828华为云征文|部署开源超轻量中文OCR项目 TrWebOCR
- 一、Flexus云服务器X实例介绍
- 二、Flexus云服务器X实例配置
-
- [2.1 重置密码](#2.1 重置密码)
- [2.2 服务器连接](#2.2 服务器连接)
- [2.3 安全组配置](#2.3 安全组配置)
- [2.4 Docker 环境搭建](#2.4 Docker 环境搭建)
- [三、Flexus云服务器X实例部署 TrWebOCR](#三、Flexus云服务器X实例部署 TrWebOCR)
-
- [3.1 TrWebOCR 介绍](#3.1 TrWebOCR 介绍)
- [3.2 TrWebOCR 部署](#3.2 TrWebOCR 部署)
- [3.3 TrWebOCR 使用](#3.3 TrWebOCR 使用)
- 四、总结
一、Flexus云服务器X实例介绍
云服务器是一种基于云计算技术的虚拟服务器,能够提供灵活的计算资源和存储空间。与传统的物理服务器相比,云服务器具有高可扩展性、灵活性和成本效益。用户可以根据需求随时调整资源配置,确保业务的高效运行。此外,云服务器还提供了强大的安全性和灾备能力,确保数据的安全和业务的连续性。无论是中小企业还是大型企业,云服务器都是一个理想的解决方案。
华为云下一代云服务器Flexus X实例焕新上线,新产品基于用户业务负载动态和内存峰值画像,动态推荐规格,减少算力浪费,提升资源利用率,首创大模型加持,智能全域调度;X-Turbo加速,常见应用性能最高可达业界同规格6倍,覆盖行业大多数通用工作负载场景。
Flexus X实例通过和其他服务组合,具备计算、镜像安装、网络、存储、安全等能力,您可根据业务需要灵活配置各资源。

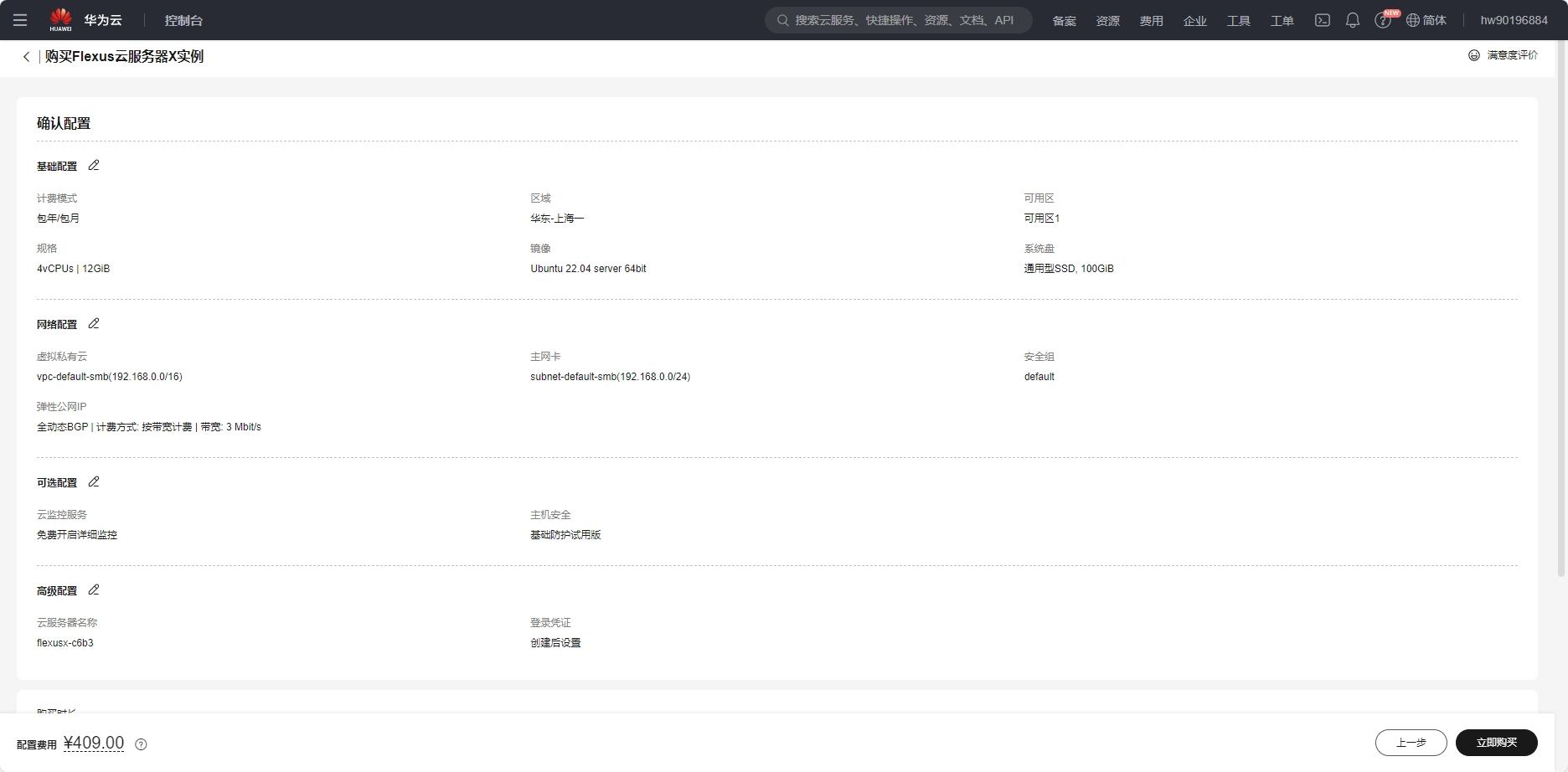
本次测评使用的规格是:4核12G-100G-3M规格的Flexus X实例基础模式
二、Flexus云服务器X实例配置
2.1 重置密码
购买服务器的时候可以提前设置用户名和密码,因为我这里跳过了,所以购买完成后需要重置密码,会短信或站内消息通过你的云服务器信息,重点是公网IP地址和用户名,首先打开你的服务器控制台,选择重置密码
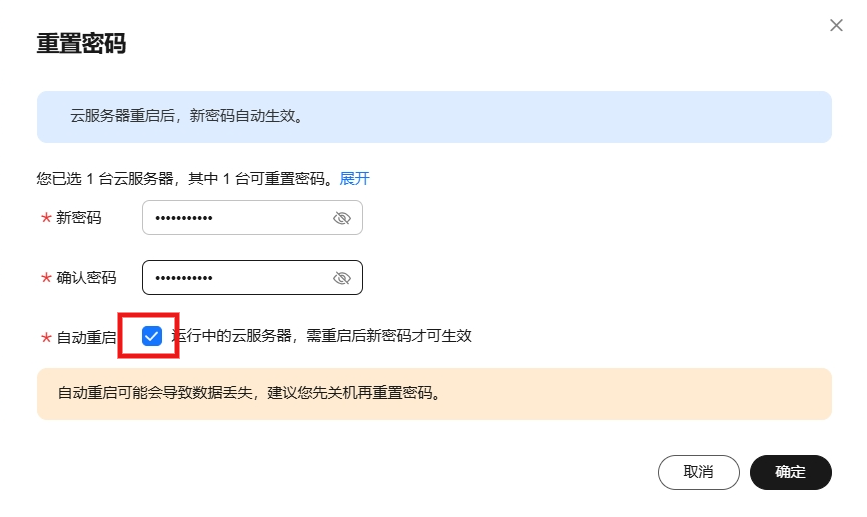
勾选自动重启,点击确定即可
2.2 服务器连接
华为云服务器提供了多种链接方式,如使用控制台提供的VNC方式登录、使用Linux/Mac OS系统主机登录Linux弹性云服务器(即ssh root@192.168.48.78命令)或者使用Putty、Xshell等工具登录Linux弹性云服务器。
我个人习惯使用 MobaXterm 这款软件,添加SSH连接,输出公网IP、用户名和端口(默认22),连接即可。
2.3 安全组配置
安全组是一个逻辑上的分组,为同一个VPC内的云服务器提供访问策略。用户可以在安全组中定义各种访问规则,当云服务器加入该安全组后,即受到这些访问规则的保护。
系统为每个网卡默认创建一个默认安全组,默认安全组的规则是对出方向上的数据报文全部放行,入方向访问受限。您可以使用默认安全组,也可以根据需要创建自定义的安全组。
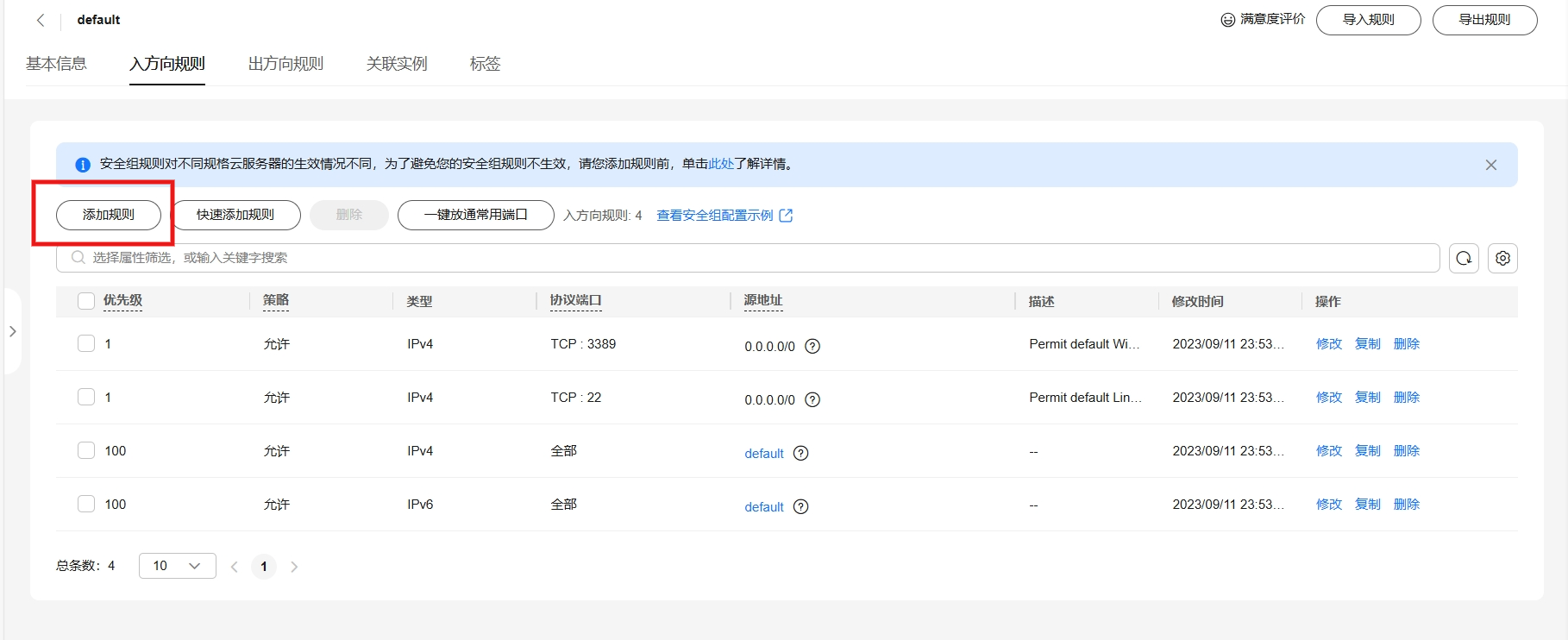
主要需要填写优先级(默认填1即可)、协议端口(协议一般为TCP或UDP,端口一般选择你项目需要暴露的端口即可),描述(选填,一般会填写此端口的用途以免忘记了),其他默认点击确定即可。安全组配置主要是暴露端口可以给外网访问。
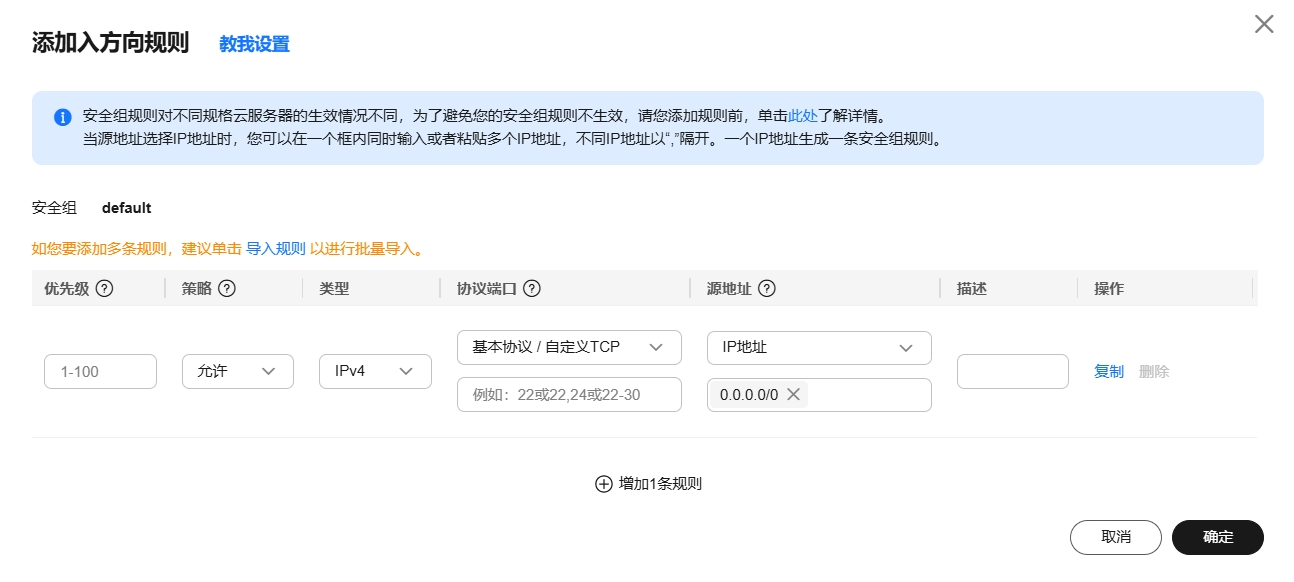
如果还不清楚可以参考文档:安全组配置示例
2.4 Docker 环境搭建
本次服务器环境是ubuntu系统镜像,需要自己安装docker环境
| 服务器类别 | 系统镜像 | 内网IP地址 | Docker版本 | 操作系统版本 |
|---|---|---|---|---|
| Flexus云服务器X实例 | Ubuntu | 192.168.0.168 | 27.2.0 | Ubuntu 22.04.4 LTS |
使用apt-get命令安装docker及其配置
bash
# 安装必要工具包
$ sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# 添加Docker GPG秘钥
$ sudo curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# 配置仓库源
$ sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
# 更新apt包索引
$ sudo apt-get update
# 安装docker
$ sudo apt-get install docker-ce docker-ce-cli containerd.io
# 添加docker镜像源
$ sudo vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://ustc-edu-cn.mirror.aliyuncs.com/",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn",
"https://ccr.ccs.tencentyun.com/",
"https://docker.m.daocloud.io/",
"https://dockerproxy.com",
]
}
# 重启
$ sudo systemctl daemon-reload
$ sudo systemctl restart docker测试docker安装是否成功
bash
root@flexusx-c6b3:~# docker -v
Docker version 27.2.0, build 3ab4256```检查docker服务状态
bash
root@flexusx-c6b3:~# systemctl status docker
* docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2024-08-30 15:53:45 CST; 17h ago
TriggeredBy: * docker.socket
Docs: https://docs.docker.com
Main PID: 24912 (dockerd)
Tasks: 13
Memory: 24.7M
CPU: 3.778s
CGroup: /system.slice/docker.service
`-24912 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock检查docker compose版本
bash
root@flexusx-c6b3:~# docker compose version
Docker Compose version v2.29.2三、Flexus云服务器X实例部署 TrWebOCR
3.1 TrWebOCR 介绍
TrWebOCR是一个基于Python构建的离线OCR系统。它提供一个易于使用的web界面,并且支持HTTP接口调用,使得其他项目的集成变得简单。该项目旨在实现高效和高识别率的中文文本识别,尤其是在面临复杂排版或文字倾斜等情况下,TrWebOCR也能进行准确的检测和识别。
值得关注的是,TrWebOCR在处理大规模并发请求时表现出色。尽管其底层检测模型本身不支持并发,但得益于使用了Tornado多进程架构,TrWebOCR可以根据服务器硬件配置灵活调整其并发处理能力。
-
高识别率与快速响应
TrWebOCR的核心竞争力在于其卓越的识别能力和响应速度。开发者对OCR模型进行了深度优化,使得识别率与一些大型商业OCR产品相比丝毫不逊色。用户无需强大的硬件配置即可体验快速、精准的中文识别。
-
易用的界面和接口
该项目不仅提供直观友好的Web界面,便于日常使用和调试,更支持通过API调用进行文件处理。用户可选择使用File上传文件进行识别,也可以通过Base64方式实现图片传输,极大地提高了项目的兼容性和灵活性。
-
完美的离线运行
为了用户的数据安全与隐私,TrWebOCR完全支持在本地服务器上离线运行。该功能消除了大多数网络环境对OCR使用的限制,从而使得在没有互联网连接的场合下同样可以进行有效的文字识别处理。
-
跨平台支持
TrWebOCR支持在多种Linux发行版本及Windows、MacOS上通过Docker容器进行运行,这为多样化的操作系统需求提供了强有力的技术支持。

在信息技术迅猛发展的今天,文字识别技术(Optical Character Recognition,简称OCR)在众多领域大放异彩。不论是档案管理、财务票据整理还是教育行业的试卷判阅,OCR技术都为人们的工作带来了极大的便利。然而,市面上的许多OCR方案往往都是在线服务,需要消耗大量的网络资源和时间,同时数据安全性也得不到充分保障,TrWebOCR项目为用户提供了一种强大的开源离线OCR解决方案。
3.2 TrWebOCR 部署
- 最低配置要求
- CPU: 1核
- 内存: 2G
- SWAP: 2G
- 创建 docker-compose.yml
yml
version: '3.5'
services:
trwebocr:
image: mmmz/trwebocr:latest
container_name: trwebocr
ports:
- "8089:8089"
restart: "no"
stdin_open: true
tty: true
- ports: 映射主机的 8089 端口到容器的 8089 端口
- stdin_open: 等同于 -i,保持标准输入打开
- tty: 等同于 -t,分配一个伪终端
如果将上述代码片段保存在名为 docker-compose.yml 的文件中,则只需从同一文件夹中运行 docker compose up -d 即可自动拉取 TrWebOCR 镜像,并创建并启动一个容器。 up 表示启动服务,-d 表示在后台执行。docker-compose down 命令用于停止和清理由 docker-compose up 启动的服务。
- 启动服务
进入项目目录,执行docker-compose up -d启动命令,会自动拉取容器并运行
从 Dockerhub 拉取 TrWebOCR 镜像,地址:https://hub.docker.com/r/mmmz/trwebocr
bash
root@flexusx-c6b3:~/trwebocr# docker-compose up -d
Creating network "trwebocr_default" with the default driver
Pulling trwebocr (mmmz/trwebocr:latest)...
latest: Pulling from mmmz/trwebocr
8559a31e96f4: Pull complete
62e60f3ef11e: Pull complete
002bcbc97d49: Pull complete
ba21c0b7837a: Pull complete
b3463869e7af: Pull complete
d8d420c09900: Pull complete
3b6ac3f09dee: Pull complete
Digest: sha256:43906e1116cd418706df8216e359068545e733338c172d59abc0009201626541
Status: Downloaded newer image for mmmz/trwebocr:latest
Creating trwebocr ...
Creating trwebocr ... done- 配置安全组
在Flexus云服务器X实例的安全组管理页面,添加入方向规则,接下来我们启动服务需要监听8089端口,所以添加安全组为TCP:8089协议端口。

- 检查容器状态
检查 TrWebOCR 容器状态,确保容器正常启动
bash
root@flexusx-c6b3:~/trwebocr# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9aee4d7965f9 mmmz/trwebocr:latest "supervisord -c /TrW..." About a minute ago Up 33 seconds 0.0.0.0:8089->8089/tcp, :::8089->8089/tcp trwebocr- 访问地址
- 访问结果

若出现此页面,则部署 trwebocr server 成功。
3.3 TrWebOCR 使用
界面比较简单,但是功能还是很强大的,左侧是上传需要识别的图片的地方,支持点击、拖动或着粘贴图片的方式上传图片,一个识别按钮,还有个压缩图片开关以及压缩图片尺寸的配置

点击上传图片文件方式,这张图片的文字比较多,第一次开启压缩后识别到的文字比较少,于是关闭压缩图片再次识别(这个网页不支持连续识别,需要再次上传同样的图片才会再次启动识别功能),这个文字基本都识别到了,但是有缺点,就是会把图片logo也识别出文字或字母

使用拖动文件方式上传,识别效果类似,会有较多无用的字符,中文识别精度很高,没有出现错别字,同样的关闭压缩图片的精度会高很多,所以图片的分辨率尺寸很影响识别的效率和准确率

使用粘贴图片的方式上传,这应该是平常最主要的上传方式了,因为比较方便,而且是需要OCR识别时最常见的场景了。这次截图主要是文字信息,开启压缩图片,压缩尺寸默认为1600,识别结果很快,而且文字都识别出来了,也很准确,效果很好

粘贴一张代码片段截图识别,识别速度很快,结果也很准确,这样就可以一键拷贝代码了

之所以部署在线的WebOCR项目,是平时很多这种需求,比如很多技术博客网站或者文库网站,不能直接复制文字或代码,会有登录或会员要求限制,就会很麻烦。有时候也会从一些图片博文中获取关键字时,直接打字太慢,对着照片打字效率很低,这个时候在线OCR就很有用处了,直接粘贴截图,一键识别,再一键复制结果,不要太舒服了。
之前一直使用 Windows QQ 截图的文字识别功能,很好用,但是每次要登录QQ就会很麻烦,而且Linux版本的QQ是不支持的,看过很多OCR项目,都是提供后台识别API,但是没有提供Web版本的,也没有找到合适的直接填入OCR API地址就可以运行的开源OCR Web项目。虽然知道 PaddleOCR 的识别能力很强,可以识别表格格式的,但是只提供 API 部署。
TrWebOCR 是集合了OCR识别功能和易用的web页面的项目,并且支持Docker直接部署使用的,很方便,识别能力也很强,满足个人的使用了,还有更多有趣的设置和功能就需要自行探索了。
四、总结
TrWebOCR这个项目依托于开源项目Tr,通过扩展功能形成了一套便捷的中文OCR识别方案,与传统OCR服务不同,该项目突出强调了离线功能。研发者意识到在离线模式下进行OCR不仅可以省去不必要的网络流量消耗,更重要的是提高了数据隐私的安全性,使用户更加放心地进行大量敏感信息的处理。此次使用的Flexus X实例配置还是很高的4核12G-100G-3M规格的基础模式,开发者对OCR模型进行了深度优化,用户无需强大的硬件配置即可体验快速、精准的中文识别,识别速度很快,系统硬件绰绰有余。
华为云服务器,高配低价,性价比超高!灵活的配置方案,按需付费,让您不再为高昂的硬件成本烦恼。无论是初创企业还是大型企业,都能找到适合的方案。现在正值828 B2B企业节,价格更优惠,快来体验!
