String 类型
String 类型 :Redis 最基本的数据类型,它是二进制安全的,意味着你可以用它来存储任何类型的数据,如图片、序列化对象等。使用场景:
-
缓存对象 :方式①:直接缓存整个对象的 JSON,命令例子:
SET user:1 '{"name":"xiaolin", "age":18}'。方式②:采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用MGET获取各属性值,命令例子:MSET user:1:name xiaolin user:1:age 18 user:2:name xiaomei user:2:age 20。 -
常规计数器 :因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。比如文章的阅读量:

-
分布式锁 :加锁过程使用
SET、NX命令;
-
共享 Session 信息:。
List 类型
Redis 的列表是简单的字符串列表,按照插入顺序排序。你可以向列表的头部或尾部添加元素。(列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素。)
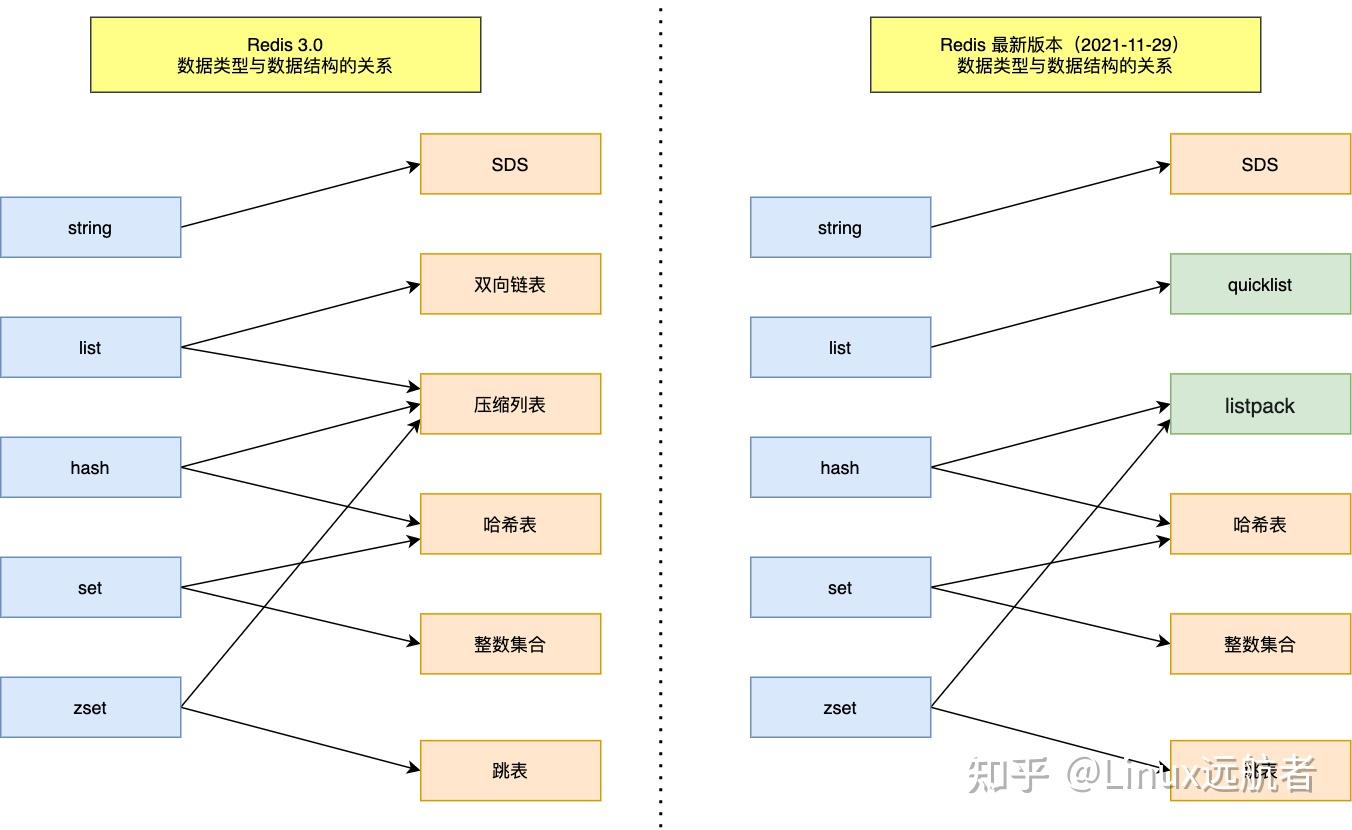
内部实现:①redis 3.2之前,使用 双向链表(linkedlist) + 压缩列表(ziplist);②redis 3.2 版本之后,快速列表(quicklist);
使用场景:
- 消息队列 (或任何先进先出的场景):可以将 List 用作消息队列来实现异步任务处理。生产者将任务添加到列表的尾部(使用
RPUSH命令),消费者从列表的头部获取任务并进行处理(使用LPOP命令)。 - 事件发布与订阅:类似于消息队列,List 可以用于实现事件的发布与订阅机制。发布者将事件添加到列表中,订阅者从列表中获取事件并进行相应的处理。
Hash 类型
Redis 中的哈希是一个键值对的集合,其中的键和值都是字符串。其中 value 的形式如:value=[{field1,value1},...{fieldN,valueN}]。Hash 特别适合用于存储对象。

内部实现 :哈希表(hashtable)(底层使用字典表) + 压缩列表(ziplist)。
- 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;
- 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的 底层数据结构。
使用场景:
-
缓存对象:Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。

Set 集合
Redis 的集合是一个无序 的字符串集合,不允许有重复的元素。集合通过哈希表实现的,所以添加、删除、查找的复杂度都是 O(1)。
内部实现:Set 类型的底层数据结构是由哈希表 、整数集合实现的:
- 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
应用场景:Set 集合的主要特点有 无序、不可重复、支持并、交、差集操作。
- 点赞:Set 类型可以保证一个用户只能点一个赞。
- 共同关注:Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
Zset 有序集合
Redis 的有序集合类似于集合,但它为每个元素关联了一个浮点数分数(score),这使得集合中的元素能够按分数进行排序。虽然成员是唯一的,但分数(score)可以重复。

内部实现:Zset 类型的底层数据结构是由压缩列表或跳表实现的。
- 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
- 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
使用场景:
- 排行榜:有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
BitMap
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
内部实现:Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
- String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
使用场景:Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。
-
签到统计:在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
HyperLogLog
Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数 」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。简单来说 HyperLogLog 提供不精确的去重计数。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
使用场景:
- 百万级网页 UV(Unique Visitor,独立访客数) 计数;
Stream
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
使用场景:
- 消息队列。
问:redis的 String、Hash 类型都实现 缓存对象时,区别是什么?
答:在 Redis 中,String 和 Hash 类型都可以用来存储和缓存对象,缓存的方式有所区别:
-
使用
String类型 缓存对象:是将整个对象序列化为一个字符串(如 JSON、XML、或二进制)后存储在 Redis 中。
-
使用
Hash类型 缓存对象:适合存储具有字段和值的对象(类似于一个对象的属性和属性值)。Hash可以存储多个字段(key-value 对),每个字段的值也是字符串。
因此,String 类型 适用于存储和操作整体对象 的场景,尤其是对象结构固定(不频繁变动)、大小适中且频繁读取整个对象时。Hash 类型 适合存储结构化对象,并且需要频繁操作对象的部分字段。