文章汇总
当前VLMs微调中存在的问题
提示微调的问题

在提示调优中缺乏对先验知识保存的保证(me:即提示微调有可能会丢失预训练模型中的通用知识 )。虽然预先训练的文本分支模块(如文本编码器和投影)的权重在提示调优范式中被冻结,但原始的良好学习的分类边界或多或少受到破坏。这是因为输入提示的调优最终会得到一个新的边界,如果没有显式的正则化,这个边界可能会忘记旧的知识。
适配器微调的问题
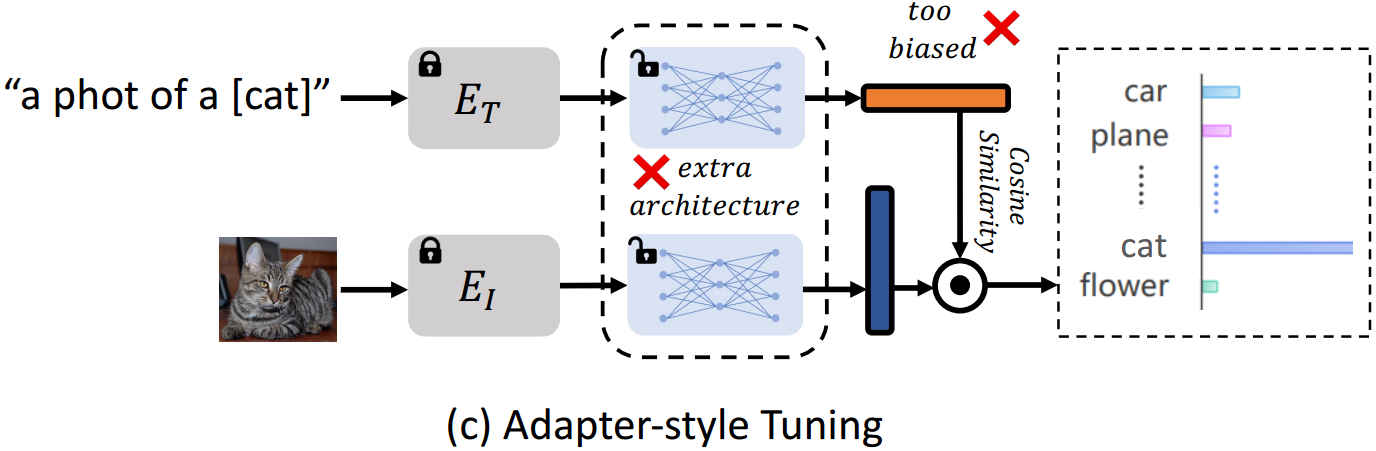
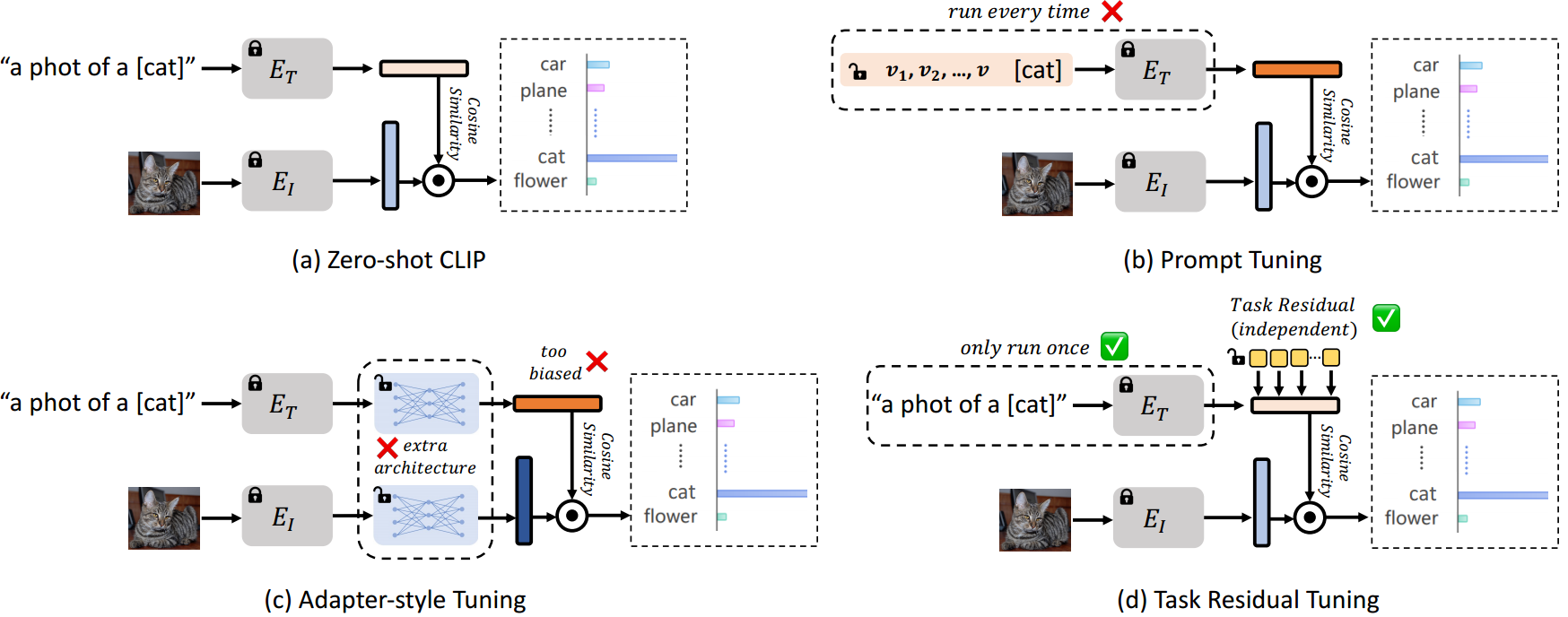
在适配器式调优中,新知识探索的灵活性有限 。下游任务中的数据分布往往偏离预训练分布,一些特定于任务或细粒度的视觉概念/表示可能无法被预训练的VLMs很好地学习,例如,从CLIP55到卫星图像数据集EuroSAT20。因此,需要适当地探索有关下游任务的新知识。我们观察到,适配器式调优可能无法充分探索任务特定的知识,因为适配器的输入严格限于旧的/预训练的特征,如图2 ©所示。无论预训练的特征是否适合任务,适配器的结果都只依赖于它们,这使得适配器式调优对于学习新知识的灵活性有限。
解决办法
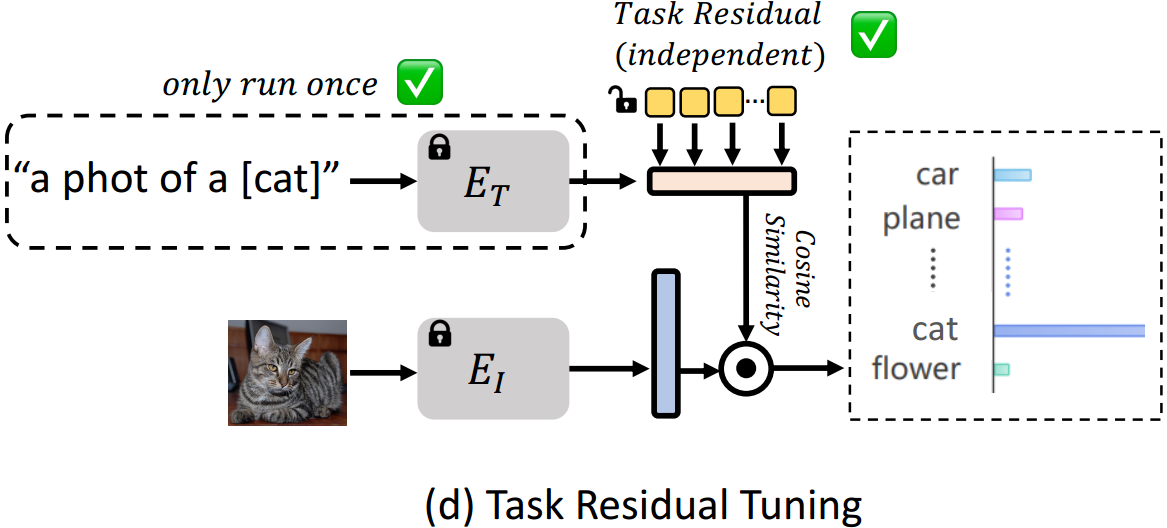
对应每个 K K K分类任务,我们有基本分类器表示为 t ∈ R K × D t\in \mathbb{R}^{K\times D} t∈RK×D。然而,为了在不受先验知识限制的情况下学习特定于任务的知识 ,我们提出了任务残差,它是一组可调参数 x ∈ R K × D x\in \mathbb{R}^{K\times D} x∈RK×D(me:应该就是图中黄色那一块),不依赖于基本分类器。我们的任务残差通过因子 α \alpha α 进行缩放(me:用来控制参数作用的),并将数据地添加到基本分类器中,以形成目标任务的新分类器 t ′ t' t′,写为

摘要
大规模视觉语言模型(VLMs)在数十亿级数据上进行了预训练,学习了一般的视觉表示和广义的视觉概念。原则上,VLMs的良好知识结构在转移到数据有限的下游任务时应该得到适当的继承。然而,大多数针对VLMs的高效迁移学习(ETL)方法要么破坏先验知识,要么过度偏向先验知识,例如,提示调优(PT)丢弃预训练的基于文本的分类器并构建新的分类器,而适配器式调优(AT)完全依赖于预训练的特征。为了解决这个问题,我们提出了一种新的高效的VLMs调优方法,称为任务残差调优(TaskRes),它直接在基于文本的分类器上执行,并显式地将预训练模型的先验知识和关于目标任务的新知识解耦。具体而言,TaskRes将VLMs的原始分类器权重保持不变,并通过调整一组先验无关参数作为原始参数的残差来获得目标任务的新分类器,从而实现可靠的先验知识保存和灵活的任务特定知识探索。提出的TaskRes简单而有效,在11个基准数据集上显著优于以前的ETL方法(例如PT和AT),同时需要最小的实现努力。我们的代码可在https://github.com/geekyutao/TaskRes上获得
1. 介绍
在过去的十年中,基于深度学习的视觉识别模型10,19,31,61,64取得了巨大的成功。这些最先进的模型通常是在大量的图像和离散标签对上进行训练的。离散标签是通过将详细的文本描述(如"American curl cat")转换为简单的标量来生成的,这极大地简化了损失函数的计算。然而,这也导致了两个明显的限制:(i)丰富的语义在文本描述中未充分利用,并且(ii)训练的模型仅限于识别近集类。
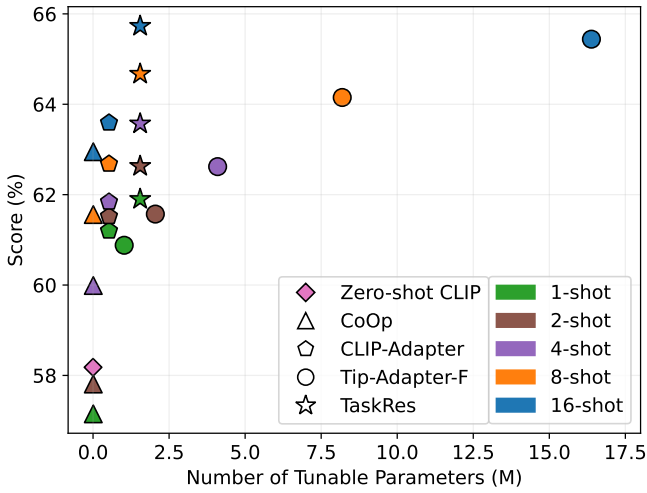
图1所示。Zero-shot CLIP 55, CoOp 79, CLIP- adapter 16, Tip-Adapter-F77和我们在ImageNet上的TaskRes的性能比较。
最近的大规模视觉语言模型(VLM)预训练1,25,36,55,75通过文本监督学习视觉表征消除了这些限制。例如,在预训练期间,文本和图像通过对比损失被编码并映射到一个统一的空间中55。然后,可以使用预训练的文本编码器合成基于文本的图像识别分类器,给出相应的自然语言描述,如图2 (a)所示。这些预训练的VLMs已经证明了在各种下游任务上以零采样的方式具有强大的可移植性。然而,上述模型的有效性在很大程度上依赖于它们的大规模架构和训练数据集。例如,CLIP55拥有多达4.28亿个参数,并在4亿个文本图像对上进行了训练,而Flamingo1拥有多达800亿个参数,并在惊人的21亿对上进行了训练。这使得在低数据状态下对下游任务进行完全微调模型变得不切实际。
因此,基于预训练VLMs的高效迁移学习(ETL)16,77 - 79越来越受欢迎。ETL代表了向下游任务的迁移学习参数和数据高效的方式。ETL的核心有两个方面:(1)适当地继承VLMs良好的知识结构,这种知识结构已经具有可转移性;(ii)在有限的数据下有效地探索特定任务的知识。然而,大多数现有的ETL方法,即提示调优(PT)78,79和适配器式调优(AT)16,77,要么破坏VLMs的先验知识,要么以不适当/不充分的方式学习任务的新知识。例如,CoOp79没有使用预先训练好的基于文本的分类器,而是学习一个连续的提示来合成一个全新的分类器,这不可避免地会导致之前知识的丢失。因此,CoOp在ImageNet上进行1-/2-shot学习时的表现比Zero-shot CLIP差1.03%/0.37%(见图1)。相比之下,CLIP- adapter16保留了预训练的分类器,但在学习新任务时过度偏向于先验知识,即将预训练的分类器权重转换为特定于任务的权重,如图2 ©所示。这导致新知识的探索较差,从而降低了图1所示的准确率。
为了更好地在预训练VLMs上进行ETL,我们提出了一种新的高效调优方法,称为任务残差调优(TaskRes),该方法直接在基于文本的分类器上执行,并显式地将预训练模型的旧知识与目标任务的新知识解耦。其基本原理是,解耦使得从VLMs中更好地继承旧知识和更灵活的特定于任务的知识探索,即,在任务独立于旧知识的情况下学习到的知识。具体来说,TaskRes保持原始分类器权重不变,并引入一组与权重无关的先验参数。这些为适应目标任务而调整的附加参数因此被命名为"任务残差"。
为了深入了解TaskRes是如何工作的,我们在11个基准数据集上进行了广泛的实验79,并对学习任务残差进行了系统的调查。实验结果表明,引入任务残差可以显著提高迁移性能。我们可视化了学习任务残差大小与预训练模型迁移到下游任务的难度之间的相关性,并观察到残差大小随着迁移难度的增加而增加。这表明残差自动适应任务以充分探索新知识,从而在11个不同的数据集上实现了新的最先进的性能。此外,值得注意的是,我们的方法在实现上只需要最小的努力,也就是说,技术上只添加一行代码。我们的贡献总结如下:
•我们首次强调了通过ETL从预训练的VLMs到下游任务的适当知识继承的必要性,揭示了现有调优范式的陷阱,并进行了深入的分析,以表明解耦旧的预训练知识和新的任务特定知识是关键。
•我们提出了一种新的高效调优方法,即任务残差调优(TaskRes),该方法可以更好地继承VLMs的旧知识,并实现更灵活的任务特定知识探索。
•TaskRes使用方便,它需要一些调优参数就可轻松实现。
2. 相关工作
2.1. 视觉语言模型
我们主要回顾了关于语言驱动视觉表征学习(LDVRL)的视觉语言模型(VLMs)的文献2,9,12,15,18,27,32,34,55,58,62。LDVRL的核心是将文本(语言)和图像映射到一个公共空间中,以便文本表示可以用于视觉分类。为此,需要分别对文本和图像使用两个编码器,并使用特定的损失函数作为正则化。
早期的研究探索了无监督预训练模型62或用于文本嵌入的skip-gram文本建模15,50,51,而用于视觉编码的稀疏编码和矢量量化7,62或Classeme特征12,66。对于训练目标,采用MSE62、自监督主题概率匹配18或多类逻辑损失。然而,这些方法仅限于小数据集9,27,34和弱代表性编码骨干7,62,这极大地阻碍了它们的可移植性。
相比之下,最近的研究25,39,55通过利用来自互联网和超级强大的神经网络(例如变形金刚10,67,68,74,76)的图像-文本对的十亿级数据进行表示学习,从而改进了先前的研究。通过端到端具有对比损失的预训练,大规模VLMs以零样本评估的方式在各种下游任务上表现出显著的可转移性。基于大规模视觉语言预训练强大的迁移能力,我们进一步探索其在高效迁移学习中的潜力。
2.2. 高效迁移学习
在大规模数据集(如ImageNet8和WebImageText55)上预训练神经网络,然后在下游任务上对其进行微调,这是迁移学习的常见步骤40 - 42,71 - 73。在这里,我们主要关注预训练VLMs上的高效迁移学习(ETL)。ETL代表参数高效和数据高效的迁移学习,其中少量参数被调优,少量数据被利用。现有的关于ETL的工作可以分为两类:提示调优46,78,79和适配器式调优(AT)16,77。具体而言,首先探索提示工程26,60,为下游任务生成适当的离散提示。随后,学习能够更好地适应新任务的连续提示45,79,表现出更高级的性能。然而,这些方法面临两个问题:(1)需要预先训练好的文本编码器参与整个训练过程,限制了其可扩展性,增加了计算开销;(2)放弃预先训练好的基于文本的分类器而生成新的分类器,导致VLMs的先验知识丢失。
基于AT的方法16,77通过使用一次文本编码器生成基于文本的分类器,然后专注于仅适应文本/图像特征来解决上述问题。这种简单的设计可以获得更好的性能,但它严重依赖于先验知识/预训练的特征,导致新知识的探索效果较差。为了解决这个问题,我们提出了一种新的高效调优方法,任务残差调优(TaskRes),通过先验无关的"任务残差"进行更好、更灵活的任务特定知识学习。
2.3. 少样本学习
少样本学习 (FSL)旨在通过少量标记示例使模型适应新任务/类。传统的FSL方法5,14,17,47,48,59经常对基类的大量数据进行元学习以获得自适应能力。然而,对基础数据集的学习需求限制了它们的可扩展性。最近的VLM预训练工作25,55提供了一种有效的替代方法,它不需要基本数据集。他们表明,预先训练的模型已经可以在许多下游任务中以零射击的方式取得惊人的表现。ETL16,79可以进一步提高性能。在这项工作中,我们提出了一种新的ETL方法,用于使VLMs适应下游任务,并评估了其在少量任务中的有效性。
3. 知识准备
我们简要介绍了所采用的VLM,即对比语言图像预训练(CLIP)55,并概述了VLM上ETL的两种主流方法,即提示调优和适配器式调优。
3.1. 对比语言-图像预训练
CLIP模型55旨在通过自然语言监督获得视觉表示。它是在4亿个图像-文本对上进行训练的,其中来自图像编码器的图像特征和来自文本编码器的文本特征使用对比学习损失在统一的嵌入空间内对齐,使CLIP能够有效地捕获广泛的视觉概念并学习一般的视觉表示。在测试时,CLIP可以将查询图像分类为 K K K 个可能的类别。这是通过计算从带有投影的图像编码器获得的查询图像嵌入z与通过将文本(例如,"a photo of a {class}")输入到文本分支中获得的文本嵌入 { t i } i = 1 K \{\textbf{t}i\}^K{i=1} {ti}i=1K 之间的余弦相似度来实现的。第 i 类的预测概率表示为

在 s i m ( ⋅ , ⋅ ) sim(\cdot,\cdot) sim(⋅,⋅)表示余弦相似度, τ \tau τ为CLIP的学习温度。
3.2. 回顾以前的调优范式
受到ETL方法在自然语言处理中的成功的启发,例如,提示调优33,38和适配器23,最近的进展(例如,CoOp79和CLIP-Adapter16)将他们的想法借用到VLMs上的ETL。
CoOp首次向VLMs引入了提示调优。而不是使用固定的文本提示上下文,如"a photo of a",CoOp提出使用 M M M 个可学习的上下文向量 { v m } m = 1 M \{\textbf{v}m\}^M{m=1} {vm}m=1M 作为任务特定模板。给文本编码器的提示符变成了 { v 1 , v 2 , ... , v M , c i } \{\textbf{v}_1,\textbf{v}_2,\ldots,\textbf{v}_M,\textbf{c}_i\} {v1,v2,...,vM,ci} ;其中 c i \textbf{c}_i ci 为类 i i i 的嵌入。在整个训练过程中,CoOp保持预训练VLM的参数不变,只调整可学习向量 { v m } m = 1 M \{\textbf{v}m\}^M{m=1} {vm}m=1M。
适配器式调优引入了带有可调参数的附加模块 ϕ ω ( ⋅ ) \phi_{\omega}(\cdot) ϕω(⋅) 到预训练的模型,将预训练的特征 f \textbf{f} f 转换为新的特征 f ′ \textbf{f}' f′。一般来说,适配器式调优可以表示为

其中 α \alpha α 是比例因子。在CLIP-Adapter中,适配器模块 ϕ ω \phi_{\omega} ϕω 由两个线性变换层和它们之间的ReLU激活组成。CLIP- adapter研究了视觉适配器和文本适配器,即分别将适配器模块应用于CLIP的图像和文本分支,并显示它们具有相当的性能。在下游任务的训练期间,适配器样式的方法只调整它们的适配器模块。
4.方法
在本节中,我们首先确定VLMs上现有ETL范例的缺陷。这些缺陷促使我们为VLMs提出一种新的ETL方法,称为任务残差调优(TaskRes)。提出的TaskRes很简单,但可以有效地避免陷阱。
4.1. VLMs上现有ETL范式的缺陷
我们重新思考了从预训练的VLMs中获得的先验知识的使用,以及关于下游任务的新知识的获取。一方面,使用大量数据训练的大规模VLMs学习了广泛的视觉概念,这些概念对于广泛的下游视觉任务是通用的,从而实现了同质化3。在执行转移时,应妥善保存先前的知识。另一方面,尽管在预训练中使用了大量数据,但在下游任务中不可避免地存在领域转移或不确定概念。针对下游任务的新知识应该适当地补充到先前的知识中。然而,现有的ETL范例并没有很好地考虑到上述原则,并且存在以下两个问题。
缺陷1:在提示调优中缺乏对先验知识保存的保证 。虽然预先训练的文本分支模块(如文本编码器和投影)的权重在提示调优范式中被冻结,但原始的良好学习的分类边界或多或少受到破坏。这是因为输入提示的调优最终会得到一个新的边界,如果没有显式的正则化,这个边界可能会忘记旧的知识。因此,提示调优的性能是有限的。例如,在ImageNet上进行1/2shot学习时,CoOp79的性能不如Zero-shot CLIP,如图1所示。
缺陷2:在适配器式调优中,新知识探索的灵活性有限 。下游任务中的数据分布往往偏离预训练分布,一些特定于任务或细粒度的视觉概念/表示可能无法被预训练的VLMs很好地学习,例如,从CLIP55到卫星图像数据集EuroSAT20。因此,需要适当地探索有关下游任务的新知识。我们观察到,适配器式调优可能无法充分探索任务特定的知识,因为适配器的输入严格限于旧的/预训练的特征,如图2 ©所示。无论预训练的特征是否适合任务,适配器的结果都只依赖于它们,这使得适配器式调优对于学习新知识的灵活性有限。
4.2. 任务残留调优
鉴于现有的ETL范例面临上述问题,我们提出任务残差调优(TaskRes)以一种简单的方式解决这些问题。TaskRes显式地将旧知识的维护与预训练的vlm分离开来,并将特定于任务的知识的学习与不过度偏向预训练的特征分离开来。我们在下面详细说明我们的任务。
固定基分类器 。如图2 (d)所示,我们的TaskRes直接在基于文本的分类器(即文本嵌入)上执行调优。基分类器是预先训练的视觉语言模型的文本嵌入,例如CLIP。我们将基本分类器表示为 t ∈ R K × D t\in \mathbb{R}^{K\times D} t∈RK×D,其中 K K K 是类别的数量, D D D 是特征维度。我们保持基本分类器的权重冻结,以显式地防止基本分类器被损坏。
先验无关任务残差 。为了在不受先验知识限制的情况下学习特定于任务的知识,我们提出了任务残差,它是一组可调参数 x ∈ R K × D x\in \mathbb{R}^{K\times D} x∈RK×D,不依赖于基本分类器。我们的任务残差通过因子 α \alpha α 进行缩放,并将元素明智地添加到基本分类器中,以形成目标任务的新分类器 t ′ t' t′,写为
调优下游任务 。在调优过程中,我们只调优先验无关的任务残差,同时保持基分类器(连同图像分支)的固定,从而实现可靠的旧知识保存和灵活的新知识知识的探索。给定一幅图像,CLIP的固定图像分支提取其嵌入向量 z ∈ R D z\in \mathbb{R}^{ D} z∈RD,然后计算 i i i 类的预测概率为
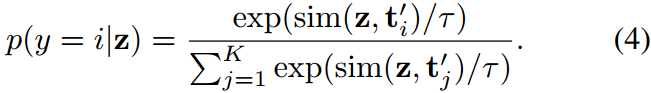
基于预测概率,下游任务损失(如交叉熵损失)仅通过标准反向传播更新任务残差。
5. 实验
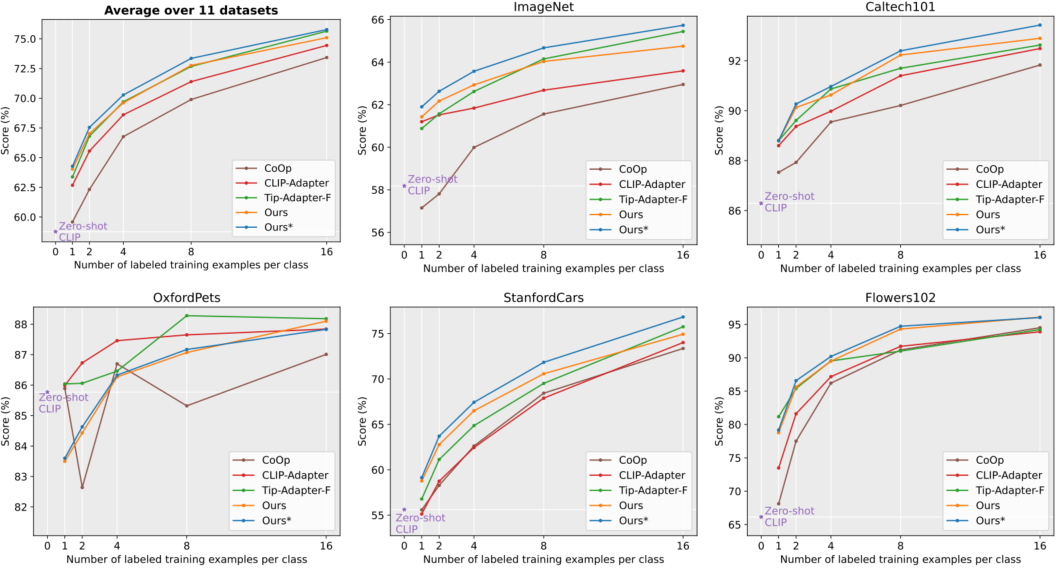
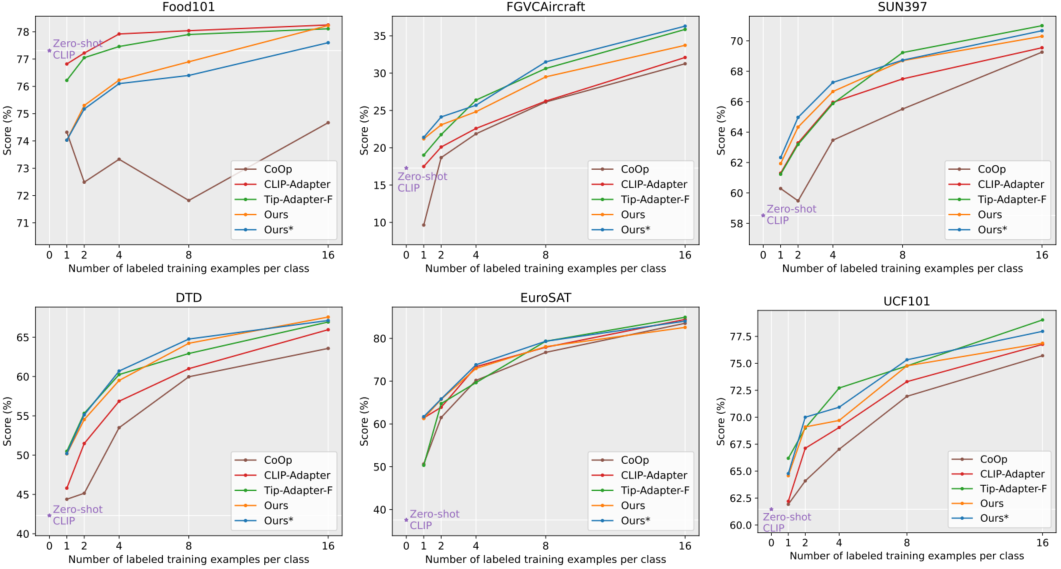
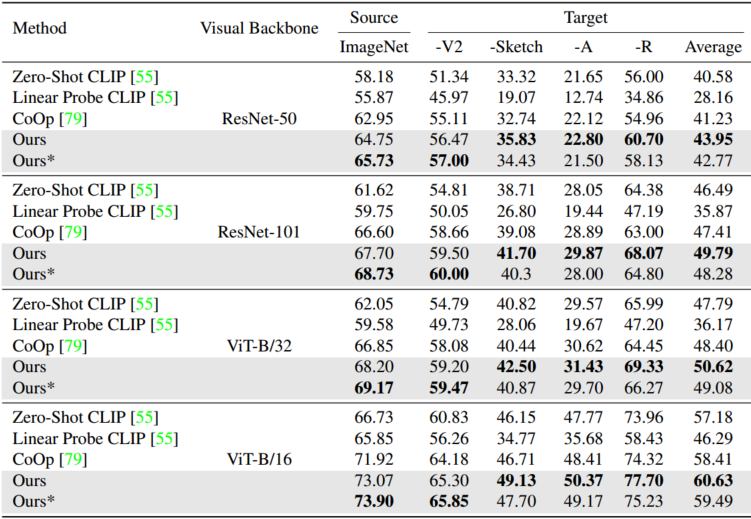
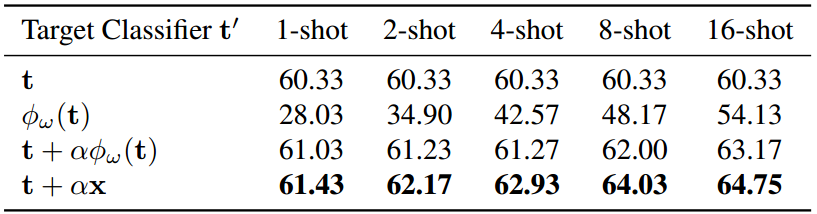
表2。消融研究了三个主要组成部分的各种组合:基础分类器 t t t、适配器模块 ϕ ω ( ⋅ ) \phi_{\omega}(\cdot) ϕω(⋅) 和我们的"任务残差" x x x,用于构建目标分类器 t ′ t' t′。实验在ImageNet上进行。
6. 结论、局限性及未来工作
在这项工作中,我们提出了一种调优VLMs的新方法,即TaskRes。提出的TaskRes通过显式地将分类器解耦为两个关键部分,在VLMs上执行有效的迁移学习(ETL):无损基分类器具有丰富的先验知识和独立于基分类器的任务残差,可以更好地探索特定任务的知识。有趣的是,学习任务残差的大小与将预训练的vlm转移到目标下游任务的难度高度相关。这可能会启发社区从一个新的角度来考虑ETL,例如,为ETL建模"任务到任务的转移难度"。大量的实验已经证明了TaskRes的有效性,尽管它很简单。
然而,我们的方法有一些局限性。例如,我们的方法在两个数据集上遇到负迁移,即OxfordPets (1-shot)和Food101 (1-/2-/4-/8shot)。我们推测这种情况发生在两个条件下:(i)下游任务具有较高的相对转移难度,如图4所示;(ii) Zero-shot CLIP已经在它们上达到了相当的精度。此外,本研究的迁移难度评估是启发式的。
随着基础模型的快速发展3,建立精确可靠的指标来评估预训练基础模型向下游任务的转移难度变得越来越重要。需要对转移难度进行全面的研究,包括分布分析35。此外,我们可以将迁移难度扩展到概念层面,并通过探索在特定数据集上训练的CLIP模型来研究性能与视觉概念出现频率之间的相关性,例如在YFCC15M上训练的SLIP5256,65。我们将在今后的工作中对此进行探讨。
参考资料
论文下载(CVPR 2023)
https://arxiv.org/abs/2211.10277
