概述
从MySQL 5.7.8版本开始,MySQL引入了对JSON字段的支持,这为处理半结构化数据提供了极大的灵活性。然而,MySQL原生并不支持直接对JSON对象中的字段进行索引。本文将介绍如何利用MySQL 5.7中的虚拟字段功能,对JSON字段中的数据进行高效索引,以提高查询性能。

假设我们有一个记录用户游戏数据的JSON对象,我们希望能够快速检索游戏玩家的相关信息。
json
{
"user_id": 101,
"username": "Alice",
"games": {
"Chess": {
"rating": 1500,
"wins": 30,
"losses": 5
},
"Poker": {
"games_played": 100,
"win_percentage": 60
},
"Tetris": {
"high_score": 85000
}
}
}表的基本结构
首先,创建一个包含JSON字段的表:
sql
CREATE TABLE `user_games` (
`user_id` INT UNSIGNED NOT NULL,
`user_data` JSON NOT NULL,
PRIMARY KEY (`user_id`)
);在上面的表结构中,我们无法直接对JSON字段中的键进行索引。接下来,我们将演示如何使用虚拟字段对JSON字段进行索引。
增加虚拟字段
虚拟列语法如下
javascript
<type> [ GENERATED ALWAYS ] AS ( <expression> ) [ VIRTUAL|STORED ]
[ UNIQUE [KEY] ] [ [PRIMARY] KEY ] [ NOT NULL ] [ COMMENT <text> ]在MySQL 5.7中,支持两种类型的生成列(Generated Column):虚拟生成列(Virtual Generated Column)和存储生成列(Stored Generated Column)。Virtual Column是默认选项,它只在数据字典中保存字段定义,而不将字段数据持久化到磁盘上。对于大多数应用场景,Virtual Column已足够使用,因为它节省了磁盘空间并且查询性能也很高。
虚拟生成列(Virtual Generated Column)
- 定义:虚拟生成列是一个只在数据字典中定义的列,它不会实际存储数据,而是在每次查询时动态计算。
- 优点 :
- 节省磁盘空间:由于数据不被存储在磁盘上,仅在查询时计算,因此不会增加表的大小。
- 适用于不常用的计算字段:对于计算频率较低的字段,使用虚拟生成列可以减少对存储空间的需求。
- 缺点 :
- 查询性能:每次查询时都需要动态计算字段值,这可能会影响查询性能,尤其是在数据量大的情况下。
javascript
CREATE TABLE example (
id INT PRIMARY KEY,
data JSON,
extracted_value VARCHAR(100) GENERATED ALWAYS AS (data->>'$.field') VIRTUAL
);存储生成列(Stored Generated Column)
- 定义:存储生成列不仅在数据字典中定义,还会将计算结果持久化到磁盘上。这意味着数据会被实际存储,并在插入或更新数据时计算。
- 优点 :
- 查询性能:由于数据已被计算并存储,因此查询时不需要再次计算,提高了查询效率。
- 适用于经常查询的字段:对于需要频繁查询的计算字段,使用存储生成列可以显著提高查询性能。
- 缺点 :
- 增加磁盘空间使用:由于数据被存储在磁盘上,表的大小会增加。
- 写入开销:每次插入或更新数据时,需要重新计算和存储字段值,可能会增加写入开销。
javascript
CREATE TABLE example (
id INT PRIMARY KEY,
data JSON,
extracted_value VARCHAR(100) GENERATED ALWAYS AS (data->>'$.field') STORED
);- 虚拟生成列适合那些计算开销较小且不需要频繁查询的字段,因为它不会占用额外的磁盘空间。
- 存储生成列适合需要高查询性能的场景,尤其是对查询性能要求较高的字段,因为计算结果被持久化到磁盘上。
以下是添加虚拟字段的建表语句:
sql
CREATE TABLE `user_games` (
`user_id` INT UNSIGNED NOT NULL,
`user_data` JSON NOT NULL,
`username_virtual` VARCHAR(50) GENERATED ALWAYS AS (`user_data` ->> '$.username') VIRTUAL NOT NULL,
`chess_rating` INT GENERATED ALWAYS AS (`user_data` ->> '$.games.Chess.rating') VIRTUAL,
PRIMARY KEY (`user_id`)
);在这个例子中,我们定义了两个虚拟字段:username_virtual和chess_rating。username_virtual字段用于存储玩家的用户名,而chess_rating字段用于存储玩家在Chess游戏中的评分。
插入数据
sql
INSERT INTO `user_games` (`user_id`, `user_data`) VALUES
(101, '{ "user_id": 101, "username": "Alice", "games": { "Chess": { "rating": 1500, "wins": 30, "losses": 5 }, "Poker": { "games_played": 100, "win_percentage": 60 }, "Tetris": { "high_score": 85000 } } }'),
(102, '{ "user_id": 102, "username": "Bob", "games": { "Chess": { "rating": 1600, "wins": 25, "losses": 10 }, "Poker": { "games_played": 80, "win_percentage": 55 }, "Tetris": { "high_score": 92000 } } }'),
(103, '{ "user_id": 103, "username": "Charlie", "games": { "Chess": { "rating": 1400, "wins": 20, "losses": 15 }, "Poker": { "games_played": 120, "win_percentage": 65 }, "Tetris": { "high_score": 80000 } } }');
查看数据
sql
SELECT * FROM `user_games`;查看表的字段
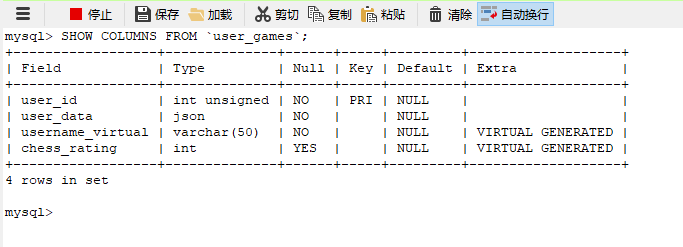
sql
SHOW COLUMNS FROM `user_games`;可以看到,虚拟字段username_virtual和chess_rating已成功创建,它们都在数据字典中进行存储,并未实际存储数据。
在虚拟字段上添加索引
为了提高查询性能,我们可以在虚拟字段上添加索引。首先查看当前查询的执行计划:
sql
EXPLAIN SELECT * FROM `user_games` WHERE `username_virtual` = 'Alice';

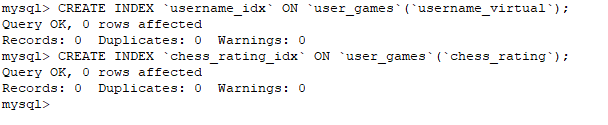
添加索引
sql
CREATE INDEX `username_idx` ON `user_games`(`username_virtual`);
CREATE INDEX `chess_rating_idx` ON `user_games`(`chess_rating`);
重新执行查询,将得到优化后的执行计划:
sql
EXPLAIN SELECT * FROM `user_games` WHERE `username_virtual` = 'Alice';
sql
EXPLAIN SELECT * FROM `user_games` WHERE `chess_rating` = 1500;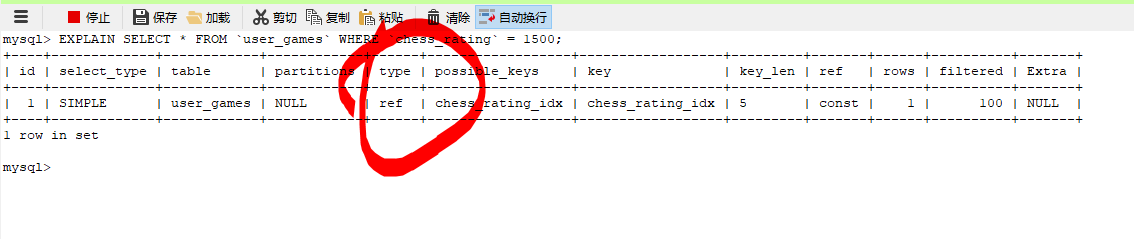
总结
在本文中,我们探讨了如何在MySQL 5.7中利用生成列来高效索引JSON字段。通过虚拟生成列和存储生成列两种方式,我们可以根据实际需求选择最适合的解决方案,平衡磁盘空间使用和查询性能。虚拟生成列在不增加存储空间的前提下,通过动态计算提升了数据存储的灵活性,而存储生成列则通过持久化计算结果显著提升了查询效率。
通过虚拟字段和索引的结合,可以显著提高对JSON字段内容的检索速度,并优化查询性能。虚拟字段不仅提供了对JSON数据的索引支持,还避免了对磁盘空间的额外消耗,是处理半结构化数据的有效工具。开发者可以更好地管理和优化JSON数据结构的查询与索引,充分发挥MySQL 5.7在现代应用中的强大能力。