PostgreSQL Cross Join
说明
在本教程中,你将学习如何使用 PostgreSQL 的 CROSS JOIN 来生成连接表的笛卡尔积。
PostgreSQL CROSS JOIN 子句简介
在 PostgreSQL 中,交叉连接(cross-join)允许你将第一个表的每一行与第二个表的每一行进行组合,产生所有行的完整组合。
用集合论的术语来说,交叉连接产生两个表中所有行的 笛卡尔积。
与其他 JOIN 子句如 LEFT JOIN 或 INNER JOIN 不同,CROSS JOIN 子句没有连接条件。
假设你要对 table1 和 table2 执行 CROSS JOIN。
如果 table1 有 n 行,table2 有 m 行,CROSS JOIN 将返回一个包含 n×m 行的结果集。
例如,如果 table1 有 1,000 行,table2 有 1,000 行,结果集将有 1,000 × 1,000 = 1,000,000 行。
由于 CROSS JOIN 可能生成大量结果集,你应该谨慎使用以避免性能问题。
CROSS JOIN 的基本语法如下:
sql
SELECT
select_list
FROM
table1
CROSS JOIN table2;以下语句与上面的语句等价:
sql
SELECT
select_list
FROM
table1,table2;另外,你也可以使用 INNER JOIN 子句加上一个始终为真的条件来模拟交叉连接:
sql
SELECT
select_list
FROM
table1
INNER JOIN table2 ON true;PostgreSQL CROSS JOIN 示例
以下 CREATE TABLE 语句创建了 T1 和 T2 表,并 插入示例数据 用于交叉连接演示。
sql
DROP TABLE IF EXISTS T1;
CREATE TABLE
T1 (LABEL CHAR(1) PRIMARY KEY);
DROP TABLE IF EXISTS T2;
CREATE TABLE
T2 (score INT PRIMARY KEY);
INSERT INTO
T1 (LABEL)
VALUES
('A'),
('B');
INSERT INTO
T2 (score)
VALUES
(1),
(2),
(3);以下语句使用 CROSS JOIN 操作符将 T1 表与 T2 表连接:
sql
SELECT *
FROM T1
CROSS JOIN T2;label | score
-------+-------
A | 1
B | 1
A | 2
B | 2
A | 3
B | 3
(6 rows)下图说明了将 T1 表与 T2 表进行 CROSS JOIN 的工作原理:
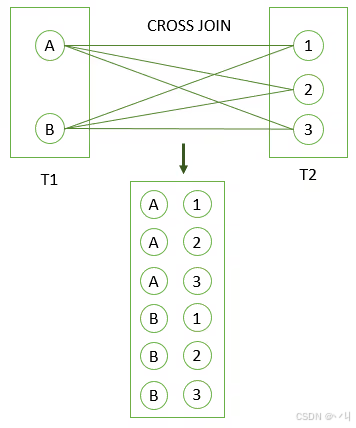
CROSS JOIN 的一些实际应用示例
实际上,当你需要在没有特定匹配条件的情况下组合两个表的数据时,CROSS JOIN 非常有用。例如:
1) 排班安排
假设你有 employees 和 shifts 两个表,你想创建一个排班表,列出所有可能的员工和班次组合,以探索各种人员配置方案:
sql
SELECT *
FROM employees
CROSS JOIN shift;2) 库存管理
在库存管理系统中,你有 warehouses 和 products 两个表。CROSS JOIN 可以帮助你分析每个仓库中每种产品的可用性:
sql
SELECT *
FROM products
CROSS JOIN warehouses;总结
- 使用 PostgreSQL
CROSS JOIN子句生成两个表中所有行的笛卡尔积。
PostgreSQL FULL OUTER JOIN
说明
在本教程中,你将学习如何使用 PostgreSQL 的 FULL OUTER JOIN 来查询两个表的数据。
PostgreSQL FULL OUTER JOIN 子句简介
FULL OUTER JOIN 组合两个表的数据,返回两个表中的所有行,包括两边的匹配行和不匹配行。
换句话说,FULL OUTER JOIN 结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
FULL OUTER JOIN 子句的基本语法如下:
sql
SELECT select_list
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name;语法说明:
- 首先,在
select_list中指定来自table1和table2的列。 - 其次,在
FROM子句中指定要从中检索数据的table1。 - 再次,在
FULL OUTER JOIN子句中指定要与table1连接的table2。 - 最后,定义连接两个表的条件。
FULL OUTER JOIN 也称为 FULL JOIN。OUTER 关键字是可选的。
FULL OUTER JOIN 的工作原理
步骤 1. 初始化结果集:
FULL OUTER JOIN从一个空结果集开始。
步骤 2. 匹配行:
- 首先,识别
table1和table2中指定column_name值匹配的行。 - 然后,将这些匹配行包含到结果集中。
步骤 3. 包含来自 table1 和 table2 的不匹配行:
- 首先,包含
table1中在table2中没有匹配的行。对于这些行中来自table2的列,填充 NULL。 - 其次,包含
table2中在table1中没有匹配的行。对于这些行中来自table1的列,填充 NULL。
步骤 4. 返回结果集:
- 返回的最终结果集将包含两个表的所有行,包括
table1和table2的匹配行和不匹配行。 - 如果一行在两边都有匹配,则将值合并到单行中。
- 如果某一边没有匹配,则不匹配侧的列将为 NULL。
以下文氏图说明了 FULL OUTER JOIN 操作:

设置示例表
首先,创建两个新表用于演示:employees 和 departments:
sql
CREATE TABLE departments (
department_id serial PRIMARY KEY,
department_name VARCHAR (255) NOT NULL
);
CREATE TABLE employees (
employee_id serial PRIMARY KEY,
employee_name VARCHAR (255),
department_id INTEGER
);每个部门有零个或多个员工,每个员工属于零个或一个部门。
其次,向 departments 和 employees 表插入一些示例数据。
sql
INSERT INTO departments (department_name)
VALUES
('Sales'),
('Marketing'),
('HR'),
('IT'),
('Production');
INSERT INTO employees (employee_name, department_id)
VALUES
('Bette Nicholson', 1),
('Christian Gable', 1),
('Joe Swank', 2),
('Fred Costner', 3),
('Sandra Kilmer', 4),
('Julia Mcqueen', NULL);第三,查询 departments 和 employees 表的数据:
sql
SELECT * FROM departments;输出:
department_id | department_name
---------------+-----------------
1 | Sales
2 | Marketing
3 | HR
4 | IT
5 | Production
(5 rows)
sql
SELECT * FROM employees;输出:
employee_id | employee_name | department_id
-------------+-----------------+---------------
1 | Bette Nicholson | 1
2 | Christian Gable | 1
3 | Joe Swank | 2
4 | Fred Costner | 3
5 | Sandra Kilmer | 4
6 | Julia Mcqueen | null
(6 rows)PostgreSQL FULL OUTER JOIN 示例
让我们看一些使用 FULL OUTER JOIN 子句的示例。
1) 基本 FULL OUTER JOIN 示例
以下查询使用 FULL OUTER JOIN 从 employees 和 departments 表中查询数据:
sql
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d
ON d.department_id = e.department_id;输出:
employee_name | department_name
-----------------+-----------------
Bette Nicholson | Sales
Christian Gable | Sales
Joe Swank | Marketing
Fred Costner | HR
Sandra Kilmer | IT
Julia Mcqueen | null
null | Production
(7 rows)结果集包括每个属于某个部门的员工和每个有员工的部门。
此外,它还包括每个不属于任何部门的员工和每个没有员工的部门。
2) FULL OUTER JOIN 与 WHERE 子句示例
以下示例使用 FULL OUTER JOIN 和 WHERE 子句查找没有任何员工的部门:
sql
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d
ON d.department_id = e.department_id
WHERE
employee_name IS NULL;输出:
employee_name | department_name
---------------+-----------------
null | Production
(1 row)结果显示 Production 部门没有任何员工。
以下示例使用 FULL OUTER JOIN 子句和 WHERE 子句查找不属于任何部门的员工:
sql
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d
ON d.department_id = e.department_id
WHERE
department_name IS NULL;输出:
employee_name | department_name
---------------+-----------------
Julia Mcqueen | null
(1 row)输出显示 Julia Mcqueen 不属于任何部门。
总结
- 使用 PostgreSQL
FULL OUTER JOIN子句组合两个表的数据,确保包含左右两边的匹配行,以及任一侧的不匹配行。
PostgreSQL Self-join By Practical Examples
说明
在本教程中,你将学习如何使用 PostgreSQL 自连接技术来比较同一表内的行。
PostgreSQL 自连接简介
自连接是一种将表与其自身连接的常规连接。实际上,你通常使用自连接来查询层次结构数据或比较同一表内的行。
要形成自连接,你需要使用 不同的表别名 指定同一个表两次,并在 ON 关键字后提供连接条件。
以下查询使用 INNER JOIN 将表与其自身连接:
sql
SELECT select_list
FROM table_name t1
INNER JOIN table_name t2 ON join_predicate;在这个语法中,table_name 使用 INNER JOIN 子句与自身连接。
另外,你也可以使用 LEFT JOIN 或 RIGHT JOIN 子句将表与其自身连接,如下所示:
sql
SELECT select_list
FROM table_name t1
LEFT JOIN table_name t2 ON join_predicate;PostgreSQL 自连接示例
让我们看一些自连接的示例。
1) 查询层次结构数据示例
让我们设置一个示例表进行演示。
假设你有以下组织结构:
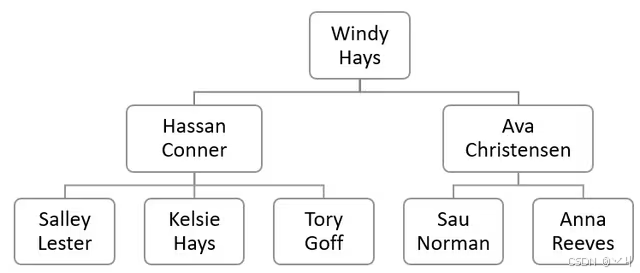
以下语句创建 employee 表并向表中插入一些示例数据。
sql
CREATE TABLE employee (
employee_id INT PRIMARY KEY,
first_name VARCHAR (255) NOT NULL,
last_name VARCHAR (255) NOT NULL,
manager_id INT,
FOREIGN KEY (manager_id) REFERENCES employee (employee_id) ON DELETE CASCADE
);
INSERT INTO employee (employee_id, first_name, last_name, manager_id)
VALUES
(1, 'Windy', 'Hays', NULL),
(2, 'Ava', 'Christensen', 1),
(3, 'Hassan', 'Conner', 1),
(4, 'Anna', 'Reeves', 2),
(5, 'Sau', 'Norman', 2),
(6, 'Kelsie', 'Hays', 3),
(7, 'Tory', 'Goff', 3),
(8, 'Salley', 'Lester', 3);
SELECT * FROM employee;输出:
employee_id | first_name | last_name | manager_id
-------------+------------+-------------+------------
1 | Windy | Hays | null
2 | Ava | Christensen | 1
3 | Hassan | Conner | 1
4 | Anna | Reeves | 2
5 | Sau | Norman | 2
6 | Kelsie | Hays | 3
7 | Tory | Goff | 3
8 | Salley | Lester | 3
(8 rows)在这个 employee 表中,manager_id 列引用 employee_id 列。
manager_id 列表示直接关系,显示员工向哪个经理汇报。
如果 manager_id 列包含 NULL,表示该员工不向任何人汇报,实际上是最高管理层职位。
以下查询使用自连接来查找谁向谁汇报:
sql
SELECT
e.first_name || ' ' || e.last_name employee,
m.first_name || ' ' || m.last_name manager
FROM
employee e
INNER JOIN employee m ON m.employee_id = e.manager_id
ORDER BY
manager;输出:
employee | manager
-----------------+-----------------
Sau Norman | Ava Christensen
Anna Reeves | Ava Christensen
Salley Lester | Hassan Conner
Kelsie Hays | Hassan Conner
Tory Goff | Hassan Conner
Ava Christensen | Windy Hays
Hassan Conner | Windy Hays
(7 rows)此查询两次引用 employees 表,一次作为员工,一次作为经理。它使用表别名 e 表示员工,m 表示经理。
连接条件通过匹配 employee_id 和 manager_id 列中的值来查找员工/经理对。
请注意,最高管理者没有出现在输出中。
要在结果集中包含最高管理者,你需要使用 LEFT JOIN 而不是 INNER JOIN 子句,如下所示:
sql
SELECT
e.first_name || ' ' || e.last_name employee,
m.first_name || ' ' || m.last_name manager
FROM
employee e
LEFT JOIN employee m ON m.employee_id = e.manager_id
ORDER BY
manager;输出:
employee | manager
-----------------+-----------------
Anna Reeves | Ava Christensen
Sau Norman | Ava Christensen
Salley Lester | Hassan Conner
Kelsie Hays | Hassan Conner
Tory Goff | Hassan Conner
Hassan Conner | Windy Hays
Ava Christensen | Windy Hays
Windy Hays | null
(8 rows)2) 比较同一表中的行
请看 DVD 租赁数据库中的以下 film 表:

以下查询查找所有长度相同的电影对:
sql
SELECT
f1.title,
f2.title,
f1.length
FROM
film f1
INNER JOIN film f2 ON f1.film_id > f2.film_id
AND f1.length = f2.length;输出:
title | title | length
---------------------------+-----------------------------+--------
Chamber Italian | Affair Prejudice | 117
Grosse Wonderful | Doors President | 49
Bright Encounters | Bedazzled Married | 73
Date Speed | Crow Grease | 104
Annie Identity | Academy Dinosaur | 86
Anything Savannah | Alone Trip | 82
Apache Divine | Anaconda Confessions | 92
Arabia Dogma | Airplane Sierra | 62
Dying Maker | Antitrust Tomatoes | 168
...连接条件匹配两个不同的电影(f1.film_id > f2.film_id)且长度相同(f1.length = f2.length)。
总结
- PostgreSQL 自连接是使用
INNER JOIN或LEFT JOIN将表与其自身连接的常规连接。 - 自连接对于查询层次结构数据或比较同一表内的行非常有用。
PostgreSQL RIGHT JOIN
说明
在本教程中,你将学习如何使用 PostgreSQL RIGHT JOIN 来连接两个表,并返回右表中的行(无论左表中是否有匹配的行)。
PostgreSQL RIGHT JOIN 子句简介
RIGHT JOIN 子句将右表与左表连接,并返回右表中的行(无论左表中是否有匹配的行)。
当你想要查找右表中在左表中没有匹配行的那些行时,RIGHT JOIN 非常有用。
RIGHT JOIN 子句的基本语法如下:
sql
SELECT
select_list
FROM
table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;语法说明:
- 首先,在
SELECT子句的select_list中指定两个表的列。 - 其次,在
FROM子句中提供要从中选择数据的左表(table1)。 - 再次,在
RIGHT JOIN子句中指定要与左表连接的右表(table2)。 - 最后,定义连接两个表的条件(
table1.column_name = table2.column_name),表示每个表中的column_name应该有匹配的行。
RIGHT JOIN 的工作原理
RIGHT JOIN 从右表(table2)开始检索数据。
对于右表(table2)中的每一行,RIGHT JOIN 检查 column_name 中的值是否等于左表(table1)中每一行对应列的值。
当这些值相等时,RIGHT JOIN 创建一个包含 select_list 中指定列的新行,并将其追加到结果集。
如果这些值不相等,RIGHT JOIN 生成一个包含 select_list 中指定列的新行,将左侧的列填充为 NULL,并将新行追加到结果集。
换句话说,RIGHT JOIN 返回右表中的所有行,无论它们在左表中是否有对应行。
以下文氏图说明了 RIGHT JOIN 的工作原理:
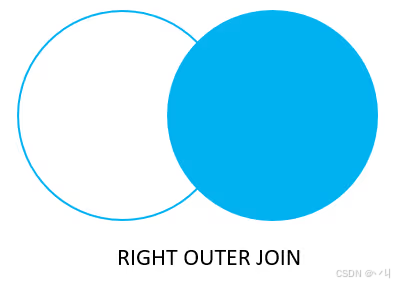
请注意,RIGHT OUTER JOIN 与 RIGHT JOIN 相同。OUTER 关键字是可选的。
USING 语法
当连接列具有相同名称时,你可以使用 USING 语法:
sql
SELECT
select_list
FROM
table1
RIGHT JOIN table2 USING (column_name);PostgreSQL RIGHT JOIN 示例
我们将使用 示例数据库 中的 film 和 inventory 表。
1) 基本 PostgreSQL RIGHT JOIN 示例
以下示例使用 RIGHT JOIN 子句检索 film 表中的所有行(无论 inventory 表中是否有对应行):
sql
SELECT
film.film_id,
film.title,
inventory.inventory_id
FROM
inventory
RIGHT JOIN film
ON film.film_id = inventory.film_id
ORDER BY
film.title;输出:
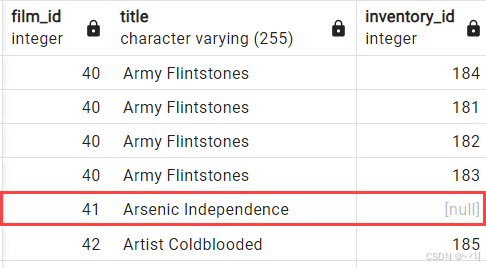
你可以使用表别名重写上述查询:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
inventory i
RIGHT JOIN film f
ON f.film_id = i.film_id
ORDER BY
f.title;由于 film 和 inventory 表都有 film_id 列,你可以使用 USING 语法:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
inventory i
RIGHT JOIN film f USING(film_id)
ORDER BY
f.title;2) PostgreSQL RIGHT JOIN 与 WHERE 子句
以下查询使用 RIGHT JOIN 子句和 WHERE 子句检索没有库存的电影:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
inventory i
RIGHT JOIN film f USING(film_id)
WHERE i.inventory_id IS NULL
ORDER BY
f.title;输出:
film_id | title | inventory_id
---------+------------------------+--------------
14 | Alice Fantasia | null
33 | Apollo Teen | null
36 | Argonauts Town | null
38 | Ark Ridgemont | null
41 | Arsenic Independence | null
...总结
- 使用 PostgreSQL
RIGHT JOIN子句将右表与左表连接,并返回右表中的行(无论左表中是否有对应行)。 RIGHT JOIN也称为RIGHT OUTER JOIN。
PostgreSQL LEFT JOIN
说明
在本教程中,你将学习如何使用 PostgreSQL 的 LEFT JOIN 子句从多个表中选择数据。
PostgreSQL LEFT JOIN 子句简介
LEFT JOIN 子句将左表与右表连接,并返回左表中的行(无论右表中是否有对应行)。
LEFT JOIN 对于从一个表中选择在另一个表中没有匹配行的行非常有用。
LEFT JOIN 子句的基本语法如下:
sql
SELECT
select_list
FROM
table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;语法说明:
- 首先,在
SELECT子句的选择列表(select_list)中指定两个表的列。 - 其次,在
FROM子句中指定要从中选择数据的左表(table1)。 - 再次,使用
LEFT JOIN关键字指定要连接的右表(table2)。 - 最后,定义连接条件(
table1.column_name = table2.column_name),表示每个表中的列(column_name)应该有匹配的值。
LEFT JOIN 的工作原理
LEFT JOIN 子句从左表(table1)开始选择数据。对于左表中的每一行,它将 column_name 中的值与右表中每一行对应列的值进行比较。
当这些值相等时,LEFT JOIN 子句生成一个包含 select_list 中出现的列的新行,并将其追加到结果集。
如果这些值不相等,LEFT JOIN 子句创建一个包含 SELECT 子句中指定列的新行。此外,它将来自右表的列填充为 NULL。
请注意,LEFT JOIN 也称为 LEFT OUTER JOIN。
如果连接两个表的列具有相同名称,你可以使用 USING 语法:
sql
SELECT
select_list
FROM
table1
LEFT JOIN table2 USING (column_name);以下文氏图说明了 LEFT JOIN 子句的工作原理:
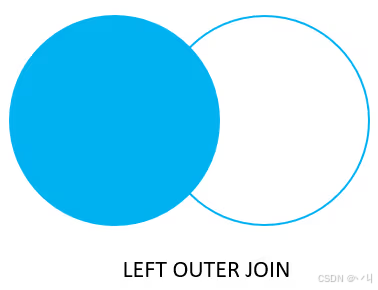
PostgreSQL LEFT JOIN 示例
让我们看一下以下 film 和 inventory 表。
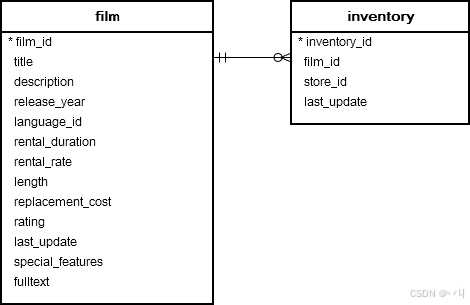
film 表中的每一行可能对应 inventory 表中的零行或多行。
相反,inventory 表中的每一行在 film 表中只有一行对应。
film 和 inventory 表之间的链接通过 film_id 列建立。
1) 基本 PostgreSQL LEFT JOIN 示例
以下语句使用 LEFT JOIN 子句将 film 表与 inventory 表连接:
sql
SELECT
film.film_id,
film.title,
inventory.inventory_id
FROM
film
LEFT JOIN inventory ON inventory.film_id = film.film_id
ORDER BY
film.title;
当 film 表中的某一行在 inventory 表中没有匹配行时,该行的 inventory_id 列值为 NULL。
以下语句使用表别名和 LEFT JOIN 子句连接 film 和 inventory 表:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film f
LEFT JOIN inventory i ON i.film_id = f.film_id
ORDER BY
i.inventory_id;由于 film 和 inventory 表共享相同的 film_id 列,你可以使用 USING 语法:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film f
LEFT JOIN inventory i USING (film_id)
ORDER BY
i.inventory_id;2) PostgreSQL LEFT JOIN 与 WHERE 子句
以下使用 LEFT JOIN 子句连接 inventory 和 film 表。它包含一个 WHERE 子句来识别库存中不存在的电影:
sql
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film f
LEFT JOIN inventory i USING (film_id)
WHERE
i.inventory_id IS NULL
ORDER BY
f.title;输出:
film_id | title | inventory_id
---------+------------------------+--------------
14 | Alice Fantasia | null
33 | Apollo Teen | null
36 | Argonauts Town | null
38 | Ark Ridgemont | null
41 | Arsenic Independence | null
...总结
- 使用 PostgreSQL
LEFT JOIN子句从一个表中选择行(无论其他表中是否有对应行)。
PostgreSQL INNER JOIN
说明
在本教程中,你将学习如何使用 PostgreSQL INNER JOIN 子句从多个表中选择数据。
PostgreSQL INNER JOIN 子句简介
在关系数据库中,数据通常分布在多个表中。要检索全面的数据,你经常需要从多个表中查询。
在本教程中,我们专注于如何使用 INNER JOIN 子句从多个表中检索数据。
以下是连接两个表的 INNER JOIN 子句的通用语法:
sql
SELECT
select_list
FROM
table1
INNER JOIN table2
ON table1.column_name = table2.column_name;语法说明:
- 首先,在
SELECT子句的选择列表中指定两个表的列。 - 其次,在
FROM子句中指定要从中选择数据的主表(table1)。 - 再次,使用
INNER JOIN关键字指定要连接的第二个表(table2)。 - 最后,定义连接条件。此条件指示每个表中的哪个列(
column_name)应该有匹配值才能进行连接。
为了使查询更简洁,你可以使用 表别名:
sql
SELECT
select_list
FROM
table1 t1
INNER JOIN table2 t2
ON t1.column_name = t2.column_name;在这个语法中,我们首先将 t1 和 t2 分配为 table1 和 table2 的表别名。然后,我们使用表别名来限定每个表的列。
如果用于匹配的列具有相同名称,你可以使用 USING 语法:
sql
SELECT
select_list
FROM
table1 t1
INNER JOIN table2 t2 USING(column_name);INNER JOIN 的工作原理
对于 table1 中的每一行,INNER JOIN 将 column_name 中的值与 table2 中每一行对应列的值进行比较。
当这些值相等时,INNER JOIN 创建一个包含两个表所有列的新行,并将此行添加到结果集。
相反,如果这些值不相等,INNER JOIN 忽略当前对,继续下一行,重复匹配过程。
以下文氏图说明了 INNER JOIN 子句的工作原理。
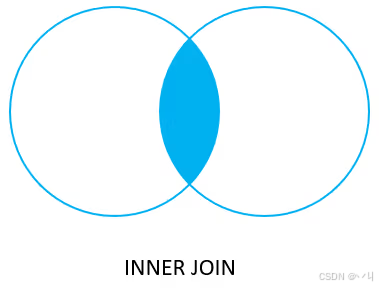
PostgreSQL INNER JOIN 示例
让我们看一些使用 INNER JOIN 子句的示例。
1) 使用 PostgreSQL INNER JOIN 连接两个表
让我们看一下 示例数据库 中的 customer 和 payment 表。
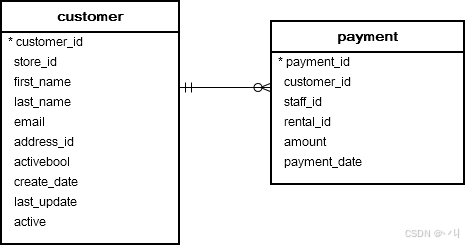
在这个模式中,每当客户付款时,新行就会插入到 payment 表中。虽然每个客户可能有零次或多次付款,但每次付款只属于一个客户。customer_id 列作为建立两个表之间关系的链接。
以下语句使用 INNER JOIN 子句从两个表中选择数据:
sql
SELECT
customer.customer_id,
customer.first_name,
customer.last_name,
payment.amount,
payment.payment_date
FROM
customer
INNER JOIN payment ON payment.customer_id = customer.customer_id
ORDER BY
payment.payment_date;输出:
customer_id | first_name | last_name | amount | payment_date
-------------+-------------+--------------+--------+----------------------------
416 | Jeffery | Pinson | 2.99 | 2007-02-14 21:21:59.996577
516 | Elmer | Noe | 4.99 | 2007-02-14 21:23:39.996577
239 | Minnie | Romero | 4.99 | 2007-02-14 21:29:00.996577
592 | Terrance | Roush | 6.99 | 2007-02-14 21:41:12.996577
49 | Joyce | Edwards | 0.99 | 2007-02-14 21:44:52.996577
...为了使查询更简洁,你可以使用表别名:
sql
SELECT
c.customer_id,
c.first_name,
c.last_name,
p.amount,
p.payment_date
FROM
customer c
INNER JOIN payment p ON p.customer_id = c.customer_id
ORDER BY
p.payment_date;由于两个表都有相同的 customer_id 列,你可以使用 USING 语法:
sql
SELECT
customer_id,
first_name,
last_name,
amount,
payment_date
FROM
customer
INNER JOIN payment USING(customer_id)
ORDER BY
payment_date;2) 使用 PostgreSQL INNER JOIN 连接三个表
下图说明了三个表之间的关系:staff、payment 和 customer:
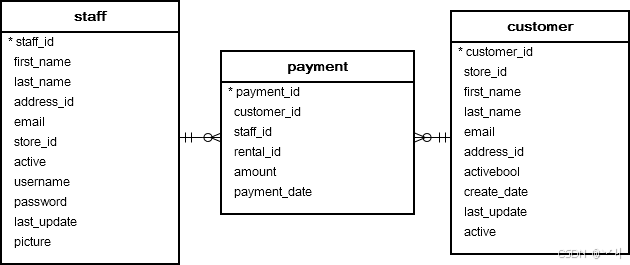
每个员工可以处理零次或多次付款,每次付款由一个且仅一个员工处理。
同样,每个客户可以进行零次或多次付款,每次付款与一个客户关联。
以下示例使用 INNER JOIN 子句从三个表中检索数据:
sql
SELECT
c.customer_id,
c.first_name || ' ' || c.last_name customer_name,
s.first_name || ' ' || s.last_name staff_name,
p.amount,
p.payment_date
FROM
customer c
INNER JOIN payment p USING(customer_id)
INNER JOIN staff s USING(staff_id)
ORDER BY
payment_date;输出:
customer_id | customer_name | staff_name | amount | payment_date
-------------+-----------------------+--------------+--------+----------------------------
416 | Jeffery Pinson | Jon Stephens | 2.99 | 2007-02-14 21:21:59.996577
516 | Elmer Noe | Jon Stephens | 4.99 | 2007-02-14 21:23:39.996577
239 | Minnie Romero | Mike Hillyer | 4.99 | 2007-02-14 21:29:00.996577
592 | Terrance Roush | Jon Stephens | 6.99 | 2007-02-14 21:41:12.996577
49 | Joyce Edwards | Mike Hillyer | 0.99 | 2007-02-14 21:44:52.996577
...总结
- 使用
INNER JOIN子句从两个或多个相关表中选择数据,并返回在所有表中都有匹配值的行。
PostgreSQL Table Aliases
说明
在本教程中,你将了解 PostgreSQL 表别名及其实际应用。
PostgreSQL 表别名简介
表别名是 SQL 中的一项功能,允许你在查询执行期间为表分配一个临时名称。
以下说明了定义表别名的语法:
sql
table_name AS alias_name语法说明:
table_name:指定要给别名的表的名称。alias_name:提供表的别名。
与 列别名 一样,AS 关键字是可选的,这意味着你可以像这样省略它:
sql
table_name alias_namePostgreSQL 表别名示例
让我们看一些使用表别名的示例。
1) 基本 PostgreSQL 表别名示例
以下示例使用表别名从 film 表中检索五个标题:
sql
SELECT f.title
FROM film AS f
ORDER BY f.title
LIMIT 5;输出:
title
------------------
Academy Dinosaur
Ace Goldfinger
Adaptation Holes
Affair Prejudice
African Egg
(5 rows)在此示例中,我们为 film 表分配别名 f,并使用表别名来完全限定 title 列。
由于 AS 关键字是可选的,你可以如下所示移除它:
sql
SELECT f.title
FROM film f
ORDER BY f.title
LIMIT 5;2) 在连接子句中使用表别名
通常,你在具有 JOIN 子句的查询中使用表别名,以从多个共享相同列名的相关表中检索数据。
如果你在同一查询中使用来自多个表的相同列名而不完全限定它们,将会出错。
为避免此错误,你可以使用以下语法限定列:
sql
table_name.column_name如果表有别名,你可以使用别名来限定其列:
sql
alias.column_name例如,以下查询使用 INNER JOIN 子句从 customer 和 payment 表中检索数据:
sql
SELECT
c.customer_id,
c.first_name,
p.amount,
p.payment_date
FROM
customer c
INNER JOIN payment p ON p.customer_id = c.customer_id
ORDER BY
p.payment_date DESC;输出:
customer_id | first_name | amount | payment_date
-------------+-------------+--------+----------------------------
94 | Norma | 4.99 | 2007-05-14 13:44:29.996577
264 | Gwendolyn | 2.99 | 2007-05-14 13:44:29.996577
263 | Hilda | 0.99 | 2007-05-14 13:44:29.996577
252 | Mattie | 4.99 | 2007-05-14 13:44:29.996577请注意,你将在后续教程中学习 INNER JOIN。
3) 在自连接中使用表别名
当你将表与其自身连接时(也称为 自连接),你需要使用表别名。这是因为在查询中多次引用同一个表会导致错误。
以下示例展示了如何使用表别名在同一查询中两次引用 film 表:
sql
SELECT
f1.title,
f2.title,
f1.length
FROM
film f1
INNER JOIN film f2
ON f1.film_id <> f2.film_id AND
f1.length = f2.length;输出:
title | title | length
-----------------------------+-----------------------------+--------
Chamber Italian | Resurrection Silverado | 117
Chamber Italian | Magic Mallrats | 117
Chamber Italian | Graffiti Love | 117
Chamber Italian | Affair Prejudice | 117
Grosse Wonderful | Hurricane Affair | 49
Grosse Wonderful | Hook Chariots | 49
Grosse Wonderful | Heavenly Gun | 49
Grosse Wonderful | Doors President | 49
...请注意,你将在后续教程中学习 自连接。
总结
- 使用 PostgreSQL 表别名在查询执行期间为表分配临时名称。
PostgreSQL NATURAL JOIN Explained By Example
说明
在本教程中,你将学习如何使用 PostgreSQL 的 NATURAL JOIN 来查询两个表的数据。
PostgreSQL NATURAL JOIN 子句简介
自然连接是一种基于连接表中相同列名创建隐式连接的 JOIN。
以下显示 PostgreSQL NATURAL JOIN 子句的语法:
sql
SELECT select_list
FROM table1
NATURAL [INNER, LEFT, RIGHT] JOIN table2;语法说明:
- 首先,在
SELECT子句的select_list中指定要从中检索数据的表的列。 - 其次,提供要从中检索数据的主表(
table1)。 - 再次,在
NATURAL JOIN子句中指定要与主表连接的表(table2)。
自然连接可以是 INNER JOIN、LEFT JOIN 或 RIGHT JOIN。如果不指定显式连接类型,PostgreSQL 默认使用 INNER JOIN。
NATURAL JOIN 的便利之处在于它不需要你在连接子句中指定条件,因为它使用基于公共列相等性的隐式条件。
NATURAL JOIN 子句的等效形式如下:
sql
SELECT select_list
FROM table1
[INNER, LEFT, RIGHT] JOIN table2
ON table1.column_name = table2.column_name;INNER JOIN
以下语句是等效的:
sql
SELECT select_list
FROM table1
NATURAL INNER JOIN table2;和
sql
SELECT select_list
FROM table1
INNER JOIN table2 USING (column_name);LEFT JOIN
以下语句是等效的:
sql
SELECT select_list
FROM table1
NATURAL LEFT JOIN table2;和
sql
SELECT select_list
FROM table1
LEFT JOIN table2 USING (column_name);RIGHT JOIN
以下语句是等效的:
sql
SELECT select_list
FROM table1
NATURAL RIGHT JOIN table2;和
sql
SELECT select_list
FROM table1
RIGHT JOIN table2 USING (column_name);设置示例表
以下语句创建 categories 和 products 表,并插入示例数据用于演示:
sql
CREATE TABLE categories (
category_id SERIAL PRIMARY KEY,
category_name VARCHAR (255) NOT NULL
);
CREATE TABLE products (
product_id serial PRIMARY KEY,
product_name VARCHAR (255) NOT NULL,
category_id INT NOT NULL,
FOREIGN KEY (category_id) REFERENCES categories (category_id)
);
INSERT INTO categories (category_name)
VALUES
('Smartphone'),
('Laptop'),
('Tablet'),
('VR')
RETURNING *;
INSERT INTO products (product_name, category_id)
VALUES
('iPhone', 1),
('Samsung Galaxy', 1),
('HP Elite', 2),
('Lenovo Thinkpad', 2),
('iPad', 3),
('Kindle Fire', 3)
RETURNING *;products 表包含以下数据:
product_id | product_name | category_id
------------+-----------------+-------------
1 | iPhone | 1
2 | Samsung Galaxy | 1
3 | HP Elite | 2
4 | Lenovo Thinkpad | 2
5 | iPad | 3
6 | Kindle Fire | 3
(6 rows)categories 表包含以下数据:
category_id | category_name
-------------+---------------
1 | Smartphone
2 | Laptop
3 | Tablet
4 | VR
(4 rows)PostgreSQL NATURAL JOIN 示例
让我们看一些使用 NATURAL JOIN 语句的示例。
1) 基本 PostgreSQL NATURAL JOIN 示例
以下语句使用 NATURAL JOIN 子句将 products 表与 categories 表连接:
sql
SELECT *
FROM products
NATURAL JOIN categories;此语句使用 category_id 列执行内连接。
输出:
category_id | product_id | product_name | category_name
-------------+------------+-----------------+---------------
1 | 1 | iPhone | Smartphone
1 | 2 | Samsung Galaxy | Smartphone
2 | 3 | HP Elite | Laptop
2 | 4 | Lenovo Thinkpad | Laptop
3 | 5 | iPad | Tablet
3 | 6 | Kindle Fire | Tablet
(6 rows)该语句等效于以下使用 INNER JOIN 子句的语句:
sql
SELECT *
FROM products
INNER JOIN categories USING (category_id);2) 使用 PostgreSQL NATURAL JOIN 执行 LEFT JOIN
以下示例使用 NATURAL JOIN 子句执行 LEFT JOIN,无需指定匹配列:
sql
SELECT *
FROM categories
NATURAL LEFT JOIN products;输出:
category_id | category_name | product_id | product_name
-------------+---------------+------------+-----------------
1 | Smartphone | 1 | iPhone
1 | Smartphone | 2 | Samsung Galaxy
2 | Laptop | 3 | HP Elite
2 | Laptop | 4 | Lenovo Thinkpad
3 | Tablet | 5 | iPad
3 | Tablet | 6 | Kindle Fire
4 | VR | null | null
(7 rows)3) 使用 NATURAL JOIN 导致意外结果的示例
实际上,应尽可能避免使用 NATURAL JOIN,因为有时它可能导致意外结果。
考虑 示例数据库 中的以下 city 和 country 表:


两个表都有相同的 country_id 列,因此你可以使用 NATURAL JOIN 来连接这些表,如下所示:
sql
SELECT *
FROM city
NATURAL JOIN country;查询返回空结果集。
原因是两个表还有另一个公共列 last_update。当 NATURAL JOIN 子句使用 last_update 列时,它找不到任何匹配项。
总结
- 使用 PostgreSQL
NATURAL JOIN子句从具有公共列的两个或多个表中查询数据。
PostgreSQL Joins
说明
在本教程中,你将了解各种 PostgreSQL 连接类型,包括内连接、左连接、右连接和全外连接。
PostgreSQL 连接用于基于相关表之间公共列的值来组合一个(自连接)或多个表的列。公共列通常是第一个表的 主键 列和第二个表的 外键 列。
PostgreSQL 支持 内连接、左连接、右连接、全外连接、交叉连接、自然连接,以及一种特殊的连接称为 自连接。
设置示例表
假设你有两个表:teams 和 players:
sql
CREATE TABLE teams (
id INT PRIMARY KEY,
team VARCHAR (100) NOT NULL,
city VARCHAR (100) NOT NULL
);
CREATE TABLE players (
id INT PRIMARY KEY,
team_id INT REFERENCES teams (id),
player VARCHAR (100) NOT NULL,
role VARCHAR (100) NOT NULL
);
INSERT INTO teams (id, team, city)
VALUES
(1, 'Lions', 'Rome'),
(2, 'Owls', 'Oslo'),
(3, 'Bears', 'Bern'),
(4, 'Sharks', 'Lima');
INSERT INTO players (id, team_id, player, role)
VALUES
(1, 1, 'Ava', 'Guard'),
(2, 1, 'Noah', 'Wing'),
(3, 2, 'Emma', 'Back'),
(4, NULL, 'Liam', 'Guard'),
(5, NULL, 'Mia', 'Wing');一个团队可以有多个球员。有些球员可能还不属于任何团队,因此他们的 team_id 为 NULL。
以下语句返回 teams 表的数据:
sql
SELECT * FROM teams;输出:
id | team | city
----+--------+------
1 | Lions | Rome
2 | Owls | Oslo
3 | Bears | Bern
4 | Sharks | Lima
(4 rows)以下语句返回 players 表的数据:
sql
SELECT * FROM players;输出:
id | team_id | player | role
----+---------+--------+-------
1 | 1 | Ava | Guard
2 | 1 | Noah | Wing
3 | 2 | Emma | Back
4 | null | Liam | Guard
5 | null | Mia | Wing
(5 rows)PostgreSQL 内连接
以下语句通过匹配 id 和 team_id 列中的值,将第一个表(teams)与第二个表(players)连接:
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
INNER JOIN players
ON teams.id = players.team_id;注意 :通常使用 JOIN 作为 INNER JOIN 的简写。输出:
team_id | team | city | player_id | player | role
---------+-------+------+-----------+--------+-------
1 | Lions | Rome | 1 | Ava | Guard
1 | Lions | Rome | 2 | Noah | Wing
2 | Owls | Oslo | 3 | Emma | Back
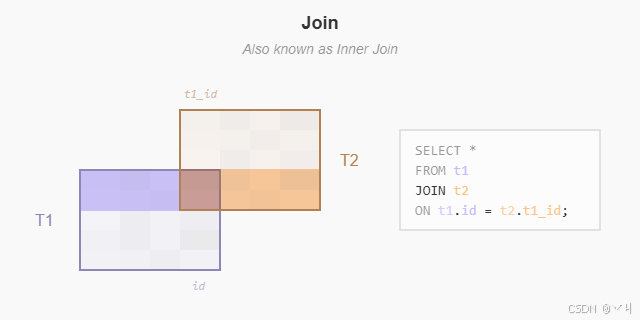
(3 rows)内连接检查第一个表(teams)中的每一行。它将 id 列中的值与第二个表(players)中每一行的 team_id 列中的值进行比较。如果这些值相等,内连接创建一个包含两个表列的新行,并将此新行添加到结果集。
下图说明了内连接:
PostgreSQL 左连接
以下语句使用左连接子句将 teams 表与 players 表连接。在左连接上下文中,第一个表称为左表,第二个表称为右表。
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
LEFT JOIN players
ON teams.id = players.team_id;输出:
team_id | team | city | player_id | player | role
---------+--------+------+-----------+--------+-------
1 | Lions | Rome | 1 | Ava | Guard
1 | Lions | Rome | 2 | Noah | Wing
2 | Owls | Oslo | 3 | Emma | Back
3 | Bears | Bern | null | null | null
4 | Sharks | Lima | null | null | null
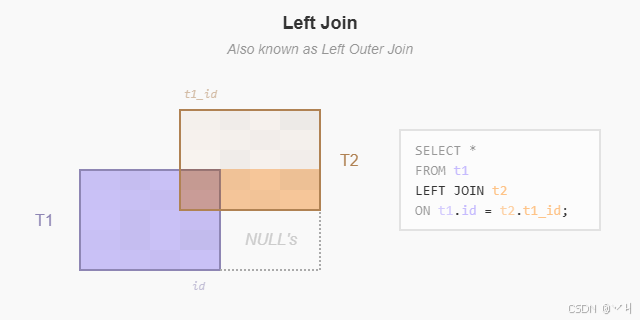
(5 rows)左连接从左表开始选择数据。它将 id 列中的值与 players 表中 team_id 列中的值进行比较。
如果这些值相等,左连接创建一个包含两个表列的新行,并将此新行添加到结果集(请参见结果集中的前三行)。
如果这些值不相等,左连接也会创建一个包含两个表列的新行,并将其添加到结果集。但是,它会用 null 填充右表(players)的列(请参见结果集中的最后两行)。
下图说明了左连接:
要从左表中选择在右表中没有匹配行的行,你可以使用左连接和 WHERE 子句。例如:
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
LEFT JOIN players
ON teams.id = players.team_id
WHERE players.id IS NULL;输出:
team_id | team | city | player_id | player | role
---------+--------+------+-----------+--------+------
3 | Bears | Bern | null | null | null
4 | Sharks | Lima | null | null | null
(2 rows)请注意,LEFT JOIN 与 LEFT OUTER JOIN 相同,因此你可以互换使用它们。
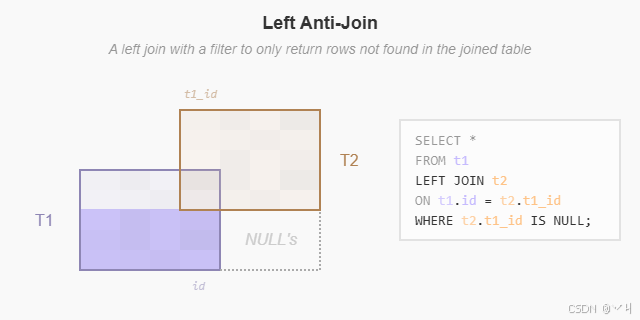
左反连接:下图说明了返回左表中在右表中没有匹配行的左连接:
PostgreSQL 右连接
右连接 是左连接的反向版本。右连接从右表开始选择数据。它将右表中每一行的 team_id 列中的每个值与 teams 表中每一行的 id 列中的每个值进行比较。
如果这些值相等,右连接创建一个包含两个表列的新行。
如果这些值不相等,右连接也会创建一个包含两个表列的新行。但是,它会用 NULL 填充左表的列。
以下语句使用右连接将 teams 表与 players 表连接:
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
RIGHT JOIN players ON teams.id = players.team_id;输出:
team_id | team | city | player_id | player | role
---------+-------+------+-----------+--------+-------
1 | Lions | Rome | 1 | Ava | Guard
1 | Lions | Rome | 2 | Noah | Wing
2 | Owls | Oslo | 3 | Emma | Back
null | null | null | 4 | Liam | Guard
null | null | null | 5 | Mia | Wing
(5 rows)以下文氏图说明了右连接:
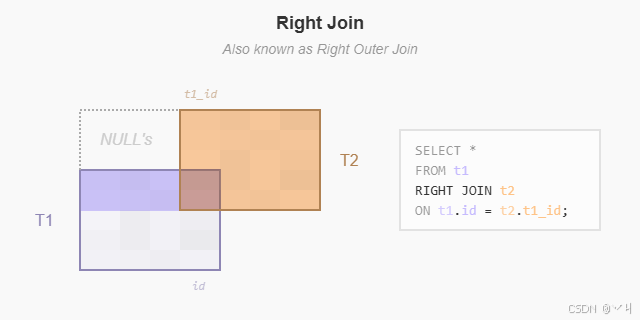
同样,你可以通过添加 WHERE 子句来获取右表中在左表中没有匹配行的行,如下所示:
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
RIGHT JOIN players
ON teams.id = players.team_id
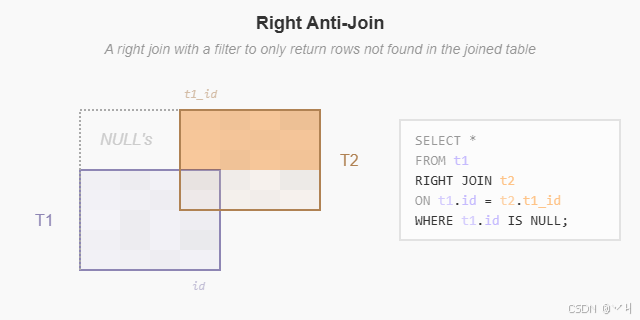
WHERE teams.id IS NULL;输出:
team_id | team | city | player_id | player | role
---------+------+------+-----------+--------+-------
null | null | null | 4 | Liam | Guard
null | null | null | 5 | Mia | Wing
(2 rows)RIGHT JOIN 和 RIGHT OUTER JOIN 相同,因此你可以互换使用它们。
右反连接:下图说明了返回右表中在左表中没有匹配行的右连接:
PostgreSQL 全外连接
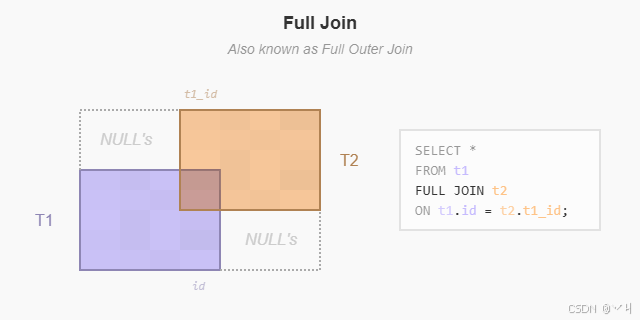
全外连接 或全连接返回包含左表和右表所有行的结果集,如果有匹配的行则包含两边的匹配行。如果没有匹配,表的列将填充为 NULL。
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
FULL OUTER JOIN players
ON teams.id = players.team_id;输出:
team_id | team | city | player_id | player | role
---------+--------+------+-----------+--------+-------
1 | Lions | Rome | 1 | Ava | Guard
1 | Lions | Rome | 2 | Noah | Wing
2 | Owls | Oslo | 3 | Emma | Back
3 | Bears | Bern | null | null | null
4 | Sharks | Lima | null | null | null
null | null | null | 4 | Liam | Guard
null | null | null | 5 | Mia | Wing
(7 rows)下图说明了全外连接:
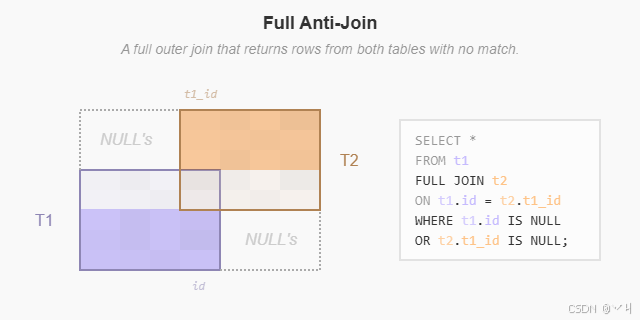
要返回一个表中在另一个表中没有匹配行的行,你可以使用全连接和 WHERE 子句,如下所示:
sql
SELECT
teams.id AS team_id,
team,
city,
players.id AS player_id,
player,
role
FROM
teams
FULL JOIN players
ON teams.id = players.team_id
WHERE teams.id IS NULL OR players.id IS NULL;结果:
team_id | team | city | player_id | player | role
---------+--------+------+-----------+--------+-------
3 | Bears | Bern | null | null | null
4 | Sharks | Lima | null | null | null
null | null | null | 4 | Liam | Guard
null | null | null | 5 | Mia | Wing
(4 rows)以下文氏图说明了返回一个表中在另一个表中没有对应行的全外连接:
下图显示了我们迄今为止讨论的所有 PostgreSQL 连接,包含详细语法:
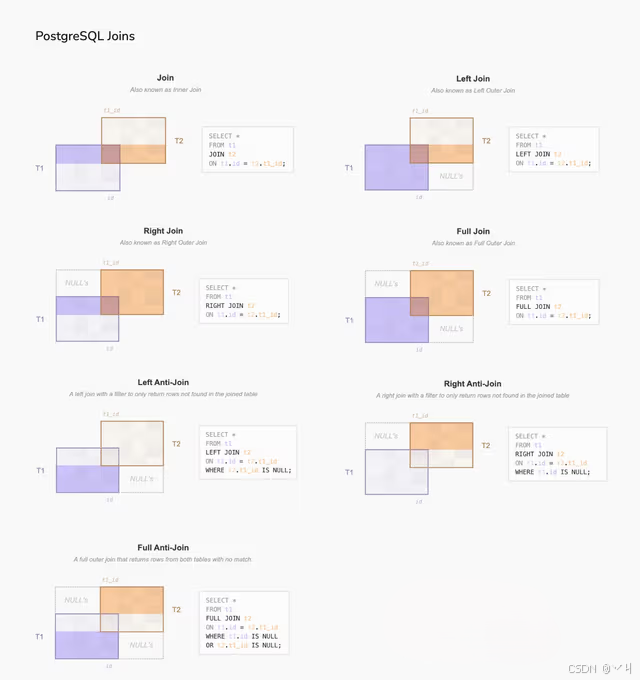
在本教程中,你学习了如何使用各种 PostgreSQL 连接来组合来自多个相关表的数据。