原文:"Foundation models are general models of language, vision, speech, and/or other modalities that are designed to support a large variety of AI tasks. They form the basis of many modern AI systems."
解释: 基础模型是支持语言、视觉、语音等多模态任务的核心,现代许多AI系统都基于这些模型构建。
Llama 3模型的特点 :
原文:"The Llama 3 Herd of models natively supports multilinguality, coding, reasoning, and tool usage. Our largest model is dense Transformer with 405B parameters, processing information in a context window of up to 128K tokens."
原文:"We start by converting a large, multilingual text corpus to discrete tokens and pre-training a large language model (LLM) on the resulting data to perform next-token prediction."
解释: Llama 3的预训练使用了大量的多语言文本语料,模型的任务是预测下一个Token。
上下文窗口的扩展 :
原文:"We pre-train a model with 405B parameters on 15.6T tokens using a context window of 8K tokens. This standard pre-training stage is followed by a continued pre-training stage that increases the supported context window to 128K tokens."
原文:"We align the model with human feedback in several rounds, each of which involves supervised finetuning (SFT) on instruction tuning data and Direct Preference Optimization (DPO; Rafailov et al., 2024)."
"We create our dataset for language model pre-training from a variety of data sources containing knowledge until the end of 2023. We apply several de-duplication methods and data cleaning mechanisms on each data source to obtain high-quality tokens. We remove domains that contain large amounts of personally identifiable information (PII), and domains with known adult content." 我们从包含截至2023年底知识的各种数据源中创建了用于语言模型预训练的数据集。我们对每个数据源应用了多种重复数据删除方法和数据清理机制,以获得高质量的标记。我们删除了包含大量个人身份信息(PII)的域名,以及已知包含成人内容的域名。
"We implement filters designed to remove data from websites are likely to contain unsafe content or high volumes of PII, domains that have been ranked as harmful according to a variety of Meta safety standards, and domains that are known to contain adult content." 我们实施了过滤器,旨在删除来自可能包含不安全内容或大量个人身份信息(PII)的网站的数据,这些域名根据Meta的多项安全标准被评为有害,或已知包含成人内容的域名。
"To obtain a high-quality language model, it is essential to carefully determine the proportion of different data sources in the pre-training data mix. Our main tools in determining this data mix are knowledge classification and scaling law experiments." 为了获得高质量的语言模型,必须仔细确定预训练数据集中不同数据源的比例。我们确定这一数据组合的主要工具是知识分类和扩展定律实验。
"Empirically, we find that annealing (see Section 3.4.3) on small amounts of high-quality code and mathematical data can boost the performance of pre-trained models on key benchmarks." 根据实证结果,我们发现对少量高质量的代码和数学数据进行退火(见第3.4.3节)可以提升预训练模型在关键基准测试中的表现。
"Llama 3 uses a standard, dense Transformer architecture (Vaswani et al., 2017). It does not deviate significantly from Llama and Llama 2 (Touvron et al., 2023a,b) in terms of model architecture; our performance gains are primarily driven by improvements in data quality and diversity as well as by increased training scale." Llama 3使用了标准的密集Transformer架构(Vaswani等人,2017)。在模型架构方面,它与Llama和Llama 2(Touvron等人,2023a,b)没有显著差异;我们的性能提升主要得益于数据质量和多样性的改进以及训练规模的增加。
"We use grouped query attention (GQA; Ainslie et al. (2023)) with 8 key-value heads to improve inference speed and to reduce the size of key-value caches during decoding." 我们使用了分组查询注意力(GQA;Ainslie等人,2023),其中包含8个键值头,以提高推理速度并减少解码过程中键值缓存的大小。
"We use an attention mask that prevents self-attention between different documents within the same sequence. We find that this change had limited impact during in standard pre-training, but find it to be important in continued pre-training on very long sequences."我们使用了一种注意力掩码,防止同一序列内不同文档之间的自注意力机制。我们发现这种改变在标准预训练过程中影响有限,但在对非常长的序列进行持续预训练时,这一改变显得至关重要。
"We use a vocabulary with 128K tokens. Our token vocabulary combines 100K tokens from the tiktoken3 tokenizer with 28K additional tokens to better support non-English languages. " 我们使用了包含128K标记的词汇表。我们的词汇表结合了来自tiktoken3分词器的100K标记,并添加了28K个额外标记,以更好地支持非英语语言。
"We increase the RoPE base frequency hyperparameter to 500,000. This enables us to better support longer contexts; Xiong et al. (2023) showed this value to be effective for context lengths up to 32,768." 我们将RoPE(旋转位置编码)的基频超参数增加到500,000。这使我们能够更好地支持更长的上下文长度;Xiong等人(2023)表明该值在支持长度达32,768的上下文时非常有效。
调整RoPE参数使得模型在处理长上下文时表现更加高效,并且能够处理更长的序列。
Infrastructure, Scaling, and Efficiency
1. 概括:
在"Infrastructure, Scaling, and Efficiency"部分,作者重点讲述了Llama 3模型在训练过程中使用的基础设施、扩展方法和效率优化。
这部分内容深入探讨了如何在大规模计算资源上高效训练模型,以及在GPU集群上实现并行计算的策略。
2. 详细讲解与观点:
(a) 基础设施配置:
Llama 3的训练使用了 大规模的GPU集群 进行加速,特别是Meta的生产集群和GPU资源。
这些集群能够为训练提供强大的计算能力,确保Llama 3在训练规模和计算需求上的支持。
论文观点:
"Llama 3 405B is trained on up to 16K H100 GPUs, each running at 700W TDP with 80GB HBM3, using Meta's Grand Teton AI server platform (Matt Bowman, 2022). "
"Tectonic (Pan et al., 2021), Meta's general-purpose distributed file system, is used to build a storage fabric (Battey and Gupta, 2024) for Llama 3 pre-training. It offers 240 PB of storage out of 7,500 servers equipped with SSDs, and supports a sustainable throughput of 2 TB/s and a peak throughput of 7 TB/s." Tectonic(Pan等人,2021),Meta的通用分布式文件系统,被用于构建Llama 3预训练的存储结构(Battey和Gupta,2024)。它提供了240 PB的存储容量,由7500台配备SSD的服务器组成,支持每秒2 TB的持续吞吐量和每秒7 TB的峰值吞吐量。
"Llama 3 405B used RDMA over Converged Ethernet (RoCE) fabric based on the Arista 7800 and Minipack2 Open Compute Project4 OCP rack switches. Smaller models in the Llama 3 family were trained using Nvidia Quantum2 Infiniband fabric." Llama 3 405B模型使用了基于Arista 7800和Minipack2开放计算项目(OCP)机架交换机的收敛以太网远程直接内存访问(RDMA over Converged Ethernet, RoCE)网络结构。Llama 3家族中的较小模型则使用了Nvidia Quantum2 InfiniBand网络结构进行训练。
网络架构的选择使得模型可以高效地在多个GPU之间进行通信,大幅降低了计算延迟,提升了整体训练速度。
(d) 负载均衡与流量优化:
在大规模集群中,负载均衡是一个重要挑战。
Llama 3采用了一些特定的优化技术来解决集群中的通信负载均衡问题。
论文观点:
"LLM training produces fat network flows that are hard to load balance across all available network paths using traditional methods"
"we employ two techniques. First, our collective library creates 16 network flows between two GPUs, instead of just one, thereby reducing the traffic per flow and providing more flows for load balancing."
"We use 4D parallelism---a combination of four different types of parallelism methods---to shard the model. This approach efficiently distributes computation across many GPUs and ensures each GPU's model parameters, optimizer states, gradients, and activations fit in its HBM." 我们使用了4D并行,这是一种结合了四种不同类型的并行方法来分片模型的技术。这种方法能够高效地将计算分布到多个GPU上,并确保每个GPU的模型参数、优化器状态、梯度和激活值都能适应其高带宽内存(HBM)。
"Through careful tuning of the parallelism configuration, hardware, and software, we achieve an overall BF16 Model FLOPs Utilization (MFU; Chowdhery et al. (2023)) of 38-43% for the configurations shown in Table 4." 通过对并行配置、硬件和软件的精心调优,我们在表4所示的配置中实现了整体BF16模型浮点运算(Model FLOPs Utilization,MFU;Chowdhery等人,2023)38-43%的利用率。
通过这些调优,Llama 3在大规模集群上能够更高效地进行计算,从而节省了训练时间和资源。
Training Recipe
Training Recipe"(训练食谱)部分,作者介绍了Llama 3模型的预训练过程,具体描述了训练的各个阶段,包括初始预训练、长上下文预训练和退火阶段。
"We pre-train Llama 3 405B using AdamW with a peak learning rate of 8 × 10−5 ; a linear warm up of 8,000 steps, and a cosine learning rate schedule decaying to 8 × 10−7 over 1,200,000 steps." 我们使用AdamW优化器对Llama 3 405B进行预训练,峰值学习率为8 × 10⁻⁵;线性预热8000步,余弦学习率调度在1,200,000步内衰减至8 × 10⁻⁷。
"In the final stages of pre-training, we train on long sequences to support context windows of up to 128K tokens." 在预训练的最后阶段,我们使用长序列进行训练,以支持最多128K标记的上下文窗口。
"we increased context length gradually in six stages, starting from the original 8K context window and ending in the final 128K context window." 我们将上下文长度分为六个阶段逐步增加,从最初的8K上下文窗口开始,最终达到128K上下文窗口。
"We first train a reward model on top of the pre-trained checkpoint using human-annotated preference data (see Section 4.1.2). We then finetune pre-trained checkpoints with supervised finetuning (SFT; see Section 4.1.3), and further align the checkpoints with Direct Preference Optimization (DPO; see Section 4.1.4)." 我们首先使用人工标注的偏好数据(见第4.1.2节)在预训练检查点的基础上训练奖励模型。随后,我们通过监督微调(SFT,见第4.1.3节)对预训练检查点进行精调,并进一步使用直接偏好优化(DPO,见第4.1.4节)对检查点进行对齐。
"Together with this rejection-sampled data and other data sources (including synthetic data), we finetune the pre-trained language model using a standard cross entropy loss on the target tokens (while masking loss on prompt tokens)." 结合这些通过拒绝采样获得的数据以及其他数据源(包括合成数据),我们使用目标标记上的标准交叉熵损失来对预训练语言模型进行微调(同时对提示标记进行损失掩码处理)。
"We further train our SFT models with Direct Preference Optimization (DPO; Rafailov et al., 2024) for human preference alignment." 我们进一步使用直接偏好优化(DPO;Rafailov等人,2024)对我们的SFT模型进行训练,以实现与人类偏好的对齐。
"During rejection sampling (RS), for each prompt collected during human annotation (Section 4.2.1) we sample K (typically between 10 and 30) outputs from the latest chat model policy"
"use our reward model to select the best candidate" 在拒绝采样(RS)过程中,对于每个在人工标注期间收集的提示(见第4.2.1节),我们从最新的聊天模型策略中采样K个输出(通常在10到30个之间)。
"we evaluate Llama 3 on a large number of standard benchmark evaluations shown in Table 8. These evaluations cover eight top-level categories: (1) commonsense reasoning; (2) knowledge; (3) reading comprehension; (4) math, reasoning, and problem solving; (5) long context; (6) code; (7) adversarial evaluations; and (8) aggregate evaluations." 我们在表8中展示了对Llama 3的大量标准基准测试评估。这些评估涵盖了八个顶级类别:(1)常识推理;(2)知识;(3)阅读理解;(4)数学、推理和问题解决;(5)长上下文;(6)代码;(7)对抗性评估;(8)综合评估。
"we train the model using 6B image-text pairs where each image is resized to fit within four tiles of 336 × 336 pixels. We use a global batch size of 16,384 and a cosine learning rate schedule with initial learning rate 10 × 10−4 and a weight decay of 0:01." 我们使用了60亿对图像-文本数据对进行模型训练,其中每张图像都被调整大小以适应四块336 × 336像素的网格。我们采用全局批量大小为16,384,使用余弦学习率调度,初始学习率为10 × 10⁻⁴,并设置权重衰减为0.01。
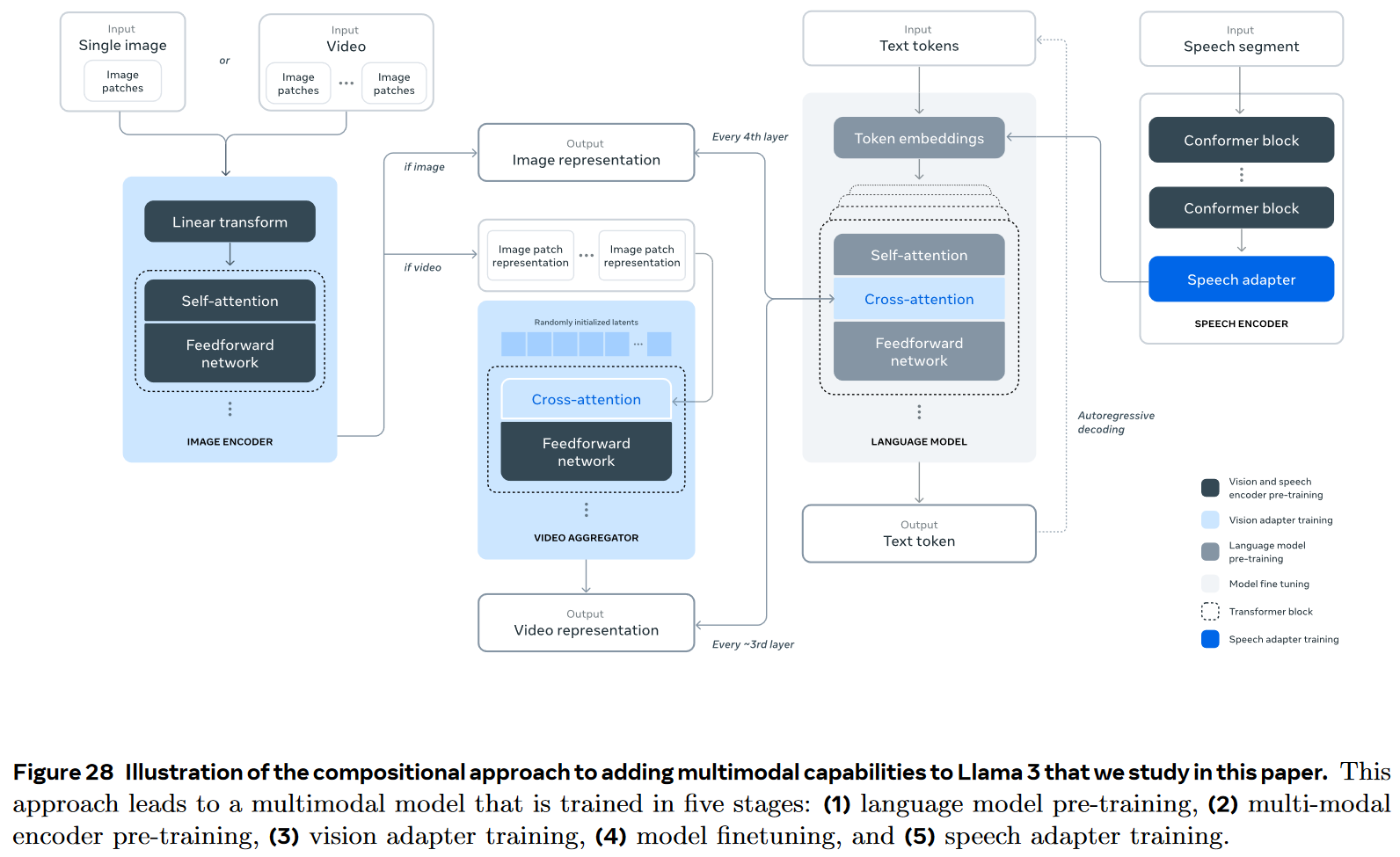
"For video pre-training, we start from the image pre-trained and annealed weights as described above. We add the video aggregator and cross-attention layers as described in the architecture, initialized randomly."
"We uniformly sample 16 frames from the full video, and represent each frame using four chunks, each of size of 448 × 448 pixels."
"A compositional approach to foundation model development has several advantages: (1) it enables us to parallelize the development of the vision and language modeling capabilities; (2) it circumvents complexities of joint pre-training on visual and language data that stem from tokenization of visual data, differences in background perplexities of tokens originating from different modalities, and contention between modalities; (3) it guarantees that model performance on text-only tasks is not affected by the introduction of visual-recognition capabilities, and (4) the cross-attention architecture ensures that we do not have to expend compute passing full-resolution images through the increasingly LLM backbones (specifically, the feed-forward networks in each transformer layer), making it more efficient during inference. "
"We construct this dataset via a complex data processing pipeline that consists of four main stages: (1) quality filtering, (2) perceptual de-duplication, (3) resampling, and (4) optical character recognition."
论文原文: "On the input side, the speech module consists of two successive modules: a speech encoder and an adapter. The output of the speech module is directly fed into the language model as token representation, enabling direct interaction between speech and text tokens." 在输入端,语音模块由两个连续的模块组成:语音编码器和适配器。语音模块的输出被直接作为标记表示输入到语言模型中,从而实现语音和文本标记之间的直接交互。
论文原文: "To enhance the naturalness and expressiveness of synthesized speech, we integrate a decoder-only Transformer-based Prosody model (PM) (Radford et al., 2021) that takes the Llama 3 embeddings as an additional input. This integration leverages the linguistic capabilities of Llama 3" 为了增强合成语音的自然性和表现力,我们集成了一个仅解码器的基于Transformer的韵律模型(Prosody Model, PM)(Radford等人,2021),该模型将Llama 3的嵌入作为额外的输入。此集成利用了Llama 3的语言能力。
论文原文: "As shown in Table 35, the Llama 3 8B PM is preferred 60% of the time compared to the streaming baseline, and 63.6% of the time compared to the non-streaming baseline, indicating a significant improvement in perceived quality." 如表35所示,与流式基线相比,Llama 3 8B韵律模型(PM)在60%的情况下被偏好,且与非流式基线相比,在63.6%的情况下被偏好,这表明在感知质量上有显著提升。
"Llama 3 follows the enduring trend of applying straightforward methods at ever increasing scales in foundation models. Improvements are driven by increased compute and improved data, with the 405B model using almost fifty times the pre-training compute budget of Llama 2 70B". Llama 3遵循了在基础模型中应用简单方法并不断扩大规模的长期趋势。其改进主要由计算能力的增加和数据质量的提升驱动,405B模型的预训练计算预算几乎是Llama 2 70B的五十倍。
"Developments in smaller models have paralleled those in large models. Models with fewer parameters can dramatically improve inference cost and simplify deployment". 小模型的发展与大模型的发展并行。参数较少的模型可以显著降低推理成本,并简化部署过程。
"Llama 3 outperforms these models, suggesting that dense architectures are not the limiting factor, but there remain numerous trade offs in terms of training and inference efficiency, and model stability at scale."Llama 3 的表现优于这些模型,表明密集架构不是限制因素,但在训练和推理效率以及大规模模型稳定性方面仍然存在许多权衡。
"Open weights foundation models have rapidly improved over the last year, with Llama3-405B now competitive with the current closed weight state-of-the-art."开源权重的基础模型在过去一年中迅速提升,Llama 3-405B现已能够与当前闭源权重的最先进模型相媲美。
"Post-training Llama 3 follows the established strategy of instruction tuning (Chung et al., 2022; Ouyang et al., 2022) followed by alignment with human feedback (Kaufmann et al., 2023)." Llama 3的后训练阶段遵循了既定的策略,即先进行指令微调(Chung等人,2022;Ouyang等人,2022),然后通过与人类反馈对齐(Kaufmann等人,2023)。
"Our experience in developing Llama 3 suggests that substantial further improvements of these models are on the horizon. Throughout the development of the Llama 3 model family, we found that a strong focus on high-quality data, scale, and simplicity consistently yielded the best results". 我们在开发Llama 3的过程中发现,这些模型在未来仍有巨大的改进空间。在Llama 3模型家族的开发过程中,我们发现对高质量数据、规模和简化的强烈关注始终带来了最佳结果。
"To ensure Llama 3 is not accidentally overfitted on commonly used benchmarks, our pre-training data was procured and processed by a separate team that was strongly incentivized to prevent contamination of that pre-training data with external benchmarks". 为了确保Llama 3不会在常用基准测试上意外过拟合,我们的预训练数据由一个独立的团队采购和处理,该团队有强烈的激励措施来防止预训练数据被外部基准测试污染。
"We believe that the public release of foundation models plays a key role in the responsible development of such models, and we hope that the release of Llama 3 encourages the industry to embrace the open, responsible development of AGI". 我们相信,基础模型的公开发布在这些模型的负责任开发中发挥着关键作用,我们希望Llama 3的发布能够鼓励业界拥抱开放、负责任的AGI(通用人工智能)开发。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
这里的 1 d k \frac{1}{\sqrt{d_k}} dk 1是缩放因子,避免点积值过大,导致softmax梯度消失问题。软最大值函数:
softmax ( z i ) = e z i ∑ j e z j \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} softmax(zi)=∑jezjezi
MultiHead ( Q , K , V ) = Concat ( head 1 , ... , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W_O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
这里的每个 head i \text{head}_i headi都是一个独立的注意力机制结果,最终通过权重矩阵 W O W_O WO线性变换得到输出。
Llama 3 的训练过程中采用了AdamW 优化器,它是经典 Adam 算法的一个变种,增加了权重衰减(weight decay)的正则化,帮助防止过拟合。AdamW 的数学原理基于梯度下降,但其具体计算方式如下:
Adam 优化器的更新公式:Adam 通过计算梯度的一阶动量和二阶动量来更新参数,其核心公式为:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
m t ^ = m t 1 − β 1 t , v t ^ = v t 1 − β 2 t \hat{m_t} = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v_t} = \frac{v_t}{1 - \beta_2^t} mt^=1−β1tmt,vt^=1−β2tvt
θ t = θ t − 1 − α m t ^ v t ^ + ϵ \theta_t = \theta_{t-1} - \alpha \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} θt=θt−1−αvt^ +ϵmt^
其中, m t m_t mt和 v t v_t vt分别是一阶和二阶动量的估计值, α \alpha α是学习率, θ t \theta_t θt是模型参数。
在深度学习模型中,尤其是像 Llama 3 这样的大型语言模型,矩阵乘法是最耗时和资源密集的操作之一。为了提高计算效率,Llama 3 在某些操作中可能采用了矩阵分解 (Matrix Factorization)技术。矩阵分解将一个大型稠密矩阵分解为两个或多个较小的矩阵,降低了计算复杂度。例如,给定一个矩阵 A A A,它可以分解为两个更小的矩阵 B B B和 C C C,使得 A ≈ B × C A \approx B \times C A≈B×C。这种方法减少了乘法操作的总次数,特别是在使用大量参数的情况下。
自回归模型的时间复杂度 :在处理长序列时,传统的 Transformer 模型的时间复杂度为 O ( n 2 ) O(n^2) O(n2)(其中 n n n 是序列长度),因为每个 token 与序列中的每个其他 token 都需要计算注意力权重。Llama 3 通过分层次的自注意力机制或通过稀疏注意力机制来降低这一复杂度,减少不必要的计算。
多模态嵌入空间的构建 :在多模态学习中,模型需要将不同模态的数据(如图像、语音、文本)映射到同一个嵌入空间。假设输入图像的特征向量为 v img v_{\text{img}} vimg,输入文本的特征向量为 v txt v_{\text{txt}} vtxt,模型需要学习一个映射 f f f,使得 f ( v img ) ≈ f ( v txt ) f(v_{\text{img}}) \approx f(v_{\text{txt}}) f(vimg)≈f(vtxt)。这种映射通常通过对比学习(Contrastive Learning)来实现,其目标是最小化同一模态下特征的距离,同时最大化不同模态下特征的距离:
L = − log exp ( f ( v img ) ⋅ f ( v txt ) / τ ) ∑ i exp ( f ( v img ) ⋅ f ( v txt ( i ) ) / τ ) L = - \log \frac{\exp(f(v_{\text{img}}) \cdot f(v_{\text{txt}}) / \tau)}{\sum_{i} \exp(f(v_{\text{img}}) \cdot f(v_{\text{txt}}^{(i)}) / \tau)} L=−log∑iexp(f(vimg)⋅f(vtxt(i))/τ)exp(f(vimg)⋅f(vtxt)/τ)