导读
作为一个分布式数据库,扩缩容是 TiDB 集群最常见的运维操作之一。本系列文章,我们将基于 v7.5.0 具体介绍扩缩容操作的具体原理、相关配置及常见问题的排查。
通常,我们根据当前资源状态来决定是否需要调整 TiKV 节点的规模,无论是增加还是减少节点。我们希望在调整后,集群能够通过重新调度尽快实现所有在线 TiKV 节点资源的平衡利用。
因此对于扩缩容来说,我们主要关心的还是以下两点:
- 资源均衡调度指令产生速度(PD 上调度产生的速度 )
- 资源均衡调度指令执行速度(TiKV 间数据搬迁的速度)
本系列文章将围绕以上两个逻辑,重点介绍扩缩容过程中的核心模块及常见问题,分为以下几个部分:
- 扩缩容调度生成原理及常见问题:
- 扩容过程中调度生成原理及常见问题
- 缩容过程中调度生成原理及常见问题
- 扩缩容过程调度执行(TiKV 副本搬迁)的原理及常见问题
本文我们将重点介绍 TiDB 扩容过程中 PD 生成调度的原理和常见问题,希望能够帮助大家更好地理解和运维 TiDB。
扩容过程中 PD 生成调度的原理及常见问题
一般的,当集群中 TiKV 资源跑到 75% 左右时,一般的调优手段无法解决资源使用上的瓶颈,此时,我们就需要通过 添加 tikv 节点的方式,来提高集群的整体性能。
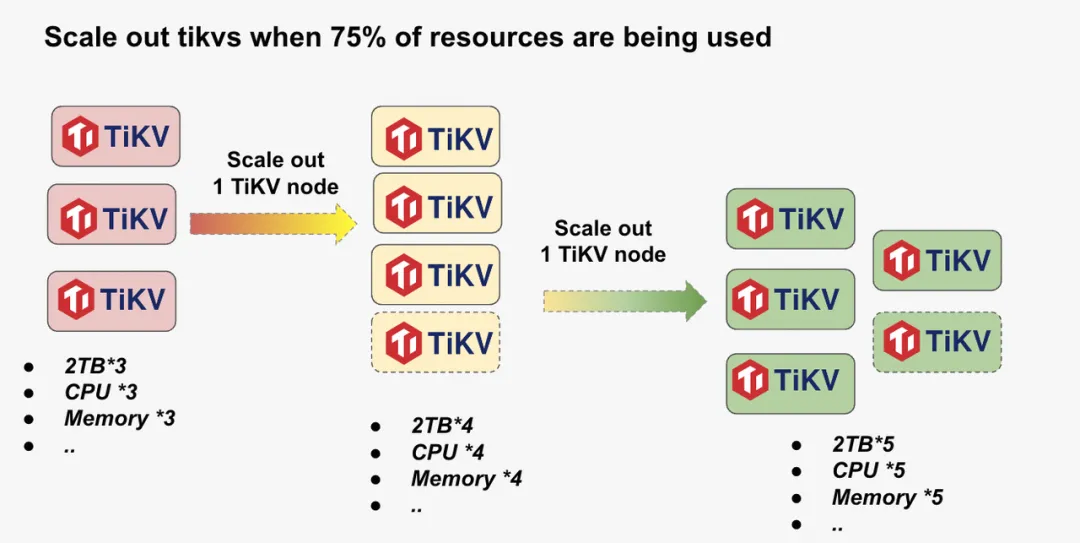
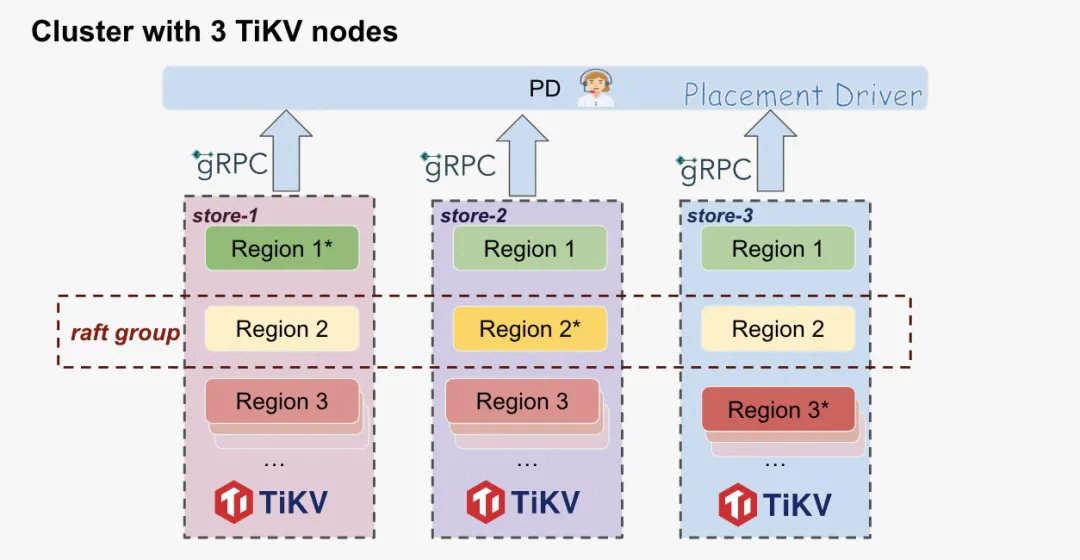
如图,当集群只有 三个 tikv 时,能够使用的存储、CPU 、 memory 到达使用瓶颈时,我们可以通过加节点的方式增加集群相关资源。下面我们简单来看一下,三 tikv 节点下,增加一个 tikv 节点时,TiDB 集群是如何让新节点的物理资源能够被集群使用起来的。首先在三个 TiKV 节点的集群中,在我们 PD 的统一调度下,会尽量将三个 tikv 节点的资源得到均衡使用。
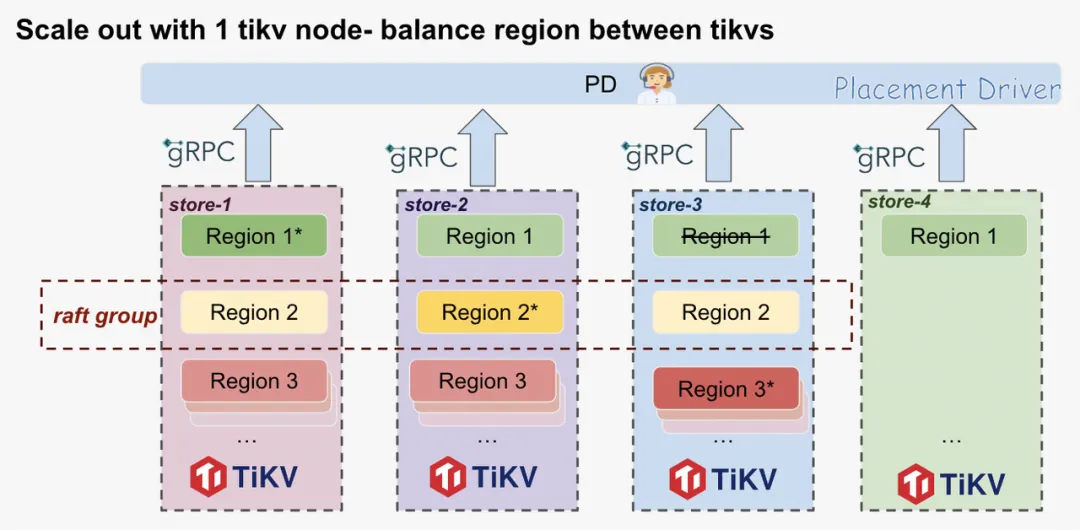
新加入一个节点时,PD 会慢慢的将相关数据以 Region 为单位迁移到新节点上,以充分使用新节点的 存储、memory 和 CPU 等资源。这当中最重要也是最耗时的就是将 Region 的副本数据从老节点搬迁到新节点上。如下图,PD 将 Region 1 的其中一个副本从 store-3 搬迁到了新节点 store-4 上,这个过程我们叫 balance-region.
Balance region 具体步骤
Balance region 以 region 为单位执行,由 PD 计算需要搬迁的 region, 由 TiKV 执行。具体执行过程,简单的来说,主要分为以下三个步骤:
- 新节点上新增副本 learner 节点(leaner 节点不参与投票过程)。
- 将新节点的 learner 角色和老节点的 follower 角色互换
- 将老节点上的副本(learner) 删除以上步骤最终会变成一条条调度指令,下发给 KV 去执行,下面我们来看每个调度指令是如何从进行的:
Step1: Add learner
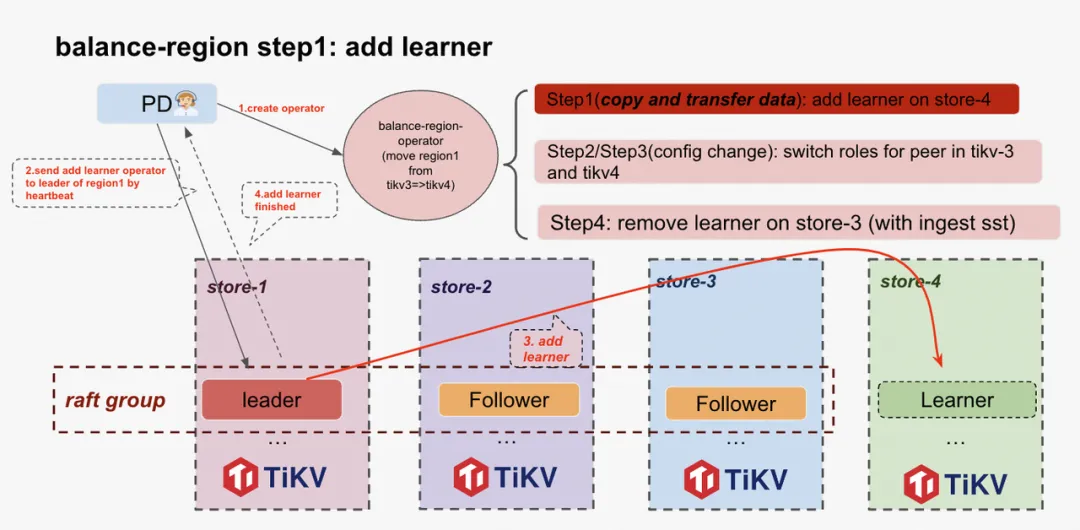
- PD 中 balance-region-scheduler 生成balance-region operator, 制定具体执行步骤。
- PD 通过心跳的方式,告诉 leader 节点执行 add learner peer 操作
- Leader 所在节点在这个 Region 的 raft-group 里面广播这个消息,并最终从 leader 上生成 snapshot 发送给 store-4 , 添加 learner 节点完成。
- Leader 收到来自 learner 的消息,上报心跳给 PD 告知 add learner 这一步骤执行成功
Step2: Switch role
store-4 上的 learner 节点虽然有完整的数据,但不参与投票过程。我们期望是将 store-3 上的 follower 迁移到 store-4 上,因此,在这一步骤,我们会将 store-4 和 store-3 上的副本的角色互换,最终 store-3 上的老副本会变成 learner, 而新节点上的副本角色变成 voter 也就是 follower.这个过程为了保证数据的安全性,实际情况分为两条调度指令执行。
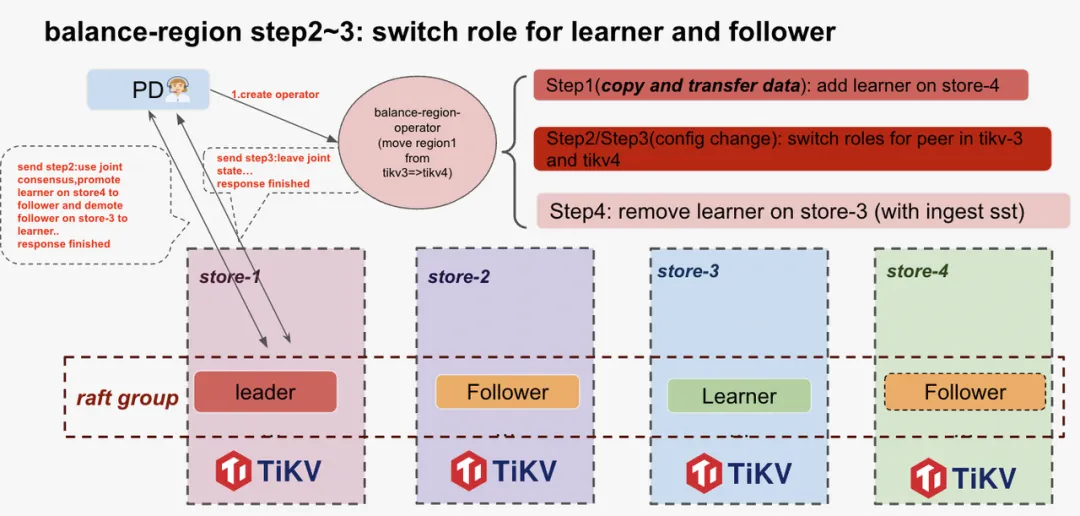
具体执行步骤为:
- PD 通过心跳知道 learner 添加成功后,发送角色互换的指导给 leader 节点
- Leader 节点在 raft-group 里面广播消息
- 所有副本收到该心跳后,更新自己的配置。至此,该 raft-group 完成角色互换的配置更新。
这个过程因为只涉及逻辑变更,很快,也很难出问题。
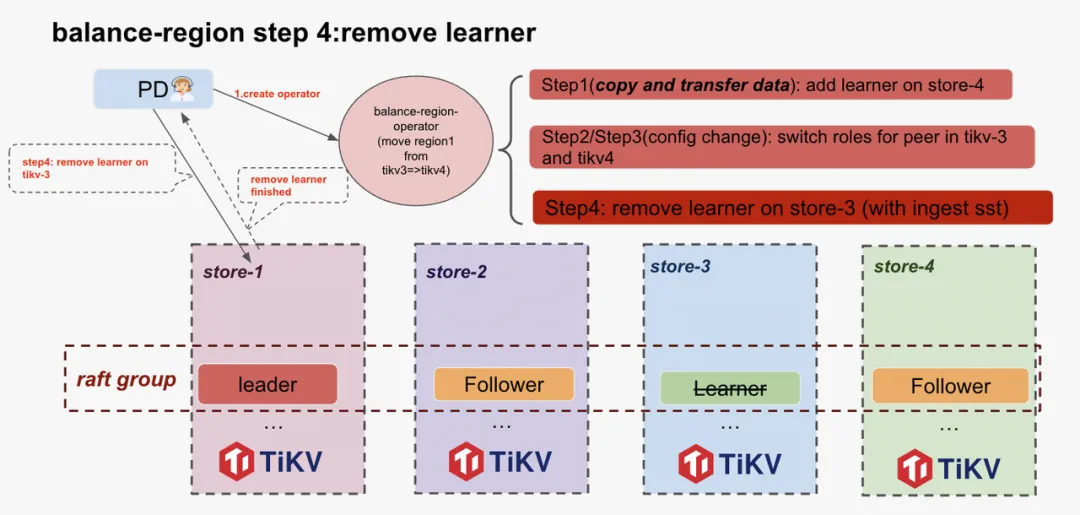
Step3: Remove old peer
经过步骤 2,store-4 上已经有一个 follower, 且已经不会有数据访问到 store-3 上的 learner, 因此我们可以安全的删除这个副本。具体执行步骤如下:
- PD 发送心跳给 leader, 告知删除 store-3 上的副本
- Leader 在当前 region 的 raft-group 里面广播这个消息
- 所有副本在收到这个消息后,更新自己的配置信息,而 store-3 则会将自己这个副本完全删除。
PD 上关键日志
以上过程,我们可以从 PD 的日志中看到完整的执行情况:
create balance-region operator
// create balance-region operator
[2024/07/09 16:25:23.105 +08:00] [INFO] [operator_controller.go:488] ["add operator"] [region-id=142725] [operator="\"balance-region {mv peer: store [1] to [166543141]} (kind:region, region:142725(575, 5), createAt:2024-07-09 16:25:23.105733052 +0800 CST m=+1209042.707881308, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, size:92, steps:[0:{add learner peer 166543143 on store 166543141}, 1:{use joint consensus, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner}, 2:{leave joint state, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner}, 3:{remove peer on store 1}], timeout:[17m0s])\""] [additional-info="{\"sourceScore\":\"817938.92\",\"targetScore\":\"4194.83\"}"]Step1: add learner peer on new store
// Step1: add learner node
[2024/07/09 16:25:23.105 +08:00] [INFO] [operator_controller.go:732] ["send schedule command"] [region-id=142725] [step="add learner peer 166543143 on store 166543141"] [source=create]
[2024/07/09 16:25:23.107 +08:00] [INFO] [region.go:751] ["region ConfVer changed"] [region-id=142725] [detail="Add peer:{id:166543143 store_id:166543141 role:Learner }"] [old-confver=5] [new-confver=6]
[2024/07/09 16:25:23.108 +08:00] [INFO] [operator_controller.go:732] ["send schedule command"] [region-id=142725] [step="add learner peer 166543143 on store 166543141"] [source=heartbeatStep2/Step3: use joint consensus to switch role
// Step2: use joint consensus
[2024/07/09 16:25:24.248 +08:00] [INFO] [operator_controller.go:732] ["send schedule command"] [region-id=142725] [step="use joint consensus, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner"] [source=heartbeat]
[2024/07/09 16:25:24.250 +08:00] [INFO] [region.go:751] ["region ConfVer changed"] [region-id=142725] [detail="Remove peer:{id:142726 store_id:1 },Remove peer:{id:166543143 store_id:166543141 role:Learner },Add peer:{id:142726 store_id:1 role:DemotingVoter },Add peer:{id:166543143 store_id:166543141 role:IncomingVoter }"] [old-confver=6] [new-confver=8]
// Step3: leave joint state
[2024/07/09 16:25:24.250 +08:00] [INFO] [operator_controller.go:732] ["send schedule command"] [region-id=142725] [step="leave joint state, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner"] [source=heartbeat]
[2024/07/09 16:25:24.252 +08:00] [INFO] [region.go:751] ["region ConfVer changed"] [region-id=142725] [detail="Remove peer:{id:142726 store_id:1 role:DemotingVoter },Remove peer:{id:166543143 store_id:166543141 role:IncomingVoter },Add peer:{id:142726 store_id:1 role:Learner },Add peer:{id:166543143 store_id:166543141 }"] [old-confver=8] [new-confver=10Step4: remove old peer
// Step4: remove learner node
[2024/07/09 16:25:24.252 +08:00] [INFO] [operator_controller.go:732] ["send schedule command"] [region-id=142725] [step="remove peer on store 1"] [source=heartbeat]
[2024/07/09 16:25:24.255 +08:00] [INFO] [region.go:751] ["region ConfVer changed"] [region-id=142725] [detail="Remove peer:{id:142726 store_id:1 role:Learner }"] [old-confver=10] [new-confver=11]PD report operator is finished
// operator finished
[2024/07/09 16:25:24.255 +08:00] [INFO] [operator_controller.go:635] ["operator finish"] [region-id=142725] [takes=1.149978179s] [operator="\"balance-region {mv peer: store [1] to [166543141]} (kind:region, region:142725(575, 5), createAt:2024-07-09 16:25:23.105733052 +0800 CST m=+1209042.707881308, startAt:2024-07-09 16:25:23.10595495 +0800 CST m=+1209042.708103209, currentStep:4, size:92, steps:[0:{add learner peer 166543143 on store 166543141}, 1:{use joint consensus, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner}, 2:{leave joint state, promote learner peer 166543143 on store 166543141 to voter, demote voter peer 142726 on store 1 to learner}, 3:{remove peer on store 1}], timeout:[17m0s]) finished\""] [additional-info="{\"cancel-reason\":\"\",\"sourceScore\":\"817938.92\",\"targetScore\":\"4194.83\"}"]在具体的运维过程中,当发现上线速度缓慢时,如果有大量的 balance-region operator 执行超时,我们可以通过查看 PD 日志中具体某个 operator 的执行情况,对照着以上日志,来看 balance-region 具体卡在哪一步。
实时监控扩容速度
从上文我们知道,扩容 TiKV 的速度主要取决于数据的搬迁情况,主要分为两个因素:
- PD 产生 balance-region operator 的速度
- TiKV 消费 balance-region 的速度,也就是物理数据的搬迁速度。
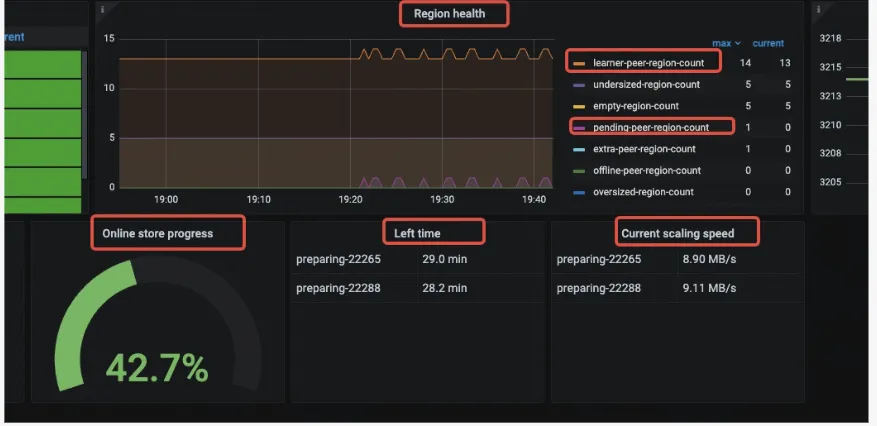
在扩容后,要做到整个集群的资源的快速均匀,一般跟我们 region 的数量、size 有直接关系,当然与我们集群的繁忙程度也有关系。目前,PD 提供了一些监控可以让我们看到扩容的状态,主要有
- PD->metrics:
- Region health
- Pending-region-count: 正准备
add learner但还没添加成功的副本 - Learner-peer-count: 当前集群中
learner副本的个数,需要注意的是,如果集群本身有Tiflash节点,这个数量也包含了Tiflash节点里的learner个数。
- Pending-region-count: 正准备
- Speed:
- Online store progress:当前扩容进度,根据剩余需要 balance 的空间计算得出
- Left time: 预估剩余时间,根据剩余需要 balance 的空间及当前数据搬迁速度得出
- Current scaling speed: 当前扩容数据搬迁实际速度
- Region health
Balance region operator 调度生成原理及常见问题
因为本身 PD 就有一系列监控和平衡各个 TiKV 之间的资源使用情况的调度器,因此 PD 没有针对扩容给出单独的调度器。目前这类调度器主要有两类:
- Balance-region-scheduler:负责将 Region 均匀的分散在集群中所有的 store 上,主要用于分散存储压力
- Balance-leader-scheduler: 负责将 region leader 均匀分布在 store 上,主要负责分散客户端的请求压力(CPU)
因此我们也可以认为,在扩容过程中,负责生成调度的主要是以上两个调度器在发挥作用。对于 balance-leader-scheduler, 因为没有数据搬迁,只是 raft-group 元数据的变更,因此特别快。一般情况下,我们不需要特别关注这个(也很少出问题) 本节将重点介绍 balance-region-scheduler, 也就是扩容情况下,迅速往新扩容 kv 上搬迁副本的调度器行为及常见问题。
首先我们来看一下 balance-region-scheduler 是如何选择并生成 balance-region operator 的:
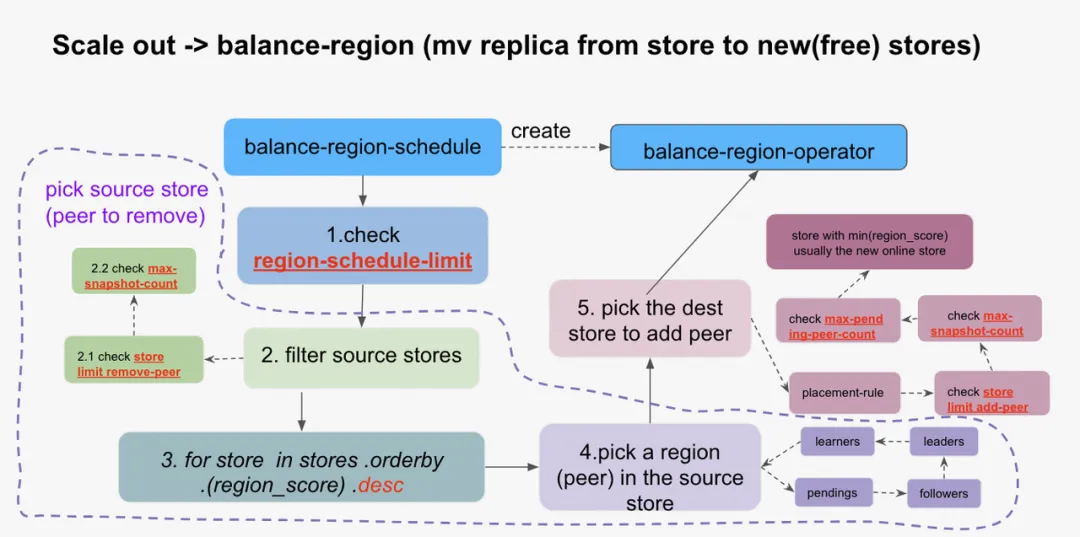
调度原理
Balance-region-scheduler 每隔 10ms~5s/10s 会发起一次调度。balance-region-scheduler 每次生成调度的具体逻辑如下:
-
检查 region-schedule-limit ( https://docs.pingcap.com/tidb/v7.5/pd-configuration-file#region-schedule-limit ), 用于控制当前 balance-region operator 的并发数量。
-
选择本次要搬走的 store
- 空间不足时,优先选剩余空间最不足的节点 (使得 tikv 的剩余数据量均衡)
- 空间富裕时,选择已用空间最多的节点(使得 tikv 的数据量分布均衡)
- 中间状态综合考虑两个因素
- 检查 store-limit 是否符合条件:store limit remove-peer ( https://docs.pingcap.com/tidb/stable/configure-store-limit#principles-of-store-limit-v2 )
- 检查这个 store 上的 max-snapshot-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-snapshot-count ) 是否超过
- 过滤选出可以作为数据源搬迁的 store, 过滤条件有:
- 在符合要求的 store 里面,选出最适合搬走副本的 store, 按照 region_score 倒叙排序, 优先考虑的条件有:
-
选择要搬走的副本,从当前选中的 source store 中选择一个副本,选择条件按优先级如下:
- pending regions
- followers
- Leaders
- Learners
-
选择一个目标 store 作为当前副本的目标
- 通过 placement-rule 选择符合要求的 store
- 检查 store limit add-peer ( https://docs.pingcap.com/tidb/stable/configure-store-limit#principles-of-store-limit-v2 )
- 检查 max-snapshot-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-snapshot-count )
- 检查 max-pending-peer-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-pending-peer-count )
- 最后对以上条件都符合的目标 store , 选择 region_score 最小的那个节点
常见问题
接下来,我们将根据上文说的调度生成的顺序,来介绍过程中可能遇到的问题及解决方案。
scheduler 被关闭导致没有调度生成
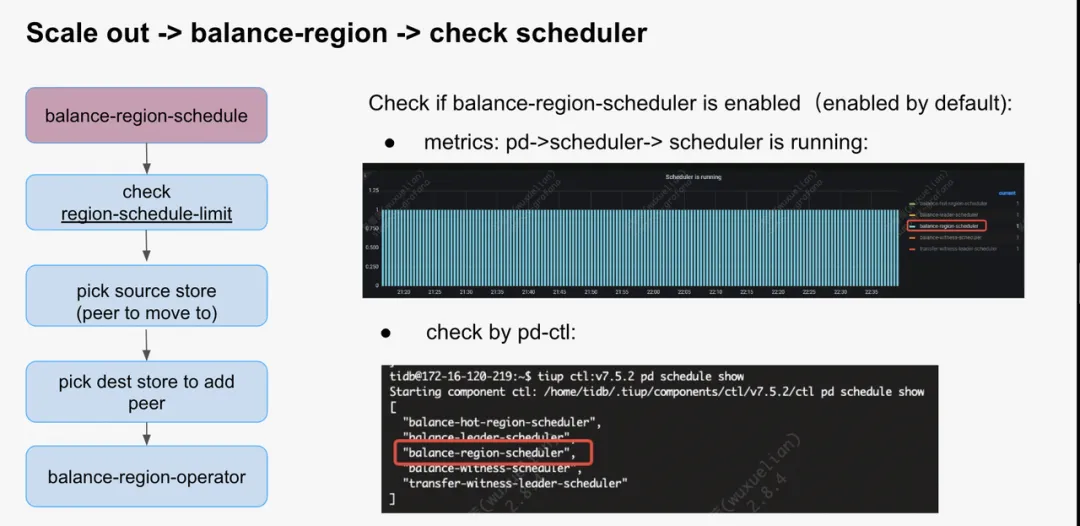
默认情况下 balance-region-scheduler 会被启用,但确实能够用 pd-ctl 将其删除。当发现没有 balance-region operator 生成时,第一步需要检查的便是确认 balance-region-scheduler 是否被启用。
- 通过监控查看 balance-region-scheduler 是否被启用,即调度发生的频率:
- PD->scheduler->scheduler is running
- 通过 pd-ctl 查看当前正在运行的 schedule
-
编辑 balance-region-scheduler
// remove balance-region-scheduler
~ tiup ctl:v7.5.2 pd schedule remove balance-region-scheduler Starting component ctl: /home/tidb/.tiup/components/ctl/v7.5.2/ctl pd schedule remove balance-region-scheduler Success! // add balance-region-scheduler ~ tiup ctl:v7.5.2 pd schedule add balance-region-scheduler
Starting component ctl: /home/tidb/.tiup/components/ctl/v7.5.2/ctl pd schedule add balance-region-scheduler Success! The scheduler is created."
受限于 region-schedule-limit
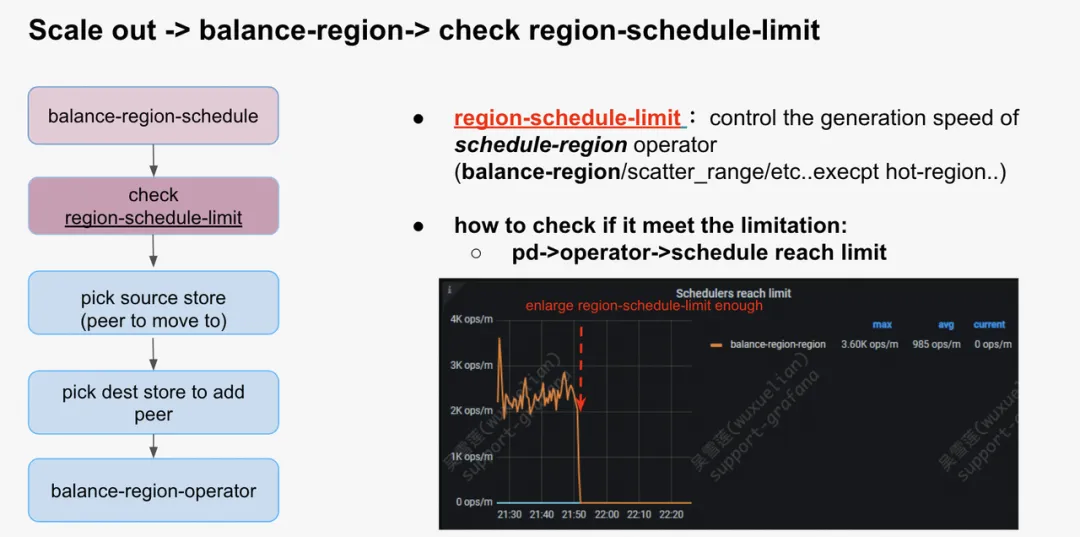
region-schedule-limit 是用来控制 balance-region / scatter-range/hot-region 等 region 相关的 operator 生成的并发度的,默认值是 2048,一般很难到达瓶颈。但考虑到这个参数是可以修改的,有时候误操作会将这个参数改得比较小,就容易出现问题。
-
通过 pd-ctl 检查及设置
// check config
tidb@:$ tiup ctl:v7.5.2 pd config show
Starting component ctl: /home/tidb/.tiup/components/ctl/v7.5.2/ctl pd config show
{
.....
"schedule": {
....
"max-movable-hot-peer-size": 512,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 0,
"patrol-region-interval": "10ms",
"region-schedule-limit": 2048,
....
}
}// update region-schedule-limit
tidb@:$ tiup ctl:v7.5.2 pd config set region-schedule-limit 1024
Starting component ctl: /home/tidb/.tiup/components/ctl/v7.5.2/ctl pd config set region-schedule-limit 1024
Success! -
通过监控看是否遇到瓶颈: PD ->operator->schedule reach limit
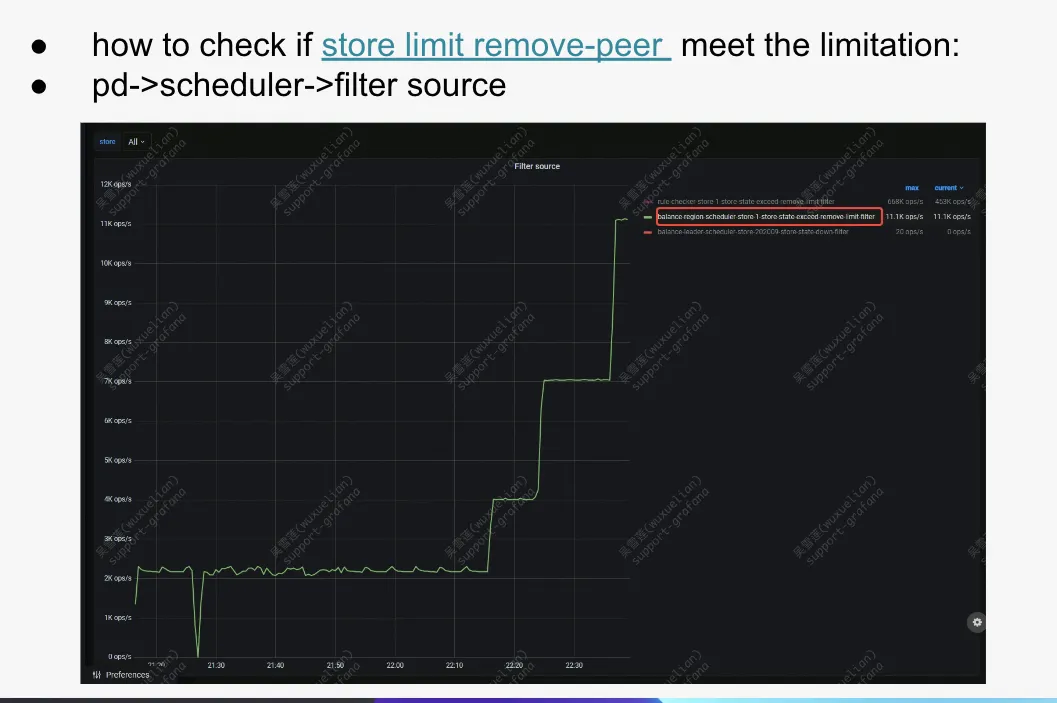
检查要被 move peer 的 store

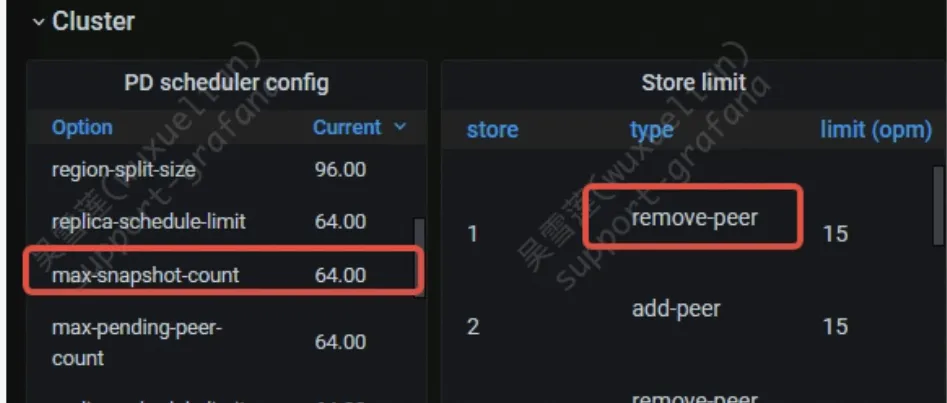
一般在 scale out 的过程中,已用空间比较大的 store 很容易被选为 balance-region 的目标对象,因此已用空间比较大的那个 store 很容易受到 store limit remove-peer 的影响。
- 通过监控查看 store limit 配置:PD->cluster->PD scheduler config/store limit
- Store limit remove peer 不足的场景:PD->scheduler->filter source 看到大量的 balance-region-XXX-remove-limit 时:
检查待 add peer 的 store
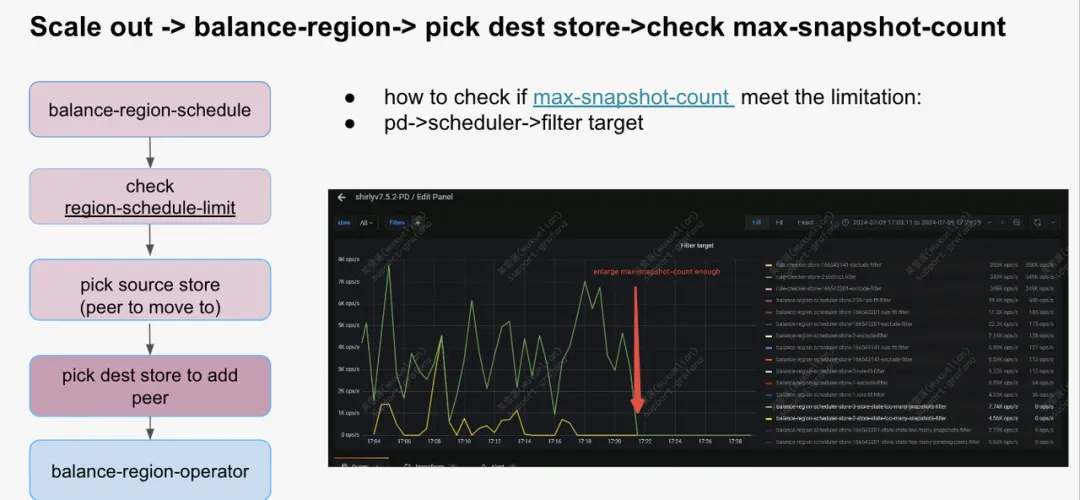
在扩容场景下,这类 store 往往是新扩容的节点,因此这些新节点很容易变成热点,相关配置也比较容易到达使用瓶颈。这里相关配置主要是以下三个:
- store limit add-peer ( https://docs.pingcap.com/tidb/stable/configure-store-limit#principles-of-store-limit-v2 ) : speed limit for the special store
- max-snapshot-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-snapshot-count ) : when the number of snapshots that a single store receives or sends meet the limit, it will never be chosen as a source or target store
- max-pending-peer-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-pending-peer-count ): control the maximum number of pending peers in a single store.
- Metrics 中查看配置项(同 source store 配置项查看):pd->cluster->pd scheduler config/store limit
- 查看目标节点配置项是否遇到瓶颈:pd->schedule -> filter target -> balance-regionXXX-{config}-filter
生成 operator 的速度
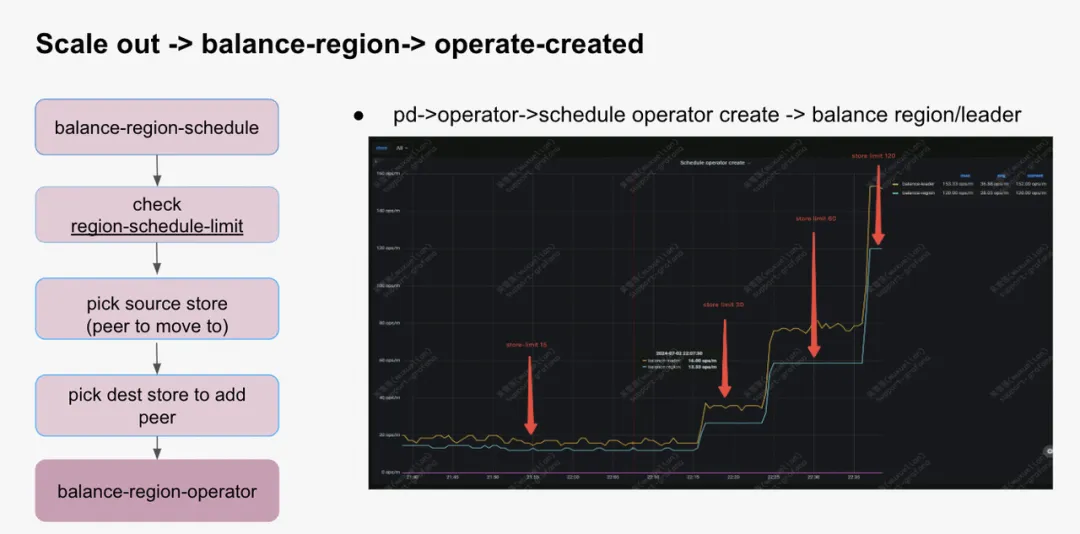
经过以上步骤,一个 balance region 的 operator 变生成了。我们可以通过 pd->operator->schedule operator create -> balance region 查看当前 operator 的产生速度.
Summary
PD 生成 balance region operator 的速度,直接影响整个扩容的速度。为了保证 PD 在生成 operator 的速度不会成为瓶颈,我们可以根据上文中的监控来确定以下配置项是否设置合理,进行适当的调优:
- ensure balance-region-scheduler is running
- region-schedule-limit ( https://docs.pingcap.com/tidb/v7.5/pd-configuration-file#region-schedule-limit ) :control the generation speed of schedule-region operator
- store limit remove-peer/add-peer ( https://docs.pingcap.com/tidb/stable/configure-store-limit#principles-of-store-limit-v2 ) : speed limit for the special store
- max-snapshot-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-snapshot-count ) : when the number of snapshots that a single store receives or sends meet the limit, it will never be choosed as a source or target store
- max-pending-peer-count ( https://docs.pingcap.com/tidb/stable/pd-configuration-file#max-pending-peer-count ): control the maximum number of pending peers in a single store.
如何判断当前扩容的瓶颈在 TiKV 还是在 PD 上
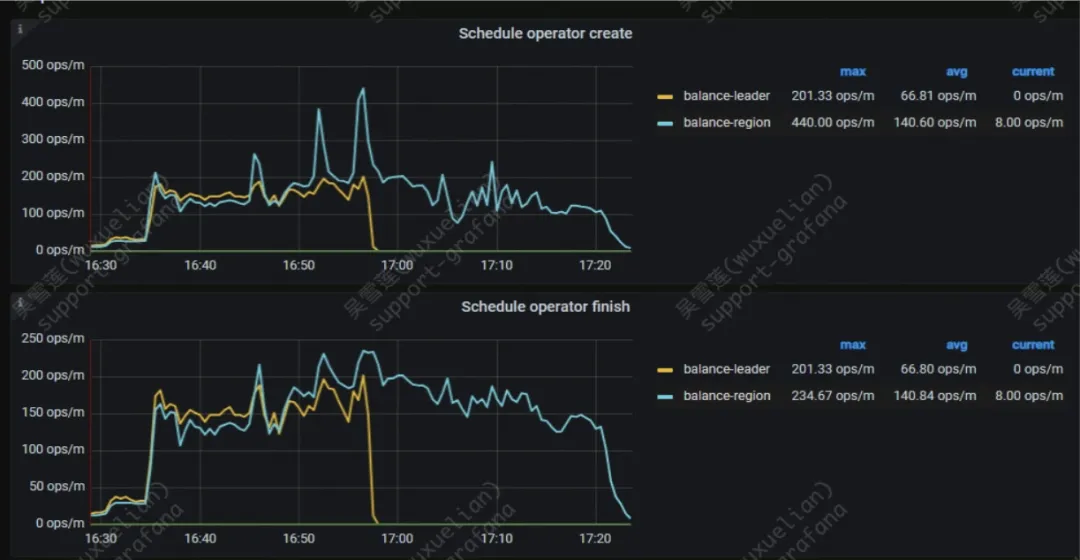
我们可以通过对比 PD 上的以上两个监控:
- PD->operators->schedule operator create
- PD->operators->schedule operator finish
来判断 operator 的消费速度能否跟得上生成速度,如果不能,说明 TiKV 中出现了瓶颈,则需要继续从 TiKV 中去寻找答案。