概述
摘要: 容器的三大基石包括: namespaces, docker,rootfs。其中Namespace实现进程隔离。Cgroups用于限制进程资源,如CPU、内存、磁盘空间、网络流量等。rootfs则是容器的基础文件系统。通过这些技术,Docker实现了轻量级的容器隔离。本文将介绍cgroup的基础知识,并通过实验加深对cgroup的认知。
正文
cgroup
why - 为何需要cgroup
- 如何防止服务器中的某一个进行对资源的限制,避免程序bug导致整个系统故障?比如开发了一个监控agent程序,需要对监控程序做资源限制,如何实现?
- docker中如何实现各个pod资源使用的限制?
这类常见的场景就需要cgroup来实现。
what - 什么是cgroup
在 Linux 系统中,Control Group(简称 cgroup)是一种用于对进程或进程组提供资源限制、优先级调度以及进程隔离的机制。Cgroup 通过将进程组织成层次结构并为每个层次结构分配一组特定的资源限制参数来实现这些功能。
使用 cgroup,您可以对进程或进程所在的组设置以下资源参数限制:
CPU使用率限制;
内存使用限制;
磁盘 I/O 限制;
网络带宽限制;
cgroup 是 Linux 内核的一部分,由内核开发人员于 2007 年引入。这一机制在容器技术的发展过程中发挥了重要作用,并被 Docker、Kubernetes 和 OpenStack 等开源项目广泛使用,以便启用容器化的应用程序管理和调度。
How - cgroup是如何实现的
CGroup 基本概念
在介绍 CGroup 原理前,先介绍一下 CGroup 几个相关的概念,因为要理解 CGroup 就必须要理解他们:
-
任务(task)。任务指的是系统的一个进程,如上面介绍的 tasks 文件中的进程; -
控制组(control group,缩写cgroup)。控制组就是受相同资源限制的一组进程。CGroup 中的资源控制都是以控制组为单位实现。一个进程可以加入到某个控制组,也从一个进程组迁移到另一个控制组。一个进程组的进程可以使用 CGroup 以控制组为单位分配的资源,同时受到 CGroup 以控制组为单位设定的限制; -
层级(hierarchy)。由于控制组是以目录形式存在的,所以控制组可以组织成层级的形式,即一棵控制组组成的树。控制组树上的子节点控制组是父节点控制组的孩子,继承父控制组的特定的属性; -
子系统(subsystem)。一个子系统就是一个资源控制器,比如 CPU子系统 就是控制 CPU 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制组都受到这个子系统的控制。包括的子系统有:-
cpu设置进程的CPU调度的策略,比如CPU时间片的分配 -
cpuacct统计/生成cgroup中的任务占用CPU资源报告 -
cpuset在多核机器上分配给任务(task)独立的CPU和内存节点(内存仅使用于NUMA架构) -
memory用于控制cgroup中进程的占用以及生成内存占用报告 -
hugetlb限制使用的内存页数量 -
blkio对块设备(比如硬盘)的IO进行访问限制 -
devices控制cgroup中对设备的访问 -
freezer挂起(suspend) / 恢复 (resume)cgroup中的进程 -
net_cls使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器 tc (traffic controller) 可以识别来自特定 cgroup 的包并做限流或监控 -
net_prio设置cgroup中进程产生的网络流量的优先级 -
pids限制任务的数量 -
ns可以使不同cgroups下面的进程使用不同的namespace.每个
subsystem会关联到定义的cgroup上,并对这个cgoup中的进程做相应的限制和控制.
-
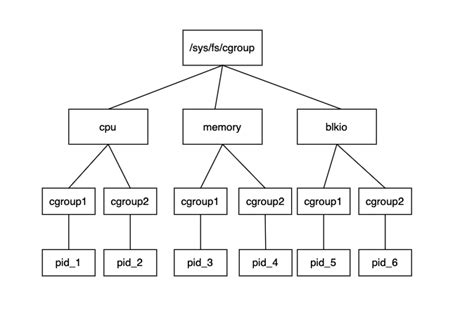
(图片来源于网络,如有侵权请联系作者)
注意点:
- \[\] root cgroup 对应的路径可以根据不同的 Linux 发行版和配置而有所不同。在大多数 Linux 发行版中,root cgroup 的路径通常是 /sys/fs/cgroup 或 /sys/fs/cgroup/systemd
- 一个进程
fork出子进程时,该子进程默认自动成为父进程所在的cgroup的成员,也可以根据情况将其移动到到不同的cgroup中.
由于常用的子系统有cpu,memory,所以我们详细了解下:
cpu子系统
cpu子系统限制对CPU的访问,每个参数独立存在于cgroups虚拟文件系统的伪文件中,参数解释如下:
-
cpu.shares: cgroup对时间的分配。比如cgroup A设置的是1,cgroup B设置的是2,那么B中的任务获取cpu的时间,是A中任务的2倍。
-
cpu.cfs_period_us: 完全公平调度器的调整时间配额的周期。
-
cpu.cfs_quota_us: 完全公平调度器的周期当中可以占用的时间。
-
cpu.stat
统计值
- nr_periods 进入周期的次数
- nr_throttled 运行时间被调整的次数
- throttled_time 用于调整的时间
memory子系统
memory子系统主要涉及内存一些的限制和操作,主要有以下参数:
- memory.usage_in_bytes # 当前内存中的使用量
- memory.memsw.usage_in_bytes # 当前内存和交换空间中的使用量
- memory.limit_in_bytes # 设置or查看内存使用量的限制
- memory.memsw.limit_in_bytes # 设置or查看 内存加交换空间使用量
- memory.failcnt # 查看内存使用量被限制的次数
- memory.memsw.failcnt # - 查看内存和交换空间使用量被限制的次数
- memory.max_usage_in_bytes # 查看内存最大使用量
- memory.memsw.max_usage_in_bytes # 查看最大内存和交换空间使用量
- memory.soft_limit_in_bytes # 设置or查看内存的soft limit
- memory.stat # 统计信息
- memory.use_hierarchy # 设置or查看层级统计的功能
- memory.force_empty # 触发强制page回收
- memory.pressure_level # 设置内存压力通知
- memory.swappiness # 设置or查看vmscan swappiness 参数
- memory.move_charge_at_immigrate # 设置or查看 controls of moving charges?
- memory.oom_control # 设置or查看内存超限控制信息(OOM killer).其中的oom_kill_disable,默认值为0表示使用OOM_killer机制。
- memory.numa_stat # 每个numa节点的内存使用数量
- memory.kmem.limit_in_bytes # 设置or查看 内核内存限制的硬限
- memory.kmem.usage_in_bytes # 读取当前内核内存的分配
- memory.kmem.failcnt # 读取当前内核内存分配受限的次数
- memory.kmem.max_usage_in_bytes # 读取最大内核内存使用量
- memory.kmem.tcp.limit_in_bytes # 设置tcp 缓存内存的hard limit
- memory.kmem.tcp.usage_in_bytes # 读取tcp 缓存内存的使用量
- memory.kmem.tcp.failcnt # tcp 缓存内存分配的受限次数
- memory.kmem.tcp.max_usage_in_bytes # tcp 缓存内存的最大使用量
cgroups文件系统
Linux通过文件的方式,将cgroups的功能和配置暴露给用户,这得益于Linux的虚拟文件系统(VFS)。VFS将具体文件系统的细节隐藏起来,给用户态提供一个统一的文件系统API接口,cgroups和VFS之间的链接部分,称之为cgroups文件系统。
比如查看已经挂载的子系统

cgroup的实战
使用cgroup实现对内存的限制
为了对上面所述的概念更深入的理解,下面通过一个进程的内存限制的操作来加深认识
实践的步骤:
-
创建hierarchy
-
在hierarchy中创建一个cgroup
-
在cgroup下的memory子系统实现对进程的内存限制
查看linux是否启用cgroup
cat /boot/config-4.15.0-101-generic |grep -i cgroup
CONFIG_CGROUPS=y
CONFIG_BLK_CGROUP=y
# CONFIG_DEBUG_BLK_CGROUP is not set
CONFIG_CGROUP_WRITEBACK=y
CONFIG_CGROUP_SCHED=y
CONFIG_CGROUP_PIDS=y
CONFIG_CGROUP_RDMA=y
CONFIG_CGROUP_FREEZER=y
CONFIG_CGROUP_HUGETLB=y
CONFIG_CGROUP_DEVICE=y
CONFIG_CGROUP_CPUACCT=y
CONFIG_CGROUP_PERF=y
CONFIG_CGROUP_BPF=y
# CONFIG_CGROUP_DEBUG is not set
CONFIG_SOCK_CGROUP_DATA=y
CONFIG_NETFILTER_XT_MATCH_CGROUP=m
CONFIG_NET_CLS_CGROUP=m
CONFIG_CGROUP_NET_PRIO=y
CONFIG_CGROUP_NET_CLASSID=y第一行CGROUP项为"y", 表示已经打开linux cgroups功能。
创建hierarchy: cgrouptest

可以看到名为cgrouptest的hierarchy下,默认创建一些cgroup相关的目录。这里cgrouptest/就是一个root cgroup

| 字段名 | 含义 |
|---|---|
cgroup.clone_children |
**默认值是0,子系统cpuset会读取这个配置文件,**如果这个被值改为 1,子cgroup才会继承父cgroup的cpuset的配置 |
cgroup.procs |
是树中当前节点cgroup中的进程组ID。因为现在的位置是根节点,所以这个文件中的值,是现在系统中所有进程组的ID (查看目前全部进程PID `ps -ef |
cgroup.sane.behavior |
控制cgroup.procs是否能加入多个进程ID。默认值0,允许。值1时,只有一个进程或线程可以写入 cgroup.procs 。 |
notify_on_release |
和release_agent 会一起使用,notify_on_release 标志当这个cgroup最后一个进程退出的时候,是否执行了release_agent |
release_agent |
则是一个路径,通常用作进程退出后自动清理不再使用的cgroup |
task |
标识该cgroup下面进程ID,如果把一个进程ID写到task文件中,便会把相应的进程加入到这个cgroup中 |
创建在hierarchy下创建控制组mycgroup

mycgroup 继承了父cgroup即cgrouptest的属性
将memory子系统挂到mycgroup下面去

memory子系统已经挂载成功

在memory子系统下创建一个目录mymemory-limit, 之后先将需要限制的内存大小写入*memory.limit_in_bytes*,再将需要限制的进程号写入tasks,
为了做对比,先启动一个进程memtest,观察内存大于17G。

开始限制 cgroup 内进程的内存使用量
我们将当前终端登录的进程ID写入tasks,由于cgroup对子进程的限制会继承起父进程。

从htop可以看出,stress申请2048M内存,但系统只分配了物理内存RES为1000M(接近1024M),但虚拟内存VIRT使用了2055M内存。所以肯定是使用了swap空间。这个我们可以通过查看进程status能够确认: cat /proc/589120/status,这里589120对应的是stress的进程id.

设想一下,如果我们关闭swap,这时的现象是怎么样呢?如果stress申请2048M内存,但cgroup限制了只能分配1024M物理内存,而又因为swap关闭,获取不到swap空。进程是不是会被oom_killer掉呢?
我们来验证一下。
新开一个终端,同理把当前进程ID写入task后,在关闭swap后再stress操作。这次stress进程的ID号是593069

再用dmest -T观察内核信息,发现stress进程是因为/memory-limt做了内存限制,而内存申请有达到申请的阈值,所以被oom_killer机制杀掉

其他常用命令:
查看当前子系统已使用内存和总限制的内存

使用cgroup实现对cpu的限制
本次我们在系统默认的cpu子系统 /sys/fs/cgroup/cpu下创建目录实现对cpu的限制.
在/sys/fs/cgroup/cpu创建cpu-limit目录,将当前终端进程号写入tasks,再使用cpu.cfs_period_us, cpu.cfs_quota_us实现对cpu使用率的限制

启动一个无限循环,模拟对cpu的压测

开启另一窗口使用top命令观察cpu使用情况

至此,我们通过cgroup完成了对进程内存、cpu的限制目的。