问题描述
最近生产有个服务突然出现频繁告警,接口P99响应时间变长,运维同学观察到相应的pod cpu飙升,内存占用很高。
cpu升高问题排查是老生常谈的话题了,一般可以使用top -p pid -H 查看是哪个线程占用cpu高,再结合jstack 找到对应的java线程代码。
不过经验告诉我们,cpu升高还有另外一个更常见的原因,内存不足导致频繁gc。垃圾收集器回收内存后又很快不足,继续回收,循环这个过程,而gc期间涉及到STW,用户线程会被挂起,响应时间自然会增加。这里的内存不足可能是正常的服务本身内存就不够用,也可以是异常的程序bug导致内存溢出。
果不其然,当时节点的full gc时间陡增,通过jstat -gcutil pid 500 30也可以看到fc非常频繁。如图:
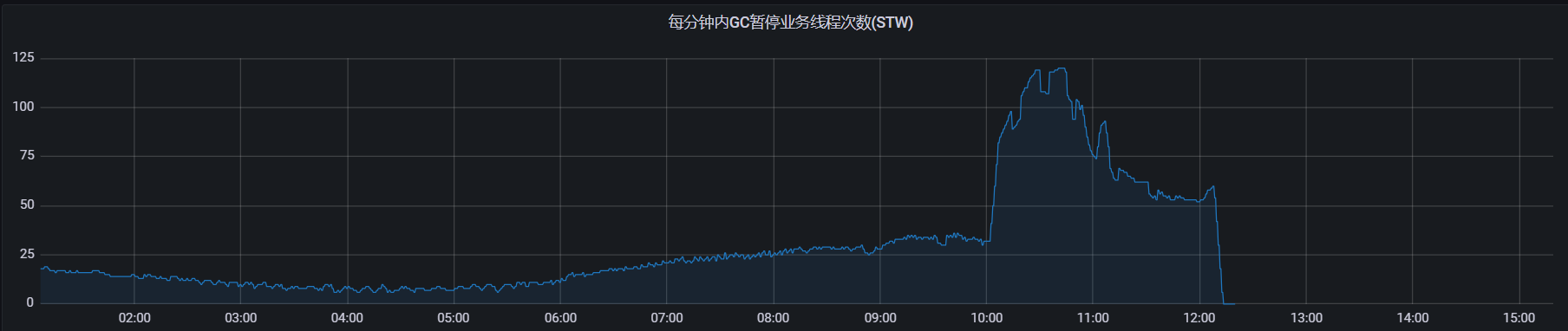
这个问题实际月初也出现过,当时研发同学和运维同学通过重启暂时解决,今天又出现了,看来不是简单通过"重启大法"能解决的,这次我们需要分析解决它。
排查过程
这次我们通过heap dump将堆导出分析,命令:
jmap -dump:format=b,file=./pid.hprof pid用jdk自带的virsualvm 或idea virsualvm launcher插件打开堆文件可以看到
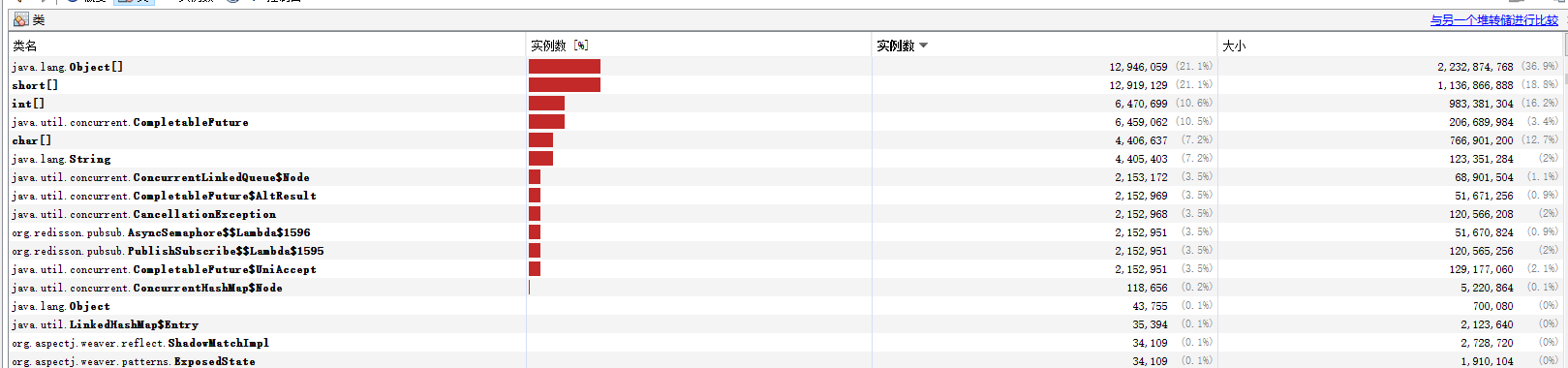
很明显,跟redisson相关,我们使用的版本是3.17.1!查找服务涉及到redisson的地方并不多,调用量高且可疑的只有一处,简化后的代码如下:
RLock lock = this.redissonClient.getLock("mytest");
lock.tryLock(50, 100, TimeUnit.MILLISECONDS);
//业务代码...
RLock lock2 = this.redissonClient.getLock("mytest");
if (lock2.isLocked() && lock2.isHeldByCurrentThread()) {
lock2.unlock();
}首先我们先简单分析下RedissonLock tryLock和unlock的源码,主要地方添加了备注。
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// 获取到锁,返回成功
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - current;
if (time <= 0) {
//或取不到锁,且超过等待时间,返回失败
acquireFailed(waitTime, unit, threadId);
return false;
}
current = System.currentTimeMillis();
//订阅锁释放消息,subscribe是本次的核心!!!
CompletableFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
try {
subscribeFuture.get(time, TimeUnit.MILLISECONDS);
} catch (ExecutionException | TimeoutException e) {
//超时,获取锁失败
if (!subscribeFuture.cancel(false)) {
subscribeFuture.whenComplete((res, ex) -> {
if (ex == null) {
unsubscribe(res, threadId);
}
});
}
acquireFailed(waitTime, unit, threadId);
return false;
}
try {
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
//锁释放了,还未超时,自旋尝试获取
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// 获取到锁,返回成功
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
//或取不到锁,且超过等待时间,返回失败
acquireFailed(waitTime, unit, threadId);
return false;
}
// 等待锁释放
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
//或取不到锁,且超过等待时间,返回失败
acquireFailed(waitTime, unit, threadId);
return false;
}
}
} finally {
//取消订阅
unsubscribe(commandExecutor.getNow(subscribeFuture), threadId);
}
}
@Override
public RFuture<Void> unlockAsync(long threadId) {
RFuture<Boolean> future = unlockInnerAsync(threadId);
CompletionStage<Void> f = future.handle((opStatus, e) -> {
//取消锁续期
cancelExpirationRenewal(threadId);
//...
});
return new CompletableFutureWrapper<>(f);
}
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getRawName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}redisson加解锁主要利用了lua脚本 和redis的发布订阅机制 ,使用到的数据结构是hash 。
lua脚本保证了多个命令执行的原子性,不会有并发问题。
在java代码中使用synchroized/lock加锁失败时,可以将线程放到链表中等待唤醒重新获取锁。在使用redis的分布式系统中,使用的是发布订阅机制,通过订阅channel,当锁释放时重新获取锁。redis的发布订阅跟我们使用kafka等mq中间件是一样的原理,实际也可以用redis的发布订阅机制来实现mq功能,如下channel相当于是mq中的topic。相关命令是:
- PUBLISH channel message,发布一个消息到channel。
- SUBSCRIBE channel channel ...,订阅channel,当channel有消息时,客户端会收到通知。
- UNSUBSCRIBE channel \[channel ...],取消订阅
- PSUBSCRIBE pattern pattern ...,订阅匹配模式的channel
- PUNSUBSCRIBE pattern \[pattern ...],取消订阅匹配模式的channel
接下来是我们的排查过程:
怀疑写法问题
回到我们的代码,首先映入眼帘值得怀疑的是,加锁和解锁使用不是同个对象,如果redisson加解锁是与对象状态相关的,那就会有问题。
但从源码分析可以看到,解锁逻辑非常简单,主要使用到的是线程id,这个是不会变的。当然这种写法还是要修正,除了会给人误导,也没必要多创建一个锁对象。此外持有锁的时间设置为100ms也太短了,尽管业务逻辑处理很快,但如果持有锁期间发生full gc,锁就会过期,其它线程就可以获取到锁,出现并发执行。
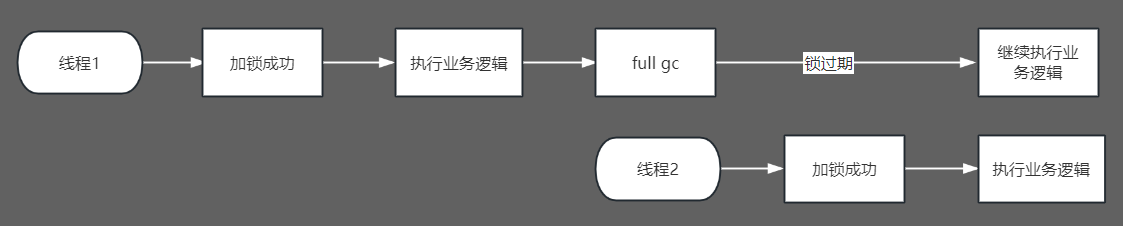
怀疑网络问题
由于不是频繁出现问题,一个月就出现一两次,所以怀疑是不是某些特殊条件才触发,例如当时出现过网络抖动,主从切换等异常情况。联系dba同学得知前一天redis网络确实出现过抖动,结合生产日志发现8月份出现两次问题的前一天都有redis异常,redisson github上也有一些相关讨论,这更坚定了我的推测,在网络异常情况下可能触发某个bug,导致内存溢出,验证这一点也浪费了我们不少时间。

网络问题主要有两种,连接直接断开和读取超时。连接直接断开我们连开发环境的redis很好模拟,直接将内网断开即可。读取超时可以使用redis-cli登录redis server,然后使用client pause命令阻塞客户端,如下会阻塞所有客户端请求10s,这个命令在我平时一些模拟测试也经常用到。
client pause 10000接着写代码循环测试,使用jvirsualvm观察内存对象,发现并没有问题,redisson相关对象占比都很低,且能被gc回收。
for (int i = 0; i < 10000000; i++) {
//贴入前面的代码
}源码分析
前面的源码分析是最外层,最简单的部分,还不足以帮忙我们发现问题。从前面subscribe方法进入,内部还有大量逻辑做并发控制和发布订阅相关逻辑。
进入subscribe,会调用PublishScribe 的subscribe方法,接着会调用AsyncSemaphore的acquire方法获取信号量。jdk的Semaphore我们都很熟悉,AsyncSemaphore是异步的形式,使用信号量最关键的就是申请到许可使用完后,要调用release方法归还,否则其它申请者就无法再次申请到许可。
public CompletableFuture<E> subscribe(String entryName, String channelName) {
AsyncSemaphore semaphore = service.getSemaphore(new ChannelName(channelName));
CompletableFuture<E> newPromise = new CompletableFuture<>();
semaphore.acquire(() -> {
if (newPromise.isDone()) {
semaphore.release();
return;
}
E entry = entries.get(entryName);
if (entry != null) {
entry.acquire();
//1.释放许可
semaphore.release();
//...
return;
}
E oldValue = entries.putIfAbsent(entryName, value);
if (oldValue != null) {
//2.释放许可
semaphore.release();
//...
return;
}
RedisPubSubListener<Object> listener = createListener(channelName, value);
CompletableFuture<PubSubConnectionEntry> s = service.subscribeNoTimeout(LongCodec.INSTANCE, channelName, semaphore, listener);
//...
});
return newPromise;
}AsyncSemaphore主要代码如下,permits是1,listeners是一个无界队列。在我们dump出来的异常实例中有一个AsyncSemaphore lambda对象,也有CompletableFuture lambda对象,看起来和这里高度匹配,这里大概率就是问题所在了,应该是在某种情况下,acquire后没有调用release,导致其它线程调用decrementAndGet的时候是<=0,进而没法执行listeners.poll()移除元素,最终listeners队列元素越来越多,直到内存溢出。
public class AsyncSemaphore {
private final AtomicInteger counter;
private final Queue<CompletableFuture<Void>> listeners = new ConcurrentLinkedQueue<>();
public AsyncSemaphore(int permits) {
counter = new AtomicInteger(permits);
}
public CompletableFuture<Void> acquire() {
CompletableFuture<Void> future = new CompletableFuture<>();
listeners.add(future);
tryRun();
return future;
}
public void acquire(Runnable listener) {
acquire().thenAccept(r -> listener.run());
}
private void tryRun() {
while (true) {
if (counter.decrementAndGet() >= 0) {
CompletableFuture<Void> future = listeners.poll();
if (future == null) {
counter.incrementAndGet();
return;
}
if (future.complete(null)) {
return;
}
}
if (counter.incrementAndGet() <= 0) {
return;
}
}
}
public void release() {
counter.incrementAndGet();
tryRun();
}
}关于Semaphore还有话说,如果一次acquire,但程序异常多次调用release,将导致许可超发,后续的acquire可以申请到许可执行。解决方案可以参考rocketmq SemaphoreReleaseOnlyOnce,它封装了Semaphore,并维护一个AtomicBoolean,保证只能释放一次。
回到上面subscribe方法,有两处正常调用了release,还有一处进入了PublishSubscribeServie 的subscribeNoTimeout(LongCodec.INSTANCE, channelName, semaphore, listener)方法,重点这里传的topicType类型是PubSubType.SUBSCRIBE。
public CompletableFuture<PubSubConnectionEntry> subscribeNoTimeout(Codec codec, String channelName,
AsyncSemaphore semaphore, RedisPubSubListener<?>... listeners) {
CompletableFuture<PubSubConnectionEntry> promise = new CompletableFuture<>();
//重点:PubSubType.SUBSCRIBE
subscribeNoTimeout(codec, new ChannelName(channelName), getEntry(new ChannelName(channelName)), promise,
PubSubType.SUBSCRIBE, semaphore, new AtomicInteger(), listeners);
return promise;
}里面的逻辑比较复杂,有兴趣的同学可以自己分析分析,但我们关注的是每个分支最终都需要调用semaphore.release。
按照这个思路,最终笔者在此处发现一处可能没有调用release的方法:org.redisson.pubsub.PublishSubscribeService#unsubscribe。
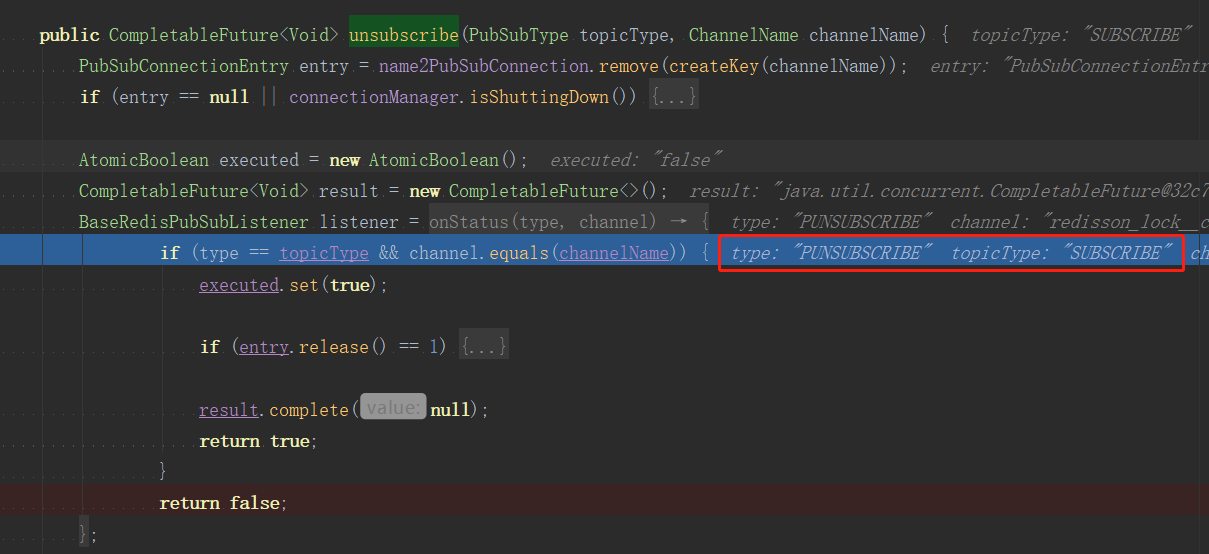
unsubscribe方法在complete的时候会执行lock.release(),它的complete是在BaseRedisPubSubListener回调中调用的,只有if条件成立才会执行。前面我们说传记录的topicType是subscribe,而这里BaseRedisPubSubListener处理的是unsubscribe 和punsubscribe类型,对应不上了,这就导致whenComplete不会执行,lock.release()不会执行。
private CompletableFuture<Void> addListeners(ChannelName channelName, CompletableFuture<PubSubConnectionEntry> promise,
PubSubType type, AsyncSemaphore lock, PubSubConnectionEntry connEntry,
RedisPubSubListener<?>... listeners) {
//...
subscribeFuture.whenComplete((res, e) -> {
if (e != null) {
lock.release();
return;
}
if (!promise.complete(connEntry)) {
if (!connEntry.hasListeners(channelName)) {
unsubscribe(type, channelName)
.whenComplete((r, ex) -> {
//这里不会被执行,AsyncSemaphore release没有执行!
lock.release();
});
} else {
lock.release();
}
} else {
lock.release();
}
});
return subscribeFuture;
}
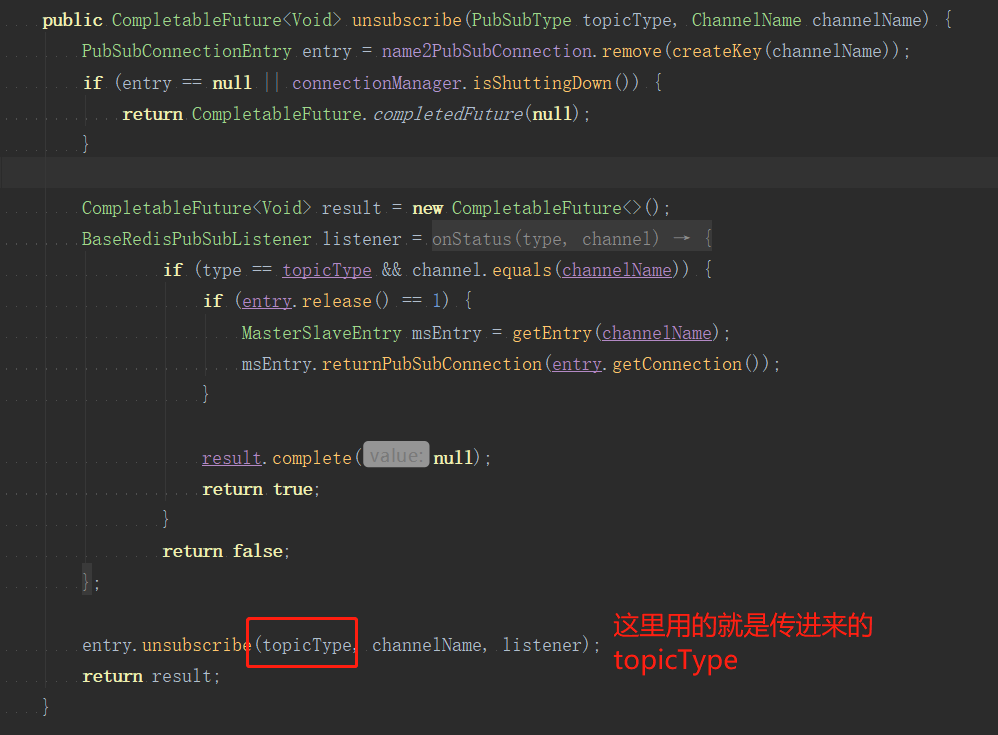
public CompletableFuture<Void> unsubscribe(PubSubType topicType, ChannelName channelName) {
//...
BaseRedisPubSubListener listener = new BaseRedisPubSubListener() {
@Override
public boolean onStatus(PubSubType type, CharSequence channel) {
//这个if不会进入...
if (type == topicType && channel.equals(channelName)) {
executed.set(true);
if (entry.release() == 1) {
MasterSlaveEntry msEntry = getEntry(channelName);
msEntry.returnPubSubConnection(entry.getConnection());
}
//触发外面whenComplete的执行
result.complete(null);
return true;
}
return false;
}
};
ChannelFuture future;
//这里是unsubscribe和punsubscribe,而前面传进来的topicType是subscribe,对不上了
if (topicType == PubSubType.UNSUBSCRIBE) {
future = entry.unsubscribe(channelName, listener);
} else {
future = entry.punsubscribe(channelName, listener);
}
return result;
}问题复现
前面分析得头头是道,我们还得通过实践证明一下,有理有据才行。
我的复现代码如下,通过并发调用加锁,开始运行加个断点在org.redisson.pubsub.PublishSubscribeService#unsubscribe里的BaseRedisPubSubListener的onStatus方法,发现正如前面所说,topicType确实对不上。接着运行一段时间后,打一个断点在AsyncSemaphore.acquire方法,观察到listener属性的size不断增长,通过jmap pid GC.run触发gc后也不会回收,问题得以复现。
public void test() {
for (int i = 0; i < 20000000; i++) {
executor.submit(() -> {
//贴入前面的代码,提交到线程池
});
}
}
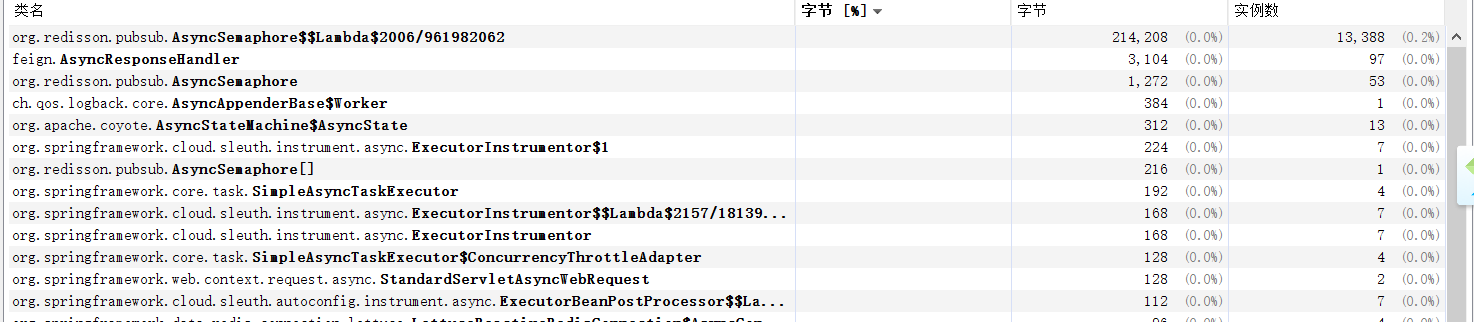
问题解决
在开始排查问题的时候,笔者就在github提issue咨询是什么原因,如何解决。他们的回复是跟这个相关,并推荐升级到3.21.2版本,不过里面提到的描述跟我的不太一样,所以按照版本选择的经验,我决定将版本升级到3.17最后一个小版本3.17.7试一下,重新跑上面的测试代码,跑一段时间后,发现问题没有出现了。
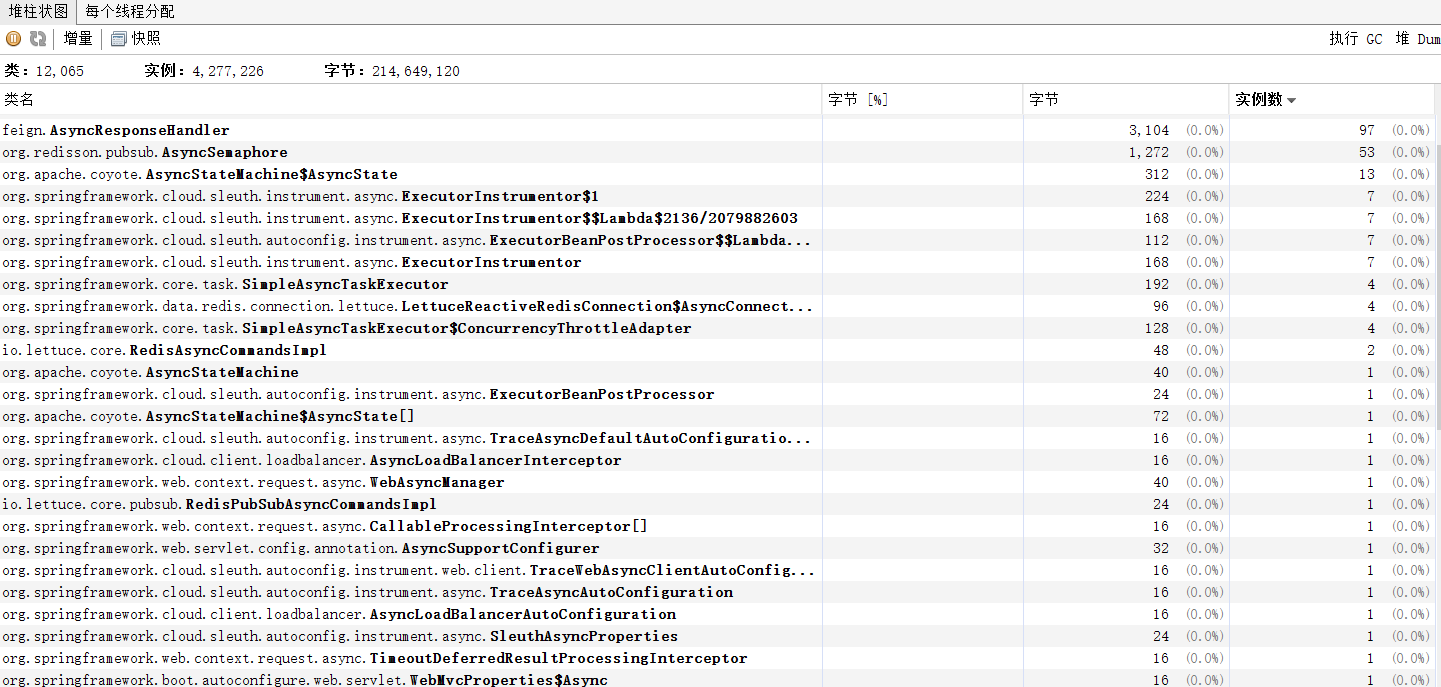
查看org.redisson.pubsub.PublishSubscribeService#unsubscribe源码,发现出问题那段逻辑已经被修复了。
经验总结
遇到难啃问题几乎是每个开发不可避免的事情,解决问题的过程,方法和事后复盘,经验总结非常重要,对个人的学习和能力提升有很大的帮助。
以下几点是我本次的总结:
-
及时止损
当生产出现问题,很多开发同学首先会想如何找到原因,解决根本问题,但实际情况应该是评估影响,及时止损,避免问题发散,扩大影响。
例如不能在短时间内解决的,还要下来慢慢看日志,分析代码的,能回滚的先回滚,能重启的先重启,争取在出现资损前解决问题,减少对业务产生影响。
-
向上汇报
遇到棘手问题不要闷声自己想办法解决,正确做法是先向你的leader汇报问题和风险。如果问题比较棘手和严重,可以请求协助,避免因为个人能力不足迟迟不能解决问题,小问题拖成大问题。
-
保留现场
有时候问题是难以复现的,像我们本次的情况一个月可能就出现一次,如果直接重启服务,那么等下次问题出现就非常久了。所以正确的做法是保留现场,同时要不影响业务,可以保留一个节点,将其流量摘除,通过jstack/jmap dump出程序堆栈,其它节点重启。
-
保持耐心
有些问题不是一时半会就能解决的,有的以天为单位,有的可能要一个月才解决。所以保持耐心很重要,多看看官方文档,github issue,分析源码,尝试各种方式,排除各种可能,相信总会找到解决方法。
-
版本选择
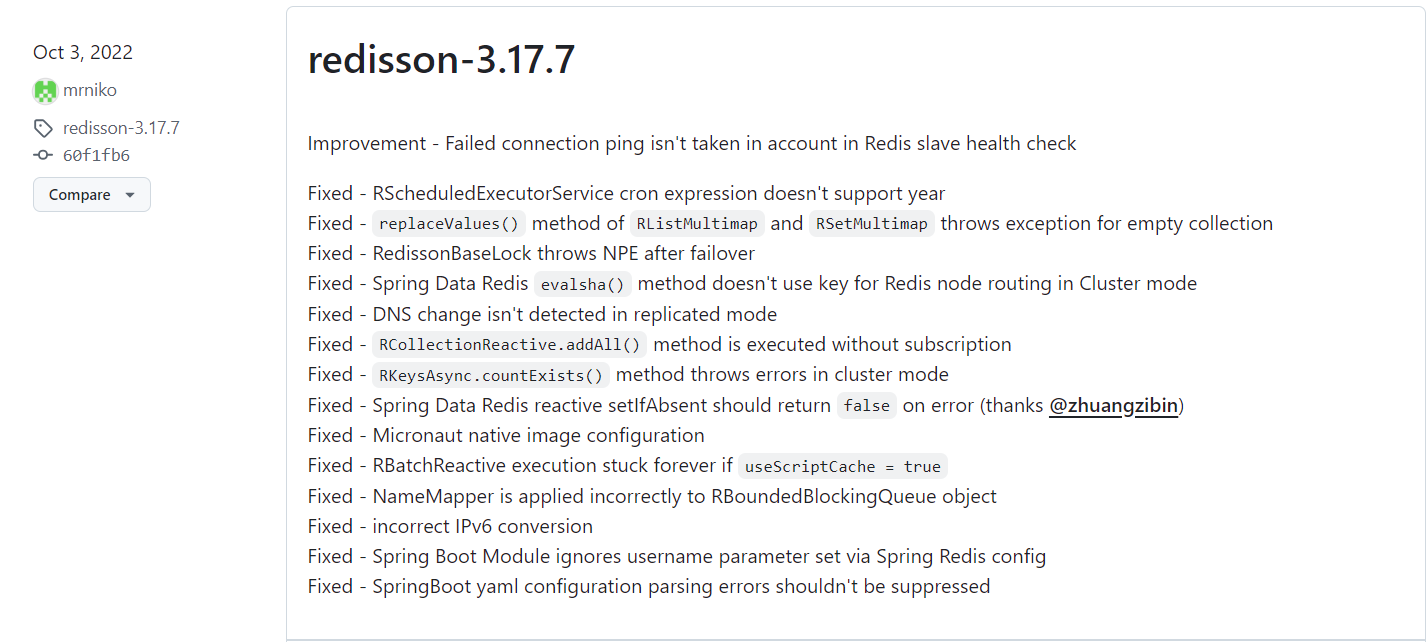
我们选择的redisson版本是3.17.1,实际这个选择不是很好。按照x.y.z的版本规范,x表示大版本,通常是有重大更新,y表示小版本,通常是一些功能迭代,z表示修复版本,通常是修bug用的。例如springboot从2.x升级到3.0,jdk版本要求最低17,是一个非常重大的更新。
上面我为什么选择3.17.7来测试,是因为3.17.7是3.17的最后一个小版本,看到这个版本的release报告你就知道是为什么了,它全部都是在修bug。
当然本次的问题修复不一定在.7这个版本,可能是在1-7之间的某个版本,有兴趣的可以再细看下。
更多分享,欢迎关注我的github:https://github.com/jmilktea/jtea