前言
对于生成型AI的画图能力,尤其是AI画美女的能力,相信同行们已经有了充分的了解。然而,对于游戏开发者而言,仅仅是漂亮的二维图片实际上很难直接用于角色设计,因为,除了设计风格之外,角色设计还需要考虑大量的细节,比如角色姿势是否自然、细节是否清晰、光照是否合理?都需要很多的考量。

不过,在Stable Diffusion的帮助下,角色设计师可以大幅提升工作效率。比如最近,就有一位资深设计师分享了自己使用Stable
Diffusion+ControlNet以及图形、建模软件进行角色设计的全过程:
以下是Gamelook听译的完整内容:
今天我们将模拟一个适合概念艺术管线blue
sky部分的角色设计流程,不过会有所调整。我将使用ControlNet和多个扩展以及3D软件来创作你们现在看到的这个角色。
我开始会深度解释每一个预处理程序是做什么的,同时以自己的艺术作品作为测试案例。熟悉了ControlNet的功能之后,我们将使用姿势编辑器创作2D姿势模板(pose
template)。在我们熟练地为概念想法创作和使用角色模板之后,我们就会开始将3D加入我们的工作流程,使用Blender给我们一个合适的具有开放式立柱骨架深度和准确数据的绑定。当我们开始生成最终角色设计的时候,这可以很大程度上帮我们得到更高保真度和可复用性。
解决了初始设计之后,我会谈到是如何对需要提升的图片区域进行局部重绘的,我还会展示如何通过Blender聚焦每一只手的近景照,来生成高保真的双手。一旦设计变得更加充实,我会认真讨论如何呈现一个最终角色的设计。
如果这一切听起来是你感兴趣的,那么我们就开始吧。
**什么是ControlNet?**
* 1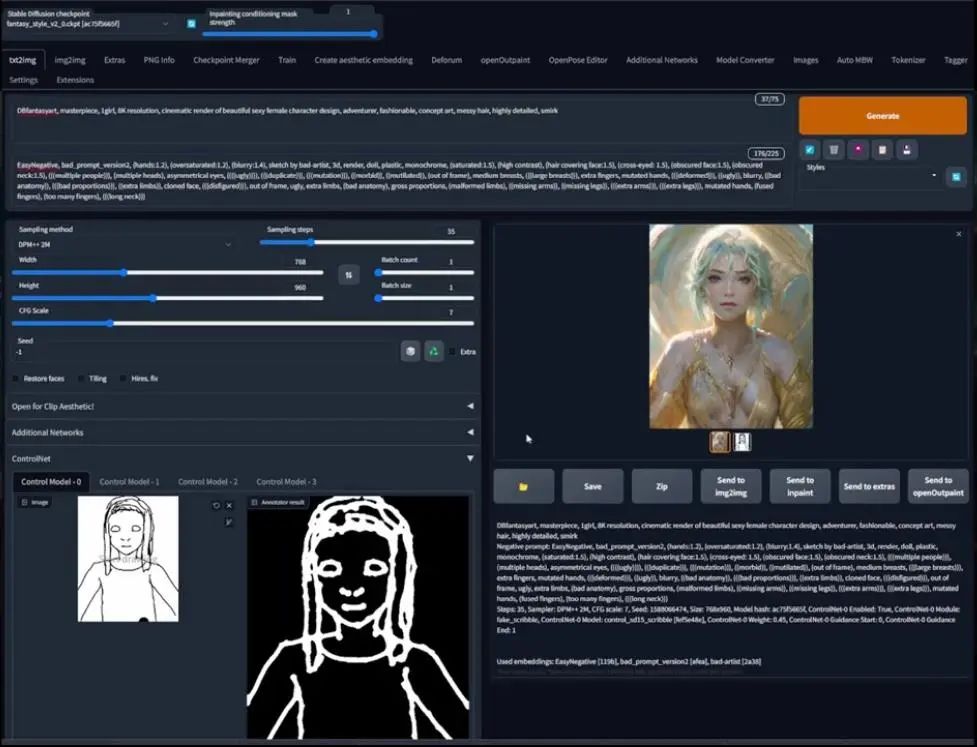
首先,什么是ControlNet?简单来说,你可以将ControlNet当做一个辅助引导指令的工具,论文(https://arxiv.org/abs/2302.05543)是由两个人撰写并发布,不过我们用的扩展是由Miku制作的,它也被当做ControlNet的非正式扩展。
在开始之前,你需要安装一些东西:AUTOMATIC1111
webui以及Miku打造的ControlNet扩展。你还需要有来自Huggingface的预训练权重,并且将它们放到你的ControlNet扩展文件夹之中。你不用下载注解,因为当你开始使用ControlNet的时候,它们会自动下载。
这里,你还需要另一个扩展,由FK Yoon创作的open pose编辑器。
最后,我会使用Blender 3.4版本以及toy XYZ提供的一个blend文件。如果不知道如何使用Blender或者没有任何3D
CGI经验,不用担心,我会努力让Blender处理流程尽可能简单易懂。一切准备就绪之后,我们就可以开始了。
**第一部分:ControlNet模型**
* 11.1、OpenPose模型
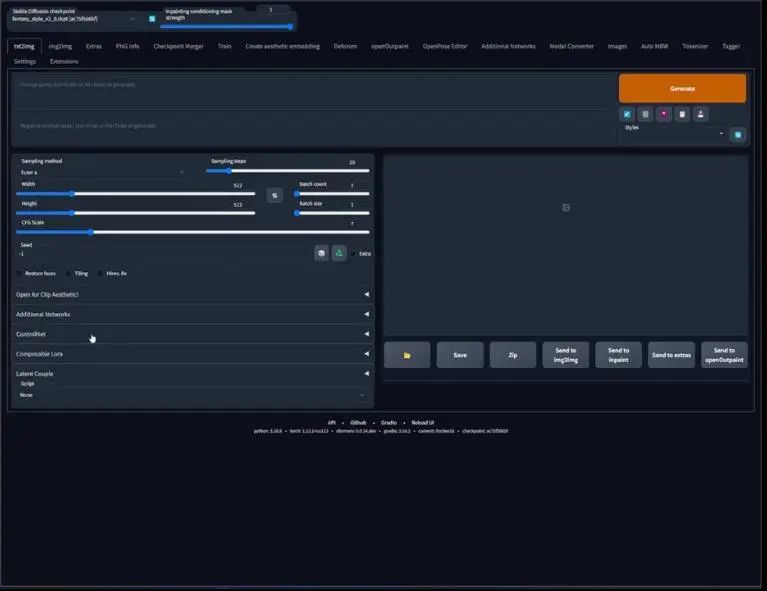
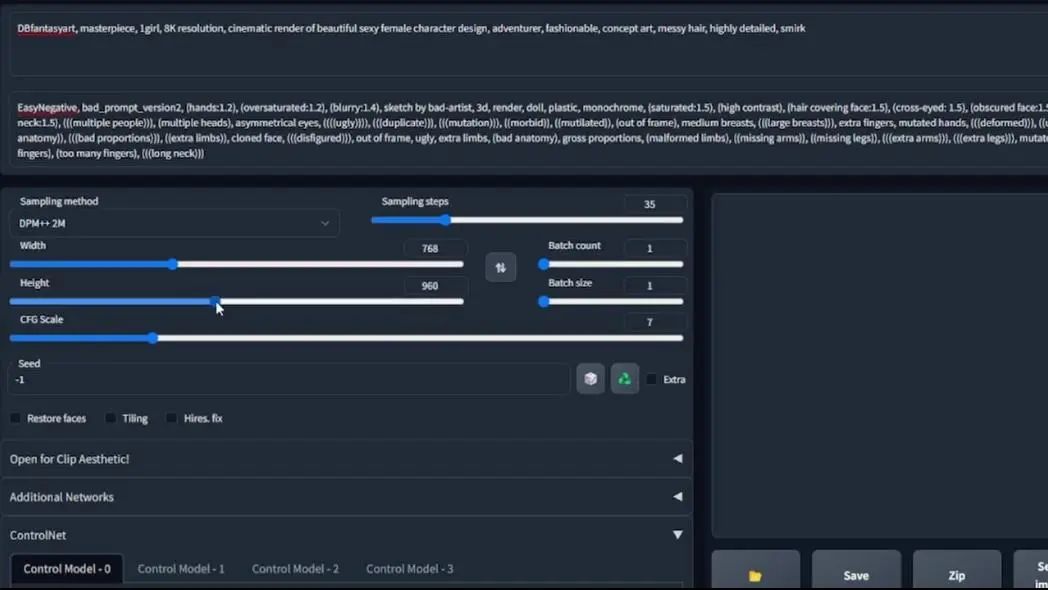
安装了ControlNet扩展之后,你的webui看起来应该是与这张图片里的相似,在文生图和图生图界面的下方,增加了ControlNet标签。为了展示,我们回到文生图界面并点开ControlNet标签:
你可以看到这些选择,它有些复杂,但又不是特别的复杂。
首先,我会用一张来自我上传到Civitai的魔幻风格V 1.6版本的样本图片,来展示ControlNet具体是做什么的。
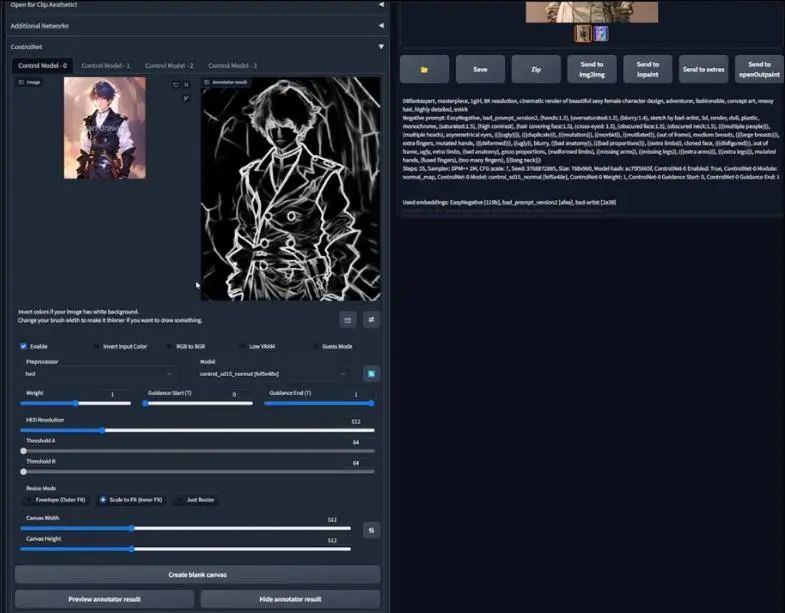
这是一个穿着军装的男孩图片,如之前所说,ControlNet就像是指令的指引者,因此它使用不同的指引方法,也就是这里的模型列表,包括canny、depth等等。
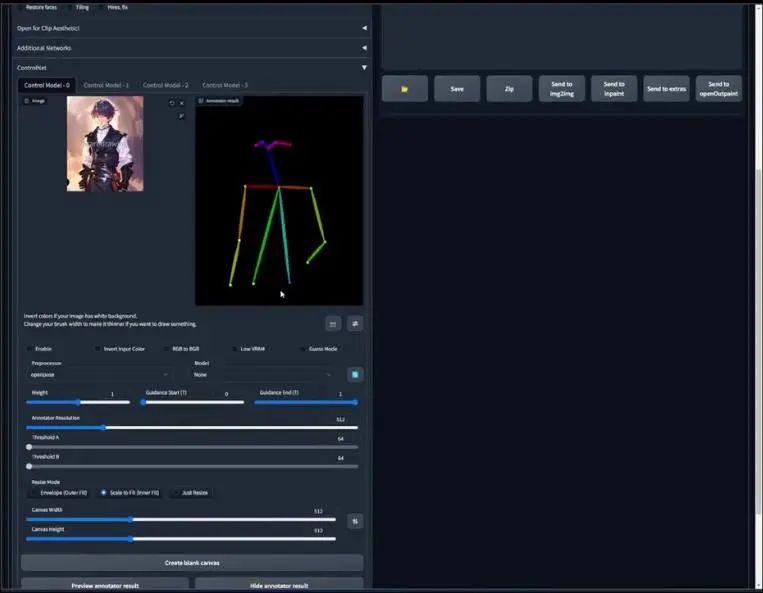
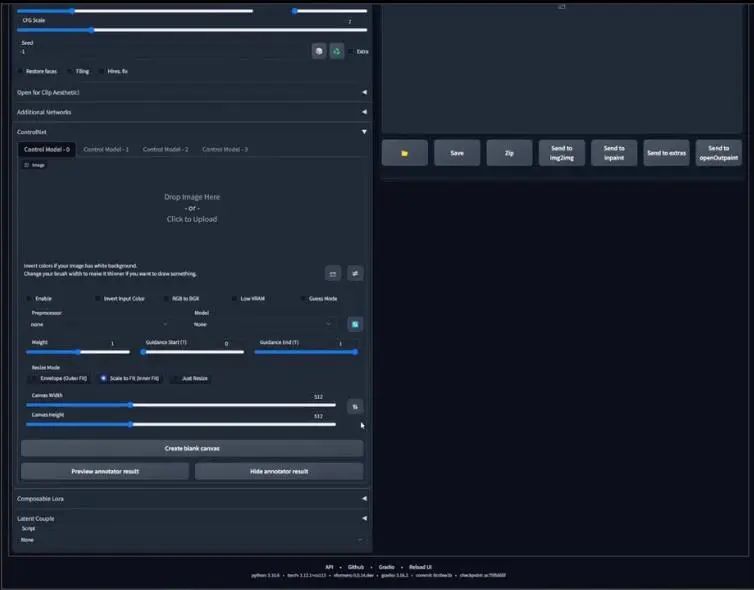
不过,我们先用OpenPose模型,它是一个用来探测人类身体关键点的机器学习算法,因此我们首先在左侧的预处理器(preprocessor)标签下选择OpenPose。可以看到很多选项,但这里我们最应该注意的是preview
Annotator Result,点击这里,经过一段处理之后,你可以看到一个多颜色组成的骨骼,也就是OpenPose骨骼。
为了更好地理解,你可以将上边的骨骼视为眼睛和头部,更低的区域或底下的两个点可以当做骨盆髂骨,其余是肩膀和手臂。由于图片更多的是上半身视角拍摄,所以骨骼的其余部分,尤其是双腿并没有呈现出来。
有了骨骼之后,我们用它来做什么?ControlNet和它的模型起到的是指引作用,由于我们在文生图界面,所以我会放入一些指令,然后生成一些东西。
复制一些经常使用的指令,并且将设置改为我习惯的设定,确保你的预处理器和模型始终是匹配的,否则你会得到一些很有趣的结果。别忘记勾选启用"enable",这一点同样重要。

这是我们生成的结果,可以注意到生成的角色遵循了OpenPose骨骼,右侧的胳膊弯曲,左侧胳膊处于很自然的位置。尽管不是那么正确,我们总是可以在绘制的时候解决,或者,你们也可以看到我是如何处理的。
我们再次点击生成,上面的结果或许是侥幸的,或者是我们比较幸运,但我有些怀疑,所以不妨多生成几次来测试效果。

可以看到,角色的姿势与OpenPose骨骼保持一致。
1.2、深度、segmentation、法线通道概览
在解释其他的预处理器和模型之前,我先来向你们介绍深度颜色(depth color)ID或Clown pass以及法线通道(normal
pass)。如果你是3D美术师,那么应该已经非常熟悉这些概念。然而,我相信大多数使用Stable
Diffusion的人都不知道这些东西是什么,所以我会认真讲这些东西,因为如果我们要充分利用ControlNet的潜力,那么它是一个需要了解的重要基础概念。
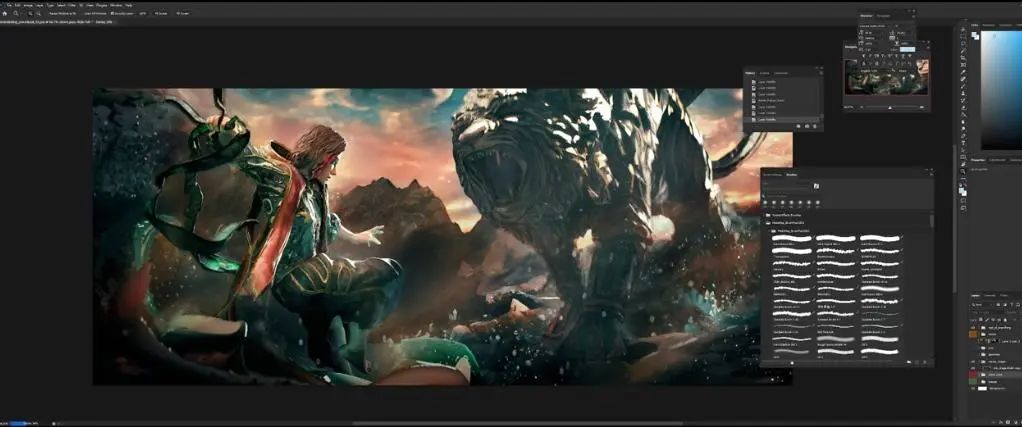
我们跳转到Photoshop,这是我在Fleet
City系列图片里做的一张图片,这些图片是通过在3D环境对物体进行雕刻、建模和贴图得到的,对它们进行渲染然后绘制。图片中的图像遵循同样的流程。
右下角你可以看到一个叫做通道(passes)的文件夹以及clown pass,后者是很多层当中的一层,这就是clown pass:

如果仔细观察,可以发现它基本上就是一个语义分割通道。

这是深度通道(depth pass)

这里是法线通道
如果你觉得这些没有帮助,不要担心,我接下来会一步步解释。如果你对我从Blender得到的图片是什么感兴趣,那么:

刚刚展示的是最终的图片,这是从Blender得到的图片

这是我通过图生图之后得到的图片,可以看到天地之间的界限比较模糊,这可以让狮子更有型,这是个很强大的工具。接下来我们说通道,我会先从最容易理解的开始。
1.3、深度通道

从Blender获得深度通道有很多种方式,但我的方式是渲染一个Mist通道,我们随后将会为3D
OpenPose骨骼使用的Blender文件,用另一种技巧渲染出了深度通道,这只是个人偏好的原因。

第一眼看深度通道,可以看到很多灰色形状,所以100%的灰就是黑,0%的灰色就是白。在2D和3D当中,白色遮罩(white
mask)代表一切都是显示的,黑色遮罩(black mask)意味着一切都被隐藏。了解这些之后,我增加一个白色遮罩,可以看到什么都没有发生。

然后,我们撤销操作,再增加一个黑色遮罩,可以看到深度通道消失了,它之下的那一层(法线通道)被显示出来,所以,这是需要理解的非常关键的概念。

如果注意摄像头的远方,可以看到一种叫做大气霾雾(Atmosphere
Haze)的现象,可以看到近处人像饱和度更高,远处的城市饱和度不足,因此显得更亮。如果这仍然不能说明白,那么我们进入Photoshop界面:
我们在图片上新建一个黑色图层,然后选择颜色混合模式,它看起来会是这样:

如果仔细观察,可以发现离我们比较近的一切都显得更暗,远处的区域仍然更亮一些。

我们再调暗一些,可以看到天空明显有大气霾雾现象。

如果还不相信,可以反过来,将色调调更亮,远处的东西很快就消失了,如果再继续调亮,就会让图片内容模糊,不过岩石与图片其他部分相比仍然比较暗,这就是深度通道。
回到最初的深度通道,它告诉我们的信息是,这个女性角色离我们更近,狮子稍微远一些,因为与前景相比它的值更亮。
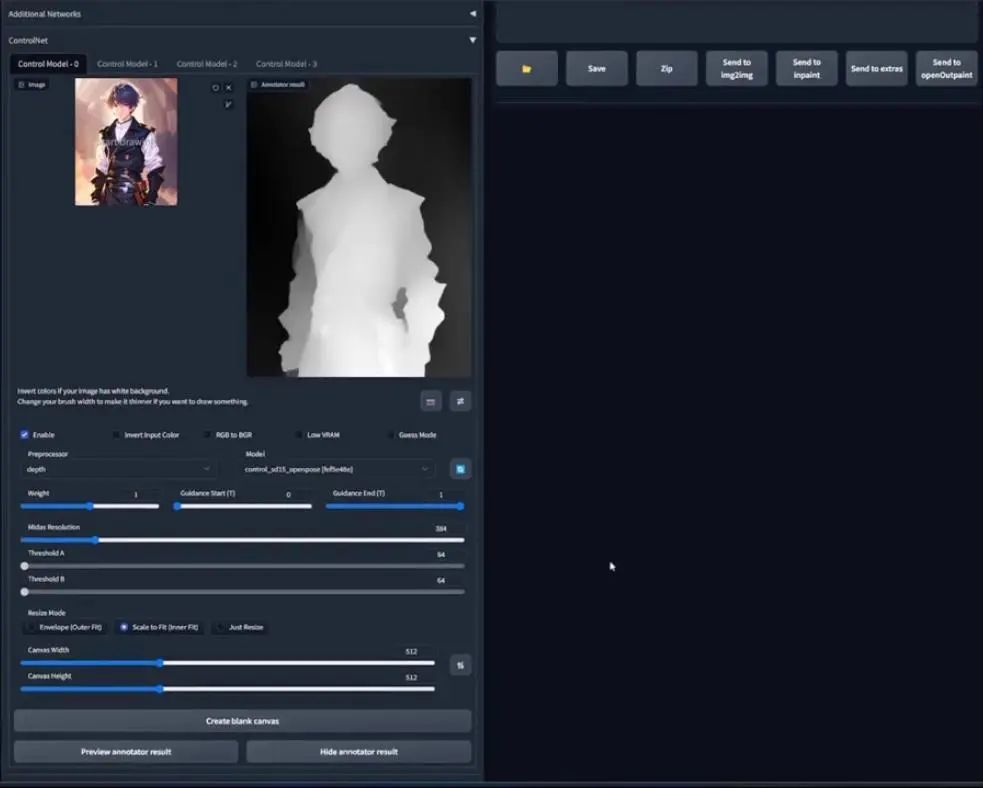
所以我们回到webui,如果我们想要使用深度通道,只需要将预处理器换成depth,然后按preview Annotator
Result,就可以得到展示角色图深度信息的图片。然而在webui当中,深度图的信息是反转的,可以看到前景更亮,背景更暗。
还记得之前所说的吗?白色遮罩意味着一切都显示出来,意味着白色区域会接收更多的指令指引,因此生产图片的时候,这个男孩的形状是会被保留的,但颜色之类的信息会改变,因为这不是图生图操作,我们无法看到背景的效果。运行之前,确保模型切换为depth,保持和预处理器一致。

这是生成的新图片,看起来有些像《最终幻想14》里的阿莉塞,这是我没有预料到的。

如果两者对比,可以看到原图是穿黑色军队服装的男孩,而生产图则是浅色衣服的女性,因为指令里添加了女孩这个提示词,但角色身体的形状保留的非常好。
1.4、segmentation pass
接下来是segmentation pass,它实际上和clown pass一样,基本上它们都是可互换术语,通过颜色将不同目标区分。

可以看到角色的头发、衣服、身体都用不同颜色分割。
狮子是通过不同部位颜色进行分割,因为我可以通过Zbrush改变不同部位的摆放。

Clown pass很容易理解,但这里我会用demo展示,你可以选择多个部位进行重绘,而且不会影响到其他部位,这也是这个通道对于渲染非常重要的主要原因。
回到webui,将预处理器改为segmentation,然后点击preview annotator result:
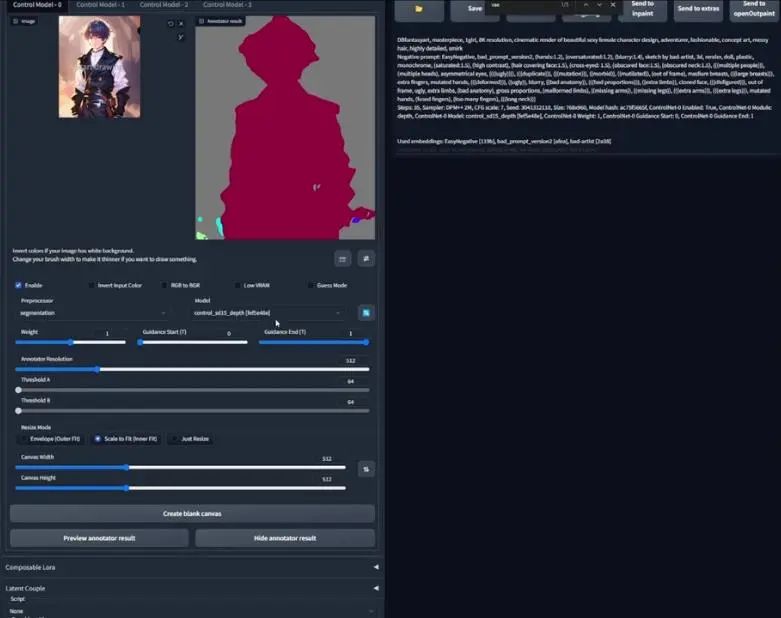
我们看到有斑点的角色,几乎是紫褐色的,这是因为在iliasville的segmentation论文中,他表示语义分割是基于SDE20K数据集进行训练,如果深度探索,我们可以发现它对人物的划分颜色就是紫褐色。
我们再次用同样的指令运行,别忘了将模型改为seg模型。可以预期的是,我们将生成一个女性角色,因为提示词里有girl,但角色姿势可能会变化,因为紫褐色块状作为局部重绘遮罩,因为它是红色的,所以仅对于人类有效。
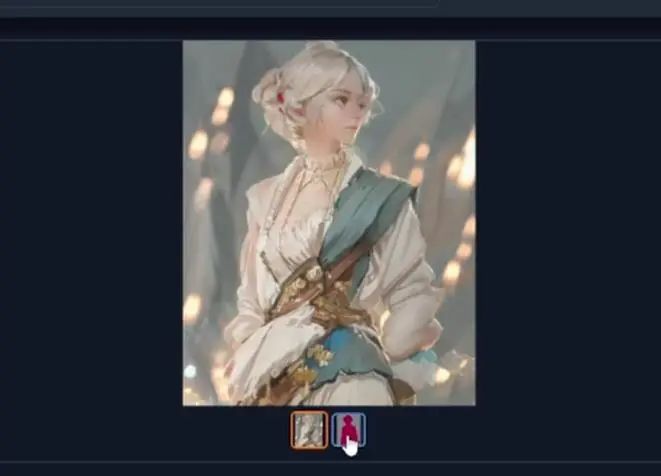

这是我们用segmentation预处理器得到的第一个结果,可以看到这个女性看向右边,与原图男孩的视线方向刚好相反。至于其中的原因,你可以点击第二张图片,发现生产图片与其剪影完全一致,而后者又是从原图得到的。
我们再生成一次,看得到什么结果:

这一次得到的角色看着自己的右肩膀,但它们的剪影是一样的。
1.5、法线通道
最后是法线通道,如果你不是一名3D美术师,这个概念是很难理解的。基本而言,法线贴图是给基础模型细节的图片,现在我展示的是最初的Blender场景,如果放大观看狮子头部:
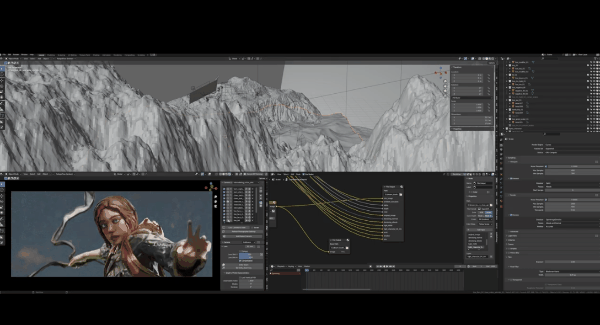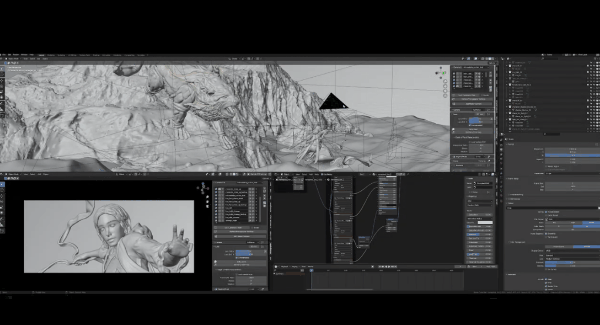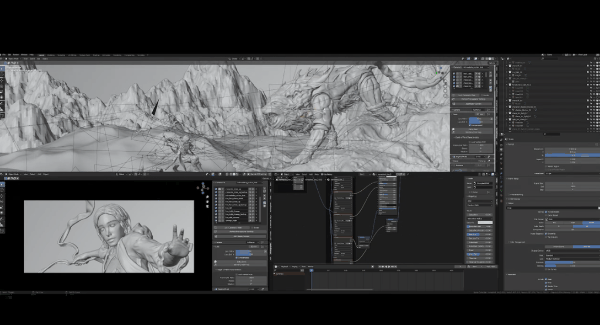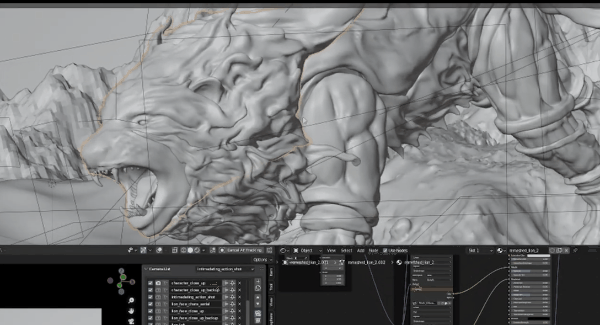
你会发现模型的细节并不差,实际上非常平滑,因为在渲染时,法线贴图具备所有烘焙表面细节映射到场景中每个目标的UV空间上。所这个场景中几乎所有东西都是UV过的,只有一些例外,比如地面、山脉和水域是程序化生成的,因此它们有自动UV,效果很差,但没有关系。
我们这里选择狮子的头部,调出它的法线贴图,所以我们将它拖拽到另一个窗口。我将切换到图片编辑器然后打开纹理位置。
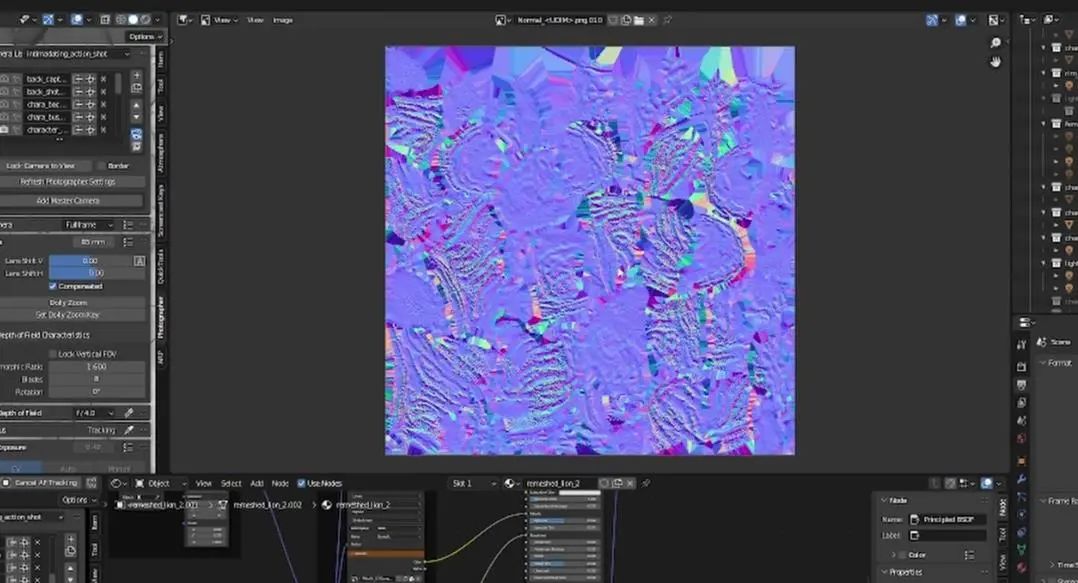
这就是一个法线贴图看起来的样子,通常是蓝色,和一些红色、绿色组成,不过大部分颜色都是蓝色。我们用烘焙法线贴图的原因是,我们做雕塑的时候如果不用法线贴图,就会有上千万面,渲染一帧就需要数分钟。如果是一个由数十亿多边形的场景,那么渲染一帧的时间就会长到无法接受。
所以,说了这么多,我想要让大家知道的是,法线贴图就是细节保留。另外,如果你想知道如何从Blender得到法线通道,方法其实很原始、很基础。
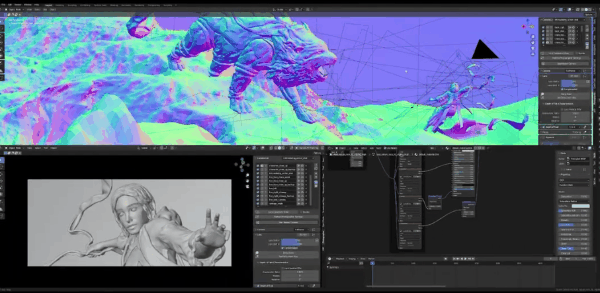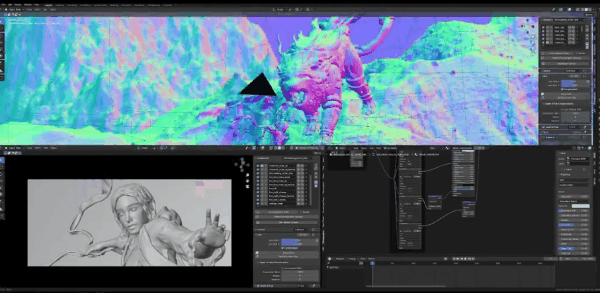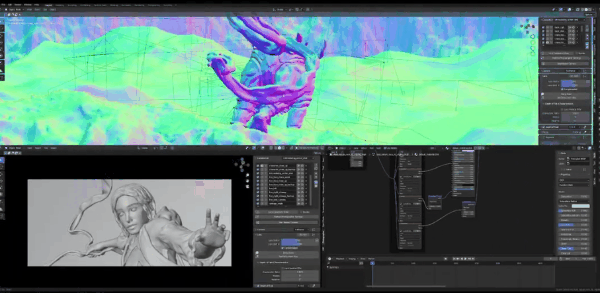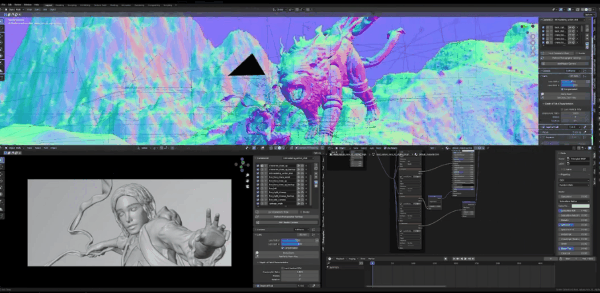
到右上,点击Matcap,然后确保是用的Single而非其他标签,然后确保颜色是纯白,零色彩、零饱和度,数值为1,就可以得到法线通道。
随后,我们回到webui,将预处理器改为normalmap,模型切换为normal,然后预览annotator结果,这就是它给我们的法线贴图:
我很确定Blender里的法线贴图不是这样,但这是预处理器告诉我们的结果,所以我们再次生成,看得到什么结果:

可以看到很多东西被保留了下来,比如将军外套,甚至比深度图保留了更多细节,比如书包,不过大致上与深度通道相差不大。

再次生成,可以看到角色发生了一些变化,不过书包仍然保留了下来,外套颜色有所变化,但让角色看起来更加英俊
1.6、Canny
接下来是边缘检测贴图(edge detect maps),具体的边缘检测预处理器和模型是canny,列表中的hed,全称是holistically
nested edge detection,mlsd指的是multi-scale line segment detector。
Canny预处理器是一个规则为基础的边缘检测算法,被发明于1980年代,我们点击预览annotator结果来看得到了什么:
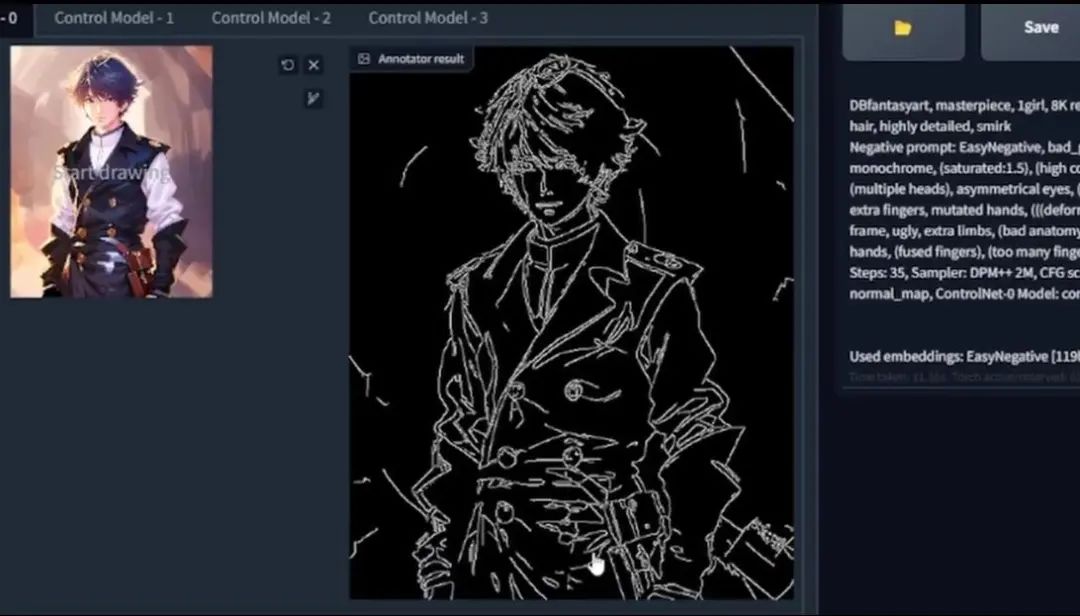
我还会选择HED来对比差别:
除了是深度学习算法或模型之外,它们之间的差别并没有那么大,只需要选择你认为好的就行。
我们选回canny、将模型切换成canny,然后点击生成:

这是我们从canny模型得到的第一个结果,可以看到,虽然图片发生了变化,但线条仍然十分完整。
1.7、HED
这次我们尝试HED,将模型换为HED,点击生成之后得到这张图片:

看起来很像韩国明星,可以看到白色边缘仍然存在,但线内的所有东西都改变了。所以你可以把它当做一本填色书,你只需要将颜色轮廓内部重新填色即可。
1.8、MLSD
边缘检测最后一个选择是mlsd预处理器,如果从名字multiscale line segment
det.来看,你可能会觉得它在人类图像上行不通,当然你这个想法是正确的。
接下来,我会使用最喜欢的3D程序,它是计算机辅助设计软件moment of inspiration
3D(简称MOI3D),调出我在那里创作的硬面模型,以充分展示mlsd预处理器和模型的全部潜力。
回到Stable Diffusion webui,我将自己创作的刀柄放到这里,将预处理器和模型切换为mlsd,然后预览结果:
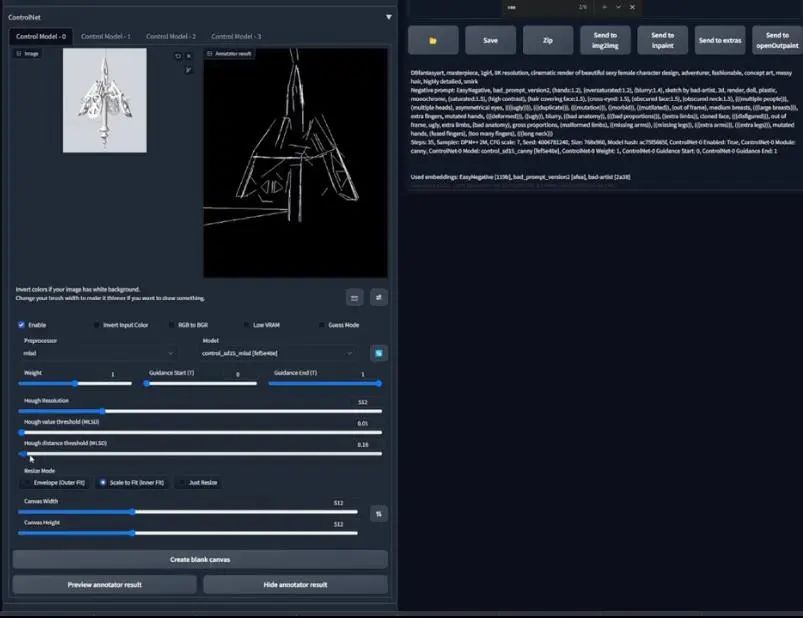
看起来不是很奏效,我们不妨改变阈值,降低一些,结果更接近了,但我们还可以调更低。
将指令进行修改,将剑柄加进去,再加一些描述词汇,然后看生成什么结果:
可以看到,它将一个剑柄生成了一个全副武装的人,不过看起来也是很酷的。
我们改变指令,再次生成:

仍然没有得到我想要的剑柄,我们再次尝试改变指令,比如加入武器、尖锐的物体:

看起来好了一些,仍然是不理想的,不过我们已经可以看到了潜力。这就要说到我们没提到过的最后一个预处理器。
1.9、Scribble
这是Photoshop界面,对于Scribble,我们需要画一张图:

涂鸦是比较痛苦的事情,对我来说,它整体看起来还行,我们把它导出,用刚刚画的涂鸦,然后将预处理器选择成Scribble,实际上是伪Scribble,同样把模型也改为Scribble。
我不希望太遵循涂鸦,所以将权重降低到0.6,预览、然后点击生成:
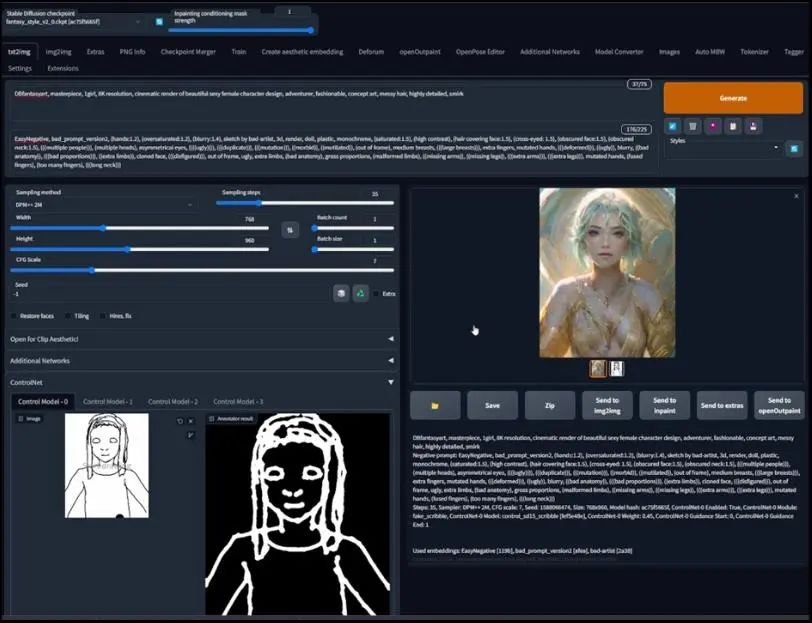
这个结果稍微好一些,但仍然需要加工。
所以,以上就是ControlNet的这些预处理器和模型,有些预处理器我没有详细说,不过别担心,如果有机会,我会在后续提到它们。
了解了它们之后,我开始通过openpose将这些预处理器运用到角色设计中,为此,我首先要用openpose编辑器扩展。
**第二部分:Pose编辑器**
* 12.1、OpenPose编辑器
我先从创作一个角色模板开始,在角色设计管线当中,角色模板是很重要的一部分,通常在此之前,你已经创作了一些缩略图,但这个部分也可以作为你的缩略草图过程。
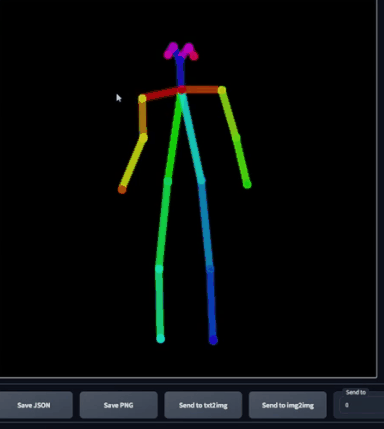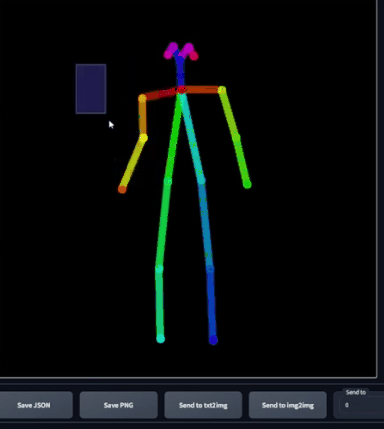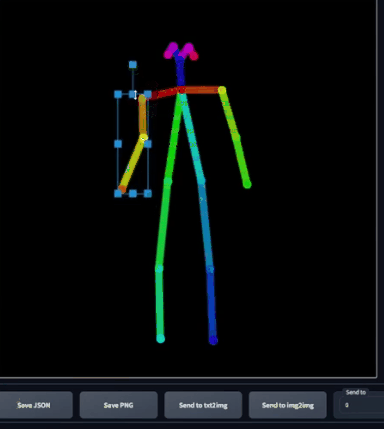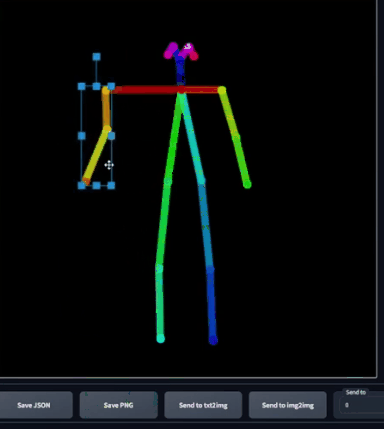
这个骨骼很直观,你可以调整身体部位,如果想要整体移动某个部位,选中对应位置即可。然而,这并不是一个逆运动学绑定(inverse kinematic
rig),所以物理上并不精确,如果是逆运动学绑定,如果我移动了胳膊,那么肩膀也应该随之运动,但很明显这里没有。这只是一个2D骨骼,而非一个绑定。
另一个使用它并非好主意的原因是,这里没有depth preservation,因为它基本上就是一个只有两个维度的单眼图像(monocular
image)。所以这些是它的两大主要问题,还有一些小问题。
不过,这并没有关系,如果我们想要快速丰富基础想法,它仍然是各很好的工具。你可以按照自己的喜好设计好一个姿势,但并非所有人都有那个时间探索,所以我们要做的是从已有图片检测。
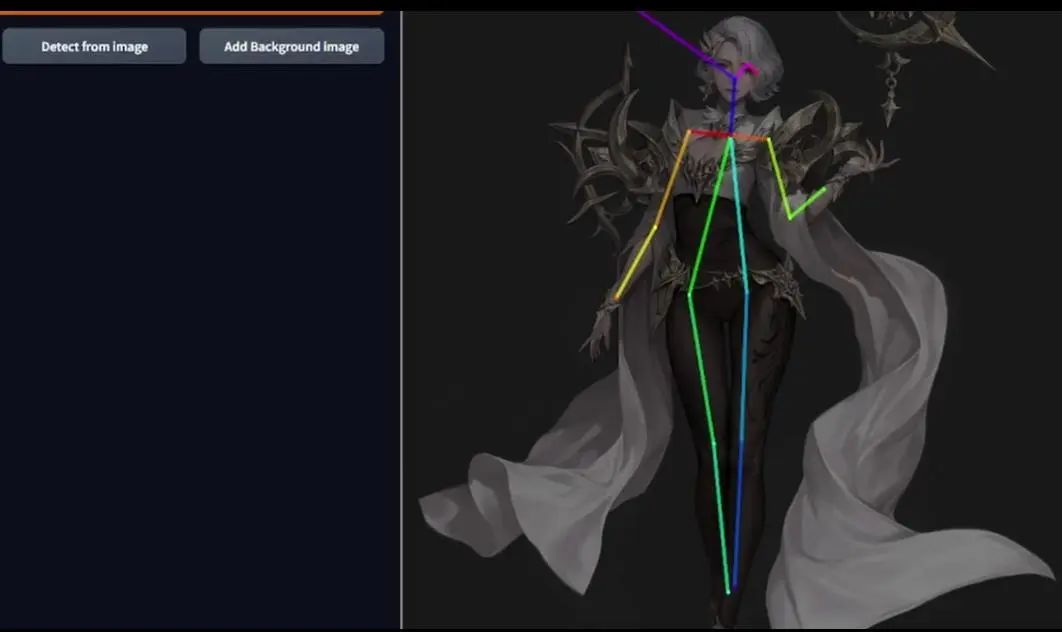
这是我们选择的第一张图片,加载需要一些时间,这些线就是得到的姿势,不过有些出错。
如果你了解过Openpose,就会知道头部的中间点应该在鼻子位置,两侧应该是眼睛,所以这样对我来说是可以接受的,虽然不那么完美,但并不影响理解。一旦有了你满意的结果,就把他存储为PNG格式。
现在我们想要使用已经做好的骨骼,来确保它真的可行。
打开控制模型,拖拽openpose骨骼,我们不需要预处理器,将模型切换为openpose,如果一切看起来不错,那就点击生成,我们生成的图片应该紧密遵循这个骨骼姿势,但谁知道呢?我们来看看结果:

这是第一个结果,角色胳膊从肘部弯曲,另一只胳膊自然摆放。
再运行一次,看它是否与骨骼姿势一致:

可以看到非常忠于原图片,这个结果很酷。
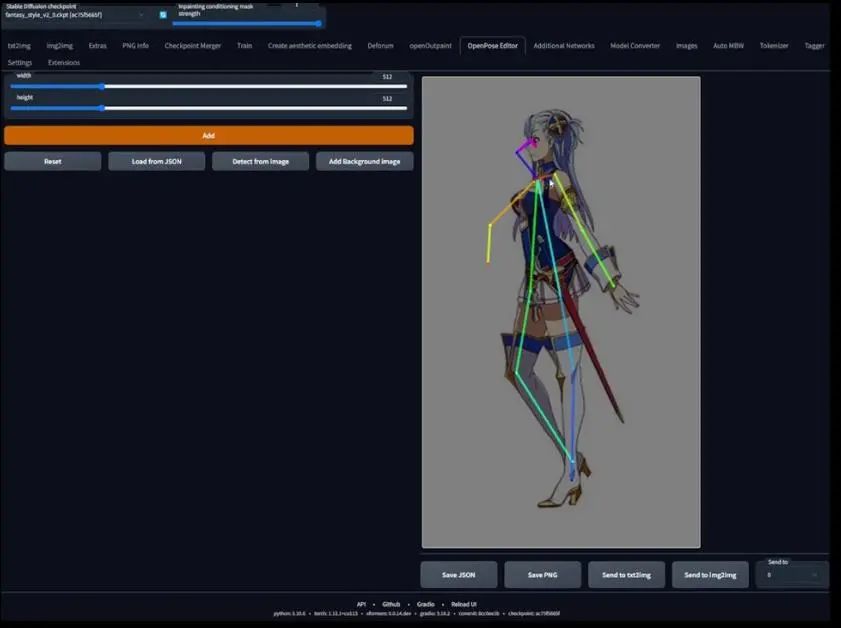
我们回到openpose编辑器,做更多的模板。我用图片检测方式得到了另一个openpose骨骼姿势。这里可以看到角色没有左侧胳膊,所以,我会进入Photoshop删掉这个关键点,然后用黑色覆盖。
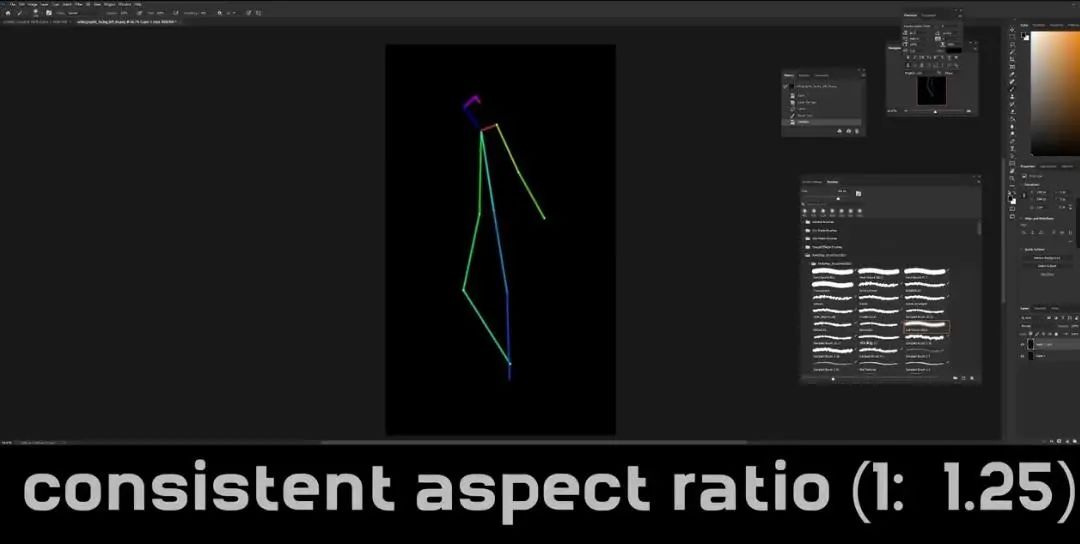
这里我们需要做两个非常大的改变,首先是去掉左侧肩膀,接下来是确保你的骨骼分辨率与指令匹配,我的分辨率是768×960,因此两者要一致。所以我们新建文件,将骨骼复制到新文件上。
可以看到它们并不匹配,所以我需要修改骨骼图片的大小,然后将背景变成黑色,随后将其保存导出到Stable
Diffusion。与以往步骤一样,拖拽,预览annotator结果、生成:

第一个结果看起来仍然不够清晰,因为左胳膊显示了出来,所以我们再次生成,第二个结果看起来还不错。

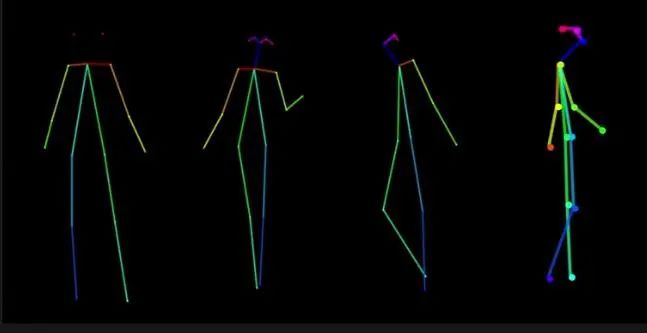
接下来我会做一个反转姿势。
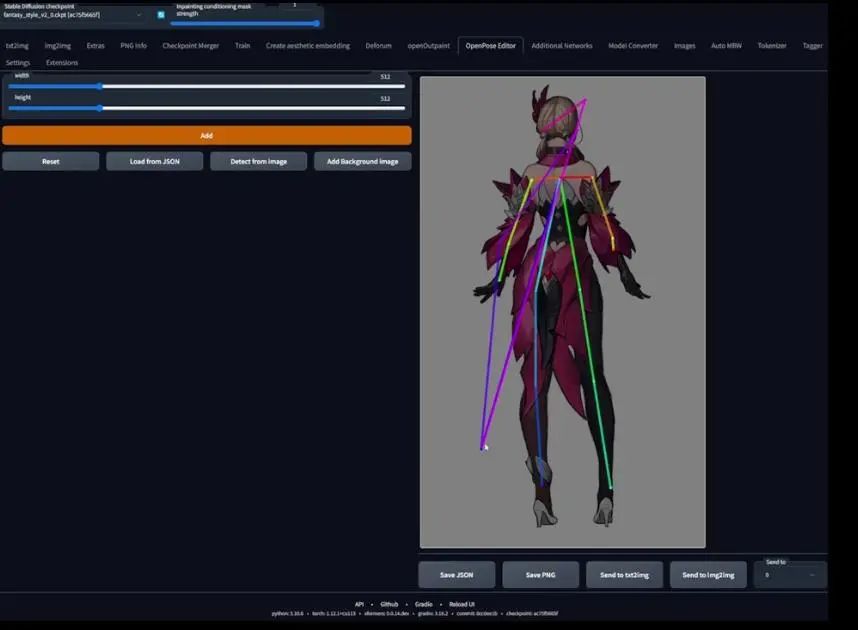
这里是个显示背面的角色,我们需要对生成的骨骼模板进行调整,上边的蓝色可能需要去掉,因为可能会被AI理解为角色在向上看。
将骨骼图片倒入Photoshop,由于是背面图,我们需要将骨骼模板当中被理解为眼睛和颈部去掉。所以我会新建一个图层,选择头部中间的一切,将它变成黑色。另外,别忘记将分辨率保持一致(新建文件、复制粘贴,修改大小、将新文件背景改为黑色,保存)。
现在,我们将骨骼模板导入Stable
Diffusion,之所以将头部骨骼抹去,是因为我尝试了之前的版本,但生成的结果全部都是正面视角。所以,希望这次能够有理想的效果,我们点击生成:
结果看起来不错,两次生成都是背面视角。
对于最后一个视角,侧面视角,我发现大部分图片生成的谷歌模板都不好用,所以哪怕很痛苦,我还是决定自己画,因为有时候我们别无选择。
这是我画的结果,希望它能奏效,因为绘制的过程真的很乏味。
角色的头部仍然有些靠前面,或许是因为骨骼模板里的蓝色记号是错的,我们再生成一次:

结果是一样的,可以确定是蓝色记号的问题。所以我们解决这个瑕疵然后继续。
调整幅度很小,所以我们直接再次生成:

我对这个结果还算满意,虽然腿有些短。
我们继续调整骨骼。我的方法是将多个姿势的谷歌进行对比,然后试图将所有部位保持同样的高度,然后将分辨率设置为1920×960,点击预览annotator结果之后开始生成:

某种意义上来说,这个结果也不错,哪怕脸部是一团糟,而且很多地方出错,但如果你将这个版本交给艺术总监,那么他一定会对这个结果感到满意。如果了解3D美术,就知道这个版本已经可以用来进入下一个概念模型了。
然而,这仅仅是模板的表面,虽然第一个结果看起来有些粗糙,但我们可以通过调整设置多次生成,找到我喜欢的概念然后保留种子继续优化。
我们可以在指令中写入深色长筒袜,因为在LoRA模型当中,这样做可以将注意力更多的放到上半身的训练。将批处理量改为20,然后我们点击生成,这会需要一定的时间,所以我们可以做别的事情。

数分钟之后,我们得到了20张不同姿势的图片作为参照,可以看到这些结果很多都不错。
然而这里有个小问题,我们可以发现所有生成的姿势图都存在不连贯的问题,同一张图片里的四个角色着装都不同。

有了这些之后,我接下来想要设计一个更细节的角色正面视角。需要补充的是,我希望创作的是起初展示的那个世界里的角色的一个朋友。

你们可能会问,为何不解决所有的这些问题,然后生成一个通用的角色设计模板以便提高后续的效率呢?

其实问题在于,每一张图片都有很多问题要解决,比如有些图片的上半身不连贯,如果逐个修复可能需要大量时间。
然而,这只是次要原因,最主要的原因在于,很多使用ControlNet的人都已经有了自己比较喜欢的角色,他们只是希望通过ControlNet改变姿势,或者以不同方式重构。另外,我希望展示如何通过用Stable
Diffusion和ControlNet生成更干净的输出结果。
现在我们只是使用了OpenPose模型,通过Blender以及toyXYZ的blend文件帮助,我们可以修改一个3D绑定骨骼,使用canny以及更多模型调整更多的细节,这在生成最终角色设计的时候很明显会快很多。
**第三部分:3D姿势(Posing in 3D)**
* 13.1、Blender介绍
介绍Blender之前,我们需要下载这个blender文件(链接),下载并解压之后,你应该可以看到这个OpenPosebones_47文件夹,打开并点击blend文件,随后你可以看到如下界面:
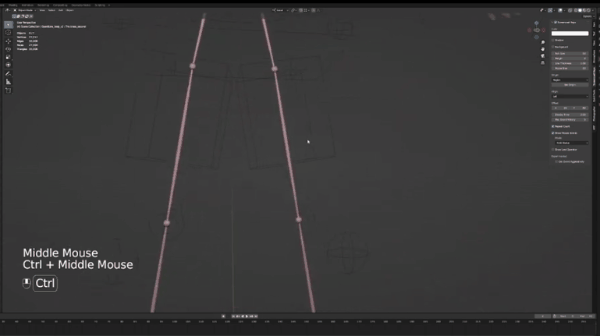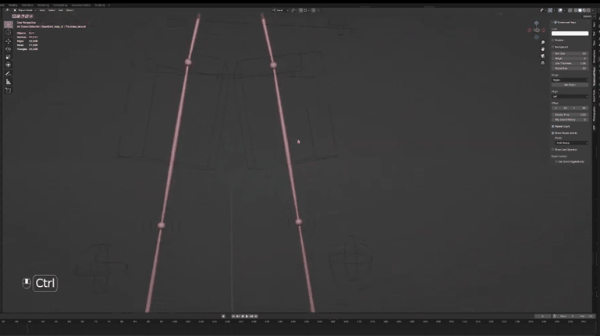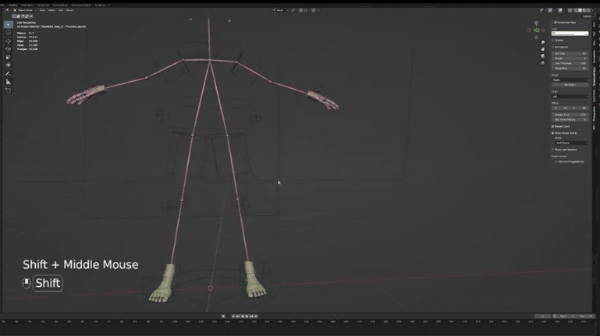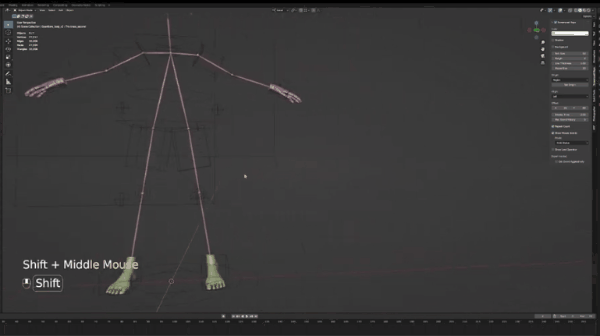
为引导摄像头移动,用鼠标滚轮调整,用shift+鼠标滚轮左右移动。
左上角这些叫做collection,都在当前场景之下,启用或者关闭某个collection,将其对应的勾选框打钩或取消即可。需要注意的是,如果你取消了collection,那么它不会出现在viewport或最终渲染中,有时候你可能想要单独渲染一些东西,所以这是个比较高级的技巧。
接下来我们说绑定,不要担心是否理解这个概念,因为更重要的是,你该如何使用它?
要修改绑定,你首先要选中它,然后点击左上角选择pose mode,当然,你也可以想我一样使用热键操作(如图):
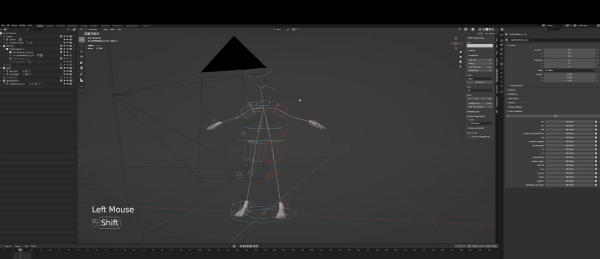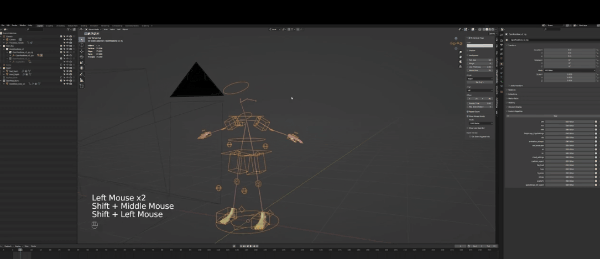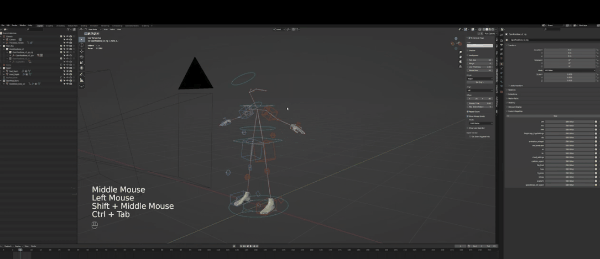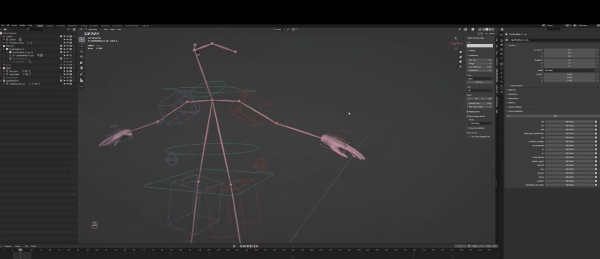
随后,你就可以对Control绑定进行操作,也就是图片里的那些箱子和圆圈。但你可能会问,这些东西用来做什么?
在3D软件中,你可以做的变体有三种,第一种是按G键移动,第二是R键旋转,最后是缩放工具(S键)。
通常来说,你不需要对绑定进行缩放,虽然偶尔会使用,但大部分时候都用不到,旋转是非常有用的,我们开始建模一个姿势。
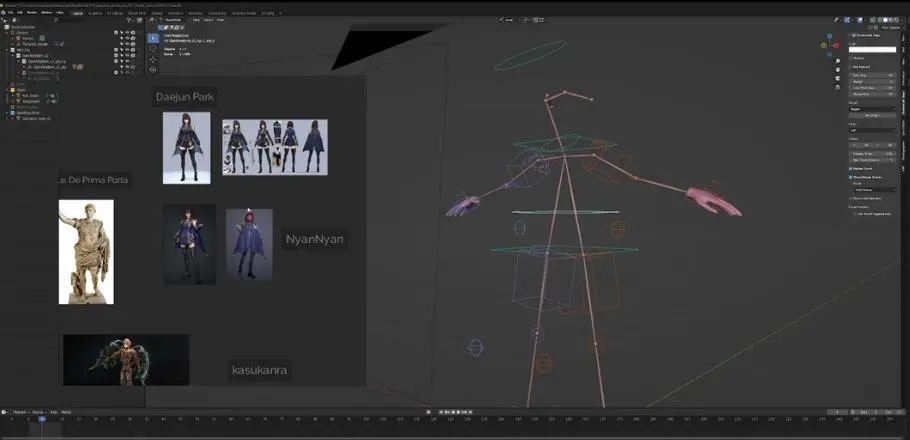
3.2、姿势基础
我们现在对模型摆造型,你通常会需要一些参照,所以左侧是一些来自其他美术师的作品,我主要参考这个来自NyanNyan的女性角色模型,它实际上是概念设计师Daejun
Park早期作品的粉丝艺术。
另外一个是"第一门的奥古斯都"雕塑,我去罗马旅游的时候也拍过一张保存在硬盘里。不过,他出现在这里是因为著名的"训示姿势(adlocutio pose)"。

实际上,这个女性角色的姿势也来自于此。训示姿势其实是一种对立式平衡(contrapposto)姿势,角色一只手举起来显示权力或者掌控。

你们可能会问什么是对立式平衡,我会在3D环境中展示,不过你们也可以看我做的一个雕塑,这是手势,不过躯干有些长,可以看到盆骨有些偏左,躯干有些向右后方,这其实就是对立式平衡,你需要平衡重力才能让角色不至于跌倒。
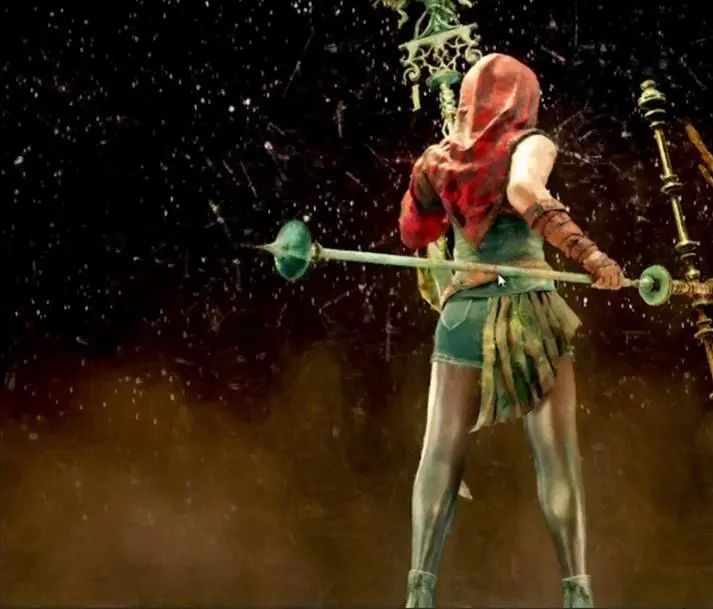
再来看这里的女性雕塑背面视图,这也是对立式平衡姿势,但我们看不到太多东西。

了解对立式平衡的基础之后,我们就可以从盆骨绑定开始。图片中可以看到角色盆骨在左侧,所以左侧应该是比右侧更高一些的。
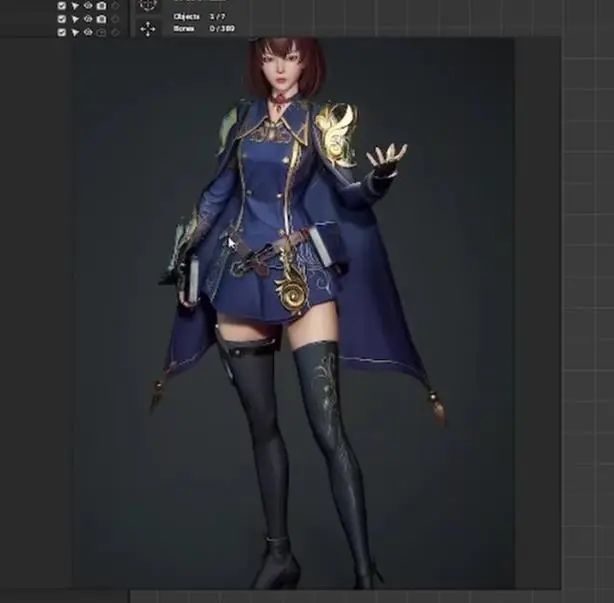
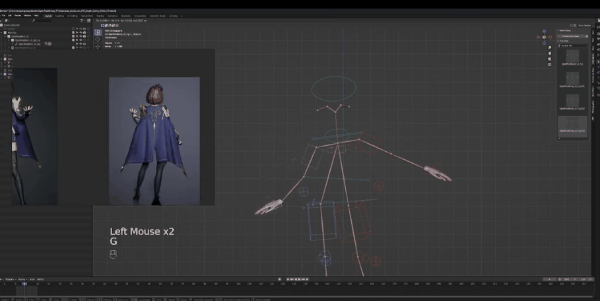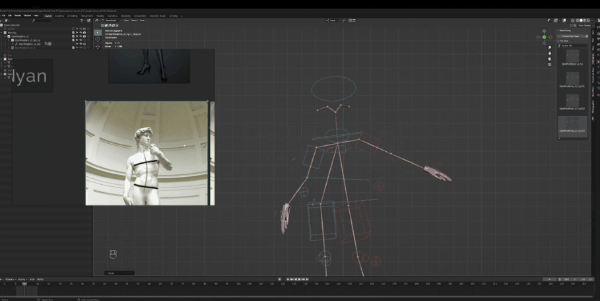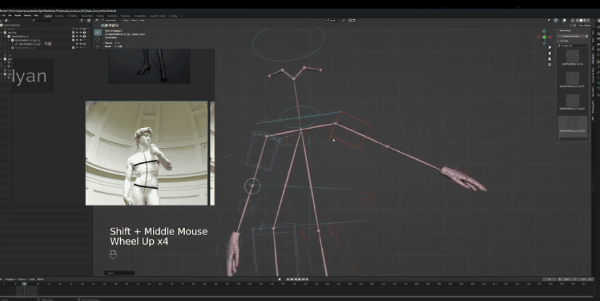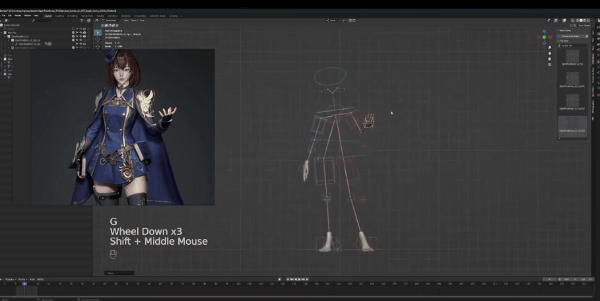
从图片来看,角色躯干有些向右倾斜,但实际上这是设计上的瑕疵。因为,当你向右倾斜的时候,那么支撑腿是左腿,这样做会让你倒下去。
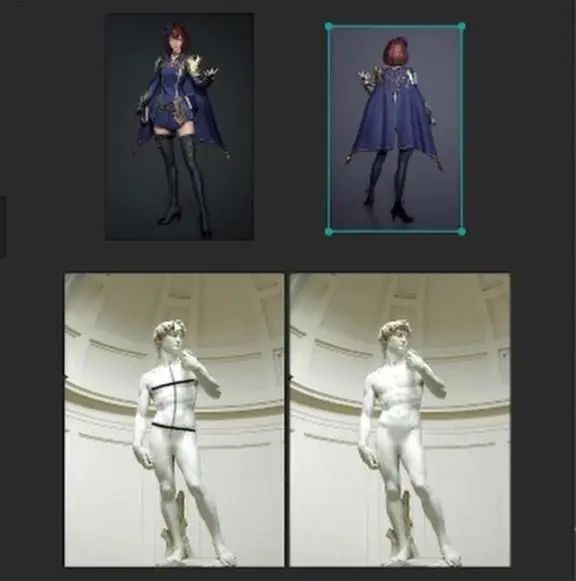
为了证明我说的点,我们来看大卫雕像,可以看到左腿是支撑腿,但躯干则是向左倾斜的,主要是为了平衡重力,所以女角色的姿势是有问题的。
不过,我喜欢这张图的其他元素,在进一步操作之前,我要重做这个姿势,所以Ctrl+Z回到中立姿势。原因是我们没有保存这个中立姿势,如果想要回到这个姿势该怎么办?难道要重新打开一个全新的blend文件吗?当然不是,Blender软件做的比我们想象的好。
如果我们想要保存或保留我们建模或绑定的姿势,只需要使用动画标签,而且它只在姿势模式的时候出现。
所以,点击绑定,然后Ctrl+Tab,这时候就有了一个动画标签,点击创建姿势资源,这就是基础的姿势。然后在点击新建一个姿势,如果想要回到默认,可以点击右上角上边的姿势,如果想回到盆骨调整的姿势,可以点击下边。
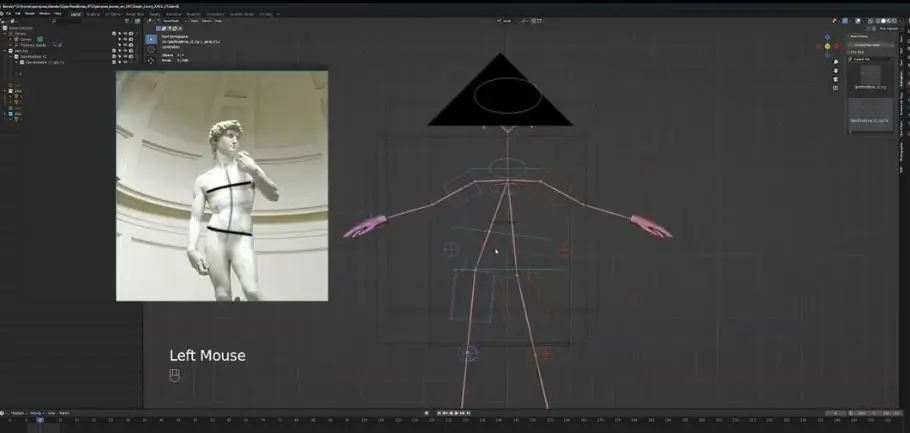
盆骨摆好造型之后,我们需要做躯干或者肩膀的姿势,可以看到,左侧图片里下方灰色线是从左到右降低的,为了保持平衡,我们需要选中肩膀,让右肩膀比左肩膀更高一些。
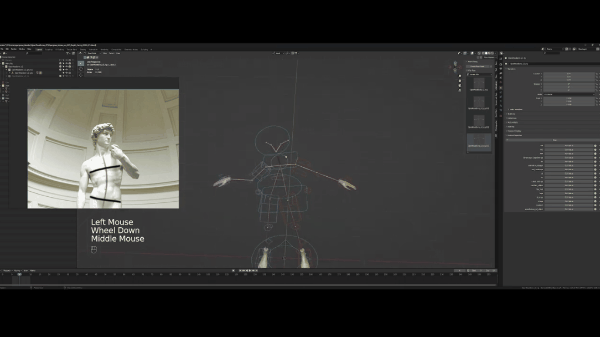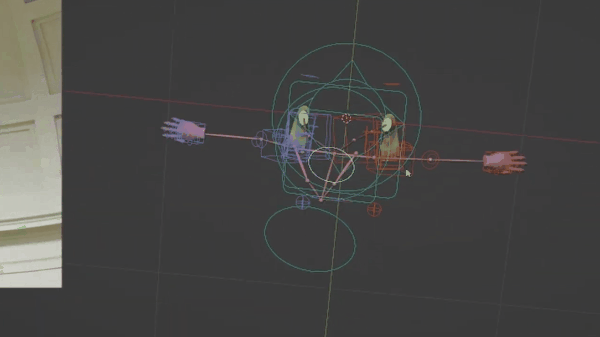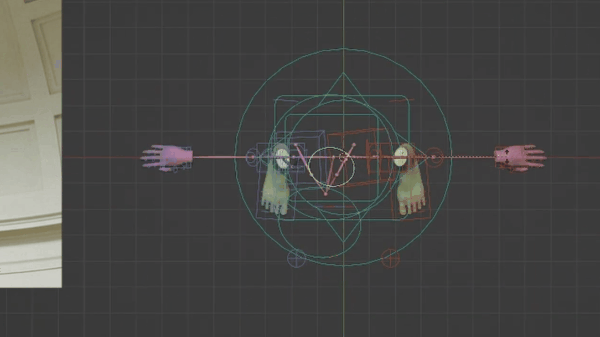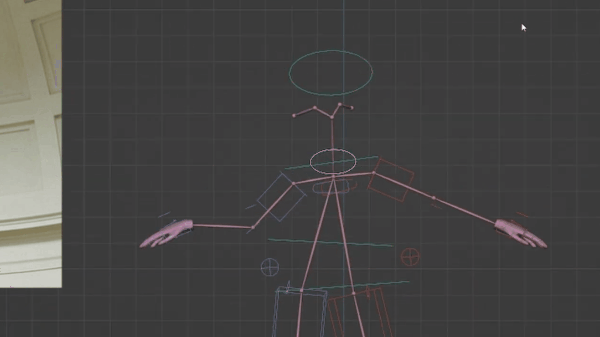
接下来我们做头部姿势,一直看着摄像机很奇怪,所以我们关掉它。如果我们来看大卫雕塑的头部,它是向右旋转的,目光向上看,我们不需要让角色看的太远,但可以对头部进行小幅度旋转。为此,我们选中颈部圆圈,进入俯视视角,然后旋转,如果想要向下看一点,也可以随时调整。
接下来我们要解决的是腿和脚的定位,如果对照图片,可以从正面图和背面图看出,右脚位置靠前。所以点击这箱子,按G然后将它向前移动。膝盖有点靠内,我们点击膝关节上的圆圈然后调整。另外,脚后跟也有些抬起,所以我们再次选中右脚调整,这时候姿势与参照图就非常接近了。
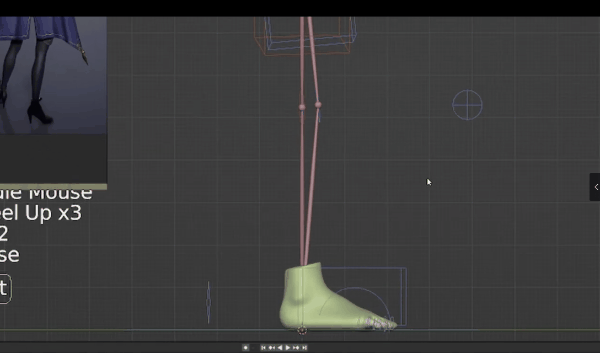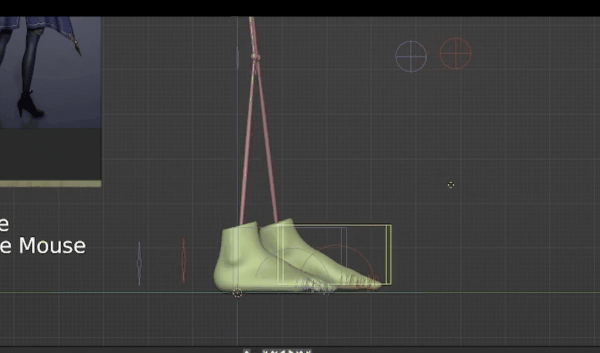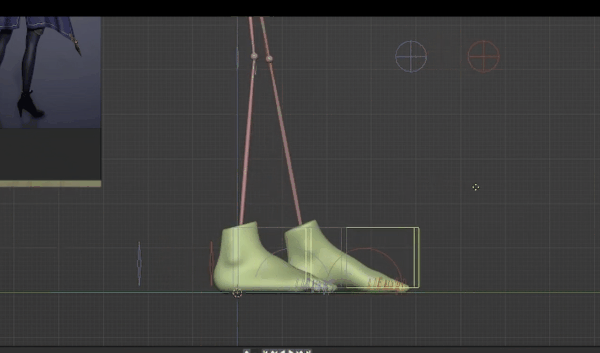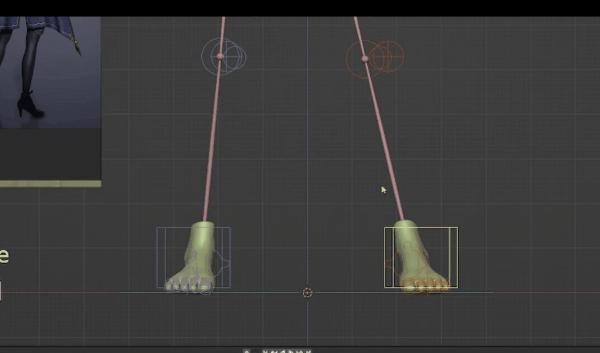
对于左脚,我们进入俯视视角,将其向后移动,另外,两只脚的距离稍近,而且左腿略微向外,所以我们对应调整。
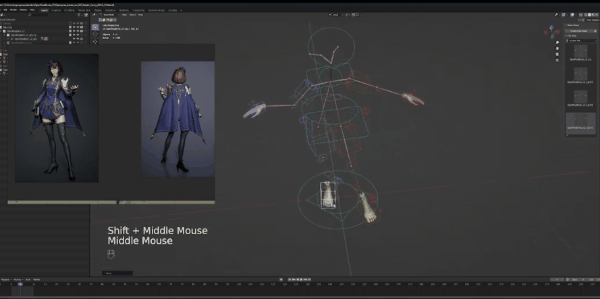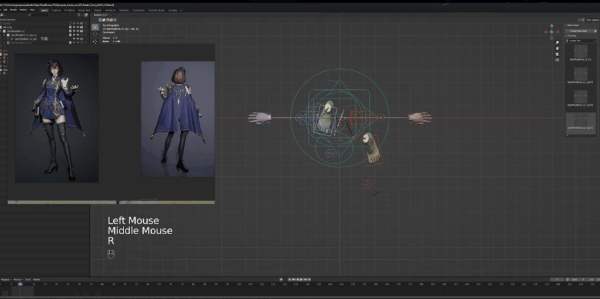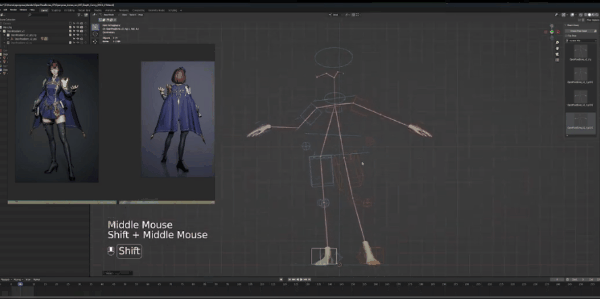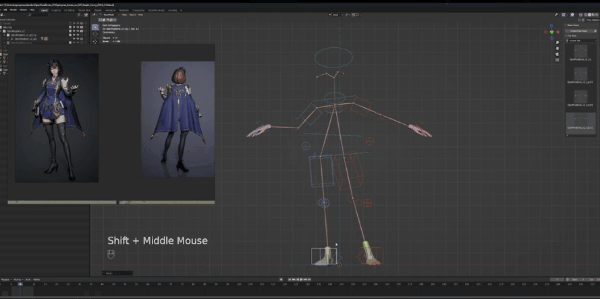
最后要调整的是胳膊,左胳膊看起来比较自然,所以我们将它往下放。如果对比大卫,左肩膀实际上比右肩膀靠后,所以我们要对其进行旋转,将左手位置稍微靠后放。手部是最后调整的,我们接着调整右胳膊。
弯曲,向前移动,然后旋转让手掌向上,通过姿势可以看到,我们的形状很简单,但都捕捉到了角色姿势的精华。
接下来是手部姿势,它有着自己的雕塑,所以我会给出一些建议和提示。
3.3、手部姿势
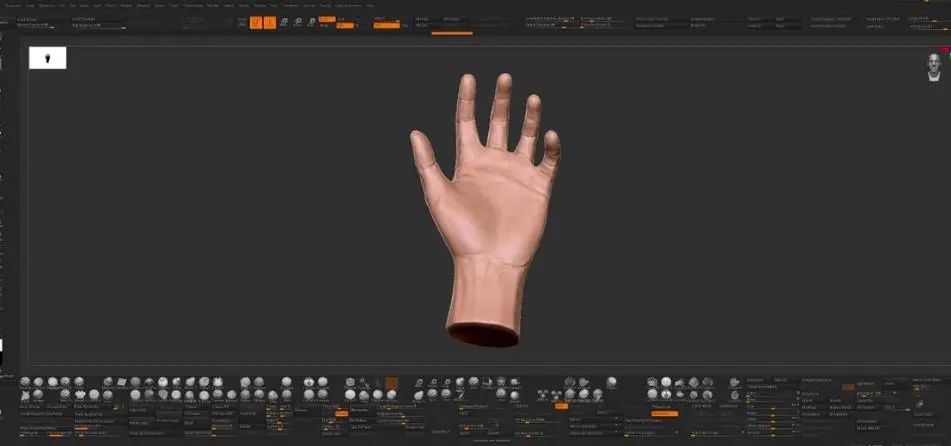
我们打开Zbrush,这是几年前我为了做深度研究做的一个手部雕塑,手部姿势最为关键的是手指的自然摆放。拉近看,可以发现食指钱两个关节是有些弯曲的,而且第2个关节的弯曲是第1个关节弯曲倾斜度的一半。

就像图片中标注的那样。如果不知道这是怎么来的,那么接下来我进一步展示:
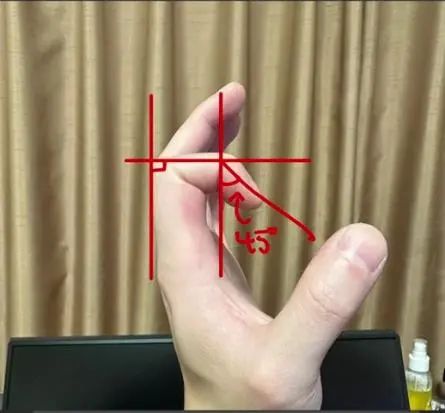
换一个姿势,你会发现食指这两个关节的弯曲度仍然是2:1。
这是几年前做的,虽然也能看,但明显和我现在的水平相比很低。当我们在Blender做手部姿势的时候,需要记住这些,以便得到看起来自然的手势。
进入Blender,我们开始给两只手的手指摆姿势。如果看不清手掌,可以关掉展示重叠选项。
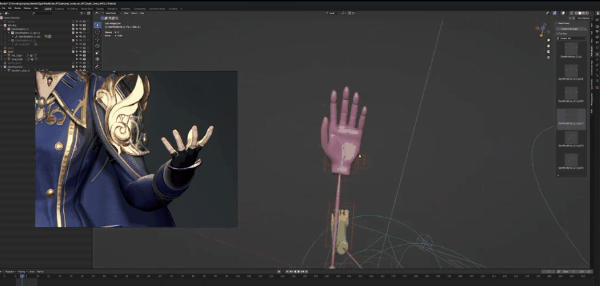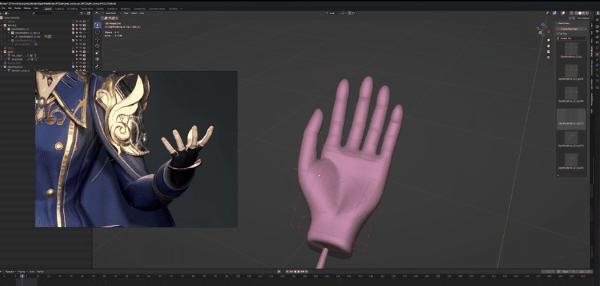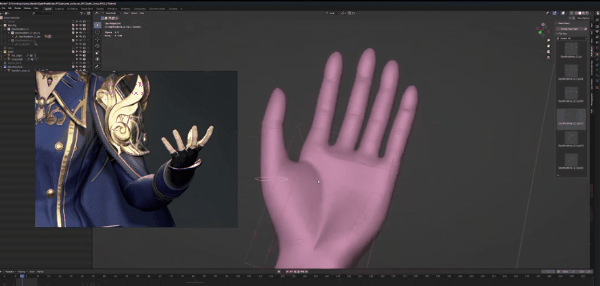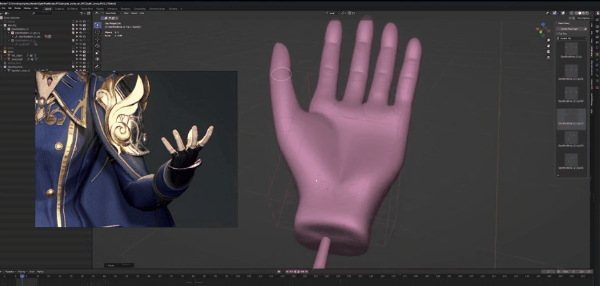
先调节大拇指,我们按参照图片将它向外扩,记得2:1比例,这样会让手指看起来更自然。将其余四根手指间的距离扩大,然后将其向上弯曲。
姿势里的手指比图片里稍长,这里我们先不作处理,等待生成的时候再解决。
经过了一系列的调整之后,姿势基本上完成了。
3.4、渲染通道
接下来我们可以进入渲染通道,点击右上角最后一个icon(视口着色,Viewport
Shading),就可以看到渲染后的效果,去掉重叠,可以看到一个OpenPose骨骼。所以我们回到姿势界面开始渲染。
点击F3,输入render image,点击这个选项,它就会给我们一个渲染通道:

不过,记得这里它渲染了一切,所以我们只需要保存OpenPose骨骼文件。
随后,我需要调整摄像机分辨率,以适应我的需求,我选择的是768×960。
再次渲染,得到的是深度通道,我们想要的是视图层,保存图片。
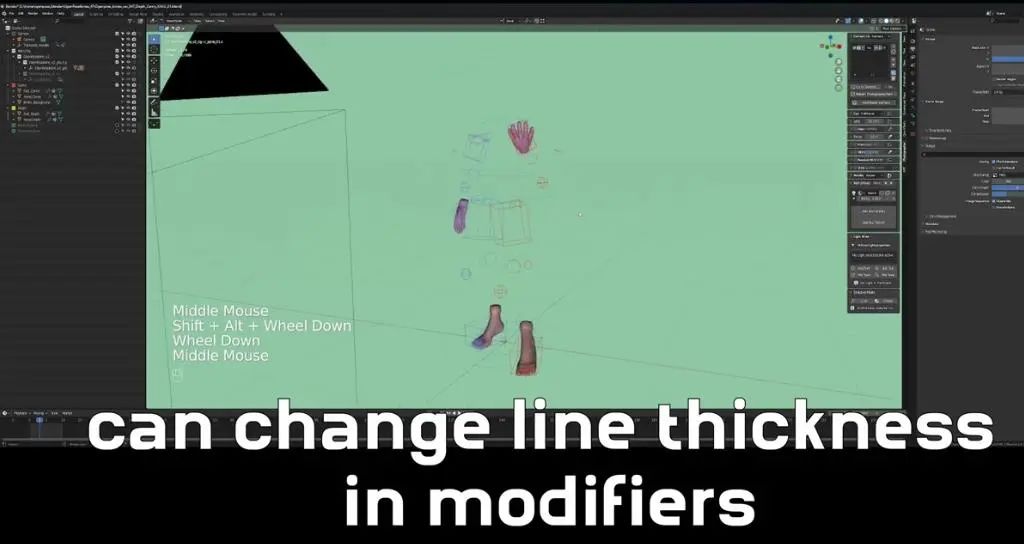
下一步是canny,我们想给双手和双脚增加一个canny通道,为此我们在左侧启用canny,关闭OpenPose骨骼,这时候你只能看见手和脚。
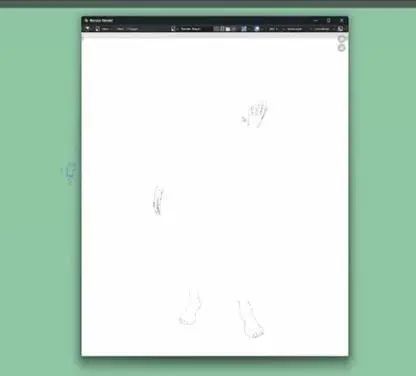
点击渲染,进入视图层,这就是我们的canny通道。
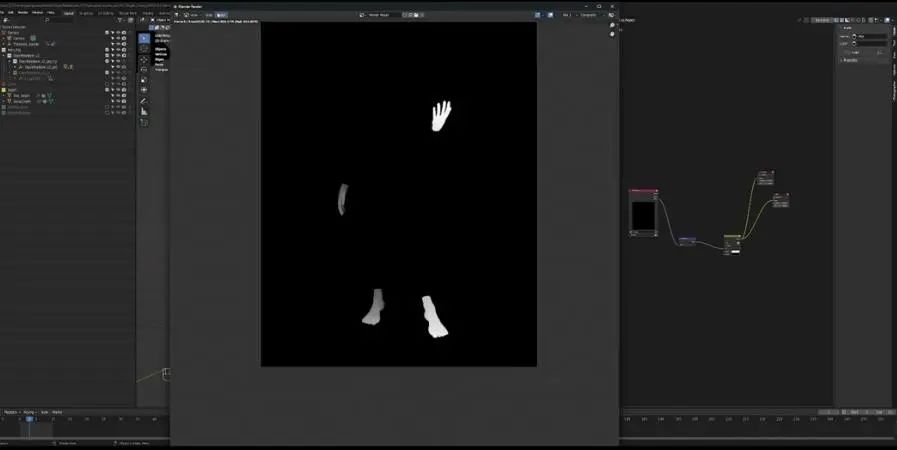
最后是深度通道,这一步很简单,渲染,然后保存图片。做完了所有通道之后,就可以回到Stable Diffusion了。
**第四部分:Multiple ControlNet**
* 14.1、创作基础设计
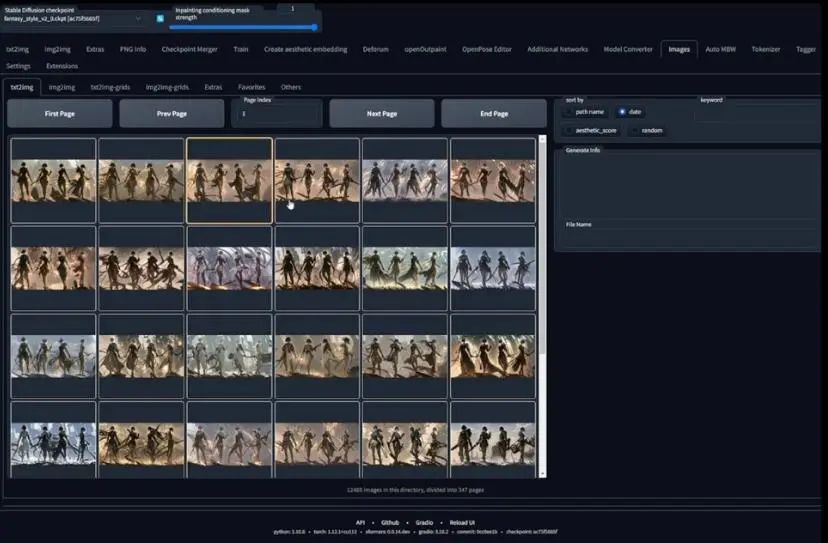
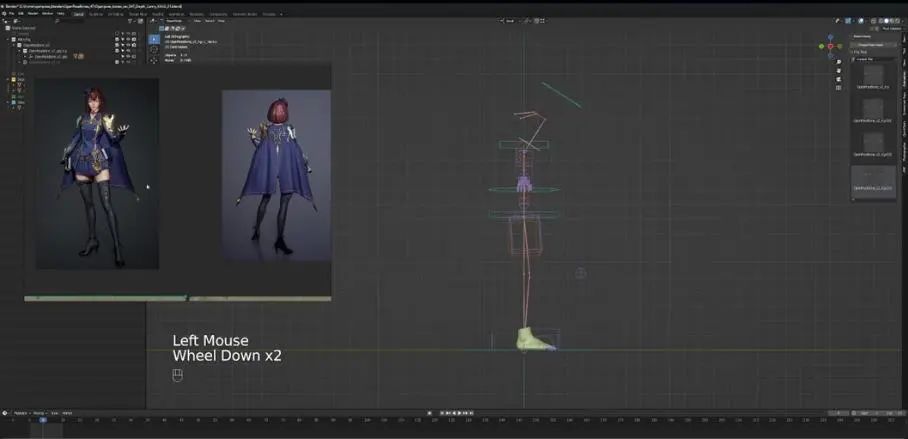
在webui界面,我们想要用ControlNet测试从Blender得到的贴图,但我们首先需要确定一个种子。我们可以点击图片(images)标签,从之前生成的模板当中选择一个,然后选择发送到文生图。
改变权重,比如分辨率是768×960,保存种子,然后看ControlNet在做什么。
首先是地以一个通道OpenPose,拖拽之前保存的图片,启用,将模型改为OpenPose,点击生成:

可以看到结果有些令人困惑,因为每一边的胳膊都有两条,不过,可以看到OpenPose姿势被保留了下来。
接下来我们看另一个Control模型,启用,这次选择深度通道,选择深度模型,将guidance start修改为0.3,然后生成:

仍然多了手臂,手握成了拳,脚似乎抓住了什么东西,不过稍后我们看到底发生了什么。
接下来进入另一个Control模型,这时候我们使用canny贴图,选择canny模型,点击生成:

虽然多余的手臂还在,但很明显正在消失,能看到明显的效果改善,意味着我们的贴图是有影响的。
我们再用随机种子测试,将批处理量改为30或者40,因为我们现在处于概念搜索阶段,从生产结果看哪一个最令人满意。
4.2、选择女主角的设计

生成完成了,我们得到了这个30张图片的网格,我们来仔细查看:

第二张看起来不错,还有几张图片看起来也可以,我们选择第二张进一步设计。
先将图片保存,然后进入Photoshop修改,因为我觉得有一些比例问题需要解决。
4.3、整理图片

这里有两张图片,都是同一个种子生成,但两张都有我喜欢的一些元素,所以增加一个黑色通道,然后对细节修改:

现在看起来效果好了一些,不过脖子有些长,选定头部,复制选区然后layer via copy,将其位置往下放。
鞋子看起来也有问题,腿部也有些问题,我们接着修图。
4.4、局部重绘面部
回到webui,在做图片之前,我们需要稍微放大一些,这里我们选择放大两倍,这里得到了放大版本的图片:

另外,我们还需要使用之前的指令,所以回到images标签,找到我们选择的图片,发送到图生图,将种子设为随机(-1)。然后,在extras标签将放大后的图片发送到局部重绘(send
to inpaint)。
我们在inpaint标签对面部重绘,降噪设置为0.25,将指令改为"beautiful female face",点击生成,看效果如何:

由于分辨率较低,我们很难看出是否有改善,所以我们需要放到外部浏览器选择满意的一个。
4.5、渲染新手掌
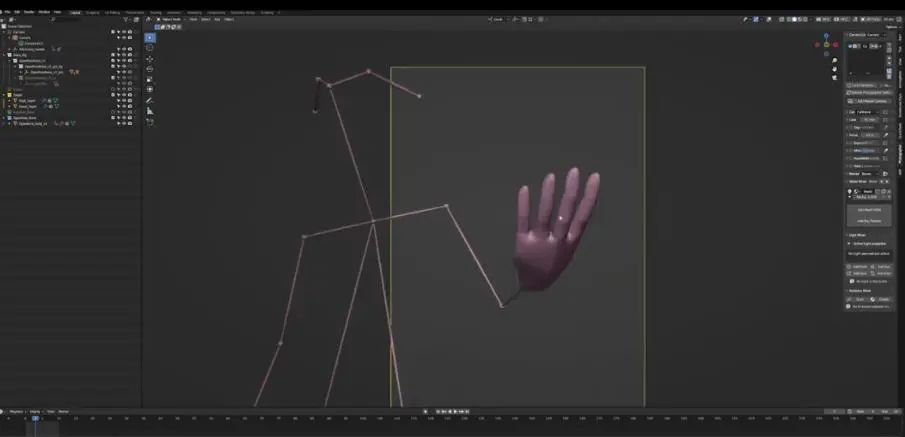
再次回到Blender,之所以这么做是因为之前的深度图无法捕捉手掌细节。所以我们放大,离近看手掌,重新渲染,这时候手掌在框架内,身体几乎在框架外。

想要渲染手掌,首先隐藏骨骼(关掉OpenPose bones),渲染图片,这就是手掌的深度图,保存图片。
我们需要用到第二个摄像机,所以全选并复制左侧的摄像机文件夹,粘贴,然后它会作为摄像机001存在,我们关掉原来的摄像机,这时候就回到了新摄像机角度,通过移动骨骼,我们可以将左手放到摄像机前,这时候它就会被放大。
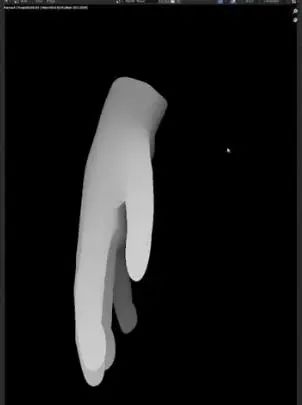
同样的步骤渲染,保存深度图。
4.6、生成新手掌

我生成了一批手掌,可以看到我们有了很多可用的手掌,选择其中一个,或者一直生成到右满意的为止。
随后我们生成另一只手:

接下来进入Photoshop进行调整。
4.7、Photobashing新手掌
将文生图得到的手掌拖到Photoshop里,这里需要强调的一点是,左下角的信息是72dpi,很明显这不是对的分辨率。如果你想要展示,比如打印,那么至少要达到300dpi。
所以,新建文件夹,宽度设为3072,高度3840,300dpi。
然后,将生成的手掌复制到新文件,这时候就得到了200dpi的结果,另一只手也如此操作。
我们将它放到最初的角色设计文档里。
你们可能会问,如果我不是美术师,或者不了解这些美术知识怎么办?如何知道怎么放这些手掌才看起来自然呢?
还记得我们之前生成了三个通道,将深度图放到角色图层之上,你就可以看到手和脚的位置应该在什么地方。

不过,在将手掌放到角色设计图片之前,我们还需要修复一些细节,但也并不是那么多。因为在正常情况下,手掌的可见度并不是那么高,除非我们放大看,所以并不需要那么精准,但依然需要把它做的好看。
选中手掌并复制图层,实际上我还会在新建一个图层,然后选择smart object,这样你可以把它缩小,再放大之后细节仍然不会丢失。
复制到角色设计图片,调整手掌颜色之前,我们要将其缩小并放到合适的位置。因为有些东西是重复的,毕竟原来角色已经有一双手,你可以将不需要的区域选中擦掉,随后改变手掌颜色。
4.8、匹配皮肤基调
新生成的右手有些泛黄,所以我们需要做一些处理,在增加或改变颜色之前,我们先将手掌进行修复。现在的界面是智能对象图层,如果你想将智能对象做成与其他图层一样的效果,只需要新建一个图层,右键选择"Layer
via copy"确保智能对象图层在其之上,然后Ctrl+E向下合并图层,这样你就得到了一个重新调整后的图层。
接下来,复制手掌和手腕之间的部分,将它向下移动,因为我们需要让手掌覆盖更多地方,看起来像是一个手套。所以,下一步就是让手掌与右胳膊颜色一致。
我们关掉手掌图层,新建图层,将所有东西合并起来,这就是基础图层,这里我只选择右胳膊,右键选择"Layer via copy",我们将其命名为copied
arm 02,启用手掌,然后复制手掌备用。
因为接下来我们要做的是点击图片,调整,然后选择match
color,如果使用的是Photoshop较新的版本,确保颜色模式使用的是8bit模式,否则这个功能可能会出错。
在source项选择当前文档,匹配对象选择手掌,可以看到手掌颜色与胳膊很接近。
有些地方的颜色仍然没有达到一致,所以我们需要手动调整,新建一个调整图层,关掉所有手掌图层,选择颜色比较接近的一条腿,右键选择"Layer via
copy",命名为copied leg,然后开启手掌图层。

找到左手掌,复制,创建新图层,然后Ctrl + E向下合并图层,然后以之前的步骤进行颜色匹配。

这就是我们修复的图片,左手还需要局部重绘,希望能够得到更好的效果。
4.9、局部重绘手掌
首先需要一个局部重绘模型,这里我们A模型选择了inpainting
checkpoint(后缀为ckpt),B模型选择了fantasy_style_v2_0,然后C模型选择了v1-5-pruned.ckpt。自定义名字里,我们可以将其命名为fantasy_style_v2-inpainting。
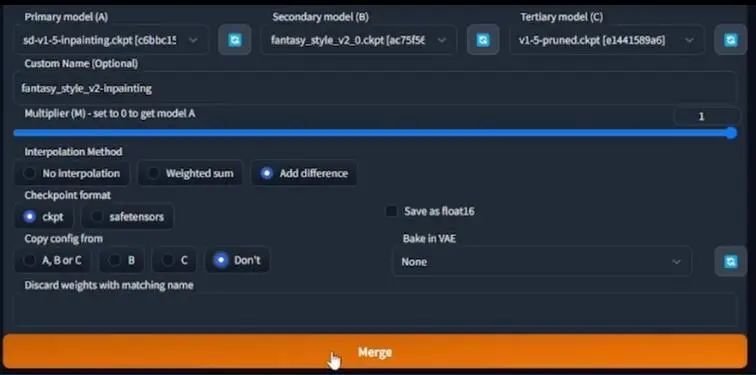
其余设置如上图,随后点击底部的merge,局部重绘模型就做好了。
接下来回到图生图界面,将模型改为刚刚建好的模型,等待加载完成。先重绘右手,将去噪值降低到0.15,局部重绘选择"仅遮罩(only
masked)",点击生成:

可以看到手掌结果好了很多,或许我们还可以将去噪值再调低一些,然后以同样的操作对左手掌进行局部重绘。
**第五部分:最后润色**
* 15.1、构图元素
经过了几个小时的局部重绘和Photoshop修复之后,我做到了现在的效果:
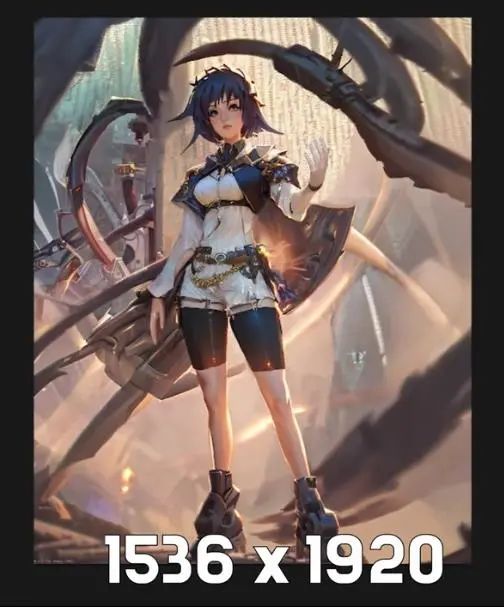
尺寸放大到了1536×1920,比原图片大了一倍,主要原因是我不希望局部重绘的分辨率过高,因为那样做需要更久的时间,而且我们将其缩小也能让图片看起来很不错。
我还希望增加一些东西,也就是一些构图元素,并且对脸部进行升级。

你们可能会问,什么是构图元素?可以看图片中画出来部分,我们希望在这些地方增加一些东西,让整个图片的焦点聚焦在角色上。
我实际上在右下角只是复制并粘贴了两个图层,然后新建一个合并图层,用污点修复工具进行修复,因为我希望Stable
Diffusion知道如何对这里的部分进行混合。

下一步,我们将它导入到webui,我们选择局部重绘,选择新建图层的那部分,希望能将它变成机械风格的元素,需要补充的是,我的指令写加入了"mechanical
pipes,factory environment,a pile of rocks"之类的词汇。点击生成:

这就是我从webui得到的图片,虽然有个奇怪的机器人,但与之前相比已经比较令人满意,另外背景部分与鞋子的重叠有些多,我们进入Photoshop修复(使用污点修复工具,新建图层将你不喜欢的东西覆盖掉)。

这个效果对我而言还是不错的,不过左侧我们还需要一些构图元素,所以我们重复以上的局部重绘步骤:

可以看到,Stable Diffusion帮我绘制了看起来效果非常酷的管道。
5.2、升级面部
我对这个结果还是比较满意的,但这里不会讲特别多的细节,因为这是一个最终角色设计和世界构建部分,而不是做最终的插画。

我们将图片修改为黑白模式,只是为了看色值是否连贯,当然,结果看起来还是可以的,离角色近的一切都应该更暗,远的更亮。
就像之前提到的,我们需要将基础图片的像素提高,这样才能在面部局部重绘得到更好的效果。由于之前已经放大了两倍,这里我们选择将其再放大两倍。
将得到的结果发送到局部重绘,可以看到分辨率达到了3072×3840,不过我们只是对面部重回,所以将其修改为768×768,选择"仅遮罩",然后选择面部,点击生成:

看起来是有些效果,但去噪值可能有点高,我们将其调回0.2:
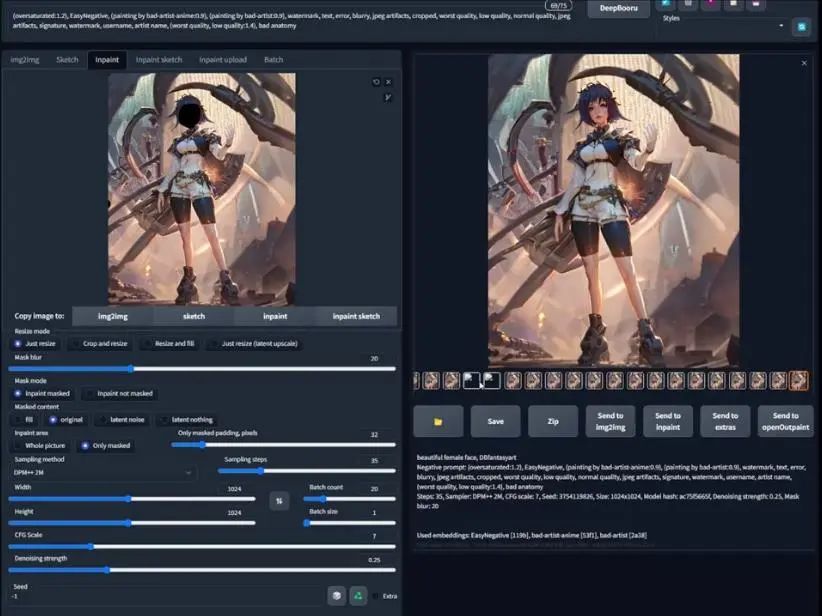
这里生成了20个结果,我们挑一个满意的进入Photoshop修改。
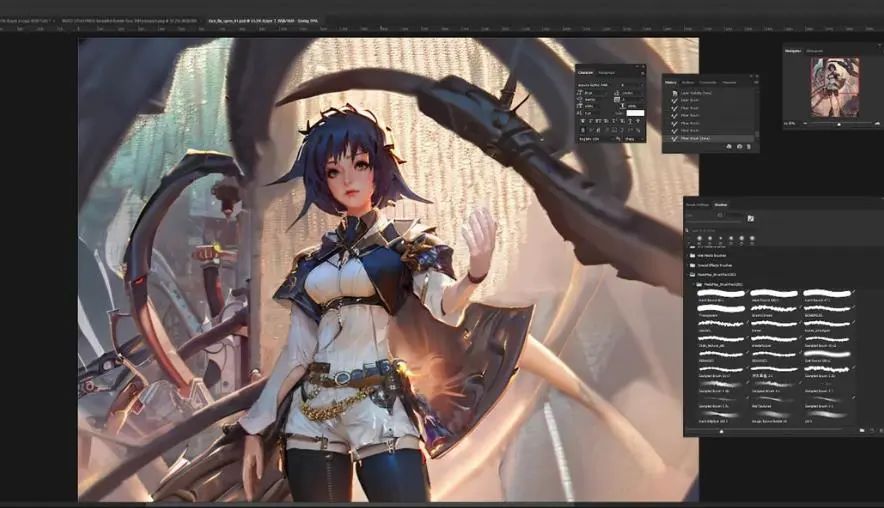
这就是我们最终修改前的图片,可以看到面部细节已经差不多,当然,这只是个角色模板,不用对细节太过于苛求。
5.3、色值调整
这里有一些细节我觉得还需要调整,比如右手掌与其他肤色看起来还不是那么协调,另外,整个图片的肤色变化也比较明显,比如腿部偏重、面部偏红。
你可以选择最为中和的颜色(左手),新建图层,选择颜色,然后用油漆桶工具对各种图层填充,随后降低不透明度,直到效果看起来令人满意:
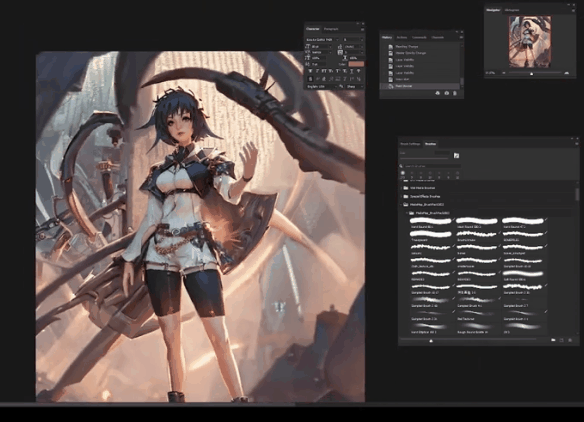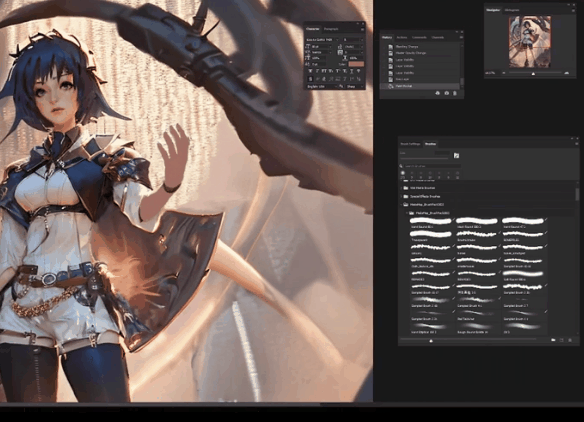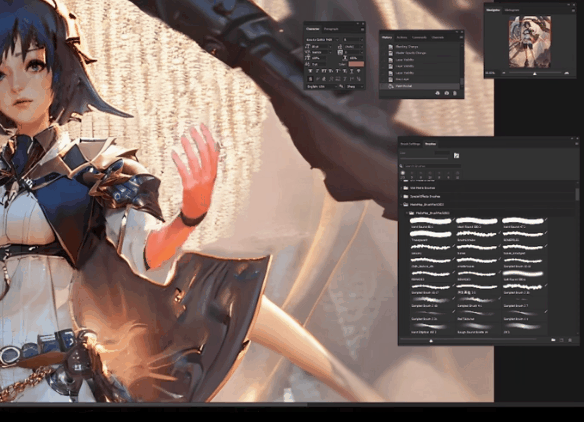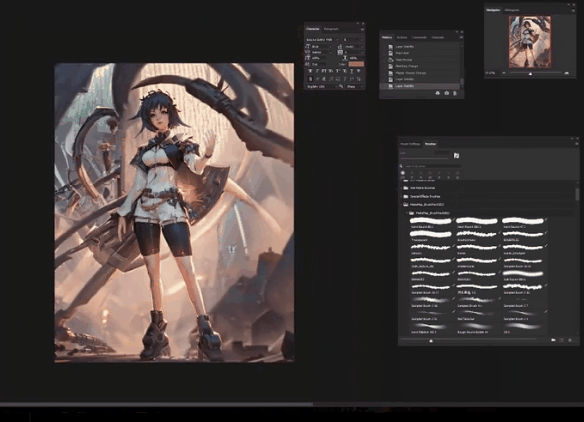
对于光照,我的选择是在其之上新建一个全局图层,然后进行色值调整。我们将图片色调暗,来看哪些地方是需要改动的:

对于希望调整的部分,我觉得背景部分应该更亮一些,所以我们进行调整:

然后将图片色值调亮,可以看到有些近景管道颜色太亮,因此我们再次调整:

有一点不太满意的是,当我们将色值调亮的时候,角色不应该这么模糊,因为她离摄像机更近,所以重复上面的操作:

可以看到,我们的图片有了更多的层次感。
5.4、灯光通道(Lighting Pass)
经过了大量繁琐的细节调整之后,现在我们可以开始做一些艺术选择。我们开始做最终的灯光通道,首先上面新建一个全局雾霾层(global haze
layer)可以看到整体效果好了一些:

它看起来将图片的光照统一,但有些强烈,所以我们调低一些。
可以看到更有氛围感,我的第一步始终都是将图片灯光统一,接下来增加对比度。
在右下角图层新建曲线调整图层,调整将其作为阴影,可以看到阴影总是在左侧,意味着灯光来自右后方,点击Ctrl+I进行反转,在黑色遮罩进行调整,将左侧部位调暗,以突出光照效果。
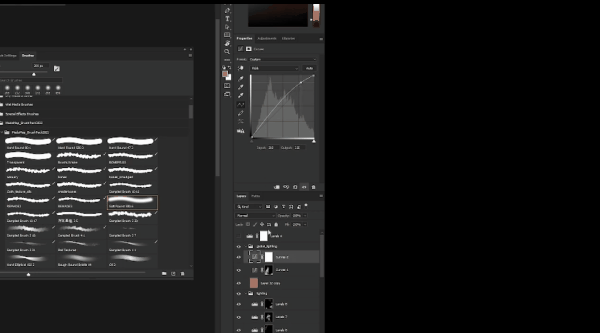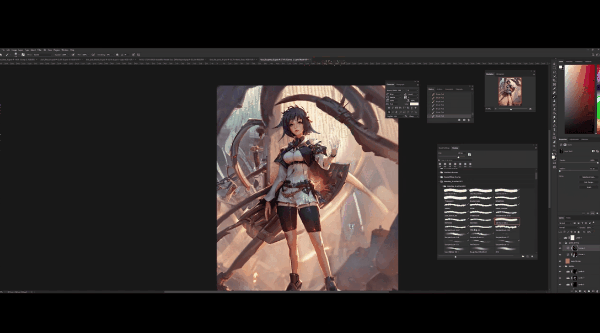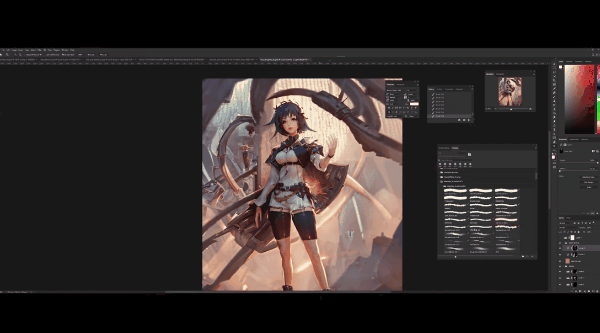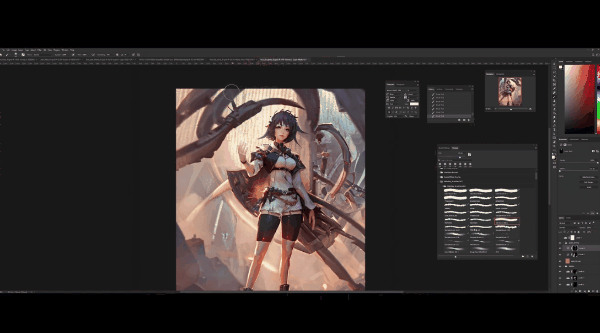
下一步是高光,同样,新建一个曲线调整图层,将右边脸和右手的亮度调高。
接下来我们需要一个辉光图层(bloom layer),也就是围绕角色或物体结构的照明。新建图层,滤镜-模糊,高斯模糊数值选择64。
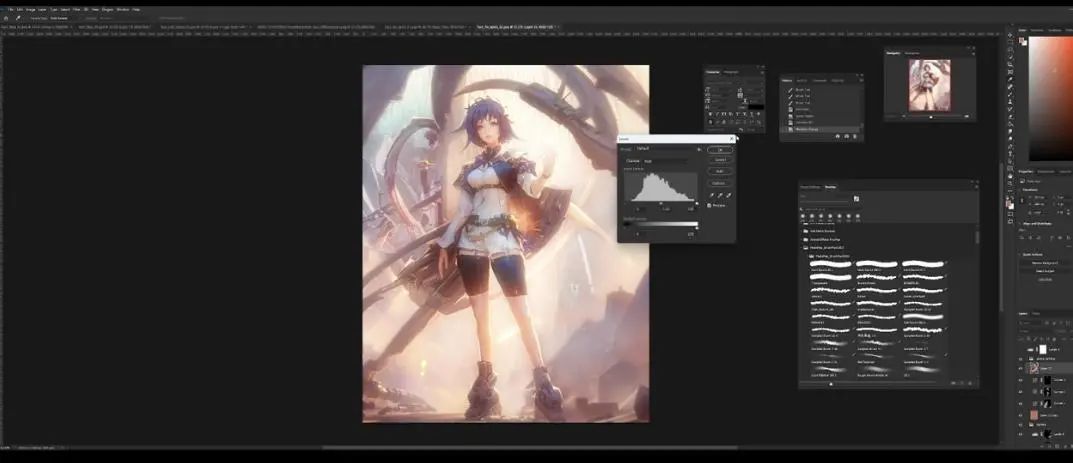
Ctrl+N调出曲线进行调整,创建黑色遮罩调整细节,可以看到这就是辉光,非常有趣。
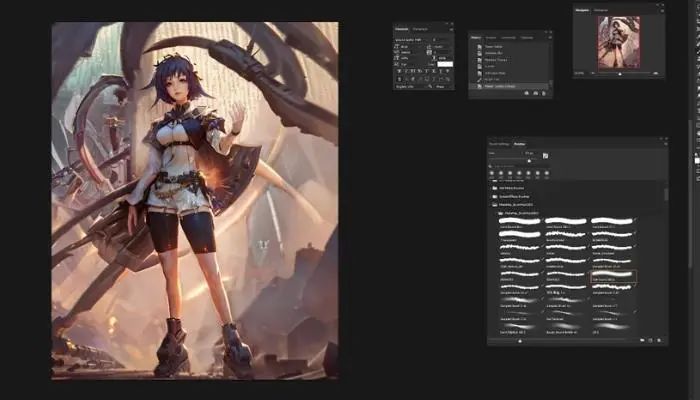
最后是Camera raw滤镜图层,也是我完成图片通常做的最后一步,新建图层,Ctrl+shift+E,滤镜,选择camera
raw,shift+Ctrl+A

这里的曲线告诉我们,图片实际上已经比较平衡,我们不太需要做很多的调整,当然,你可以对各项数值进行调整,直到满意为止,这时候保存设置。
之所以在最后喜欢使用camera raw,是因为它不会撒谎。
最后是god rays,如果看现在的图片,可以发现右手与整个图片有些不协调。你可以新建图层,选择手旁边的环境颜色,然后画出光束:

这里直接将该软件分享出来给大家吧~
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

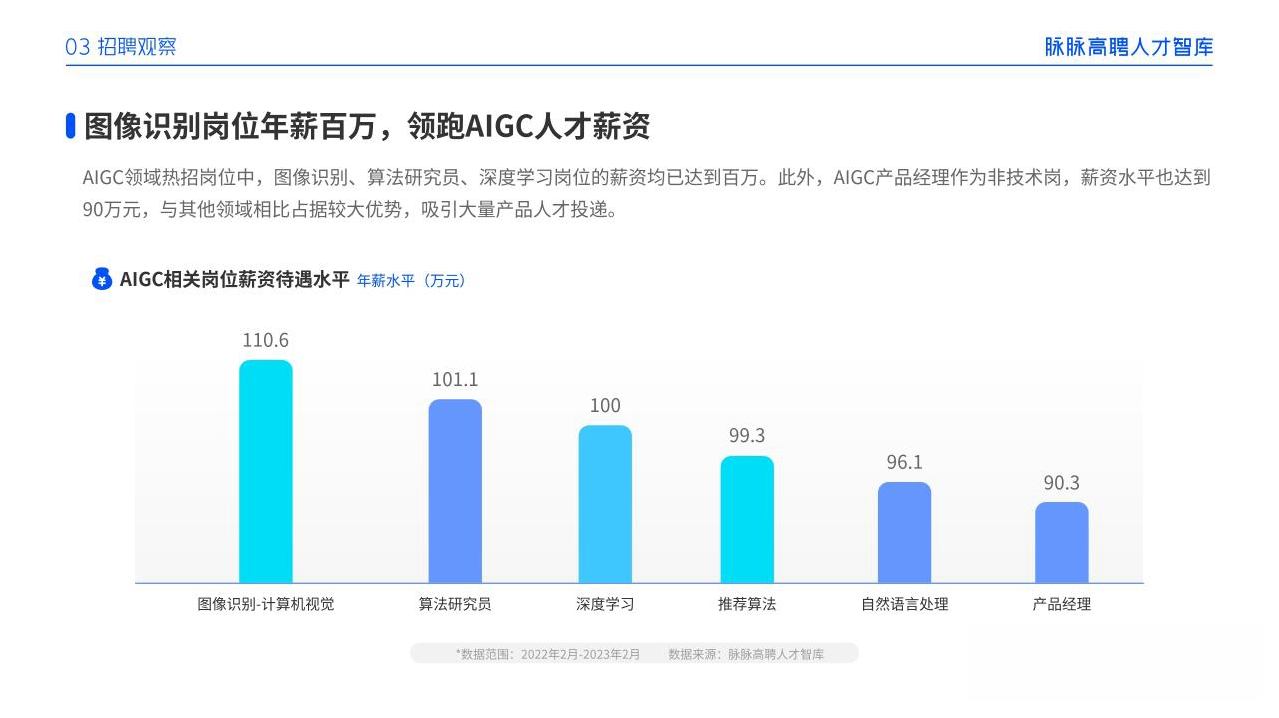
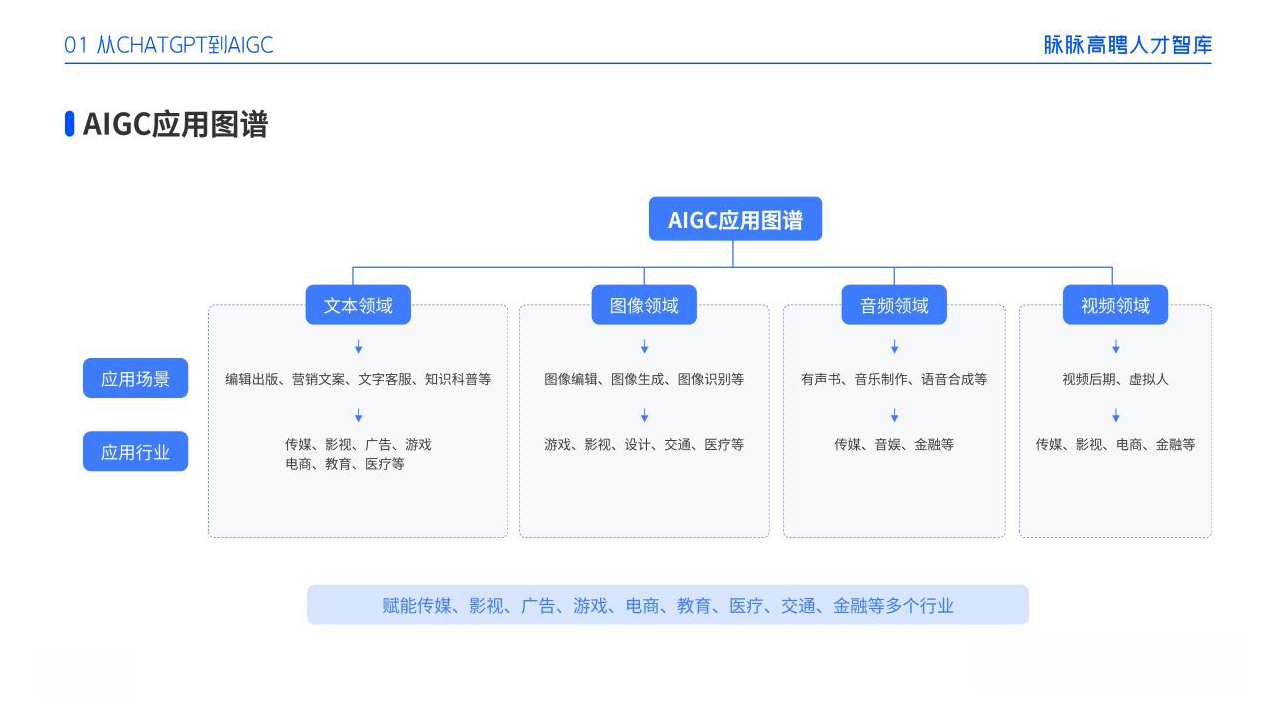
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
