本文主要为大家介绍Apache DolphinScheduler的单机部署方式,方便大家快速体验。
环境准备
需要Java环境,这是一个老生常谈的问题,关于Java环境的安装与配置期望大家都可以熟练掌握。
验证java环境
sh
java -version
下载安装包并解压
使用wget下载安装包
sh
wget https://dlcdn.apache.org/dolphinscheduler/3.2.1/apache-dolphinscheduler-3.2.1-src.tar.gz解压安装包
sh
tar -xvzf apache-dolphinscheduler-3.2.1-bin.tar.gz启动DolphinScheduler服务
进入到项目根目录
sh
cd apache-dolphinscheduler-3.2.1-bin启动服务
sh
./bin/dolphinscheduler-daemon.sh start standalone
-server
至此,单机部署Apache DolphinScheduler就完成了,是不是非常的简单方便啊!
验证
访问Web UIhttp://localhost:12345/dolphinscheduler/ui,账号和密码分别是admin和dolphinscheduler123
登录成功后,我们就可以体验了。
停止服务
停止服务和启动服务一样简单
sh
./bin/dolphinscheduler-daemon.sh stop standalone-server
简单案例
为了让大家体验到DolphinScheduler的神奇之处,我接下来为大家介绍如何实现定时往MySQL的表中写入数据。
由于我们需要对Mysql数据库进行读写,所以就需要使用到MySQL的JDBC驱动。那么我们首先需要下载驱动并分别放到api-server/libs和worker-server/libs目录下。
sh
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
完成以后,重新启动服务即可。
- 配置Mysql数据源
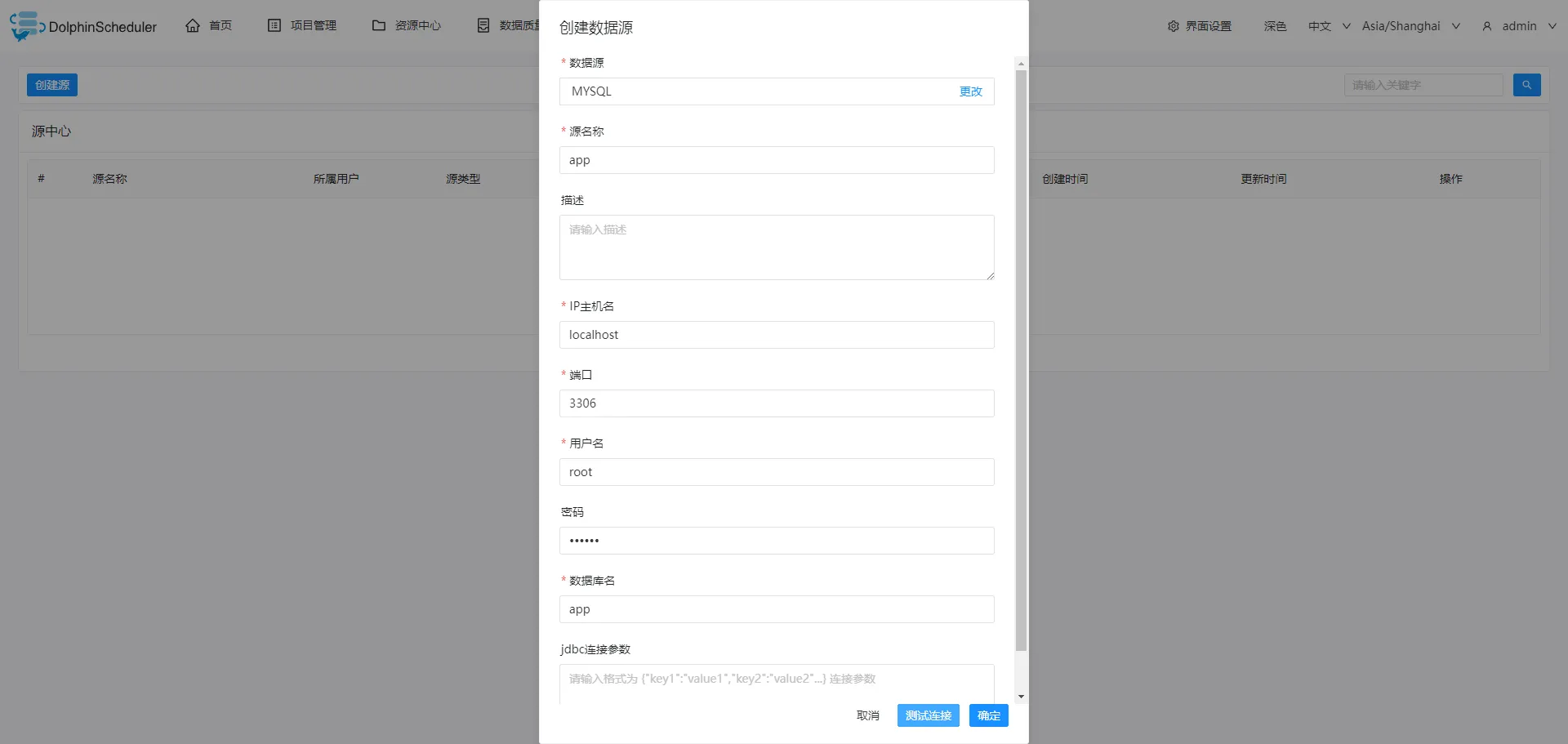
填写好数据库的信息,确保测试连接可以正常连接到数据库

这样我们就准备好了一个可以用的数据源
在app数据库中,需要先创建一张users表
sql
CREATE TABLE users (
id BIGINT PRIMARY KEY auto_increment,
name varchar(100) NULL
);- 创建一个项目
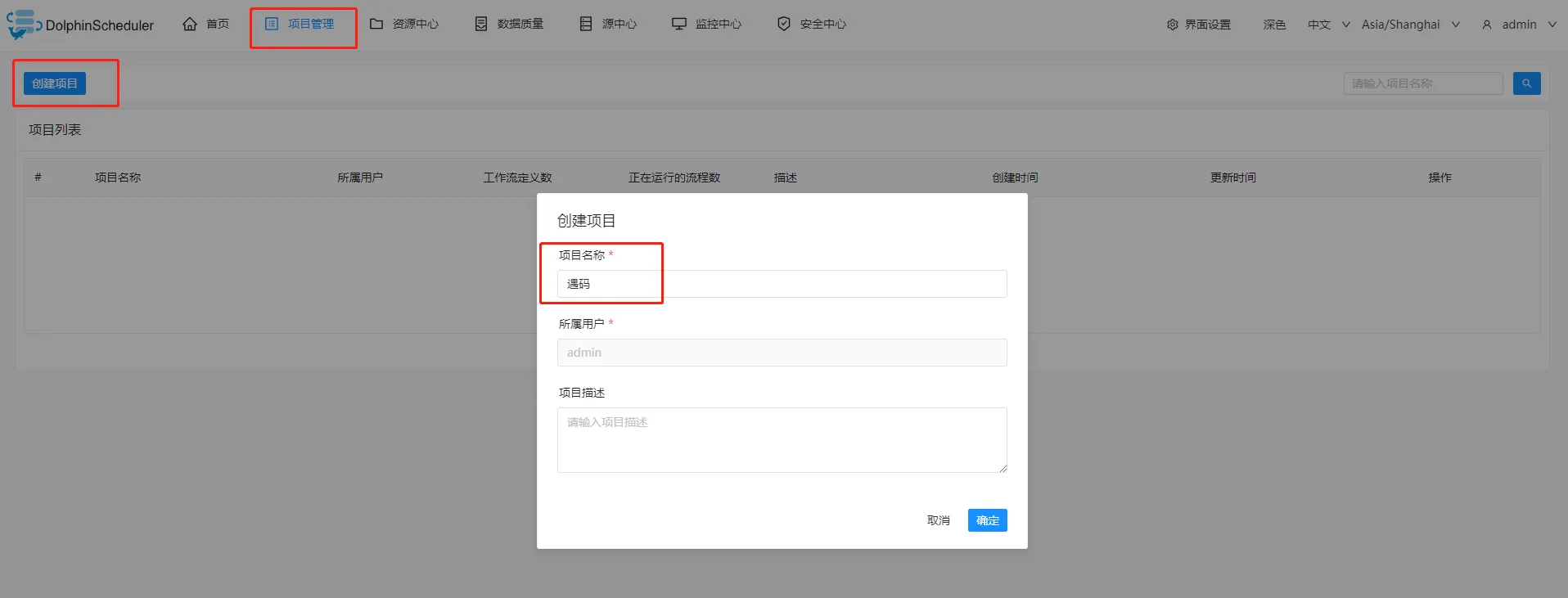
- 创建工作流
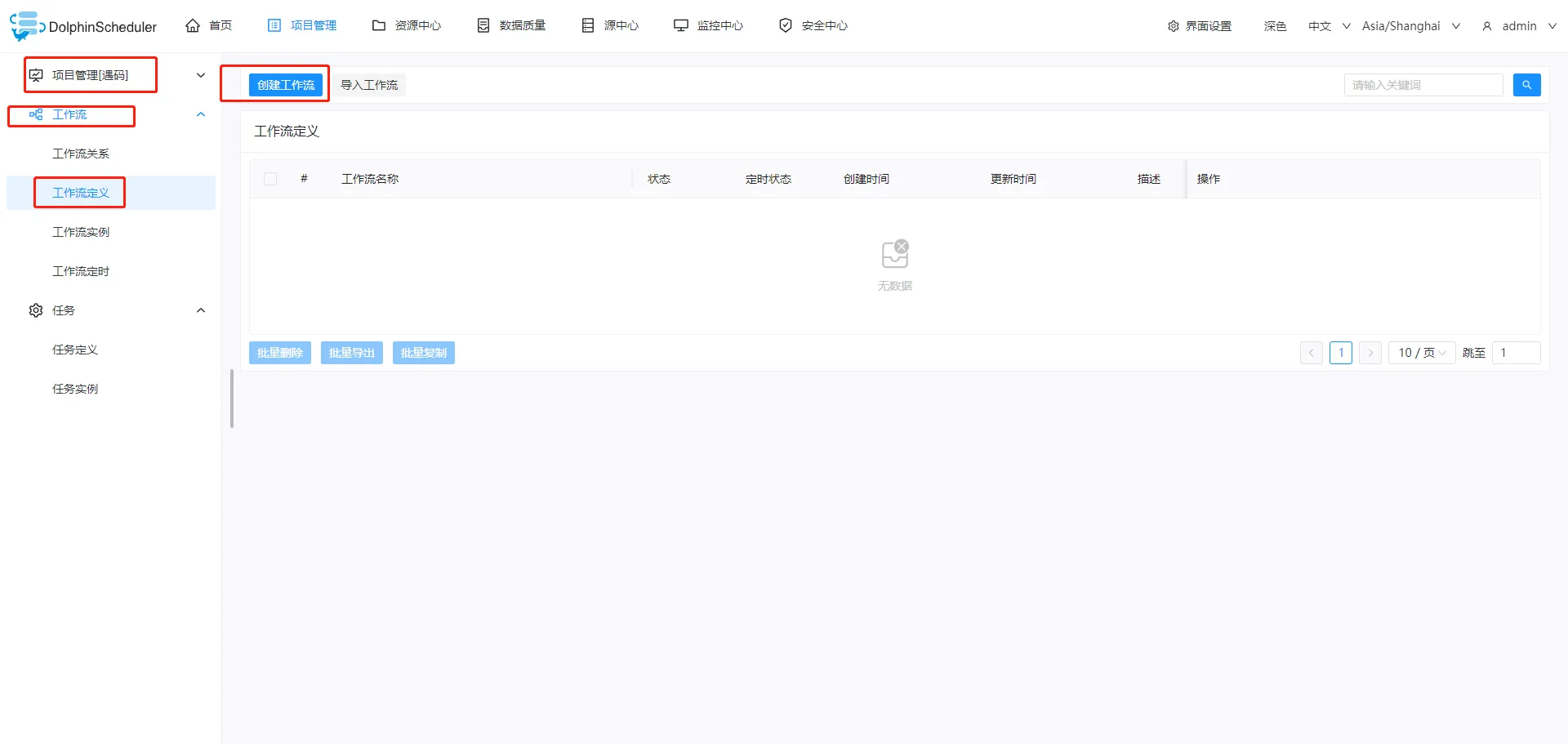 4. 配置SQL组件 将左侧的SQL组件拖入到右侧的画布中,完成配置
4. 配置SQL组件 将左侧的SQL组件拖入到右侧的画布中,完成配置
节点名称可以随意写

数据源类型选择MYSQL,数据源实例选择前面配置好的数据源app,SQL类型则选择非查询
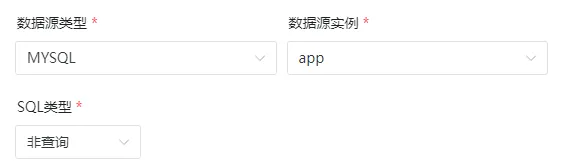
SQL语句则为插入数据,此处我们模拟插入一样的数据
sql
insert into users (name) values ('tsingliu');
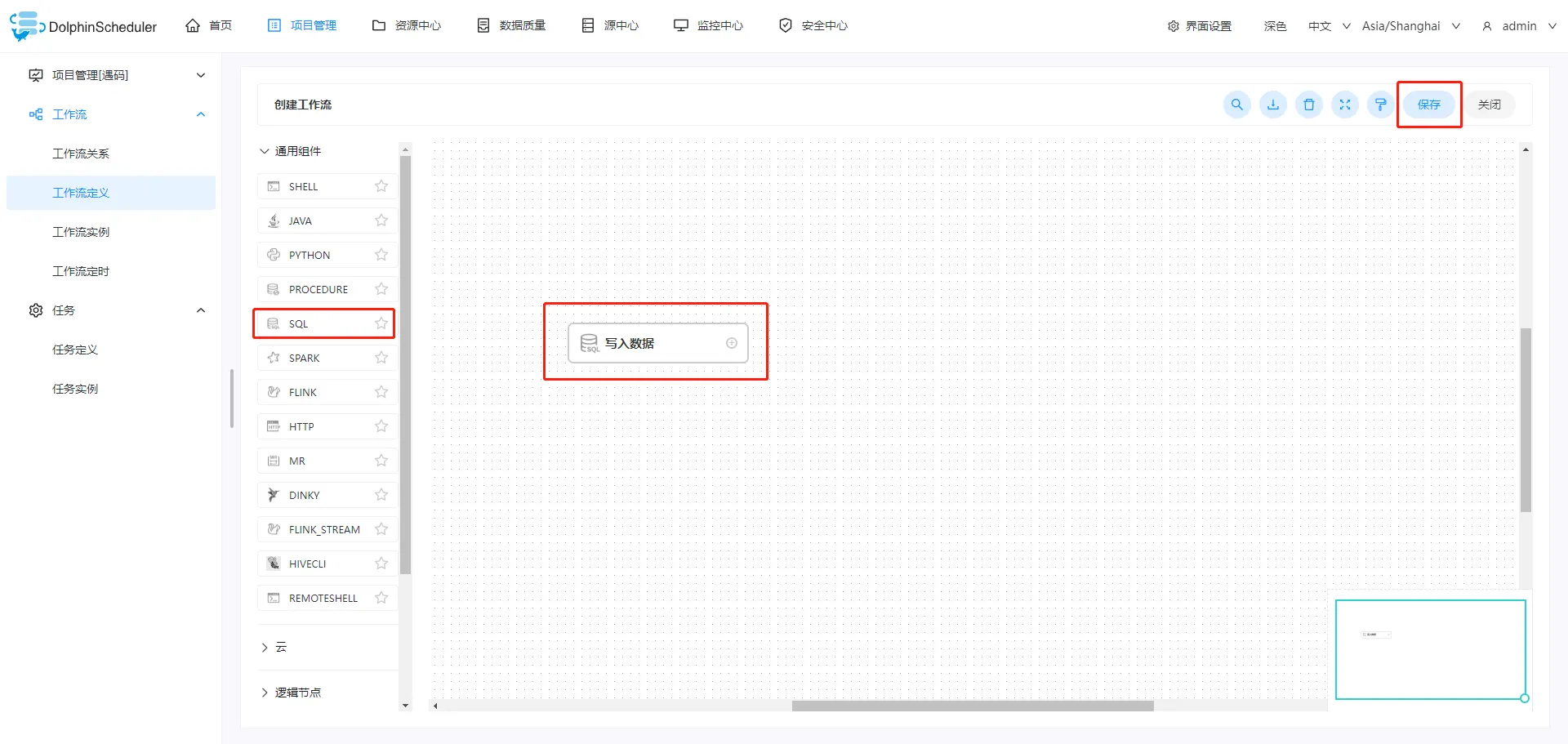
配置好节点以后,保存工作流
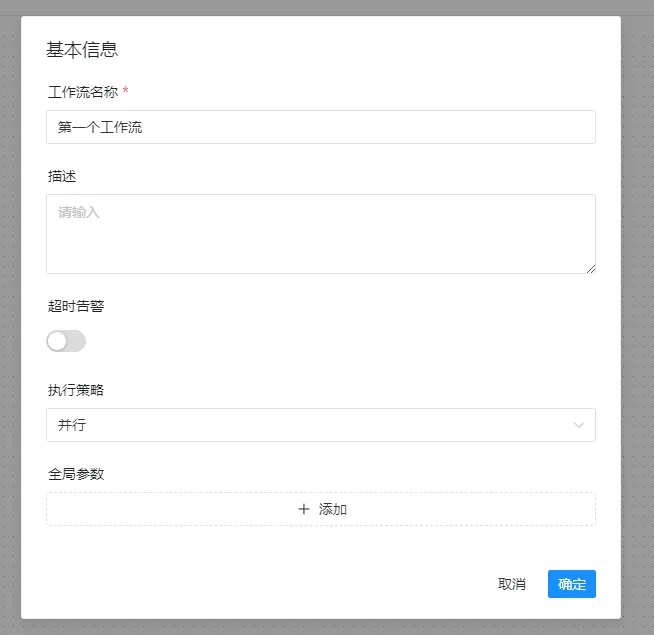
上线工作流和定时
默认情况下工作流处于下线状态

首先需要上线任务

此时就可以点击运行,验证工作流是否配置正常。
多数情况下我们更需要定时执行,可以配置定时规则,我们期望每5s写入一次数据
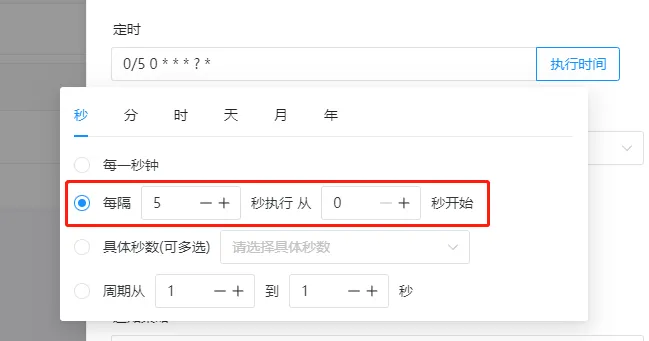
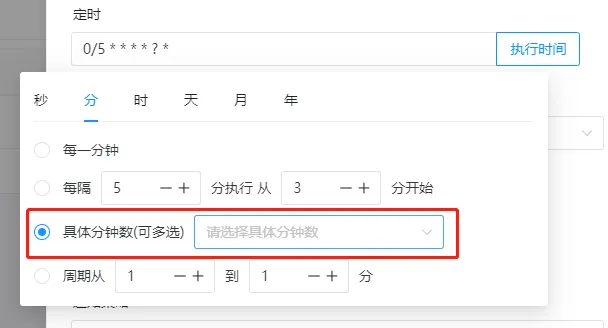
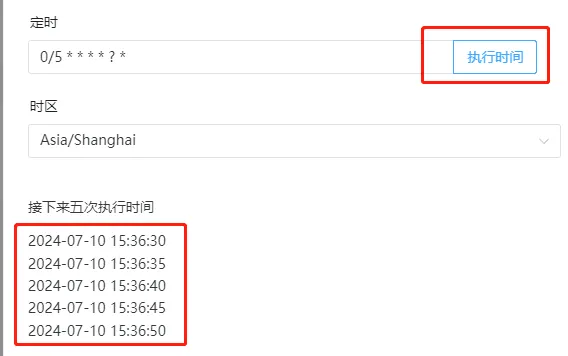
配置好定时规则后,可以点击执行时间,查看接下来五次执行时间是不是和预期一样。
配置好后可以上线定时

查看日志
工作流上线后,我们不清楚任务是不是已经正常开始执行,我们可以查看任务实例
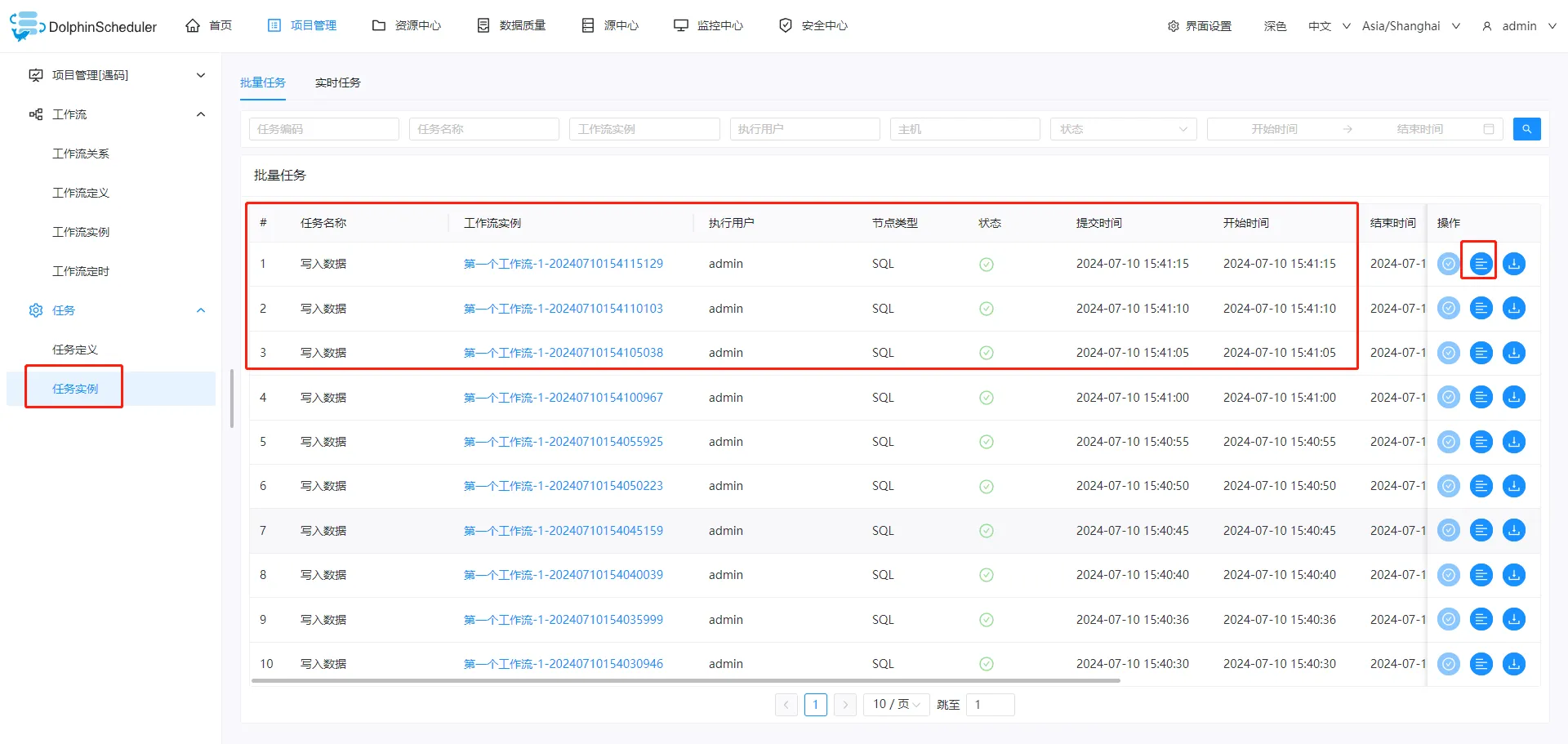
可以看到已经有多个任务已经执行成功了,每个任务之间的间隔时间也是5s。
另外如果任务执行失败了,也可以在此处查看详细的日志,方便我们排查问题。
进阶
以上这个简单的案例只能是让大家对Apache DolphinScheduler有一个初步的认知,大家可以根据自身遇到的实际问题来编排自己复杂的工作流,有更多问题欢迎访问官网官方文档。
本文由 白鲸开源科技 提供发布支持!