论文阅读:2023,Foundations & Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions
阶段性记录,梳理下好知道最近干了啥。。。

一、概述
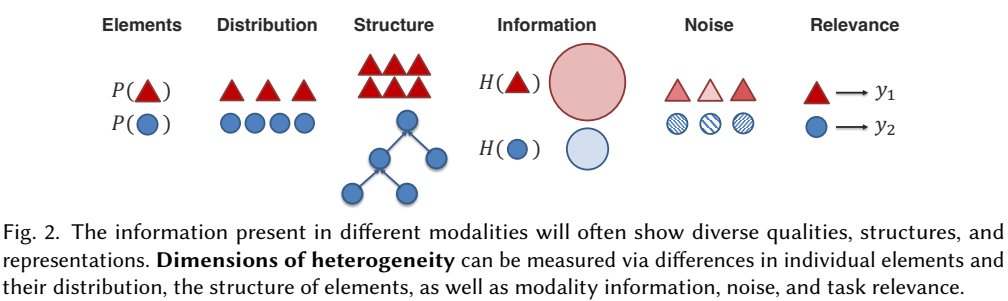
多模态学习领域面临显著的模态间异构数据处理和关联性分析的挑战。大体上来看,可以从异构、关联和相互作用三个方面分析多模态学习领域的特点。1)首先,多模态数据是显著异构的,这类数据表现出复杂多样的数据特性、分布、结构、信息粒度、表征等,例如,图像和文本数据、结构化数据和图数据、不同的表征处理方法等,更详细的来看,以图像和文本为例,图像通常表示为一个像素矩阵,而文本通常表示为离散序列。从时间维度上,图像偏向于连续的,文本偏向于离散的;从空间维度上,图像通常是二维的,而文本是一维的;从信息粒度上看,图像是具体而低容量的,而文本则是抽象和高容量的,如图所示。2)其次,模态的关联性表现在模态之间往往存在相关性并且存在共享信息。3)最后,模态间的相互作用表明在进行模型推理的过程中往往能产生更加丰富的新的上下文信息,进而增加模型的推理性能。
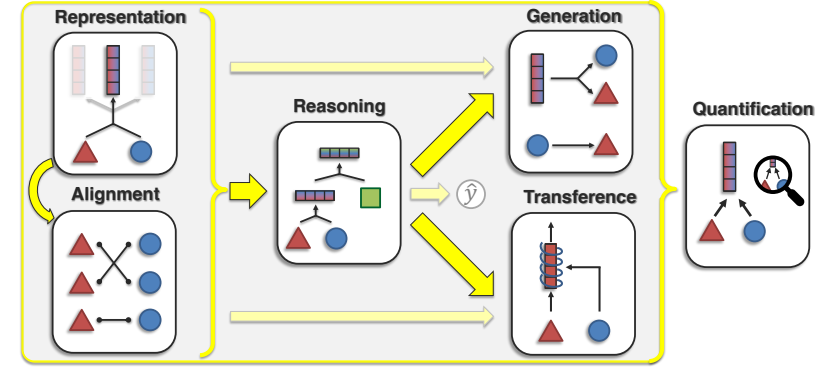
从一个完整深度学习模型训练过程来看,多模态学习可以划分为如下六个研究角度:数据处理(模态融合/表征、模态对齐 )、模型训练(推理 )、下游任务(生成、转换 )、模型验证(评估)。
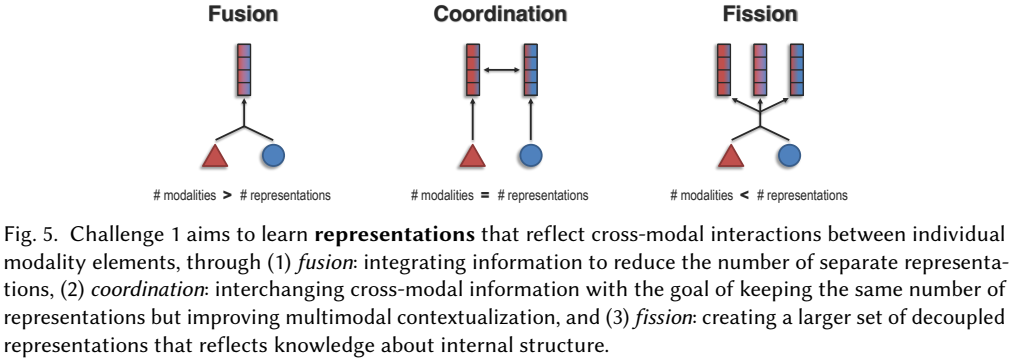
模态表征主要探讨如何通过有效表征来反映出模态数据的异构型和关联性。该类研究的划分种类繁杂,例如:1)从模态数量来看,可以划分为模态融合、模态协同和模态分裂。具体而言,模态融合是将多种模态模态数据转换到一个共享的表征空间,进而捕捉模态间的相关性;模态协同的目标是在保证模态数量不变的前提下提供多模态学习中的上下文感知能力;最后,模态分裂则是构建一组更大的非相关表征来反映信息中的内部结构。
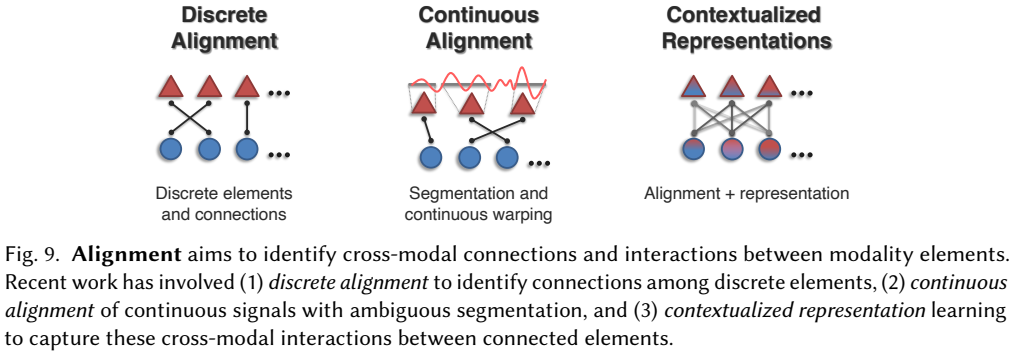
从上面可以看出,模态表征研究有效的表征构建方法,将多模态数据转变为可以进行推理的结构。然而,大量的研究表明,单纯的模态表征往往无法发挥出多模态模型的全部性能,其中主要的一个瓶颈就是多模态间的关联性分析挑战,**如何识别模态数据间的关联性和相关性就是多模态对齐需要着重考虑的研究内容。**对齐的挑战可能源自于大范围依赖、模糊的数据划分、模态间的一对一、多对多等复杂的关联关系。
二、多模态融合
简要概述多模态学习技术的发展历程:从2011-2013年,处于基于机器学习的通用整体表示学习技术,从2014-2018年,开始面向特定任务的多模态表示(融合)、对齐、转换技术,从2019年-至今,主要开展基于多模态预训练模型的通用表示学习或完成多个多模态任务。
首先了解下多模态表征的研究现状,从融合的角度来看,多模态融合方法根据融合阶段可以分为:早期融合、中期融合和晚期融合。根据融合方式进行划分:简单融合、门控融合、基于注意力融合、Transformers融合、图模型融合、双线性注意力融合。(注:此类方法广泛出现在2022年以前,后续研究还未调研) 值得注意的是,图模型融合和 Transformers 融合通常 可获得更好的性能;门控机制和注意力机制跟预训练模型结合,也能取得不错的性能。除了上述的融合方法,由于不同模态的采样频率不同,针对模态间呈现的异步性问题,也存在研究讨论如何在"未对齐"的多模态序列上进行建模。
三、VL预训练模型
目前预训练模型均通过不同的深度学习网络作为编码器,如视觉编码器Vit、CNN等,文本编码器BERT、Transformer、LLM等对不同的输入数据进行处理,然后以显示对齐或隐式对齐的方法作为目标进行训练。不同的研究者划分模型架构的方法各有差异,包括如下内容:1)单塔架构、双塔架构;2)编码器、编解码器;3)双塔架构、融合架构;4)基于编码器深浅的划分方式;5)基于端到端(end-to-end)范式的模型和基于参数冻结对齐(frozen alignment)的模型。
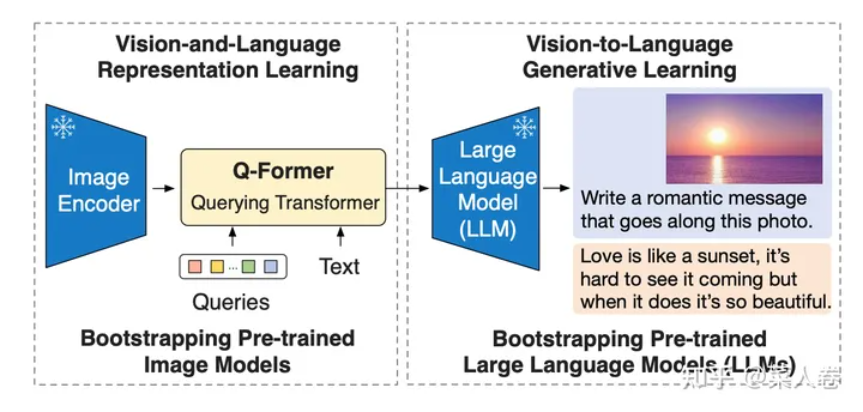
个人以第四种编码器的深浅层次作为基础,对其他架构进行理解。可以看出,尽管各类研究针对模型架构的划分方式不同,但较为通用的来看,对于第一种 划分方式,不同的模态均需要相应的编码器进行表征嵌入,如视觉的Linear project、CNN,文本的Word2Vec、Bert,不同的模态数据也需要通过深度网络进行表征提取,因此个人认为这都属于双塔架构,只是编码器的深浅层次、表征提取的抽象程度不同。对于第二种 划分方式,更多的可以从下游任务来看,是否需要模型具有生成能力。对于第三种,较为明显的实例包括:采用双塔架构的CLIP模型,采用融合架构的ALBEF、TCl模型等,对于CLIP模型,原文通过对比学习来显示的对齐不同模态间的关联性,而融合架构的模型则通过深层神经网络进行关联性提取,如Transformer系列、cross-attention层等。在第三种架构中,提到了CLIP的显示对齐方式,这与前文多模态融合、对齐等基础研究的共同作用相呼应,另一类隐式对齐的方式可以联系到第五种架构划分方式:基于端到端(end-to-end)范式的模型和基于参数冻结对齐(frozen alignment)的模型。在这里,基于端到端范式的模型架构就是前面几类架构的总结,参数冻结范式主要是多模态生成式语言模型(MLLM),比如BLIP-2模型中提到的Q-Former模块,主要是为了将视觉表征和后续的LLM模型进行隐式对齐操作,如图所示。
四、QA
怎么理解多模态融合和多模态对齐:
模态融合的目的是将不同模态的输入信息进行整合,以实现多模态的特征提取。例如,将从图像和文本数据中提取出的特征拼接在一起,作为大语言模型的输入,通过监督训练使模型理解两种模态信息。需要注意的是,模态融合并不要求不同模态的语义空间进行对齐,它强调的是模型具备了同时接收不同模态信息的能力,并在模型内部进行联合计算后输出一个包含多模态信息的结果。
模态对齐旨在建立对不同模态的共同理解,它通常将不同模态的语义空间进行对齐,即在提取含义相近的不同模态数据的特征后得到相近的特征向量。其算法原理可分为显式对齐和隐式对齐。
(1)显式对齐是指模型训练的一个目标函数就是不同模态数据的对齐程度。例如,CLIP6使用一个双塔结构(编码器),其中图像塔和文本塔分别处理图像和文本数据。在训练过程中,输入数据为语义相关的图文对,CLIP通过最小化图像塔和文本塔之间的余弦相似度来学习图像和文本之间的映射关系。通过显式模态对齐,图像和文本能够共享一个特征空间,从而实现跨模态检索和识别等功能。
(2)隐式对齐不是直接将两个模态的语义空间进行对齐,而是将这种对齐过程作为另一个任务的中间步骤。例如,LLaVA7使用简单的连接层将通过图像塔提取的特征映射到大语言模型的输入空间,随后语言模型结合文本指令和映射后的图像特征,输出有关图像内容的回答。经过监督学习,最终语言模型能够理解映射后的图像特征。