赛题介绍
- 指定的数据集
一、病例行动数据集
- 病例历史行动数据集(训练集1) 1M+
- 确诊病例数据 (测试集1) 500+
- 实时病例行动数据集(测试集2) 1000+
二、天猫精灵行为数据集
- 天猫精灵历史行为数据集(训练集2) 1M+
- 用户行为数据集(测试集3) 500+
- 实时用户行为数据集(测试集4) 1000+
- 四个任务
- 根据测试集1每条数据的特征向量,在训练集1中找出该病例(人)对应的所有记录。
- 对测试集2的每条数据,根据其特征向量进行实时分类(人)。
- 根据测试集3每条数据的特征向量,在训练集2中找出该用户行为(领域+意图)对应的所有记录。
- 对测试集4的每条数据,根据其特征向量进行实时分类(领域+意图)。
- 性能要求
- Job总运行时间不能超过3小时。
- 对每条实时数据完成实时分类的响应时间不能超过500ms。
- 平台和组件
Flink,PyFlink,Flink ai_flow,达摩院 Proxima,Intel Zoo cluster serving
解决方案 - Workflow

解决方案 - Workflow config file
本方案中,代码框架设定了一个目标:对于新增的相似应用的数据集,不修改python代码,只需新增一个workflow config file(yaml文件),根据新数据集的基本属性以及数据结构的特性设置相应的配置即可。
/code/package/wf_config_1.yaml --病例行动数据集对应的配置文件
WORKFLOW_NO: 1
KAFKA_SOLUTION_NO: 2 #1: Use TABLE API for kafka. 2: Use Kafka API
CLUSTER_SERVING_PARALLELISM: 16
PREDICT_WITH_TRAIN_PARALLELISM: 50
INPUT_DIM: 512
ENCODING_DIM: 128
LEARNING_RATE: 0.001
EPOCHS: 1
#MODEL_TYPE: SIMPLE_AUTOENCODER, DEEP_AUTOENCODER
MODEL_TYPE: SIMPLE_AUTOENCODER
MODEL_NAME: camera_auto_encoder
data_set_dir: /tcdata/
output_dir: /opt/result/
train_data_file: train_data.csv
feature_column_no: 3
train_predict_result_dir: camera_predict_result
...
...
create_training_table_sql: create table training_table(
uuid varchar,
face_id varchar,
device_id varchar,
feature_data varchar
) with (
'connector.type' = 'filesystem',
'format.type' = 'csv',
'connector.path' = '{}',
'format.ignore-first-line' = 'false',
'format.field-delimiter' = ';'
)
create_merge_table_sql: create table merge_table(
uuid varchar,
.../code/package/wf_config_2.yaml --天猫精灵行为数据集对应的配置文件
WORKFLOW_NO: 2
KAFKA_SOLUTION_NO: 2 #1: Use TABLE API for kafka. 2: Use Kafka API
CLUSTER_SERVING_PARALLELISM: 16
PREDICT_WITH_TRAIN_PARALLELISM: 64
INPUT_DIM: 700
ENCODING_DIM: 128
LEARNING_RATE: 0.001
EPOCHS: 1
#MODEL_TYPE: SIMPLE_AUTOENCODER, DEEP_AUTOENCODER
MODEL_TYPE: SIMPLE_AUTOENCODER
MODEL_NAME: genie_auto_encoder
data_set_dir: /tcdata/
output_dir: /opt/result/
train_data_file: genie_data.csv
feature_column_no: 2
train_predict_result_dir: genie_predict_result
...
...
create_training_table_sql: create table training_table(
uuid varchar,
action_id varchar,
feature_data varchar
) with (
'connector.type' = 'filesystem',
'format.type' = 'csv',
'connector.path' = '{}',
'format.ignore-first-line' = 'false',
'format.field-delimiter' = ';'
)
create_merge_table_sql: create table merge_table(
uuid varchar,
...解决方案 - Data pre-processing
- 病例行动数据集
不含异常数据,且特征向量已经L2 Normalization,不需要特别的预处理。 - 天猫精灵行为数据集
存在一些异常数据,需要做以下预处理:
- 移除某些特征向量数据末尾多出的空格(注:如果不做相应处理,score3通常得0分)
- Re-generate UUID for duplicated UUID
- Processing zero vector
- Processing duplicated vector
- L2 Normalization
解决方案 - Model training
- Model
- Simple AutoEncoder (实测效果好,稳定,性能好,采用)
- Deep AutoEncoder(实测效果好,性能一般,最终未采用)
- VAE (Variational AutoEncoder) (实测效果相对较差,未采用)
- PCA (Principal Component Analysis) (实测效果相对较差,未采用)
- NMF (Non-negative matrix factorization) (实测效果相对较差,未采用)
模型关键参数
- 损失函数:MSE
- 激活函数:linear
降维的维度选择
- 病例行动数据集:512=>128
- 天猫精灵行为数据集:700=>128
解决方案 - Inference
- Intel Zoo Cluster Serving
- 支持Tensorflow Saved Model 以及PyTorch Model for Inference
- 支持并发Inference(本赛题设置为16个并发),在多并发下运行稳定
- 模型针对CPU做了优化,无需GPU环境
- 自动生成配置,方便部署
- 响应时间短。平均每个请求响应时间实测小于35ms,充分满足本方案中的性能需求。
向量索引和向量检索
- 阿里达摩院proxima
- 使用Proxima HnswBuilder 创建索引,使用HnswSearch search vector
- 支持海量数据向量检索
- 召回率高,Top100 召回率超过98.5%
- 检索性能高,在本赛题中,平均每个请求(TopK=1024)的响应时间小于3ms,完全满足TopK筛选+再聚类这样类型的应用需求,对于实时的向量检索也毫无压力。
解决方案 - 聚类算法
- 针对历史行动数据的聚类
- 根据指定要search的vector,Topk=1024,通过Proxima search 出1024个UUIDs只是作为初步筛选的UUIDs。再使用Pandas查出它们对应的vectors,然后将这些vectors和指定search的那个vector合并为1025个vectors。
- 使用聚类算法Chinese_Whispers,对上述1025个vectors进行聚类分组后,取出和指定vector属于相同组的所有vectors所对应的UUIDs输出。Chinese_Whispers算法对于病例行动数据集效果最好。
- 另外尝试了K-Means,发现基本不可行。尝试了DBSCAN聚类算法,可行,但效果不如Chinese Whispers。
- 针对天猫精灵的数据集,还尝试了一种简单算法:Topk=128,从search出的128个UUIDs中根据result.score(),设置一个阈值,将result.score()<阈值的UUIDs全部输出。该实际评分效果要略微优于Chinese_Whispers。
- 其它一些常见的聚类算法以及较新的GCN(Graph Convolutional Network),因时间关系,计划赛后继续尝试。
- 针对实时行动数据的实时分类
- 根据指定的vector,search Top1 UUID。
- 直接使用Top1 UUID 作为分类label输出。(注:用此分类方法+合适的模型+online data处理不超时,score2可得满分500分)
聚类算法 - Chinese_Whispers
-
算法流程
1 初始化:将所有的样本点初始化为不同的类。
2 建图:构建无向图,以每个节点为一个类别,不同节点之间计算相似度,当相似度超过threshold,将两个节点相连形成关联边,边的权重为相似度。
3 迭代:
3.1 随机选取一个节点i开始,在其相连节点中选取边权重最大者j,并将i归为节点j类(若相连节点中有多个节点属于同一类,则将这些权重相加再做比较)
3.2 遍历所有节点后,重复迭代至满足迭代次数。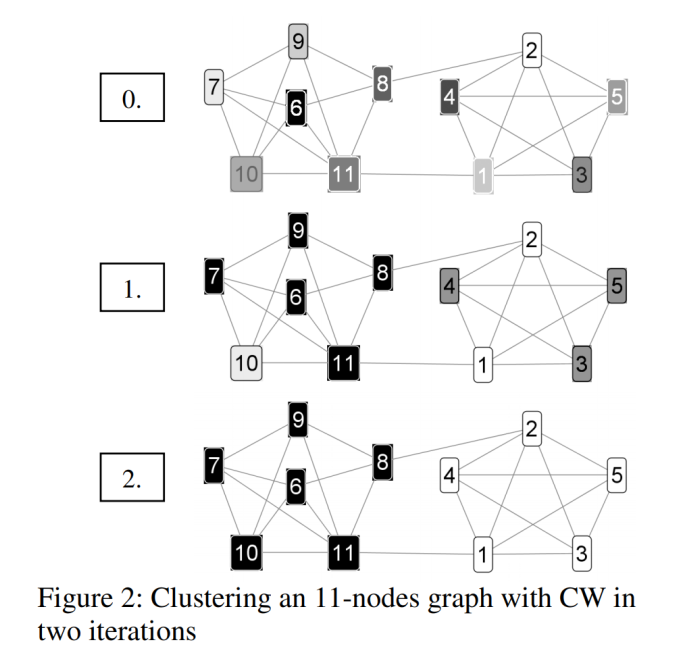
解决方案 -- 解决Online Data (Kafka) 超时的问题
- 方法一、使用ai_flow 内建的算子
1 使用ai_flow.read_example、ai_flow.predict、ai_flow.transform和ai_flow.write_example
2 在其中的SourceExecutor/SinkExecutor实现类中使用PyFlink TABLE API(For Kafka) 读/写Kafka Topic
3 为相应Flink job的StreamExecutionEnvironment设置参数:stream_env.enable_checkpointing(250)
该参数默认为3000ms,3000ms会导致每3秒才集中从Kafka Topic中读出6条数据。所以,如果不设置这个参数,必定会导致每6条数据中平均有5条会超时500ms,使得实时数据(score2和score4)得分很难超过100分(满分500分),因此必须改变这个参数设置。针对本赛题,可以设置为250ms。
方法一在产线上应用没什么问题,但是在本比赛中它有一个小问题,那就是初始会有8秒延迟,这个延迟会使得赛题程序开始发送的约16条数据被TABLE API(For Kafka)读到时都会超时500ms,从而对最终评分有所影响(实测大概影响6分左右)。
使用方法一可确保只会有少量的初始数据(实测16条左右)产生超时。 - 方法二、使用ai_flow的用户自定义算子
1 ai_flow支持更为灵活的用户自定义算子af.user_define_operation
2 在用户自定义算子的Executor实现类中,直接使用Kafka Consumer/Producer 读写Kafka Topic
3 直接通过 Kafka consumer从Kafka Topic读取数据,然后call Inference API (by Zoo cluster serving) 降维,然后使用Proxima search API search Top1 UUID,然后得出分类label,最后直接通过Kafka Producer 将结果数据写入Kafka Topic。
使用方法二可避免初始16条数据的超时问题,设置好关键参数 (如fetch_max_wait_ms=200),可确保所有数据都不会超时。
总结和感想
本次比赛是算法+工程化问题。既要设计好算法,又要考虑实际工程需要。
模型算法:如果数据集的特征向量已经经过很好的处理,那么降维模型的模型可选择MSE loss损失小且Inference性能高的模型即可。而聚类算法要根据数据集特征向量的特性选择合适的算法。
向量检索:对于海量数据,必须使用专门的向量检索组件。阿里proxima提供了高召回率且极短的响应时间。
并行Inference:如果服务器只有CPU环境,那么使用Intel Zoo Cluster Serving 为Inference提供并行服务目前是非常好的选择。
实时数据处理:充分利用Zoo Cluster Serving、Proxima 的性能优势以及ai_flow user defined operation 的灵活优势,将实时数据处理效果最佳化。
代码框架:针对相似应用的新数据集,只需给出相应的新配置文件即可,无需改动python code。
工程考虑:代码不仅考虑比赛得分效果,同时也考虑了通过配置的方式在不同应用场景下使用不同的实现。
生产价值:一些基于向量检索的应用具有相似性,在这样的思路和不断改进下,它们应该可以泛化成通用的应用架构和代码框架,最终或许也可以实现为某一类软件产品或平台。另外,Zoo Cluster Serving 以及Proxima 在无昂贵GPU仅有CPU的环境下,提供了高并发及高性能的特性。因此,充分使用了Zoo Cluster Serving 以及Proxima的解决方案在一些实际生产系统的最终方案选择中,将具备很强的竞争力。
查看更多内容,欢迎访问天池技术圈官方地址: 第二届Apache Flink极客挑战赛冠军比赛攻略_SkyPeaceLL队_天池技术圈-阿里云天池