一、什么是机器学习?
机器学习的核心逻辑可以概括为:
- 针对一个具体任务(如下棋、判断西瓜好坏);
- 用大量 "经验"(历史数据)训练模型;
- 通过评估任务完成效果,让模型不断优化;
- 最终能对新数据(未知情况)做出准确预测。
就像人类通过大量练习学会骑车,机器学习通过数据 "练习" 学会解决问题。
二、机器学习核心术语:看懂数据的 "语言"
要理解机器学习,先得掌握它的 "专业词汇"。我们以 "判断好瓜" 的案例为例,拆解核心术语:
1. 数据集与样本
- 数据集:数据记录的集合。比如 17 条西瓜的记录组成一个 "西瓜数据集"。
- 样本:数据集中的每条记录。比如第 1 条 "青绿、蜷缩、浊响" 的西瓜就是一个样本。
2. 特征(属性)与属性空间
- 特征:描述对象的属性。比如西瓜的 "色泽""根蒂""敲声" 都是特征。
- 属性空间:所有特征组成的 "坐标系"。比如 "色泽(青绿 / 乌黑 / 浅白)+ 根蒂(蜷缩 / 稍蜷 / 硬挺)" 就构成一个 2 维属性空间,每个样本都是这个空间中的一个点。
3. 训练集与测试集
- 训练集:带 "正确答案" 的数据,用于训练模型。比如标注了 "好瓜 = 是 / 否" 的 14 条西瓜记录。
- 测试集:不带答案的数据,用于检验模型效果。比如 3 条未标注 "好瓜" 的西瓜记录,看模型能否猜对。
三、机器学习的三大学习类型
根据数据是否带 "正确答案"(标签),机器学习可分为三大类:
1. 监督学习:
特点 :数据集自带 "正确答案"(标签),模型通过学习 "特征 - 标签" 的对应关系进行预测。
细分类型:
- 分类:输出是离散值(有限选项)。比如 "判断西瓜是好瓜(是 / 否)""识别图片是猫还是狗"。
- 回归:输出是连续值(任意范围)。比如 "预测房价""估算西瓜甜度"。
例子:用带 "好瓜 = 是 / 否" 标签的西瓜数据训练模型,再用新西瓜的特征(色泽、根蒂等)预测它是否为好瓜。
2. 无监督学习:没有 "答案" 的自主探索
特点 :数据集没有标签,模型通过挖掘数据本身的规律(如相似度)自主分组。
核心应用:
- 聚类:将相似样本归为一类。比如自动把西瓜分成 "甜瓜组""甜瓜组",无需提前知道分类标准。
- 关联分析:发现样本间的隐藏关系。比如超市发现 "买尿布的人常买啤酒",从而优化货架摆放。
例子:给 100 个西瓜的特征(不标好坏),模型自动分成 "表皮光滑组""敲声清脆组" 等,帮助发现新规律。
3. 集成学习:"三个臭皮匠,顶个诸葛亮"
特点 :组合多个简单模型(弱学习器),形成一个更强的模型(强学习器)。
原理 :就像多人决策往往比单人判断更准,多个模型的 "投票" 能降低单一模型的误差。
例子:用 3 个不同模型分别判断西瓜好坏,最终按 "少数服从多数" 决定结果,准确率更高。
**注意:**模型准确率要高且各有千秋
四、模型评估与选择:如何判断 "模型好坏"?
训练出模型后,怎么知道它好不好用?这就需要科学的评估方法。
1. 基础评估指标
- 错误率:分类错误的样本占比(错误率 = 错分样本数 / 总样本数)。
- 精度:1 - 错误率,即分类正确的样本占比。
- 残差:回归任务中,预测值与真实值的差距(残差越小,模型越好)。
2. 训练误差与泛化误差
- 训练误差:模型在训练集上的误差(类似学生模拟考成绩)。
- 泛化误差 :模型在新数据(测试集)上的误差(类似高考成绩)。
关键:我们真正关心的是泛化误差 ------ 模型能否 "举一反三"。
3. 欠拟合与过拟合
-
欠拟合 :模型太简单,数据集太复杂。
比如判断西瓜时,只看 "色泽",忽略 "根蒂""敲声",导致很多好瓜被错判。
解决:增加特征、提高模型复杂度(如用更复杂的公式)。 -
过拟合 :模型太复杂,数据集太简单。
比如判断树叶时,错误认为 "有锯齿的才是树叶",导致没有锯齿的树叶被错判。
解决:增加训练数据、简化模型(如删除无关特征)、用正则化限制模型复杂度。
4. 评估方法:如何公平 "测试" 模型?
-
留出法 :将数据集按比例(如 7:3)分为训练集(70%)和测试集(30%),用测试集评估效果。
注意:要保持数据分布一致(如好瓜 / 坏瓜比例不变),避免偏差。
-
交叉验证法 :将数据集分为 k 个互斥子集,每次用 k-1 个子集训练,1 个测试,重复 k 次取平均。
常用 "10 折交叉验证",结果更稳定,是工业界常用方法。
5. 分类任务的核心指标:查准率与查全率
对于分类任务(如 "识别好瓜"),仅用精度不够,需要更细致的指标:
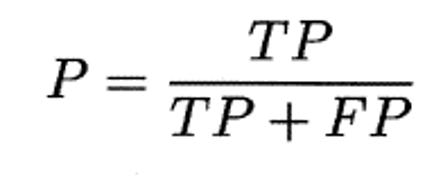
TP(真正例):真实值与预测值都为好瓜。
FP(假正例):真实值为坏瓜,预测值为好瓜。
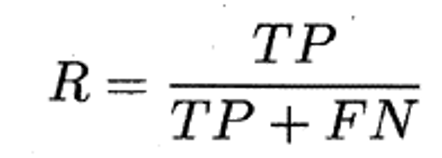
TP(真正例):真实值与预测值都为好瓜。
FN(假反例):真实值为好瓜,预测值为坏瓜。
- 查准率(P):预测为 "好瓜" 的样本中,真正是好瓜的比例(挑出来的瓜里,好瓜占多少)。
- 查全率(R):所有真实好瓜中,被正确预测的比例(所有好瓜里,挑对了多少)。
两者通常 "此消彼长":想多挑好瓜(高查全率),可能会混入坏瓜(低查准率);想挑的全是好瓜(高查准率),可能会漏掉很多好瓜(低查全率)。通过 P-R 曲线可直观对比不同模型的性能。
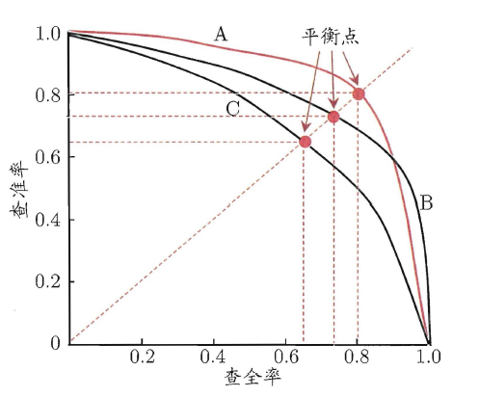
五、机器学习的关键原则
-
奥卡姆剃刀原理:"如无必要,勿增实体"。简单模型能解决问题时,就不用复杂模型。比如用 3 个特征能判断好瓜,就不用 10 个特征。
-
没有免费的午餐定理(NFL):不存在 "万能模型"。一个模型在 A 任务上表现好,可能在 B 任务上很差。选择模型必须结合具体问题,不能盲目跟风 "最先进算法"。
六、总结:机器学习的核心逻辑
机器学习的本质,是让计算机从数据中 "自主发现规律"。从术语到评估,从学习类型到模型选择,核心都是围绕一个目标:用数据训练出能 "举一反三" 的模型。