HyperlinkCollector超链采集器单机版v0.1
软件采用python的pyside2和selenium开发,暂时只支持window环境,抓取方式支持普通程序抓取和selenium模拟浏览器抓取。软件遵守robots协议。
首先下载后解压缩,然后运行app目录下的HyperlinkCollector.exe
运行后,我们先创建一个采集项目。
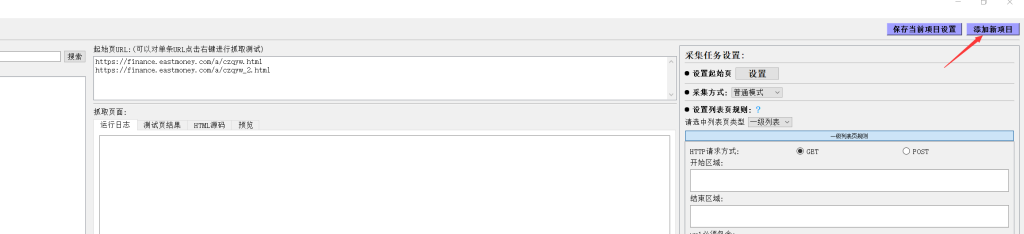
主要是填写项目名称和起始页url,如果采集多个列表页,可以添加完成后在"设置起始页"中进行修改。
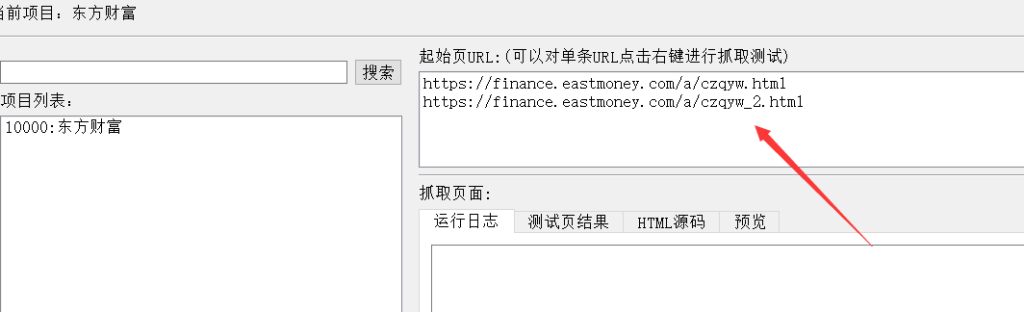
创建好项目后,我们右键选择一个起始页,然后选择"抓取测试",运行后,会在下面显示抓取到的url。
这里我以抓取东方财富网新闻为例:我们要抓取文章的内容,设置一下内容页URL的规则,比如这里我们在"url必须包含"中填写"finance.eastmoney.com/a/"。
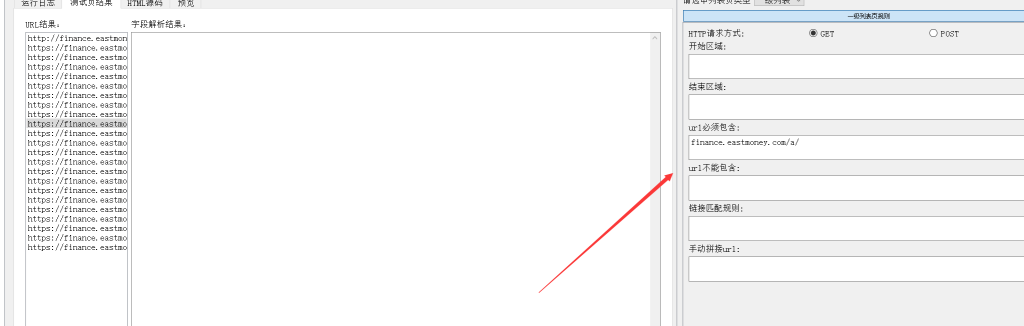
然后再重新右键选择起始页进行抓取测试。这时候获取的url就是根据我们设置的规则获取的内容url。然后继续选择其中一条内容url,右键选择"抓取测试"。这时候,测试结果里会显示抓取的内容字段(系统默认添加了一个title和一个body)。
点击切换到"预览"标签,这里显示的是内容页url的预览 ,可以鼠标划取要抓取的内容部分,比如我们要抓取文章内容,我们可以只划取内容开头的一段文字,这时候会弹出一个快捷菜单,可以获取所选内容的xpath或者css选择器名称。
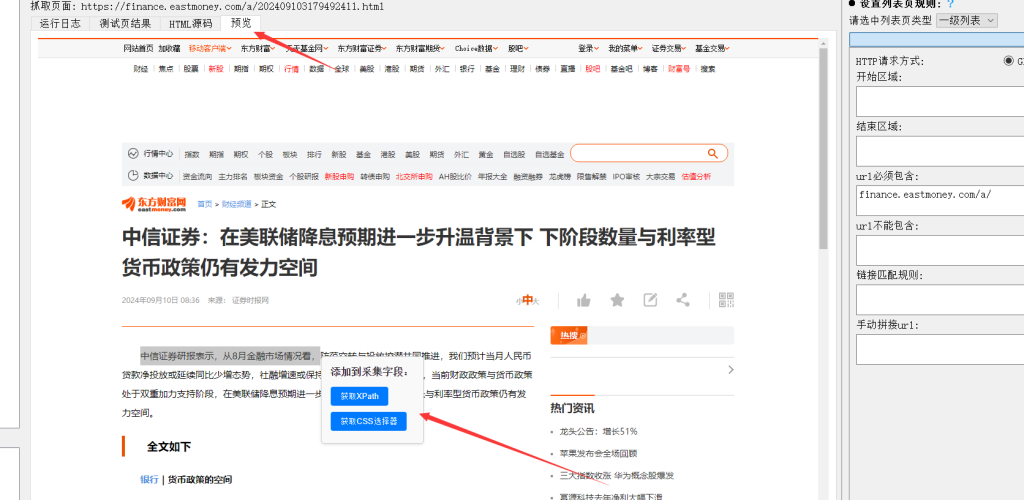
我这里以css选择器为例,点击"获取css选择器"之后,弹出窗口中,显示了包含所选内容的所有"css选择器名称",这里可以对给出的css选择器进行测试,我们选择其中一个对应的。这里需要注意:获取的css选择器是当前选择内容的css选择器,实际中可能需要的是它的父级,这个要根据实际情况进行调节。比如我要抓取整篇文章,但划取后给出的css选择器是"html>body>div.main>div.contentwrap>div.contentbox>div.mainleft>div.zwinfos>div.txtinfos>p" ,只是其中我划取的那一段。这时候可以直接在文本框中修改,使用当前的父级"html>body>div.main>div.contentwrap>div.contentbox>div.mainleft>div.zwinfos>div.txtinfos",然后再点击测试按钮,看看获取的内容是否正确。
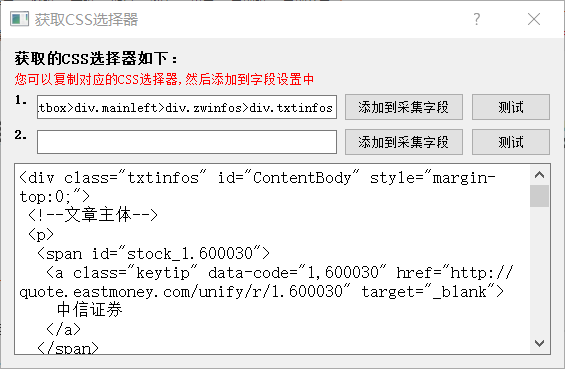
设置完成后,选择"添加到采集字段",将设置的 "css选择器"添加到采集字段
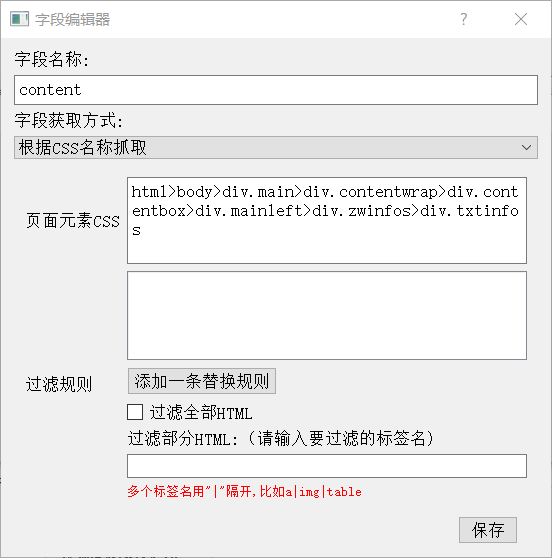
然后写一个字段名称保存。然后可以再进行一次测试看是否正常。
最后选择"保存当前项目设置",设置任何修改后,要记得保存,否则采集时还是按以前的规则采集。
做完上面设置后,我们可以在左边的 项目列表中,右键选择刚刚设置的项目,然后选择"运行所选项目"
然后软件就会进行抓取。
数据保存,可以设置保存为excel或导出到接口,默认情况时保存到excel。但实际应用中更实用的时通过一个接口程序保存,以便根据自己的需求对采集数据进行二次加工处理。保存到接口时,数据是以json格式post提交的。设置中给了一个php接收的示例,您可以根据实际情况进行修改。
CSDN下载地址:
免费爬虫软件"HyperlinkCollector超链采集器v0.1"单机版
软件现在免费使用,有些功能还在不断完善中,如果您在使用软件中有什么问题,或者有开发需求,可以与我联系。