前言
网络爬虫早就是企业获取公开信息、支撑业务增长的核心工具。但传统爬虫的痛点实在太突出------高技术门槛把非技术团队挡在门外,网站一改版爬虫就失效,维护成本居高不下,技术团队大半精力都耗在重复适配这种琐事上,实在不值当。
好在大语言模型(LLM)、计算机视觉这些AI技术成熟后,新一代AI网络爬虫彻底改变了游戏规则。它们靠Prompt驱动、自动自愈这些核心特性,把原本要数天的爬虫开发压缩到几分钟,维护成本几乎降到零,这波技术迭代确实解决了行业的真痛点。
本文深度对比2026年最值得关注的10款AI网络爬虫工具,核心聚焦AI技术带来的实际价值。
一、AI网络爬虫的核心价值与对比维度
1、 核心解决的传统爬虫痛点
- 传统爬虫需要编写复杂的CSS选择器/XPath,非技术人员无法参与;
- 网站DOM结构微小变动即导致爬虫失效,需要持续投入开发资源维护;
- 扩展到新网站需要重复编码、测试,响应业务需求速度缓慢;
- 面对复杂反爬机制,需要手动配置代理、请求头,技术门槛高;
- 数据提取后需要额外进行结构化处理,效率低下。
2、 AI特色专属对比维度
比起传统爬虫,AI爬虫的核心竞争力其实就集中在5个专属维度上------这也是我觉得选型时最该重点关注的部分:
- AI技术类型(LLM/NLP/计算机视觉/自适应学习/知识图谱)
- Prompt驱动能力(自然语言生成可运行爬虫)
- 自愈能力(网站变动自动检测、一键适配)
- 智能数据提取(无需手动配置选择器、自动识别字段)
- 零代码到专家模式的无缝切换(满足不同层级用户需求)
二 、10款AI网络爬虫工具完整对比表格(2026年最新版)
|---------------------------------------------------------------------------------------------------|------------------------|-------------------------|------------------------|--------------|---------------------|-------------------------|------------------------|
| 工具名称 | AI技术类型 | 部署难度/学习曲线 | Prompt生成 | 零代码 | 代码可控度 | 反爬/代理能力 | 成本模型 |
| Bright Data AI Scraper Studio | LLM+视觉AI+自适应学习 | 零代码→进阶→专家无缝切换,全层级适配 | ⭐⭐⭐⭐⭐ | ✅ | 完整IDE代码控制,支持自定义扩展 | ⭐⭐⭐⭐⭐(1.5亿+全球IP,自动反爬绕过) | 付费(按需/包月/企业定制,含免费试用) |
| Bright Data Web Scraper API | LLM增强模板+自适应学习 | 低代码,开发者3分钟上手 | ⭐⭐⭐⭐(模板化Prompt,无需手动编写) | ✅(模板直接调用) | API参数高度自定义 | ⭐⭐⭐⭐⭐(共享全球代理网络) | 付费(按请求计费,无最低消费) |
| Browse AI | 计算机视觉识别+少量NLP | 零代码,非技术人员5分钟上手 | ❌ | ✅ | 仅支持简单规则调整 | ⭐⭐⭐(基础反爬,支持简单代理) | 免费版(有限请求)+付费版(按项目计费) |
| Diffbot | 知识图谱AI+机器学习+NLP | 低代码,需熟悉API参数配置 | ❌ | ✅(可视化配置) | 无代码控制,仅API参数扩展 | ⭐⭐⭐⭐(企业级反爬,支持全球代理) | 付费(按API调用次数,企业定制) |
| Hexomatic | 工作流AI+ChatGPT/Gemini集成 | 零代码,拖拽式配置,10分钟上手 | ⭐⭐(简单指令) | ✅ | 无代码自定义能力 | ⭐⭐(基础反爬,无内置高级代理) | 免费试用+付费(按工作流节点计费) |
| Bardeen AI | 工作流AI+轻量级LLM | 零代码,浏览器插件即装即用 | ⭐⭐(基础指令) | ✅ | 无代码控制 | ⭐⭐(基础反爬) | 免费版(有限工作流)+付费版(无限工作流) |
| Apify Actor | AI集成框架+结构化解析AI | 零代码/低代码/代码级全覆盖,生态学习成本中等 | ❌(需配置/自定义Actor) | ✅(现成Actor调用) | 支持JS/Python自定义Actor | ⭐⭐⭐(可额外购买代理) | 免费试用(有限计算单元)+付费(按计算单元) |
| Axiom.ai | 浏览器自动化AI+ChatGPT集成 | 零代码,可视化流程配置,复杂流程学习成本较高 | ❌ | ✅ | 无代码自定义能力 | ⭐⭐(基础反爬) | 7天免费试用+付费(按套餐计费) |
| ScrapeStorm | 传统机器学习+中文语义理解 | 零代码,中文界面,国内用户3分钟上手 | ❌ | ✅ | 有限脚本自定义 | ⭐⭐⭐(适配国内反爬,支持第三方代理) | 免费版(有限功能)+付费版(无采集限制) |
| ParseHub | 传统机器学习+视觉识别 | 零代码,配置流程略繁琐,需15分钟熟悉 | ❌ | ✅ | 仅支持简单规则调整 | ⭐⭐(基础反爬,支持简单代理) | 免费版(有限项目)+付费版(无限制+云采集) |
三 、10大AI网络爬虫工具详细对比
下面我介绍下10大AI网络爬虫工具,从核心维度、优势亮点到适用场景,不同工具具有不同的适配边界,而不是重复看同类头部产品的优势。
1.Bright Data AI Scraper Studio
AI Scraper Studio通过自然语言prompt生成爬虫脚本,既实现了零代码、极速上线,又保留了扩展性和代码级定制能力,更适合需快速扩展多域、追求极致效率与弹性的现代数据团队。
我们可以直接创建自己的爬虫代码,也可以用AI帮我们生成自定义爬虫代码(需要填写目标网站、爬虫提示词),AI Scraper Studio提供了模版供我们选择,比如:Amazon Products、Youtube Videos、Faceboos profile posts、LinkedIn people profile PDP等等
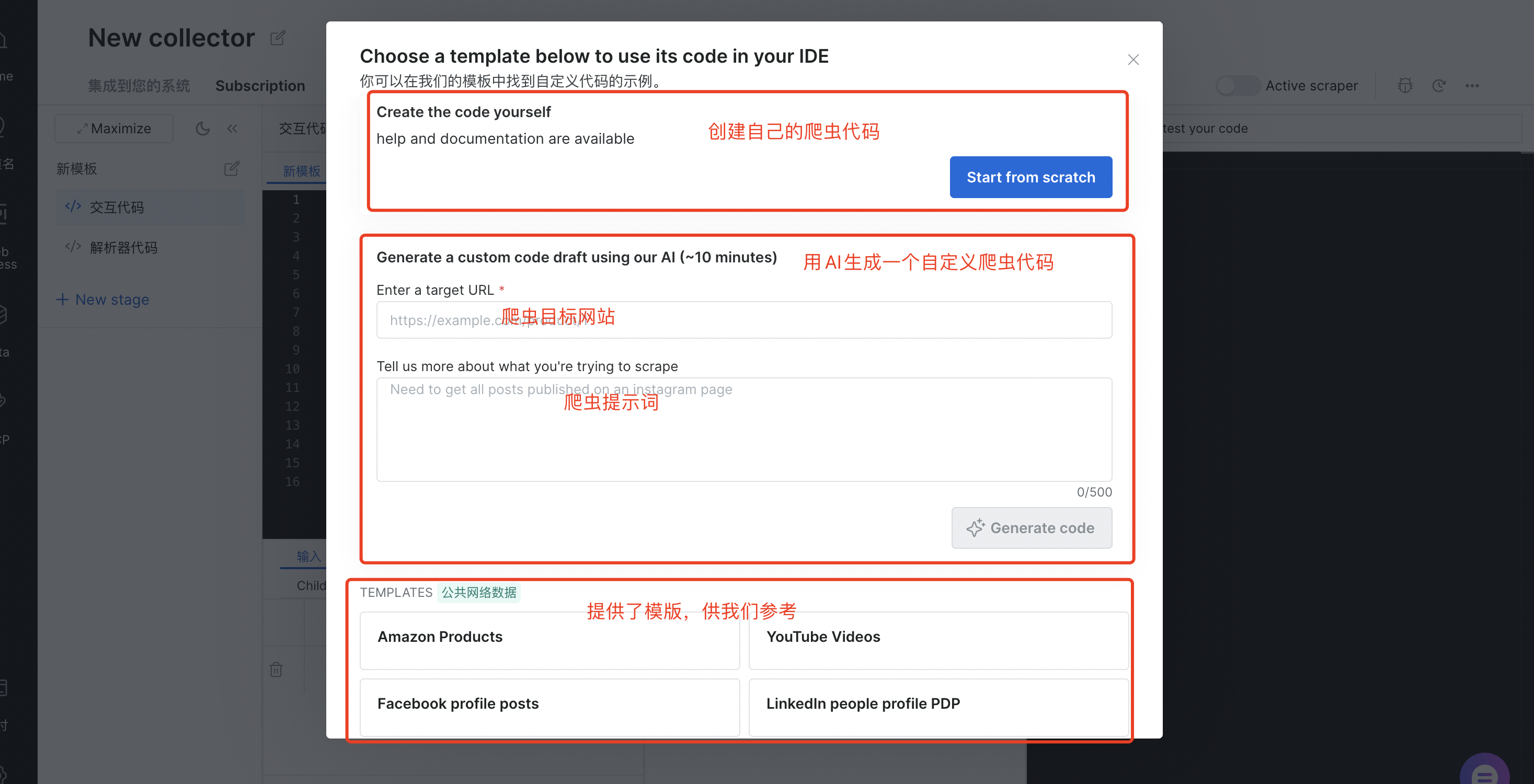
这里我输入下面的信息,然后点击"Generate code"

随后等待代码生成
最终可以看到生成的爬虫脚本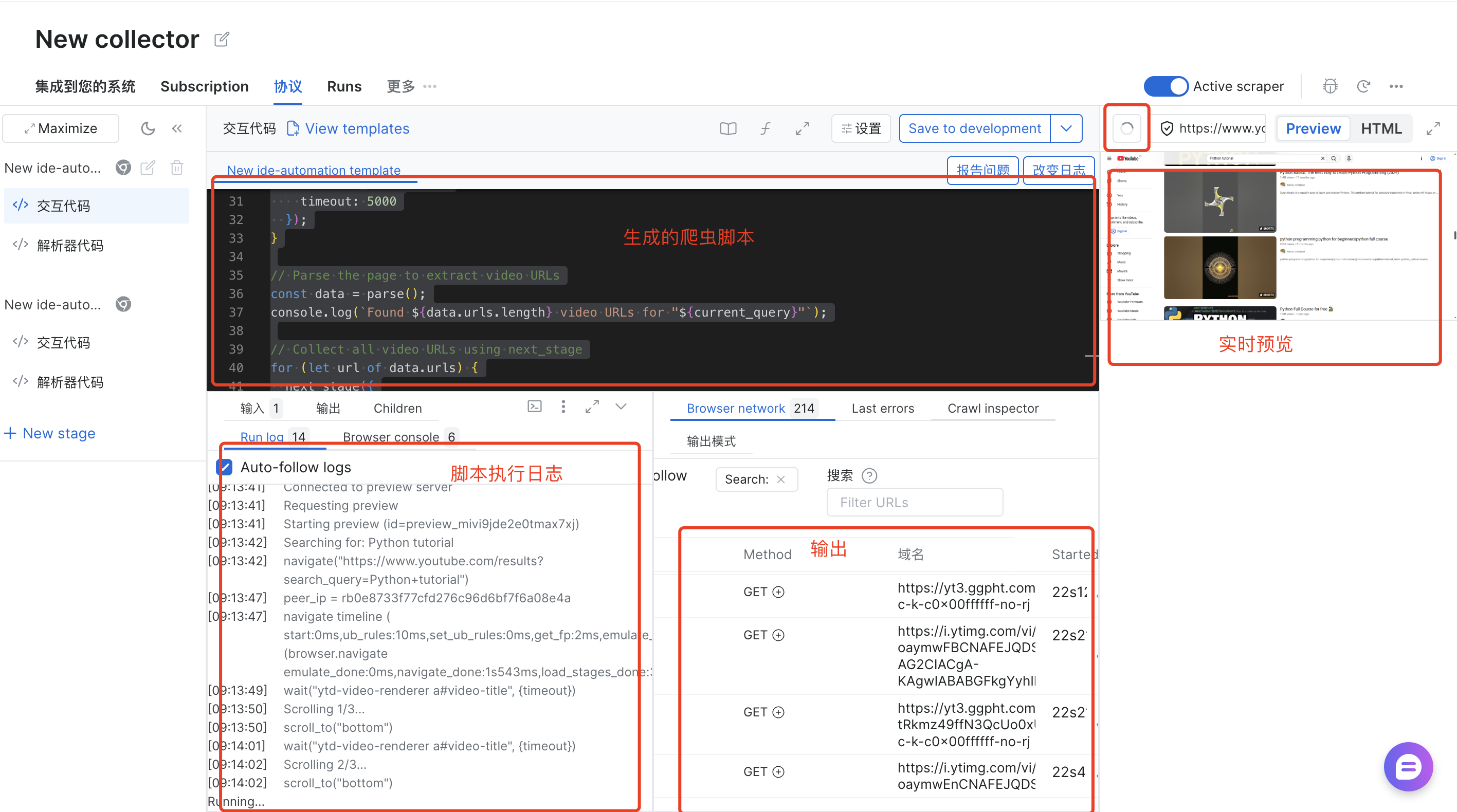
2. Bright Data Web Scraper API
Bright Data Web Scraper API更偏向开发者友好的API服务,通过API接口,可以轻松抓取互联网上的大量数据,无需人工手动提取,节省时间和人工成本,在数据抓取后可以直接进行初步清洗和格式化处理,输出结构化的数据(如CSV、JSON等),方便后续使用。它提供了120+API供我们选择,可以说是非常丰富了
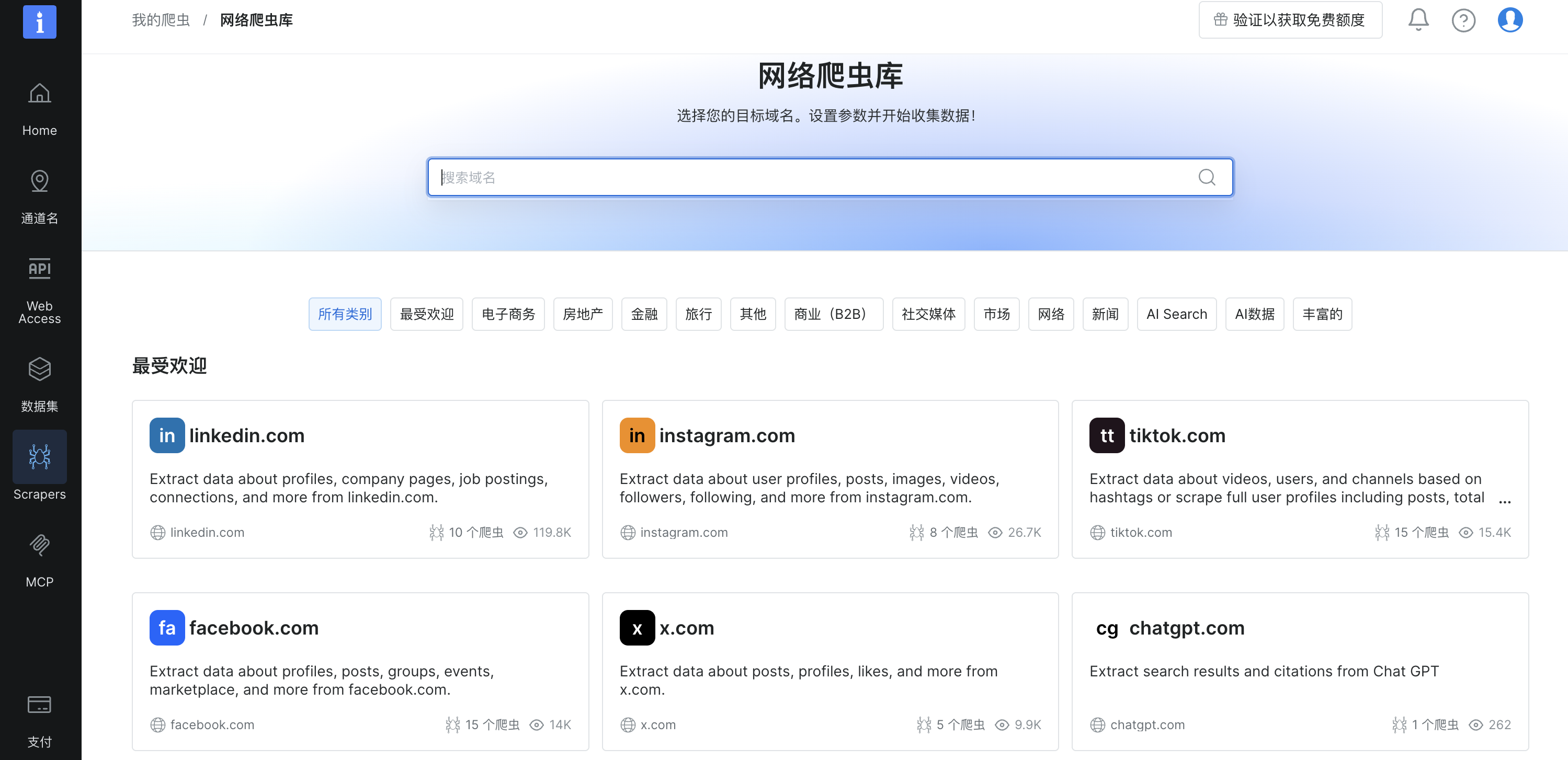
选择AI Search,可以看到有多种AI供我们选择
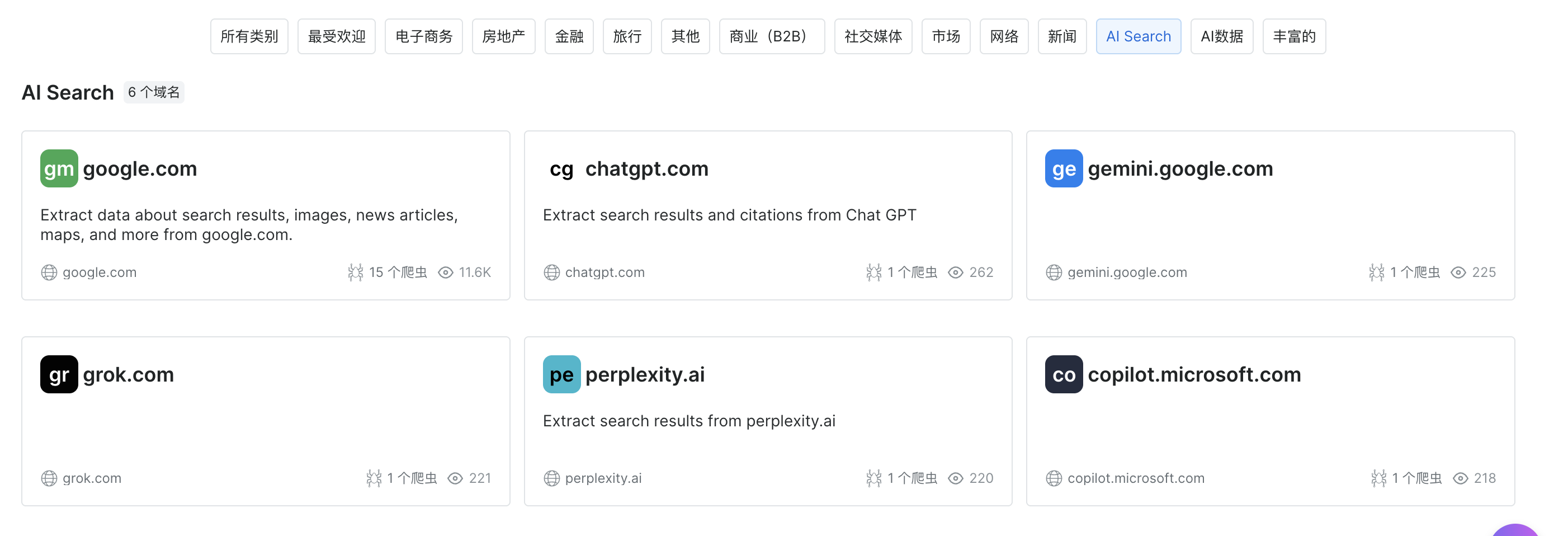
这里选择chatgpt.com,点击手动允许就可以爬取
3. Browse AI(视觉识别驱动)
Browse AI专为非技术人员打造的零代码网页数据采集平台,通过计算机视觉技术实现鼠标框选提取数据,无需了解 DOM 结构,对小白极为友好。它支持定时抓取和 CSV/Excel 导出,日常使用便捷,轻微页面改版能自动识别字段位置,减少手动调整,免费版加付费版的灵活定价也满足不同需求。
javascript
import requests
# 配置信息(需先在Browse AI网页端创建爬虫任务,获取任务ID和API密钥)
API_KEY = "你的Browse AI API密钥"
TASK_ID = "已创建的爬虫任务ID"
ENDPOINT = f"https://api.browse.ai/v2/tasks/{TASK_ID}/run"
# 请求参数
payload = {
"input": {"url": "https://example-ecommerce.com/product/12345"}, # 目标产品页URL
"output_format": "json"
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 触发爬虫任务并获取结果
response = requests.post(ENDPOINT, json=payload, headers=headers)
result = response.json()
# 输出结构化数据
print("产品数据:", result.get("data"))不过它缺乏 Prompt 驱动和代码自定义能力,复杂动态页面处理能力有限,也没有全球代理网络,反爬能力一般,整体适合电商详情页、新闻列表等固定布局页面的数据采集,是运营团队和个人用户的轻量级数据采集利器。
4. Diffbot(知识图谱AI)
Diffbot专注于实体关系提取的企业级知识图谱构建平台,通过知识图谱 AI、机器学习和 NLP 技术,能够高效识别实体及其关联关系,直接构建结构化知识图谱。它支持万级 URL 批量采集,数据结构化程度极高,核心实体字段识别稳定,轻微页面变动不影响。
javascript
import requests
# 配置信息
API_KEY = "你的Diffbot API密钥"
ENDPOINT = "https://api.diffbot.com/v3/product" # 产品实体提取端点
# 请求参数
params = {
"token": API_KEY,
"url": "https://example-ecommerce.com/product/phone-pro-max",
"fields": "name,price,brand,specs,relatedProducts" # 提取实体及关联关系
}
# 发送请求并获取结构化知识数据
response = requests.get(ENDPOINT, params=params)
result = response.json()
# 输出产品实体及关联关系
print("产品实体信息:", result.get("objects")[0])
print("关联产品关系:", result.get("objects")[0].get("relatedProducts"))它缺乏 Prompt 驱动能力,零代码用户上手有难度,不能做代码级自定义,爬虫逻辑调整不灵活,太聚焦实体提取导致非结构化文本抓取困难,价格较高对中小团队压力大。主要适合 AI/ML 工程师构建知识图谱、企业竞品分析和行业研究机构梳理产业数据等场景。
5. Hexomatic(工作流AI+多模型集成)
Hexomatic是零代码爬虫与自动化工作流一体化平台,集成工作流 AI 和原生 ChatGPT/Google Gemini,专注 "采集 - 处理 - 应用" 全链路。它支持 1-click 一键抓取主流网站数据和自定义采集规则,内置 100 + 现成自动化工具,可将采集数据与 AI 任务联动,支持构建端到端工作流无需人工干预。
javascript
import requests
# 配置信息(需先在Hexomatic网页端创建工作流,获取工作流ID和API密钥)
API_KEY = "你的Hexomatic API密钥"
WORKFLOW_ID = "已创建的采集-处理工作流ID"
ENDPOINT = f"https://api.hexomatic.com/v1/workflows/{WORKFLOW_ID}/execute"
# 请求参数(触发工作流,采集Google Maps本地企业信息)
payload = {
"inputs": [
{"name": "search_query", "value": "北京 手机店"},
{"name": "location", "value": "北京"}
],
"output_format": "json"
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 触发工作流并获取结果
response = requests.post(ENDPOINT, json=payload, headers=headers)
result = response.json()
# 输出采集的企业线索数据
print("B2B线索数据:", result.get("results"))其 Prompt 驱动能力较弱,仅支持简单自然语言指令,爬虫自愈能力有限,复杂动态页面采集准确率一般,不支持代码级自定义。主要适合销售团队 B2B 线索挖掘、营销团队竞品分析、非技术人员批量数据处理与自动化任务等场景。
6. Bardeen AI(浏览器插件式Workflow AI)
Bardeen AI是浏览器插件式爬虫工具,集成工作流 AI 和轻量级 LLM,专注简单工作流自动化与数据同步。它支持浏览器插件直接安装无需部署环境,通过拖拽式操作构建采集工作流上手门槛极低,可将采集数据实时同步至 Google Sheets、Notion、Airtable 等办公工具,具备基础自然语言指令能力可通过简单 Prompt 生成基础采集规则。
javascript
// 需在浏览器扩展环境中运行(Bardeen AI插件内置API)
async function scrapeAndSyncData() {
try {
// 1. 采集当前页面的产品标题和价格
const productData = await bardeen.actions.scrape({
fields: [
{ name: "title", selector: "h1.product-title" },
{ name: "price", selector: "span.product-price" }
]
});
// 2. 将数据同步至Google Sheets
await bardeen.actions.syncToGoogleSheets({
spreadsheetId: "你的Google Sheets ID",
sheetName: "产品数据",
data: productData
});
console.log("采集并同步成功:", productData);
} catch (error) {
console.error("操作失败:", error);
}
}
// 执行采集同步任务
scrapeAndSyncData();其 Prompt 驱动能力较弱仅支持简单指令,无自愈能力网站变动后需重新配置,不支持大规模并发采集单任务速度较慢,无内置高级代理复杂反爬网站难以突破。主要适合个人用户轻量数据采集、小型运营团队简单数据同步任务等。
7. Apify Actor(AI集成+生态化爬虫平台)
Apify Actor是生态化爬虫平台,集成 AI 集成框架和结构化数据解析 AI,通过 "Actor" 模块实现灵活的采集与 AI 联动。它拥有 4000 + 现成的 Actor 模块覆盖全场景,深度集成主流 AI 框架可将采集数据直接喂给 LLM 等适配 AI 模型训练需求,支持无代码配置与代码自定义兼顾不同用户,可与 Make 等自动化平台联动实现大规模工作流自动化。
javascript
from apify_client import ApifyClient
# 配置信息
APIFY_TOKEN = "你的Apify API令牌"
client = ApifyClient(APIFY_TOKEN)
# 调用现成的电商采集Actor
run_input = {
"startUrls": [{"url": "https://example-ecommerce.com/category/phones"}],
"maxItems": 100,
"outputFields": ["title", "price", "rating", "imageUrl"],
"excludeAds": True
}
# 启动Actor并等待完成
run = client.actor("apify/ecommerce-scraper").call(run_input=run_input)
# 获取并输出结果
result = [item for item in client.dataset(run["defaultDatasetId"]).iterate_items()]
print("采集的电商数据:", result)其无原生 Prompt 生成爬虫能力需手动配置,零代码用户上手需熟悉 Actor 生态学习成本较高,基础版无全球代理复杂反爬场景成本高,免费版计算单元有限。主要适合 AI/ML 工程师获取训练数据、技术团队灵活采集需求、需要与现有 AI 工作流集成的企业等场景。
8. Axiom.ai(无代码浏览器自动化+GPT集成,三星半推荐)
Axiom.ai是无代码浏览器自动化工具,集成浏览器自动化 AI 和 ChatGPT 数据解析,专注复杂浏览器操作与 AI 数据解析结合。它支持模拟人类浏览器操作可抓取需要复杂交互的页面,集成 ChatGPT 可利用 AI 解析非结构化数据,数据可自动导出至 Google Sheets 并支持定时执行任务,无需代码通过可视化流程配置实现复杂采集需求。
javascript
import requests
# 配置信息(需先在Axiom.ai网页端创建自动化流程,获取流程ID和API密钥)
API_KEY = "你的Axiom.ai API密钥"
FLOW_ID = "已创建的浏览器自动化流程ID"
ENDPOINT = f"https://api.axiom.ai/v1/flows/{FLOW_ID}/run"
# 请求参数(触发流程:登录电商平台并采集订单数据)
payload = {
"inputs": [
{"name": "username", "value": "你的电商账号"},
{"name": "password", "value": "你的电商密码"},
{"name": "order_date_start", "value": "2026-01-01"}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 触发流程并获取结果
response = requests.post(ENDPOINT, json=payload, headers=headers)
result = response.json()
# 输出采集的订单数据
print("订单数据:", result.get("output"))不过它无 Prompt 生成爬虫能力所有流程需手动配置,无自愈能力页面元素变动后需重新调整,不支持全球代理面对反爬严格的网站表现一般,单个任务执行速度较慢不适合大规模并发采集。主要适合需要复杂浏览器交互的采集任务、非技术人员的复杂数据解析需求、企业的重复性浏览器操作自动化等场景。代码案例(Python调用Axiom.ai自动化流程API)
9. ScrapeStorm(智能识别)
ScrapeStorm是国内自研零代码爬虫工具,集成传统机器学习、智能字段识别和中文语义理解,专注中文网站采集与本土化需求。它提供中文界面友好适配国内用户习惯,零代码操作通过智能识别自动提取字段支持可视化调试,支持云采集和定时抓取实现无人值守,数据导出格式丰富且具备有限代码自定义能力。
javascript
import requests
# 配置信息(需先在ScrapeStorm客户端创建采集规则,获取任务ID和API密钥)
API_KEY = "你的ScrapeStorm API密钥"
TASK_ID = "已创建的中文电商采集任务ID"
ENDPOINT = "https://api.scrapestorm.cn/v1/task/run"
# 请求参数
payload = {
"apiKey": API_KEY,
"taskId": TASK_ID,
"startUrl": "https://example-chinese-ecommerce.com/category/手机",
"outputFormat": "json"
}
# 触发云采集任务并获取结果
response = requests.post(ENDPOINT, json=payload)
result = response.json()
# 输出采集的中文电商数据
print("中文电商产品数据:", result.get("data"))它无 Prompt 驱动能力依赖手动配置,自愈能力较弱网站大幅改版后需重新训练,面对国外复杂网站和反爬机制表现不佳,AI 数据解析能力有限复杂结构化数据提取准确率一般。主要适合国内非技术人员抓取国内网站数据、中小型企业本土化采集需求、无复杂反爬需求的中文内容采集等场景。
10. ParseHub(机器学习+视觉识别)
ParseHub是零代码爬虫工具,集成传统机器学习和基础视觉识别,面向非技术人员的基础数据采集。它提供可视化界面操作通过点击选择提取字段,支持循环点击和自动翻页等复杂操作,可处理动态 JavaScript 渲染页面抓取单页应用数据,数据可导出 CSV、JSON、Excel 等多种格式,支持定时抓取与云存储无需本地运行。
javascript
import requests
# 配置信息(需先在ParseHub网页端创建爬虫项目,获取项目ID和API密钥)
API_KEY = "你的ParseHub API密钥"
PROJECT_TOKEN = "已创建的新闻采集项目ID"
ENDPOINT = f"https://www.parsehub.com/api/v2/projects/{PROJECT_TOKEN}/run"
# 请求参数
payload = {
"api_key": API_KEY,
"start_url": "https://example-news-site.com/latest",
"output_format": "json"
}
# 启动爬虫并获取运行状态
response = requests.post(ENDPOINT, data=payload)
run_token = response.json().get("run_token")
# 等待爬虫完成并获取结果
result_endpoint = f"https://www.parsehub.com/api/v2/runs/{run_token}/data"
result_response = requests.get(result_endpoint, params={"api_key": API_KEY})
result = result_response.json()
# 输出采集的新闻数据
print("新闻列表数据:", result.get("news"))它无 Prompt 驱动能力配置流程较为繁琐,自愈能力有限网站结构变动后需重新配置,不支持代码级自定义灵活度不足,大规模采集性能较弱并发能力有限,无内置高级代理复杂反爬场景难以应对。主要适合个人用户和小型团队的简单数据采集、非技术背景业务人员基础市场调研、布局相对固定的网页采集等场景。
四 、推荐试用与落地建议
我觉得在选择代理工具的时候要匹配自己的需求,不要盲目测试所有工具,可以先明确自身的核心诉求,这里给大家的一下使用选择建议:
- 企业级首选(大型团队、复杂需求、高准确率):Bright Data AI Scraper Studio,兼顾零代码易用性与专家模式灵活性,自愈能力与反爬能力行业领先,适合需要大规模、高稳定数据采集的企业;
- 开发者首选(快速获取标准化数据) :Bright Data Web Scraper API,模板化调用,无需编写复杂代码,效率高,适合开发者快速响应业务需求;
- 非技术人员轻量需求(个人/小型团队、简单页面):Browse AI、Bardeen AI,零代码上手,操作简单,满足基础数据采集需求;
- 知识图谱/AI训练数据采集:Diffbot,擅长实体关系提取与知识图谱构建,适合AI/ML工程师与行业研究团队;
- 国内网站采集:ScrapeStorm,中文界面友好,适配国内网站,满足中小型企业的本土化数据采集需求。
AI爬虫虽然能够大幅提升效率,但是我们必须要遵守相关法律法规,采集公开可获取的信息,避免侵犯隐私和知识产权。合理利用AI技术,才能让数据真正成为业务增长的助力。
结语
AI技术正在彻底颠覆传统网络爬虫的工作模式,从编码驱动转向Prompt驱动,从被动修复转向主动自愈,从技术人员专属转向全民可用。选择一款合适的AI网络爬虫工具,不仅能够大幅提升数据采集效率,降低维护成本,更能让企业快速响应市场变化,在数据驱动的竞争中占据先机。Bright Data作为AI网络爬虫领域的领军者,其AI Scraper Studio与Web Scraper API具备行业领先的效率与稳定性**。**
2026年,AI网络爬虫将成为企业的标配工具,而Bright Data凭借其领先的技术实力与企业级服务,可以说是智能数据采集的最佳选择。