【1】分布式分片集群基础概念
【1.1】ES的分布式集群有什么用?
高可用
高可用(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
负载均衡
将流量均衡的分布在不同的节点上,每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。
高性能
将流量分发到不同机器,充分利用多机器多CPU,从串行计算到并行计算提供系统性能。
【1.2】ES的分布式集群是怎么一个概念和形式?
集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node): 单个 ElasticSearch 实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index): 在 ES 中, 索引是一组文档的集合
分片(shard): 因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节.
副本(replica): ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片成本, 而每个主分片都相应的有一个 copy。对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。
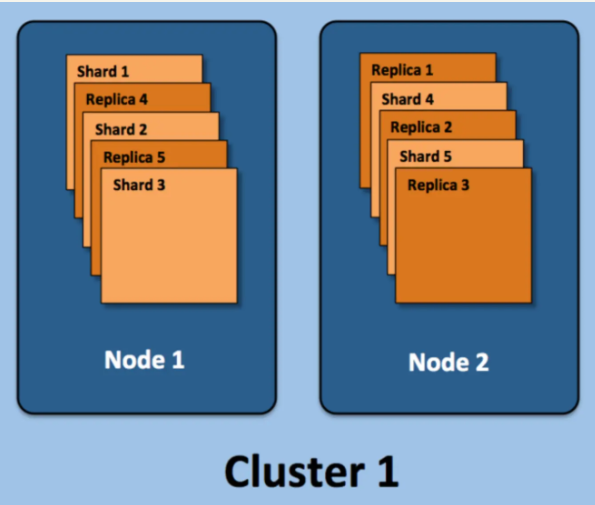
【2】节点角色的概念
Master Node
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。建议集群中Master节点的个数为奇数个,如3个或者5个。
设置一个几点为Master节点的方式如下:
node.master: true
node.data: false
node.ingest: false
search.remote.connect: falseData Node
主要负责集群中数据的索引和检索,一般压力比较大。建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
设置一个几点为Data Node节点的方式如下:
node.master: false
node.data: true
node.ingest: false
search.remote.connect: falseCoordinating Node
负责接收Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起
每个节点默认都起到了Coordinating Node的职责
Ingest Node
Ingest node专门对索引的文档做预处理,实际中不常用,除非文档在索引之前有大量的预处理工作需要做。Ingest node设置如下:
node.master: false node.master: false node.master: false
node.data: false
node.ingest: true
search.remote.connect: falseTribe Node
Tribe Node主要用于跨级群透明访问。但是官方已经不建议使用了,在5.4.0版本以后已经废弃掉了,在7.0的版本中将移除该功能。在5.5版本以后建议使用Cross-cluster search替代Tribe Node。
【3】Node节点组合
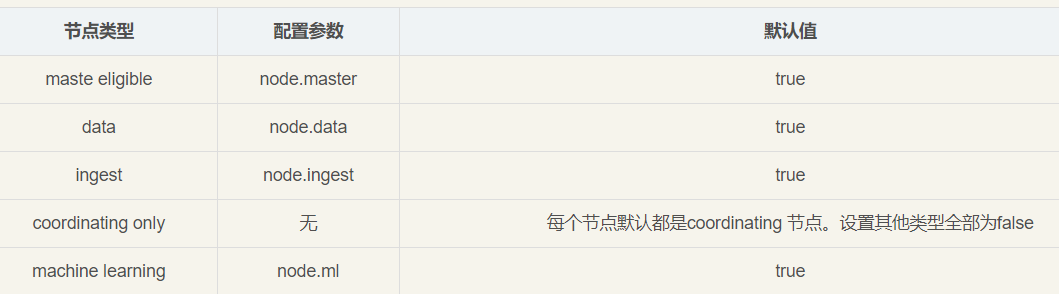
主节点+数据节点(master+data)
节点即有称为主节点的资格,又存储数据
node.master: true
node.data: true数据节点(data)
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候,可以进行负载均衡
node.master: false
node.data: false【4】ES集群搭建规划与准备工作
【4.1】集群规划表
|--------------------------------------|----------------------|----------------------|-----------|------------------|--------------|
| OS | ES version | Ip | node.name | Role | cluster.name |
| CentOS Linux release 7.8.2003 (Core) | elasticsearch-7.11.1 | 192.168.175.129:9201 | node_1 | node.master=true | my_es |
| CentOS Linux release 7.8.2003 (Core) | elasticsearch-7.11.1 | 192.168.175.129:9202 | node_2 | node.data=true | my_es |
| CentOS Linux release 7.8.2003 (Core) | elasticsearch-7.11.1 | 192.168.175.129:9203 | node_3 | node.data=true | my_es |
【4.2】Centos7.x 系统参数调整(ulimit,vm,jdk,swapping)
以root 登录
(1)ulimit
vim /etc/security/limits.conf
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535
* soft stack 65535
* hard stack 65535
es hard memlock unlimited #单独给es启动账户开 锁定内存页不限制
es soft memlock unlimited
退出登录重登后生效;su root
(2)vm.max_map_count >= 262144 / Swapping
#vim /etc/sysctl.conf
#然后在里面加上参数:
vm.max_map_count=2655350
vm.swappiness=1
#保存,然后重新加载参数:
sysctl -p
(3)JAVA1.8+
java --version 检查是否有安装 java,如 
如果没设置 $JAVA_HOME环境变量,就用压缩包中自带的jdk了,也挺好;
【4.3】下载、解压、复制、创建专属ES账户、授权
(1)下载,解压
官网:Download Elasticsearch | Elastic
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.1-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.1-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-7.11.1-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-7.11.1-linux-x86_64.tar.gz(2)复制、创建专属账户、授权
mkdir -p /data/elasticsearch/
groupadd es
useradd es -g es
cp -rp elasticsearch-7.11.1 /data/elasticsearch/elasticsearch1
cp -rp elasticsearch-7.11.1 /data/elasticsearch/elasticsearch2
cp -rp elasticsearch-7.11.1 /data/elasticsearch/elasticsearch3
mkdir -p {/data/elasticsearch/storage/elasticsearch1,/data/elasticsearch/storage/elasticsearch2,/data/elasticsearch/storage/elasticsearch1}
chown -R es:es /data/elasticsearch【5】配置、安装ES分布式集群
【5.1】配置文件参数释义
(1)基本释义
cluster.name 集群名称,相同名称为一个集群
node.name 节点名称,集群模式下每个节点名称唯一
node.master 当前节点是否可以被选举为master节点,是:true、否:false
node.data 当前节点是否用于存储数据,是:true、否:false
path.data 索引数据存放的位置
path.logs 日志文件存放的位置
bootstrap.memory_lock 需求锁住物理内存,是:true、否:false
bootstrap.system_call_filter SecComp检测,是:true、否:false
network.host 监听地址,用于访问该es
network.publish_host 可设置成内网ip,用于集群内各机器间通信
http.port es对外提供的http端口,默认 9200
discovery.seed_hosts es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
cluster.initial_master_nodes es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
http.cors.enabled 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.allow-origin "*" 表示支持所有域名
discovery.zen.minimum_master_nodes: 2 #最少要有N个节点才能选举出主节点
我们要只需要在之前的基础上,打开配置文件elasticsearch.yml,添加如下三个配置:
cluster.name: my-es #集群名称
node.name: node-master #主节点名称
node.master: true #当前节点是否可以被选举为master节点,是:true、否:false
discovery.seed_hosts: ["192.168.175.129:9201", "192.168.175.129:9202", "192.168.175.129:9203"]#写入候选主节点的设备地址,在开启服务后可以被选为主节点
cluster.initial_master_nodes: ["node-1"] #初始化一个新的集群时需要此配置来选举master(2)核心参数
#集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
#节点名称
node.name: node-1
#是不是有资格被选举为主节点
node.master: true
#是否存储数据
node.data: true
#最⼤集群节点数
node.max_local_storage_nodes: 3
#网络地址,0.0.0.0为不限制,还可以为localhost,127.0.01,实际IP地址等
network.host: 0.0.0.0
#实例端⼝
http.port: 9200
#内部节点之间沟通端⼝,默认9300-9305
transport.tcp.port: 9300
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点,注意这个是 transport.tcp.port 端口,而不是 http.port
discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"]
#es7.x 之后新增的配置,初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径
discovery.zen.minimum_master_nodes: 2 #最少要有N个节点才能选举出主节点
path.data: /Users/louis.chen/Documents/study/search/storage/a/data
path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs 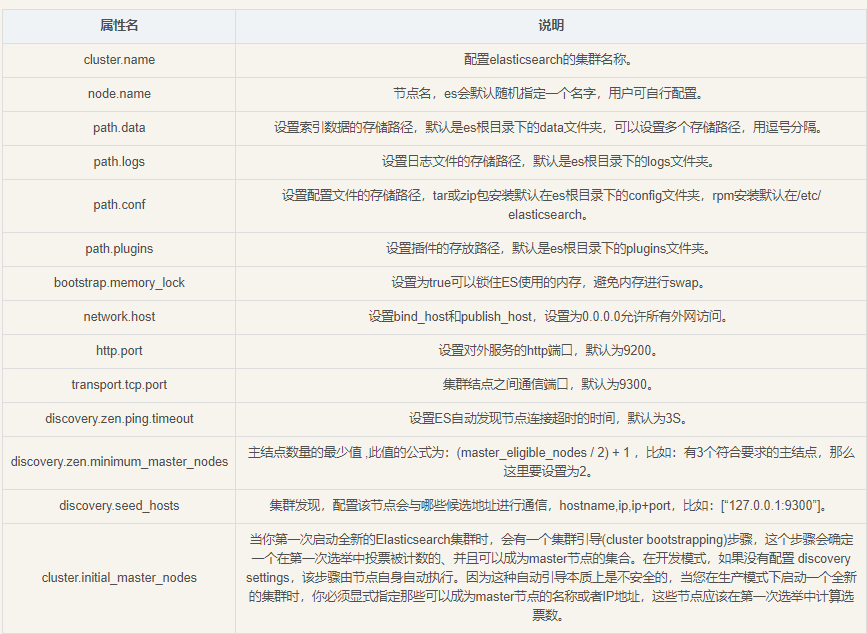
【5.2】修改配置文件
vim /data/elasticsearch/elasticsearch1/config/elasticsearch.yml
vim /data/elasticsearch/elasticsearch2/config/elasticsearch.yml
vim /data/elasticsearch/elasticsearch3/config/elasticsearch.yml
(1)9201 - node1
#-----cluster-----
cluster.name: my_es #集群名称
#gateway.recover_after_nodes: 3 #至少恢复3个节点及以上,集群节点才可以被访问
#-----node-----
node.name: node_1 #节点名称
node.master: true #该是否可被选举为主节点
node.data: true #该节点是否可成为数据节点
node.max_local_storage_nodes: 5 #集群最大逻辑存储节点数
transport.port: 9301 #集群内部通信端口
#-----data and log------
path.data: /data/elasticsearch/storage/elasticsearch1/data #生产环境建议把这2个和解压文件夹分离,避免升级丢失数据
path.logs: /data/elasticsearch/storage/elasticsearch1/logs
#-----memory-----
bootstrap.memory_lock: true #启动锁定内存页,这样就可以避免内存压力从而导致es的内存页被释放掉或被存到交换内存
#-----network-----
network.host: 192.168.175.129 # 网关地址,0.0.0.0为不限制
http.port: 9201
discovery.seed_hosts: ["192.168.175.129:9301", "192.168.175.129:9302", "192.168.175.129:9303"]
cluster.initial_master_nodes: ["node_1", "node_2", "node_3"]
#-----http requests-----
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
#-----es operation-----
#action.destructive_requires_name: true #删除索引时是否必须要实际索引名(2)9202 - node_2
#-----cluster-----
cluster.name: my_es #集群名称
#gateway.recover_after_nodes: 3 #至少恢复3个节点及以上,集群节点才可以被访问
#-----node-----
node.name: node_2 #节点名称
node.master: true #该是否可被选举为主节点
node.data: true #该节点是否可成为数据节点
node.max_local_storage_nodes: 5 #集群最大逻辑存储节点数
transport.port: 9302
#-----data and log------
path.data: /data/elasticsearch/storage/elasticsearch2/data #生产环境建议把这2个和解压文件夹分离,避免升级丢失数据
path.logs: /data/elasticsearch/storage/elasticsearch2/logs
#-----memory-----
bootstrap.memory_lock: true #启动锁定内存页,这样就可以避免内存压力从而导致es的内存页被释放掉或被存到交换内存
#-----network-----
network.host: 192.168.175.129 # 网关地址,0.0.0.0为不限制
http.port: 9202
discovery.seed_hosts: ["192.168.175.129:9301", "192.168.175.129:9302", "192.168.175.129:9303"]
cluster.initial_master_nodes: ["node_1", "node_2", "node_3"] #初始化主节点参与选举的节点,也可以用ip地址的
#-----http requests-----
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
#-----es operation-----
#action.destructive_requires_name: true #删除索引时是否必须要实际索引名(3)9203 - node_3
#-----cluster-----
cluster.name: my_es #集群名称
#gateway.recover_after_nodes: 3 #至少恢复3个节点及以上,集群节点才可以被访问
#-----node-----
node.name: node_3 #节点名称
node.master: true #该是否可被选举为主节点
node.data: true #该节点是否可成为数据节点
node.max_local_storage_nodes: 5 #集群最大逻辑存储节点数
transport.port: 9303
#-----data and log------
path.data: /data/elasticsearch/storage/elasticsearch3/data #生产环境建议把这2个和解压文件夹分离,避免升级丢失数据
path.logs: /data/elasticsearch/storage/elasticsearch3/logs
#-----memory-----
bootstrap.memory_lock: true #启动锁定内存页,这样就可以避免内存压力从而导致es的内存页被释放掉或被存到交换内存
#-----network-----
network.host: 192.168.175.129 # 网关地址,0.0.0.0为不限制
http.port: 9203
discovery.seed_hosts: ["192.168.175.129:9301", "192.168.175.129:9302", "192.168.175.129:9303"]
cluster.initial_master_nodes: ["node_1", "node_2", "node_3"] #初始化主节点参与选举的节点,也可以用ip地址的
#-----http requests-----
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
#-----es operation-----
#action.destructive_requires_name: true #删除索引时是否必须要实际索引名【5.3】启动这3个实例
su -l es -c"/data/elasticsearch/elasticsearch1/bin/elasticsearch -d -p /tmp/elasticsearch1.pid"
su -l es -c"/data/elasticsearch/elasticsearch2/bin/elasticsearch -d -p /tmp/elasticsearch2.pid"
su -l es -c"/data/elasticsearch/elasticsearch3/bin/elasticsearch -d -p /tmp/elasticsearch3.pid"有几条告警:(可以无需理会)
Future versions of Elasticsearch will require Java 11; your Java version from [/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N第一行告警是:未来 ES将会使用JAVA11,你当前的JAVA版本是JAVA8;不匹配这个版本,考虑一下使用ES集成的JDK;如果要用集成的JDK,则不要设置 $JAVA_HOME变量;
第二行告警是:OpenJDK 64位服务器VM警告:如果处理器的数量预期从一个增加,那么您应该使用-XX:ParallelGCThreads=N适当地配置并行GC线程的数量
【5.4】核验实例启动情况
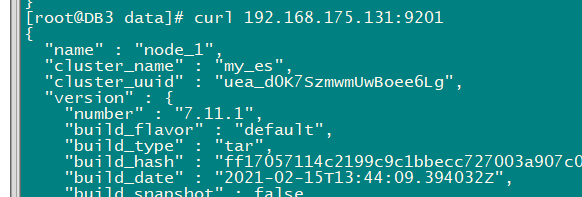
curl 192.168.175.129:9201
curl 192.168.175.129:9202
curl 192.168.175.129:9203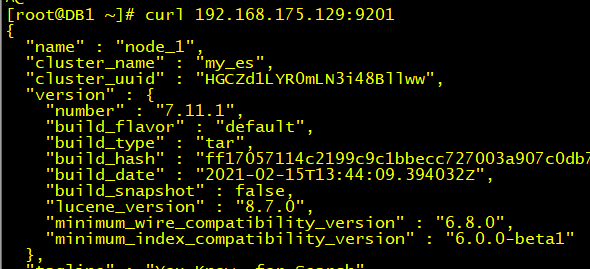
【5.5】查看集群状态

- status:集群的状态,red红表示集群不可用,有故障。yellow黄表示集群不可靠但可用,一般单节点时就是此状态。green正常状态,表示集群一切正常。
- node.total:节点数,这里是3,表示该集群有3个节点
- node.data:数据节点数,存储数据的节点数,这里是3
- shards:表示我们把数据分成多少块存储
- pri:主分片数,primary shards
- active_shards_percent:激活的分片百分比,这里可以理解为加载的数据分片数,只有加载所有的分片数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个页面,我们会发现这个百分比不断加大
【5.6】查看日志
(可略过,限参考,如果启动不起来之后可以查阅)
less /data/elasticsearch/storage/elasticsearch1/logs/my_es.log
less /data/elasticsearch/storage/elasticsearch2/logs/my_es.log
less /data/elasticsearch/storage/elasticsearch3/logs/my_es.log 【6】配置 kibana
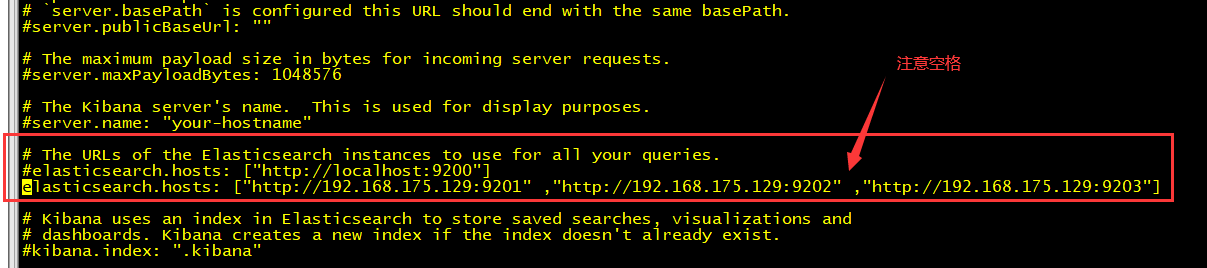
【6.1】修改配置文件kibana.yml
把我们的实例URL 都写入进去;
vim /usr/local/kibana/config/kibana.yml
elasticsearch.hosts: ["http://192.168.175.129:9201" ,"http://192.168.175.129:9202" ,"http://192.168.175.129:9203"]结果如下图:
【7】故障转移过程中的主分片、副本分片的变化(单主分片)
注意,这里是所有的索引都只有默认的1个主分片
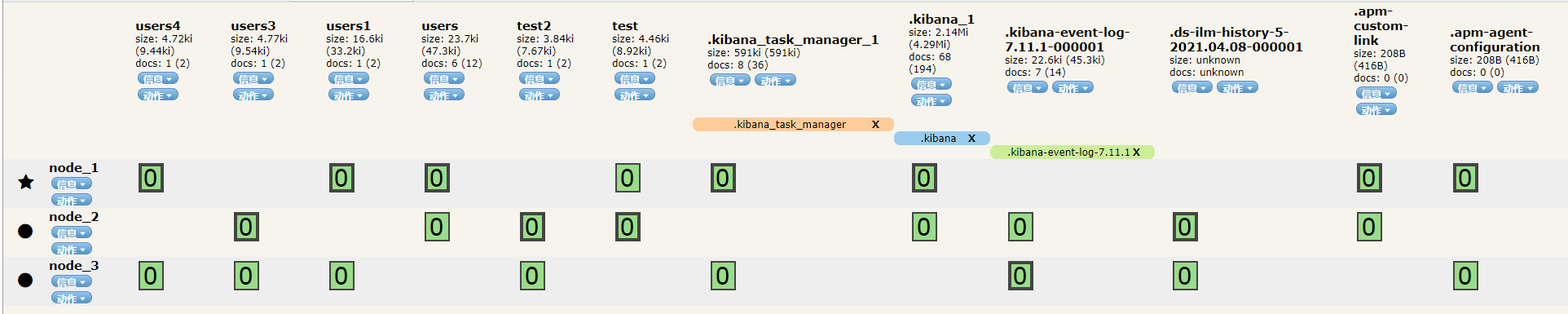
【7.1】断开重连一个节点
(1)集群正常时候
最左边的五角星单表该节点是当前的主节点;
(2)关掉主节点 node_1后:
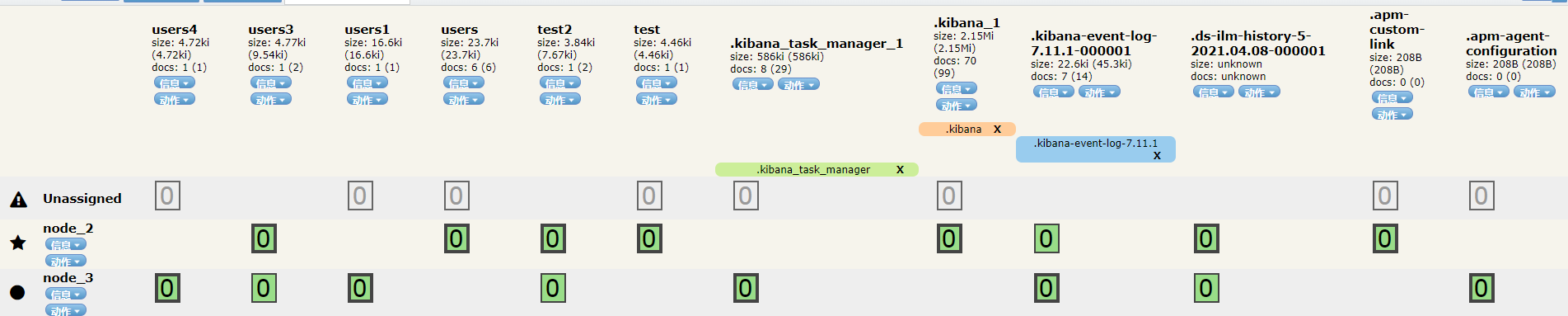
见后续文章的集群原理,过一段时间后(cluster.join.timeout:默认60秒超时 );
会因为超时,确认Node_1节点加入加入集群超时(或者说是失去连接60S)自动把该节点踢出集群;
而集群其他节点会重新选举主节点,且会把原副本分片转换成主分片,并重新生成副本分片;

(3)重新把节点1 实例加入集群(再次重新分布了副本分片、主分片的位置,我们可以发现 下图和(1)图中的分片位置不一样了)
由于是新节点加入集群,那么最终它是1s发现一次,所以刚启动好,就秒加进来了;
在过程中如果一直刷新,发现head插件提供的界面,node_1刚加进来的时候没有分片,然后其他节点会有分片变成紫色,然后紫色的分片就迁移到了新的node_1节点;

【7.2】断开两个节点
直接连都连不上了

但直接 curl 还证明,单节点是活着的
【7.3】添加一个node 节点
(1)新节点实例:修改配置文件
集群名称要一样,node.name 要不一样,discovery.seed_hosts 要包含现有要加入集群的主机信息(最好全加上)
cluster.name: my_es
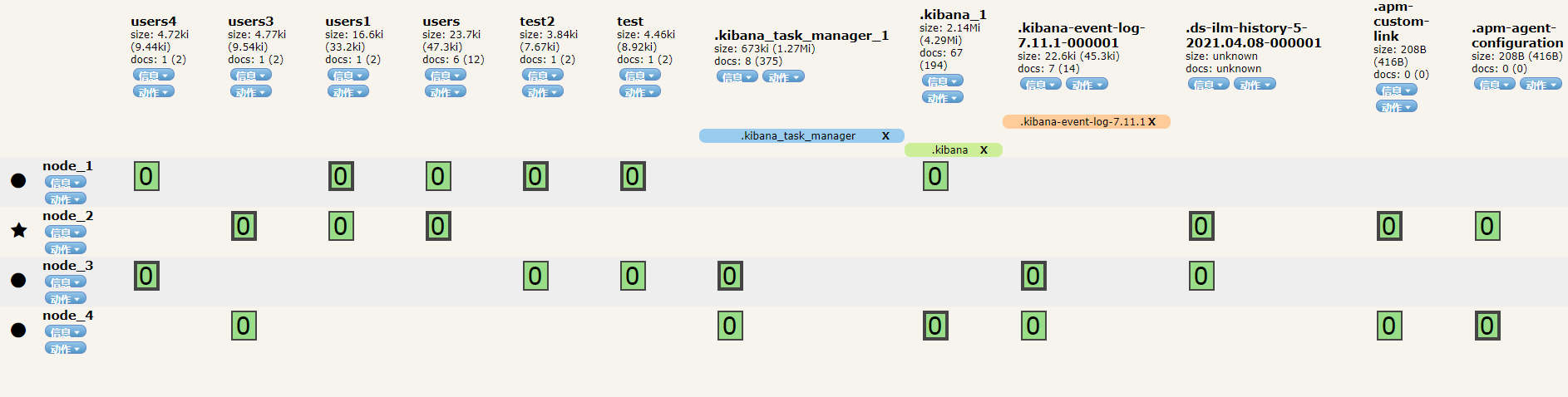
discovery.seed_hosts: ["192.168.175.131:9301", "192.168.175.131:9302", "192.168.175.131:9303"](2)添加后 加入到集群后的数据分片信息(依然是自动分片了)
【7.4】为什么分片会自动平衡?
参考官方手册:有自动的平衡设置,但是默认的可能不是最佳实践
【错误处理】
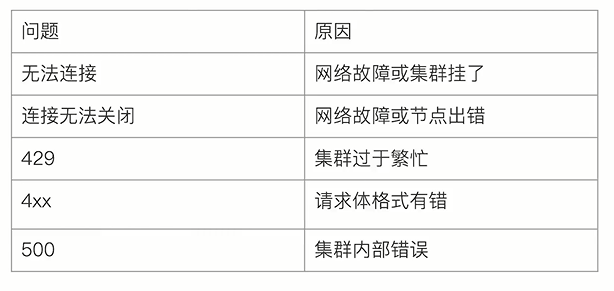
(0)各类错误代码表达的含义(429/4xx/500)
(1)memory locking requested for elasticsearch process but memory is not locked
解决方法一(关闭bootstrap.memory_lock:,会影响性能):
vim /etc/elasticsearch/elasticsearch.yml // 设置成false就正常运行了。
bootstrap.memory_lock: false
解决方法二(开启bootstrap.memory_lock:):
- 修改文件/etc/elasticsearch/elasticsearch.yml,上面那个报错就是开启后产生的,如果开启还要修改其它系统配置文件
bootstrap.memory_lock: true
- 修改文件/etc/security/limits.conf,最后添加以下内容。
es hard memlock unlimited
es soft memlock unlimited
(2)集群节点无法互相发现
es集群配置文件 没有任何问题 但启动后无法互相发现集群节点,需要删除data目录里面的所有文件,然后重新启动所有节点,即可发现。
(3)巨坑,配置文件 discovery.seed_hosts 与 cluster.initial_master_nodes!!
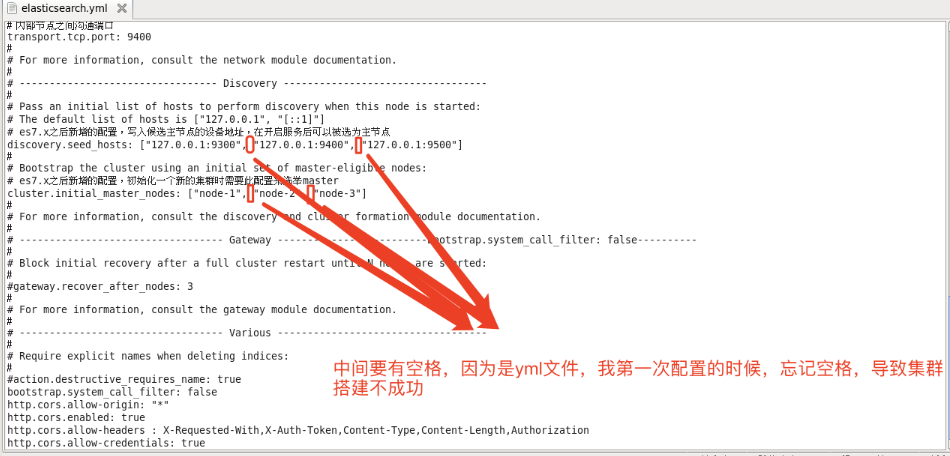
(4)折磨了我两天的错误:master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster
curl ip:port/_cat/health?v显示:
{"error":{"root_cause":{"type":"master_not_discovered_exception","reason":null},"type":"master_not_discovered_exception","reason":null},"status":503}
查看错误日志显示:
[2021-03-11T16:41:13,660][WARN ][o.e.c.c.ClusterFormationFailureHelper] [node_1] master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster,
and this node must discover master-eligible nodes [node_1, node_2, node_3] to bootstrap a cluster:
have discovered [{node_1}{3D2LMma-SWeX5HjT-C0W_Q}{gYZDUrSfTHW43fYN5gPfgA}{192.168.175.129}{192.168.175.129:9301}{cdhilmrstw}{ml.machine_memory=5967216640, xpack.installed=true,
transform.node=true, ml.max_open_jobs=20, ml.max_jvm_size=1065025536}]; discovery will continue using [192.168.175.129:9302, 192.168.175.129:9303] from hosts providers
and [{node_1}{3D2LMma-SWeX5HjT-C0W_Q}{gYZDUrSfTHW43fYN5gPfgA}{192.168.175.129}{192.168.175.129:9301}{cdhilmrstw}{ml.machine_memory=5967216640, xpack.installed=true,
transform.node=true, ml.max_open_jobs=20, ml.max_jvm_size=1065025536}] from last-known cluster state; node term 0, last-accepted version 0 in term 0解决:
【参数问题】
(1)主机发现问题
discovery.seed_hosts: "192.168.175.129:9301", "192.168.175.129:9302", "192.168.175.129:9303"
transport.port: 9303
=》上面 discovery.seed_hosts 里面的地址,一定是 transport.port 端口(如果该参数没设置,则默认是9300~9400端口,从9300开始使用)
(2)集群初始化主节点
cluster.initial_master_nodes: ["node_1", "node_2", "node_3"] #初始化主节点参与选举的节点,也可以用ip地址的因为配置了这个,所以必须要半数服务器以上实例节点启动后,才会有主节点,错误信息页会停止报错(这里配置3个,那就需要3/2+1,2个节点启动后,才能开始初始化选举)
所以不要着急,如本案例,至少要有2个ES实例启动后,才会开始初始化选举主节点
(5)为什么我的进程僵死?内推太少,一个空的ES 至少需要1.3-1.5G内存
我之前就是弄了3G的虚拟机玩的,结果启动不起来,直接僵死;查看日志也发现没有动静,ps -ef 直接看不到进程;不过 pid 文件倒是还在
(6)无法发现主机 failure when sending a validation request to node
删除目录下的,data里的数据,里面有个Node目录,里面记录了集群信息
rm -rf /data/elasticsearch/storage/elasticsearch1/data/*
rm -rf /data/elasticsearch/storage/elasticsearch2/data/*
rm -rf /data/elasticsearch/storage/elasticsearch3/data/*