工作流调度平台 Dolphinscheduler - Standalone 单机部署 + Flink 部署
目录
- [工作流调度平台 Dolphinscheduler - Standalone 单机部署 + Flink 部署](#工作流调度平台 Dolphinscheduler - Standalone 单机部署 + Flink 部署)
-
- 安装
- [启动 DolphinScheduler Standalone Server](#启动 DolphinScheduler Standalone Server)
- 创建工作流
- 其他修改
-
- [1、修改虚拟机的全局环境变量配置文件 /etc/profile](#1、修改虚拟机的全局环境变量配置文件 /etc/profile)
- [dolphinscheduler 和 flink 的关系](#dolphinscheduler 和 flink 的关系)
-
- [1、停止 flink 服务进程](#1、停止 flink 服务进程)
- 2、查看进程
- [3、用 DolphinScheduler 的 Shell 任务启动 Flink](#3、用 DolphinScheduler 的 Shell 任务启动 Flink)
- 4、拷贝jar包
- [5、命令执行 running jobs 提交作业操作](#5、命令执行 running jobs 提交作业操作)
- [6、用 dolphinscheduler 的shell脚本让 flink 执行 running jobs 操作](#6、用 dolphinscheduler 的shell脚本让 flink 执行 running jobs 操作)
- 总结
ps:这个dolphinscheduler是个人自行研究,要是有不对的地方,欢迎指点不足~
安装

下载
命令下载3.3.2版本
wget https://mirrors.huaweicloud.com/repository/apache/dolphinscheduler/3.3.2/apache-dolphinscheduler-3.3.2-bin.tar.gz
校验压缩包
.sha512 文件出自 Apache 官方 archive,内容是官方发布的校验哈希,用来自检下载完整性
下载校验文件
wget https://archive.apache.org/dist/dolphinscheduler/3.3.2/apache-dolphinscheduler-3.3.2-bin.tar.gz.sha512
校验:
sha512sum -c apache-dolphinscheduler-3.3.2-bin.tar.gz.sha512

解压
tar -xvzf apache-dolphinscheduler-3.3.2-bin.tar.gz
下载插件

需要在bin目录 -> /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin/bin
下执行这个命令,用来执行脚本文件,安装插件依赖
我的版本是3.3.2,所以这里就是3.3.2,如果用其他版本号会出错
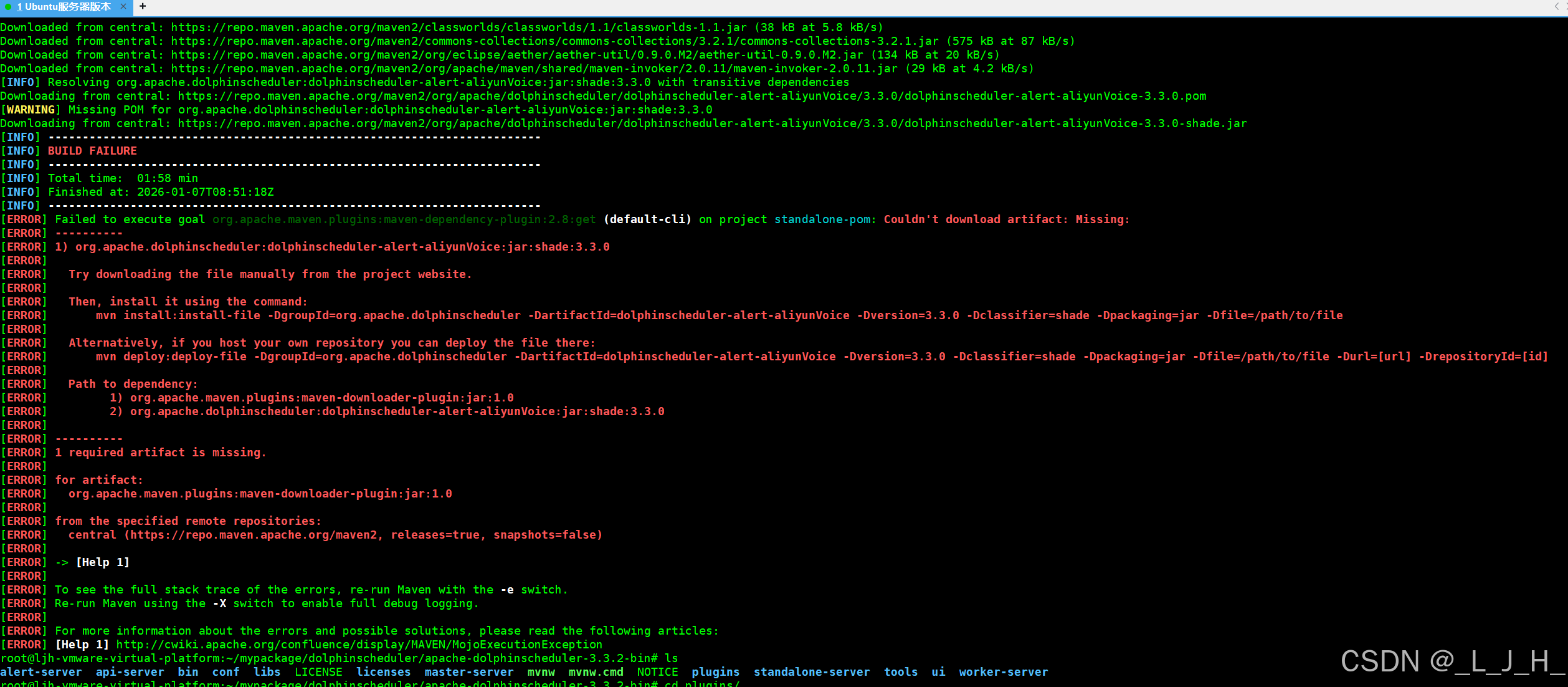
bash ./bin/install-plugins.sh 3.3.2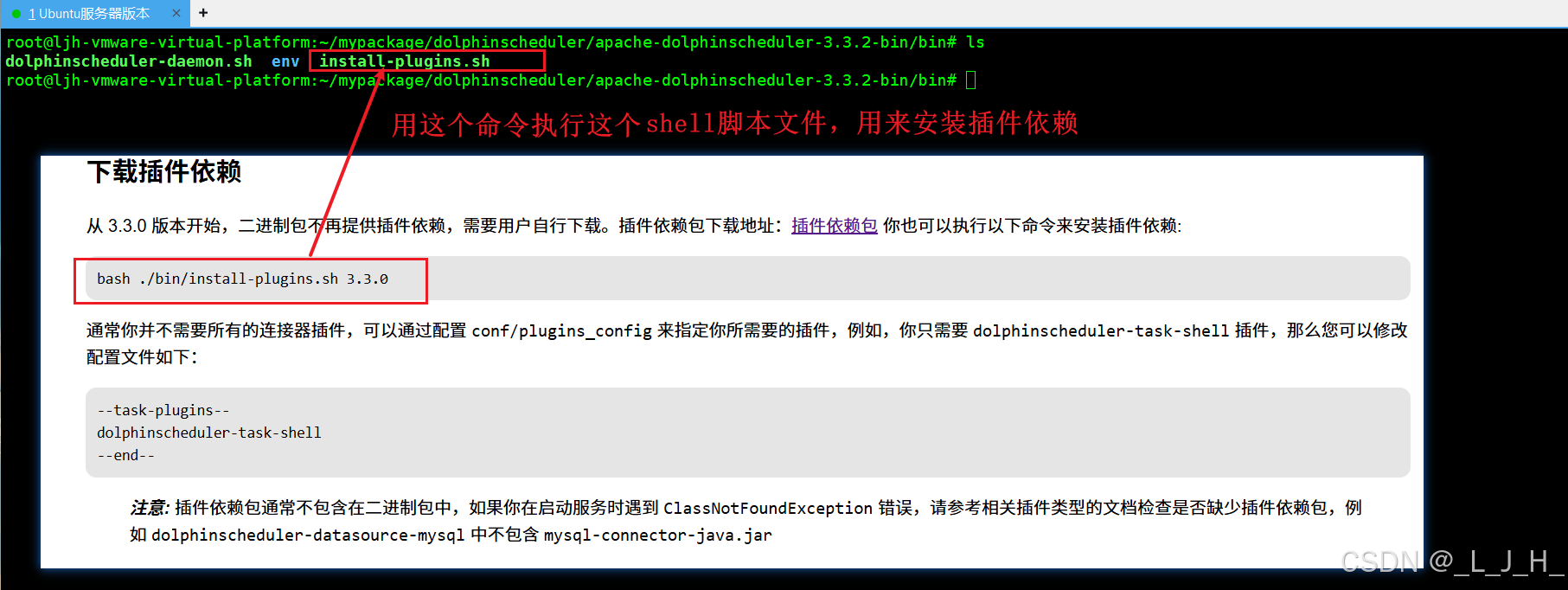
有些依赖没安装成功,先不用理,到时缺什么再补---原因:版本号问题,改成3.3.2就好
配置用户免密及权限

创建部署用户
任意位置执行创建用户的命令即可:
# 创建用户需使用 root 登录
useradd dolphinscheduler
添加密码
# 添加密码---官网提供的这个命令,ubuntu 版本无法使用
(将用户dolphinscheduler的密码设置为dolphinscheduler)
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
所以改成 :passwd dolphinscheduler
配置 sudo 免密
官网是这样的:
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requiretty/#Defaults requiretty/g' /etc/sudoers我这里这么改
visudo 是"安全编辑 /etc/sudoers 文件的专用命令,
相当于打开 /etc/sudoers 这个文件让你编辑,但带安全保护。
用这里命令,如果编辑的时候语法出现错误是无法保存的,但是如果用vim编辑,语法出现错误还是会保存。
输入这个编辑命令:
visudo
在文件末尾添加这行,不要多空格
dolphinscheduler ALL=(ALL) NOPASSWD: ALL
添加完后 ctrl + 0 保存
然后会提示文件名,回车确认即可
然后再 ctrl+x 退出编辑页面
如果改错了 ctrl + x ,然后输入 N 即可不修改退出
------------------------------------------
这个是属于 nano 的编辑方式,
【nano 是 Linux 下的一个"终端文本编辑器",visudo就是用 nano来编辑 /etc/sudoers 这个配置文件】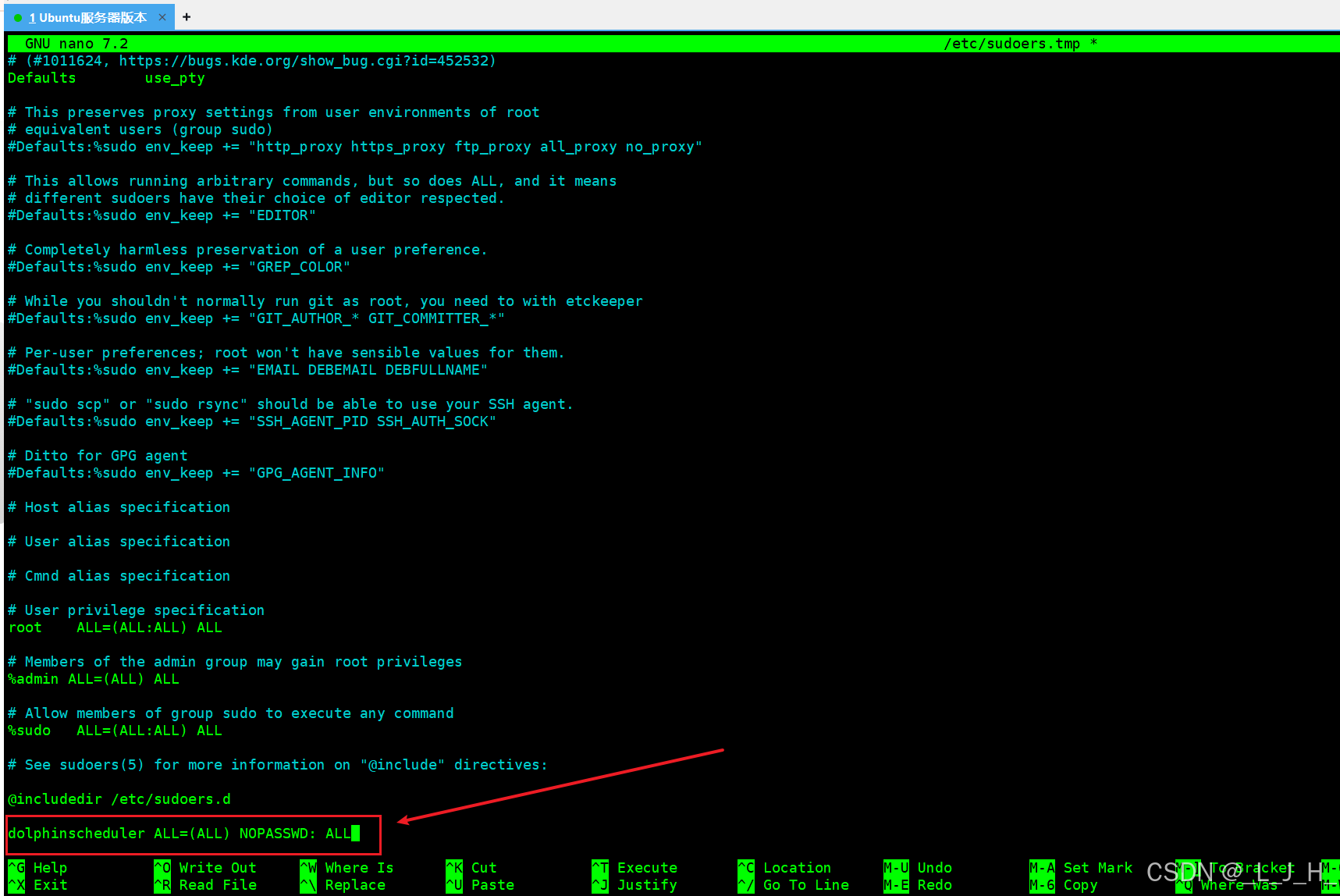
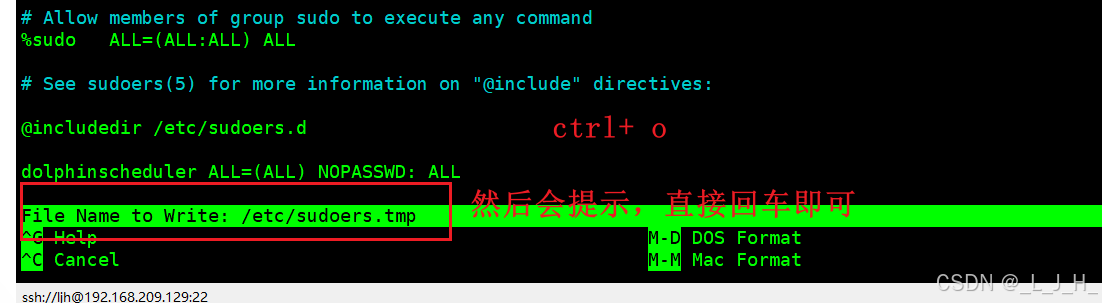
如果发现 /etc/sudoers 文件中有 "Defaults requiretty" 这行,也请注释掉。
这个主要存在于 centos 版本 ,我的ubuntu版本没有,所以不用理修改目录权限
部署用户就是我刚刚添加的【dolphinscheduler】,让它能够读 / 写 / 执行 DolphinScheduler 的安装目录

chown -R → 递归修改目录属主和属组
chmod -R 755 → 递归修改目录权限,让属主可读写执行,其他人可读执行
它们操作的是整个 apache-dolphinscheduler-3.3.2-bin 目录,不是里面的 bin 子目录
我安装的目录是:
/root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin
所以命令需要按自己的路径这么修改:
chown -R dolphinscheduler:dolphinscheduler /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin
chmod -R 755 /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin
这两条命令任意位置执行即可。
验证是否成功
ls -ld /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin

启动 DolphinScheduler Standalone Server
解压并启动 DolphinScheduler

# 启动 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
# 停止 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh stop standalone-server
# 查看 Standalone Server 状态
bash ./bin/dolphinscheduler-daemon.sh status standalone-server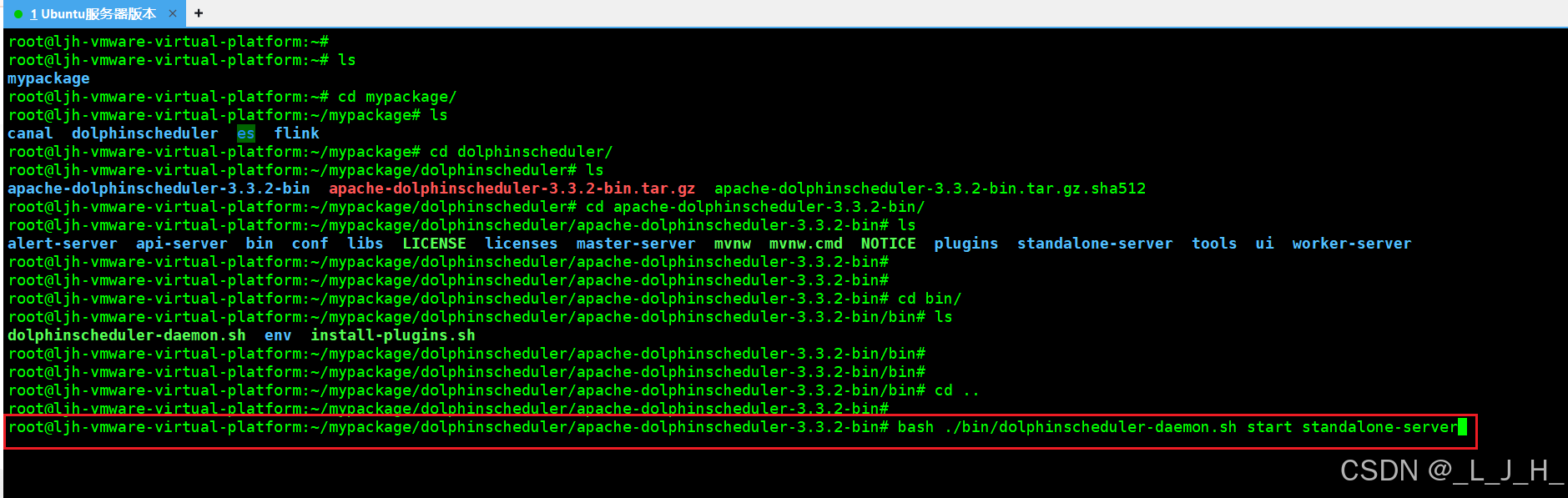
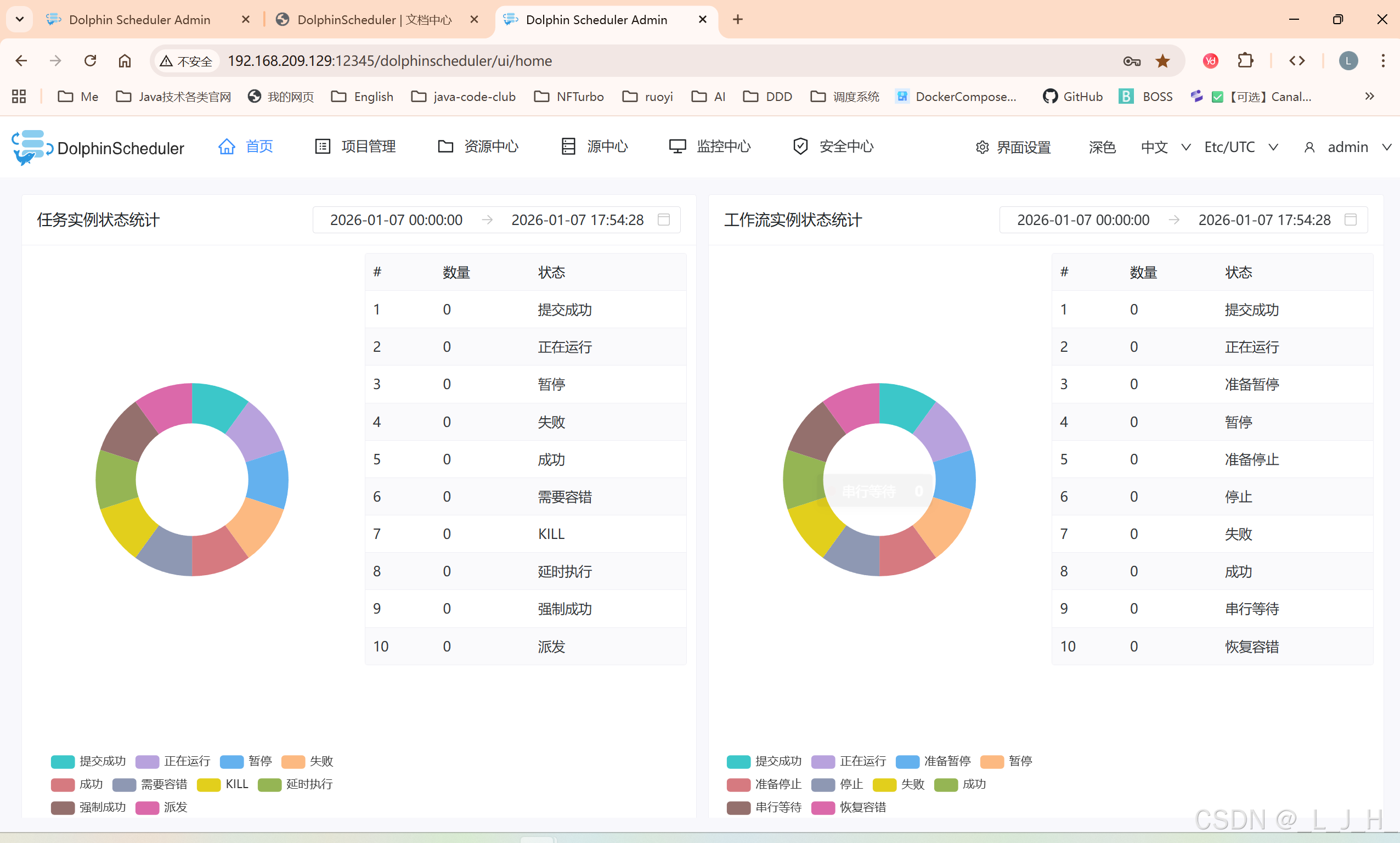
登录 DolphinScheduler
注意:ip是自己虚拟机的ip
http://192.168.209.129:12345/dolphinscheduler/ui/home
账号:admin
密码:dolphinscheduler123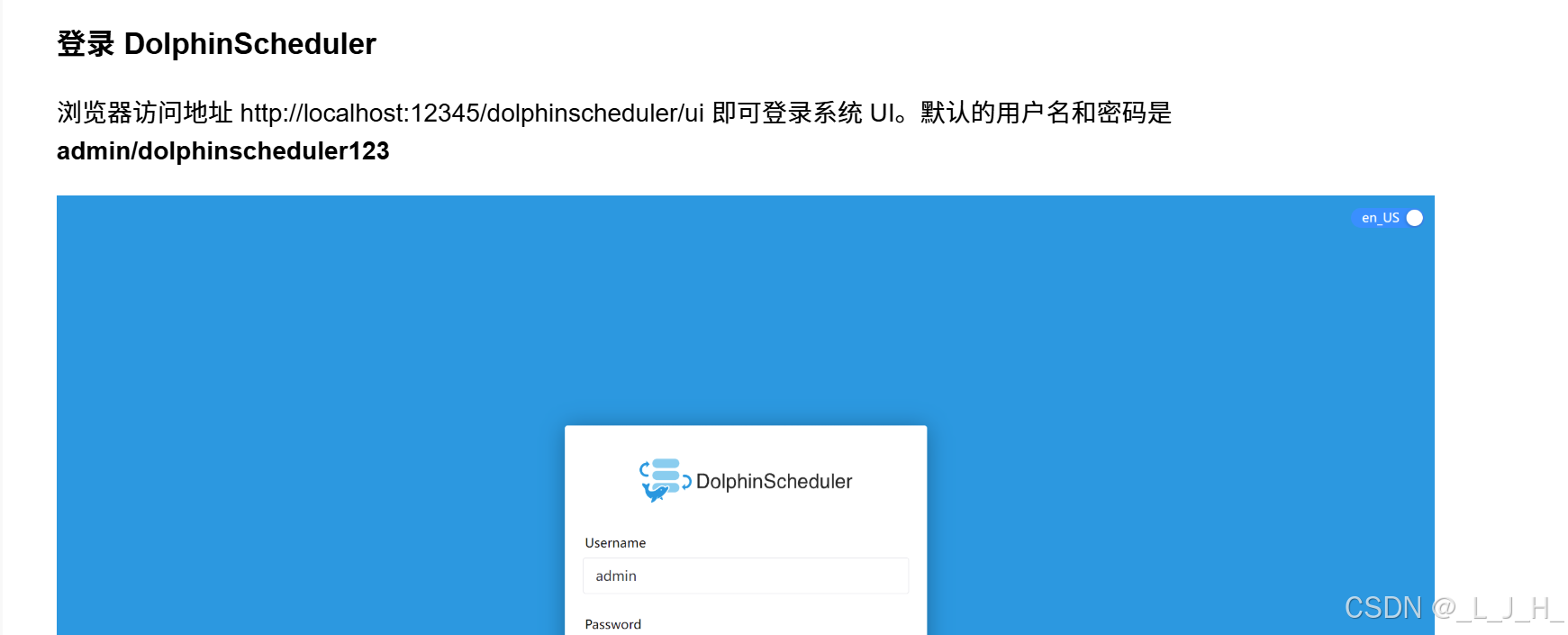
产生问题:
1、jdk版本过高
我的虚拟机有java8和21,java-version是显示21,改成用java8
1、确认 Java 8 安装路径
update-alternatives --config java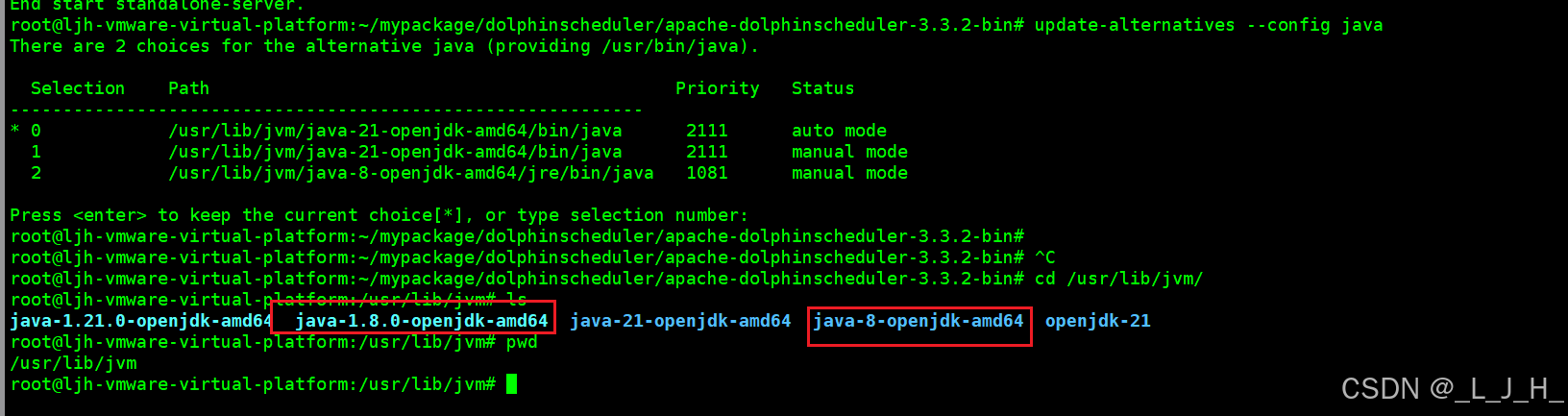
如图操作即可:
切换系统默认 Java
sudo update-alternatives --config java
Java 编译器也要同步:
sudo update-alternatives --config javac
java -version
javac -version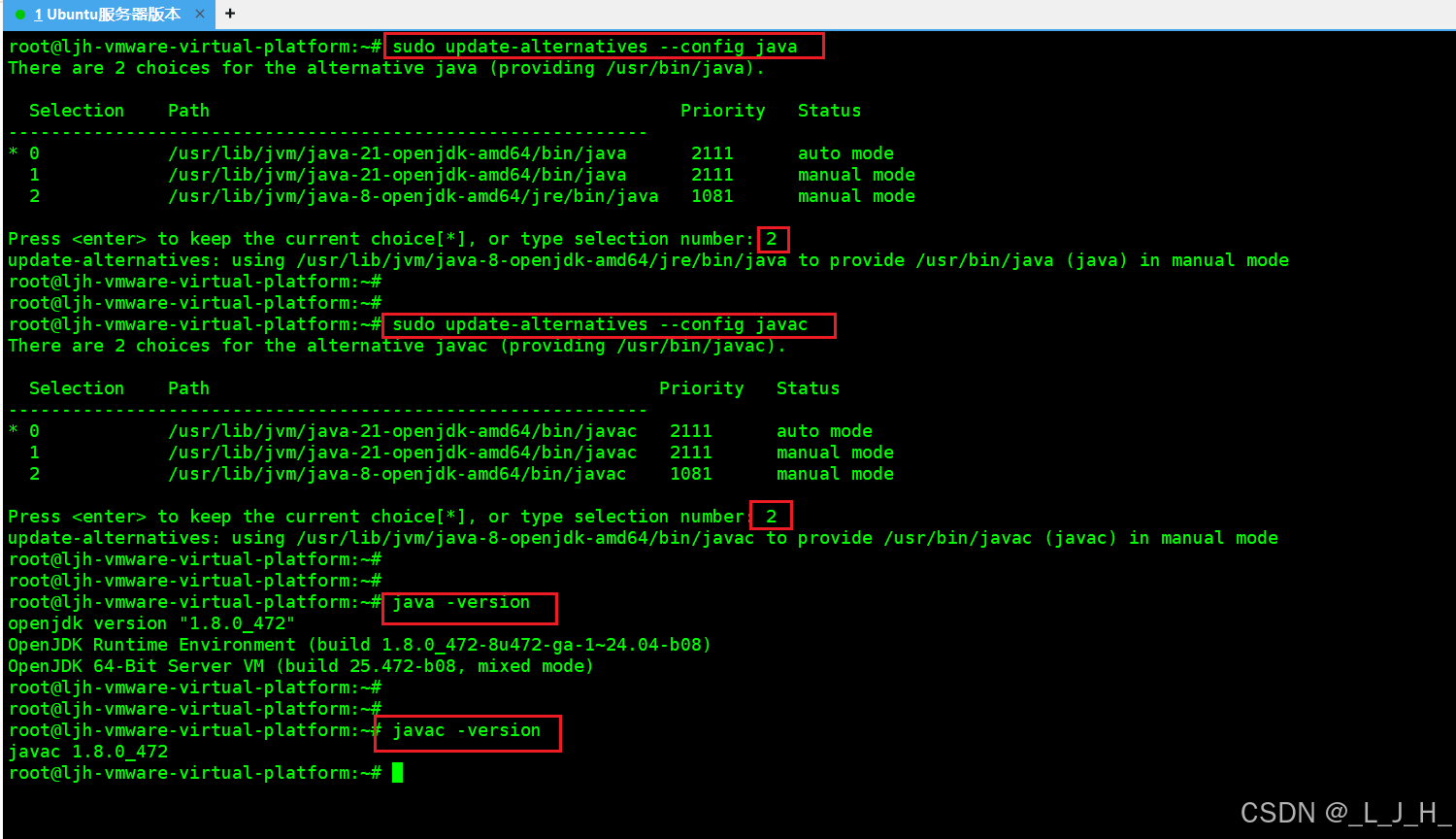
重启dolphinscheduler
# 启动 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
# 停止 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh stop standalone-server
# 查看 Standalone Server 状态
bash ./bin/dolphinscheduler-daemon.sh status standalone-server2、flink 问题
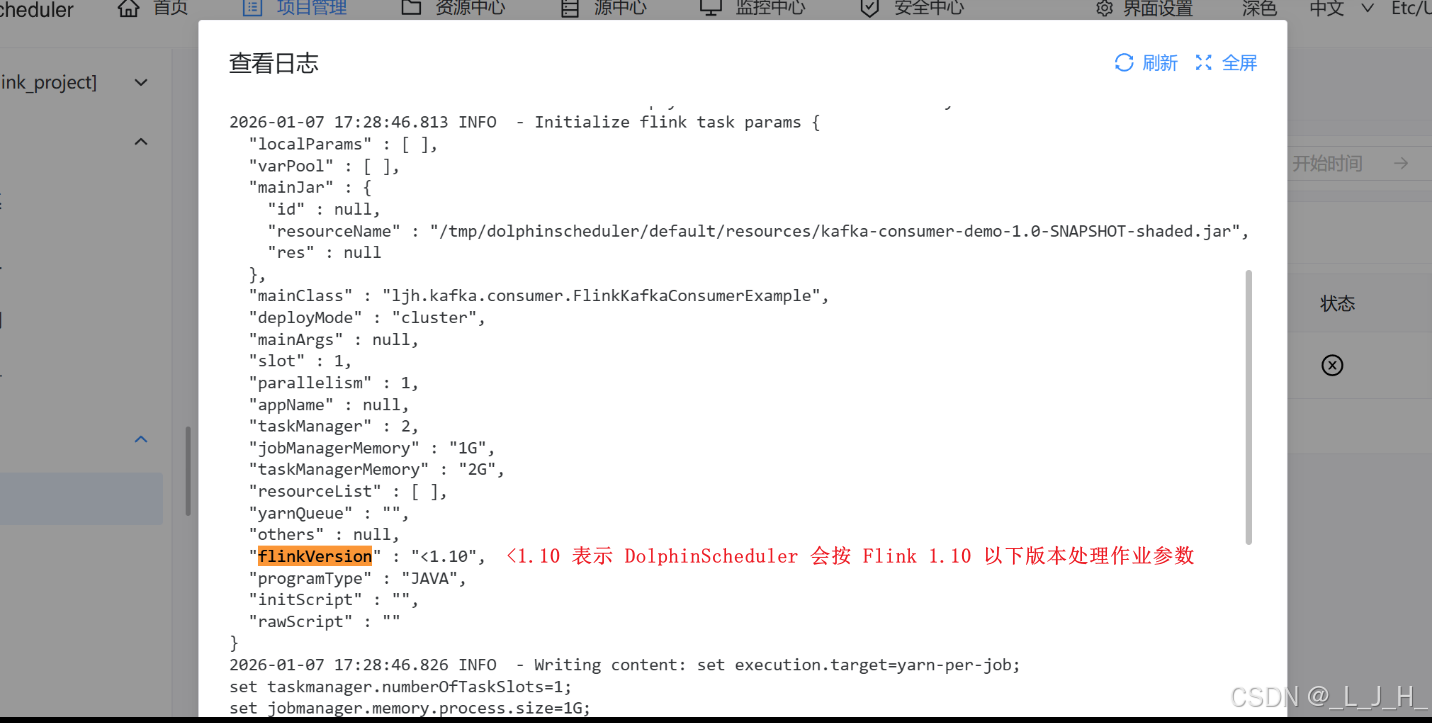
日志中 DolphinScheduler 任务执行失败的核心原因在这一行:
/tmp/dolphinscheduler/exec/process/1/1.sh: line 4: /bin/flink: No such file or directory
也就是说,DolphinScheduler 尝试执行 Flink 任务时找不到 Flink 命令。
结合执行脚本:
${FLINK_HOME}/bin/flink run -m yarn-cluster -ys 1 -yn 2 -yjm 1G -ytm 2G -p 1 -sae -c ljh.kafka.consumer.FlinkKafkaConsumerExample /tmp/dolphinscheduler/exec/process/1/kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar
${FLINK_HOME} 这个环境变量没有正确配置,或者指向的目录不存在。
因为最终执行的是 /bin/flink,说明 ${FLINK_HOME} 为空,所以执行失败。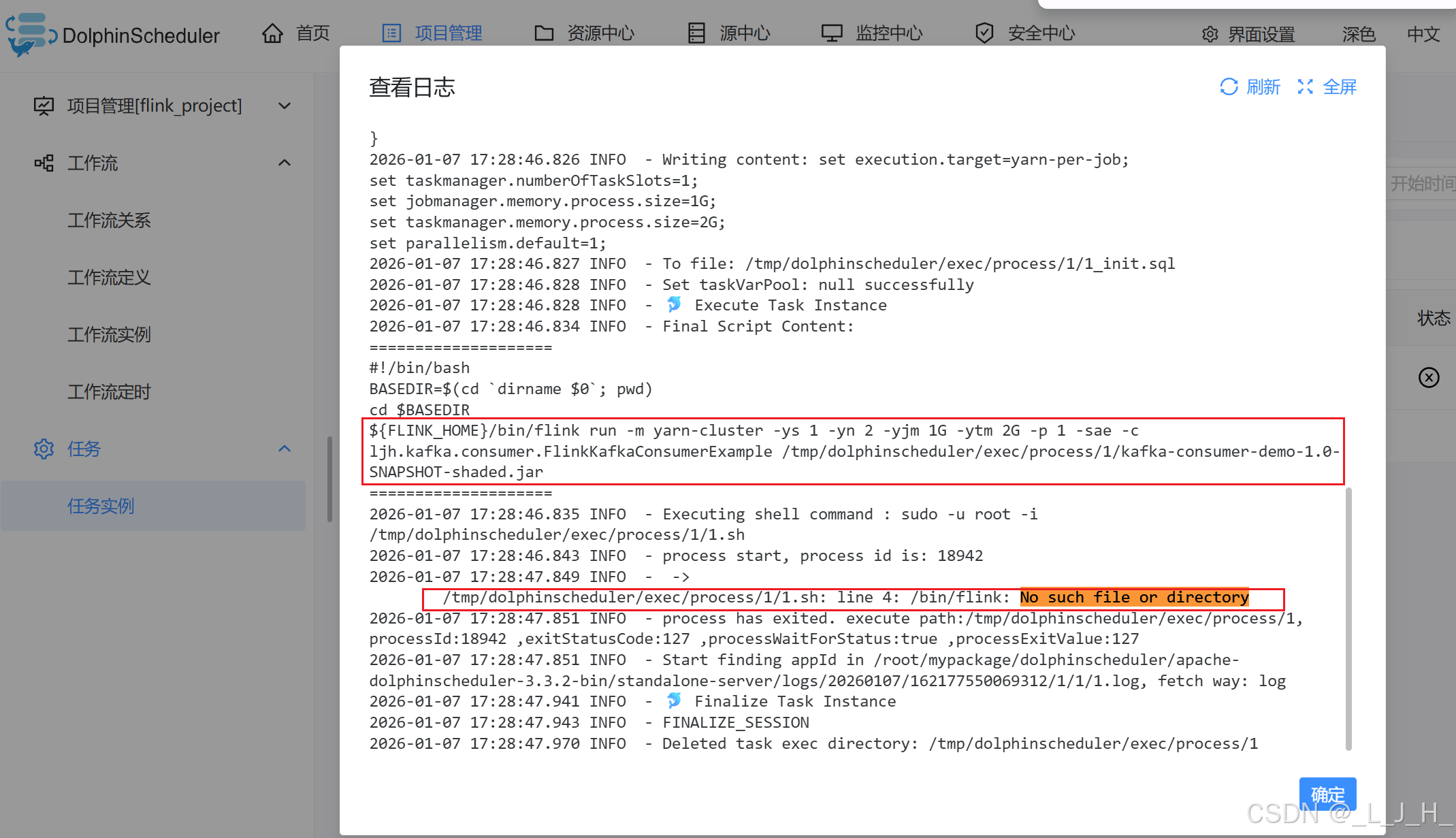
问题出现原因理解:
1、我在代码里面引入了flink依赖,进行kafka的消息消费处理,但是这只保证了编译时 和 打包时 jar 中有 Flink 的类,我可以在本地 IDEA 或 Spring Boot 程序里直接调用 Flink API(比如 FlinkKafkaConsumerExample)
2、但是如果用 DolphinScheduler 执行 Flink 类型的任务,它不是直接运行我写的 Java main 方法,而是调用 Flink 集群命令行工具 flink run 来提交作业。
也就是说,它需要在系统中有一个 Flink 环境(bin/flink 命令),不管我的 jar 有多少依赖都必须有 Flink 程序来运行任务。
日志中的命令就是:${FLINK_HOME}/bin/flink run -m yarn-cluster ...
DolphinScheduler 只是帮我调用了 Flink CLI 来提交任务,它 不会自己解析我这个 jar 内的 Flink 类
所以我需要在虚拟机也安装 flink
安装与 jar 版本对应的 Flink。
配置环境变量 FLINK_HOME。
这样 DolphinScheduler 就可以通过 flink run 提交作业
安装 flink
下载flink1.11.6版本:
wget https://repo.huaweicloud.com/apache/flink/flink-1.11.6/flink-1.11.6-bin-scala_2.12.tgz
校验压缩包
校验下这个压缩包是否是官方正品【生产环境必须要检验】
下载官方校验文件:
wget https://archive.apache.org/dist/flink/flink-1.11.6/flink-1.11.6-bin-scala_2.12.tgz.sha512
执行校验命令,输出 ok 即可
sha512sum -c flink-1.11.6-bin-scala_2.12.tgz.sha512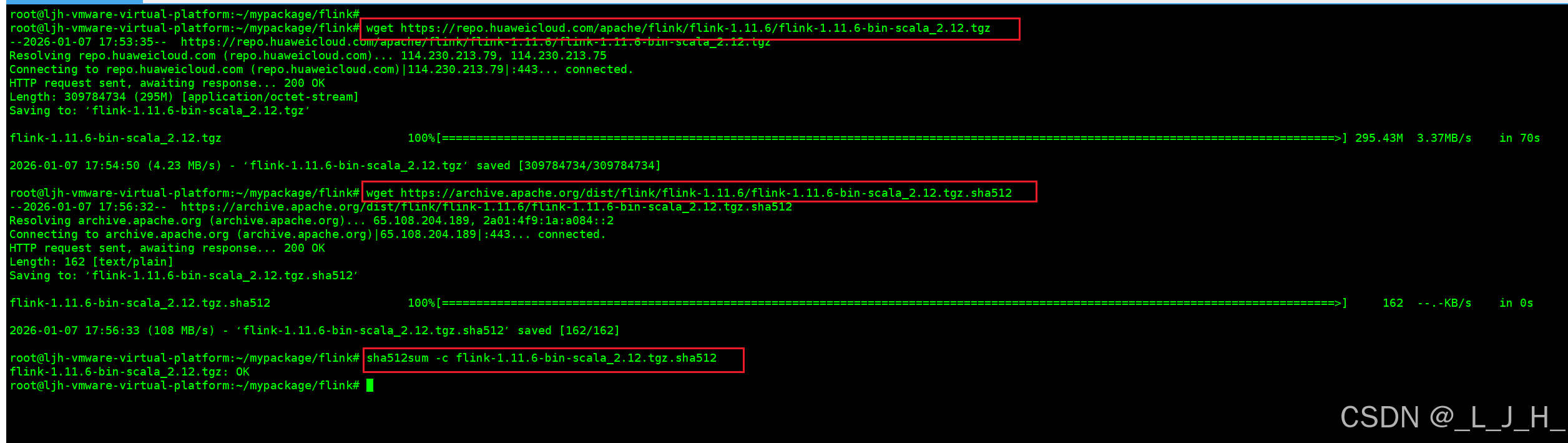
解压
tar -xzvf flink-1.11.6-bin-scala_2.12.tgz
启动
到这个位置 /root/mypackage/flink/flink-1.11.6 执行
./bin/start-cluster.sh
./bin/stop-cluster.sh浏览器访问
现在虚拟机访问下,如果返回 html或json 即可
curl http://localhost:8081
简单提交jar包看看
这里有正常刷新
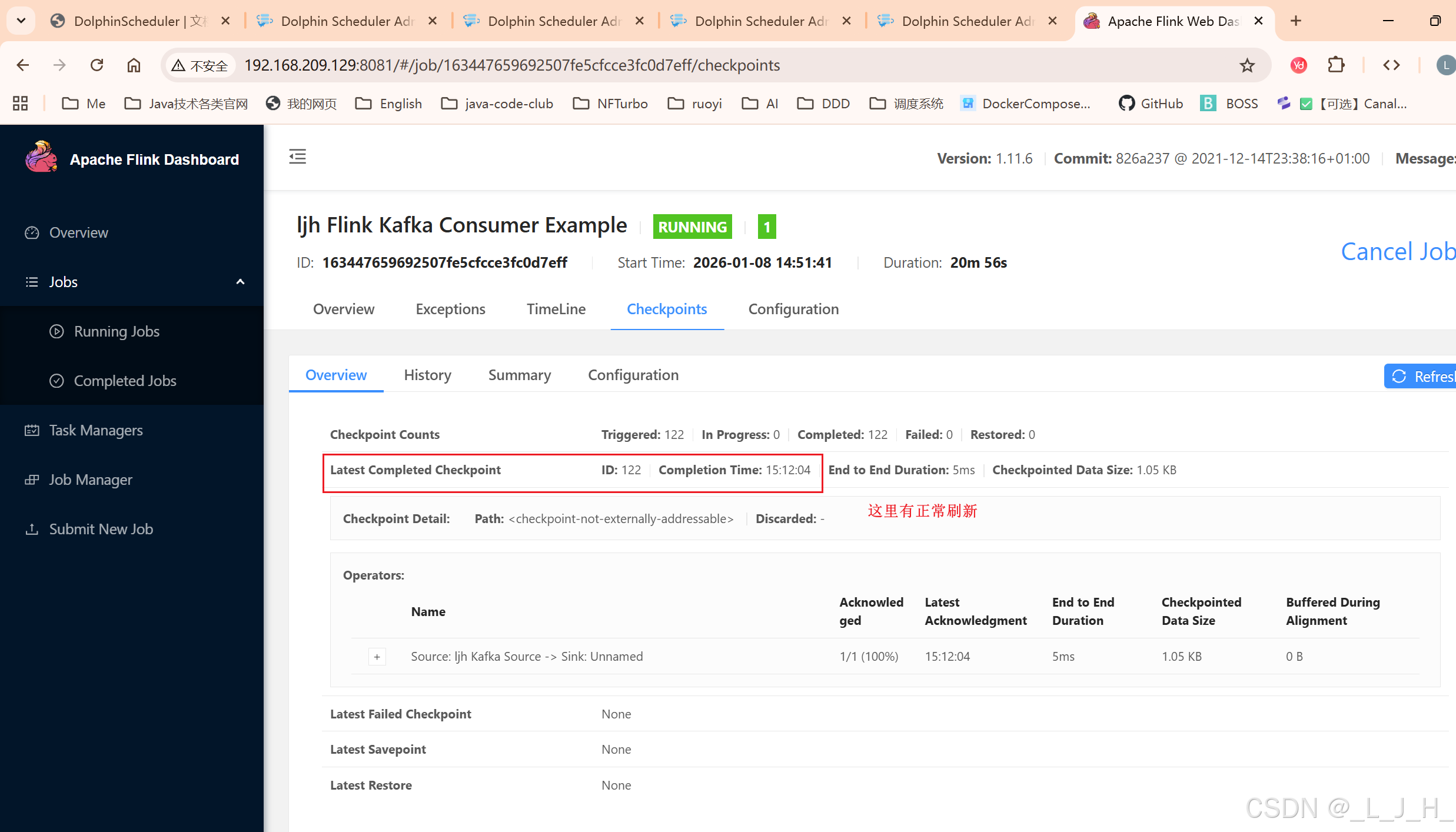
这里可以看到消费的日志

在虚拟机上看日志:
cd /root/mypackage/flink/flink-1.11.6/log
tail -f flink-root-taskexecutor-0-ljh-vmware-virtual-platform.log
dolphinscheduler 配置环境变量
已经下载并解压了 Flink 1.11.6,下一步就是 配置环境变量,让 DolphinScheduler 能找到 Flink
1、修改 dolphinscheduler_env.sh
官网的说法:

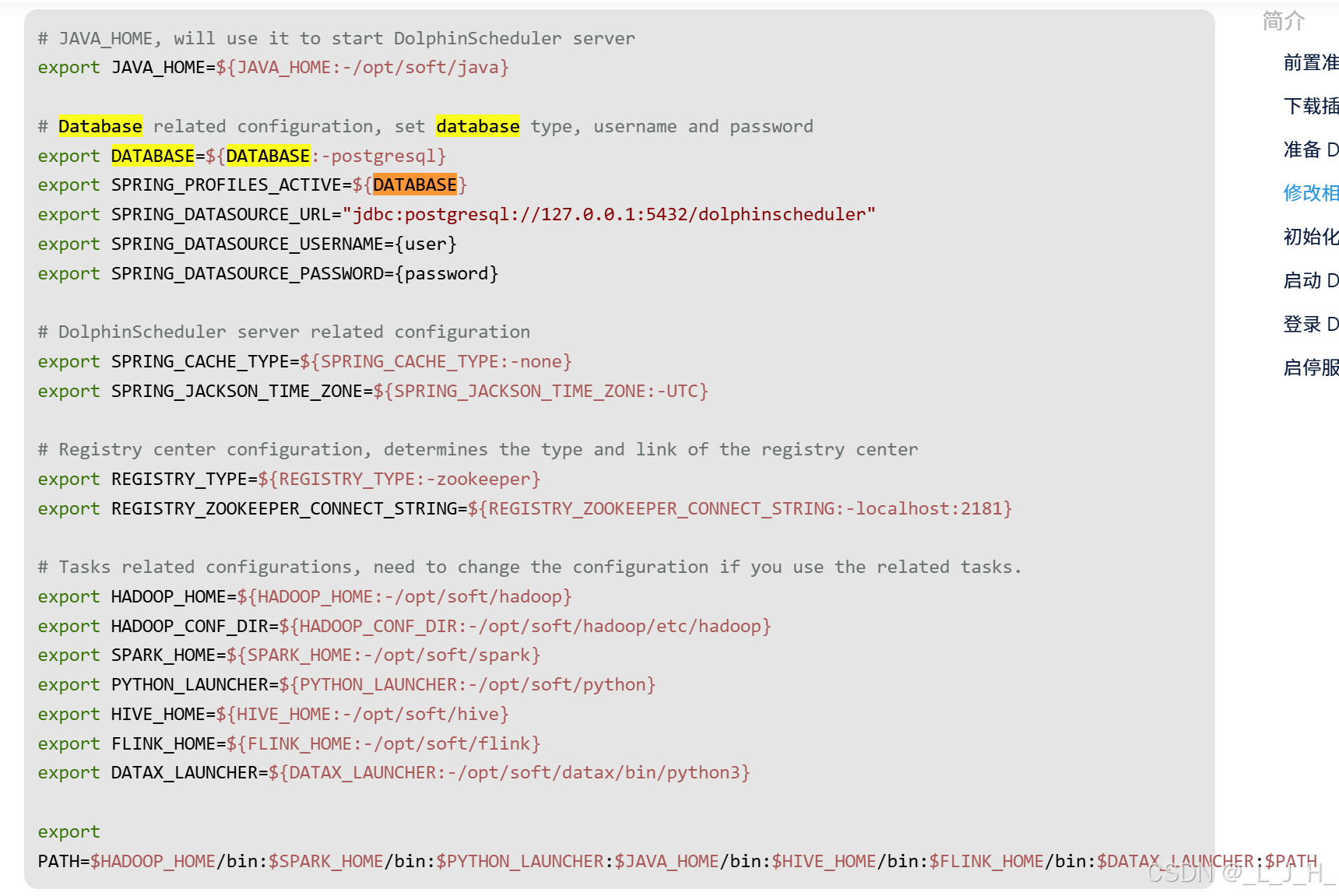

看下启动脚本文件dolphinscheduler-daemon.sh 里面说的,
脚本会尝试读取 ./bin/env/dolphinscheduler_env.sh,
dolphinscheduler_env.sh 文件中的配置会覆盖各个服务的配置文件(application.yaml)中的配置,
以 dolphinscheduler_env.sh 文件中的配置为准

# Java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
# Flink
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$FLINK_HOME/bin:$PATH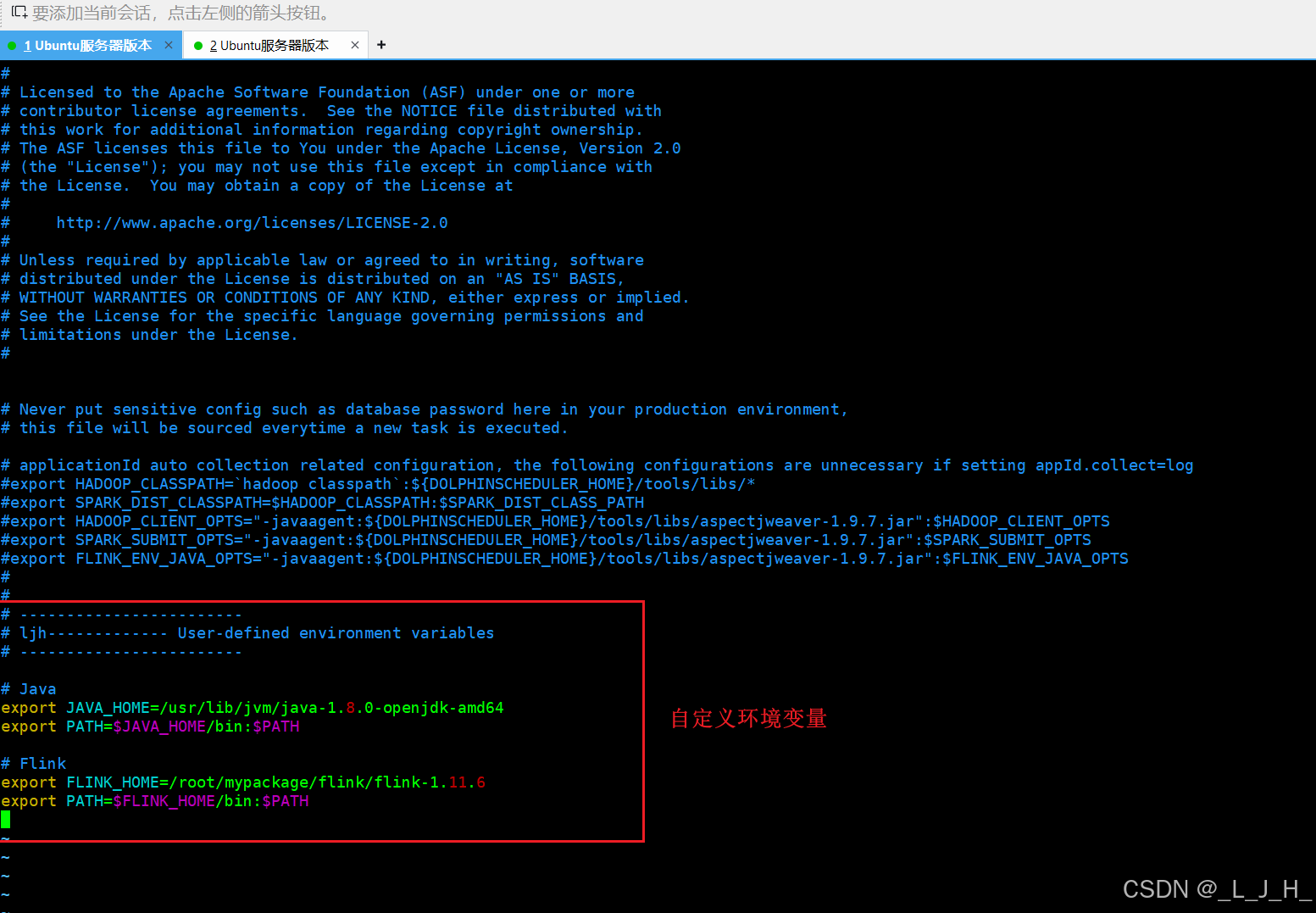
让当前终端加载并执行 dolphinscheduler_env.sh 文件里的内容,也就是把里面的环境变量生效到当前的 shell 中
生效要执行这条命令
source /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin/bin/env/dolphinscheduler_env.sh
查看flink版本
flink -v
停止再重启下dolphinscheduler
cd /root/mypackage/dolphinscheduler/apache-dolphinscheduler-3.3.2-bin
# 停止 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh stop standalone-server
# 启动 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
# 查看 Standalone Server 状态
bash ./bin/dolphinscheduler-daemon.sh status standalone-server【最终没啥效果,换另一种方法就可以,就是把内容写在任务参数中,在创建工作流中体现】
创建工作流
1、上传jar包
把我写的消费kafka消息的jar包上传
2、创建项目
3、创建工作流
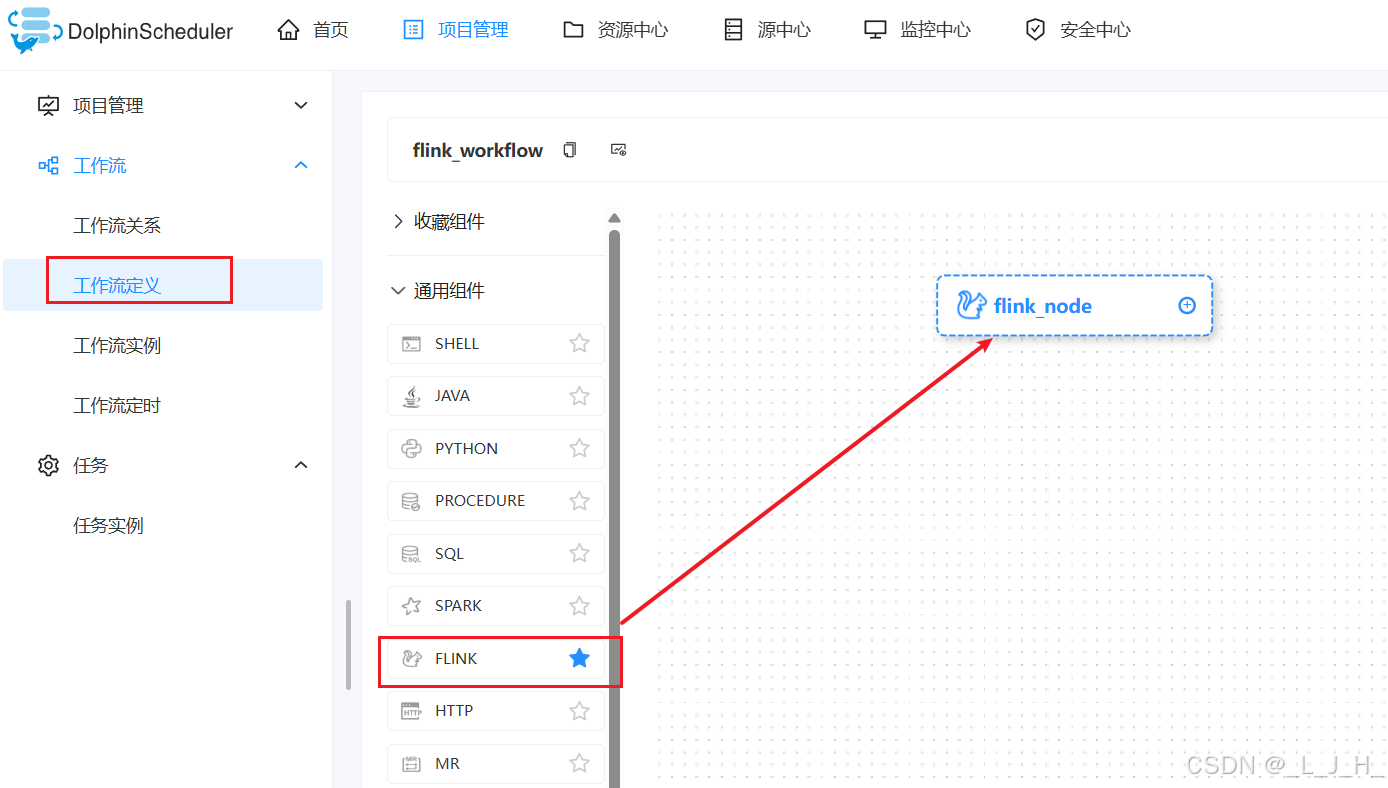
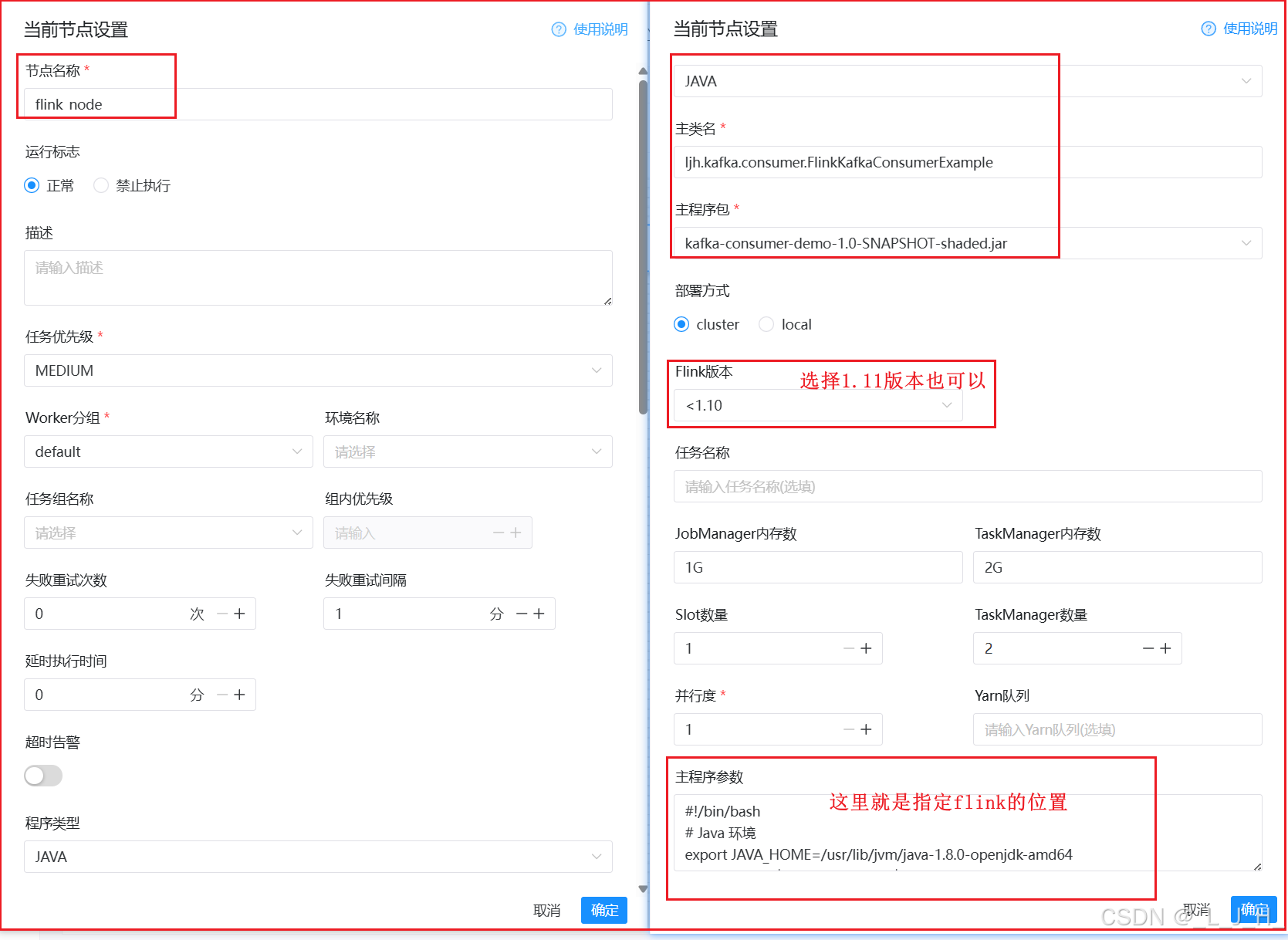
主程序参数就是这个:【这个操作应该是不对的】
#!/bin/bash
# Java 环境
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
# Flink 环境
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$FLINK_HOME/bin:$PATH4、上线 / 运行
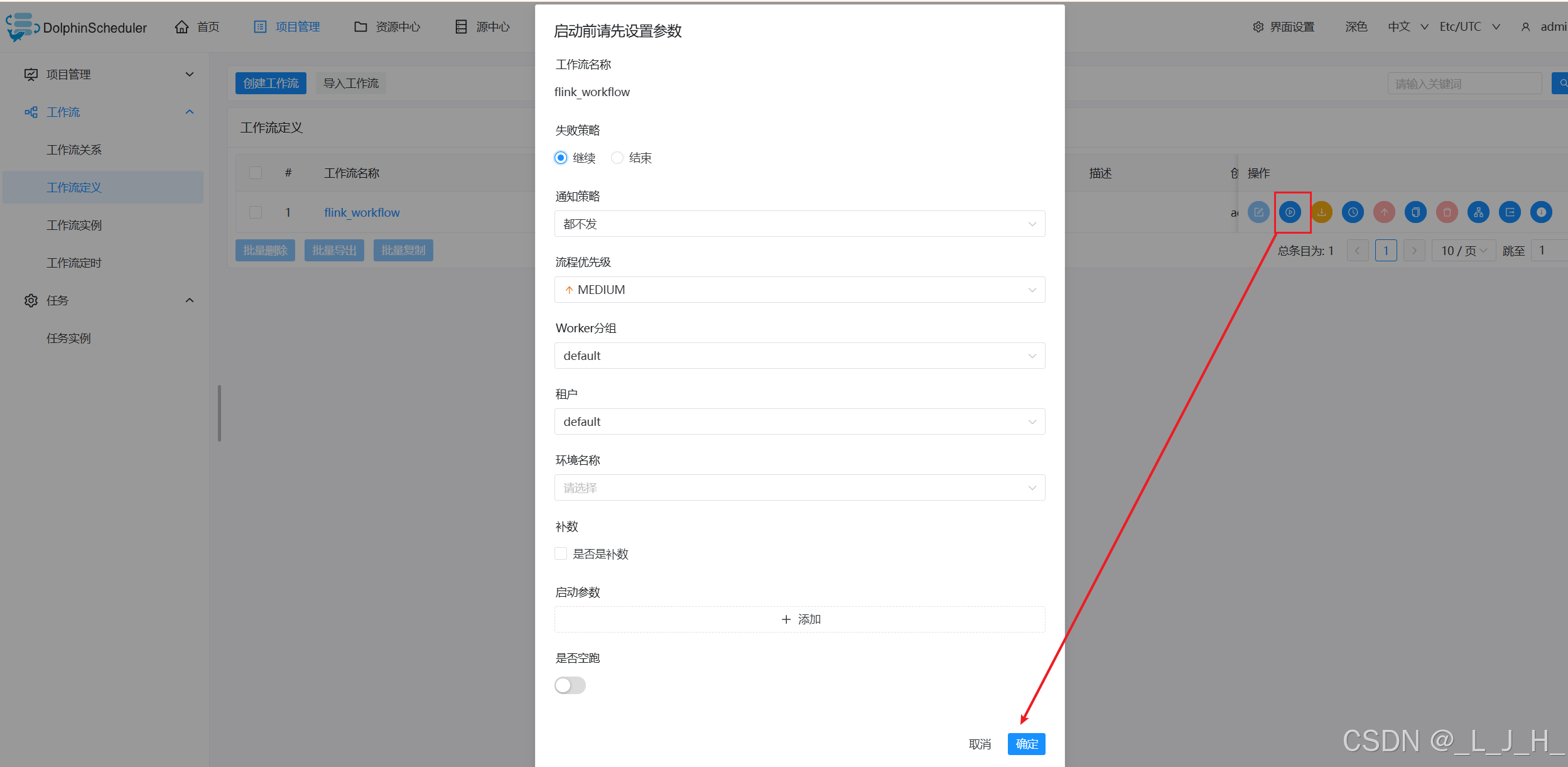
就能成功运行了---但是问题是,日志显示 flink 还是没拿到
其他修改
还有很多问题,没看到消费kafka的消息,主要是dolphinscheduler和flink的设置
1、修改虚拟机的全局环境变量配置文件 /etc/profile
vim /etc/profile
最尾部添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$JAVA_HOME/bin:$FLINK_HOME/bin:$PATH
让配置文件生效
source /etc/profile
查看版本
java -version
flink -v
which flink 是用来查看:你当前执行的 flink 命令,实际用的是哪一个可执行文件
which flink
输出:/root/mypackage/flink/flink-1.11.6/bin/flink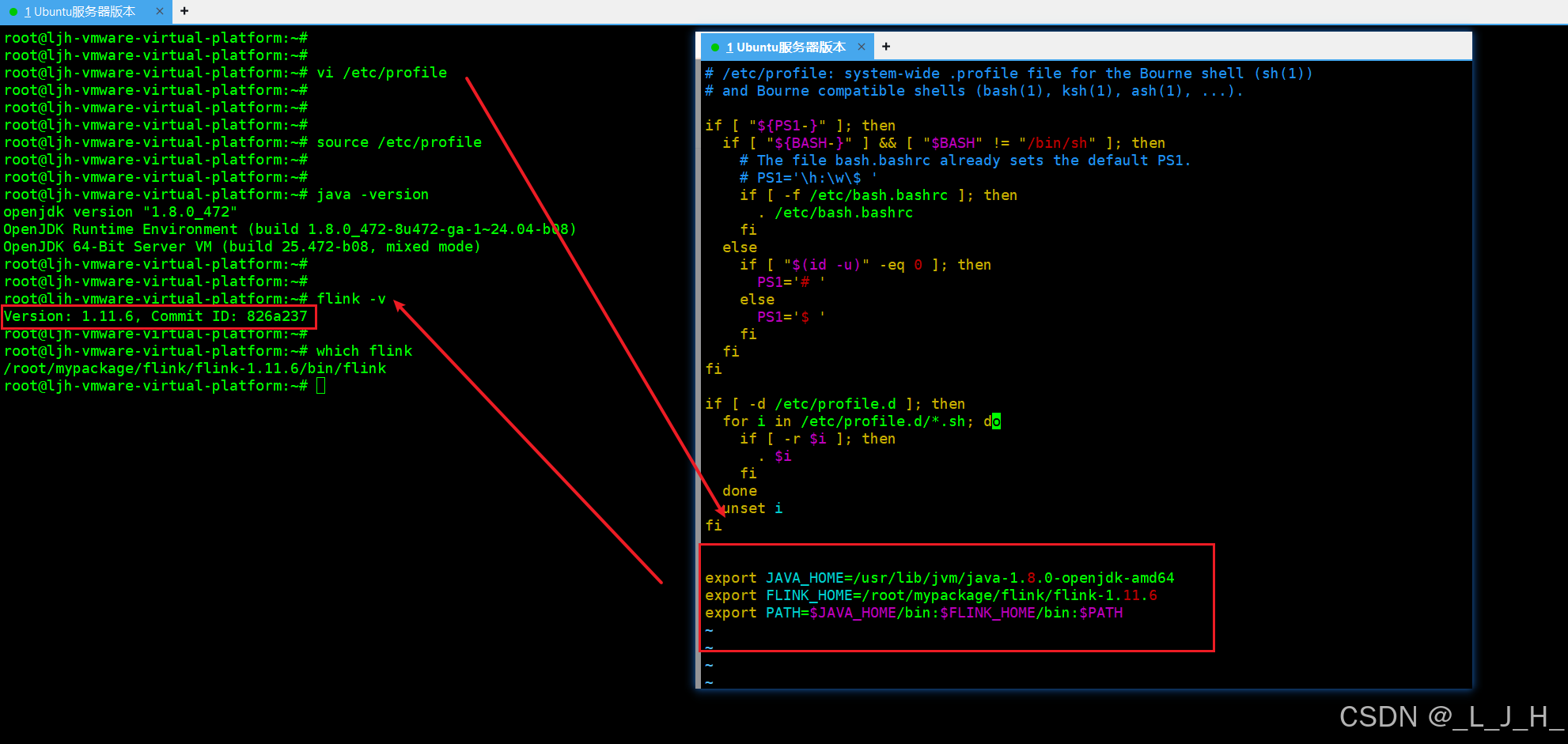
dolphinscheduler 和 flink 的关系
dolphinscheduler 类似于定时任务,定时去调用 flink 执行消费消息的任务,例如每天凌晨1点执行,消费完消息后就让flink退出。
DolphinScheduler 就是:
定时 / 依赖地触发 Flink 批任务,
让 Flink 在指定时间消费"有限数据",
消费完成后自动退出。
1、停止 flink 服务进程
比如我现在先让 flink 退出
1、停止 flink 服务进程
$FLINK_HOME/bin/stop-cluster.sh
$FLINK_HOME 在全局变量已经有设置了,是FLINK_HOME=/root/mypackage/flink/flink-1.11.6
或者到 flink 安装目录下执行这个 ./stop-cluster.sh 也一样
etc/profile 全局变量这里是这么设置的,重温一下
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$JAVA_HOME/bin:$FLINK_HOME/bin:$PATH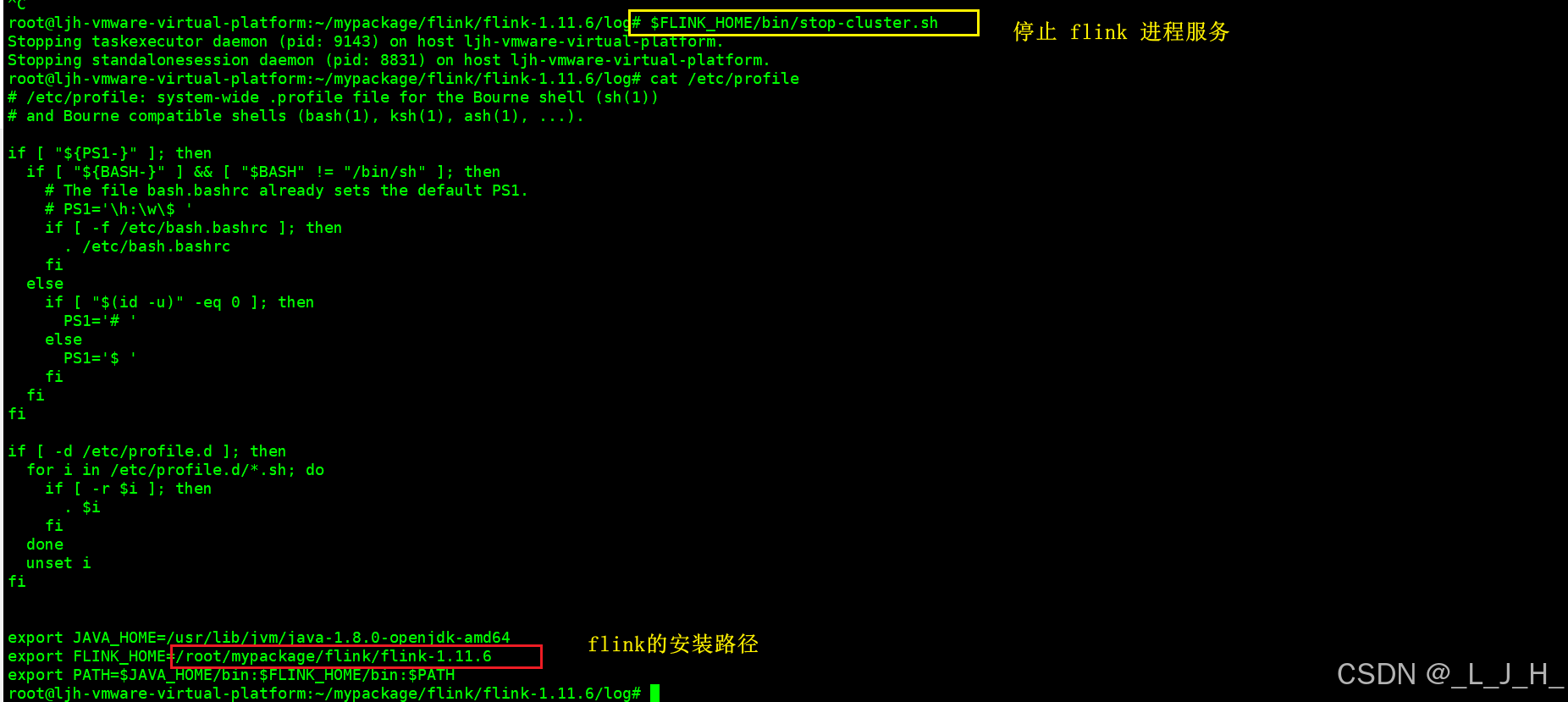
2、查看进程
2、jps 是 JDK 自带的一个命令,用来查看当前机器上正在运行的 JVM 进程
jps 
3、用 DolphinScheduler 的 Shell 任务启动 Flink
创建一个 shell 类型的工作流,用来启动 flink 这个服务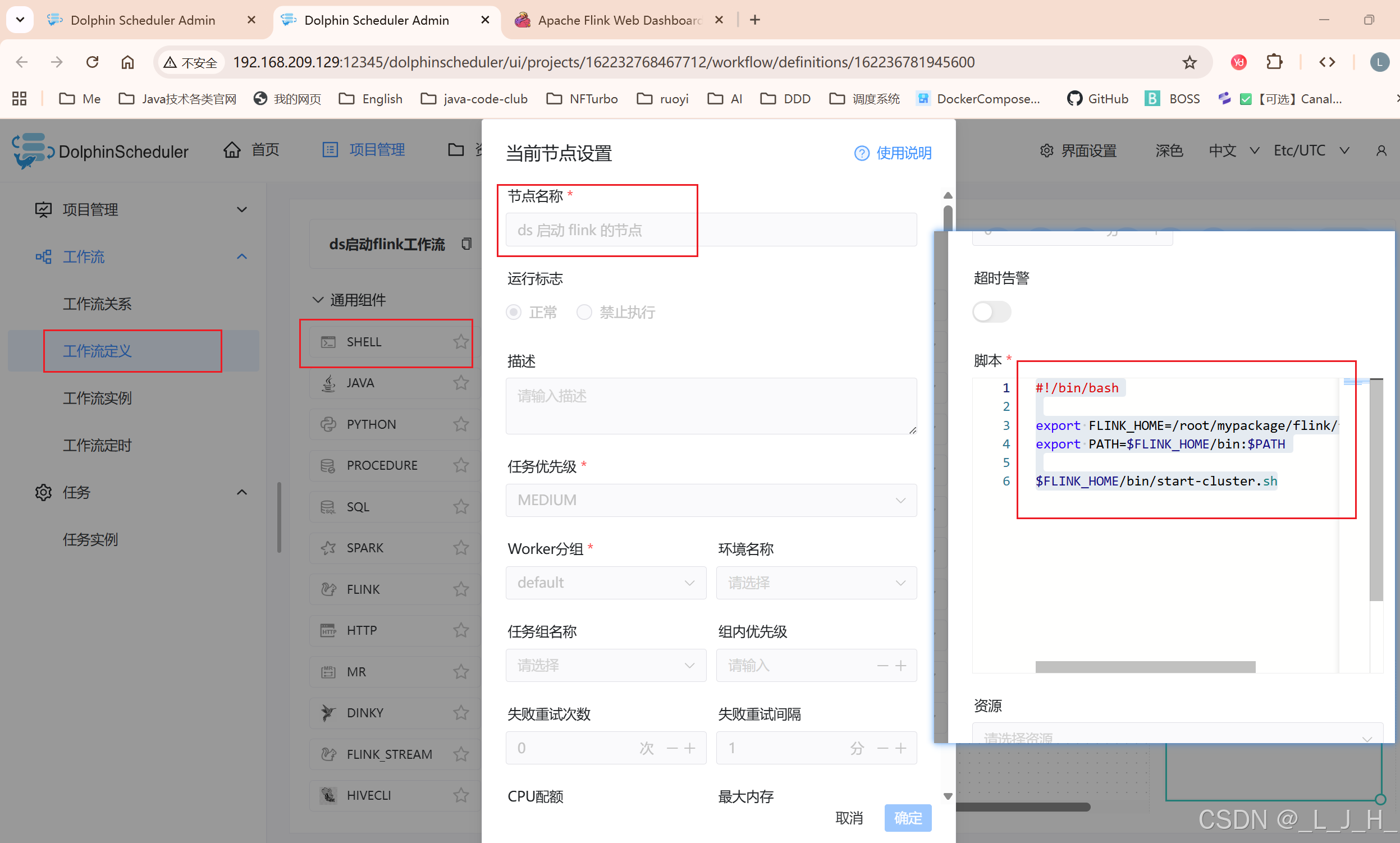
#!/bin/bash
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$FLINK_HOME/bin:$PATH
$FLINK_HOME/bin/start-cluster.sh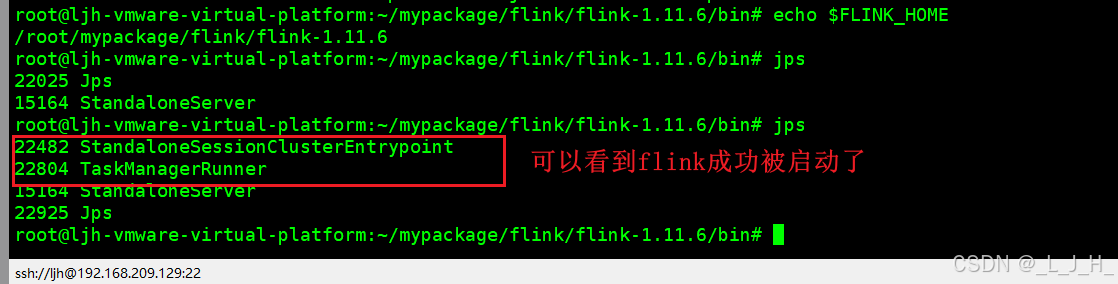
执行shell启动flink的脚本后,网站也能正常访问了,如果没执行这个启动脚本,这个是访问不了的,因为上面已经先关闭了。
4、拷贝jar包
因为flink重启数据会丢失,还没有做持久化下,我这里先将jar保存到我宿主机的某个路径下先。
找一下这个jar在哪
find /tmp -name "*.jar" | grep flink
拷贝到我指定的目录下
sudo cp \
/tmp/flink-web-de67d8e4-ca98-46da-94f2-fc7068d3175d/flink-web-upload/94009e26-fcd1-4d8a-a5f8-fbcd95a5f1cc_kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar \
/root/mypackage/my-jars/kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar
755 给 目录 的权限,644 给 文件(jar) 的权限,root 拥有完全控制权,其他用户只能读目录和文件,不能改
chmod 755 /root/mypackage/my-jars
chmod 644 /root/mypackage/my-jars/kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar5、命令执行 running jobs 提交作业操作
现在虚拟机尝试能不能提交jar到flink去执行,相当于在web界面上传jar+submit new job 的操作
flink run -d -c ljh.kafka.consumer.FlinkKafkaConsumerExample /root/mypackage/my-jars/kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar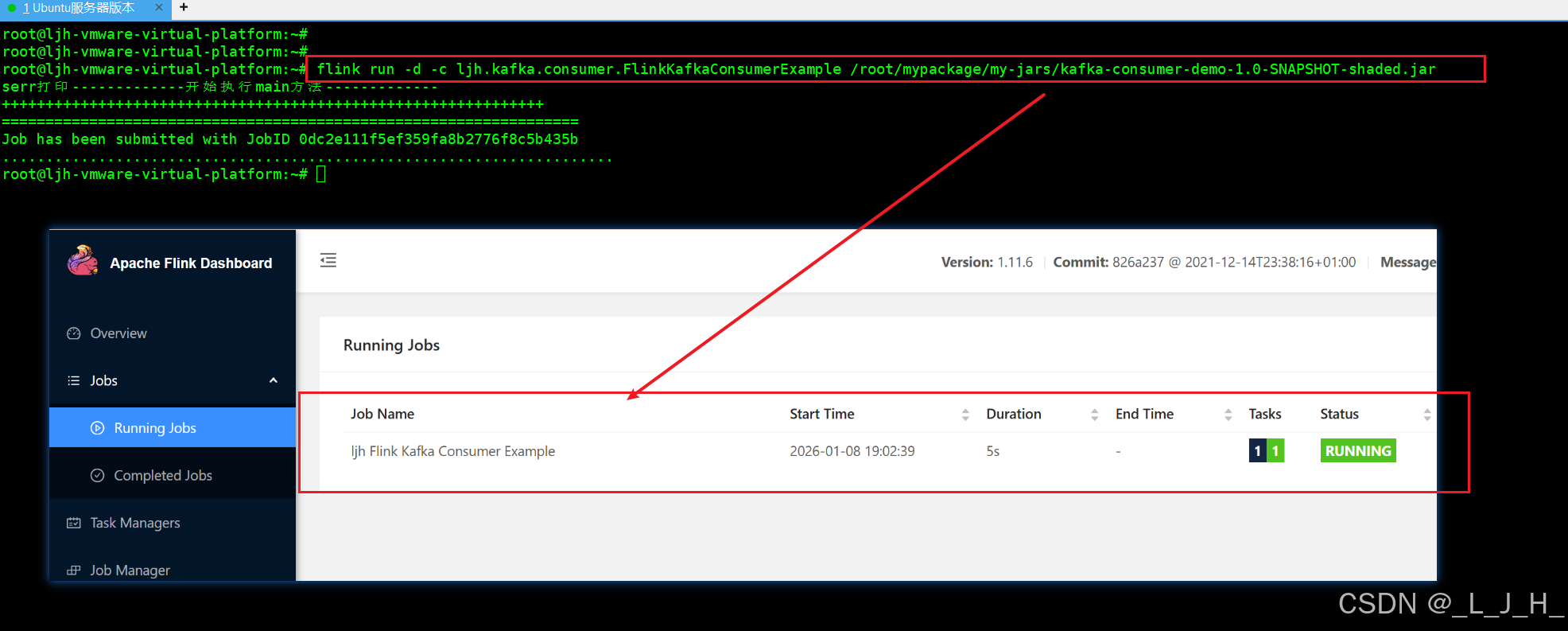
6、用 dolphinscheduler 的shell脚本让 flink 执行 running jobs 操作
如图,在dolphinscheduler中通过执行shell脚本,在命令行提交一个 Flink 作业(Job)
这个脚本就相当于我们在web界面 ->1、先上传jar包,2、然后执行 submit new job 操作
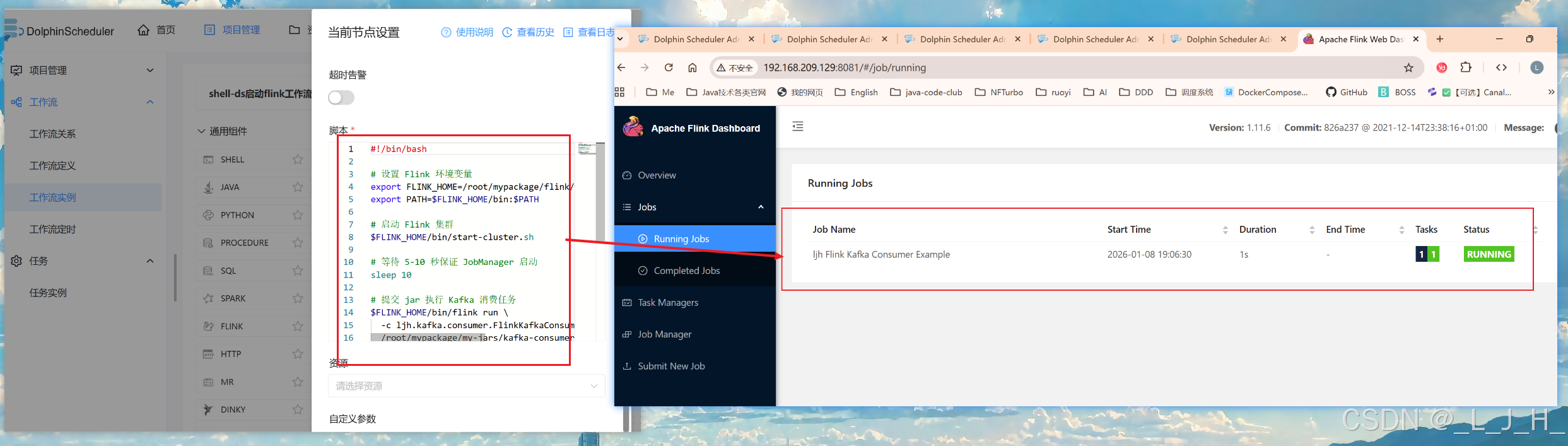
#!/bin/bash
# 设置 Flink 环境变量
export FLINK_HOME=/root/mypackage/flink/flink-1.11.6
export PATH=$FLINK_HOME/bin:$PATH
# 启动 Flink 集群
$FLINK_HOME/bin/start-cluster.sh
# 等待 5-10 秒保证 JobManager 启动
sleep 10
# 提交 jar 执行 Kafka 消费任务
$FLINK_HOME/bin/flink run \
-c ljh.kafka.consumer.FlinkKafkaConsumerExample \
/root/mypackage/my-jars/kafka-consumer-demo-1.0-SNAPSHOT-shaded.jar可以看到能正常消费kafka的消息。
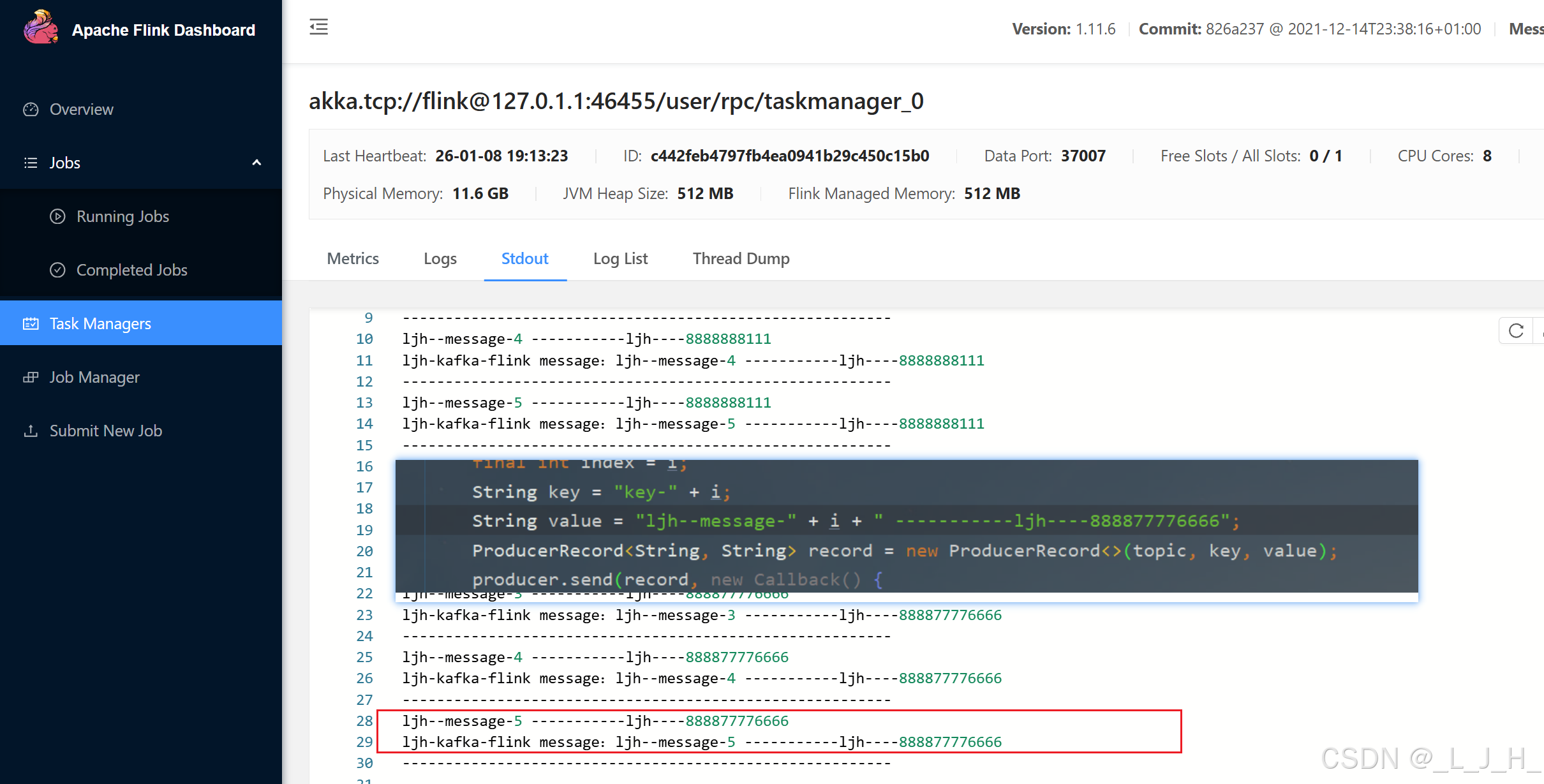
我多次执行脚本,就出现多个 task ,然后当我用生产者发送消息时,只有其中一个task去执行消息消费,没有出现多个task重复执行消息的情况出现。
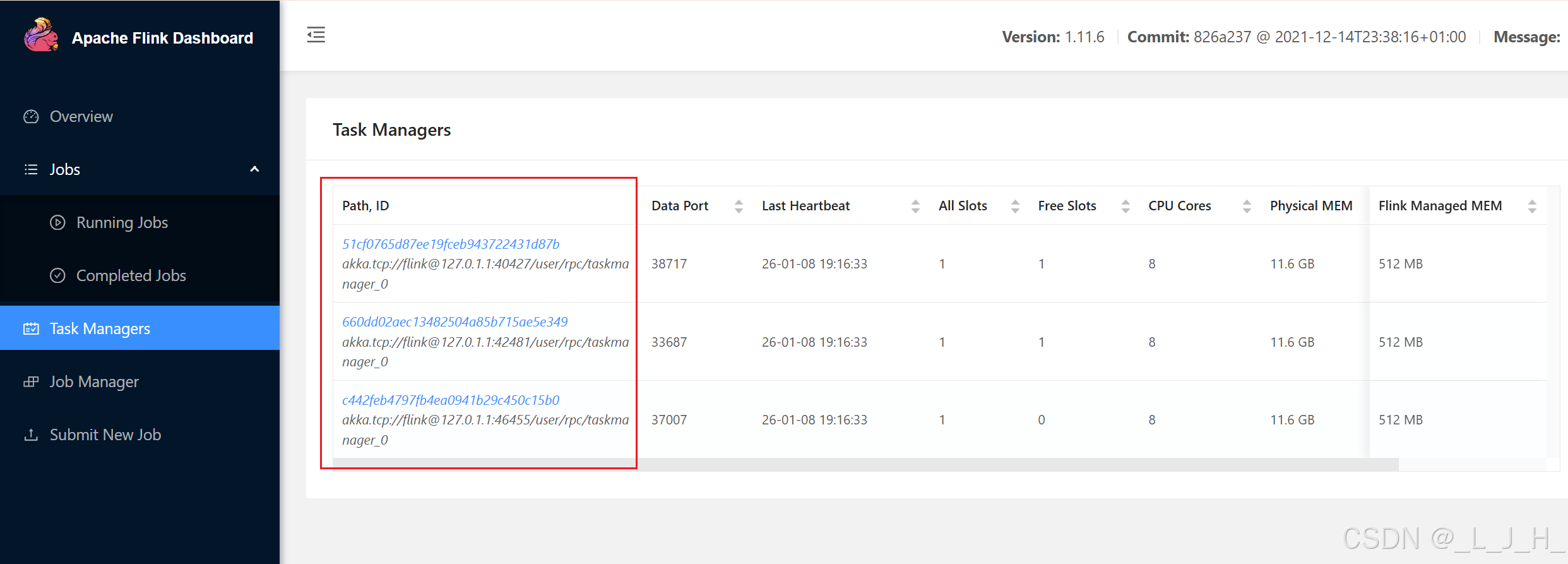
总结
现在就是能通过 dolphinscheduler 创建一个工作流,执行一个shell脚本,用来启动flink服务进程,然后让 flink能到指定的位置找到jar包(消费kafka消息的代码),然后提交一个 Flink 作业(Job)。
接着我用生产者发送消息,能成功看到其中一个 task 执行jar包中的代码,也就是消费消息。