前言
记录一次请求univer在线电子表格在进行上万条数据返回前端页面响应的优化过程
本次优化主要是针对大数据量下页面加载响应,通过前后端相关优化提高响应速度,增强用户体验。
一般我们要分析一个页面响应过慢,我们可以先通过按 F12 打开浏览器的开发者工具。切换到 Network 网络,点击一次刷新可以看到打开本次页面请求了哪些服务器接口,以及哪些静态文件,并且每次请求耗时,以及请求数据大小;下面还会显示本次页面请求全部完成用时多长等一些汇总信息。通过这些信息我们就可以有效的分析出这个页面打开过慢的原因,主要加载什么耗时过多.
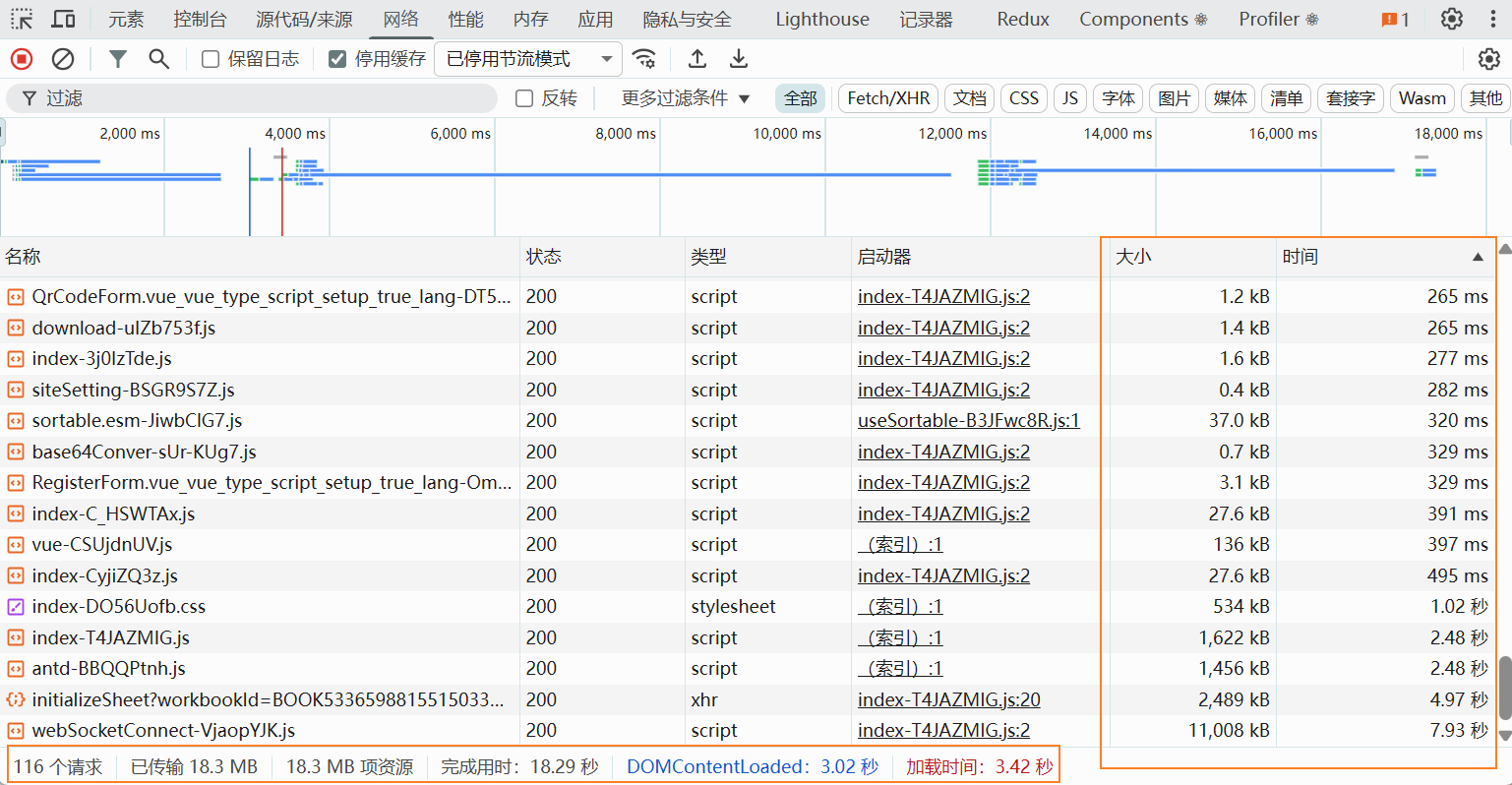
通过下面两次测试可以看出,在优化前和优化后,打开页面耗时上提升了5到6倍,这样给用户的体验上就会提升很多
优化前:
优化后:
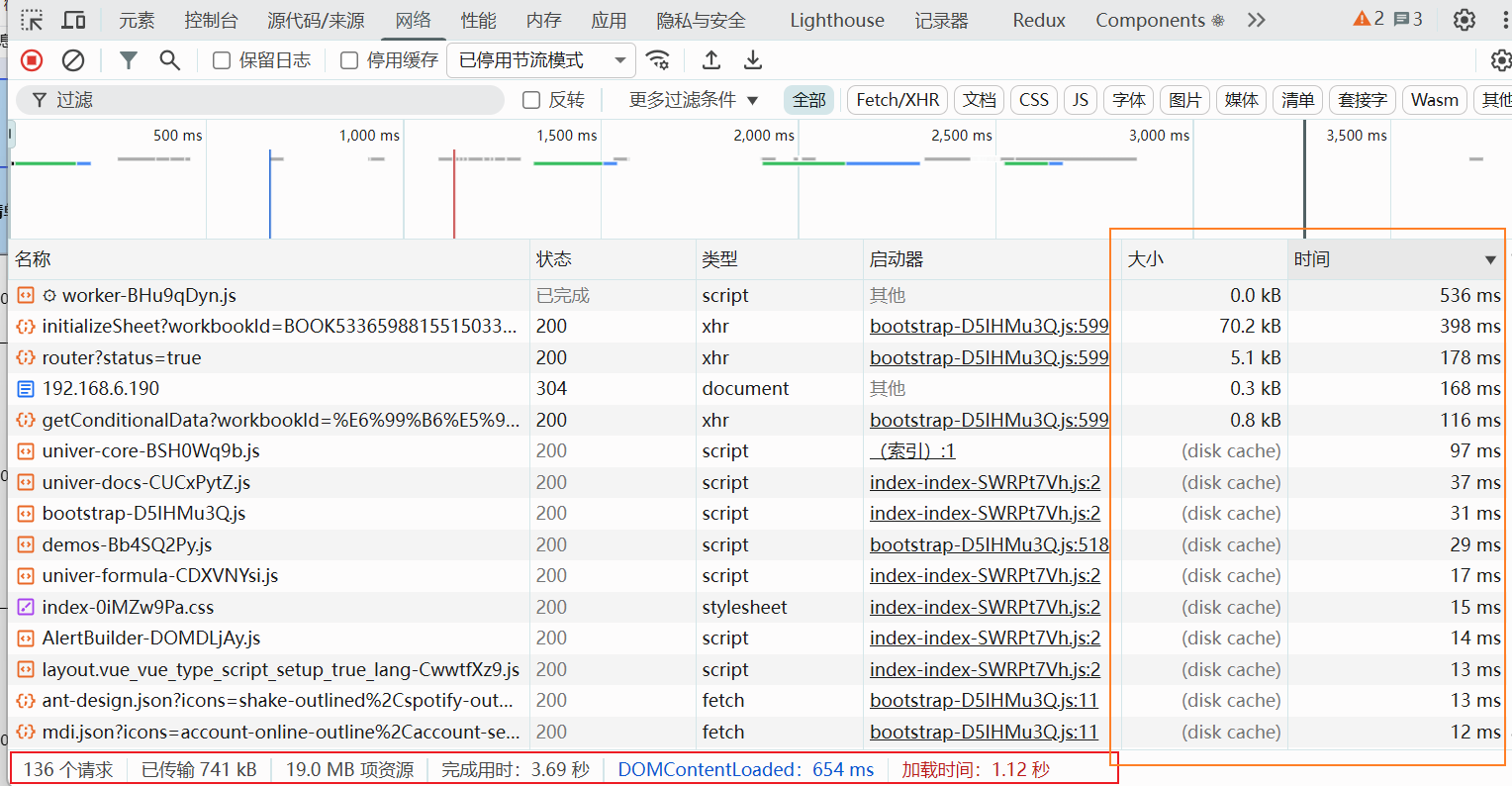
前端优化
可以看到上面优化前,打开页面加载耗时最长的就是请求webSocketConnect-VjaopYJK.js这个文件。这个文件是我的univer的在线sheet电子表格引擎依赖,他内部引用到了非常多的插件,并且全部默认打包到了一起造成这个js文件非常大,因此请求非常耗时。
1、通过代码配置优化减少.js静态文件体积
- 先通过代码优化,把相关的一些没有用到的依赖清除出去,减少整体的文件大小
- 既然默认打包到一起了,那可以通过配置
vite.config.mts的build进行拆chunks,拆开打包,避免全部请求一个文件;原来一个,拆包后变为了几个,但拆包也不建议拆的过细,这样会造成依赖调用上的一些问题,而且拆的过细请求过多了也不好,效率反而会慢。

下面是我的vben构建配置文件 :
主要配置拆分打包配置
javascript
import type { UserConfig } from 'vite';
import { defineConfig } from '@vben/vite-config';
export default defineConfig(async (): Promise<UserConfig> => {
return {
application: {},
plugins: [
{
name: 'remove-preload-links',
transformIndexHtml(html) {
return html
.replaceAll(/<link[^>]+rel="preload"[^>]+as="style"[^>]*>/g, '')
.replaceAll(/<link[^>]+rel="modulepreload"[^>]*>/g, '');
},
},
],
//开发服务器代理
vite: {
server: {
proxy: {
'/api': {
changeOrigin: true,
rewrite: (path) => path.replace(/^\/api/, ''),
target: 'http://localhost:9000',
ws: true,
},
},
},
//拆分打包
build: {
sourcemap: false,
minify: 'esbuild',
target: 'esnext',
modulePreload: false,
rollupOptions: {
external: ['bwipjs'],
output: {
chunkFileNames: 'assets/[name].[hash].js',
entryFileNames: 'assets/[name].[hash].js',
assetFileNames: (assetInfo) => {
if (assetInfo.name?.endsWith('.css')) {
return 'assets/[name].[hash].css';
}
return 'assets/[name].[hash].[ext]';
},
manualChunks(id, { getModuleInfo }) {
if (
id.includes('@univerjs/core') ||
id.includes('@univerjs/engine-render') ||
id.includes('@univerjs/ui') ||
id.includes('@univerjs/design') ||
id.includes('@univerjs/engine-formula') ||
id.includes('@univerjs/ui-adapter-vue3') ||
id.includes('@univerjs/rpc')
) {
return 'univer-core'; // 稳定 chunk 名
}
if (
id.includes('@univerjs/sheets') ||
id.includes('@univerjs/sheets-formula') ||
id.includes('@univerjs/sheets-formula-ui') ||
id.includes('@univerjs/sheets-numfmt') ||
id.includes('@univerjs/sheets-numfmt-ui') ||
id.includes('@univerjs/sheets-find-replace') ||
id.includes('@univerjs/sheets-conditional-formatting') ||
id.includes('@univerjs/sheets-data-validation') ||
id.includes('@univerjs/sheets-sort') ||
id.includes('@univerjs/sheets-filter-ui')
) {
return 'univer-sheet';
}
if (
id.includes('@univerjs/docs') ||
id.includes('@univerjs/docs-ui') ||
id.includes('@univerjs/find-replace')
) {
return 'univer-doc';
}
if (id.includes('@univerjs/')) {
const pkgName = id
.split('node_modules/@univerjs/')[1]
?.split('/')[0];
if (pkgName) return `univer-${pkgName}`;
}
return undefined;
},
},
},
chunkSizeWarningLimit: 2000,
},
optimizeDeps: { exclude: ['bwipjs'] },
},
};
});
- 通过压缩静态文件,把文件进行gzip压缩传输,可以使得传输数据大大减少。压缩前和压缩后大小降低了5倍作用。压缩通过配置nginx进行压缩传输,使用
vben预压缩也可以。

- 通过nginx设置静态文件存储浏览器缓存时间,默认浏览器缓存一般是几个小时,所以用户打开页面的时候都得去服务器请求下载静态文件渲染页面。但如果缓存在本地磁盘的话,渲染速度会指数级上升。
nginx.conf配置文件 :
主要配置gzip压缩和设置静态文件缓存
powershell
worker_processes auto;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
##############################
# gzip 压缩
##############################
gzip on;
gzip_static off;
gzip_vary on; # 添加 Vary: Accept-Encoding 头,避免 CDN 缓存问题
gzip_min_length 1024; # 小于 1KB 的文件不压缩(避免小文件压缩反而变大)
gzip_proxied any; # 对代理请求也启用压缩(如 /api/)
gzip_disable "msie6"; # 旧 IE6 不支持 gzip,禁用
gzip_comp_level 6; # 压缩级别(1~9),6 是速度与压缩率平衡点
gzip_types
text/plain
text/css
text/xml
text/javascript
application/javascript
application/x-javascript
application/json
application/xml
application/xhtml+xml
application/rss+xml
application/vnd.ms-fontobject
application/x-font-ttf
font/opentype
image/svg+xml
;
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
sendfile on;
keepalive_timeout 65;
server {
listen 91;
server_name localhost;
client_max_body_size 20m;
root /usr/share/nginx/d2o-web/v3/prod/;
location = /index.html {
try_files $uri $uri/ /index.html;
add_header Cache-Control "no-store, no-cache, must-revalidate, proxy-revalidate" always;
add_header Pragma "no-cache" always;
add_header Expires "0" always;
}
# 所有 HTML 文件禁止缓存
location ~ \.html$ {
add_header Cache-Control "no-store, no-cache, must-revalidate" always;
add_header Pragma "no-cache" always;
add_header Expires "0" always;
}
# 带哈希的静态资源缓存60天
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg|woff2|woff|ttf)$ {
if ($request_filename ~ "\.[a-f0-9]{8}\.(js|css|png|jpg|jpeg|gif|ico|svg|woff2|woff|ttf)$") {
expires 60d;
add_header Cache-Control "public, immutable" always;
}
# 无哈希文件短缓存(如 favicon.ico)
if ($request_filename !~ "\.[a-f0-9]{8}\.") {
expires 7d;
add_header Cache-Control "public" always;
}
}
# index.html不缓存
location / {
try_files $uri $uri/ /index.html;
index index.html index.htm;
}
location /api/ {
gunzip on;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 根据前端请求代理指向后端的接口地址
proxy_pass http://192.168.6.190:9100/;
proxy_set_header Accept-Encoding "";
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}上面就是前端的一些优化方案,可以有效的提高用户的响应数据,特别是针对一些必须得大数据渲染的页面来说。当然这些只是我想到的一些方案,如果还有好的方案方案欢迎评论区留言。
后端优化
前端主要是侧着于页面渲染,后端则侧重于逻辑计算包裹最终返回前端需要的结构数据。
后端的优化上主要可以拆分为两块一块是数据库的SQL优化,一块就是代码方面的优化。
1、SQL优化
SQL优化,一般我们在执行SQL的时候总共分为两种,一种类型增、删、改,还有就是查询。
1.1、增删改类 SQL 优化(INSERT/UPDATE/DELETE)
- 新增优化
- 多条数据插入的时候,可以用批量插入代替单条循环插入。一般可以一次性插入1000条左右去循环插入,一次性插入太多了效率也不太好。
- 并且可以关闭自动提交,全部写入后在手动提交。
- 更新/删除(UPDATE/DELETE)优化
- 在操作的时候尽量用主键/唯一索引筛选,避免全表更新/删除
- 还有在大批量更新/删除时也可以1000左右分批执行。
1.2、查询类 SQL 优化(SELECT)
上面的增删改上需要优化的场景一般比较少,基本上平常在使用到的场景80%是查询。查询的核心主要就是精准筛选 + 索引利用。
- 对于一些常用的查询的字段可以为这些字段建立对应的索引。
- 查询的时候也尽量减少查询返回字段。避免使用SELECT * 这种全量返回字段的语句;尽量只返回我们需要的字段就行
- 多表查询的时候合理使用JOIN,尽量小表驱动大表;并且不建议去一次性JOIN连接太多的表一起查询
- 不要再SQL里加入计算相关的数据,尽量在代码层面执行
- 还有就是尽量限制返回的数据数量。限制返回的结果集,避免一次性返回大量数据
一般SQL优化做好了可以解决平常80%的场景。毕竟用户一次性也就只能看那么多条数据。这里只提供大致的思路,具体的SQL相关优化网上太多资料了,可以自行翻阅。
2、代码方面
一般考虑使用代码进行优化,针对的就是数据比较多的情况。通过SQL优化已经不能满足响应效率了。
-
配置
<select>标签里的fetchSize参数(Oracle数据库尤其需要)。fetchSize:为每次从数据库加载多少条数据到服务里来。MYSQL是一次性全部加载过来;Oracle是一次性加载10条。如果一次性查询的数据量很大的话,一次性加载数万 / 数十万行数据到 JVM 堆内存可能会出现内存溢出的情况。而如果是Oracle则一次性加载10条数据则会去请求加载上万次会造成速度非常慢。一般配置fetchSize="2000"效率会比较合适
-
如果是一些需要计算类型的数据。则可以采用多线程进行并行执行。
- 异步并行执行可以使用下面的一些方式执行异步并行等任务计算
Stream.parallel()CompletableFuture.runAsync(() -> {})ThreadPoolExecutor
- 异步并行执行可以使用下面的一些方式执行异步并行等任务计算
3.在大数据返回前端的时候,可以采用压缩GZIP压缩。可以有效的降低网络传输耗时,提升前端 / 客户端接收数据的速度。毕竟1M和100M的数据传输不是一个量级。
如果是Springboot项目可以添加下面的配置。如果是微服务项目Gateway服务也要加
yaml
server:
compression:
enabled: true # 开启HTTP响应压缩
#指定需要压缩的 MIME 类型
mime-types: >
text/html,
text/xml,
text/plain,
text/css,
text/javascript,
application/javascript,
application/json,
application/x-javascript,
text/x-component,
application/x-chrome-extension,
application/x-opera-extension,
application/x-oauth2-credentials,
application/x-web-app-manifest+json,
application/json; charset=utf-8,
application/atom+xml,
application/rss+xml,
application/json
min-response-size: 1024 #压缩最小阈值通过上面这些配置下来,基本上可以解决绝大部分的应用场景了。