一、设计要求
- 利用Python编写网络爬虫,在联网条件下实现自动爬取。
- 该爬虫是模拟用户在网上书城浏览图书榜单,爬取榜单上的书名、书的封面、书的畅销排名、作者、推荐度、评价人次、书的价格等七项数据类型。
- 模拟用户行为,发送http请求至目标网站,解析响应网页内容,根据需求,提取数据。
- 将爬取的众多数据转存为csv格式。
二、设计方案
具体思路:
1、首先明确爬取内容是什么,该爬虫爬取的是当当网上的畅销榜单,榜单包含:排名、书籍及书籍内容、作者、推荐度、评论次数、书的价格。
2、分析网页的结构:对当当网的页面结构进行分析,寻找包含目标数据的html元素,而我们是通过edge自带的页面检查工具DevTools进行分析。
3、然后,模拟请求发送数据。在确定了数据所在的元素后,我们需要构建一个能够模拟用户行为的请求发送器,这里就会用到requests库。
4、解析数据。发送请求后,我们会获得服务器响应的HTML内容。这时,我们需要解析这些内容,提取出我们关心的数据。这可以通过BeautifulSoup库或者PyQuery库来实现。
5、保存数据。我们需要将爬取到的数据以csv格式保存下来,而我们首先要在爬虫中导入csv库文件,以实现该相关功能。
爬取过程:
1、根据需要,导入库文件。
2、确定URL地址:通过浏览器查找正确的URL地址,并根据页面的不同部分构造相应的URL参数。
3、确定爬取节点:使用开发者工具分析DOM结构,确定数据所在的节点。
4、保存爬取信息:将爬取到的数据保存到文件中。
问题解决:
- import库文件后,显示错误,未找到?
这是本地Python库中未包含该文件,需要手动下载至本地。方法有两种:一种可以选择每个py程序下自带的Terminal,在控制终端中敲击命令"pip install + 导入库名"。另一种在File>Settings>PythonProject>Python Interpreter中手动输入导入库名,等待片刻,即可安装完成。
- 如何从网页中提取出要求的内容?
针对这种情况,就要使用re库中的正则表达式,利用正则表达式模板(parttern)来匹配特定的html内容,然后使用re.findall()函数在html字符串中匹配所有满足pattern条件的内容,然后将数据存储在一个列表items中,并最终返回该表。
三、设计代码
import requests
import re
import csv
def request_dandan(url):
try: # 发送GET请求获取网页内容
response = requests.get(url)
if response.status_code == 200: # 如果响应状态码为200,表示请求成功
return response.text # 返回响应的文本内容
except requests.RequestException as e: #异常处理
print(e) #输出异常信息
return None # 返回None表示请求失败
def parse_result(html): #目的是从html字符串中提取出满足特定格式的数据,并将这些数据以元组列表的形式返回
pattern = re.compile('<li>.*?list_num.*?(\d+)\.</div>.*?<img src="(.*?)".*?class="name".*?title="(.*?)">.*?class="star">.*?class="tuijian">(.*?)</span>.*?class="publisher_info">.*?target="_blank">(.*?)</a>.*?class="biaosheng">.*?<span>(.*?)</span></div>.*?<p><span class="price_n">(.*?)</span>.*?</li>', re.S)
items = re.findall(pattern, html)
for item in items: #通过迭代items列表中的每个元素item,将提取出的书籍信息存储在一个字典中
yield { #使用yield关键字逐个生成这些字典作为生成器的输出
'range': item0,
'image': item1,
'title': item2,
'recommend': item3,
'author': item4,
'times': item5,
'price': item6
}
with open(r'C:\Users\22059\Desktop\爬虫数据.csv', 'a', encoding='UTF-8', newline='') as f:
f.write("热销榜单,书籍封面,书名,推荐度,作者,评价次数,价格\n")
def write_item_to_file(item):
print('爬取图书信息中..... ' + str(item))
with open(r'C:\Users\22059\Desktop\爬虫数据.csv', 'a', encoding='UTF-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(item.values())
def main(page):
url = 'http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-' + str(page)
html = request_dandan(url) #调用request_dandan函数发送HTTP请求
items = parse_result(html) #调用parse_result函数解析爬取到的HTML内容
for item in items:
write_item_to_file(item) #对每个书籍信息执行写入文件的操作,将爬取到的书籍信息写入csv文件
if name == "main":
for i in range(1, 50): #爬取页数范围
main(i)
- 实现效果
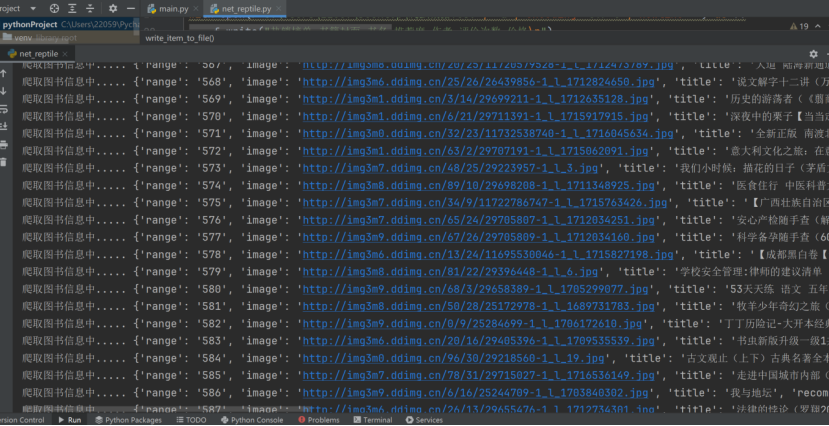
上图为终端中实时爬取数据情况,每一行为一套信息,包含七项数据
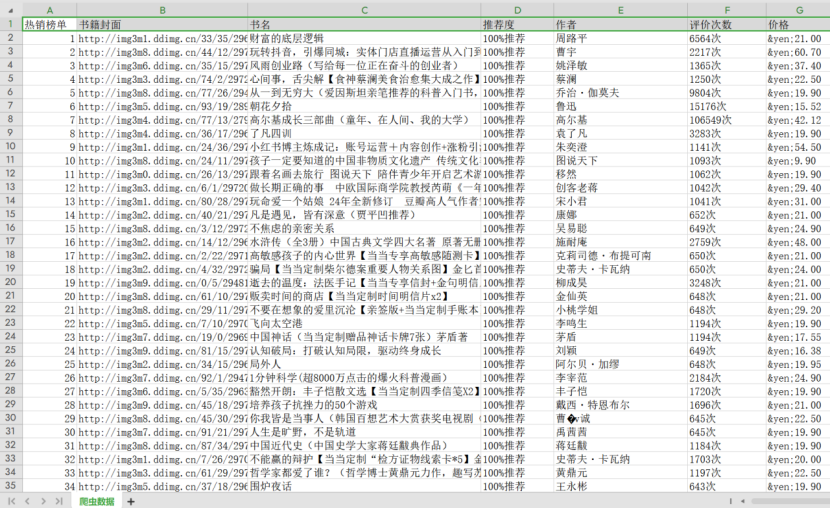

上图为爬取信息转存为csv格式,每条数据包含七项,共计598条数据。原因在于被爬取的网页内容有限,598条数据已是极限。
五、设计总结
本次设计遇到的第一个问题就是库文件的添加,当我选择使用上述所说第二种添加方式时,出现语法错误,库文件无法下载至本地库中,尝试使用命令提示符手动添加也未能成功,最后是更换添加库文件方法,使用Python的Terminal,输入"pip install + 库文件"才顺利解决问题。
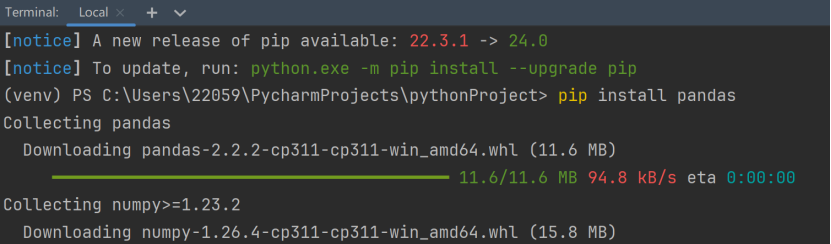
另一个问题就是文件出现错误,在将数据写入文件后,遇到了路径上的问题,保存的csv文件不知道跑哪里去了,将之前的错误路径修改为绝对路径后,csv文件成功的存在了我想要存在的地方,比如桌面上。

通过本次综合设计,我对爬虫技术有了更能深入的学习,在实际操作中所遇到的问题和解决办法有助于提升我的编程能力和应变能力,特别是在应对复杂网页结构和反爬虫策略方面时。同时,学习爬虫技术对信息安全内容学习有很大帮助,可用于一些攻击方式,例如拒绝服务攻击,威胁情报等。