问题现象
用户迁移到新集群后,反馈他们开发平台大量 flink 任务提交失败了,当时集群的 yarn 资源是足够的
排查过程
用户是在他们的开发平台上提交的,查看他们失败的任务,发现是他们提交端主动 Kill 的,接着沟通发现他们提交平台有个逻辑就是提交到 yarn 的 flink 任务,如果在 2分钟内没有在 yarn 上启动起来,也就是提交的 flink yarn application 没有变成 running 状态的话,开发平台会终止这个提交,并判定这个任务的状态为提交失败了.
已知背景如下:
-
旧集群没有这个问题,迁移到新集群后出现的
-
在提交任务的高峰期才会出现这种问题,低峰期没有这个问题
-
提交端客户端的日志是显示在等待,然后超过 2分钟了,cancel 了
2022-07-26 17:45:32,355 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1625727384658_7951
2022-07-26 17:45:32,577 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1625727384658_7951
2022-07-26 17:45:32,578 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2022-07-26 17:45:32,579 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2022-07-26 17:46:32,801 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
2022-07-26 17:46:33,052 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor
......
2022-07-26 17:47:16,655 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
2022-07-26 17:47:16,690 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cancelling deployment from Deployment Failure Hook
疑点
把提交平台的 2 分钟判断时间增加到 5分钟是能够保证任务成功提交的.
根据 yarn 任务提交流程 ,application 等 master 启动起来后,并向 rm 注册后, application 就从 accepted 状态变为 running 状态了,所以问题是为什么 master 在 2分钟内拉不起了
am 也是一个 container ,一般来说 container 启动过程耗时比较长的资源本地化 localized resource 过程, 从 nm 日志中也确实证实了这一点.
但是资源本地化是一个很简单的操作,如果慢了,问题不会在应用层,一般都是底层网络或者硬件的问题.
于是接着开始转向排查底层操作系统和硬件的问题
分析发现问题节点上的线程数非常多:
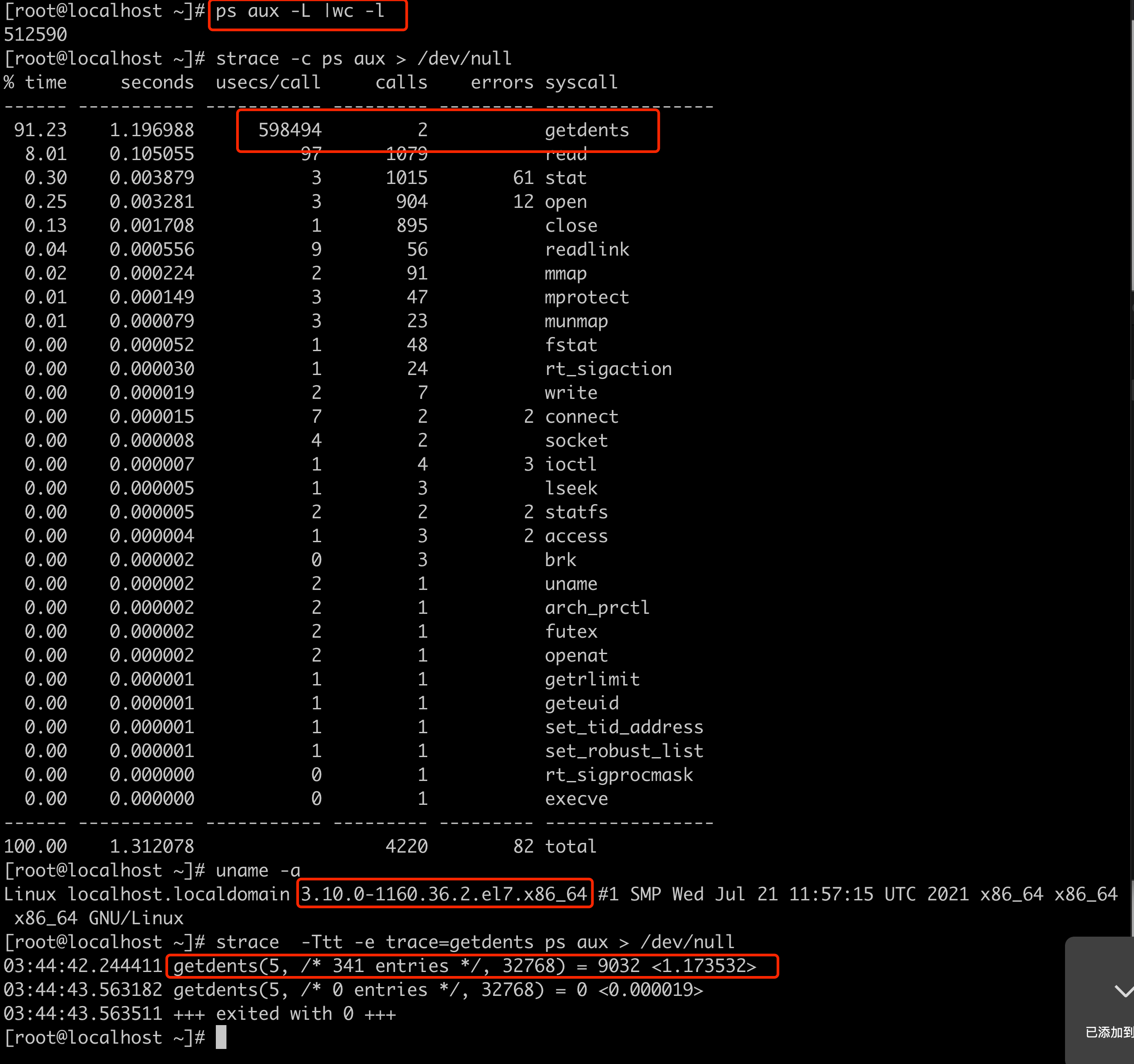
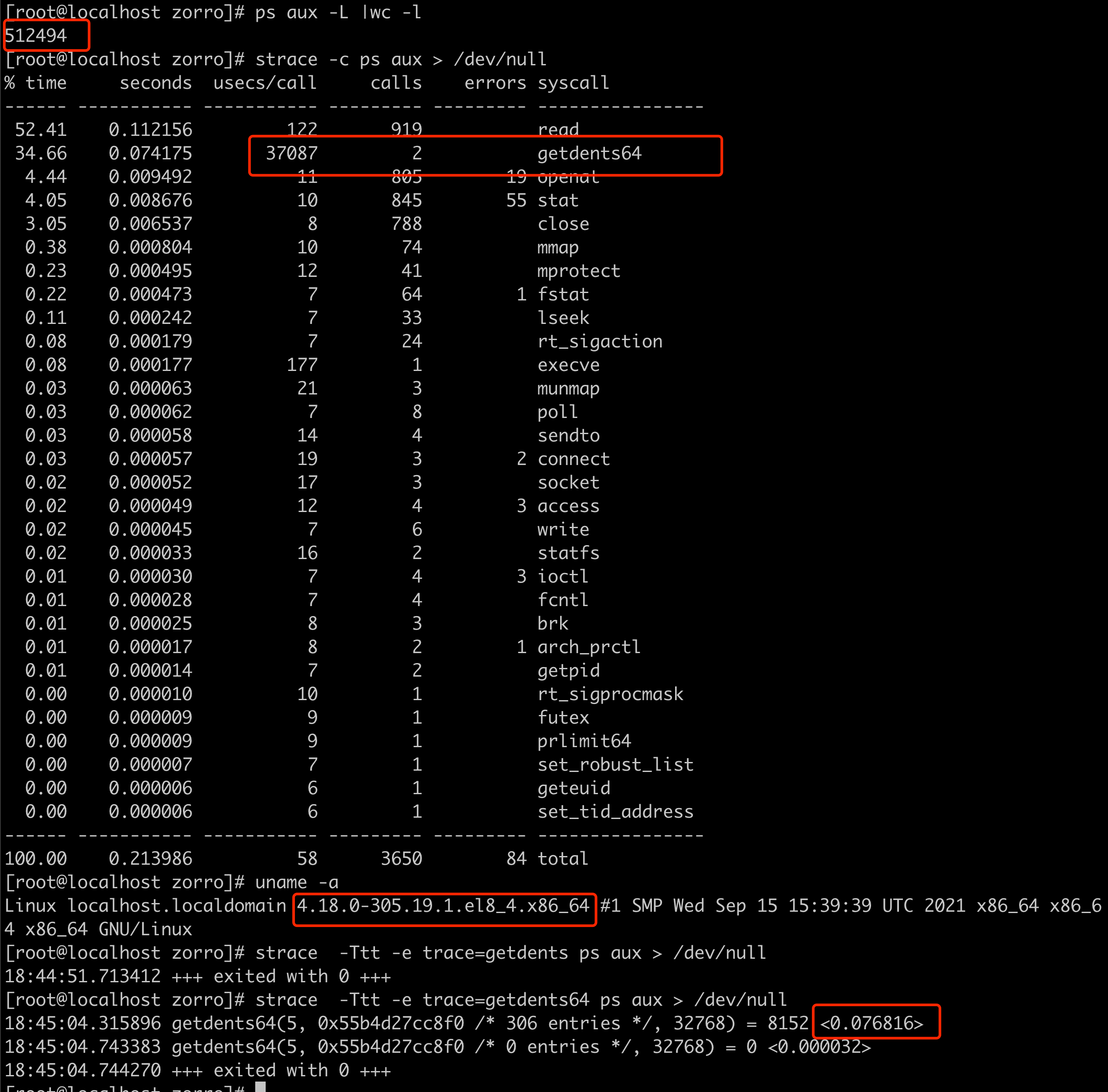
ps -efL | grep java | wc -l
有 11 w 个, 当线程数在 5 w 个的时候,是能正常拉起 flink 任务的,这也是旧集群上正常节点上的线程数,但是当提交的任务增加,线程数达到 10 w 以上时,就无法在 2 分钟内拉起提交的 flink 任务.
在问题节点上,发现 ps 执行出现卡顿的现象,从这里排查发现:
因为线程开的太多,导致/proc目录下的子目录过多,导致的遍历这些目录时,getdents 消耗时间过长,只要是会访问/proc目录下的文件,都会因为同样的原因导致处理慢。
于是猜测 flink 提交任务估计也是同样的因素导致拉起超时,接着 使用 strace 工具来跟踪 nodemanager 进程,跟踪启动 am container 的过程:
找到下载jar包的进程/线程pid,然后strace -p pid -f -Ttt 2> strace.log 发现 nm 进程底层会有 /proc 目录的操作.
所以得出结论还是由于起的线程过多,导致proc下的目录过多,引起底层的相关调用变慢,进而导致上层的 java 程序变慢.
但是用户接着提出疑问,新集群 cpu 和内存配置都是旧集群的两倍,为什么支撑不了两倍的 flink 任务提交,并且当时问题节点的 cpu load 并没满
没有其他排查线索了
这时发现问题节点使用的 linux 内核版本是3.10 的,版本比较老,怀疑是内核层面对于多核多线程的处理能力导致的,于是构造环境使用 strace 进行测试,发现确实高版本内核 getdents 调用性能差异巨大
结论
linux 内核版本3.10低版本 对多核数大量线程相关处理缺少优化,导致某些底层系统调用处理性能不高.
升级内核到 4.18 版本即可解决