文章目录
- [一. 到Hadoop官网下载安装文件hadoop-3.4.0.tar.gz。](#一. 到Hadoop官网下载安装文件hadoop-3.4.0.tar.gz。)
- [二. 环境变量](#二. 环境变量)
- [三. 配置](#三. 配置)
一. 到Hadoop官网下载安装文件hadoop-3.4.0.tar.gz。
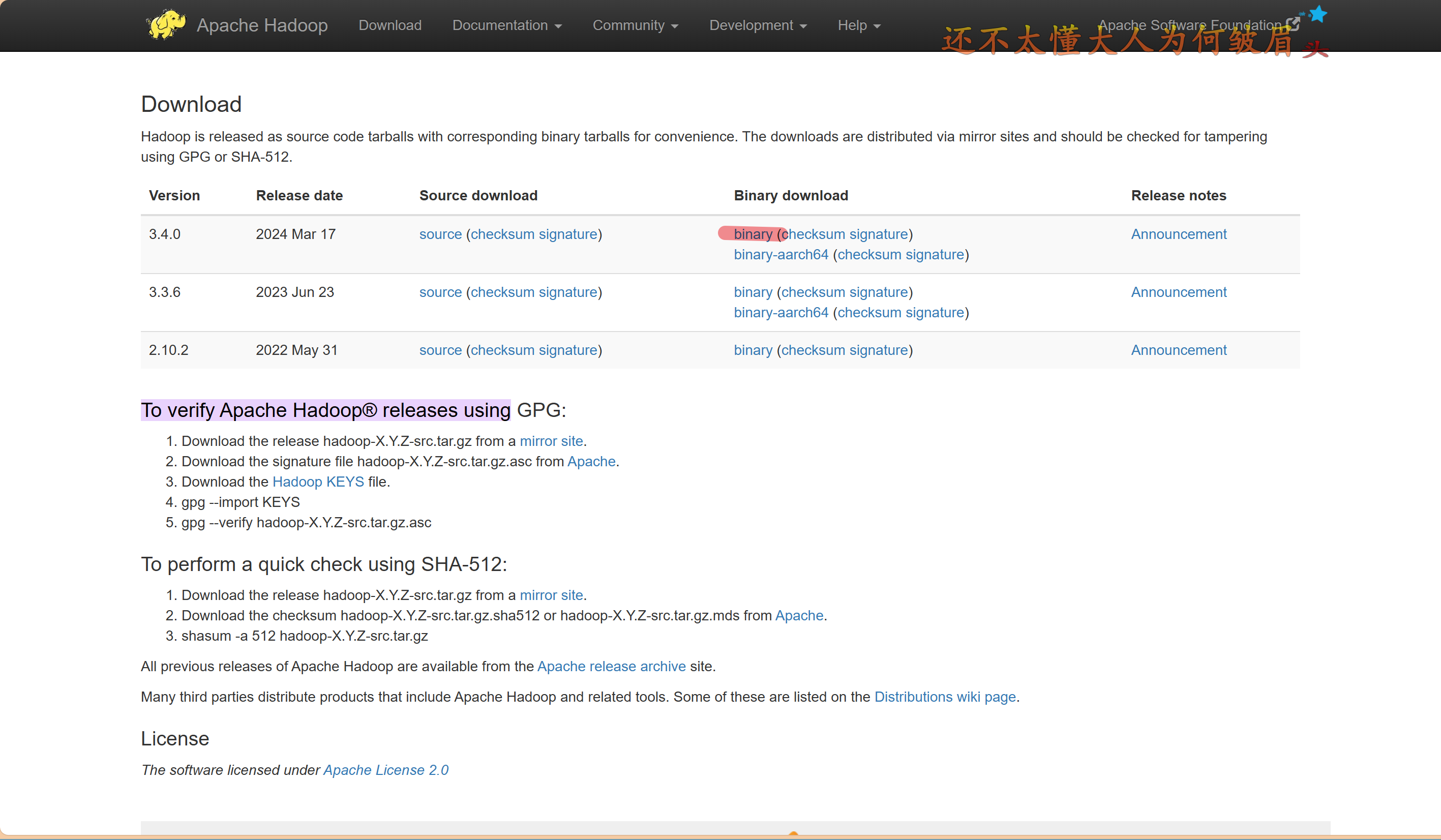
随后点击下载即可
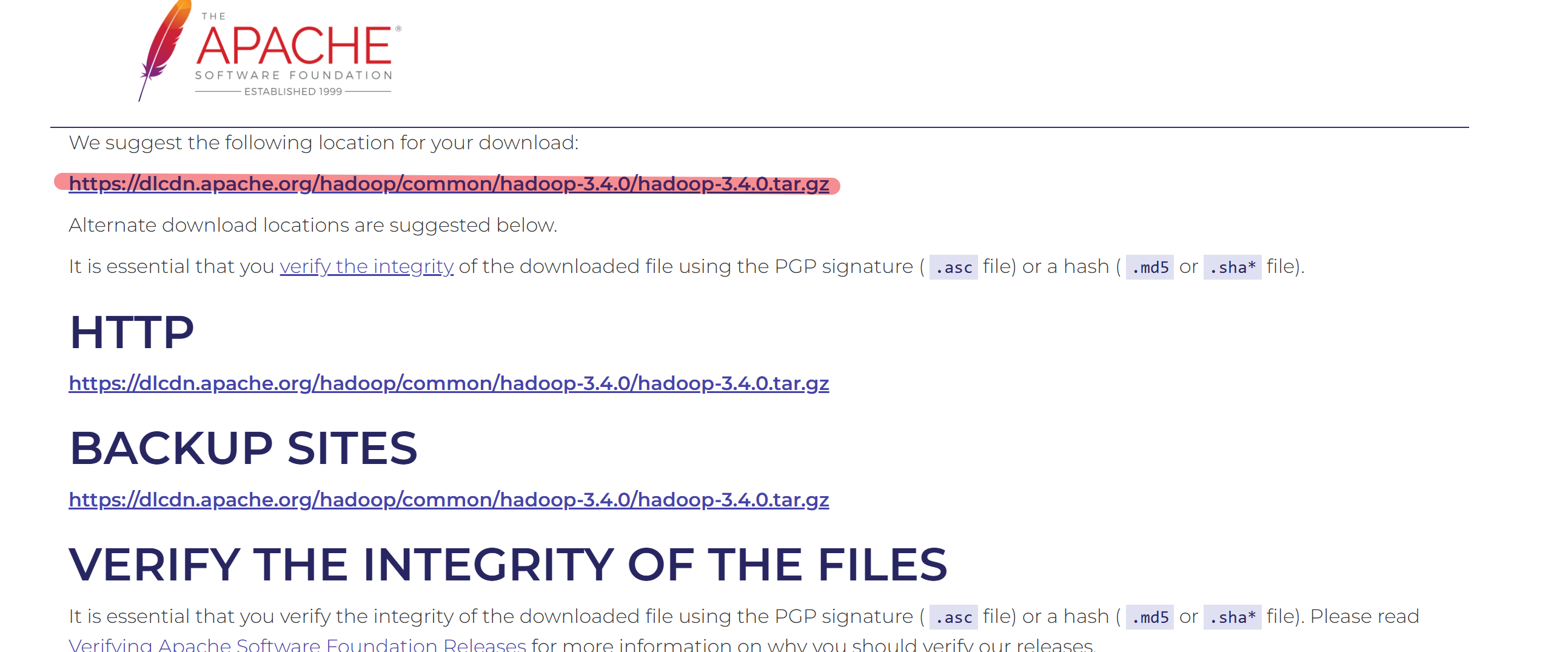
由于Hadoop不直接支持Windows系统,因此,需要修改一些配置才能运行
二. 环境变量

三. 配置
进到目录:E:\hadoop-3.4.0\etc\hadoop
修改:hadoop-env.cmd
set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_351
上述这样设置可能会出问题:Hadoop Error: JAVA_HOME is incorrectly set.
更改后:
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_351
PS:PROGRA~1是 Program Files 文件夹的dos文件名模式下的缩写 。
修改:core-sit.xml
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>PS:此文件中已有标签,可以直接覆盖掉
修改:hdfs-site.xml
配置namenode和datanode的存放位置,可以自定义
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///C:/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///C:/hadoop_data/hdfs/datanode</value>
</property>
</configuration>PS:此文件中已有标签,可以直接覆盖掉
修改:mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>PS:此文件中已有标签,可以直接覆盖掉
修改:yarn-site.xml
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>PS:此文件中已有标签,可以直接覆盖掉
