项目代码:
https://github.com/jiaweizzhao/galore![]() https://github.com/jiaweizzhao/galore
https://github.com/jiaweizzhao/galore
参考博客:
https://zhuanlan.zhihu.com/p/686686751
创建环境
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 8 卡 A800 80GB GPUs
- Python: 3.10 (需要先升级OpenSSL到1.1.1t版本(点击下载OpenSSL),然后再编译安装Python),点击下载Python
- NVIDIA驱动程序
conda create -n GaLore python=3.10
安装依赖包
pip install -r requirements.txt其中,requirements.txt 文件为:
torch==2.1.0
transformers==4.31.0
tokenizers
datasets==2.14.6
peft
wandb
loguru
nvitop
lion-pytorch
matplotlib
bitsandbytes
scipy
scikit-learn
evaluatepip install tensorly
注意:Pytorch 需确保2.1.0以上,不然会报错。

数据集准备
本文使用 C4 数据集进行训练,C4 数据集是由 Google 提供的一个大型预训练数据集,用于训练语言模型。C4 数据集包含了数十亿个网页的内容,经过处理和清洗后形成了一个适合用于训练大型语言模型的数据集。这个数据集可以用于训练各种自然语言处理任务,如文本生成、文本分类
由于数据集太大,这里只下载了一个文件大约356317条数据。
wandb 启用离线模式
启用离线模式后,wandb 将不会上传数据,但仍然会记录实验过程中的数据和结果。
wandb offline
# W&B offline. Running your script from this directory will only write metadata locally. Use wandb disabled to completely turn off W&B.单张 4090 消费级显卡预训练 LLaMA-7B
接下来,使用单个 GPU(例如:NVIDIA RTX 4090)训练 7B 模型,您所需要做的就是指定 --optimizer=galore_adamw8bit_per_layer ,这会启用 GaLoreAdamW8bit 并进行每层权重更新。通过激活(梯度)检查点(activation checkpointing),您可以将在 NVIDIA RTX 4090 上测试的批量大小保持为 16。
执行命令:
CUDA_VISIBLE_DEVICES=3 torchrun --standalone --nproc_per_node 1 torchrun_main.py \
--model_config configs/llama_7b.json \
--lr 0.005 \
--galore_scale 0.25 \
--rank 1024 \
--update_proj_gap 500 \
--batch_size 16 \
--total_batch_size 512 \
--activation_checkpointing \
--num_training_steps 150000 \
--warmup_steps 15000 \
--weight_decay 0 \
--grad_clipping 1.0 \
--dtype bfloat16 \
--eval_every 1000 \
--single_gpu \
--optimizer galore_adamw8bit_per_layerCUDA_VISIBLE_DEVICES=3 torchrun --standalone --nproc_per_node 1 torchrun_main.py --model_config configs/llama_7b.json --lr 0.005 --galore_scale 0.25 --rank 1024 --update_proj_gap 500 --batch_size 16 --total_batch_size 512 --activation_checkpointing --num_training_steps 150000 --warmup_steps 15000 --weight_decay 0 --grad_clipping 1.0 --dtype bfloat16 --eval_every 1000 --single_gpu --optimizer galore_adamw8bit_per_layer
好像是因为连不了外网所以没找到数据集:
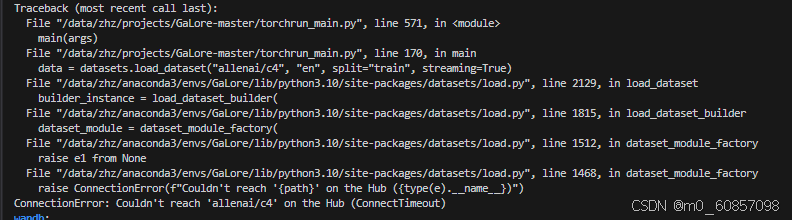
解决方法,手动下载数据集,上传到服务器:


下载地址:https://huggingface.co/datasets/allenai/c4/tree/main/en
同样,模型也要提前下好,放在指定位置:

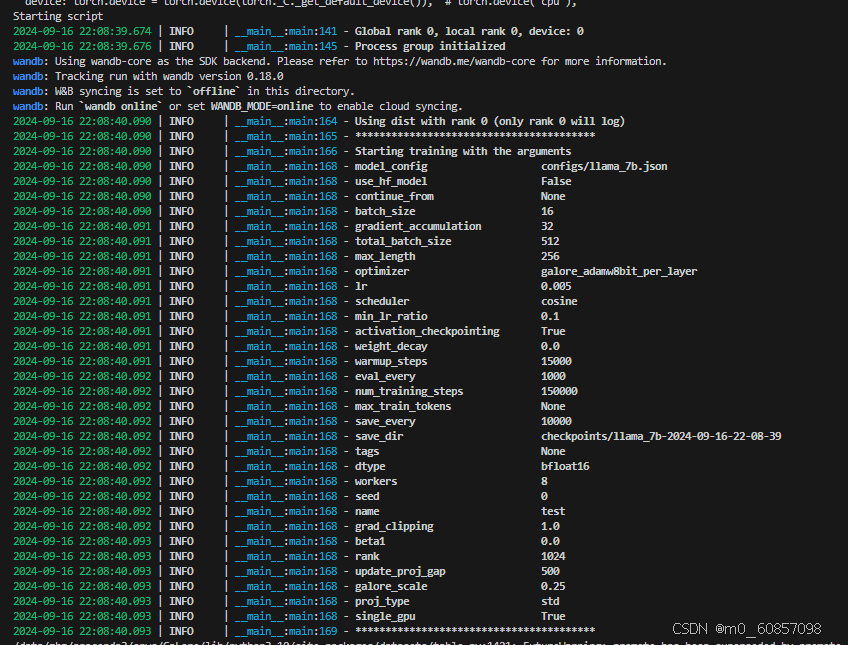
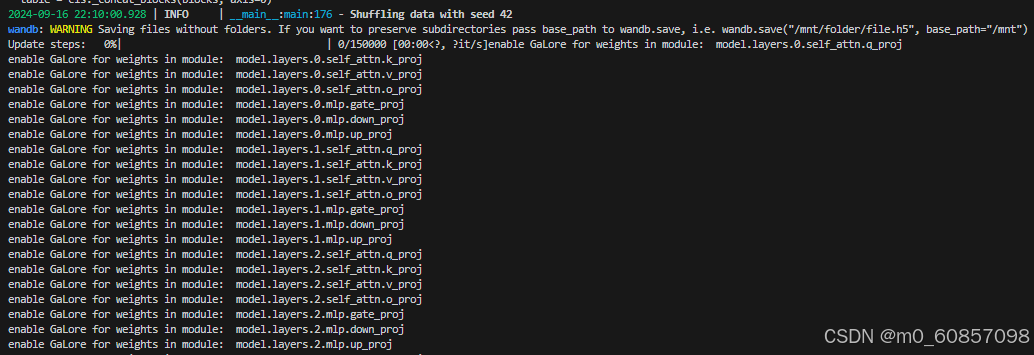
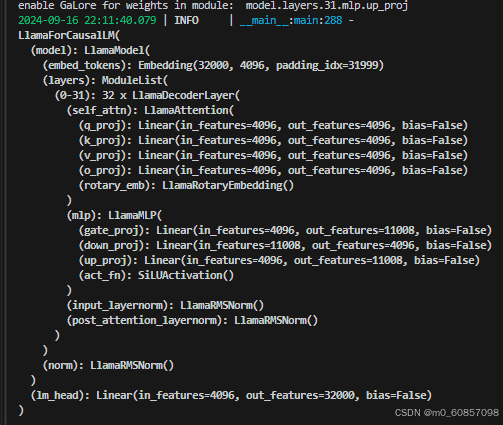


开始训练了,只是比较慢,显存开销在22G的样子: