1. 批规范化(Batch Normalization)的好处都有啥?、
A. 让每一层的输入的范围都大致固定
B. 它将权重的归一化平均值和标准差
C. 它是一种非常有效的反向传播(BP)方法
D. 这些均不是
正确答案是:A
解析:
batch normalization 就是对数据做批规范化,使得数据满足均值为0,方差为1的高斯分布。其主要作用是缓解DNN训练中的梯度消失/爆炸现象,加快模型的训练速度。 但是注意是对数据做批规范化,不是对权重。
BN的优点:
- 极大提升了训练速度,收敛过程大大加快;
- 增加了分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout或正则化也能达到相当的效果;
- 简化了调参过程,对于初始化参数权重不太敏感,允许使用较大的学习率
2. 如果我们用了一个过大的学习速率会发生什么?
A. 神经网络会收敛
B. 不好说
C. 都不对
D. 神经网络不会收敛
正确答案是:D
解析:过大,说明不适合,梯度下降时,梯度会来回震荡,神经网络不会收敛。
3. 下图所示的网络用于训练识别字符H和T,如下所示

D. 可能是A或B,取决于神经网络的权重设置
正确答案是:D
解析:不知道神经网络的权重和偏差是什么,则无法判定它将会给出什么样的输出。
4. 增加卷积核的大小对于改进卷积神经网络的效果是必要的吗?
A. 没听说过
B. 是
C. 否
D. 不知道
正确答案是:C
解析:C,增加核函数的大小不一定会提高性能。这个问题在很大程度上取决于数据集。
5. 对于一个分类任务,如果开始时神经网络的权重不是随机赋值的,而是都设成0,下面哪个叙述是正确的?
A 其他选项都不对
B 没啥问题,神经网络会正常开始训练
C 神经网络可以训练,但是所有的神经元最后都会变成识别同样的东西
D 神经网络不会开始训练,因为没有梯度改变
正确答案是:C
解析:
令所有权重都初始化为0这个一个听起来还蛮合理的想法也许是一个我们假设中最好的一个假设了, 但结果是错误的,因为如果神经网络计算出来的输出值都一个样,那么反向传播算法计算出来的梯度值一样,并且参数更新值也一样(w=w−α∗dw)。更一般地说,如果权重初始化为同一个值,网络即使是对称的, 最终所有的神经元最后都会变成识别同样的东西。
6. 下图显示,当开始训练时,误差一直很高,这是因为神经网络在往全局最小值前进之前一直被卡在局部最小值里。为了避免这种情况,我们可以采取下面哪种策略?

A 改变学习速率,比如一开始的几个训练周期不断更改学习速率
B 一开始将学习速率减小10倍,然后用动量项(momentum)
C 增加参数数目,这样神经网络就不会卡在局部最优处
D 其他都不对
正确答案是:A
解析:选项A可以将陷于局部最小值的神经网络提取出来。
7. 对于一个图像识别问题(在一张照片里找出一只猫),下面哪种神经网络可以更好地解决这个问题?
A 循环神经网络
B 感知机
C 多层感知机
D 卷积神经网络
正确答案是:D
解析:卷积神经网络将更好地适用于图像相关问题,因为考虑到图像附近位置变化的固有性质。
8. 假设在训练中我们突然遇到了一个问题,在几次循环之后,误差瞬间降低, 你认为数据有问题,于是你画出了数据并且发现也许是数据的偏度过大造成了这个问题。你打算怎么做来处理这个问题?

A 对数据作归一化
B 对数据取对数变化
C 都不对
D 对数据作主成分分析(PCA)和归一化
正确答案是:D
解析:首先您将相关的数据去掉,然后将其置零。具体来说,误差瞬间降低, 一般原因是多个数据样本有强相关性且突然被拟合命中, 或者含有较大方差数据样本突然被拟合命中. 所以对数据作主成分分析(PCA)和归一化能够改善这个问题。
9. 在下图中,我们可以观察到误差出现了许多小的"涨落"。 这种情况我们应该担心吗?

A 需要,这也许意味着神经网络的学习速率存在问题
B 不需要,只要在训练集和交叉验证集上有累积的下降就可以了
C 不知道
D 不好说
正确答案是:B
解析:选项B是正确的,为了减少这些"起伏",可以尝试增加批尺寸(batch size)。具体来说,在曲线整体趋势为下降时, 为了减少这些"起伏",可以尝试增加批尺寸(batch size)以缩小batch综合梯度方向摆动范围. 当整体曲线趋势为平缓时出现可观的"起伏", 可以尝试降低学习率以进一步收敛. "起伏"不可观时应该提前终止训练以免过拟合
10. 对于神经网络的说法, 下面正确的是 :
增加神经网络层数, 可能会增加测试数据集的分类错误率
减少神经网络层数, 总是能减小测试数据集的分类错误率
增加神经网络层数, 总是能减小训练数据集的分类错误率
A 1
B 1 和 3
C 1 和 2
D 2
正确答案是:A
解析:深度神经网络的成功, 已经证明, 增加神经网络层数, 可以增加模型泛化能力, 即, 训练数据集和测试数据集都表现得更好. 但更多的层数, 也不一定能保证有更好的表现. 所以, 不能绝对地说层数多的好坏, 只能选A
11. 考虑某个具体问题时,你可能只有少量数据来解决这个问题。不过幸运的是你有一个类似问题已经预先训练好的神经网络。可以用下面哪种方法来利用这个预先训练好的网络?
A 把除了最后一层外所有的层都冻结,重新训练最后一层
B 对新数据重新训练整个模型
C 只对最后几层进行调参(fine tune)
D 对每一层模型进行评估,选择其中的少数来用
正确答案是:C
解析:如果有个预先训练好的神经网络, 就相当于网络各参数有个很靠谱的先验代替随机初始化.
- 若新的少量数据来自于先前训练数据(或者先前训练数据量很好地描述了数据分布, 而新数据采样自完全相同的分布), 则冻结前面所有层而重新训练最后一层即可; -> 迁移学习
- 但一般情况下, 新数据分布跟先前训练集分布有所偏差, 所以先验网络不足以完全拟合新数据时, 可以冻结大部分前层网络, 只对最后几层进行训练调参(这也称之为fine tune)。 -> fine tuning
12. 深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m < n < p < q,以下计算顺序效率最高的是()
A. (AB)C
B. AC(B)
C. A(BC)
D. 所以效率都相同
正确答案是:A
解析:
首先,根据简单的矩阵知识,因为 A * B , A 的列数必须和 B 的行数相等。因此,可以排除 B 选项
然后,再看 A 、 C 选项。在 A 选项中,m∗n 的矩阵 A 和n∗p的矩阵 B 的乘积,得到 m∗p的矩阵 A * B ,而 A∗B的每个元素需要 n 次乘法和 n-1 次加法,忽略加法,共需要 m∗n∗p次乘法运算。
同样情况分析 A * B 之后再乘以 C 时的情况,共需要 m∗p∗q次乘法运算
因此, A 选项 (AB)C 需要的乘法次数是 m∗n∗p+m∗p∗q 。
同理分析, C 选项 A (BC) 需要的乘法次数是 n∗p∗q+m∗n∗q。
13. 下列哪个神经网络结构会发生权重共享?
A 卷积神经网络
B 循环神经网络
C 全连接神经网络
D 选项A和B
正确答案是:D
解析:CNN卷积核卷积计算时可以重复用。 RNN序列的每个时间步的参数都是共享的。
14.不属于深度学习开发框架的是?
A、CNTK
B、Keras
C、BAFA
D、MXNet
答案:C
15.不属于深度学习算法的是?
A自编码器
B卷积神经网络
C循环神经网络
D支持向量机
答案:D
16.训练误差会降低模型的准确率,产生欠拟合,此时如何提升模型拟合度?
A、增加数据量
B、特征工程
C、减少正则化参数
D、增加特征
答案:AB
17.关于超参数描述错误的是?
A、超参数是算法开始学习之前设置值的参数
B、大多数机器学习算法都有超参数
C、超参数是不能修改的
D、超参数的值不是通过算法本身学习出来的
答案:C
18. 不属于自动超参数优化算法的是?
A、网格搜索
B、随机梯度下降
C、随机搜索
D、基于模型的超参数优化
答案:C
19.关于循环神经网络(RNN)描述正确的是?
A、可以用于处理序列数据
B、不能处理可变长序列数据
C、不同于卷积神经网络,RNN的参数不能共享。
D、隐藏层上面的unit彼此没有关联
答案:A
20. 训练CNN时,可以对输入进行旋转、平移、缩放等预处理提高模型泛化能力。这么说是对,还是不对?
(对)
解释:
输入进行旋转、平移、缩放等预处理相当于做了数据增强,提升泛化能力
21. 深度学习与机器学习算法之间的区别在于,后者过程中无需进行特征提取工作,也就是说,我们建议在进行深度学习过程之前要首先完成特征提取的工作。这种说法是:
(错)
解释:
机器学习和深度学习都需要特征提取工作
深度学习是直接从数据中自动学习到特征,无需提前人工进行特征提取
22. 假设我们有一个使用ReLU激活函数(ReLU activation function)的神经网络,假如我们把ReLU激活替换为线性激活,那么这个神经网络能够模拟出同或函数(XNOR function)吗?
A、可以
B、不好说
C、不一定
D、不能
( D )
解释:
加入激活函数,模型具有了模拟非线性函数的作用,如果被替换成了线性,那么模型就不能进行其他非线性函数的模拟。
23. 梯度下降算法的正确步骤是什么
a.计算预测值和真实值之间的误差
b.重复迭代,直至得到网络权重的最佳值
c.把输入传入网络,得到输出值
d.用随机值初始化权重和偏差
e.对每一个产生误差的神经元,调整相应的(权重)值以减小误差
A、abcde
B、edcba
C、cbaed
D、dcaeb
( D )
24. 下列哪一项属于特征学习算法(representation learning algorithm)
A、K近邻算法
B、随机森林
C、神经网络
D、都不属于
( C )
解释:
特征学习能够替代手动特征工程,而只有神经网络是自动学习特征
25. caffe中基本的计算单元为
A、blob
B、layer
C、net
D、solver
( B )
解释:
Blob是Caffe的基本存储单元
Layer是Caffe的基本计算单元
26. 阅读以下文字:假设我们拥有一个已完成训练的、用来解决车辆检测问题的深度神经网络模型,训练所用的数据集由汽车和卡车的照片构成,而训练目标是检测出每种车辆的名称(车辆共有10种类型)。现在想要使用这个模型来解决另外一个问题,问题数据集中仅包含一种车(福特野马)而目标变为定位车辆在照片中的位置
A、除去神经网络中的最后一层,冻结所有层然后重新训练
B、对神经网络中的最后几层进行微调,同时将最后一层(分类层)更改为回归层
C、使用新的数据集重新训练模型
D、所有答案均不对
( B )
解释:
一个是分类任务,一个是检测任务
27. 考虑以下问题:假设我们有一个5层的神经网络,这个神经网络在使用一个4GB显存显卡时需要花费3个小时来完成训练。而在测试过程中,单个数据需要花费2秒的时间。 如果我们现在把架构变换一下,当评分是0.2和0.3时,分别在第2层和第4层添加Dropout,那么新架构的测试所用时间会变为多少?
A、少于2s
B、大于2s
C、仍是2s
D、说不准
( C )
解释:
在架构中添加Dropout这一改动仅会影响训练过程,而并不影响测试过程。
Dropout是在训练过程中以一定的概率使神经元失活,即输出为0,以提高模型的泛化能力,减少过拟合。Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。而在测试时,应该用整个训练好的模型,因此不需要dropout。
Batch Normalization(BN),就是在深度神经网络训练过程中使得每一层神经网络的输入保持相近的分布。
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
28. 下列的哪种方法可以用来降低深度学习模型的过拟合问题?
①增加更多的数据
②使用数据扩增技术(data augmentation)
③使用归纳性更好的架构
④ 正规化数据
⑤ 降低架构的复杂度
A、1 4 5
B、1 2 3
C、1 3 4 5
D、所有项目都有用
( D )
解释:
防止过拟合的几种方法:
- 引入正则化
- Dropout
- 提前终止训练
- 增加样本量
29. 如果我们用了一个过大的学习速率会发生什么?
A、神经网络会收敛
B、不好说
C、都不对
D、神经网络不会收敛
( D )
解释:
学习率过小,收敛太慢,学习率过大,震荡不收敛
如果使用自适应优化器,训练到后期学习率是会变小的
30. ResNet-50 有多少个卷积层?
A、48
B、49
C、50
D、51
( B )
31. 如果增加多层感知机(Multilayer Perceptron)的隐藏层 层数,分类误差便会减小。这种陈述正确还是错误?
A、正确
B、错误
( B )
解释:
过拟合可能会导致错误增加
32. 假设你有5个大小为7x7、边界值为0的卷积核,同时卷积神经网络第一层的深度为1。此时如果你向这一层传入一个维度为224x224x3的数据,那么神经网络下一层所接收到的数据维度是多少?
A、218x218x5
B、217x217x8
C、217x217x3
D、220x220x5
( A )
解释:
(W−F+2P)/S + 1
其中W为输入,F为卷积核,P为pading值,S为步长
(224 - 7 + 2 * 0)/ 1 + 1 为218,取218
33. 在CNN网络中,图A经过核为3x3,步长为2的卷积层,ReLU激活函数层,BN层,以及一个步长为2,核为2 * 2的池化层后,再经过一个3 * 3 的的卷积层,步长为1,此时的感受野是
A、10
B、11
C、12
D、13
( D )
解释:
感受野:现在的一个像素对应原来的多少个像素
倒推上一层感受野Ln-1 =( Ln -1)* Sn-1+ Kn-1 ,S 和 K分别是stride(步长)和kernel size(卷积核大小)
卷积层3x3,步长1: 1(1-1)+3=3 * 3;
池化层 2x2,步长2:2(3-1)+2=6 * 6
卷积层3x3,步长2:2(6-1)+3=13 * 13
34. 在训练神经网络时,损失函数(loss)在最初的几个epochs时没有下降,可能的原因是?

A、学习率(learning rate)太低
B、正则参数太高
C、陷入局部最小值
D、以上都有可能
(D)
35.下图是一个利用sigmoid函数作为激活函数的含四个隐藏层的神经网络训练的梯度下降图。这个神经网络遇到了梯度消失的问题。下面哪个叙述是正确的?
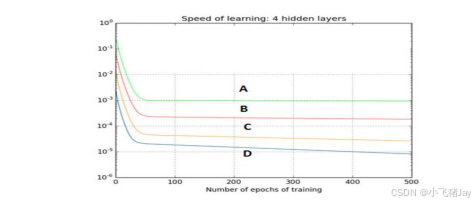
A、第一隐藏层对应D,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应A
B、第一隐藏层对应A,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应D
C、第一隐藏层对应A,第二隐藏层对应B,第三隐藏层对应C,第四隐藏层对应D
D、第一隐藏层对应B,第二隐藏层对应D,第三隐藏层对应C,第四隐藏层对应A
(A)
解释:
由于梯度反向传播,在梯度消失情况下越接近输入层,其梯度越小;在梯度爆炸的情况下越接近输入层,其梯度越大。
损失函数曲线越平,就说明梯度消失越厉害,在前向传播中,越接近输出层,梯度越接近0,所以最先消失的一定是离输出层最近的。
由于反向传播算法进入起始层,学习能力降低,这就是梯度消失。换言之,梯度消失是梯度在前向传播中逐渐减为0, 按照图标题所说, 四条曲线是4个隐藏层的学习曲线, 那么第一层梯度最高(损失函数曲线下降明显), 最后一层梯度几乎为零(损失函数曲线变成平直线). 所以D是第一层, A是最后一层。
36. 当在卷积神经网络中加入池化层(pooling layer)时,变换的不变性会被保留,是吗?
A、不知道
B、看情况
C、是
D、否
( C )
解释:
池化算法比如取最大值/取平均值等, 都是输入数据旋转后结果不变, 所以多层叠加后也有这种不变性。
37. 在一个神经网络中,知道每一个神经元的权重和偏差是最重要的一步。如果知道了神经元准确的权重和偏差,便可以近似任何函数,但怎么获知每个神经的权重和偏移呢?
A、搜索每个可能的权重和偏差组合,直到得到最佳值
B、赋予一个初始值,然后检查跟最佳值的差值,不断迭代调整权重
C、随机赋值,听天由命
D、以上都不正确的
( B )
解释:
深度学习是根据梯度下降优化参数的
38. 深度学习中的激活函数需要具有哪些属性
A、计算简单
B、非线性
C、具有饱和区
D、几乎处处可微
( A B D )
解释:
- 非线性:即导数不是常数
- 几乎处处可微(即仅在有限个点处不可微):保证了在优化中梯度的可计算性
- 计算简单:激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。
- 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。
- 单调性(monotonic):即导数符号不变。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
- 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。
- 接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。
- 参数少:大部分激活函数都是没有参数的。
39. 准确率(查准率)、召回率(查全率)、F值
正确率、召回率和F值是目标的重要评价指标。
- 正确率 = 正确识别的个体总数 / 识别出的个体总数
- 召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
- F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)