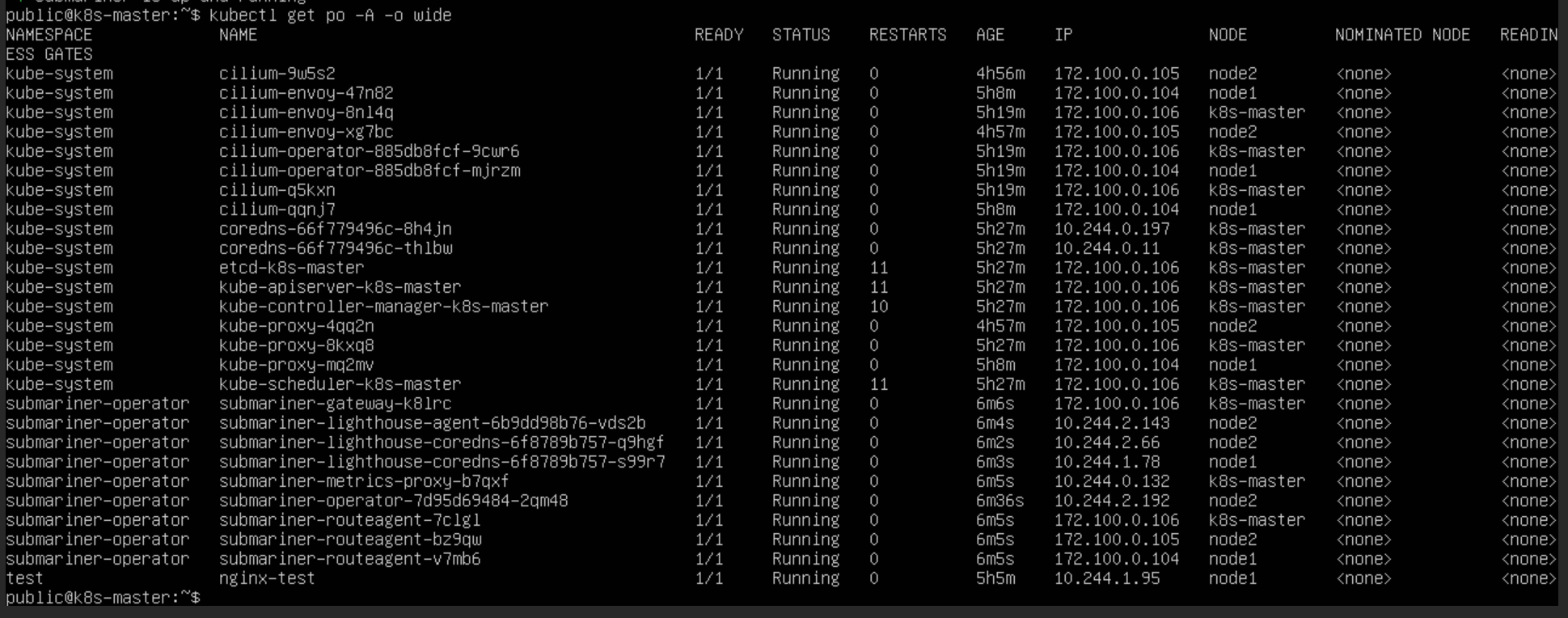
Submariner 部署全过程
部署集群配置
broker 集群:
pod-cidr:11.244.0.0/16
service-cidr 11.96.0.0/12
broker 172.100.0.109
node 172.100.0.108
集群 1( pve3 ):
pod-cidr:10.244.0.0/16
service-cidr 10.96.0.0/12
k8s-master 172.100.0.106
node1 172.100.0.104
node2 172.100.0.105
集群 2 ( pve2 ):
pod-cidr:10.244.0.0/16
service-cidr 10.96.0.0/12
k8s-master 172.110.0.102
k8s-node1 172.110.0.105
subctl 安装
下载 subctl 二进制文件,并部署到相应路径:
shell
# github 地址
https://github.com/submariner-io/get.submariner.io
# 运行命令
curl -Ls https://get.submariner.io | bash
export PATH=$PATH:~/.local/bin
echo export PATH=\$PATH:~/.local/bin >> ~/.profile
source ~/.profile 如果运行 curl 命令的时候报错请求403的问题,可以先把网页的命令代码存到 .sh 文件中,再用 bash 命令执行
shell
curl -L https://get.submariner.io -o install_submariner.sh
bash install_submariner.sh
subctl uninstal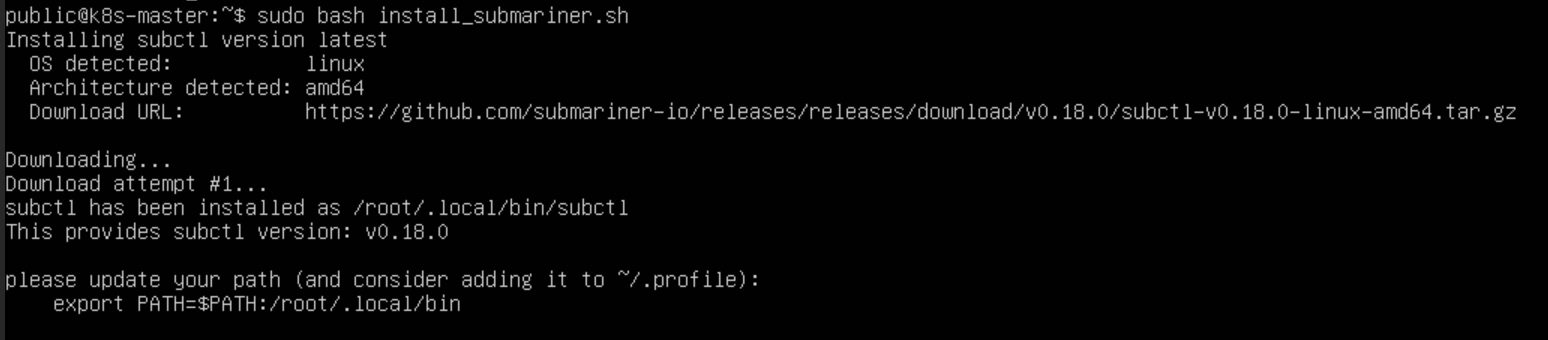
部署 Broker
Broker 集群可以是专用集群,也可以是连接的集群之一。执行 subctl deploy-broker 命令部署 Broker,Broker 只包含了一组 CRD,并没有部署 Pod 或者 Service。
shell
subctl deploy-broker
# 删除submariner
subctl uninstall --kubeconfig /root/.kube/config3 broker-info.subm --yes
subctl uninstall --kubeconfig /root/.kube/configheader broker-info.subm --yes
subctl uninstall deploy-broker /root/.kube/config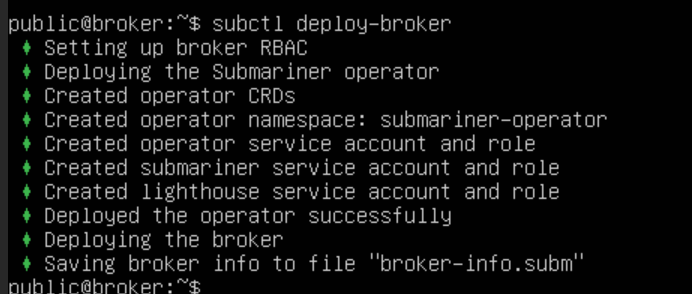
部署完成后,会生成 broker-info.subm 文件,文件以 Base64 加密,其中包含了连接 Broker 集群 API Server 的地址以及证书信息,还有 IPsec 的密钥信息
加入集群
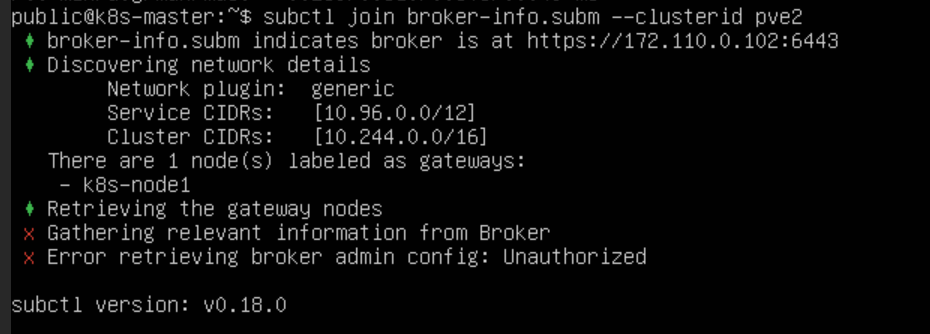
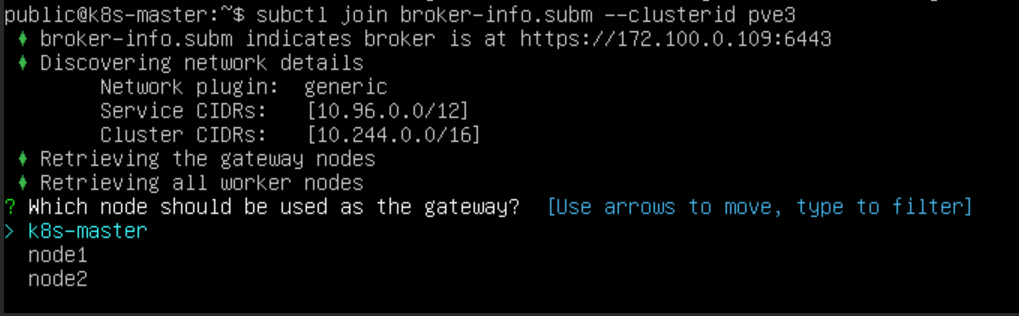
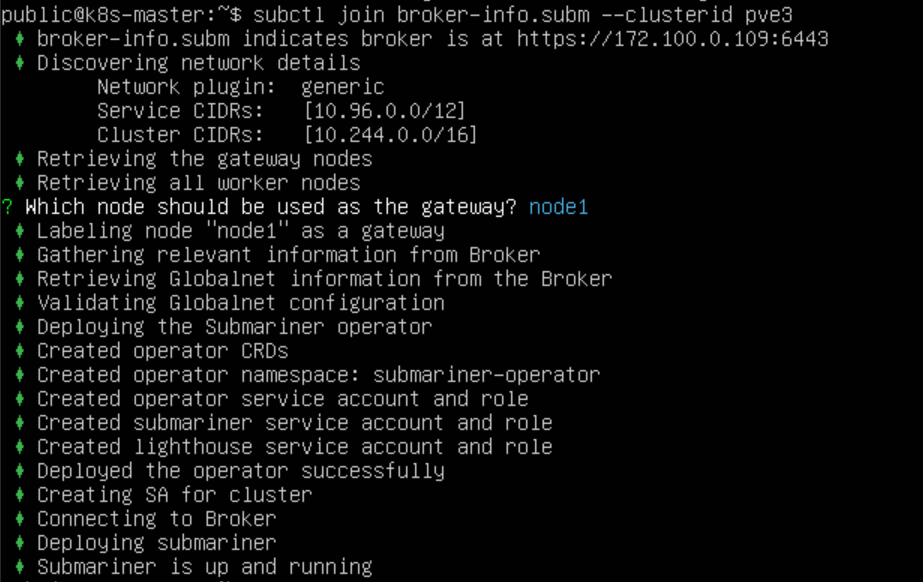
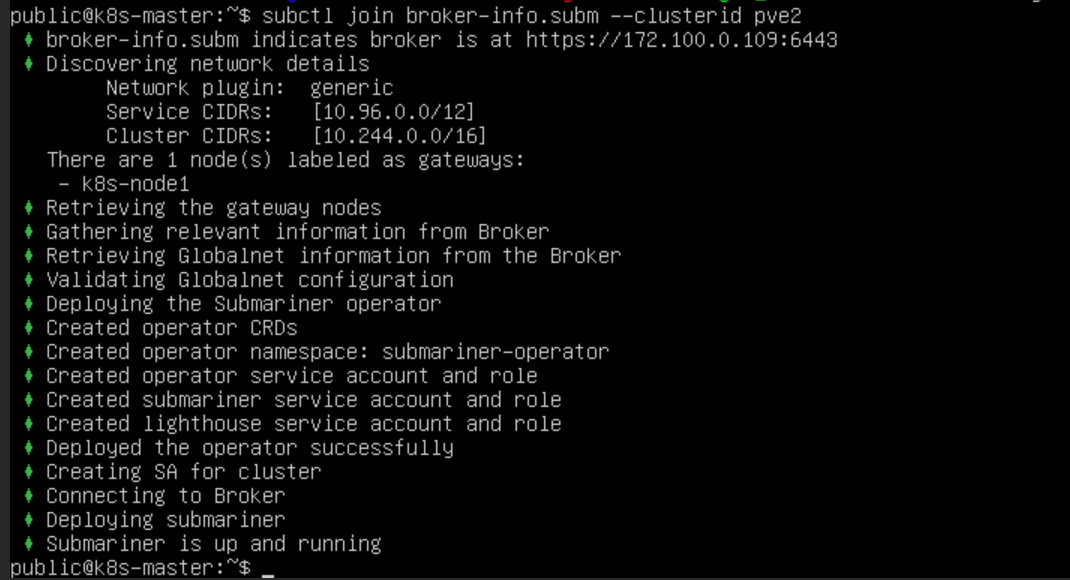
执行 subctl join 命令将 集群1 和 集群2 两个集群加入 Broker 集群。使用 --clusterid 参数指定集群 ID,每个集群 ID 需要唯一。提供上一步生成的 broker-info.subm 文件用于集群注册
shell
subctl join broker-info.subm --clusterid pve2
subctl join broker-info.subm --clusterid pve3 但是这里虚拟机上的文件无法下载上传,没有 broker 集群的证书文件集群没有加入权限

使用 scp 命令进行主机与主机之间的文件传输
shell
scp file 远程用户名@远程服务器IP:~/
# 冒号和目录之间无空格

会提示我们选择一个节点作为 Gateway Node,集群1 选择 node1 节点作为 Gateway,集群2 选择 k8s-node1 节点作为 Gateway。之后会分别使用这两个节点的地址在两个集群间建立隧道连接
命令查看集群间连接情况,发现链接并未建立
shell
subctl show connections 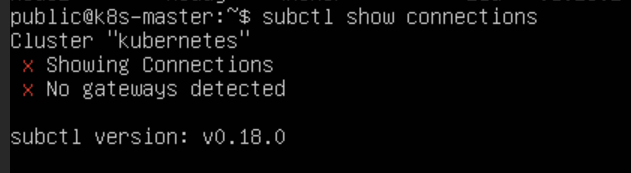
查看 submariner 的节点运行状态,发现网关 Pod 运行异常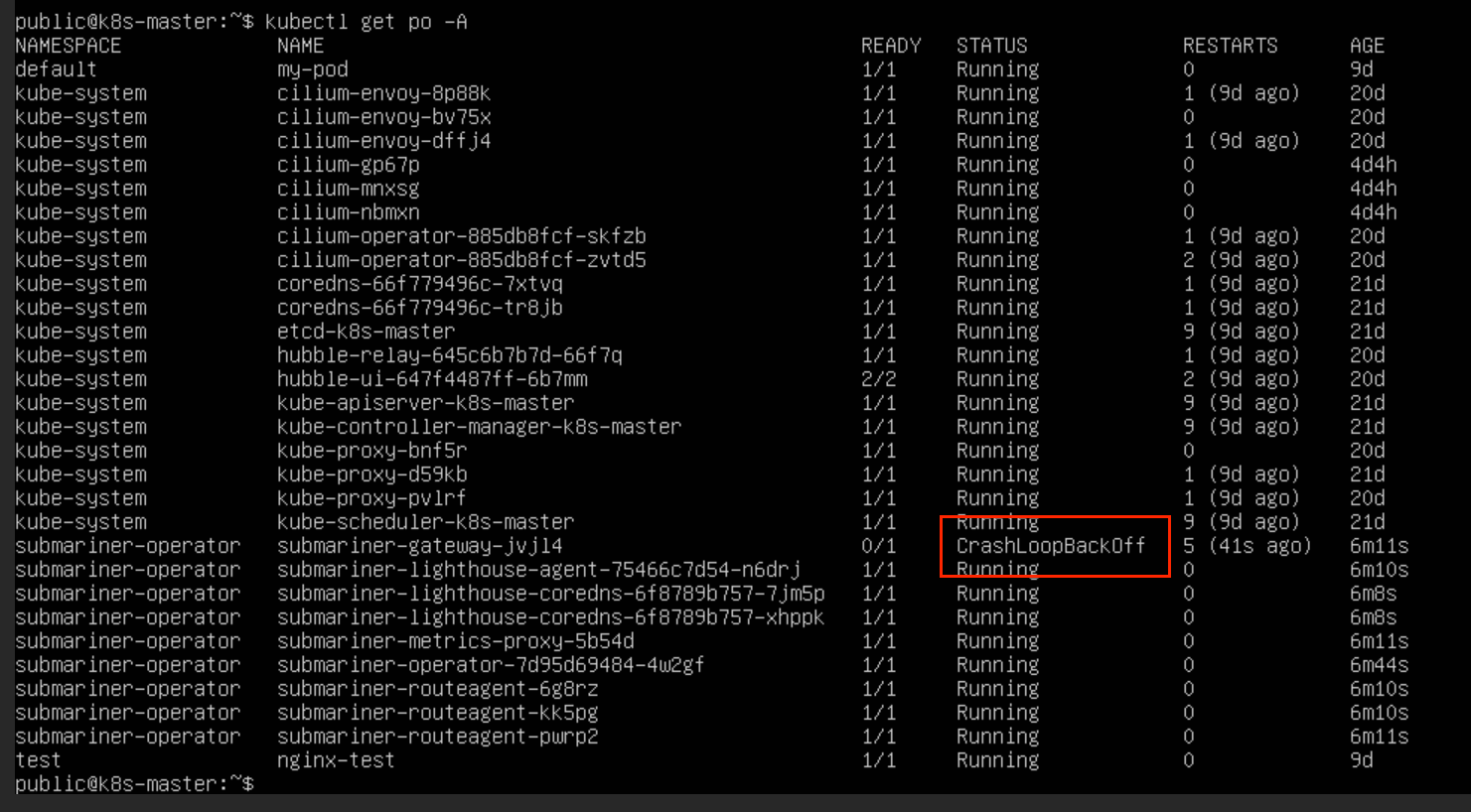
集群网段 CIDR 异常
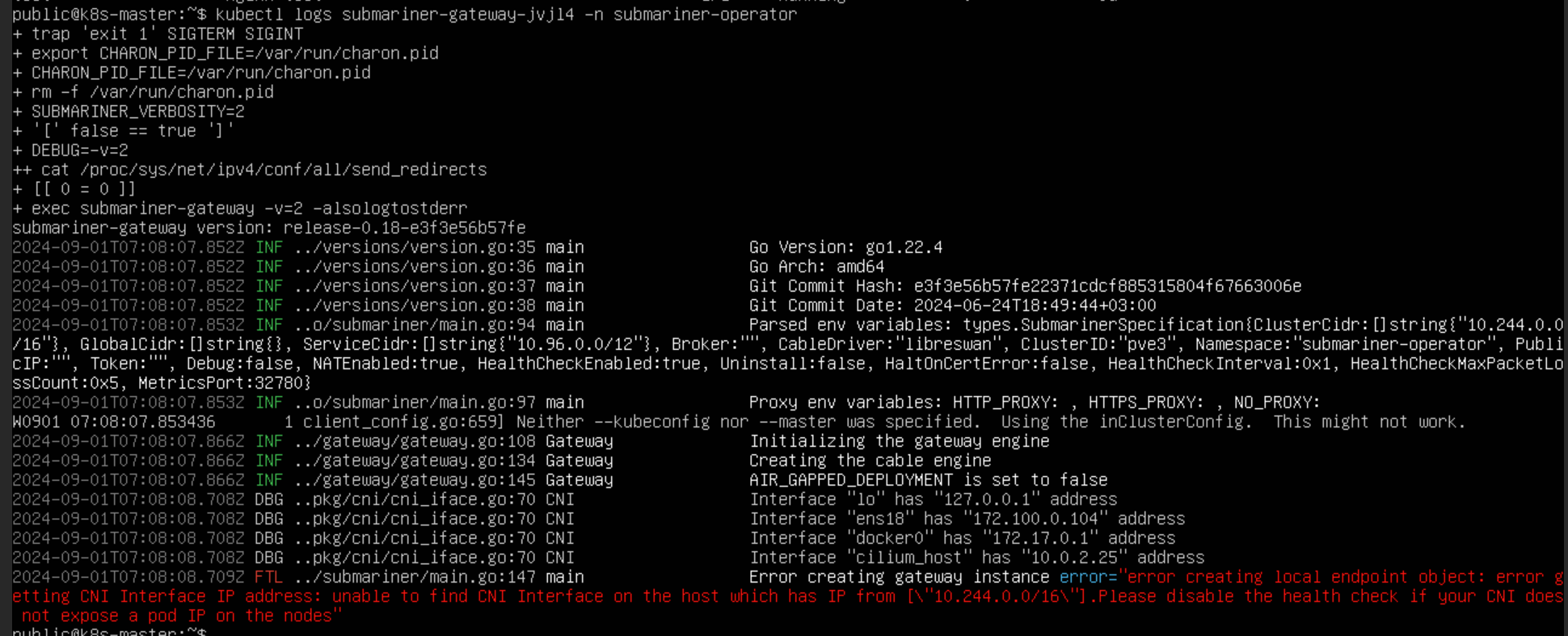
查看 Pod 信息和日志发现,网关节点创建失败,无法在IP地址为"10.244.0.0/16"的主机上找到CNI接口。初步判断是集群为 Pod 分配网段出现问题
shell
kubectl describe pod <Pod名称> <命名空间>
kubectl logs <Pod名称> <命名空间>
更改k8s网段 CIDR
涉及到pod网段的位置包括
cilium
controller-manager
kube-proxy
shell
# 查看 cilium 配置文件
kubectl edit configmap cilium-config -n kube-system
# 重启 cilium
kubectl rollout restart daemonset cilium -n kube-system
# 删除 pod 重启
kubectl get daemonset -n kube-system
kubectl delete pods -l k8s-app=cilium -n kube-system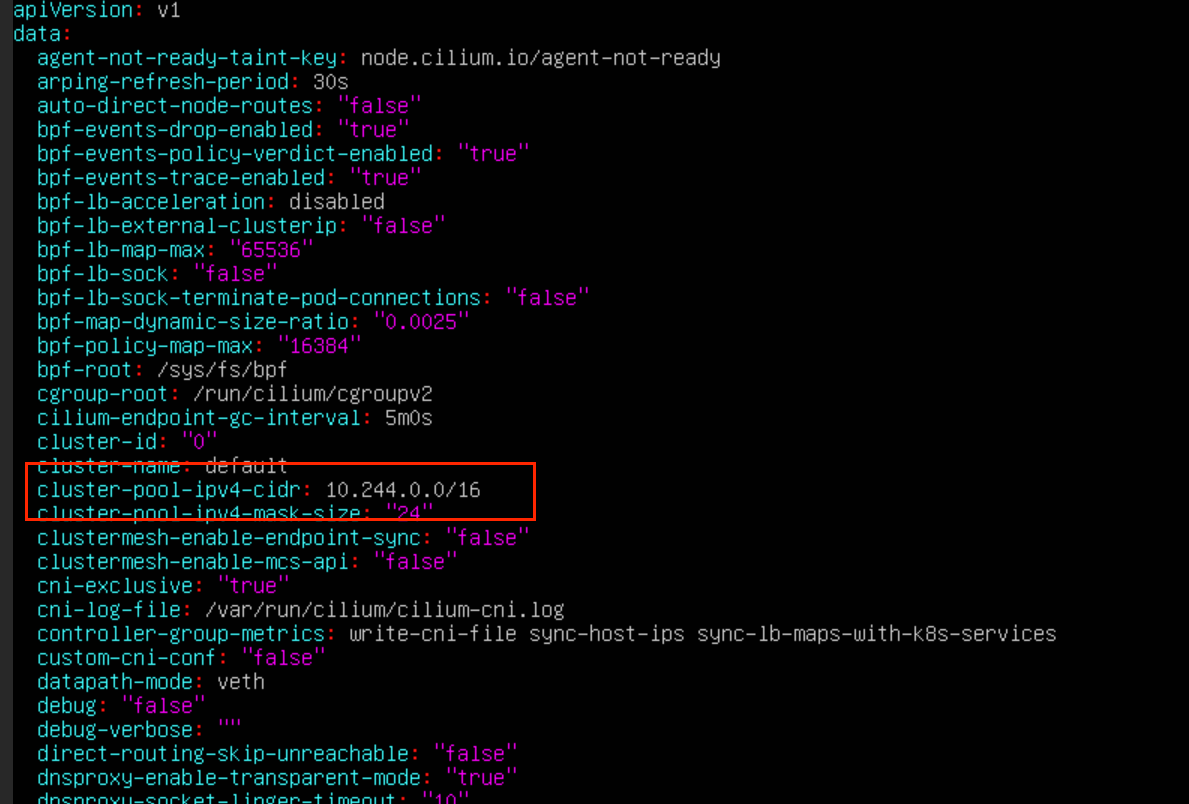

shell
# 修改controller-manager的配置
vim /etc/kubernetes/manifests/kube-controller-manager.yaml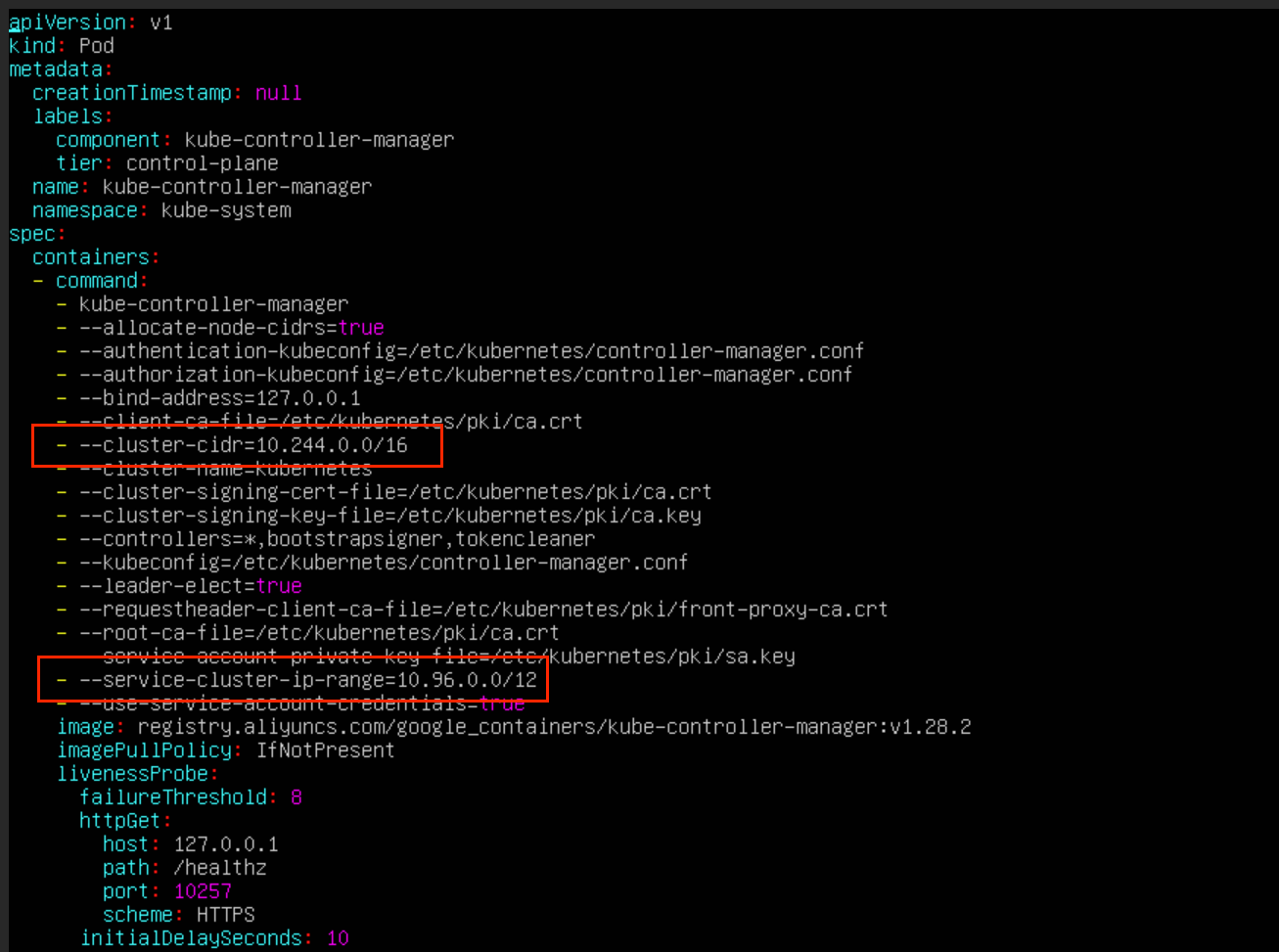
shell
# 修改kube-proxy的配置
kubectl edit cm kube-proxy -n kube-system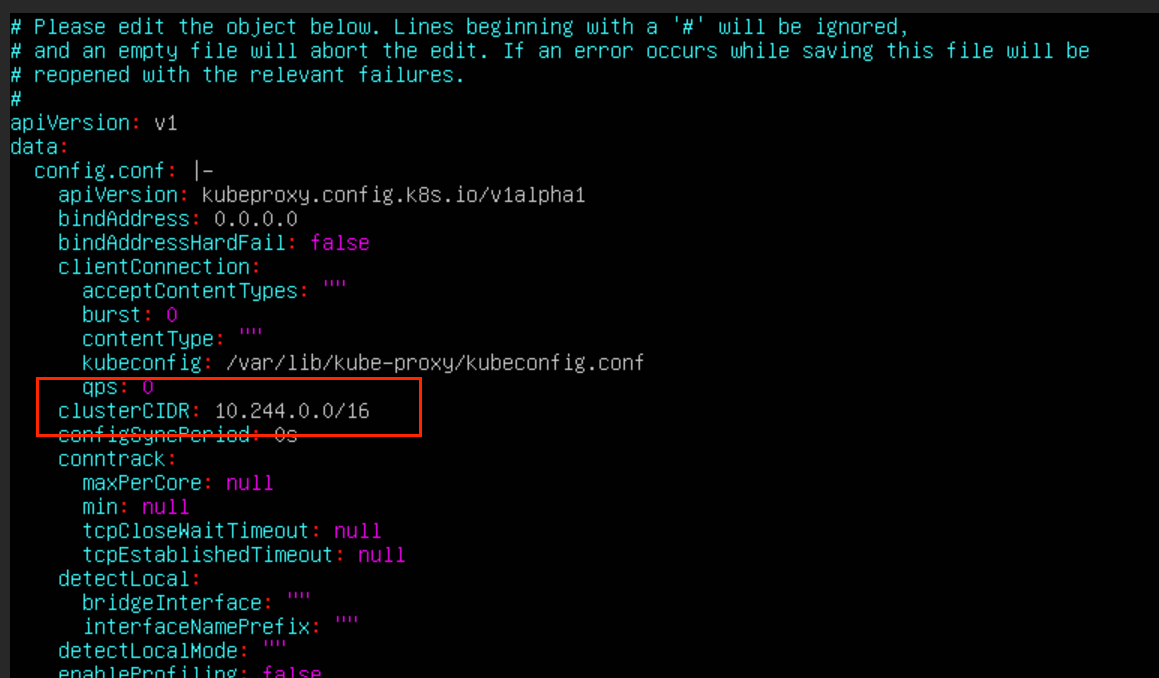
重启,再次创建 pod 网段未更改
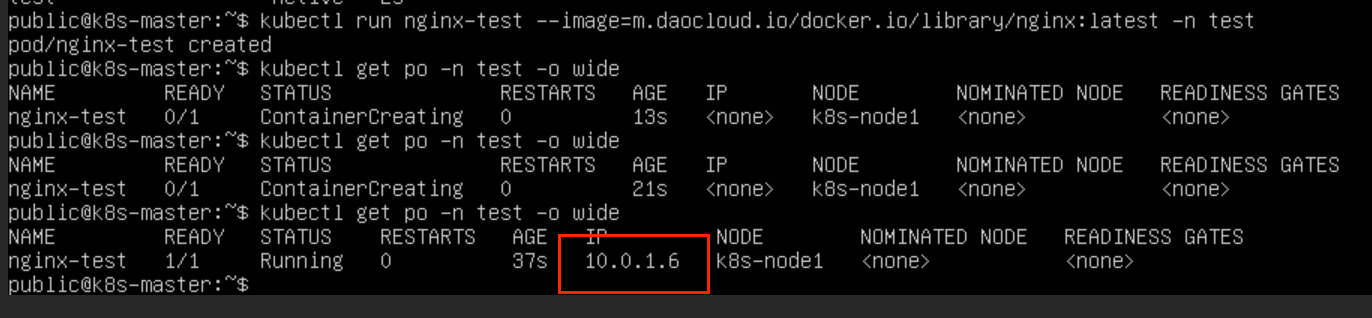
由于系统初始化的 coredns pod 的 IP 是根据网络插件的 CIDR 来分配 IP 的,所以需要在集群初始化时,更改插件的 CIDR配置
shell
helm uninstall cilium -n kube-system
shell
# 生成网络插件配置文件
helm show values cilium/cilium > values.yaml 更改 cilium 的 values.yaml 配置文件相关网段部分
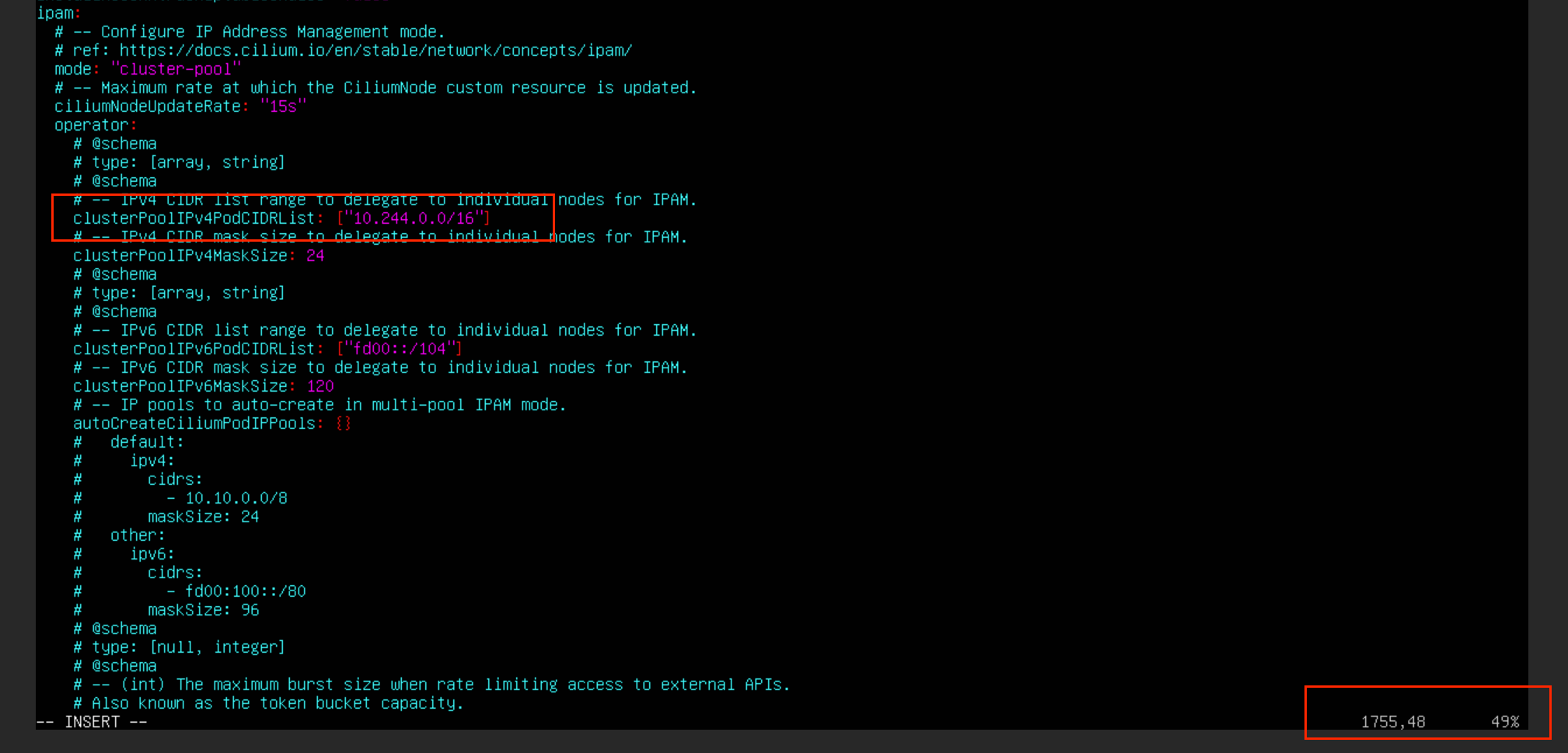
shell
# 根据配置文件安装插件
helm install cilium cilium/cilium --namespace kube-system -f values.yaml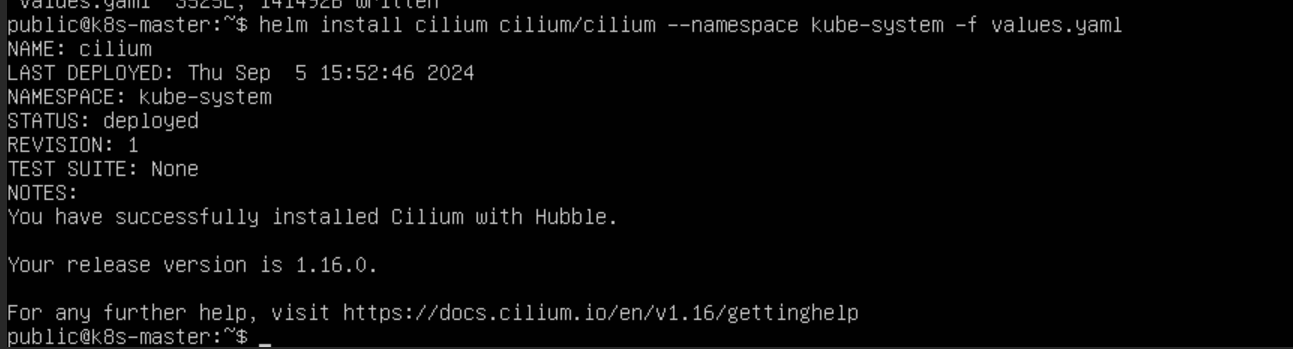
更改后 Pod 的 IP 的 CIDR 为网络插件的设置
启用globalnet 建立隧道
在不启用 globalnet 的情况下,CIDR 用重叠的两个集群之间,是无法建立连接的,因为 pod 之间的 IP 可能会出现重复无法辨别的情况
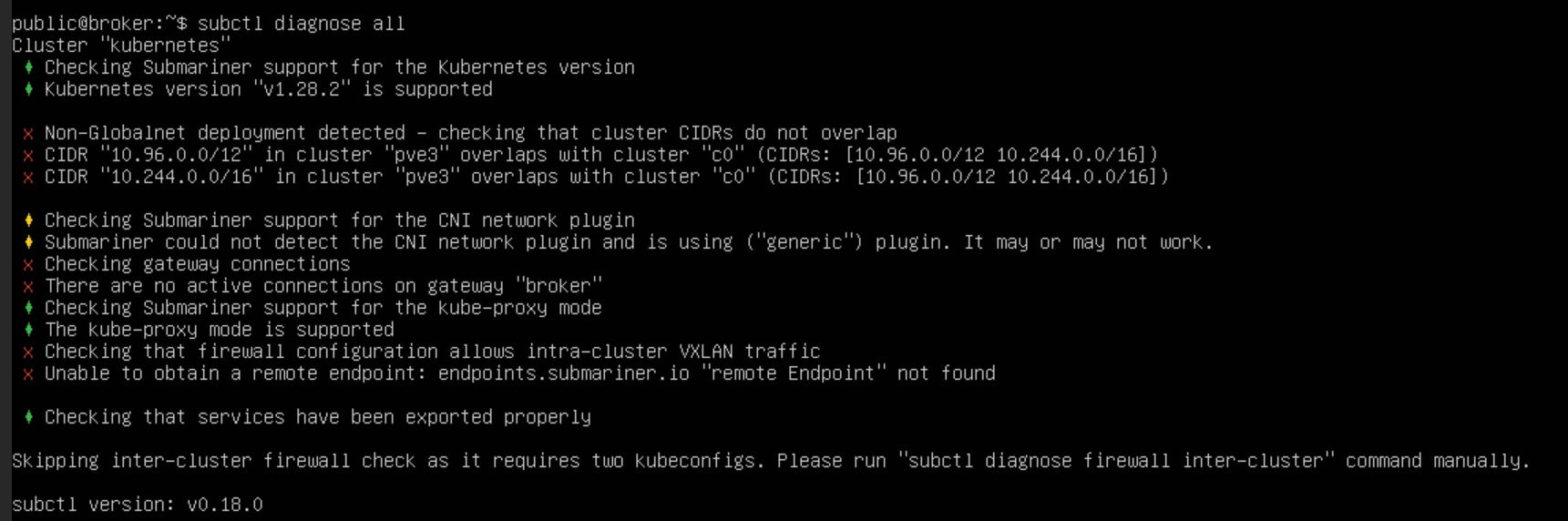
在不启用 globalnet 的情况下,CIDR 完全不重叠的两个集群之间是可以建立连接的,且建立好之后,直接通过 Pod 的 IP 就可以进行通信
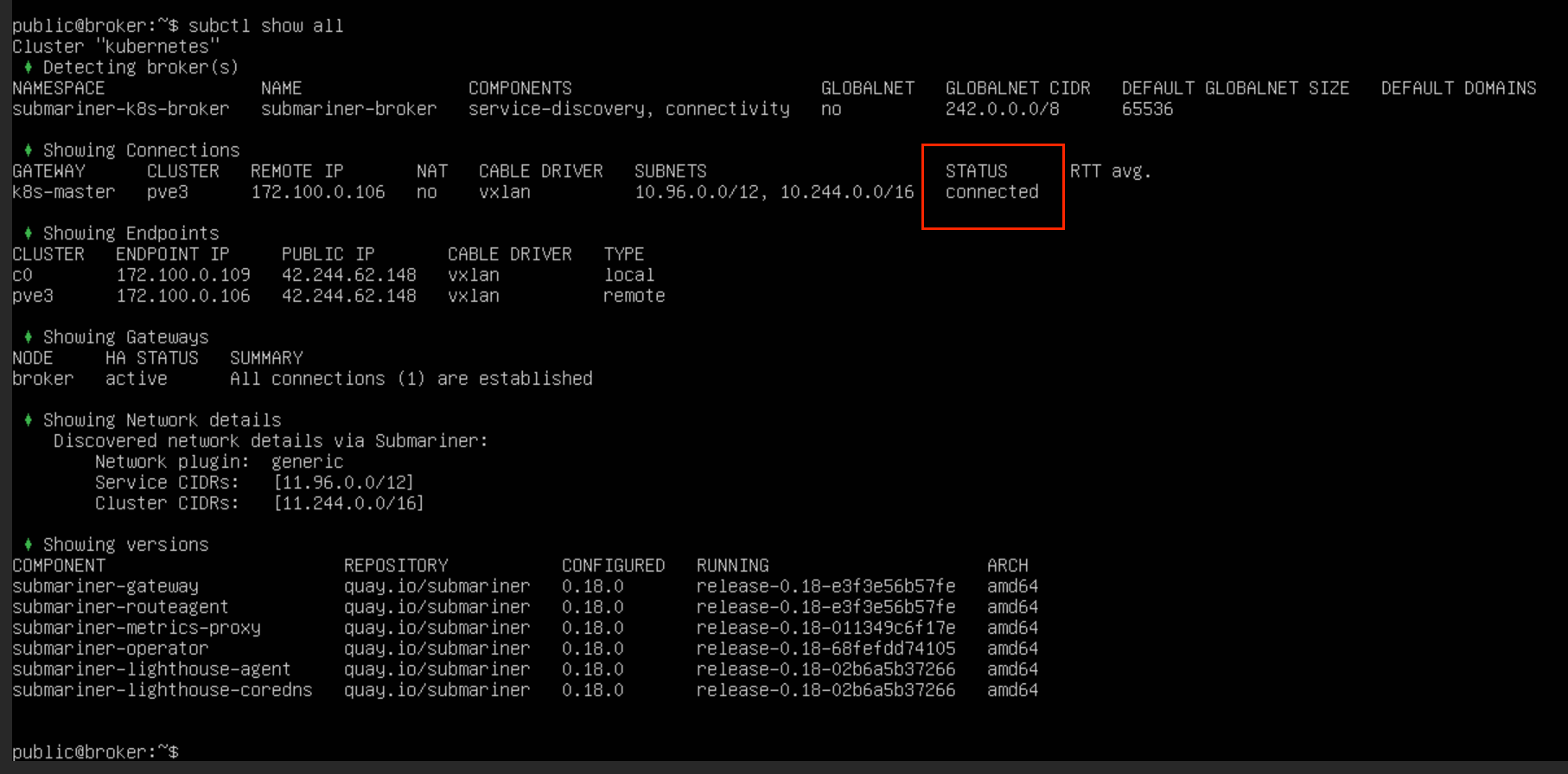
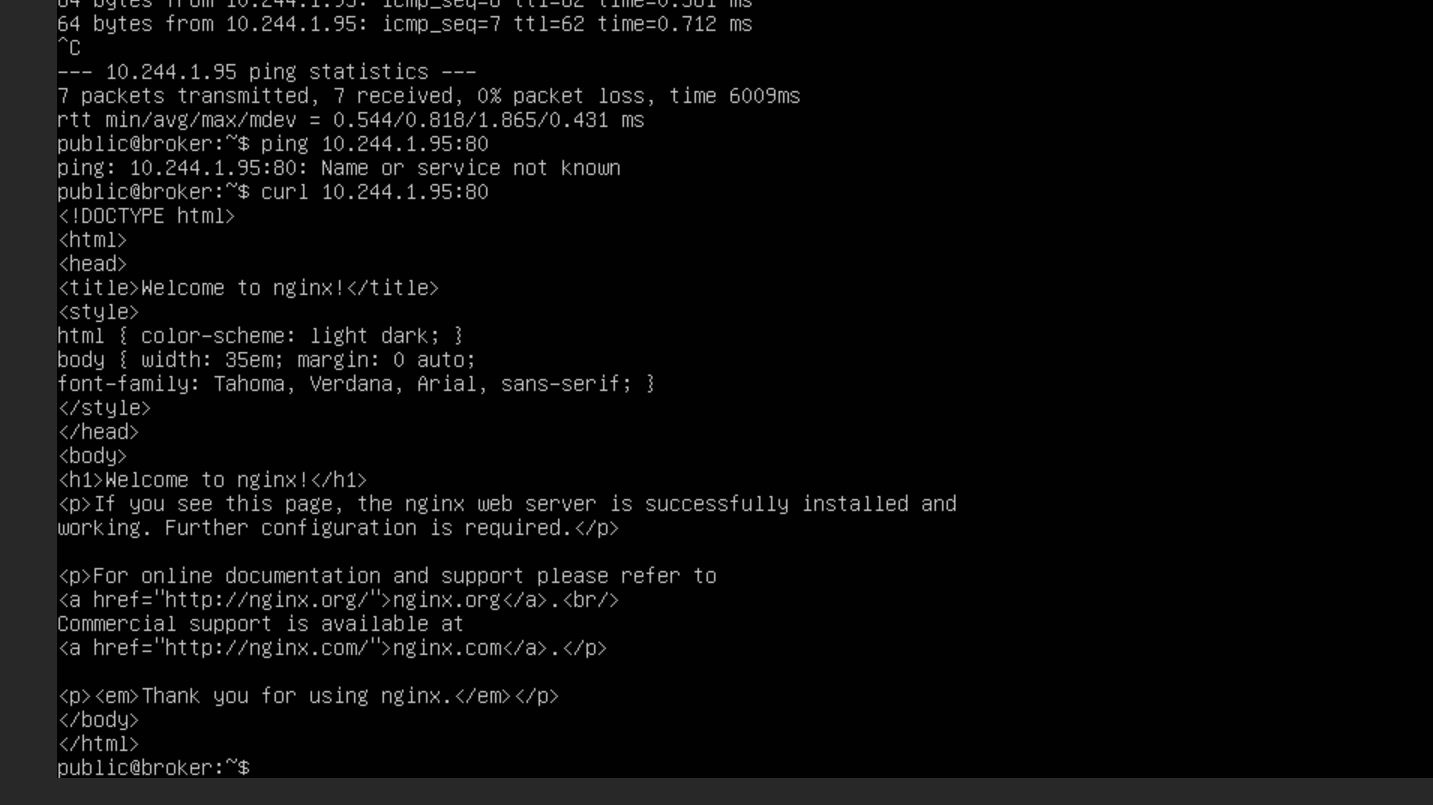
如果想在 CIDR 有重复的集群之间建立连接,需要启用 globalnet
shell
# 建立 broker
subctl --kubeconfig ~/.kube/config deploy-broker --globalnet
# 加入
subctl join broker-info.subm --clusterid pve3 --globalnet --cable-driver vxlan --health-check=false
# 指定网关节点,打标签
kubectl label nodes cluster1 submariner.io/gateway=true
# 查看集群注册信息
kubectl get clusters.submariner.io -n submariner-k8s-broker
# 删除
kubectl delete clusters.submariner.io <cluster-name> -n submariner-k8s-broker
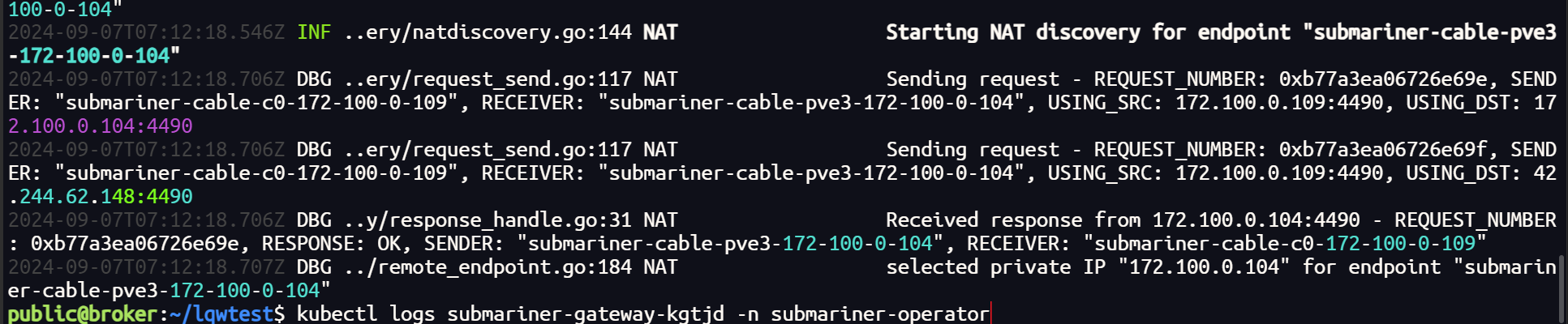
查看日志,隧道和路由成功建立
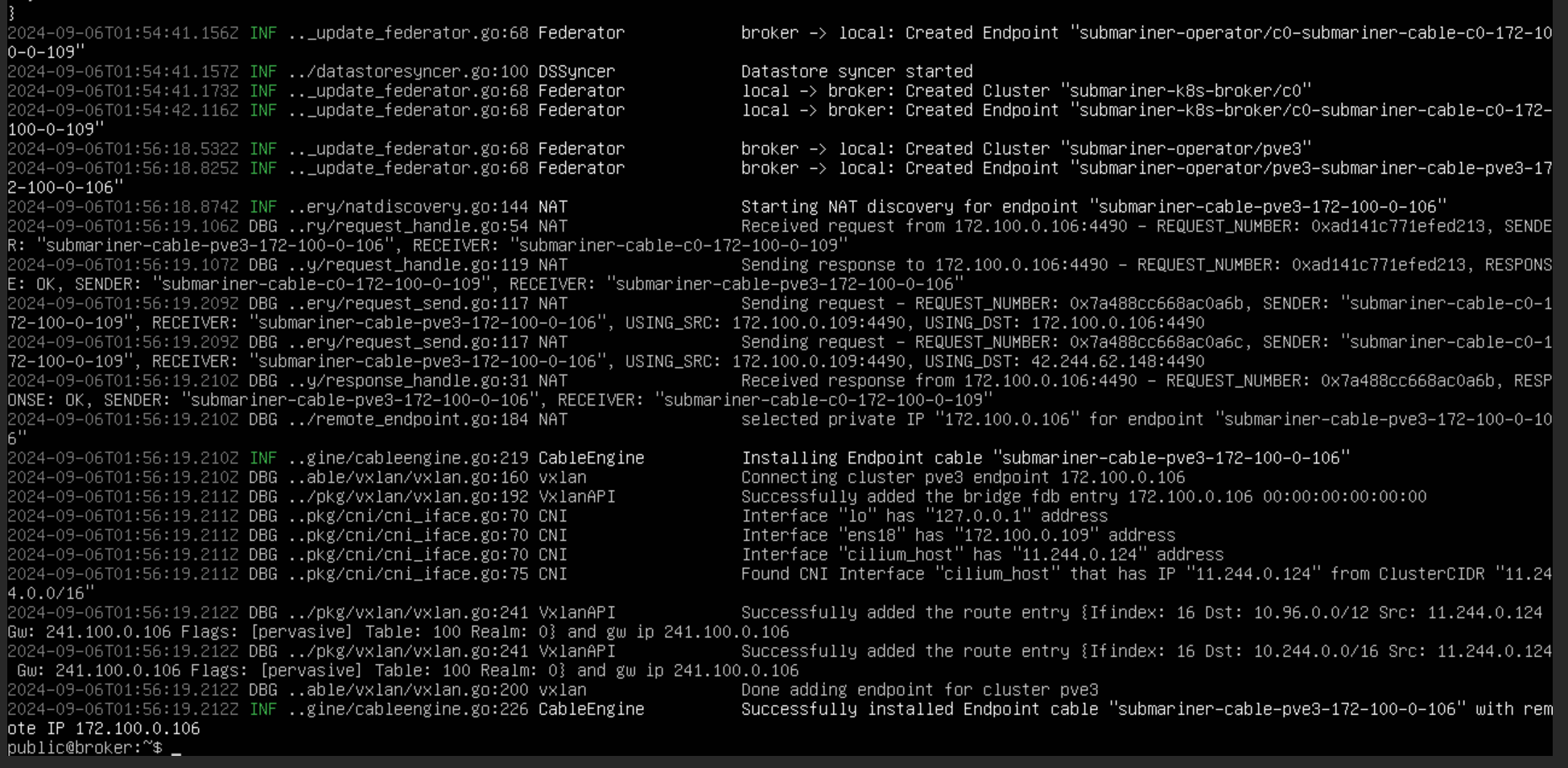
启用 globalnet 后,虚拟 CIDR 可以 自定义设置,但是设置的虚拟网段的地址不能重叠,否则同样无法建立隧道
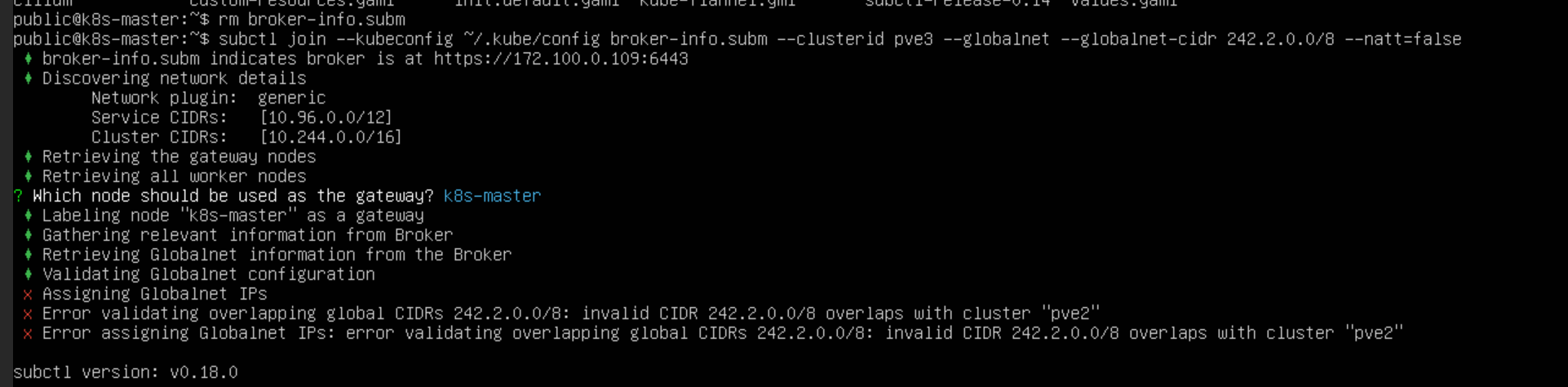
还有一点,由于网络插件 Cilium 的网络配置 主要支持 vxlan,submariner 建立 IPsec 隧道,隧道状态为 error。(据说,更改一下网络插件的相关设置可以解决这个问题,但目前还没有尝试,使用 vxlan 建立隧道)

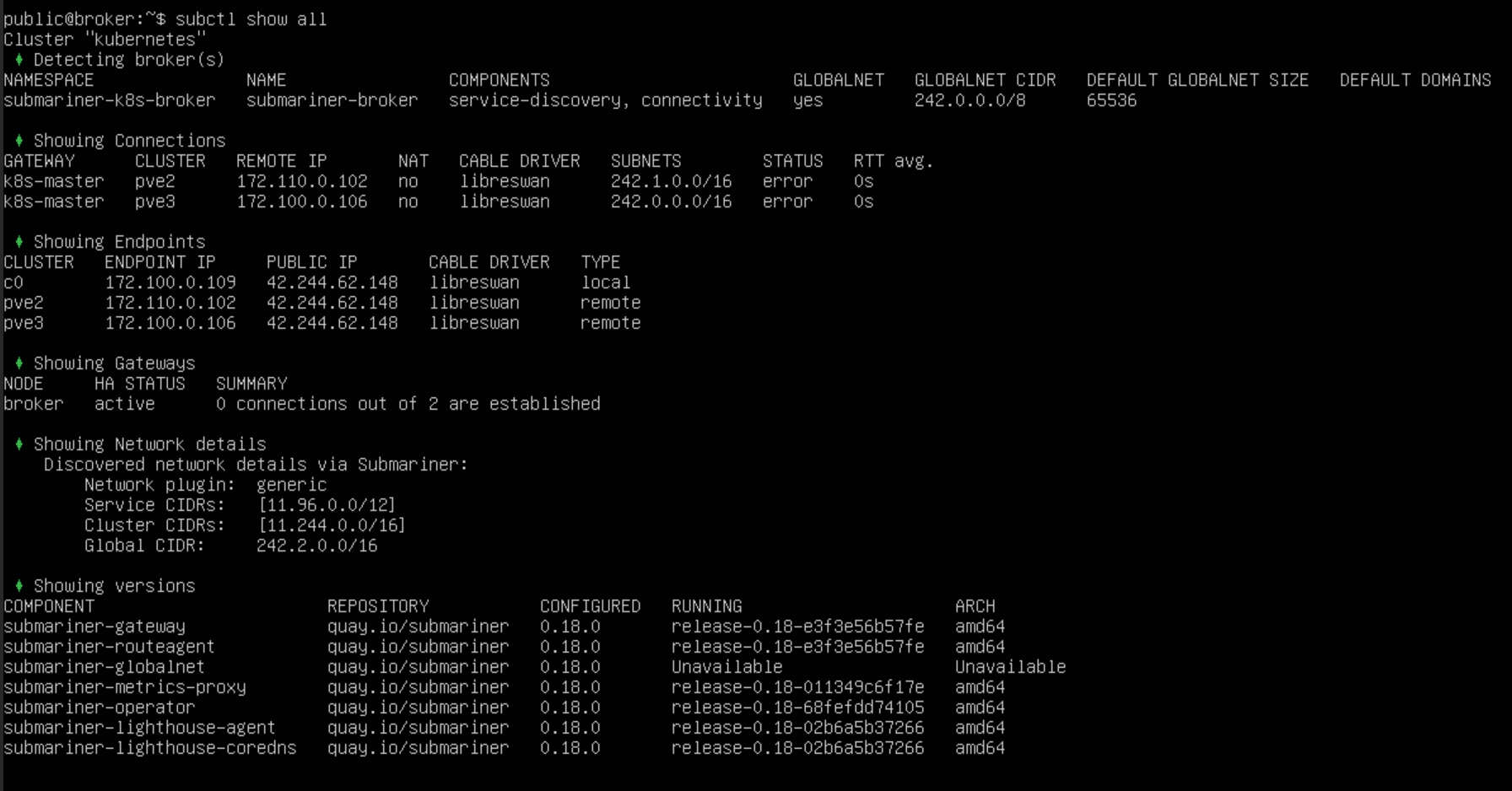
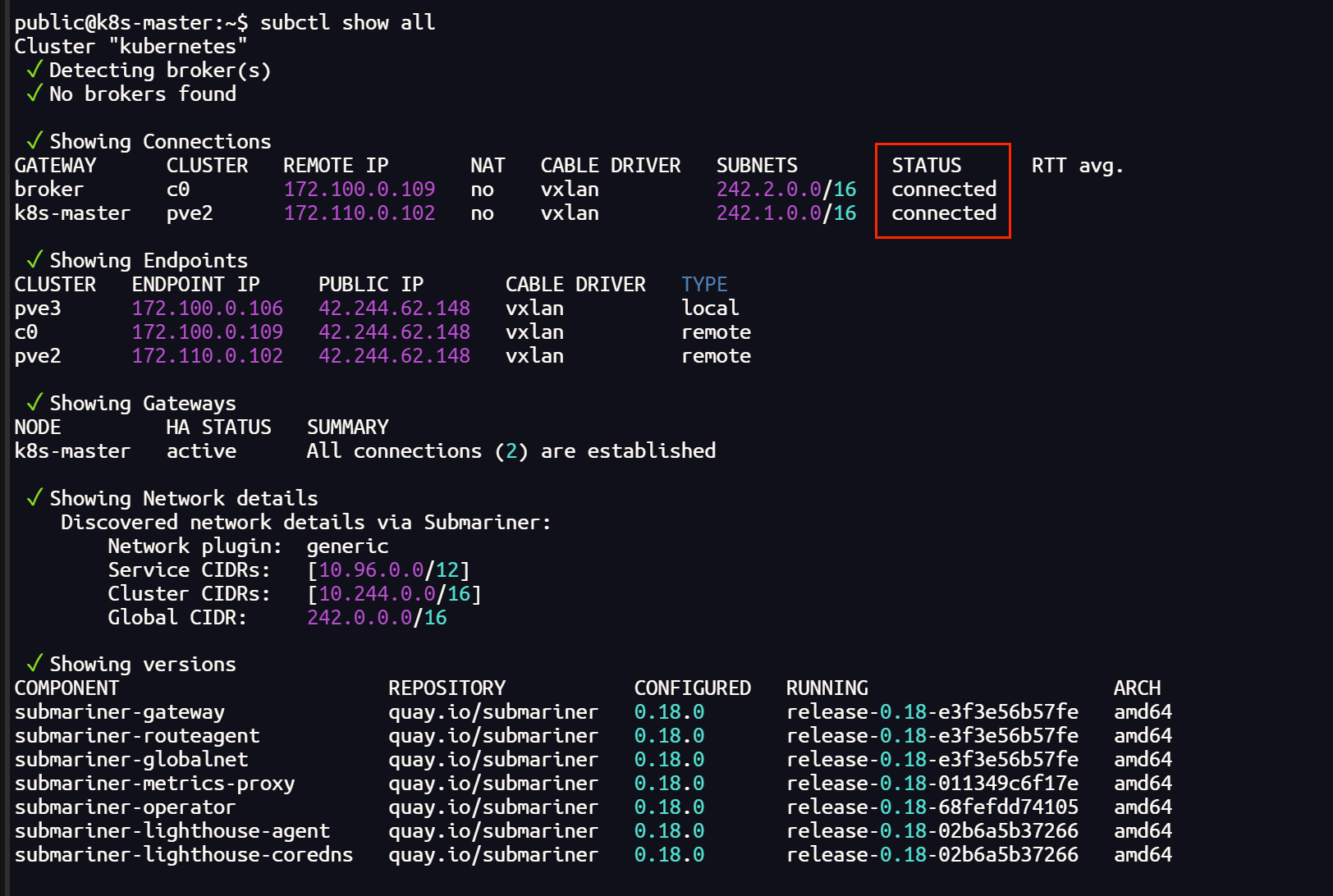
以上问题都解决之后,就可以正常建立隧道通信了,globalnet 会为每一个集群自动分配不重叠的 CIDR
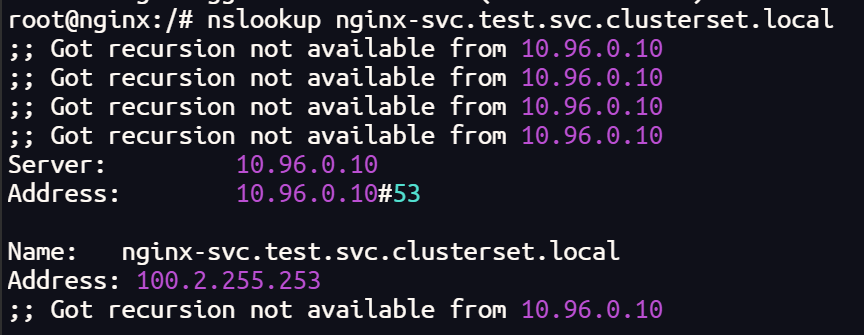
我们在一个集群中创建一个 nginx 的测试服务,并把它导出,其他集群会自动创建 导入服务(需要有相同的命名空间,否则无法导入)

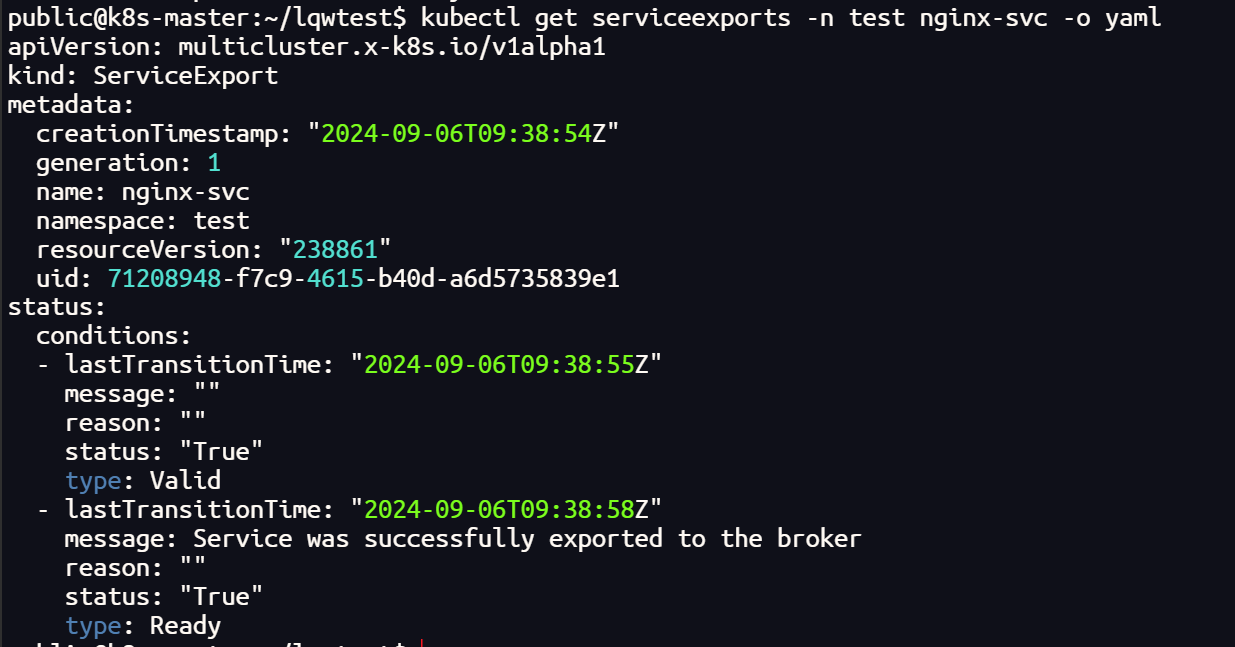

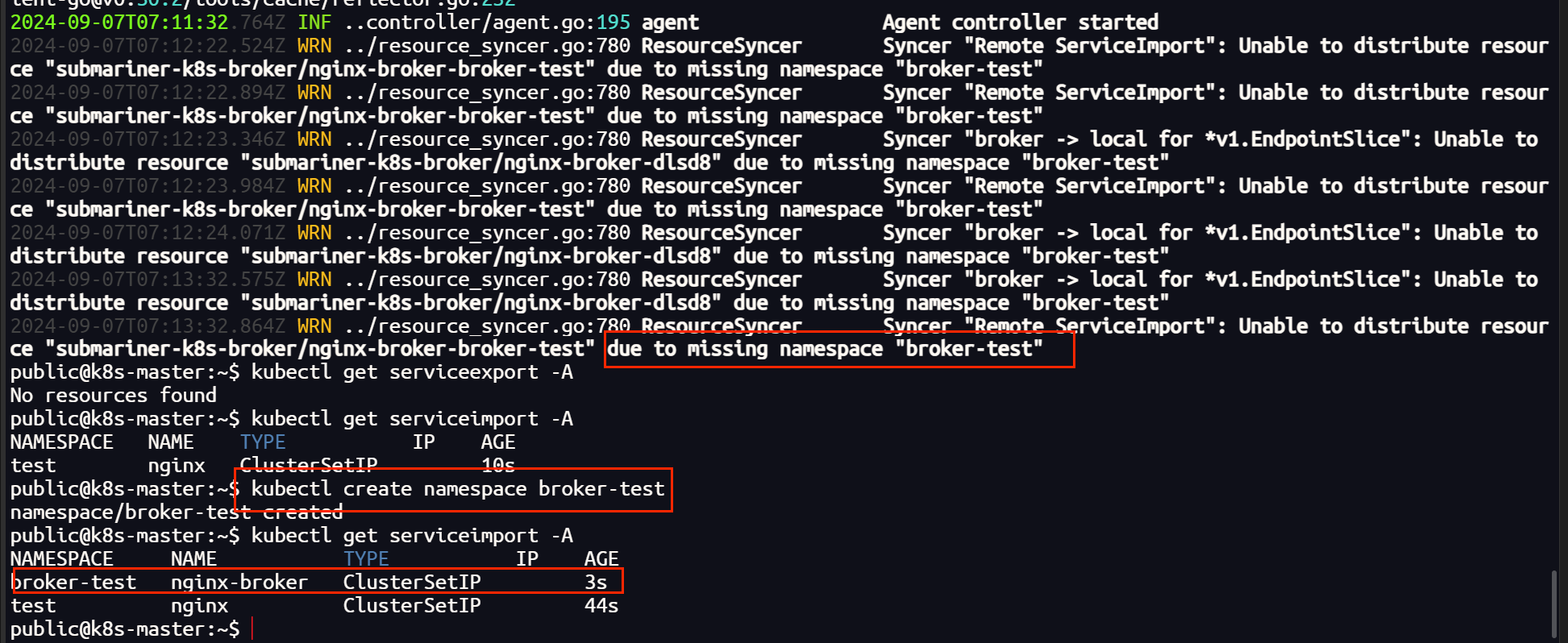
验证测试
shell
# 进入pod
kubectl exec -it <your-pod> -- bash
apt update
# 安装 nslookup
apt install -y dnsutils终端测试
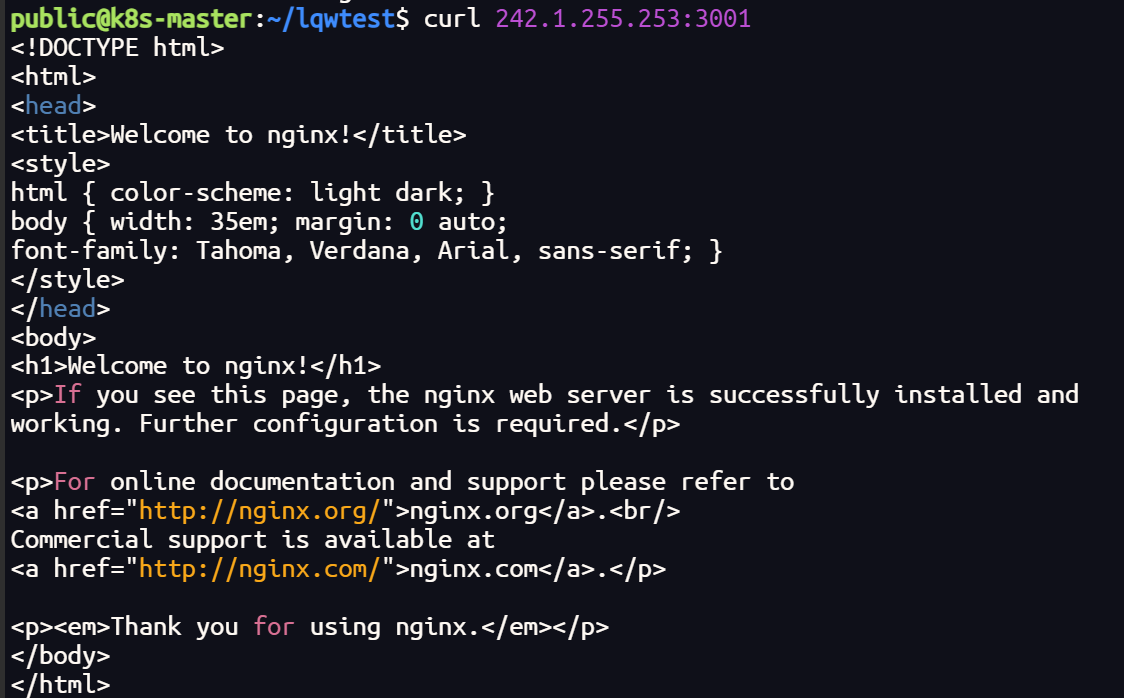

如果终端无法解析 DNS,在配置中添加 coredns 网址
shell
sudo nano /etc/resolv.conf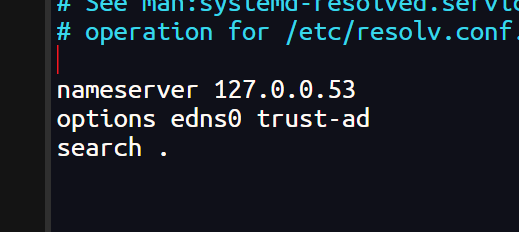
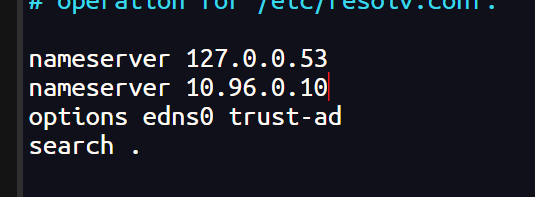
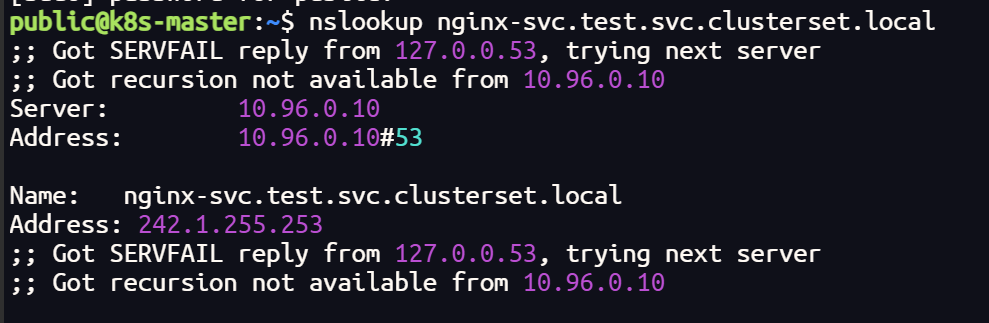
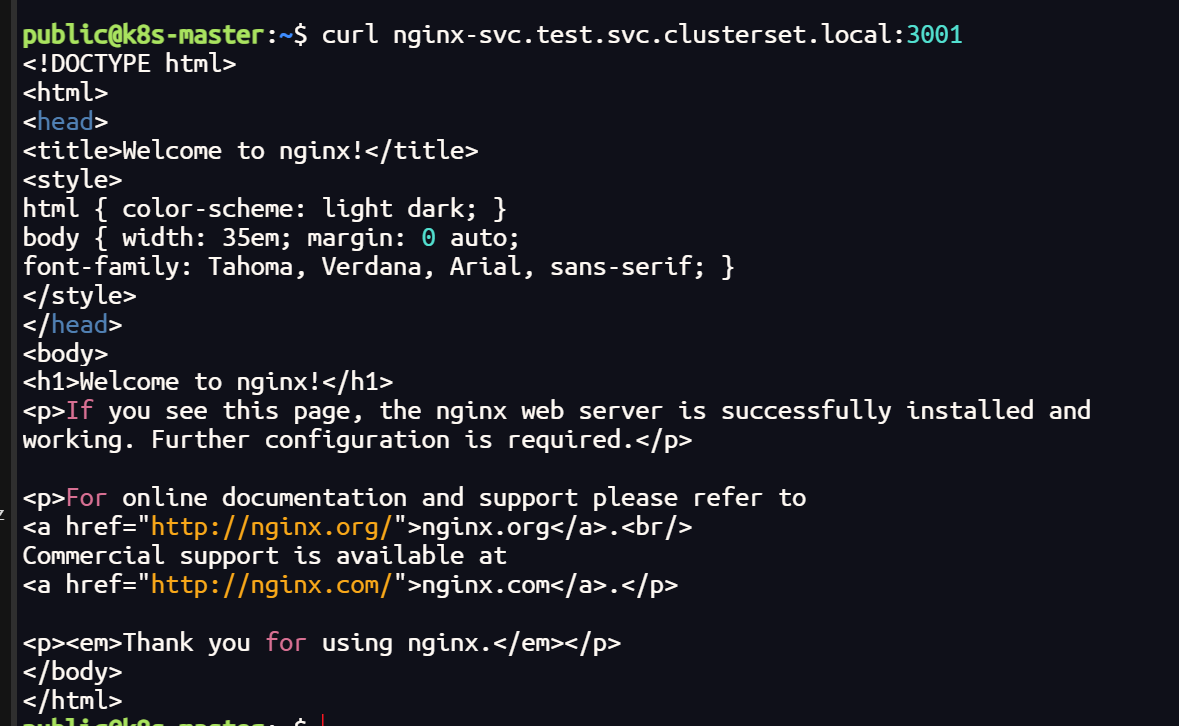
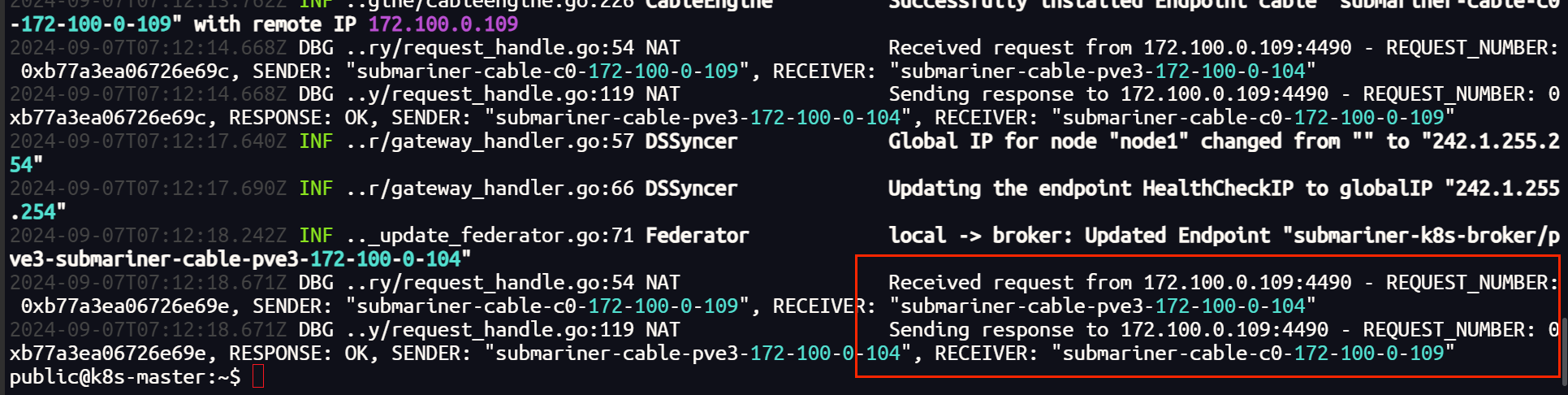
终端可以解析 DNS网址,也可以跨集群访问
Pod 内部测试
shell
# 安装网络工具
apt-get install iputils-ping dnsutils -y
iputils-ping # 包含 ping 工具。
dnsutils # 包含 nslookup 工具。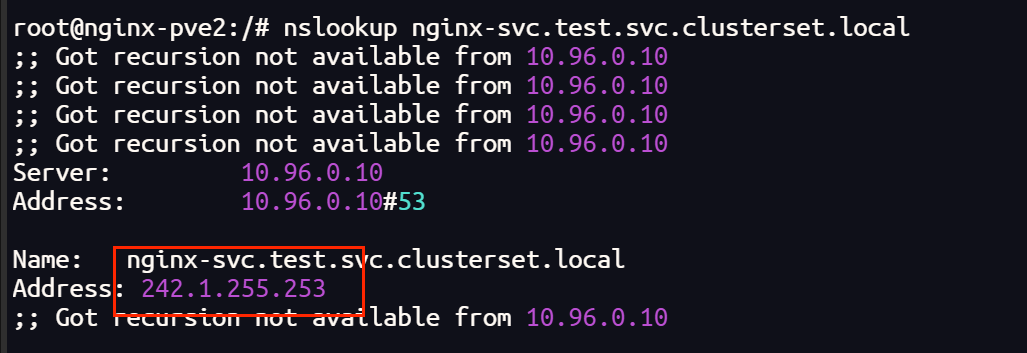

Pod 内部可以解析 DNS 网址,但是无法访问
网络插件 Cilium 更换 Calico
集群使用 submariner ,通过网络检测发现 Cilium 插件可能兼容性不太好
shell
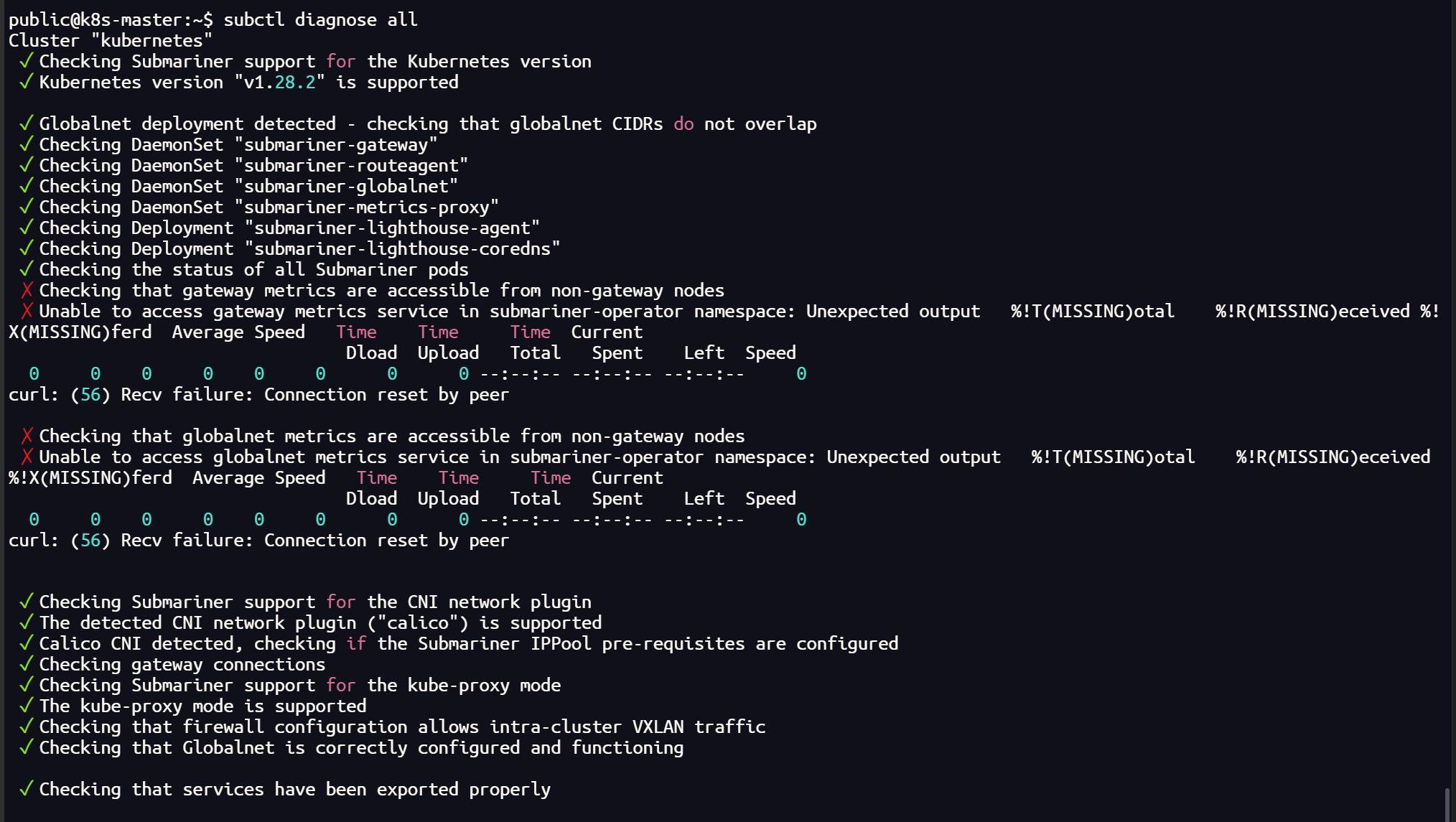
subctl diagnose all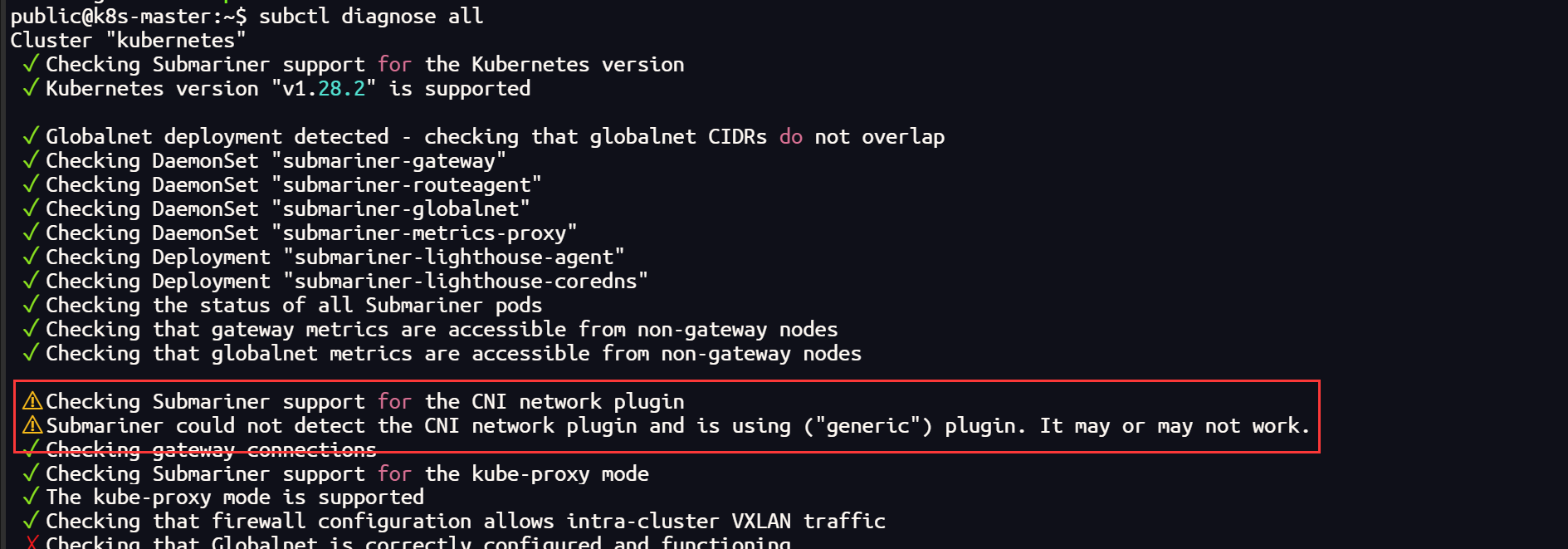
翻阅官网查询得知,submariner 官方已经测试的CNI插件并不包括 Cilium

Cilium 彻底卸载
shell
helm uninstall cilium -n kube-system
shell
# 检查集群中的所有 CNI 插件(集群的每个节点都需要删除)
sudo ls /etc/cni/net.d/
# 删除
sudo rm /etc/cni/net.d/05-cilium.conflist
sudo rm /etc/cni/net.d/10-flannel.conflist.cilium_bak
shell
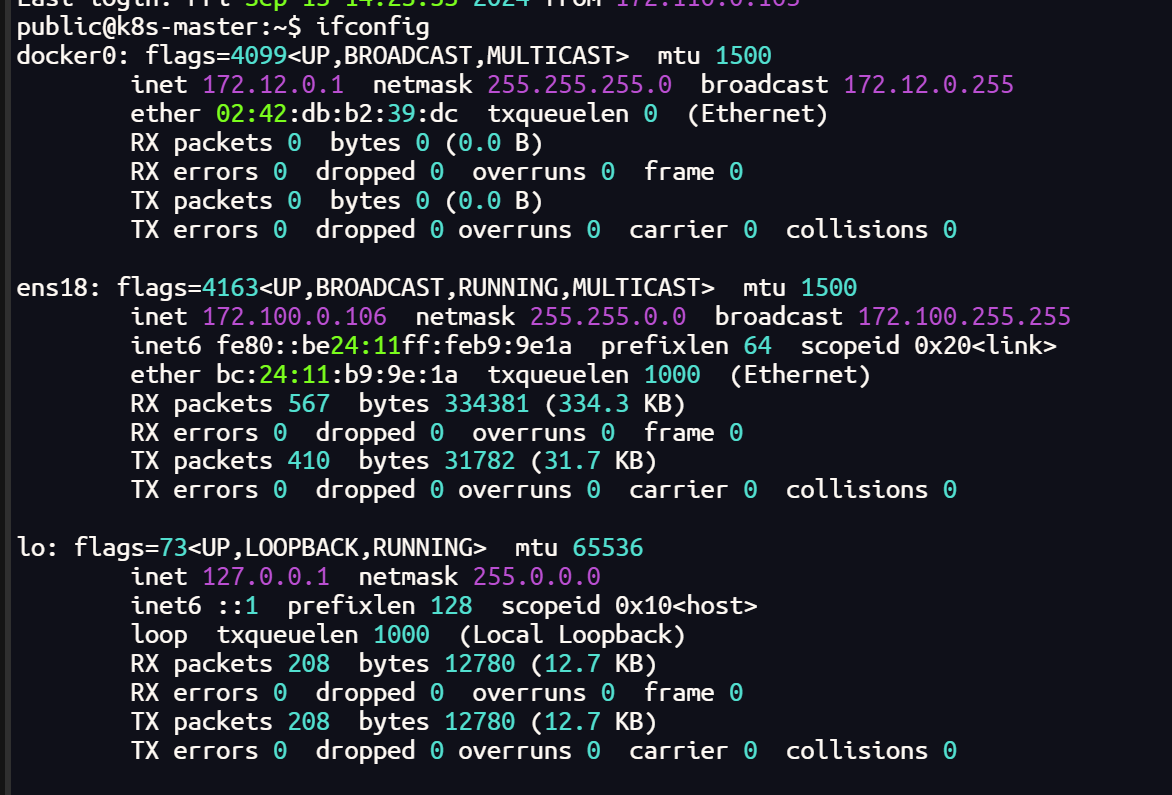
ifconfig
sudo reboot
Calico安装
calico官网地址:https://docs.tigera.io/calico/latest/getting-started/kubernetes/quickstart
安装Tigera Calico操作符和自定义资源定义:
shell
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/tigera-operator.yaml如果报错连接不上的话将文件手动下载下来再执行
shell
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
或者
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
kubectl create -f tigera-operator.yaml 下载下来后不能用 kubectl apply -f 来执行,会报错
The CustomResourceDefinition "installations.operator.tigera.io" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
意思是 annotation 长度过长了,原因是 apply 和 create 的处理不同改配置文件中这个选项的长度就不改了,不用 apply 使用 create
这里没有报错就没有问题
但运行完之后要查看一下 tigera-operator 运行是否正常,如果状态为Running 则继续执行下面的步骤
这里可能会出现 容器创建失败 的情况,查看日志一般是因为镜像拉取失败,查看配置文件关于镜像的部分,这里需要单独拉取镜像
第二步将配置文件下载下来,因为要改内容:
shell
# 下载客户端资源文件
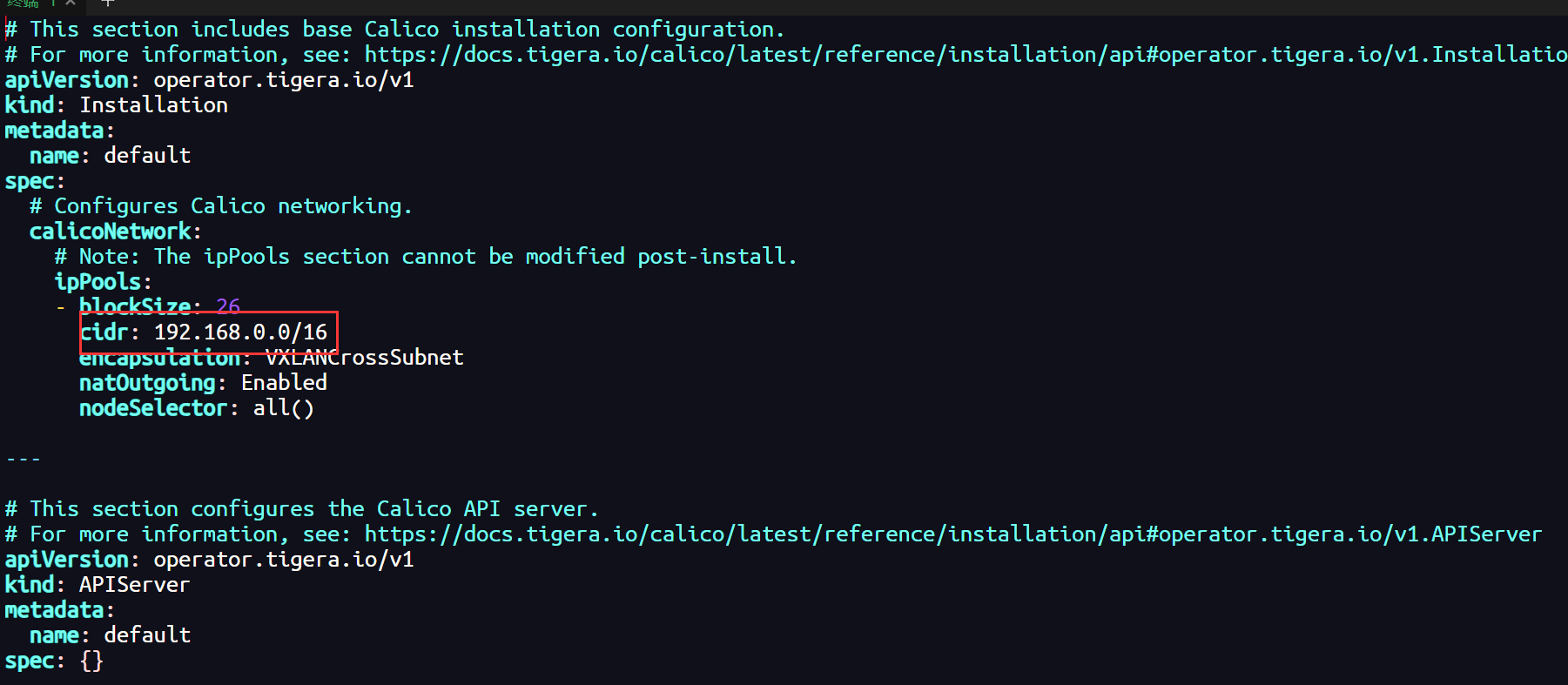
curl -LO https://raw.githubusercontent.com/projectcalico/calico/v3.27.2/manifests/custom-resources.yaml这个文件中的 192.168.0.0 为 init 时指定的 --pod-network-cidr:
shell
# 或者修改pod的网段地址
sed -i 's/cidr: 192.168.0.0/cidr: 10.244.0.0/16' custom-resources.yaml最后根据这个文件创建资源,执行下面这行命令:
shell
kubectl create -f custom-resources.yaml这里如果你的集群无法拉取国外镜像,可以尝试配置镜像加速器
shell
sed -i 's#config_path = ""#config_path = "/etc/containerd/certs.d"#' /etc/containerd/config.toml
mkdir /etc/containerd/certs.d/docker.io/ -p
# 这里的加速器地址可以选择阿里云的镜像加速地址
cat >/etc/containerd/certs.d/docker.io/hosts.toml <<EOF
[host."https://dbxvt5s3.mirror.aliyuncs.com",host."https://registry.docker-cn.com"]
capabilities = ["pull"]
EOF
#重启containerd
systemctl restart containerd 如果,配置了镜像加速器依然无法拉取,这时就需要比较繁琐复杂的过程了(因为我没有找到国内的可以镜像源地址,所以选择在本地拉取dockerhub 镜像传到个人镜像仓库再进行拉取,当然也可以打包直接传到主机)
需要拉取的镜像如下:
docker.io/calico/typha:v3.28.0
docker.io/calico/apiserver:v3.28.0
docker.io/calico/kube-controllers:v3.28.0
docker.io/calico/node-driver-registrar:v3.28.0
docker.io/calico/pod2daemon-flexvol:v3.28.0
需要注意的是,如果你采用这种方式,不要只在主节点拉取镜像,部分镜像也需要在工作节点拉取
shell
# 本地拉取镜像
docker pull docker.io/calico/typha:v3.28.0
# 上传阿里云私人仓库
docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/leung_qw/typha:[镜像版本号]
docker push registry.cn-hangzhou.aliyuncs.com/leung_qw/typha:[镜像版本号]
# 拉取镜像
sudo ctr -n k8s.io image pull registry.cn-hangzhou.aliyuncs.com/leung_qw/typha:v3.28.0
sudo ctr -n k8s.io image tag registry.cn-hangzhou.aliyuncs.com/leung_qw/typha:v3.28.0 docker.io/calico/typha:v3.28.0
# 查看镜像
sudo ctr -n k8s.io image list | grep calico
上传到私人镜像仓库,拉取后更改 tag


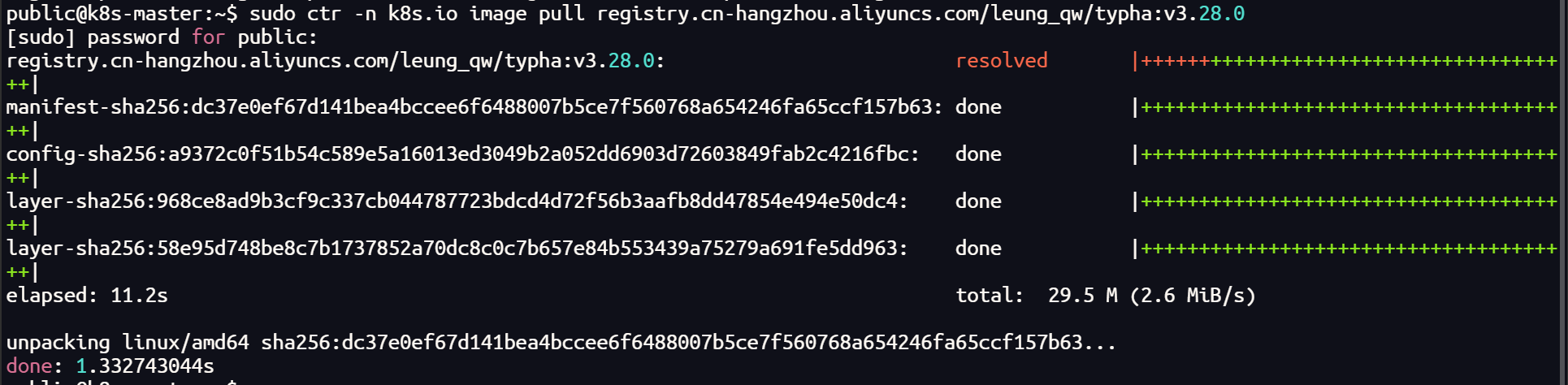
主机拉取镜像的时候,一定要带-n k8s.io 的命名空间,否则会出现,无法检测到本机镜像的情况
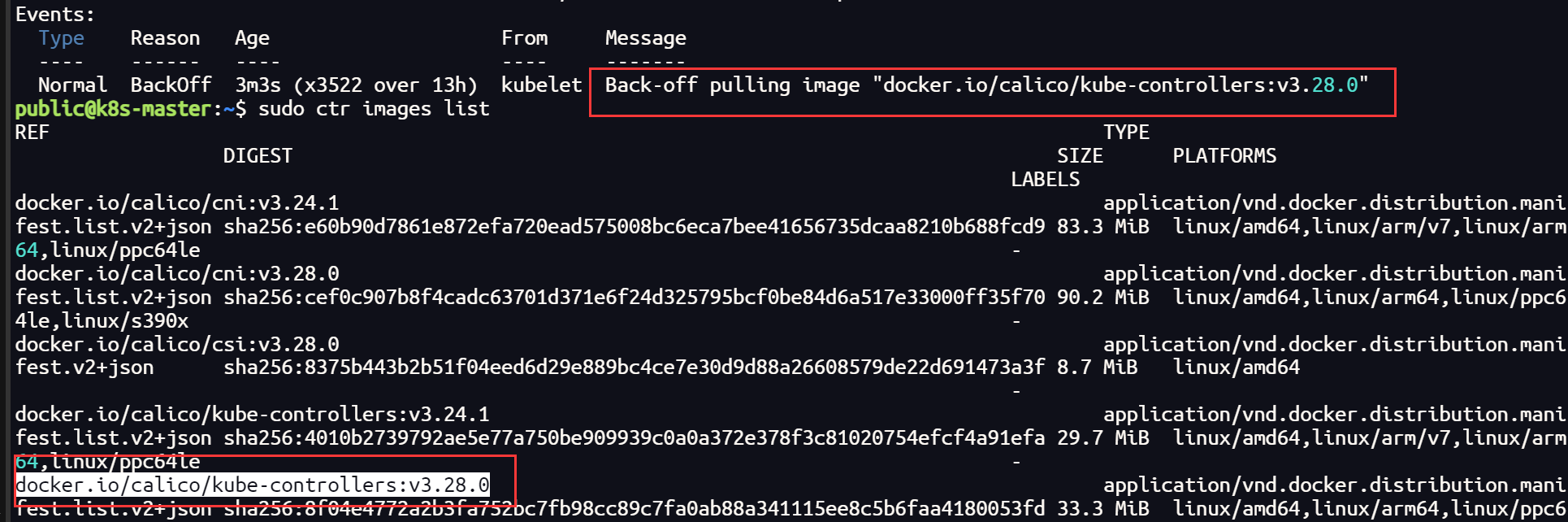

其他镜像如法炮制
如果,你在一台主机上已经有了上面的镜像,也可以将镜像打包,传给其他节点导入
shell
# 镜像打包
sudo ctr -n k8s.io images export <path-to-tar-file> <image-name>:<tag>
# 例如
sudo ctr -n k8s.io images export typha.tar docker.io/calico/typha:v3.28.0
# 传递文件
scp file 远程用户名@远程服务器IP:/path/to/destination
# 例如
scp typha.tar public@172.100.0.104:~/
# 导入镜像
sudo ctr -n k8s.io images import typha.tar使用 cilium 插件时的 submariner 以及 更换 calico 后
shell
subctl diagnose all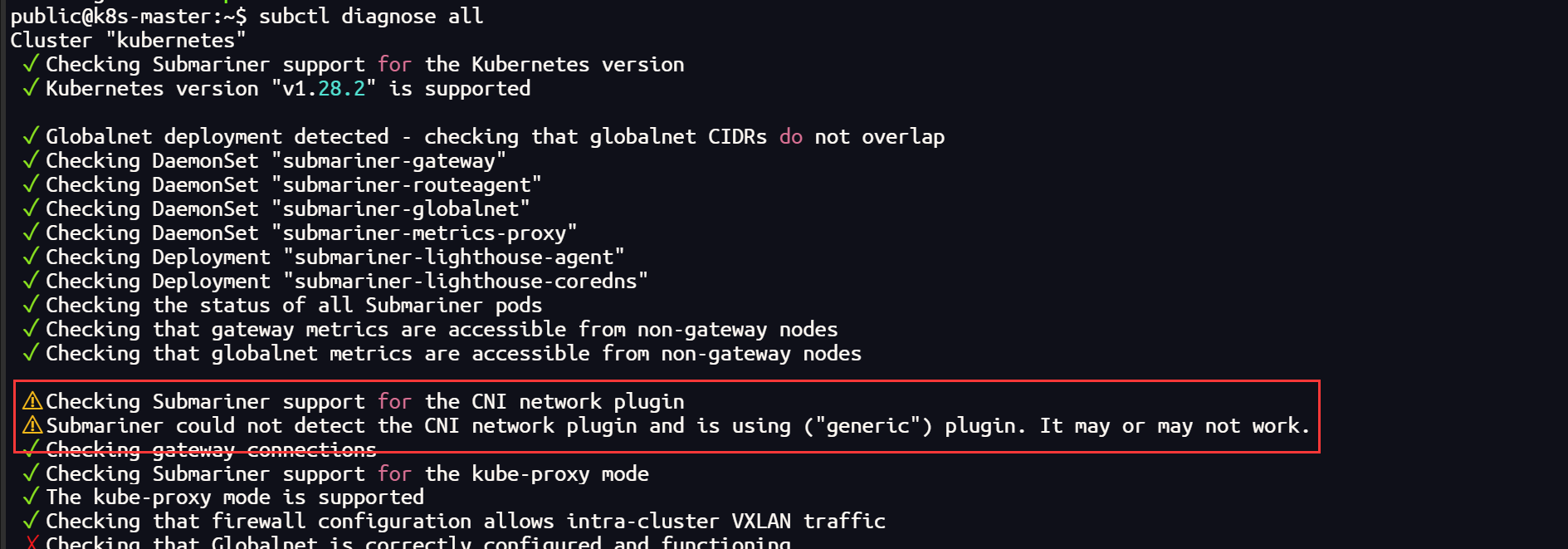
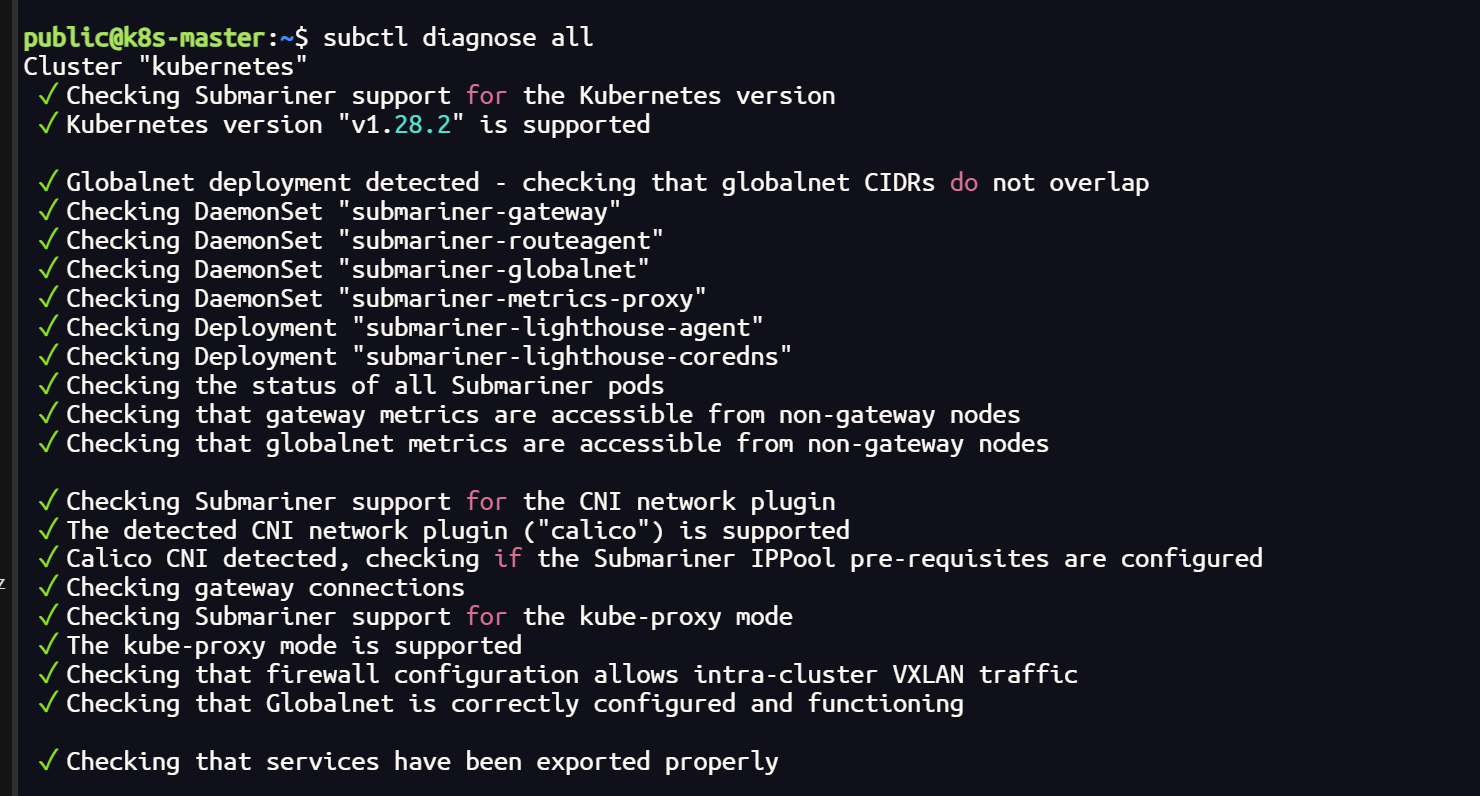
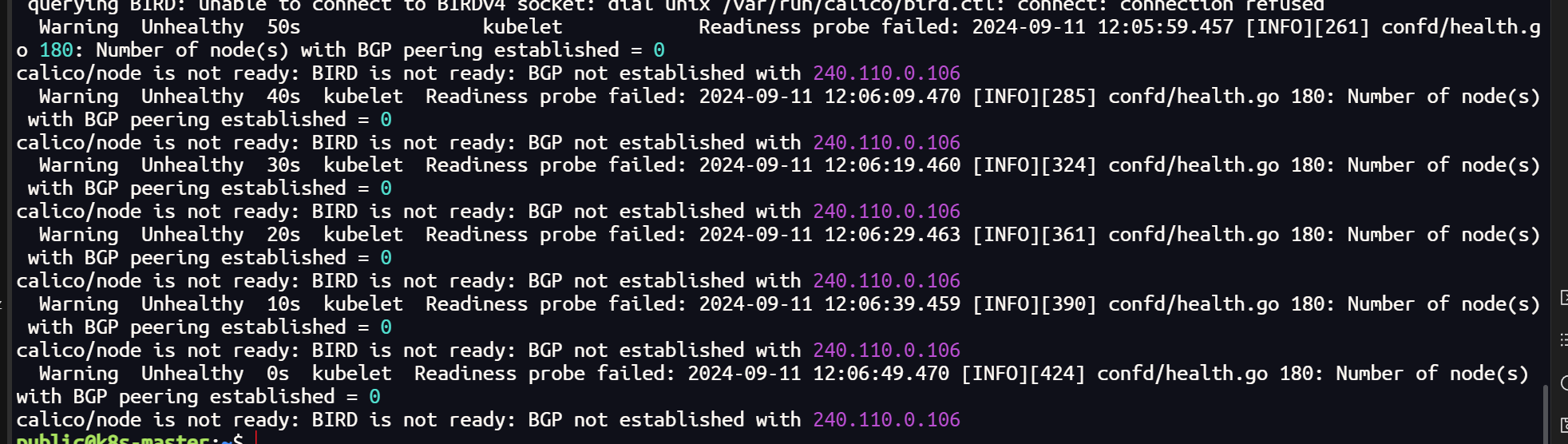
将 k8s 集群的 CNI 插件更换 Calico 后,正常情况下,所有的节点均处于Running 状态,但是当集群加入 submariner 后,vx-submariner 隧道建立后,会导致 calico-node 状态异常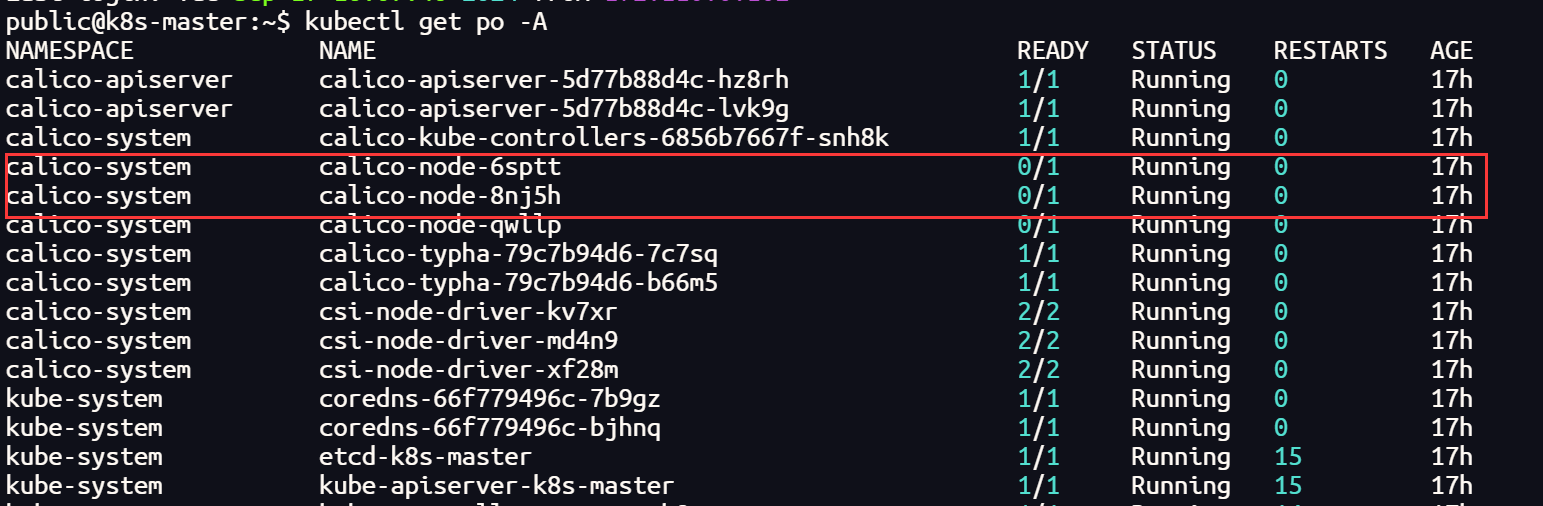
查询日志发现是隧道虚拟网卡无法建立 BGP ,Calico 主要靠 BGP 负责网络路由功能,在集群节点之间分发路由信息

calico-node 状态的异常会导致,集群内部的通信无法到达网关节点
Calicoctl 安装
版本号选择自己安装的版本
shell
# 查看calico版本
kubectl get deployment -n kube-system calico-kube-controllers -o yaml | grep image
# 下载二进制文件
curl -O -L https://github.com/projectcalico/calico/releases/download/v3.28.0/calicoctl-linux-amd64安装 calicoctl
shell
# 添加可执行权限
chmod +x calicoctl-linux-amd64
# 安装
sudo mv calicoctl-linux-amd64 /usr/local/bin/calicoctl
# 设置环境变量
export CALICO_DATASTORE_TYPE=kubernetes
export CALICO_KUBECONFIG=~/.kube/config如果不希望每次执行 calicoctl 之前都需要设置环境变量,可以将环境变量信息写到永久写入到 /etc/calico/calicoctl.cfg 文件(~/.kube/config 要更换成自己的路径)
shell
mkdir -vp /etc/calicoapiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "kubernetes"
kubeconfig: "home/public/.kube/config"
shell
# 通过~/.kube/config连接kubernetes集群,查看已运行节点
DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
# 或者(如果写入环境变量后)
calicoctl get nodes
配置 Calico IPPools 并且重新部署 submariner
重新部署submariner,一定要卸载干净,仅仅使用subctl uninstall会有部分遗留。执行命令后要注意一下 submariner-operator 命名空间是否删除
如果 submariner-operator 命名空间处于 Terminating 状态长时间未被删除,这可能是因为有某些资源仍然存在,或者有 Finalizer 阻止了删除。
移除 Finalizers。Finalizers 会阻止命名空间被删除。
获取命名空间的详细信息:
shell
kubectl get namespace submariner-operator -o json > namespace.json编辑 JSON 文件:
打开 namespace.json 文件,找到 spec.finalizers 字段,将其删除。
shell
{
"apiVersion": "v1",
"kind": "Namespace",
"metadata": {
"name": "submariner-operator",
"finalizers": [
"kubernetes"
]
},
"spec": {
"finalizers": []
}
}删除 finalizers 部分,然后保存文件。
应用修改后的文件:
shell
kubectl replace --raw "/api/v1/namespaces/submariner-operator/finalize" -f namespace.json使用 kubectl删除命名空间
shell
kubectl delete namespace submariner-operator --grace-period=0 --force broker 集群删除集群注册信息
shell
kubectl get clusters.submariner.io -n submariner-k8s-broker
kubectl delete clusters.submariner.io pve2 -n submariner-k8s-broker重新部署 submariner
submariner 官网提到,当前使用 Calico 目前仅支持 VXLAN 封装技术,且,启用 globalnet 选项后,最好不使用默认的虚拟CIDR,自定义虚拟IP范围


shell
subctl deploy-broker --globalnet --globalnet-cidr-range 100.0.0.0/8
subctl join broker-info.subm --clusterid pve2 --globalnet --globalnet-cidr 100.1.0.0/16 --cable-driver vxlan --health-check=false
subctl join broker-info.subm --clusterid pve3 --globalnet --globalnet-cidr 100.2.0.0/16 --cable-driver vxlan --health-check=false配置 Calico IPPools
ippool是 Calico 资源,它定义了Calico可以使用的IP地址范围。例如,当IP池中的Pod需要到达IP池外的资源(例如Internet)时,通常使用源网络地址转换(SNAT)。由于我们不希望Calico在集群之间对流量进行NAT转换,因此我们将在每个集群中为其他集群的pod cidr 创建 ippool。当发送到集群集中的其他集群时,这将禁用SNAT,但仍然允许pod使用NAT与Internet通信。
根据 submariner 部署的情况,对 Service CIDR,Pod CIDR,Global CIDR 建立 IPPools,这样可以解决 BGP 无法在虚拟网卡建立的问题。
SHELL
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: globalpve3cluster
spec:
cidr: 100.2.0.0/16
vxlanMode: Always # 启用 VXLAN 封装
natOutgoing: false
disabled: true
shell
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: svcpve3cluster
spec:
cidr: 10.96.0.0/12
natOutgoing: false
disabled: true
shell
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: podpve3cluster
spec:
cidr: 10.244.0.0/16
natOutgoing: false
disabled: true
shell
calicoctl create -f podpve3cluster.yaml
calicoctl create -f svcpve3cluster.yaml
calicoctl create -f globalpve3cluster.yaml
calicoctl get ippool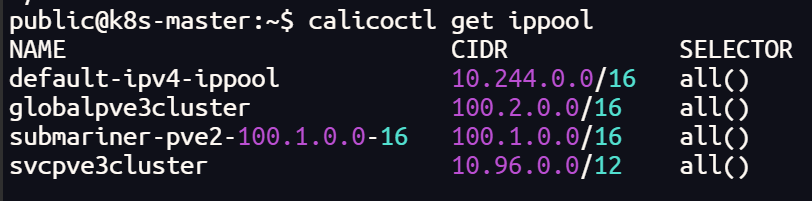
shell
subctl diagnose all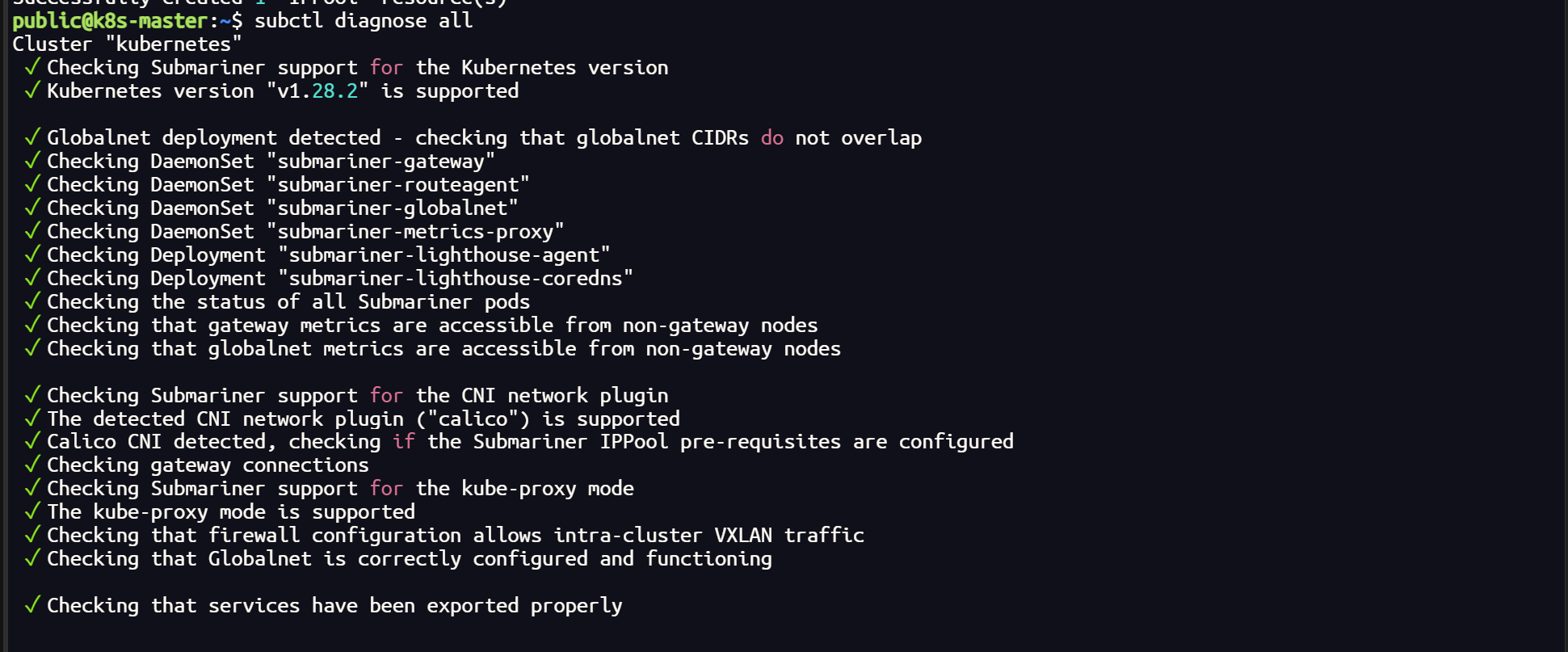
验证测试

`