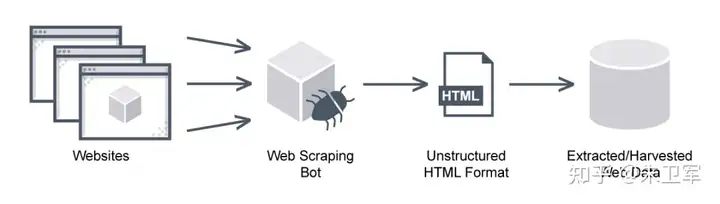
如果你是自己做爬虫脚本开发,那确实难,因为你需要掌握Python、HTML、JS、xpath、database等技术,而且还要处理反爬、动态网页、逆向等情况,不然压根不知道怎么去写代码,这些技术和经验储备起码得要个三五年。
比如这几个流程是必须的,初学者看着就很头疼。
- **用户代理(User-Agent):**模拟浏览器访问,避免被网站识别为机器人。
- **请求处理:**发送HTTP请求,获取网页内容。
- **内容解析:**使用正则表达式或DOM解析技术提取所需数据。
- **数据存储:**将提取的数据保存到数据库或文件中。
- **错误处理:**处理请求超时、服务器拒绝等异常情况。
其实对于一般非IT行业的人来说,不需要去写代码就可以实现爬虫,因为现在有很多自动化数据抓取软件,只需要调整一些参数配置就可以,比如web scraper、八爪鱼、亮数据等。
八爪鱼爬虫
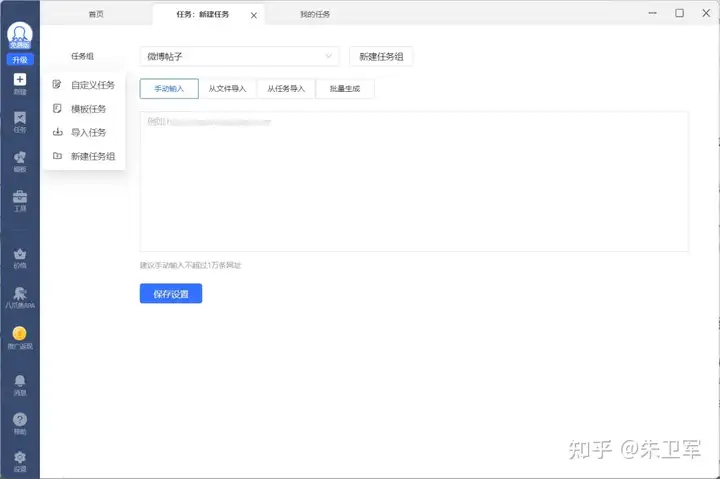
八爪鱼爬虫是一款功能强大的桌面端爬虫软件,主打可视化操作,即使是没有任何编程基础的用户也能轻松上手。
官网:https://affiliate.bazhuayu.com/csdnzwj
八爪鱼支持多种数据类型采集,包括文本、图片、表格等,并提供强大的自定义功能,能够满足不同用户需求。此外,八爪鱼爬虫支持将采集到的数据导出为多种格式,方便后续分析处理。
主要优势:
- 可视化界面:拖拽式操作,无需编写代码,即使是新手也能快速上手
- 数据类型丰富:支持文本、图片、表格、HTML等多种数据类型采集
- 自定义功能强:支持自定义采集规则、数据处理逻辑等,满足个性化需求
- 数据导出方便:支持CSV、Excel、JSON等多种数据格式导出
使用方法:
- 下载并安装八爪鱼爬虫软件
- 打开要采集数据的目标网页
- 使用鼠标选中要采集的数据区域
- 在软件界面设置采集规则,包括数据类型、保存路径等
- 点击"开始采集"按钮,即可获取数据
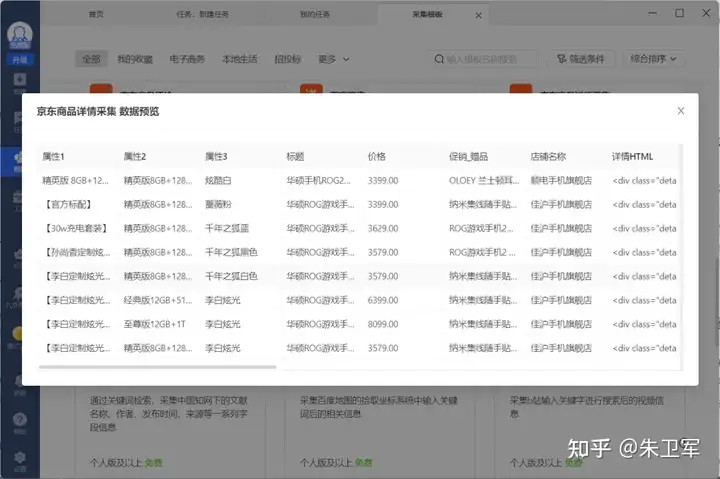
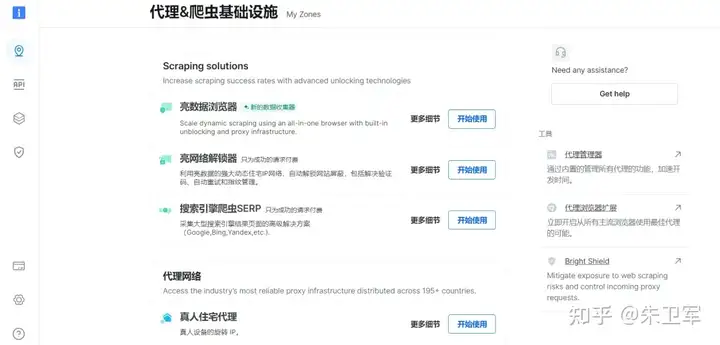
亮数据爬虫
亮数据平台提供了强大的数据采集工具,比如Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
网站:https://get.brightdata.com/weijun
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

另外,亮数据浏览器内置了自动网站解锁功能,能够应对各种反爬虫机制,确保数据的顺利抓取。它能兼容多种自动化工具,如Puppeteer、Playwright和Selenium等,用户可以根据需求选择合适的工具进行数据抓取。
主要优势:
- 平台化操作:无需搭建服务器,可直接在平台上创建、管理爬虫任务
- 数据源丰富:支持网页、API、数据库等多种数据源
- 模板化服务:提供丰富的爬虫模板,快速创建爬虫任务
使用方法:
- 注册亮数据爬虫账号
- 创建爬虫任务,选择数据源
- 选择爬虫模板或编写爬虫代码
- 设置任务参数,包括采集规则、数据存储等
- 点击"启动任务"按钮,即可获取数据
Web Scraper
Web Scraper是一款轻便易用的浏览器插件,用户无需安装额外的软件,即可在Chrome浏览器中进行爬虫。插件支持多种数据类型采集,并可将采集到的数据导出为多种格式。
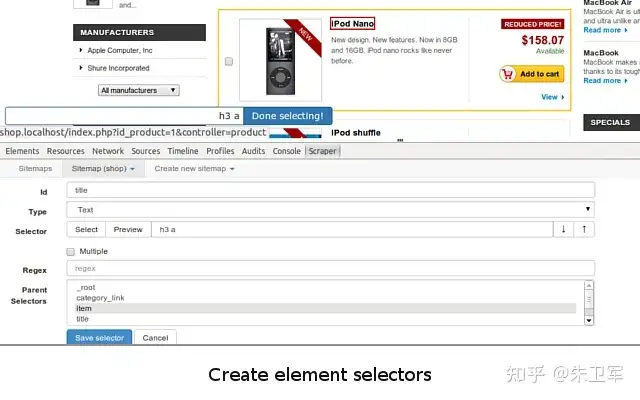
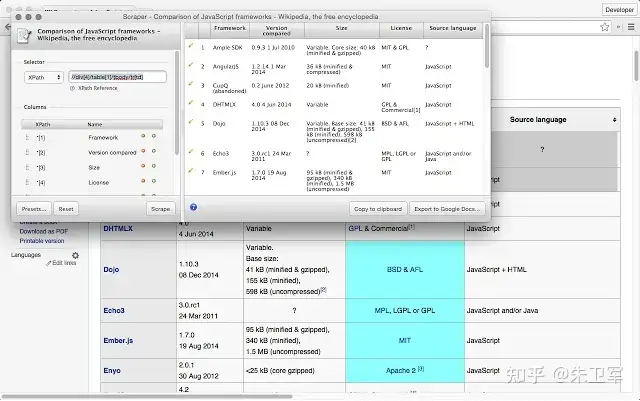
主要优势:
使用方法:
- 安装Web Scraper扩展插件
- 打开要采集数据的目标网页
- 点击扩展插件图标,选择"开始采集"
- 使用鼠标选中要采集的数据区域
- 点击"导出数据"按钮,即可获取数据
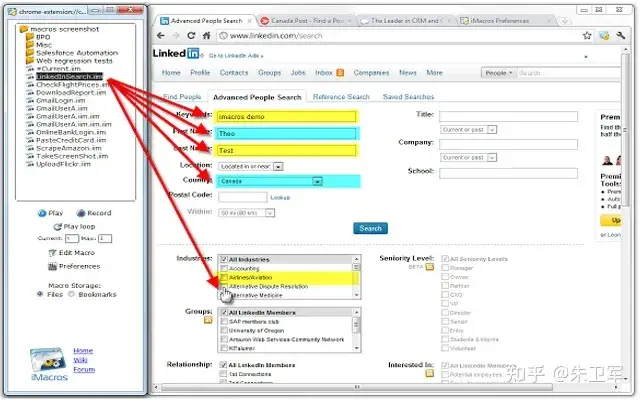
无论是需要简单快速的数据采集,还是复杂的定制化服务,八爪鱼爬虫、亮数据爬虫和Web Scraper都能满足采集需求,对一般人来说也能搞定。
选择合适的工具,能让数据采集变得更加轻松和高效。记得在使用这些工具时,一定要遵守相关网站的爬虫政策和法律法规。