在过往,不管使用 SD 还是 MJ,生成一张图片起码要等上10秒。
而现在,有了 LCM 技术的加持,已经能做到秒出图,甚至是实时出图。
LCM(潜空间一致性模型) 是由 清华大学信息科学技术研究院 研发的大模型,它最大的特点就是生成图片速度超级快,能在2-4步生成质量不错的图片。
安装部署
LoRA下载
Latent Consistency Model (LCM) LoRA: SDXL 下载链接:
https://huggingface.co/latent-consistency/lcm-lora-sdxl/tree/main
Latent Consistency Model (LCM) LoRA: SDv1-5 下载链接:
https://huggingface.co/latent-consistency/lcm-lora-sdv1-5/tree/main
以上两个模型下载后,放置位置:SD安装目录\models\Lora\lcm
模型下载
目前唯一支持 SD webui 的LCM模型:LCM_Dreamshaper_v7
下载链接:https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7/tree/main
模型下载后,放置在:SD安装目录\models\Stable-diffusion
sd-webui-lcm 插件
PS:LCM_Dreamshaper_v7 模型不能直接使用,需要搭配 sd-webui-lcm插件 使用。
下载链接:https://github.com/0xbitches/sd-webui-lcm
插件下载解压后,放置在:SD安装目录\extensions
修改代码
在 SD安装目录\modules 中找到 sd_samplers_extra.py 与 sd_samplers_kdiffusion.py 两个文件。

在修改之前,切记要把这两个文件进行复制备份,以免改坏了还能还原回来。
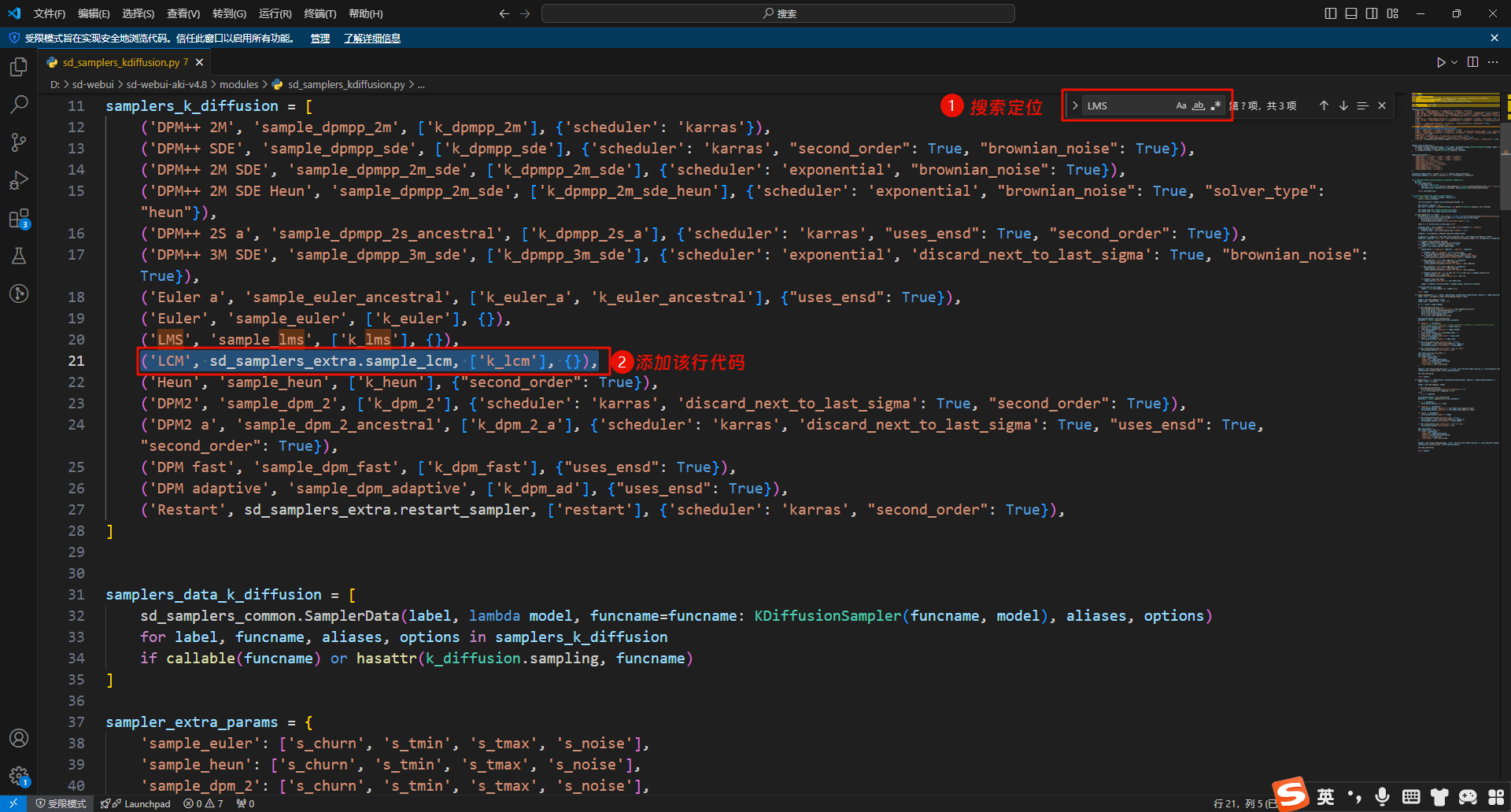
sd_samplers_kdiffusion.py 修改:
在对应位置添加代码后保存:('LCM', sd_samplers_extra.sample_lcm, ['k_lcm'], {}),
sd_samplers_extra.py 修改:
在如下位置添加代码后保存:
python
@torch.no_grad()
def sample_lcm(model, x, sigmas, extra_args=None, callback=None, disable=None, noise_sampler=None):
extra_args = {} if extra_args is None else extra_args
noise_sampler = k_diffusion.sampling.default_noise_sampler(x) if noise_sampler is None else noise_sampler
s_in = x.new_ones([x.shape[0]])
for i in tqdm.auto.trange(len(sigmas) - 1, disable=disable):
denoised = model(x, sigmas[i] * s_in, **extra_args)
if callback is not None:
callback({"x": x, "i": i, "sigma": sigmas[i], "sigma_hat": sigmas[i], "denoised": denoised})
x = denoised
if sigmas[i+1] > 0:
x += sigmas[i+1] * noise_sampler(sigmas[i], sigmas[i+1])
return x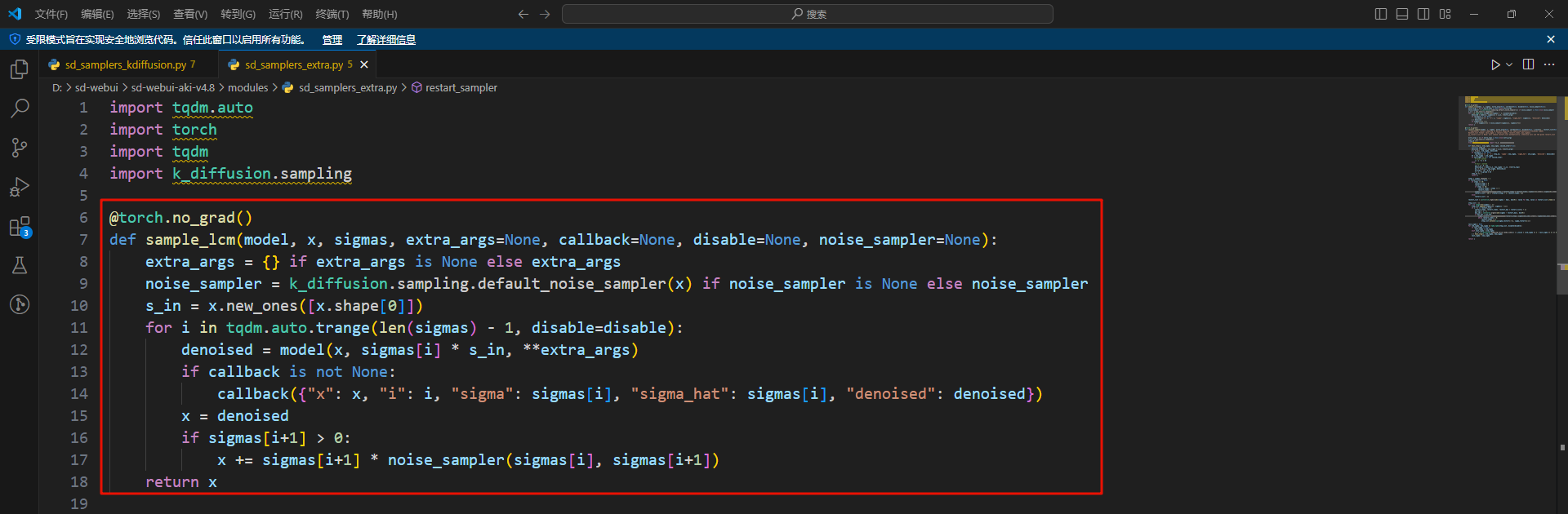
LCM 速度测试
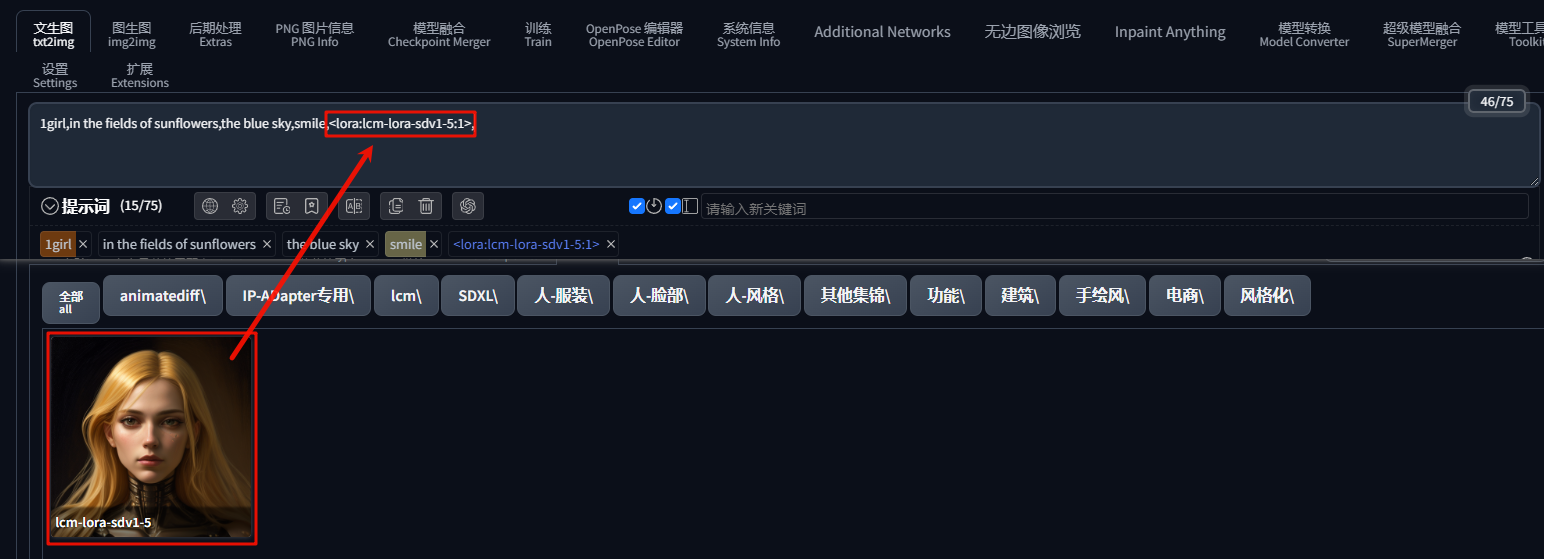
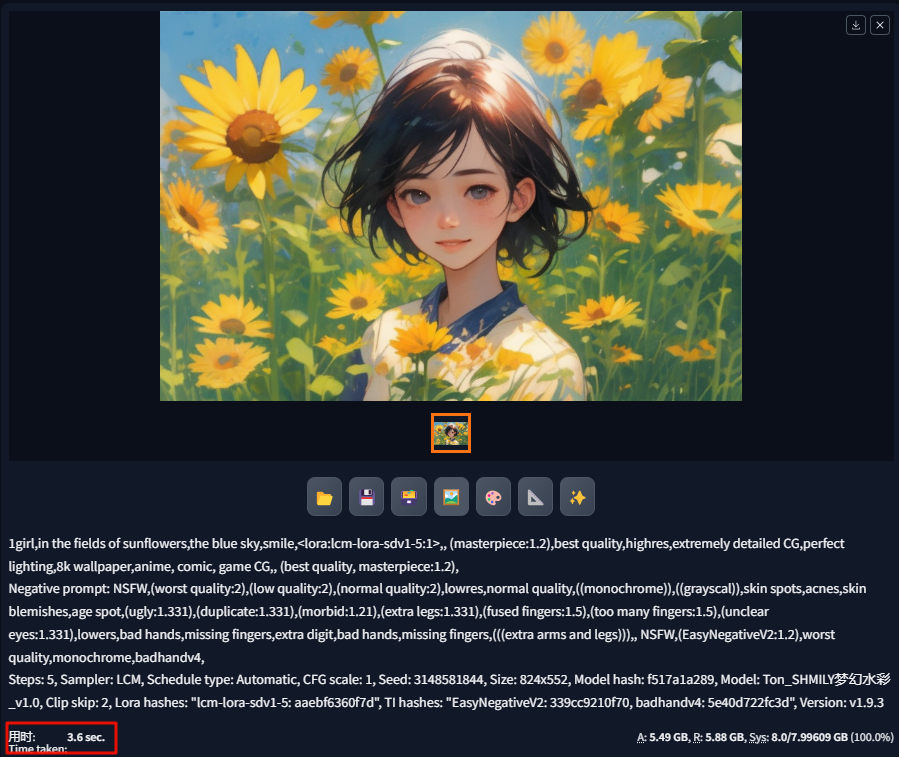
输入一段提示词,把 LoRA 添加进来:
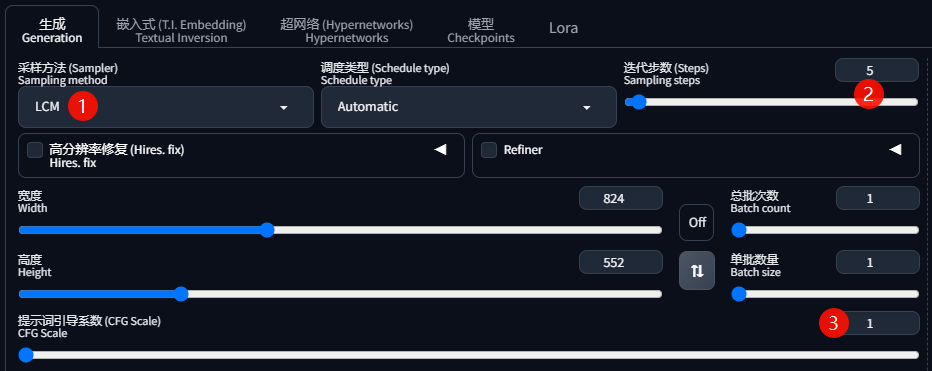
按照下图修改配置参数:
用时 3.6s 就能出图:
不同采样器出图效果对比:

再来看看,不同迭代步数的出图效果对比:



当 迭代步数 达到4步时,图片已达到基本可用的程度,
在 5步 之后,每增加 1步,画面会更加锐利,
增加到 第9步 之后,继续增加迭代步数,画质提升不太明显。
LCM 技术的加入,确实能提高出图效率,
尽管生成图片的质量不算太高,但在该技术的帮助下,我们完全可以使用较低的步数,快速的大批量出图,
然后再挑选满意的图片进行高清放大处理,有效避免了不断重复抽卡的烦恼。
今天先分享到这里~
开启实践: SD绘画 | 为你所做的学习过滤