文章汇总
发现的现象
动机的描述

Norm增加会导致性能下降,Norm降低会导致性能上升。于是作者提出:
我们需要规范化VLMs中的软提示吗?
实验验证

在左图中的紫色块中可以看到,随着模型性能的上升,Norm value会不断下降。
解决的办法(添加两个损失函数)
总损失如下:

损坏操作介绍
两个损坏操作:REPLACE和RESCALE,它们可用于损坏学习到的软提示向量。
对于REPLACE操作,我们将学习到的单个位置的提示向量替换为具有固定方差的零均值高斯分布向量 。然后,我们可以得到一组损坏的软提示符 t i r e = { v 1 , v 2 , ... , r j , ... , v L , c i } t_i^{re}=\{v_1,v_2,\ldots,r_j,\ldots,v_L,c_i\} tire={v1,v2,...,rj,...,vL,ci},其中第 j j j 个提示向量替换为随机高斯向量 r j ∼ N ( μ 1 , σ 2 I ) r_j\sim \mathcal{N}(\mu\textbf{1},\sigma^2 \bm{\Iota}) rj∼N(μ1,σ2I),其中 1 \textbf{1} 1 表示大小合适的所有提示向量的向量, I \bm{\Iota} I 表示大小合适的单位矩阵, μ \mu μ 表示每个维度的平均值, σ \sigma σ 表示每个维度的标准差。
对于RESCALE操作,我们使用各种重新缩放因子重新缩放第 j j j个提示向量的值 。然后,我们可以得到一组损坏的软提示符 t i s c = { v 1 , v 2 , ... , s × v j , ... , v L , c i } t^{sc}_i=\{v_1,v_2,\ldots,s\times v_j,\ldots,v_L,c_i\} tisc={v1,v2,...,s×vj,...,vL,ci},其中 s < 1 s<1 s<1 是缩放因子。
PUN损失(第一个损失,辅助作用)
对于一组软提示 V L × D = { v 1 , v 2 , ... , v L } \mathbb{V}^{L\times D}=\{v_1,v_2,\ldots,v_L\} VL×D={v1,v2,...,vL},我们可以计算出它们的范数为 1 M ∑ j = 1 L α j ∣ ∣ v j ∣ ∣ p \frac{1}{M}\sum^L_{j=1}\alpha_j{||v_j||}_p M1∑j=1Lαj∣∣vj∣∣p。
对于PUN损失,集合 { α 1 , α 2 , ... , α L } \{\alpha_1,\alpha_2,\ldots,\alpha_L\} {α1,α2,...,αL}设置为相同的值,对所有位置的软提示的规范施加相同的权重。

其中 α j = ω , j = 1 , ... , L \alpha_j=\omega,j=1,\ldots,L αj=ω,j=1,...,L,.其中 ω \omega ω 是控制归一化强度的标度系数。
明显,我们有必要在训练中解决每个提示位置的低规范(Norm)效应,并动态调整 α j \alpha_j αj。
PAN损失(第二个损失,主要作用)
我们对一组软提示 V L × D = { v 1 , v 2 , ... , v L } \mathbb{V}^{L\times D}=\{v_1,v_2,\ldots,v_L\} VL×D={v1,v2,...,vL}进行 N N N次RESCALE操作(乘上一个 < 1 <1 <1的系数),注意,每次损失只损失一次向量,得到混合提示集 V ( N + 1 ) × L × D = { V , V l 1 , V l 2 , ... , V l n , ... , V l N } \mathscr{V}^{(N+1)\times L \times D}=\{\mathbb{V},\mathbb{V}{l_1},\mathbb{V}{l_2},\ldots,\mathbb{V}{l_n},\ldots,\mathbb{V}{l_N}\} V(N+1)×L×D={V,Vl1,Vl2,...,Vln,...,VlN},其中 V \mathbb{V} V为原始提示符,其他为损坏提示符。
PAN损失可以定义为

如果 ∑ b = 1 B 1 ( y ^ b , k = y b ) > ∑ b = 1 B 1 ( y ^ b = y b ) \sum^B_{b=1}{\mathbb{1}(\hat y_{b,k}=y_b)}>\sum^B_{b=1}{\mathbb{1}(\hat y_{b}=y_b)} ∑b=1B1(y^b,k=yb)>∑b=1B1(y^b=yb)(此时发生低Norm现象 ),则 α k = ω \alpha_k=\omega αk=ω,否则为 α k = 0 , k = l 1 , l 2 , ... , l N \alpha_k=0,k=l_1,l_2,\ldots,l_N αk=0,k=l1,l2,...,lN。 y ^ b , k \hat y_{b,k} y^b,k表示对批中第 b b b个样本的预测,使用在第 k k k个位置损坏的软提示符,而 y ^ b \hat y_{b} y^b表示对批中第 b b b个样本的预测,使用原始的,未损坏的软提示符。
me:在这里 ∑ b = 1 B 1 ( y ^ b = y b ) \sum^B_{b=1}{\mathbb{1}(\hat y_{b}=y_b)} ∑b=1B1(y^b=yb)是未损失的软提示 V \mathbb{V} V的正确个数, ∑ b = 1 B 1 ( y ^ b , k = y b ) \sum^B_{b=1}{\mathbb{1}(\hat y_{b,k}=y_b)} ∑b=1B1(y^b,k=yb)是第 k k k次损失后软提示 V l k \mathbb{V}{l_k} Vlk的正确个数, ∑ b = 1 B 1 ( y ^ b , k = y b ) > ∑ b = 1 B 1 ( y ^ b = y b ) \sum^B{b=1}{\mathbb{1}(\hat y_{b,k}=y_b)}>\sum^B_{b=1}{\mathbb{1}(\hat y_{b}=y_b)} ∑b=1B1(y^b,k=yb)>∑b=1B1(y^b=yb)代表这组损失后的软提示 V l k \mathbb{V}{l_k} Vlk的正确个数比未损失的软提示 V \mathbb{V} V 好,此时代表低Norm现象发生,这组损失后的软提示 V l k \mathbb{V}{l_k} Vlk 有必要保留下来,则 α k = ω \alpha_k=\omega αk=ω ;否则, ∑ b = 1 B 1 ( y ^ b , k = y b ) < ∑ b = 1 B 1 ( y ^ b = y b ) \sum^B_{b=1}{\mathbb{1}(\hat y_{b,k}=y_b)}<\sum^B_{b=1}{\mathbb{1}(\hat y_{b}=y_b)} ∑b=1B1(y^b,k=yb)<∑b=1B1(y^b=yb)代表这组损失后的软提示 V l k \mathbb{V}{l_k} Vlk 的正确个数比未损失的软提示 V \mathbb{V} V差,这组损失后的软提示 V l k \mathbb{V}{l_k} Vlk有必要保留下来,则 α k = 0 \alpha_k=0 αk=0。
可以改进的地方
来自节4.7:
较大的 ω \omega ω值通常对于小shot产生更好的性能,而较小的 ω \omega ω值对于大shot则表现良好。这一发现与第2节中提供的损坏实验结果相结合,表明出现频率较高的软提示需要更强的归一化。因此,确定合适的 ω \omega ω尺寸也是未来可能的研究方向之一。
摘要
随着大规模预训练视觉语言模型(VLMs)的流行,如CLIP,软提示调优已成为一种流行的方法,使这些模型适应各种下游任务。然而,很少有作品深入研究可学习软提示向量的固有属性,特别是它们的规范对VLMs性能的影响。这促使我们提出了一个尚未探索的研究问题:"我们需要规范化VLMs中的软提示吗?"为了填补这一研究空白,我们首先通过进行广泛的消融实验发现了一种现象,称为低规范效应,表明减少某些学习提示的规范偶尔会提高vlm的性能,而增加它们通常会降低它。为了利用这种效应,我们提出了一种新的方法,称为归一化视觉语言模型的软提示向量(Nemesis)来归一化VLMs中的软提示向量。据我们所知,我们的工作是第一个系统地研究软提示向量规范在VLMs中的作用,为未来软提示调谐的研究提供有价值的见解。代码可在https://github.com/ShyFoo/Nemesis上获得。
1.引言
在大规模预训练视觉语言模型(VLMs)的时代,如CLIP (Radford等人,2021),Flamingo (Alayrac等人,2022)和BLIP (Li等人,2022),基于软提示的方法,也称为提示调整,已经成为使这些模型适应广泛下游任务的主要方法。例如,Zhou等人(2022b)提出了一种上下文优化(CoOp)方法,在连续的CLIP空间中学习软提示,用于图像分类任务。此外,Rao等人(2022)和Du等人(2022)也分别使用提示调优来解决密集预测和开放词汇对象检测任务。
VLMs领域的最新研究主要集中在通过视觉特征和文本特征的对齐来提高模型性能。例如,在(Lu et al ., 2022)中,估计了输出嵌入的权重分布,而Zang et al .(2022)提出了一种跨多种模式的提示联合优化方法。此外,Chen等人(2023)采用了最优运输技术。为了解释习得的软提示向量,Zhou等人(2022b)和Chen等人(2023)将它们映射到嵌入空间中最近的单词。最近,Oymak等人(2023)深入研究了注意机制在提示调整中的作用,特别是在单层注意网络的背景下。
虽然基于软提示的VLMs技术取得了相当大的进步,但对其内在特性的关注却很少,特别是可学习软提示向量的规范。我们认为软提示的规范是一个重要但被忽视的属性,它显著影响VLMs的性能。本文解决了一个被忽视的方面,并提出了一个研究问题"我们是否需要规范化VLMs中的软提示?"据我们所知,还没有研究这个问题的著作。

(a,左图)顶部:软提示被损坏,Norm增加,导致性能下降;中间:CoOp学习的软提示;下图:损坏的软提示与减少Norm导致增强的性能。
(b,右图)低规范效应在11个数据集中的出现频率。每个不同的颜色或几何形状代表一个不同的数据集。
为了彻底研究软提示向量规范在VLMs性能中的作用,我们引入了两个损坏操作,REPLACE和RESCALE,以改变CoOp学习的向量规范(Zhou et al ., 2022b) 。通过习得的软提示的破坏,出现了一个有趣的现象:在这些提示中特定位置规范的减少提高了性能,而规范的增加通常会导致性能下降,如图1(a)所示。我们将这种先前发现的现象称为低规范效应。
图1(b)探讨了低规范效应在11个广泛使用的提示调优VLMs数据集中的流行程度。值得注意的是,与Flowers102 (Nilsback & Zisserman, 2008)等数据集相比,Imagenet (Deng等人,2009)、OxfordPets (Parkhi等人,2012)和Food101 (Bossard等人,2014)数据集显示出更高的这种效应频率。此外,我们观察到低规范效应的出现频率与shot次数呈负相关,这表明较少的训练数据倾向于诱导该效应。这些差异可能与数据资源有限的软提示方法的潜在退化有关,从而影响模型性能。由于不同数据集的表现不一致,解决低规范效应仍然具有挑战性。
为了利用低范数效应来提高VLMs的性能,我们提出了一种称为归一化视觉语言模型软提示向量的方法(Nemesis)。我们使用位置均匀归一化(PUN)损失来调节所有提示向量的规范。这种方法可以很容易地集成到现有的软提示方法中,计算成本可以忽略不计。然而,PUN丢失可能会降低性能,因为它可能会将不受低规范效应影响的软提示向量归一化。
为了解决这个问题,提出了位置感知归一化(PAN)损耗作为改进的PUN损耗的替代品。具体来说,在每个训练批次之前引入预推理步骤,以识别可能诱发低规范效应的位置。预推理步骤应用损坏操作,在不同位置生成多组损坏的提示,然后根据未损坏的提示对这些损坏的提示进行评估。这允许识别诱发低规范效应的位置,然后对这些位置进行选择性规范化,最终提高性能。大量的实验表明,所提出的Nemesis方法可以帮助提高基于软提示的VLMs在各种任务中的性能。
2.低规范效应
在本节中,我们研究了学习提示向量的规范如何影响VLMs的性能,并确定了低规范效应。为了达到这个目的,我们进行了广泛的消融实验通过改变学习到的提示向量的规范并应用第3.2节中提出的两种损坏操作(即REPLACE和RESCALE)来进行实验。
具体如下(Zhou et al ., 2022b),我们对CoOp模型进行训练,得到长度为 L 的学习提示向量,然后每次在单个位置破坏这些软提示向量,并记录软提示性能和规范的变化。为了减少实验随机性的影响,我们对使用不同种子的五次不同试验的结果进行了平均。实现细节和结果见附录A.2.3。
消融实验揭示了一个有趣的现象:降低特定位置的软提示规范会提高性能,而增加特定位置的软提示规范会降低性能,这种现象被称为低规范效应。这一现象通过揭示提示调谐VLMs中先前未被探索的低规范效应来回应第1节提出的研究问题。这也激发了提出的Nemesis软提示归一化方法。此外,第4.6节为低规范效应的发生提供了一个合理的解释,并提供了对所提出方法有效性的见解。我们相信我们的发现可以为软提示调谐的未来研究提供有价值的见解,为潜在的进步奠定基础。
3.方法
在本节中,我们将介绍提出的Nemesis方法。我们首先回顾了CoOp方法(Zhou等人,2022b),随后介绍了两个关键的损坏操作,REPLACE和RESCALE。最后,我们给出了整个方法。
3.1 对提示调优视觉语言模型的回顾
多年来,预训练的VLMs在零样本开放世界视觉识别中表现出令人印象深刻的泛化性能,其中模型可以在不进行显式训练的情况下执行任务。一个典型的范例是CLIP (Radford等人,2021),它由一个图像编码器和一个文本编码器组成。CLIP在大约4亿个图像-文本对上进行了训练,这使得它的性能非常出色。然而,对于下游任务,有效地微调这些VLMs仍然是一个挑战,特别是在处理少量数据时,由于它们的参数很大。CoOp方法通过将模板化的上下文提示(例如,This is a photo of {class-name})设置为可学习向量来解决这个问题,这只需要在保持预训练VLMs冻结的同时微调这些可学习向量。对于由 C 个类别组成的下游视觉识别任务,可以通过所有类别的视觉特征与文本特征之间的相似度来定义一个图像的分类权重。
形式上,图像编码器和文本编码器可以分别用 f f f 和 g g g表示。给定图像 x x x及其分类标签 y y y,其视觉特征可以表示为 f = f ( x ) f = f(x) f=f(x),而第 i i i类的文本提示可以表示为 t i = { v 1 , v 2 , ... , v L , c i } t_i=\{v_1,v_2,\ldots,v_L,c_i\} ti={v1,v2,...,vL,ci},其中 v j v_j vj和 c i c_i ci分别表示类名的第 j j j个软提示向量和单词嵌入。则第 i i i类文本特征可记为 g i = g ( t i ) g_i = g(t_i) gi=g(ti)。给定少量数据,CoOp可以学习软提示 V L × D = { v 1 , v 2 , ... , v L } \mathbb{V}^{L\times D}=\{v_1,v_2,\ldots,v_L\} VL×D={v1,v2,...,vL},其中 L L L和 D D D分别表示软提示的长度和提示向量的维数,通过最小化图像特征 f f f 与其基真文本特征 g y g_y gy之间的负对数似然来实现

其中 λ \lambda λ为温度参数, s i m ( ⋅ , ⋅ ) sim(\cdot,\cdot) sim(⋅,⋅)为余弦相似函数。在训练过程之后,文本编码器 g g g对学习到的提示 V \mathbb{V} V 和类嵌入进行编码,以生成所有类的文本特征。
3.2 损坏操作
在本节中,我们将介绍两个损坏操作:REPLACE和RESCALE,它们可用于损坏学习到的软提示向量。
对于REPLACE操作,我们将学习到的单个位置的提示向量替换为具有固定方差的零均值高斯分布向量。然后,我们可以得到一组损坏的软提示符 t i r e = { v 1 , v 2 , ... , r j , ... , v L , c i } t_i^{re}=\{v_1,v_2,\ldots,r_j,\ldots,v_L,c_i\} tire={v1,v2,...,rj,...,vL,ci},其中第 j j j个提示向量替换为随机高斯向量 r j ∼ N ( μ 1 , σ 2 I ) r_j\sim \mathcal{N}(\mu\textbf{1},\sigma^2 \bm{\Iota}) rj∼N(μ1,σ2I),其中 1 \textbf{1} 1表示大小合适的所有提示向量的向量, I \bm{\Iota} I表示大小合适的单位矩阵, μ \mu μ表示每个维度的平均值, σ \sigma σ表示每个维度的标准差。
对于RESCALE操作,我们使用各种重新缩放因子重新缩放第 j j j个提示向量的值。然后,我们可以得到一组损坏的软提示符 t i s c = { v 1 , v 2 , ... , s × v j , ... , v L , c i } t^{sc}_i=\{v_1,v_2,\ldots,s\times v_j,\ldots,v_L,c_i\} tisc={v1,v2,...,s×vj,...,vL,ci},其中 s s s是缩放因子。
从本质上讲,这两种损坏操作都可以被视为修改软提示的策略,从而改变其规范。通过改变软提示, g g g 生成的文本特征受到影响,从而影响最终的预测。具体来说,给定损坏的软提示,预测概率可以计算为
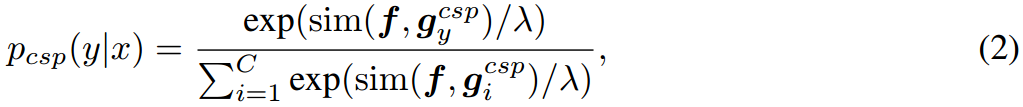
3.3 惩罚的方法
为了处理提示调谐VLMs期间的低范数效应,我们提出了两种对软提示规范进行归一化的损失:位置均匀归一化(PUN)损失和位置感知归一化(PAN)损失。在实验中,它们被分离为单独的正则化项,并添加到标准的软提示调优过程中。
通常,给定一组软提示 V L × D = { v 1 , v 2 , ... , v L } \mathbb{V}^{L\times D}=\{v_1,v_2,\ldots,v_L\} VL×D={v1,v2,...,vL},我们可以计算出它们的范数为 1 M ∑ j = 1 L α j ∣ ∣ v j ∣ ∣ p \frac{1}{M}\sum^L_{j=1}\alpha_j{||v_j||}_p M1∑j=1Lαj∣∣vj∣∣p,其中 M M M 表示集合 { α 1 , α 2 , ... , α L } \{\alpha_1,\alpha_2,\ldots,\alpha_L\} {α1,α2,...,αL}, ∣ ∣ ⋅ ∣ ∣ p {||\cdot||}_p ∣∣⋅∣∣p表示向量的 l p \mathscr{l}_p lp 的范式。除非另有说明,我们默认使用 l 2 \mathscr{l}_2 l2 范数。
对于PUN损失,集合 { α 1 , α 2 , ... , α L } \{\alpha_1,\alpha_2,\ldots,\alpha_L\} {α1,α2,...,αL}设置为相同的值,对所有位置的软提示的规范施加相同的权重。因此,这个损失可以表示为

其中 α j = ω , j = 1 , ... , L \alpha_j=\omega,j=1,\ldots,L αj=ω,j=1,...,L,.其中 ω \omega ω是控制归一化强度的标度系数。然而,在未受低规范效应影响的位置对提示向量进行规范化可能不会产生性能改进。这是因为它可能会限制这些位置的软提示的权重更新。因此,有必要在训练中解决每个提示位置的低规范效应,并动态调整 α j \alpha_j αj。
另一方面,如果能在训练过程中明确认识到低规范效应,就能有效地解决这一问题,提高软提示学习的效果。为了实现这一点,我们在每个批次训练迭代之前合并了一个额外的推理过程,以识别诱导低规范效应的提示位置。
与惩罚实验类似,我们最初设置了一个归一化因子,用 τ \tau τ表示,以诱导低范数效应,其中 τ \tau τ是小于1的正实数。然后我们在一个普通的软提示符 V \mathbb{V} V上应用RESCALE操作,在不同的提示位置 { V l 1 , V l 2 , ... , V l n , ... , V l N } \{\mathbb{V}{l_1},\mathbb{V}{l_2},\ldots,\mathbb{V}{l_n},\ldots,\mathbb{V}{l_N}\} {Vl1,Vl2,...,Vln,...,VlN} ,其中 l n {l_n} ln 表示损坏的位置。注意,对于每个训练批,我们从 L L L 个位置集合中随机选择 N N N 个不同的位置 L = { 1 , ... , L } \mathscr{L}=\{1,\ldots,L\} L={1,...,L}。形式上,位置 1 ≤ l 1 ≠ l 2 ... ≠ l n ... l N ≤ L , N ≤ L 1\le l_1 \ne l_2 \ldots \ne l_n \ldots l_N\le L,N\le L 1≤l1=l2...=ln...lN≤L,N≤L保证每组损坏提示符的重新缩放提示向量的位置是不同的。
通过有一组图像 X \mathscr{X} X ,批大小为 B B B,以及它们的真值标签 Y = ( y 1 , ... , y B ) \mathscr{Y}=(y_1,\ldots,y_B) Y=(y1,...,yB)和混合提示集 V ( N + 1 ) × L × D = { V , V l 1 , V l 2 , ... , V l n , ... , V l N } \mathscr{V}^{(N+1)\times L \times D}=\{\mathbb{V},\mathbb{V}{l_1},\mathbb{V}{l_2},\ldots,\mathbb{V}{l_n},\ldots,\mathbb{V}{l_N}\} V(N+1)×L×D={V,Vl1,Vl2,...,Vln,...,VlN},其中 V \mathbb{V} V为原始提示符,其他为损坏提示符,我们可以得到一组标签预测符: Y ^ ( N + 1 ) × B \hat{\mathscr{Y}}^{(N+1)\times B} Y^(N+1)×B 其中第一行对应于原始提示的批处理预测,接下来的 N N N行表示其损坏对应项的批处理预测。
通过计算所有提示的预测分数并进行比较,我们可以在特定位置识别出损坏的提示,这些提示比原始提示产生更准确的预测。这一观察结果表明低规范效应在训练过程中出现。因此,在这批训练中,只有那些在提示位置诱发低规范效应的软提示将被规范化。因此,PAN损失可以定义为

如果 ∑ b = 1 B 1 ( y ^ b , k = y b ) > ∑ b = 1 B 1 ( y ^ b = y b ) \sum^B_{b=1}{\mathbb{1}(\hat y_{b,k}=y_b)}>\sum^B_{b=1}{\mathbb{1}(\hat y_{b}=y_b)} ∑b=1B1(y^b,k=yb)>∑b=1B1(y^b=yb),则 α k = ω \alpha_k=\omega αk=ω,否则为 α k = 0 , k = l 1 , l 2 , ... , l N \alpha_k=0,k=l_1,l_2,\ldots,l_N αk=0,k=l1,l2,...,lN 。 y ^ b , k \hat y_{b,k} y^b,k 表示对批中第 b b b 个样本的预测,使用在第 k k k 个位置损坏的软提示符,而 y ^ b \hat y_{b} y^b 表示对批中第 b b b 个样本的预测,使用原始的,未损坏的软提示符。采用 L P A N \mathcal{L}_{PAN} LPAN的详细算法见章节A.1。
综上所述,对于一个训练批,我们可以通过最小化以下总目标来优化软提示

其中 β \beta β 等于0或1,对应于所提出的Nemesis方法的两个变体。
4.实验
在本节中,我们进行了大量的实验来评估所提出的Nemesis方法,包括与CoOp (Zhou et al ., 2022b)在少样本图像分类任务和域概化任务上的比较,以及与CoOp (Zhou et al ., 2022a)在base-to-new概化设置上的比较。此外,我们还深入分析了软提示规范对VLM性能的影响,探讨了该方法对其他软提示调优方法的可扩展性,并评估了计算效率。
4.1 数据集
对于小样本图像分类实验和从基到新的概括任务,我们分别遵循CoOp和CoOp的实验设置,在11个视觉分类数据集上进行实验,包括用于物体识别的Caltech101 (Fei-Fei et al ., 2004)和ImageNet (Deng et al ., 2009),用于卫星图像识别的EuroSAT (Helber et al ., 2019),用于纹理识别的DTD (Cimpoi et al ., 2014),用于动作识别的UCF101 (Soomro et al ., 2012),用于动作识别的SUN397 (Xiao et al ., 2012)。场景识别,牛津宠物(Parkhi等人,2012),FGVCAircraft (Maji等人,2013),Food101 (Bossard等人,2014),Flowers102 (Nilsback和Zisserman, 2008)和斯坦福汽车(Krause等人,2013)用于细粒度识别。此外,ImageNet (Deng et al ., 2009)及其变体,包括ImageNet- a (Hendrycks et al ., 2021b)、ImageNet- r (Hendrycks et al ., 2021a)、ImageNetV2 (Recht et al ., 2019)和ImageNet- sketch (Wang et al ., 2019),用于评估领域泛化。每个数据集的详细描述可在附录A.2.1中找到。
4.2 实现细节
对于小样本图像分类实验和领域泛化任务,我们将该方法与基线方法CoOp进行了比较,在base -new泛化任务中选择CoCoOp作为我们的基线模型。遵循CoOp中使用的小样本评估协议,我们从每个类别中使用固定数量的训练样本(即每类1、2、4、8、16个shot)。此外,我们遵循与这些基线模型相同的训练配置,包括训练周期、学习率和批大小等。所有报告的结果都是基于五次不同种子运行的平均值。粗体表示在每个比较设置上的最佳性能。更多的实现细节和超参数设置可以在章节A.2.2中找到。
4.3 小样本图像识别结果

图2:CoOp和CoOp+Nemesis(我们的)在11个数据集上的小样本识别结果
小样本识别的实验结果如图2所示。蓝色,橙色和绿色的线分别代表CoOp, CoOp+Nemesis与PUN损失,和CoOp+Nemesis与PAN损失。就平均性能而言,两种Nemesis方法都优于CoOp。
特别是,他们在ImageNet、OxfordPets、Food101和SUN397数据集上比CoOp取得了很大的改进。这表明,规范化VLMs中的软提示可以在这些数据集上获得更好的性能,这些数据集表现出更明显的低规范效应。以ImageNet数据集为例,在1、2、4、8、16次shot时,具有PUN损失的Nemesis比CoOp的性能提升了2.06%、3.84%、2.6%、1.16%、0.38%。同样,具有PUN损失的Nemesis也显示了0.46%,1.56%,1.74%,0.80%和0.44%的性能改进。此外,很明显,与CoOp相比,CoOp+Nemesis在Food101和OxfordPets上表现出更强的鲁棒性和更优越的性能。此外,将Nemesis与PAN损失进行比较,Nemesis与PAN损失在大shot设置下表现出更强的性能。所有这些性能比较表明,在VLMs中对软提示进行规范化可以促进软提示的有效学习,以进行少样本识别。更详细的训练过程数据和分析见附录A.2.6。
4.4 泛化性能评价
在本节中,我们进行实验来评估所提出方法的泛化性能。所有方法都在ImageNet数据集上进行训练,每个类有16个样本,并在四个不同的基于ImageNet的数据集上进行测试。表1报告了CoOp、CoOp+Nemesis (PUN)和CoOp+Nemesis (PAN)的结果。很明显,无论采用PUN损失还是PAN损失,CoOp+Nemesis在源域和目标域上的表现都一致优于CoOp,这表明Nemesis可以通过规范化VLMs中的软提示来提高CoOp的域泛化能力。
此外,我们可以观察到,使用较大 \\omega 的Nemesis可以获得更好的传输性能,这意味着更强的软提示归一化可以增强软提示对域移位的鲁棒性。对比使用PUN loss的Nemesis和使用PAN loss的Nemesis,尽管后者在源域取得了更好的性能,但其在目标域的性能不如前者。我们认为,这可能是由于PAN丢失过度优先识别和解决域内数据中的低规范效应,这可能会损害其泛化能力。碱基到新实验的结果见附录A.2.4。

表1:CoOp和CoOp+Nemesis (ours)在域泛化设置下的比较。
4.5 VLMS低规范效应的深入研究
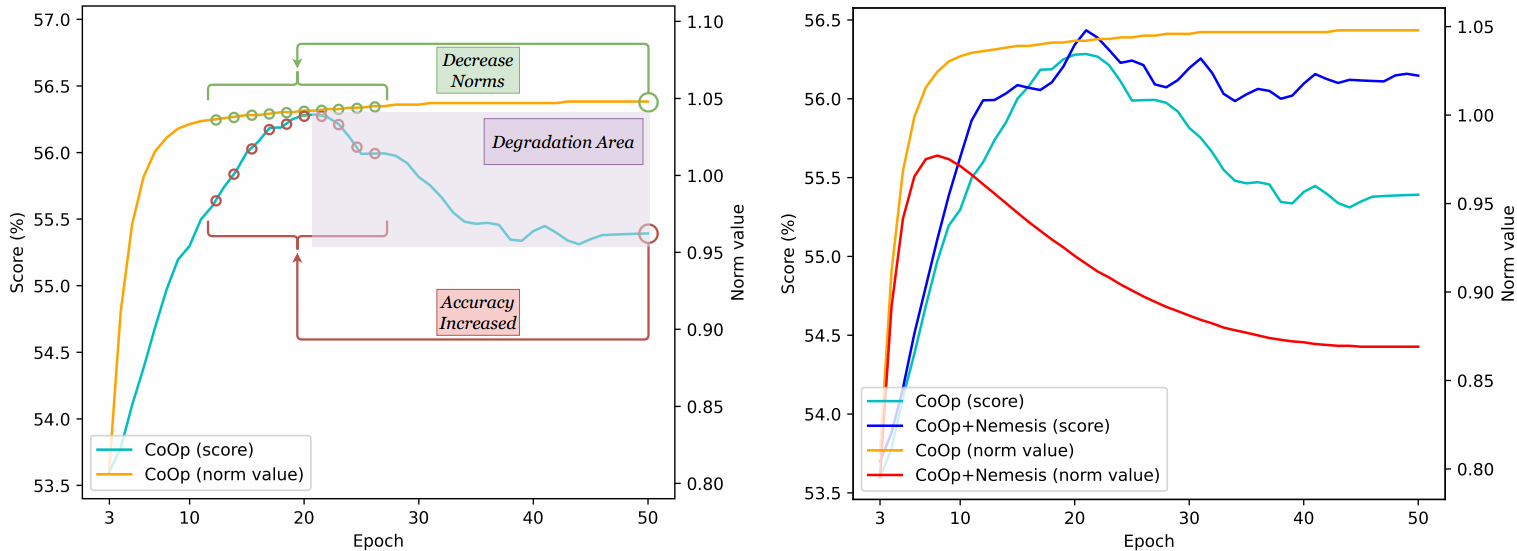
(a,左) CoOp Low-Norm Effect效应的出现。(b,右) CoOp和CoOp+Nemesis(我们的)的比较。
在本节中,我们的目标是为低规范效应的发生和所提出的Nemesis方法的有效性提供合理的解释。
从图3(a)中可以明显看出,CoOp中软提示的规范首先增加,然后趋于平稳,而测试精度则随着规范慢慢趋于平缓而下降。通过执行降低提示向量规范的破坏操作,最后一个绿色圆圈可能会被推离退化区域,并更接近那些表现出优异性能的小绿色圆圈。这可以被看作是对低规范效应发生的合理解释:那些显示出比原始版本更好性能的损坏的软提示可能正是这些小圆圈中的一个。此外,这个数字可能揭示提示学习开始退化的时间与软提示规范开始稳定的时间之间的潜在相关性。我们把这个问题留给未来的研究。
从图3(b)中可以看出,与CoOp中观察到的规范变化模式不同,CoOp+Nemesis(我们的)表现出一个明显的趋势,即规范最初增加,随后下降,最终稳定。此外,测试精度在达到平台之前呈现出一致的上升趋势,而在CoOp中则呈现下降趋势。这意味着我们的方法可以延迟软提示在学习过程中趋于平稳的时间点,从而降低学习退化的概率。
4.6 可扩展性分析
为了分析所提出的Nemesis方法的可扩展性,我们将所提出的Nemesis方法应用到其他软提示调优方法的小镜头识别实验中。PLOT(陈Et al ., 2023)是一种基于集合的提示调优方法,利用最优传输距离实现多组软提示和图像特征之间更好的对齐。在本实验中,我们将 \\omega 默认设置为0.1。表2提供了比较PLOT和PLOT+Nemesis(我们的方法)的部分结果。与PLOT相比,PLOT+Nemesis对所有shot的识别性能都有所提高。这验证了基于集成的提示调优方法也可以从规范化vlm中的软提示中获益。此外,我们还讨论了该方法的其他应用场景。详情见附录A.2.8。

表2:PLOT和PLOT+Nemesis(我们的)在多个数据集上的小样本识别结果。

表3:FGVCAircraft数据集上PAN损失的消融研究。N表示损坏位置的数量,w/o选择表示软提示直接归一化的提示位置,而不需要在PAN损失内进行选择过程。
4.7 消融研究和超参数分析
关于PAN损耗的消融研究结果如表3所示,其中w/o选择类似于利用PUN损耗对N个随机位置的软提示进行归一化,*表示少射识别任务中的默认设置。总的来说,增加N通常会导致性能的提高,除了16次射击的情况,性能最初随着N的增加而增加,然后下降。此外,在不考虑选择过程的情况下,比较PAN损失,根据性能变化选择用于归一化的提示位置显示出更稳健的性能。

表4: \\beta 消融研究
此外,表4提供了两种建议损失的综合结果。我们可以看到, \\beta=0.3 和 和 和 \\beta=0.1 分别在1次shot和16次shot时达到最佳效果。这表明PAN的损失起主导作用,而PUN的损失提供了辅助,可以导致性能的提高。另外,关于这两种损失所带来的计算成本的讨论见附录A.2.7。
此外,归一化损失中使用的 ω , τ \omega,\tau ω,τ和范数类型的超参数分析分别见于表A5、A6和A7。结果数据表明,当使用不同的范数类型和τ值时,提出的Nemesis方法具有弹性。此外,我们观察到较大的 ω \omega ω 值通常对于小shot产生更好的性能,而较小的 ω \omega ω值对于大shot则表现良好。这一发现与第2节中提供的损坏实验结果相结合,表明出现频率较高的软提示需要更强的归一化。因此,确定合适的 ω \omega ω尺寸也是未来可能的研究方向之一。
5.相关工作
5.1 视觉语言模型预训练
视觉语言模型(VLMs)通常由视觉模块和语言模块组成,旨在探索图像和文本之间的语义联系。随着互联网上可获得的大规模图像文本对,越来越多的预训练VLMs (Radford et al, 2021;崔等,2022;Yao et al ., 2021)。这些预训练的VLMs可以通过使用各种视觉语言目标(包括对比目标)捕获深度视觉语言语义对应(Radford et al, 2021;崔等,2022;Singh等人,2022;Yao等,2021;Zhong等人,2022),生成目标(Cui等人,2022;Singh et al, 2022)和对齐目标(Yao et al, 2021;钟等人,2022)。此外,这些预训练的VLMs还显示出强大的泛化能力,可以在广泛的下游任务上执行零样本预测(不需要微调模型),例如图像分类(Radford等人,2021)、视觉问答(Alayrac等人,2022)和文本引导图像生成(Avrahami等人,2022)。
5.2 参数高效微调
参数有效微调(PEFT)方法是适应预训练模型的关键方法,特别是在自然语言处理(NLP)领域。其中,提示调整(Lester et al ., 2021;Jiang et al ., 2023)因优化特定于任务的提示嵌入而受到关注,提供类似于全参数微调的性能,但可调参数较少。类似地,前缀调谐(Li & Liang, 2021)通过优化每个变压器层的前缀序列扩展了这一概念,从而略微增加了可调参数集,而前缀微调(Liu et al, 2022)将人工设计的模式融入输入嵌入中,以分散学习到的提示。受这些NLP的PEFT方法的启发,该技术已成功地扩展到VLMs。例如,CoOp (Zhou et al ., 2022b)及其变体(Zhou et al ., 2022a)将CLIP (Radford et al ., 2021)应用于少样本的视觉识别任务,方法是用可学习的软提示向量取代硬制作的提示。此外,适配器调谐(Gao et al ., 2023)是VLMs的PEFT方法的另一个研究方向,它允许对网络的一部分进行微调或对额外的网络进行微调。值得注意的是,本文提出的Nemesis方法首先提供了经验证据,证明对VLMs的软提示向量进行归一化有助于提高性能。
6 结论
在本文中,我们首次研究了软提示规范对VLMs性能的影响。我们使用两个特别设计的操作进行了广泛的腐败实验,并发现了低规范效应。为了利用这种现象,我们引入了Nemesis,这是一种在软提示调优期间对软提示进行规范化的方法。一般来说,Nemesis可以合并到任何基于软提示的方法中,甚至可以合并到其他PEFT方法中,例如前缀调优和前缀微调。我们希望我们的发现和提出的方法可以为这些领域的未来研究提供新的见解。
参考资料
文章下载(ICLR 2024 Spotlight)
https://openreview.net/pdf?id=zmJDzPh1Dm
