一、场景介绍
我们平常会遇到一些需要根据省、市、区查询信息的网站。
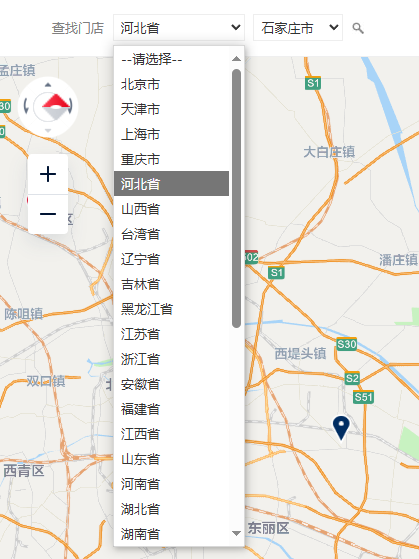
1、省市查询
比如这种,因为全国的省市比较多,手动查询工作量还是不小。
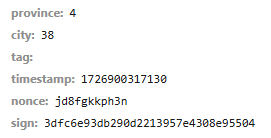
2、接口签名
有时候我们用python直接查询后台接口的话,会发现接口是加签名的。
而签名算法我们是不知道的。
扩展:
nonce("只使用一次的数字"):number once 也就是随机验证码。
timestamp:客户端访问时间戳。
sign:请求参数签名。通过特定算法,将请求参数集合映射为一个字符串,这个字符串就是签名。签名能有效防止请求信息被黑客篡改。
province、city:就是我们前端请求的业务参数。
有了 sign 签名,为什么还需要 timestamp 和 nonce 呢?
timestamp 和 nonce 参数是为了防止重放攻击。
基于 timestamp 方案
每次HTTP请求,都需要加上 timestamp 参数,然后把 timestamp 和其他参数一起进行数字签名。
因为一次正常的HTTP请求,从发出到达服务器一般都不会超过60s,
所以服务器收到HTTP请求之后,首先判断时间戳参数与当前时间相比较,
是否超过了60s,如果超过了则认为是非法的请求。
但这种方式的漏洞也是显而易见的,如果在60s之内进行高饱和重放攻击,那就没办法了,所以这种方式不能保证请求仅一次有效。
基于 nonce 方案
nonce 的意思是仅一次有效的随机字符串,要求每次请求时,该参数要保证不同,所以该参数一般与时间戳有关,方便起见,可以直接使用时间戳的16进制,实际使用时可以加上客户端的ip地址,mac地址等信息做个哈希之后,作为nonce参数。
我们将每次请求的 nonce 参数存储到一个"集合"中,可以 json 格式存储到数据库或缓存中。
每次处理HTTP请求时,首先判断该请求的nonce参数是否在该"集合"中,如果存在则认为是非法请求。
这种方式也有很大的问题,那就是存储 nonce 参数的"集合"会越来越大,验证 nonce 是否存在"集合"中的耗时会越来越长。我们不能让nonce"集合"无限大,所以需要定期清理该"集合",但是一旦该"集合"被清理,我们就无法验证被清理了的nonce参数了。也就是说,假设该"集合"平均1天清理一次的话,我们抓取到的该url,虽然当时无法进行重放攻击,但是我们还是可以每隔一天进行一次重放攻击的。而且存储24小时内,所有请求的"nonce"参数,也是一笔不小的开销。
基于 timestamp 和 nonce 方案
那我们如果同时使用 timestamp 和 nonce 参数呢?
nonce的一次性可以解决 timestamp 参数60s的问题,timestamp 可以解决 nonce 参数"集合"越来越大的问题。
我们在timestamp方案的基础上,加上nonce参数,因为timstamp参数对于超过60s的请求,都认为非法请求,所以我们只需要存储60s的nonce参数的"集合"即可。
结论:
timestamp 和 nonce 和其他参数一起进行数字签名。这样就能防止请求信息被篡改,还能防止重放攻击。
3、Selenium 自动化爬虫
这个时候,就是 python Selenium 自动化爬虫的用武之地了。
它通过分析前端界面元素,模拟用户真实点击的方式,来 请求接口数据。
然后通过分析 界面DOM元素 的方式,来 提取响应数据。
二、环境介绍
- python:3.12.5
- Edge 浏览器驱动:Edge 浏览器驱动官网
- Selenium python 插件
- Charles抓包软件(下文会介绍为什么需要)Charles 安装 可以看这篇博文
三、步骤
1、下载 Edge 浏览器驱动
首先进入 Edge 浏览器驱动官网
选择 beta(公测) 或者 stable(稳定) 版,根据自身操作系统型号,选择 64位或32位下载。
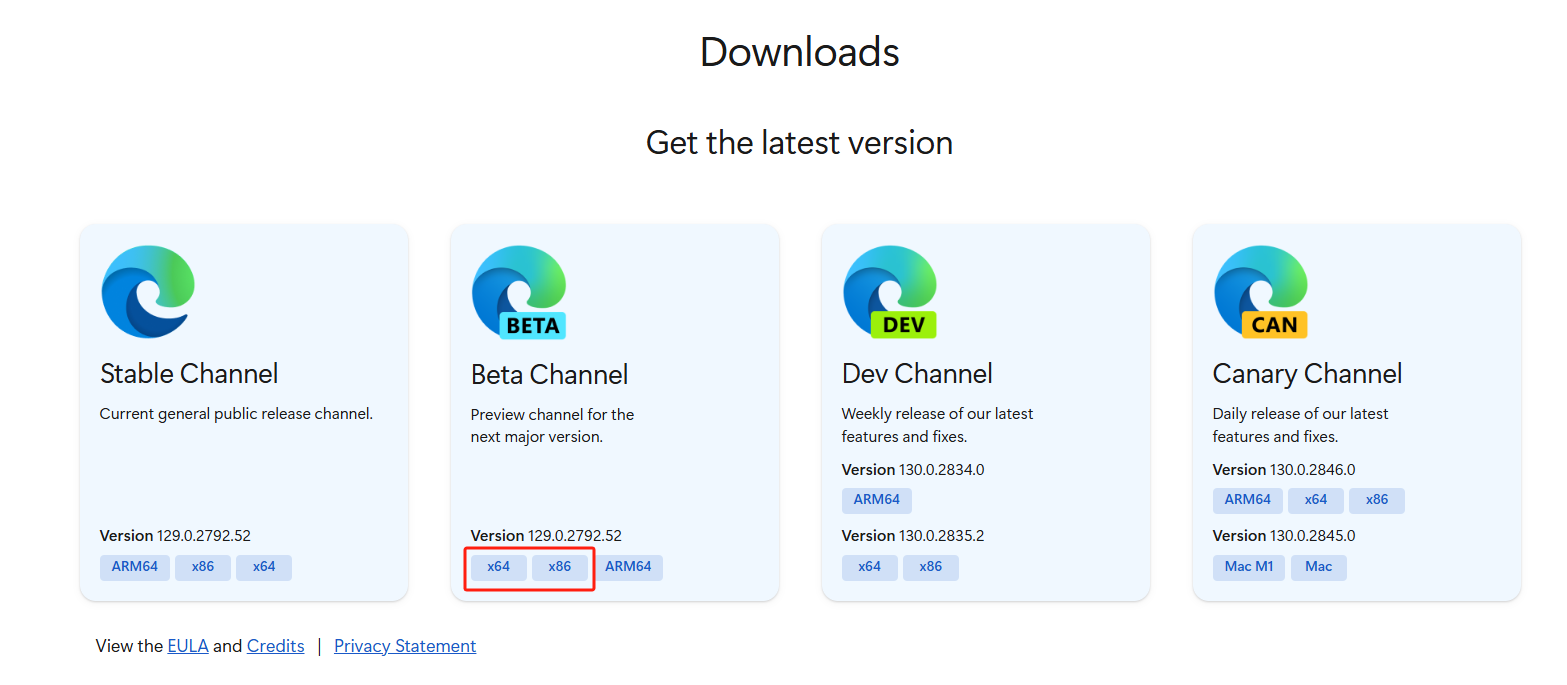
解压到电脑中某个位置备用。

2、安装 Selenium
pip install selenium3、安装 Edge-Selenium 工具
pip install msedge-selenium-tools4、F12 分析前端页面

可以找到 省 的数据。此时,市的数据界面上并没有显示出来。

不过,通过翻看网站的JS资源,我们找到一个 area.js 这个就是全国区域的基础数据。
进一步分析,我们还知道 parentid 还是 省的 id。

5、area.js 数据导入 Excel
把 area.js 数据导入 Excel 通过 JSON数据行转列方式 得到Excel 数据
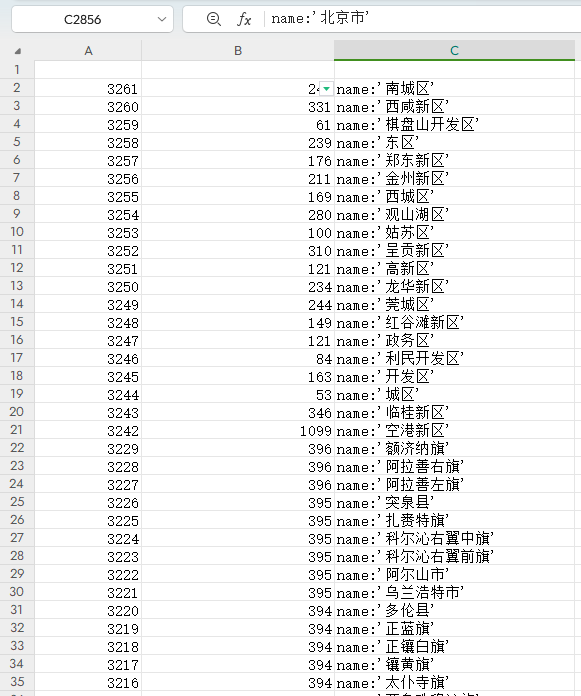
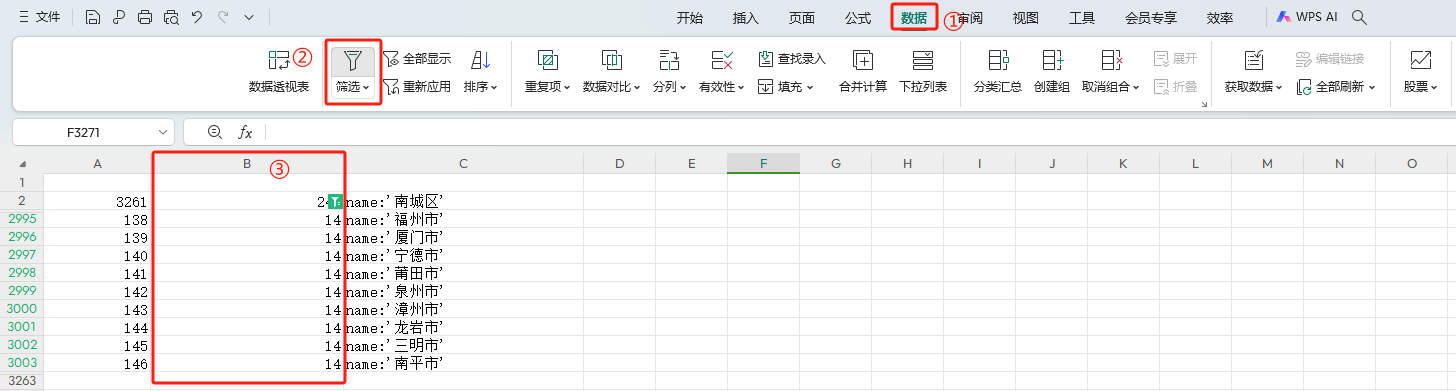
通过 Excel 的数据过滤方式,进一步证实了我们的猜测。
parentid 还是 省的 下拉控件的 value。
福建的 province 14 过滤出福建的 9 个城市。
6、初步思路
这个时候,我们有了一个用 Selenium 自动化请求的初步思路。
用 Selenium 遍历点击 省份控件,接着 级联点击 城市控件,然后点击 查询控件,
最后再用 DOM 方式提取请求响应数据。
7、数据准备
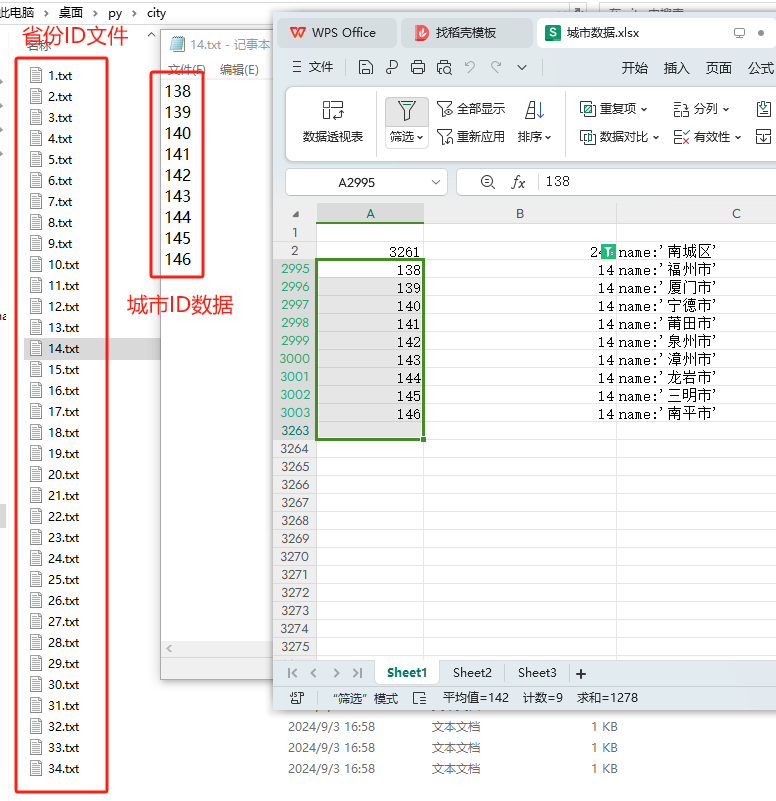
在电脑上,新建一个 city 文件夹,里面存放以 省份ID 命名的文件。
文件里面则是 城市ID,每个 城市ID 占一行。
8、Selenium 方案初版代码
经过上面的数据准备,我们基本可以写出初版的爬虫代码:
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
import time
# 浏览器驱动的存放位置
service = Service(executable_path=r"G:\msedgedriver.exe")
driver = webdriver.Edge(service=service)
driver.get("你的网页")
# 暂停 3 秒 等待网页加载完成
time.sleep(3)
# 找到 省 下拉框元素
province_element = driver.find_element(By.ID, 'province')
# 创建 Select 对象
province_select = Select(province_element)
# 找到 市 下拉框元素
city_element = driver.find_element(By.ID, 'city')
# 创建 Select 对象
city_select = Select(city_element)
# 输入文件
input_path = r"C:\Users\Administrator\Desktop\py\city"
# 输出文件
output_path = r"C:\Users\Administrator\Desktop\py\output.txt"
for province in range(1, 35):
print('-----------省份【' + str(province) + '】开始')
# 选中省份
province_select.select_by_value(str(province))
# 省份文件
file_path = input_path + "\\"+str(province)+'.txt'
with open(file_path, 'r', encoding='utf-8') as input_file:
for line in input_file:
city = line.strip()
print('---------------城市【'+city+'】开始')
# 选中城市
city_select.select_by_value(city)
# 找到 搜索 按钮
submit_element = driver.find_element(By.ID, 'submit')
# 点击搜索
submit_element.click()
# 暂停 2 秒 等待网页加载完成
time.sleep(2)
# 获取无序列表中的所有列表项
li_elements = driver.find_elements(By.TAG_NAME, 'li')
# 提取列表项中的文本内容并打印
for li in li_elements:
# 根据 属性或者 class 过滤掉不是我们想要的数据 li
# 因为一个界面里面,可能不止一个 列表
if None != li.get_attribute("data-index"):
with open(output_path, 'a', encoding='utf-8') as output_file:
output_file.write('\n' + li.text)
print('---------------城市【'+city+'】结束')
print('-----------省份【' + str(province) + '】结束')
# 关闭驱动
driver.quit()爬到的数据因为涉及信息安全问题,就不在这里展示了。
但是这个代码爬取数据,有一个问题,那就是,
有时候,接口响应的数据是完整的,但是,有些数据并没有在界面上展示,Selenium 又是基于 DOM 对界面进行分析的,这部分数据我们就拿不到了,用 python 直接访问这些接口,因为有签名的存在,又没有这个条件。这个时候,Charles 代理就闪亮登场了。
通过将浏览器的网络,指向这个 Charles 代理,Selenium 在前端进行自动化请求的同时,Charles 代理负责对会话进行记录,最后通过分析 Charles 会话数据,就可以获取到我们的接口请求数据了。
处理过程如下:

9、Selenium + Charles 方案
这个时候的爬虫代码,就变简单了,只要无脑点击就好。
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
import time
# 浏览器驱动的存放位置
service = Service(executable_path=r"G:\msedgedriver.exe")
driver = webdriver.Edge(service=service)
driver.get("你的网页")
# 暂停 3 秒 等待网页加载完成
time.sleep(3)
# 找到 省 下拉框元素
province_element = driver.find_element(By.ID, 'province')
# 创建 Select 对象
province_select = Select(province_element)
# 找到 市 下拉框元素
city_element = driver.find_element(By.ID, 'city')
# 创建 Select 对象
city_select = Select(city_element)
# 输入文件
input_path = r"C:\Users\Administrator\Desktop\py\city"
for province in range(1, 35):
print('-----------省份【' + str(province) + '】开始')
# 选中省份
province_select.select_by_value(str(province))
file_path = input_path + "\\"+str(province)+'.txt'
with open(file_path, 'r', encoding='utf-8') as input_file:
for line in input_file:
city = line.strip()
print('---------------城市【'+city+'】开始')
# 选中城市
city_select.select_by_value(city)
# 找到 搜索 按钮
submit_element = driver.find_element(By.ID, 'submit')
# 点击搜索
submit_element.click()
# 暂停 2 秒 等待网页加载完成
time.sleep(2)
print('---------------城市【'+city+'】结束')
print('-----------省份【' + str(province) + '】结束')
# 关闭驱动
driver.quit()10、分析 Charles 会话 JSON
分析 Charles 会话 JSON![]() https://blog.csdn.net/matrixlzp/article/details/142308538?spm=1001.2014.3001.5502
https://blog.csdn.net/matrixlzp/article/details/142308538?spm=1001.2014.3001.5502