类别的中心 bounding box 作为 Anchor box ,一共 k 个
-
k 的确定: 作者对 VOC 与 COCO 数据集,进行测试后,选择了 k=5k=5
3. 损失函数
YOLO - SPP
1. SPP介绍
YOLO SPP 属于是 YOLO V3 的 PRO 改进版本。在原始 yolo v3 的基础上增加了 Mosaic 数据增强、spp网络层、位置损失函数改进。
2. Mosaic 图像增强
-
思路: 将四张图片进行随机裁剪,再拼接到一张图上作为训练数据

-
优点:
- 增加样本多样性
- 增加一张图片中的目标数,利于多目标训练
- Batch Normal 一次能统计多张图片的结果
3. SPP 网络
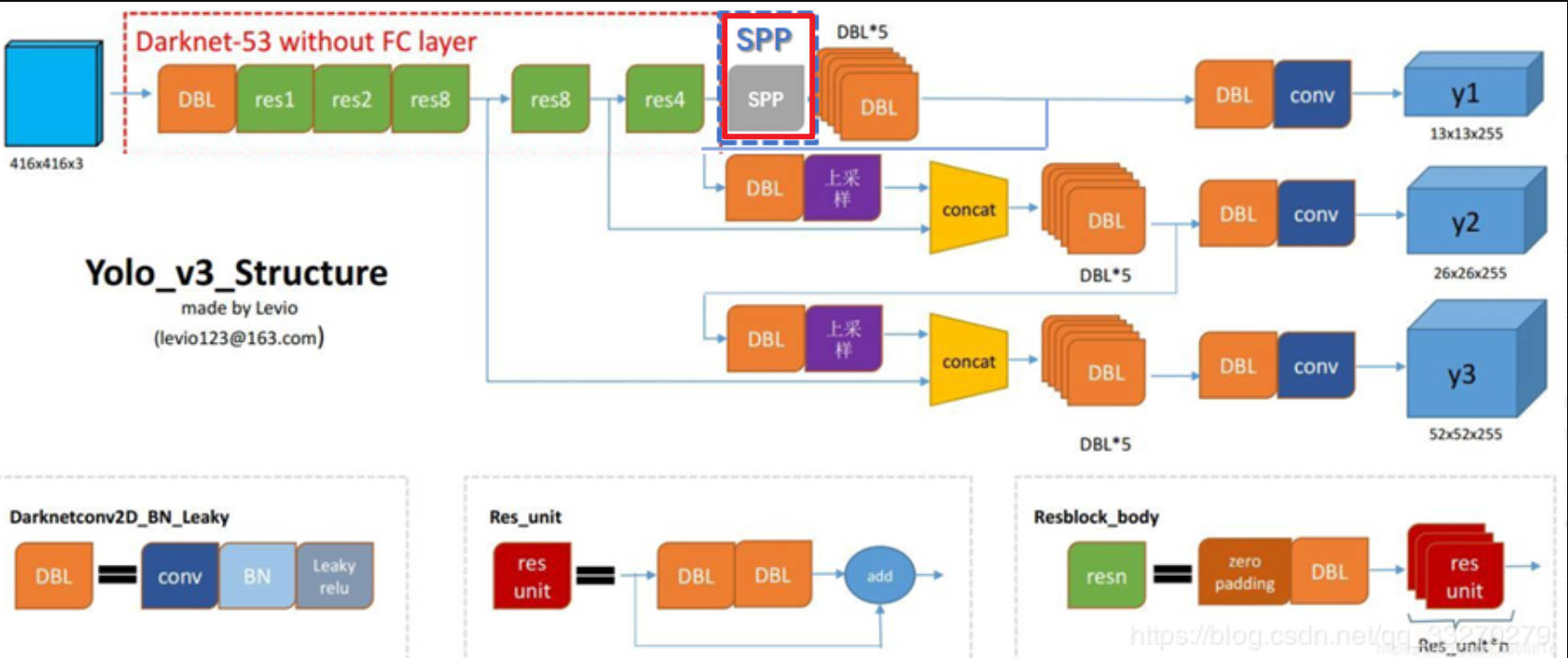
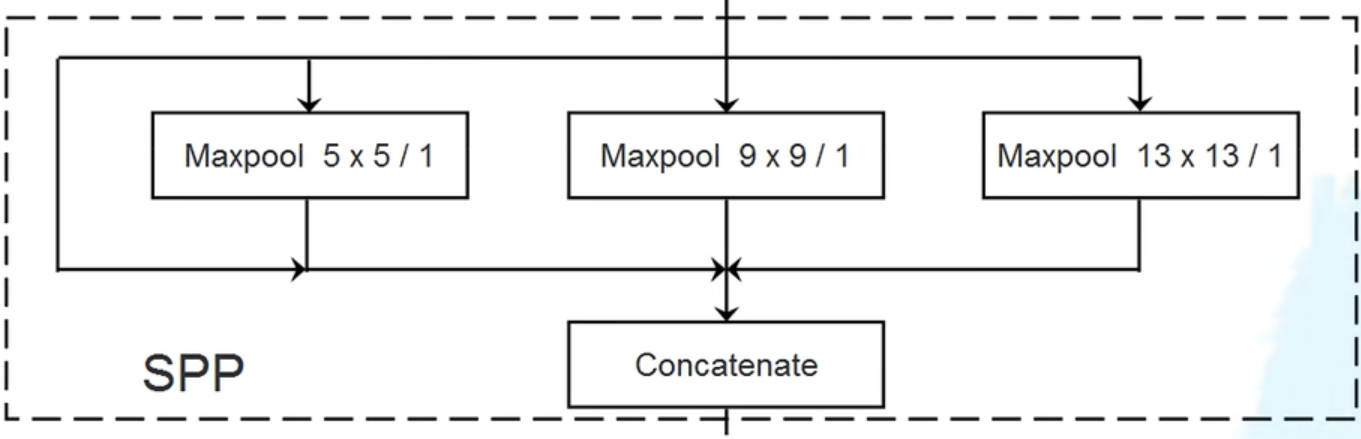
YOLO SPP 的网络在原v3的基础上增加了一层 SPP 网络层。SPP 网络的工作原理是对输入进行三次不同 kernel 的最大池化操作,且池化后特征图的尺寸不变,最后的三次池化结果在通道维度上直接拼接作为输出结果。
4. IOU 位置损失
4.1. L2 位置损失缺陷
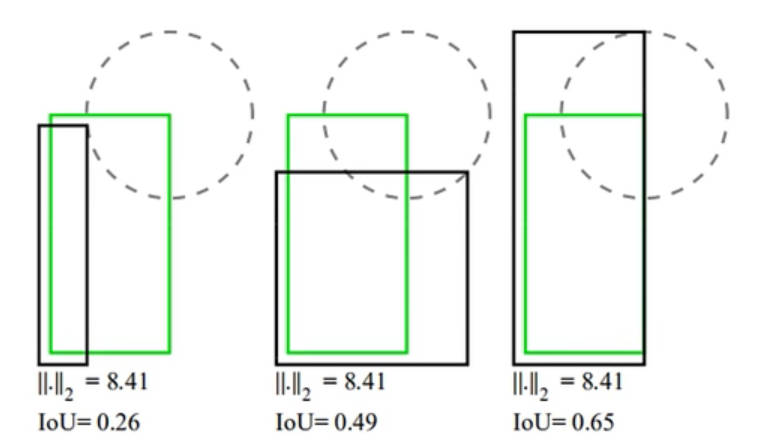
上面三种预测框与 Ground True Box 的匹配情况,原 v3 的 L2 位置损失函数计算得到损失结果是一样的,但是根据肉眼观察,明显第三种预测要优于其余两种预测结果。因此,L2 损失不能很好反应预测框与真实框相重合的优劣程度。
4.2. IOU 损失
-
原理: 基于预测框与 Ground True Box 的 IOU 来反映预测结果与期望结果的位置损失
IoU loss=1−IoUIoU loss=1−IoU
-
缺点:IOU 的取值范围为 0,1。当预测框与 Ground True Box 不存在重叠部分时,IOU恒等于0。这就导致预测框与 Ground True Box 不管相差多远,损失值都是恒定的,不利用网络学习。
4.3. GIOU 损失
-
GIOU定义:
GIoU=IoU−Ac−uAcGIoU=IoU−AcAc−u
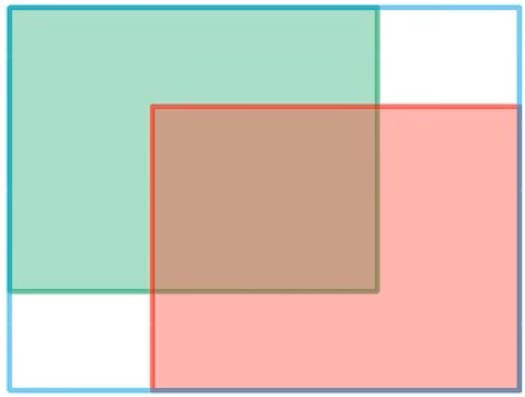
其中 AcAc 为预测框与 Ground True Box的外接矩形框面积(蓝色线框);uu 为预测框与 Ground True Box的并集。当预测框与 Ground True Box完全重合时,GIoU=1GIoU=1;当预测框与 Ground True Box 距离无限远时,GIoU=−1GIoU=−1
-
GIOU损失:
GIoU loss=1−GIoUGIoU loss=1−GIoU
-
GIOU缺点: 当预测框与 Ground True Box 高度(宽度)一样时,在水平(垂直)方向上,GIoUGIoU 会退化为 IoUIoU
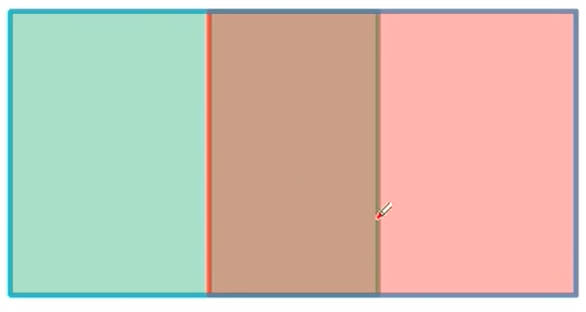
4.4. DIOU 损失
-
DIOU定义:
DIoU=IoU−d2c2DIoU=IoU−c2d2
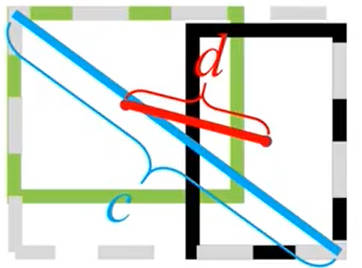
其中 dd 为预测框与 Ground True Box中心点之间的距离
-
DIOU 损失:
DIoU loss=1−DIoUDIoU loss=1−DIoU
-
优点: 收敛速度要快于 IOU 与 GIOU 损失
4.5. CIOU 损失
-
CIOU定义:
CIoU=IoU−d2c2−αvv=4π2(arctanwgthgt−arctanwh)2α=v1−IoU+vCIoUvα=IoU−c2d2−αv=π24(arctanhgtwgt−arctanhw)2=1−IoU+vv
-
CIOU损失:
CIoU loss=1−CIoUCIoU loss=1−CIoU
-
优点: DIOU 只考虑了预测框与 Ground True Box 重叠面积、中心距离的几何差异,而 CIOU 在此基础上,增加了「长宽比」的损失,使得损失的计算精度更高。
YOLO - V4
1. 网络结构
1.1. 网络模型
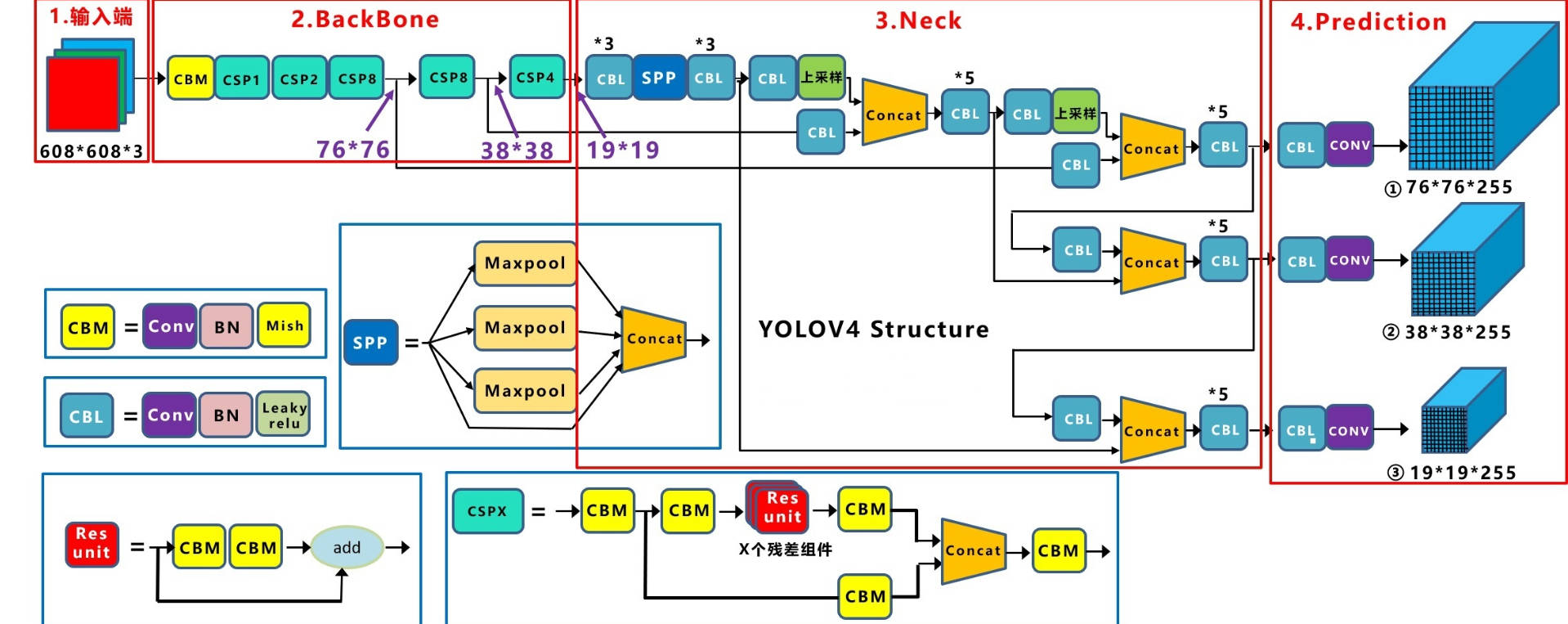
- backbone网络的组成单元不再是 RES 模块,而是 CSP 模块;
- backbone 网络的输出会经过一个 SPP 模块;
- Neck 部分则借鉴了 PAN 模块
1.2. CSP 模块
-
CSP 结构:
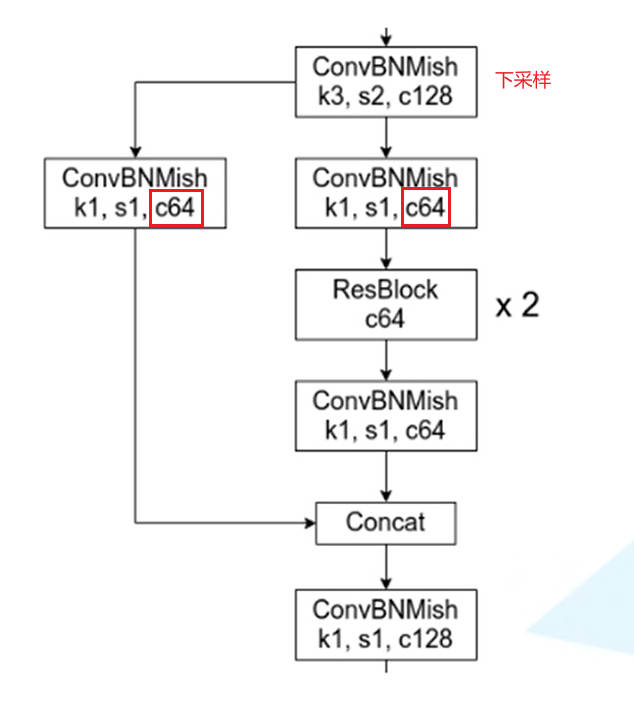
其中 Mish 表示的是 Mish 激活函数
Mish(x)=xtanh(ln(1+ex))Mish(x)=xtanh(ln(1+ex)) -
优点:
- 更快的学习速度
- 减少了内存消耗
- 加快计算速度
1.3. PAN 模块
-
PAN 模块: 先对主干网络从上到下进行特征融合,之后再从下到上进行特征融合得到预测结果
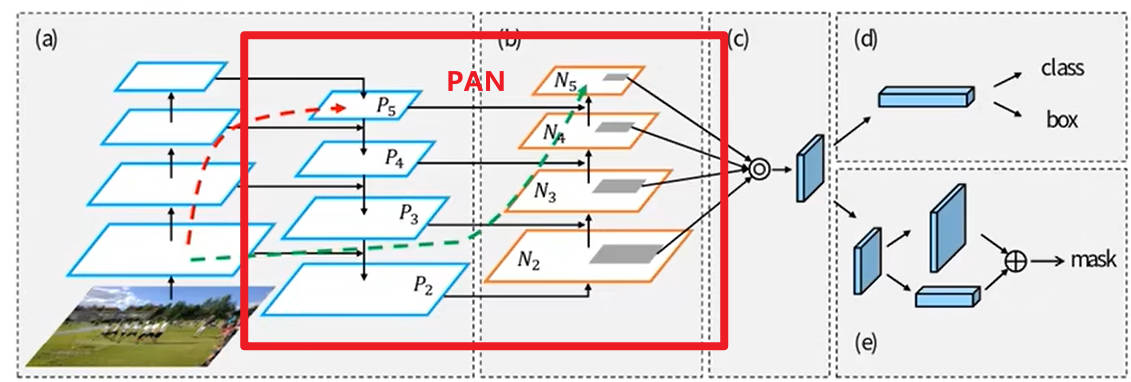
-
YOLO V4 中的实现: 在原来 v3 预测网络的结构上,又进行了一次特征层融合,最终得到最后的输出结果。
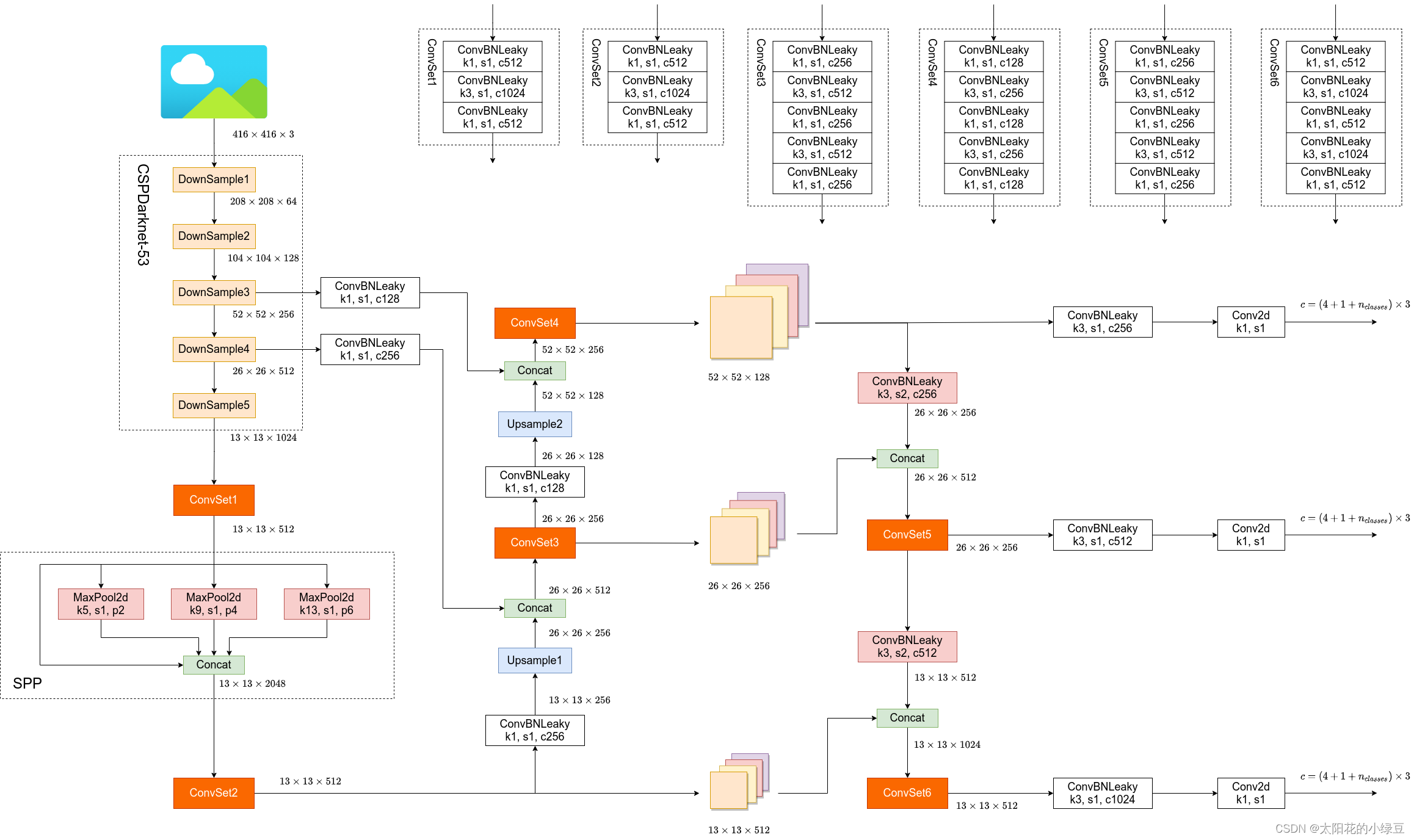
2. 预测框中心坐标改进
外接矩形框中心点坐标为:
bx=σ(tx)+Cxby=σ(ty)+Cyσ(x)=11+e−xbxbyσ(x)=σ(tx)+Cx=σ(ty)+Cy=1+e−x1
在 v2 与 v3 版本中,利用 σ(x)σ(x) 函数来约束 tx,tytx,ty ,约束后的取值范围为 (0,1)(0,1)。当 x⇒+∞x⇒+∞ 时,σ(x)=1σ(x)=1;当 x⇒−∞x⇒−∞ 时,σ(x)=0σ(x)=0,这就导致Ground True Box的中心点在网格边界上时,模型预测困难。 为了解决该问题,在 v4 中将约束后的取值范围进行拓宽,外接矩形框中心点坐标修改为
bx=σ(tx)S−S−12+Cxby=σ(ty)S−S−12+Cybxby=σ(tx)S−2S−1+Cx=σ(ty)S−2S−1+Cy
一般对于 SS 的取值为,S=2S=2
bx=2σ(tx)−0.5+Cxby=2σ(ty)−0.5+Cybxby=2σ(tx)−0.5+Cx=2σ(ty)−0.5+Cy
经过上述公式进行约束后,取值范围就变为 (−0.5,1.5)(−0.5,1.5),就解决了取值范围的问题。
3. 正样本改进
3.1. v3 版本缺点

在 v3 版本中,假设 Ground True Box 与 Anchor Box 中心重合,然后计算 IOU ,并根据 IOU 结果来确定 Ground True Box 与哪个 Anchor Box 所对应,将 IOU 最大的Anchor Box 视为 Ground True Box 的预选框,即正样本(虚线框),而 IOU 大于阈值,但并非最大值的 Anchor Box (点虚线框) 则舍弃,并不参与损失计算。这就使得一个 Ground True Box 只与模型中的一个预测结果所对应。
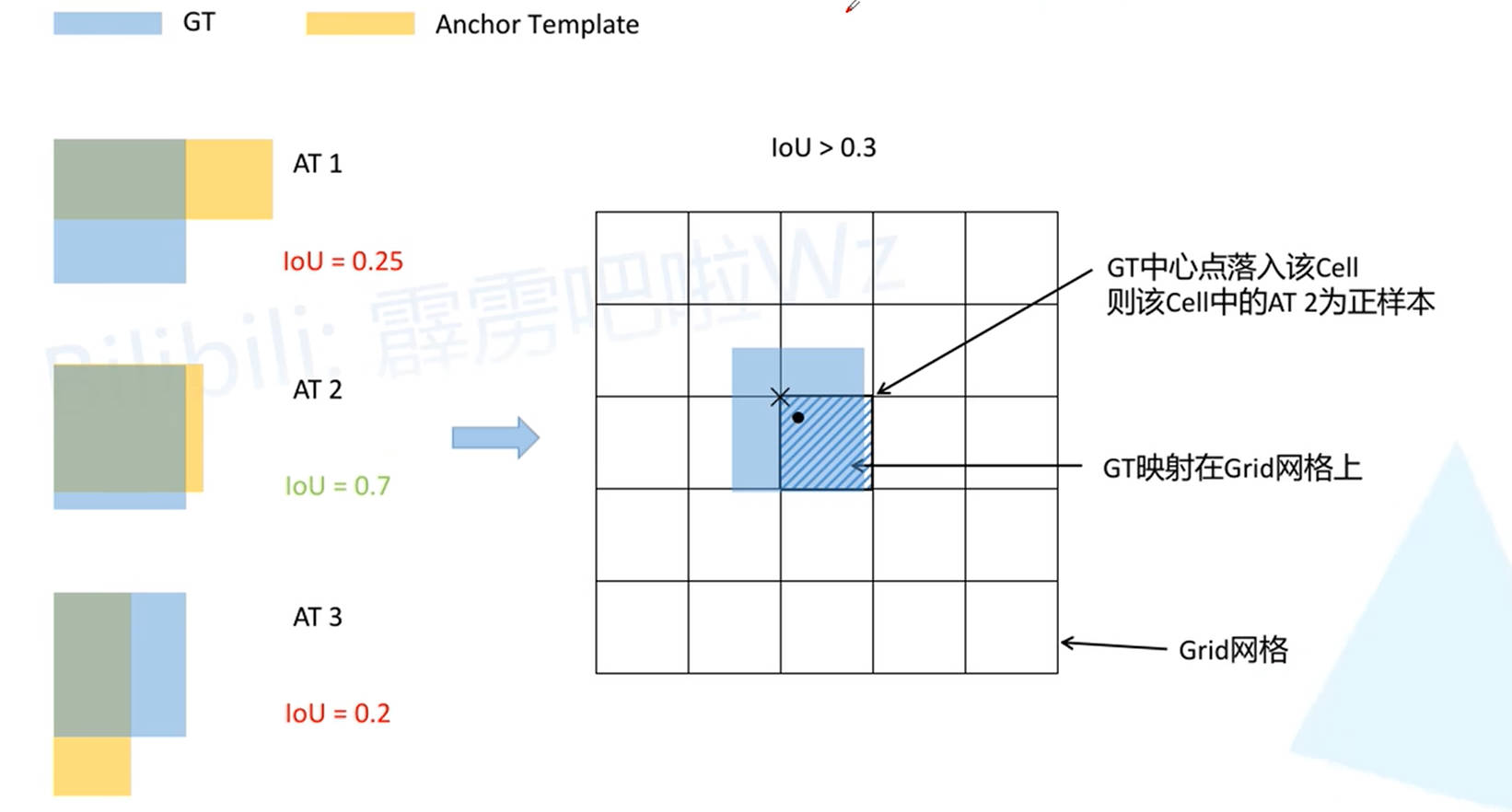
从上述 Ground True Box 与 Anchor Box 的匹配规则中可以看出:对于最终预测结果而言,正样本的数量是远小于负样本数量的。为了提高正样本的数量,v4 对匹配规则进行改进。
3.2. v4 版本改进
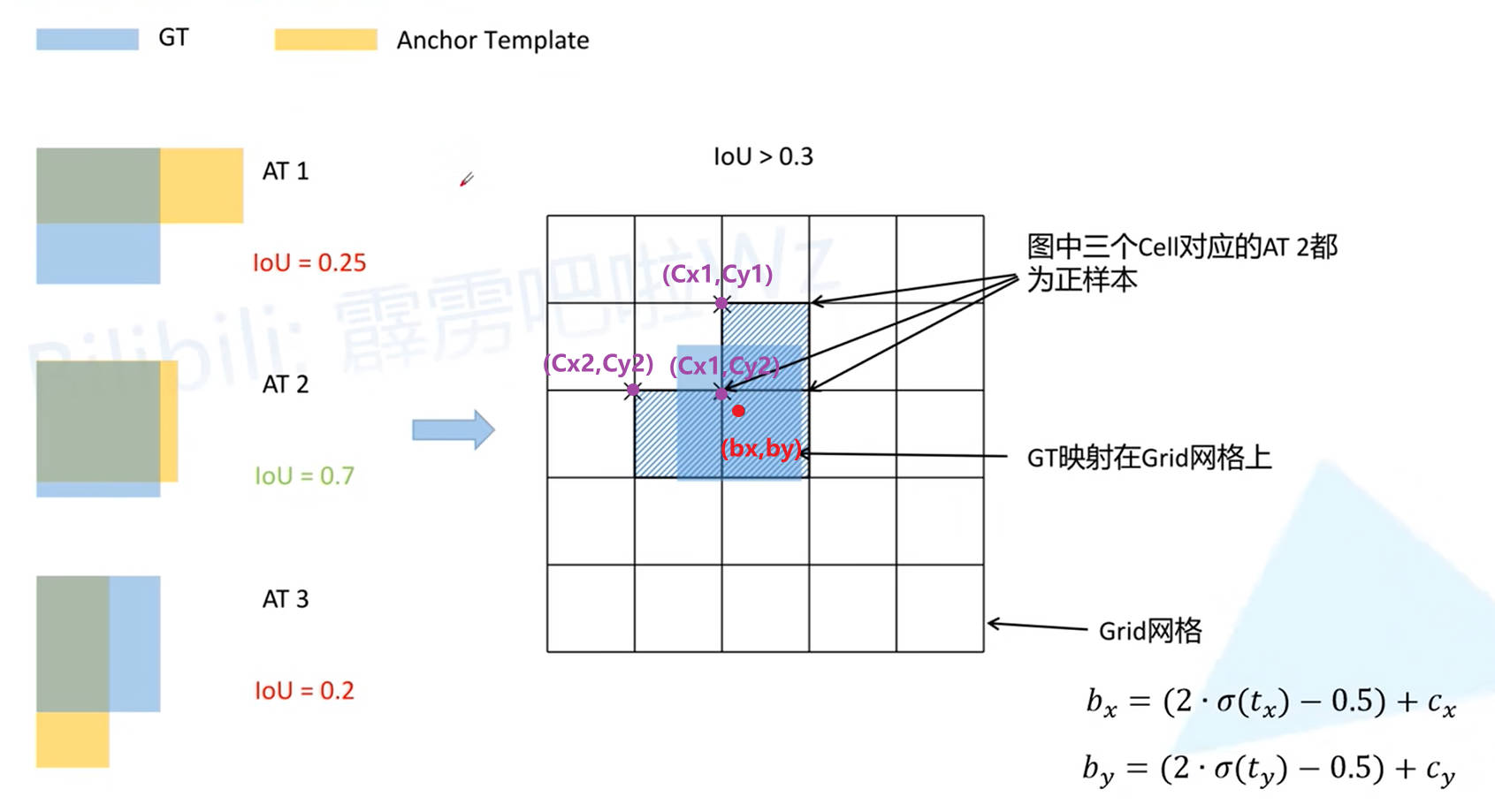
Box 中心点约束取值范围的扩大: (0,1)(0,1) 扩展为 (=0.5,1.5)(=0.5,1.5) ,这就使得一个 (bx,by)(bx,by) 坐标可以通过不同的 (cx,cy)(cx,cy) 进行表示。例如上图中的 (bx,by)(bx,by)
- 根据 v3 版本的定义,(bx,by)(bx,by) 肯定可以通过 (cx1,cy2)(cx1,cy2) 进行描述
- 由于 by<cy1+1.5by<cy1+1.5,(bx,by)(bx,by) 也可以通过 (cx1,cy1)(cx1,cy1) 进行描述
- 由于 bx<cx2+1.5bx<cx2+1.5,(bx,by)(bx,by) 也可以通过 (cx2,cy2)(cx2,cy2) 进行描述
因此,一个 Ground True Box 可以对应预测结果中三个位置的单元格。 至于三个单元格中,哪个 Anchor Box 与 Ground True Box 先对应,则和 v3 版本一样,还是根据 IOU 进行匹配, 但是不同于 v3 版本,在 v4 中,认为所有 IOU 大于阈值的 Anchor Box 对应的预测结果均是与 Ground True Box 对应的正样本。 经过上述处理,正样本数量得到了扩充。
上文只讨论了 Ground True Box 与网格中单元格的一种匹配情况,还有其他不同的匹配情形:
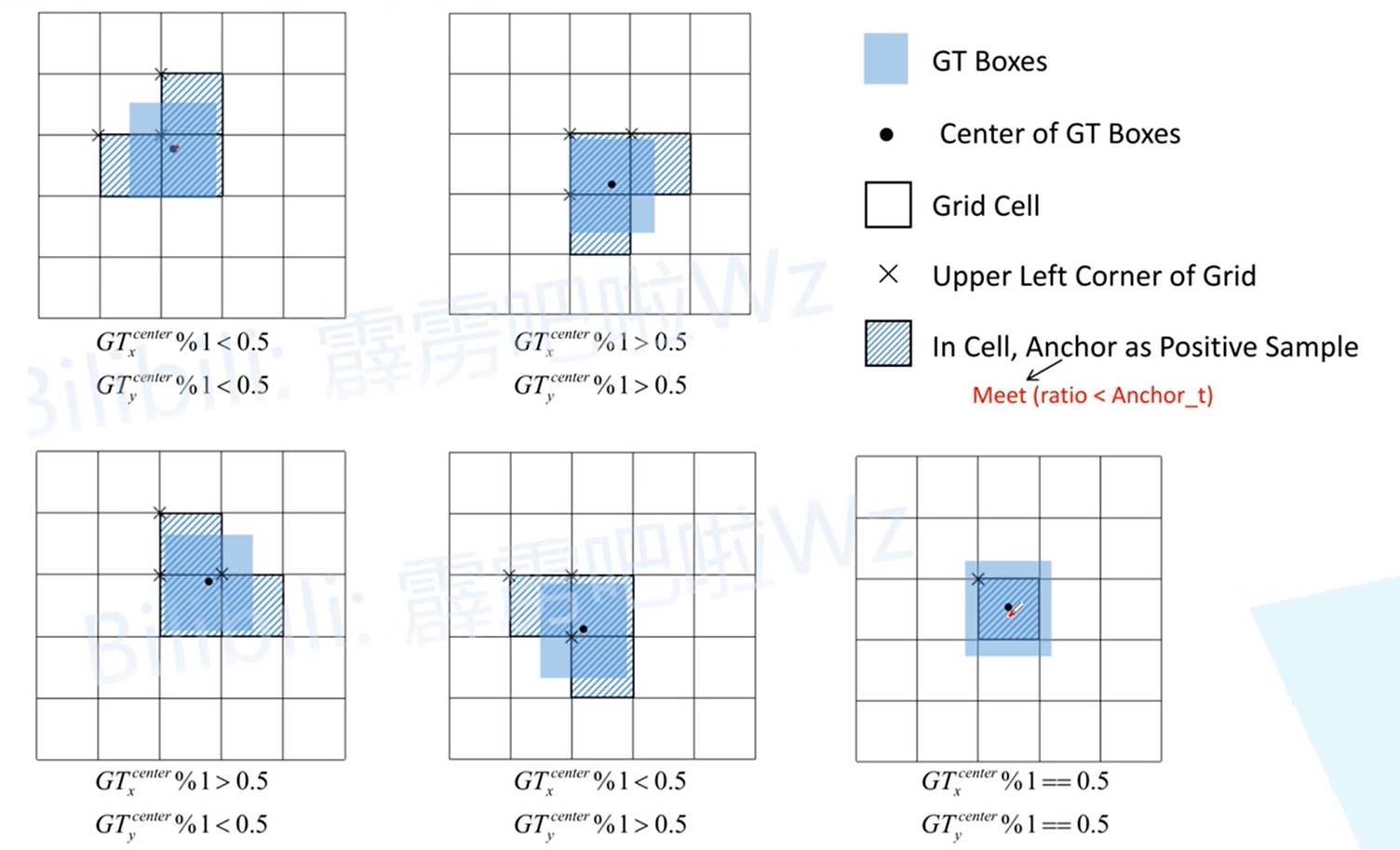
YOLO - V5
1. 网络模型
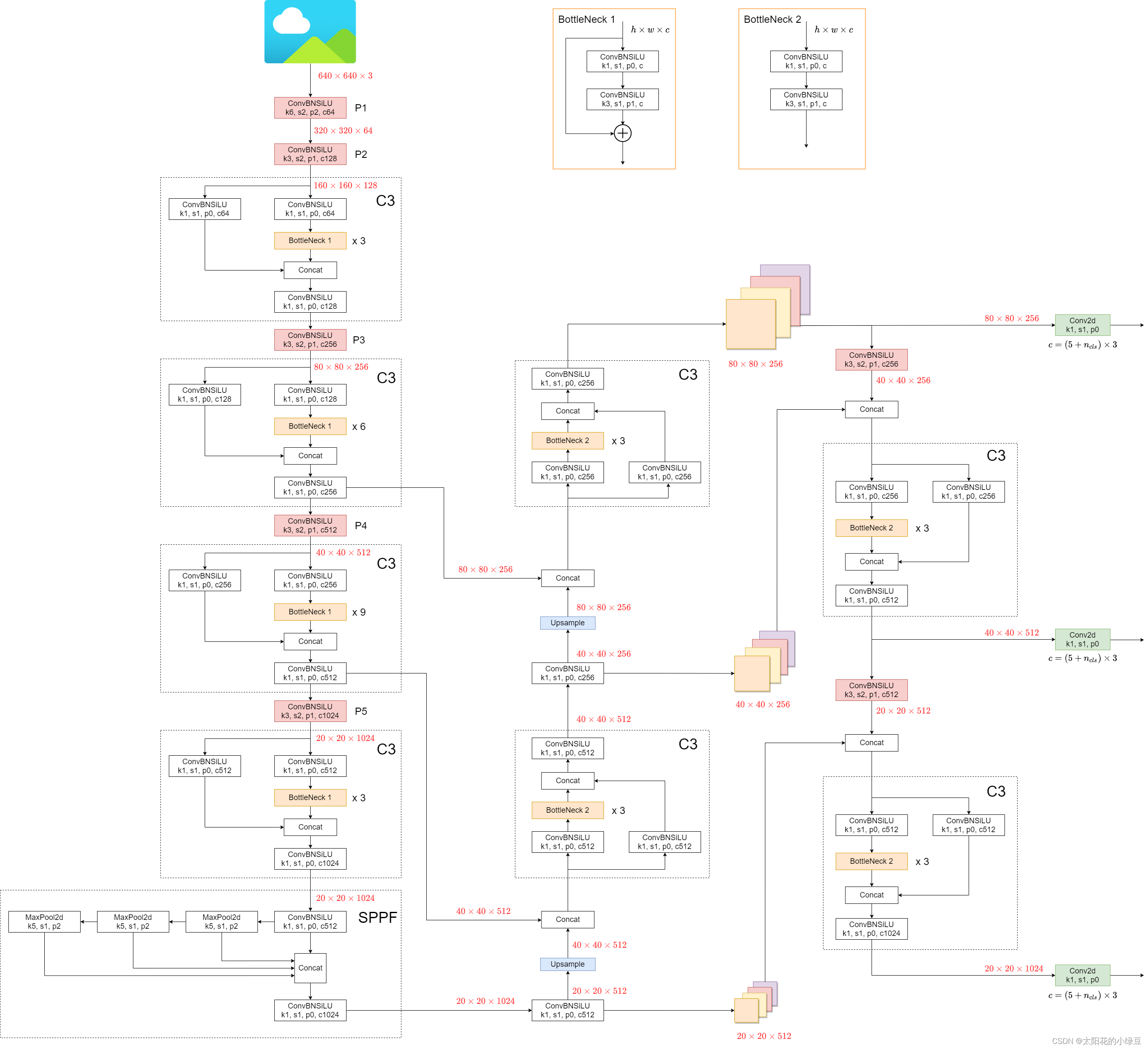
1.1. Focus 模块改进
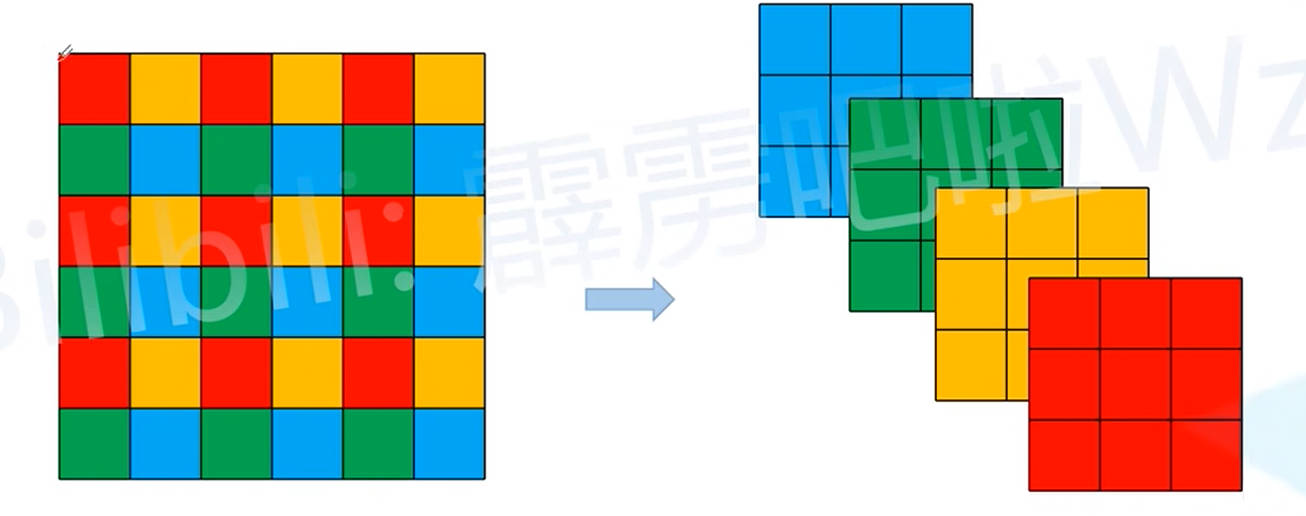
- Focus 模块: 将一个输入图片划分为一个个
2x2的像素块,然后将2x2像素块相同的颜色位置的像素拼接在一起,最终实现输入图片长宽减半,并且通过数变为4。之后在对变换后的结果,通过3x3的卷积核进行卷积。 - 改进方案: 上面的一顿操作,其实和直接对图片进行
6x6卷积核卷积的结果是等效的
1.2. SPPF 模型
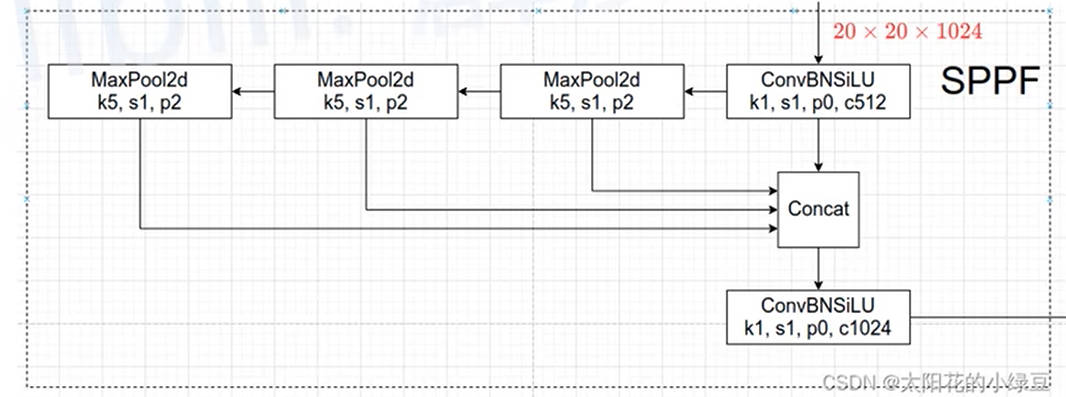
SPPF 模块就是 V4 中的 SPP 模型改进,运算结果是等效的,但是计算速度更快(类似于 OpenCV 中,利用多次简单高斯模糊来代替一次复杂的高斯模糊,这可以使得计算量降低,上一步的计算结果可以重复利用,并且最终计算结果等价)。
2. 置信度损失
-
描述的不再是当前预测结果中是否存在检测目标的概率,而是预测结果与 Ground True Box 的 CIOU。
-
加权合并不同尺度的置信度损失,对于不同预测尺度对应的损失值,给定不同的权重
confLoss=4 confLoss13+1 confLoss26+0.4 confLoss52confLoss=4 confLoss13+1 confLoss26+0.4 confLoss52
3. 预测框宽高改进
在 v2 - v4 版本中,预测框的宽高计算公式如下
bw=Pwetwbh=Phethbw=Pwetwbh=Pheth
可以看出,对于 Anchor Box 宽高的调节比列 exex 是没有最大值限制的。因此,在 v5 中将宽高的调节比列修改为
bw=Pw2σ(tw)2bh=Ph2σ(th)2bwbh=Pw2σ(tw)2=Ph2σ(th)2
4. 正样本匹配改进
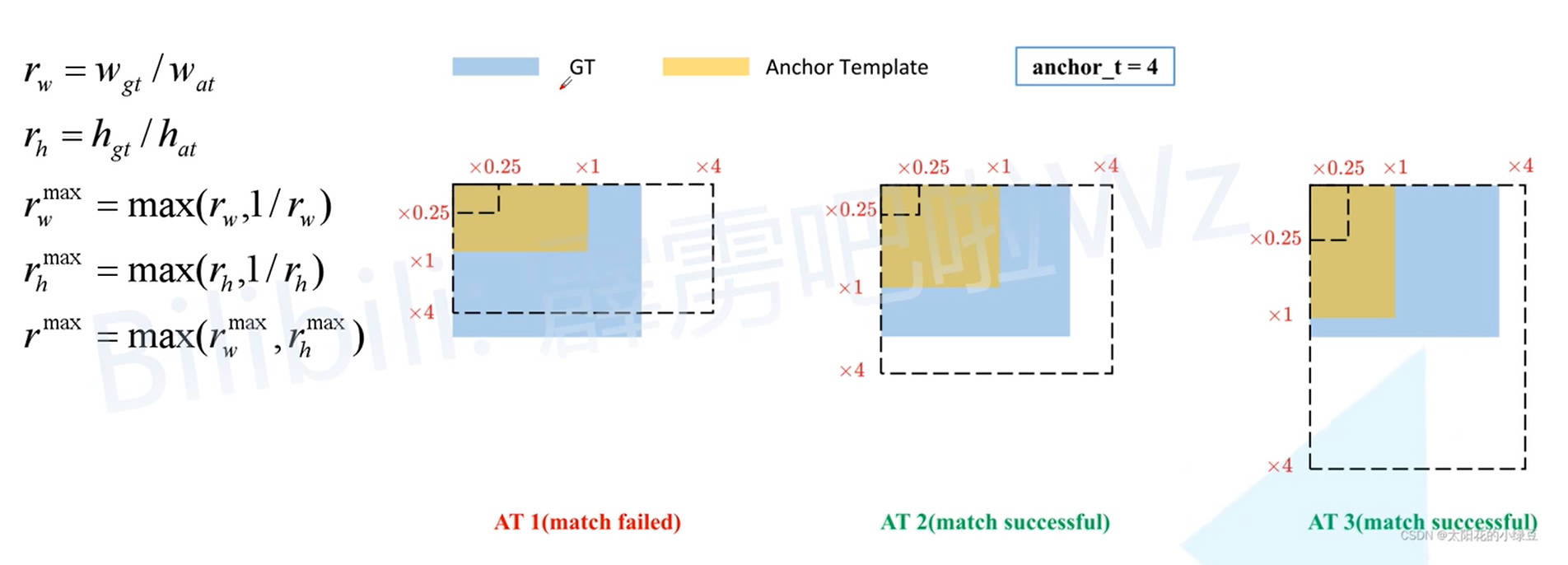
由于对预测框宽高进行了限制,v5 不在根据 IOU 结果来确定 Ground True Box 与哪个 Anchor Box 所对应,而是通过计算 Ground True Box 与 Anchor Box 的长宽比列。并且认为宽高比列小于 4 的 Anchor Box 与 Ground True Box 对应(预测结果的 Anchor Box 宽高的调节比列就被限制在 (0,4)(0,4))。
YOLO V3 代码实现
1. 项目简介
-
工程目的: 纯手撸 YOLO v3, 实现对口罩的检测。


-
训练素材 :来自 B站 UP炮哥带你学
注意:
- 由于 GitHub 上的 yolo v3 实现 偏向实际应用,其代码实现不利于学习,因此,本项目着重于对 yolo v3 原理的复现,一些花里胡哨的功能就全部忽略掉了(例如,原项目中的
.cfg配置文件)。- 本项目中给出的模型权重参数(在
weightsBackup文件夹里),由于训练次数少、训练素材少,模型复现简化等原因,其精度并不是很好,但是能玩 ( *︾▽︾)。- 由于本人是外行,能力有限,若发现存在偏差,不用怀疑,那肯定是我的问题,请多多包涵 ( •̀ ω •́ )✧
2. 项目运行
- 环境需求:
- Python
- PyTorch
- OpenCV
- 运行: 下载项目工程后,直接运行对应的 .py 文件即可。默认是启动了
GPU,如有需要,请在config中修改相关配置
3. 目录结构
triangle@LEARN:~$ tree detectMask/
. ├── ManageData/ │ └── Datasets.py ├── Model/ │ ├── Loss.py │ └── Network.py ├── Utils/ │ ├── BoxProcess.py │ ├── ImageProcess.py │ └── PostProcess.py ├── asset/ │ ├── images/ │ ├── testSet/ │ │ ├── test_images/ │ │ └── test_labels/ │ ├── trainSet/ │ │ ├── train_images/ │ │ └── train_labels/ │ ├── videos/ │ ├── weights/ │ └── weightsBackup/ └── config/ ├── detectImage.py ├── detectVideo.py └── train.py
ManageData:训练集与测试集的数据管理模块Model:Darknet 53 模型的实现;yolo v3 损失函数的实现Utils:工具模块- BoxProcess:外接矩形相关处理函数
- ImageProcess:图片展示、变换、绘制文字与外接矩形等相关处理函数
- PostProcess:极大值抑制得到最终预测结果;模型评价指标计算 precision , recall , ap
asset:存放模型测试与训练相关的视频、图片、模型权重文件资源。- images 与 videos:用来测试模型的图片与视频
- trainSet:模型训练的训练集
- testSet:模型训练的测试集
- weights:模型训练过程中,保存的权重参数
- weightsBackup:备份的权重参数
config:模型的配置参数- train.py:训练模型
- detectImage.py:利用图片进行模型测试
- detectVideo.py:利用视频进行模型测试