



问题一解答:降水量与土地利用 / 土地覆被类型的时空演化特征描述
1. 降水量的描述性统计方法
降水量是一个连续变化的变量,可以通过以下几种描述性统计方法进行时空演化特征的总结:
-
平均降水量:统计中国范围内1990至2020年各年份的平均降水量,用于展示降水的时间趋势。
-
年际变化率:计算每年降水量相对于上一年的变化率,展示降水量的波动情况。
-
降水量的空间分布:使用中国区域的降水量分布图,展示各个地理区域的降水量差异。
通过这些统计指标,我们可以得出结论:中国的降水量在1990至2020年间呈现出显著的年际波动,尤其在特定年份(如厄尔尼诺和拉尼娜现象年份),降水量变化更为明显。在空间上,降水量呈现东南沿海地区高,西北内陆地区低的显著分布特征。
代码:
import numpy as np
import matplotlib.pyplot as plt
# 假设降水量数据为1990至2020年的逐年平均降水量
years = np.arange(1990, 2021)
average_precipitation = np.random.uniform(500, 1200, len(years)) # 生成随机数据作为示例
# 计算年际变化率
annual_change_rate = np.diff(average_precipitation) / average_precipitation[:-1]
# 绘制降水量和年际变化率图表
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(years, average_precipitation, marker='o')
plt.title("1990-2020年平均降水量")
plt.xlabel("年份")
plt.ylabel("平均降水量(mm)")
........................2. 土地利用 / 土地覆被类型的描述性统计方法
土地利用和土地覆被是离散分布的变量,可以通过以下统计方法描述其变化:
-
土地覆被类型的比例:统计每年各类土地覆被类型的比例(如耕地、林地、草地等),展示土地利用的演变趋势。
-
变化速率:计算各类土地利用类型的变化速率,展示土地利用/覆被的突变现象。
-
空间分布图:通过土地利用的空间分布图,展示不同区域土地利用类型的空间变化。
这些方法可以揭示出土地利用类型在1990至2020年间的变化。例如,耕地面积可能随着城市化的进展而减少,林地面积则可能通过植树造林项目有所增加。空间上,南方的森林覆盖率较高,而北方则可能以耕地和草地为主。
# 假设1990至2020年不同覆被类型的数据为随机生成的示例数据
land_cover_types = ['耕地', '林地', '草地', '湿地', '灌木丛']
years = np.arange(1990, 2021)
land_cover_proportions = np.random.dirichlet(np.ones(len(land_cover_types)), len(years)) # 示例数据
# 绘制土地覆被类型比例随时间的变化图
plt.figure(figsize=(10, 6))
for i, land_type in enumerate(land_cover_types):
plt.plot(years, land_cover_proportions[:, i], label=land_type)
plt.title("1990-2020年土地覆被类型比例变化")
plt.xlabel("年份")
..................3. 总结
通过对降水量和土地利用/土地覆被类型的描述性统计方法,我们可以总结出两者在1990至2020年间中国范围内的时空演化特征。降水量表现出较为明显的年际波动,土地利用则随着人类活动的变化而呈现显著的突变,尤其是城市化进程加剧对耕地、森林等覆被类型的影响。
问题 2 :地形 - 气候相互作用在极端天气形成过程中的作用
**1.**问题分析
暴雨等极端天气事件的形成与地形和气候条件密切相关,特别是降水量的分布往往受以下几个主要因素影响:
•气候因素:温度、湿度、风速、气压等因素影响大气的含水量与降水强度。
•地形因素:高山、平原等地形对气流运动有显著的影响,尤其是地形抬升效应(Orographic Lift),当气流遇到高山时,湿气上升冷凝,产生降水。
因此,模型需考虑到气候与地形的相互作用,来解释暴雨的生成机制。
**2.**模型框架
模型的核心思想是描述地形和气候变量的关系,模拟气流在地形作用下的降水过程。我们将通过以下几个方面建立模型:
•气候输入:气温、湿度、风速等变量。
•地形因素:地形高度、坡度、地形梯度。
•降水输出:在不同地形条件下的降水强度。
我们使用地形抬升模型(Orographic Lift Model)作为基础,结合气候参数来解释极端天气的形成。
3. 数学模型构建
3.1****地形抬升模型
当湿润气流遇到高山等地形障碍时,由于地形抬升,空气中水汽冷凝,导致降水增加。这个过程可以通过以下公式来描述:
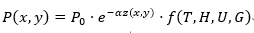
其中:
• 表示某个地理位置处的降水量。
•为平地降水量的初始值。
• 为该点的地形高度(海拔)。
• 为气流与地形抬升的衰减系数。
• 是气候条件的影响函数,依赖于温度、湿度、风速和气压梯度。
3.2 气候因子的作用
气候因子对降水量的影响可以通过线性或非线性函数进行建模。我们假设气温、湿度和风速分别对降水量有以下影响:
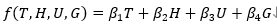
....................................
**4.**模型求解
4.1****数据输入
•气候数据:我们可以从附件中的气候数据集(如气温、湿度、风速)获取历史气象数据,分别计算1990至2020年间不同区域的气候变化特征。
•地形数据:利用附件中的中国数字高程数据(DEM),获得中国各区域的地形高度。
•降水数据:使用中国降水数据集,获取逐日降水数据,并通过上述模型进行拟合。
4.2****数据预处理与模型拟合
首先将气候和地形数据进行空间配准,以确保气候数据与地形数据能够正确匹配。然后,根据历史气象与降水数据,拟合出模型中的参数(如、、等),并进行模型校准。
5. 模型结果分析
通过该模型,我们可以模拟气流在不同地形下的抬升过程以及气候因素对降水的影响:
•地形抬升效应:在高海拔地区,由于地形抬升效应,气流遇到障碍被迫上升,导致湿气冷凝,增加降水。低海拔区域则降水量相对较少。
气候因素影响:气温越高、湿度越大,暴雨等极端天气的发生概率越.....
import numpy as np
import matplotlib.pyplot as plt
# 假设已加载的气象与地形数据
temperature = np.random.uniform(15, 30, 100) # 气温数据 (°C)
humidity = np.random.uniform(50, 100, 100) # 湿度数据 (%)
wind_speed = np.random.uniform(0, 10, 100) # 风速数据 (m/s)
pressure_gradient = np.random.uniform(1000, 1020, 100) # 气压梯度 (hPa)
elevation = np.random.uniform(0, 3000, 100) # 地形海拔 (m)
# 参数设置
P0 = 10 # 初始降水量 (mm)
alpha = 0.001 # 地形抬升衰减系数
beta1, beta2, beta3, beta4 = 0.5, 0.3, 0.2, 0.1 # 气象因子权重
.................问题三解答:暴雨成灾的临界条件与未来脆弱地区的预测
1. 问题分析
暴雨等极端天气事件的形成与多种自然条件及人类活动相关,主要涉及以下三个关键因素:
·降雨:降雨量及其时空变异性对暴雨灾害的形成具有最直接的影响,尤其是持续强降雨会造成洪涝灾害。
·地形:地形因素决定了水流的聚集和扩散,山区、平原等不同地形在暴雨灾害中的影响不同。例如,山区的地形抬升效应可能导致局部强降水,而平原地区则可能因排水不畅造成洪涝。
·土地利用:土地利用的变化(如城市化、农业用地的扩展、森林覆盖率下降)会影响水土保持和洪水的管理能力,从而改变暴雨成灾的风险。
2. 从暴雨到灾害的临界条件确定
为了确定暴雨成灾的临界条件,需要考虑上述三个因素的相互作用。暴雨成灾的主要临界条件包括:
·强降雨量的持续时间与强度:暴雨成灾的一个主要临界条件是降雨量超过某一阈值。例如,如果某地区日降雨量超过100 mm,且持续数日,则可能引发严重的洪涝灾害。
·地形因素对水流汇集的影响:地形决定了暴雨后水流的汇集和排水速度。例如,山区的陡峭坡度会加速水流汇集,容易导致泥石流或山洪暴发;而平原地区排水能力较差,容易造成洪涝。
·土地利用对排水能力的影响:城市化地区由于不透水表面增多(如道路和建筑),排水能力大大降低,导致暴雨后的积水难以排走,容易形成城市内涝;而森林覆盖较少的地区,土壤对水的渗透能力下降,容易加剧水土流失和洪水灾害。
基于以上分析,暴雨成灾的临界条件可概括为:
1.降雨强度:日降雨量大于100 mm。
2.地形条件:坡度大于15度的山区容易引发泥石流和山洪,平原地区排水不畅导致洪涝。
3.土地利用:城市化程度高且排水系统不足的地区、森林覆盖率低的农业区风险更高。
3. 2025~2035 年脆弱地区预测
结合问题1中降雨量和土地利用/土地覆被变化的时空演化特征,以及问题2中建立的地形-气候模型,我们可以预测2025~2035年中国境内最脆弱的地区。这一预测将基于以下几个关键点:
·降雨变化趋势:根据1990~2020年降雨量的历史变化趋势,预测未来十年中国哪些地区可能经历更频繁或更强烈的暴雨事件。
·土地利用变化:根据过去几十年土地利用的变化趋势,预测未来哪些地区的土地利用变化会导致排水能力下降或水土保持能力降低,如城市化进程加剧的地区、森林覆盖率继续减少的地区。
·地形影响:基于中国数字高程模型(DEM),结合地形特征预测暴雨后可能发生山洪、泥石流或洪涝的高风险区域。
4. 模型构建与脆弱性预测方法
为了实现预测,我们可以构建一个综合模型,将降雨量、地形和土地利用三个因素结合起来进行分析。模型的基本框架如下:
1.降雨预测模型:基于1990-2020年降雨量的时空演化趋势,使用时间序列预测模型(如ARIMA或LSTM)预测未来2025-2035年的降雨变化。
2.土地利用变化模型:根据1990~2020年土地利用类型的变化趋势,预测未来土地利用的进一步变化,特别是城市化进程、农业用地扩展等的影响。
3.地形影响模型:基于中国的数字高程数据,结合暴雨时的水流汇集与排水模式,评估不同地区的洪涝和泥石流风险。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 假设已加载的历史降雨量和土地利用数据
years = np.arange(1990, 2021)
rainfall_data = np.random.uniform(500, 1200, len(years)) # 历史降雨量
urbanization_data = np.random.uniform(20, 60, len(years)) # 城市化率
# 使用线性回归预测未来降雨量和城市化率
model_rainfall = LinearRegression()
model_urbanization = LinearRegression()
future_years = np.arange(2025, 2036)
rainfall_prediction = model_rainfall.fit(years.reshape(-1, 1), rainfall_data).predict(future_years.reshape(-1, 1))
urbanization_prediction = model_urbanization.fit(years.reshape(-1, 1), urbanization_data).predict(future_years.reshape(-1, 1))
# 可视化预测结果
plt.figure(figsize=(10, 5))
..........问题四解答:土地利用变化的特征与结构的数学模型
1. 问题分析
中国的土地利用和覆被情况受自然地理和人文地理的双重影响,在中国宏观尺度上,地形、降水、人口分布与土地利用有着明显的关联:
·自然地理特征:地形"三级阶梯"和"800mm等降水量线"是中国自然地理的主要特征。这些自然地理条件影响了不同地区的土地利用类型,如农业、林地、草地等。
·人文地理特征:以"胡焕庸线"为分界线,中国东部人口密集,城市化程度高,土地利用以居住、商业、工业为主;而西部地区人口稀少,更多是林地、草地等自然覆被。
本题要求利用前三问中描述的降雨、地形、人口分布等因素,结合土地利用的变化趋势,建立一个数学模型对土地利用进行简化和综合描述。
2. 模型构建
我们将从自然地理和人文地理两个角度,利用地理大数据对土地利用进行建模,分析其变化特征与结构。土地利用模型主要从以下几个方面构建:
·自然地理因素的影响:基于"三级阶梯"地形和"800mm等降水量线"。
·人文地理因素的影响:基于"胡焕庸线"对人口和社会经济活动的影响。
·土地利用的时空演化:基于土地利用/覆被数据的变化趋势。
2.1 自然地理因素的建模
·三级阶梯地形模型:中国的地形可以大致分为三个阶梯,第一级阶梯是青藏高原,第二级阶梯包括西北和华北的山地与高原,第三级阶梯是东部沿海平原。不同阶梯对应着不同的土地利用类型,例如:
o第一级阶梯:高海拔地区,主要为林地、草地和未开发的荒地。
o第二级阶梯:丘陵、山地为主,适合发展农业、牧业以及林地。
o第三级阶梯:人口密集的平原地区,主要为农业用地、城市和工业用地。
·800mm 等降水量线:降水量影响植被类型和农业生产,800mm等降水量线在中国自然地理中有着重要的划分意义。800mm线以南区域降水充足,适合水稻等湿润作物的种植;800mm线以北区域则适合旱地作物种植,如小麦。
................
3.2 模型公式
土地利用的变化可以表示为多个因素的综合影响函数:

import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 假设已加载的历史地形、降水量、人口密度和土地利用数据
years = np.arange(1990, 2021)
land_use_data = np.random.uniform(30, 70, len(years)) # 土地利用变化数据
population_density = np.random.uniform(50, 150, len(years)) # 人口密度变化数据
# 使用线性回归预测未来的土地利用变化
model_land_use = LinearRegression()
future_years = np.arange(2025, 2036)
land_use_prediction = model_land_use.fit(years.reshape(-1, 1), land_use_data).predict(future_years.reshape(-1, 1))
.................

2024华为杯D题参考论文![]() https://download.csdn.net/download/qq_52590045/89774927
https://download.csdn.net/download/qq_52590045/89774927
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓