在本篇文章中,主要是介绍RabbitMQ一些常见的面试题。对于前几篇文章的代码,都已经在码云中给出,链接是mq-test: 学习RabbitMQ的一些简单案例 (gitee.com),如果存在问题的话欢迎各位提出,望共同进步。
MQ的作用以及应用场景
简单来说,MQ的全称是Message Queue(消息队列),因此MQ的作用就是接收消息和发送消息。具体来说,MQ就是一种应用程序间的通信方法,它允许组件以异步的方式进行交互,在不同的应用场景下发挥着不同的作用。
常见的应用场景有:异步解耦、削谷削峰、消息分发、延迟通知、异步通信等。
具体介绍见【RabbitMQ】概述一文。
不同MQ的区别
业界也有许多MQ的产品,例如Kafka、RabbitMQ、RocketMQ等。
Kafka一开始是作为日志收集和传输,追求高吞吐量,性能卓越。单机吞吐量一般可达十万级,在日志领域较为成熟。但是功能比较简单,只支持简单的MQ功能。适合大数据处理、实时分析、日志聚合等应用场景。
RabbitMQ是采用Erlang语言开发,功能较为完善,几乎支持所有的主流语言,开源提供的界面非常友好,性能较好,单机吞吐量一般可达万级,社区活跃度较高,文档更新频繁。比较适合中小型公司,数据量没那么大、并且并发没那么高的场景。
RocketMQ是阿里巴巴开源的一款消息队列,后来捐赠给Apache公司,采用Java语言开发。在可用性、可靠性以及稳定性方面都非常出色,吞吐量可达十万级,在阿里巴巴内部广泛使用。但是支持的语言并不多,产品较新文档较少,并且社区活跃度一般。适合于大规模分布式系统,而且可靠性要求较高的场景,比如互联网金融。
具体介绍见【RabbitMQ】概述一文。
RabbitMQ的核心概念
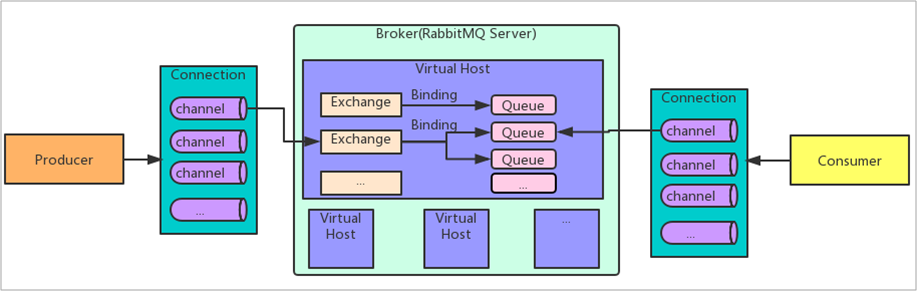
核心概念这一问题可以大概构建上述图形来简单进行介绍,我习惯先介绍生产者、消费者,然后再介绍连接、信道,最后介绍Broker以及其中的内容,VirtualHost、Exchange、Queue。
- Producer(生产者):是RabbitMQ Server的客户端,向RabbitMQ Server发送消息。
- Consumer(消费者):是RabbitMQ Server的客户端,从RabbitMQ Server接收消息。
- Connection(连接):是RabbitMQ Server和客户端之间的一个TCP连接,该连接是客户端和服务端之间发送消息的基础,他负责传输客户端和服务端之间的所有数据和控制信息。
- Channel(信道、通道):信道是连接之上的一个抽象层。在一个连接中有多个信道,每个信道都是独立的虚拟连接,消息的发送和接收就是基于信道的。信道的主要作用是将消息的读写操作复用到同一个TCP连接上,这样就可以减少建立连接和关闭连接的开销,提高性能。
- Broker:本质上就是RabbitMQ Server这个服务端实例,主要用来接收和发送消息。
- VirtualHost(虚拟主机):虚拟主机是一个虚拟概念,他为消息队列提供了一种逻辑上的隔离机制。对于一个RabbitMQ Server而言,可以存在多个虚拟主机。当多个不同的用户需要同一个Rabbit Server提供的服务时,可以划分出多个虚拟主机。每个用户在自己的虚拟主机上创建交换机、队列即可。
- Exchange(交换机):消息到达Broker的第一站,她负责接收消息并且根据路由规则把消息路由到对应的消息队列中。交换机起到了消息路由的作用,她根据交换机的规则和类型来确认如何转发接收到的消息。
- Queue(队列):用于存储消息。
具体介绍见【RabbitMQ】概述一文。
RabbitMQ的工作流程
- 发送消息:生产者生成了一条消息。
- 创建连接:生产者和RabbitMQ Server之间创建连接,并且开启一个信道。
- 声明交换机、队列以及绑定关系:生产者声明一个队列,用来存放消息;生产者声明一个交换机,用来路由消息;生产者指定一个绑定规则,使得消息从交换机成功路由到队列中。
- 发送消息:生产者将消息发送给RabbitMQ Server。
- 消息存储:RabbitMQ Server接收到消息之后,根据路由规则存入相应的队列中。如果未找到相应的队列,根据生产者的配置,选择丢弃或者回退给生产者。
- 消费消息:消费者监听队列,当消息到达时,从队列中获取消息。处理后,向Rabbit Server发送消息确认。
- 删除消息:RabbitMQ Server接收到消费者的确认(ACK)之后,从队列中把消息删除。
具体介绍见【RabbitMQ】概述一文。
RabbitMQ如何保证消息的可靠性
如何保证消息的可靠性,就要看消息在传输过程中哪里出现了问题。大致分为三个方面:第一个是从生产者到交换机、再到队列的过程,第二个是RabbitMQ Server内部,第三个是从RabbitMQ Server内部到消费者的过程。RabbitMQ对这三种情况分别推出了三种解决方案:发送方确认、持久化以及消息确认。
发送方确认有两种模式:第一个是confirm模式,保证的是从生产者到交换机过程中的消息可靠性。第二个是return模式,保证的是从交换机到队列的消息可靠性。
持久化有三种方式,分别是交换机持久化、队列持久化以及消息持久化。在三个持久化中,主要注意的是队列持久化和消息持久化,如果消息持久化了但是队列没持久化是没有作用的,比较队列都没有,消息也没地方放,自然持久化也就没有用。
消息确认有两种模式:手动确认和自动确认,在SpringAMPQ中,则是有三种策略可以选择:NONE、AUTO、MANUAL。在MANUAL中,又有三种机制可供选择,分别是接收、拒绝以及批量拒绝。
具体介绍见【RabbitMQ】可靠性传输一文。
RabbitMQ如何保证消息的顺序性
RabbitMQ中顺序性指的是生产者生产消息的顺序为msg1、msg2、msg3,那么消费者消费消息的顺序也应该依次为msg1、msg2、msg3。顺序性保障分为局部顺序性保障和全局顺序性保障。存在的解决方案有:单队列单消费者、分区消费、消息确认、业务逻辑控制(例如消费端内部实现消息排序逻辑等)。
具体介绍见【RabbitMQ】幂等性、顺序性一文。
RabbitMQ如何保证消息的幂等性
RabbitMQ中幂等性指的是一条消息,多次消费,对系统产生的影响是相同的。
在消息传递过程中,消息传输保证被分为最少一次、恰好一次、最多一次。RabbitMQ并不支持恰好一次;在业务场景比较重要的情况下,建议使用最少一次,但是在一些特殊场景下(例如消息从生产者发送出去之后出现网络故障,导致服务端没有及时返回确认机制;或者消息从服务端到消费者,消费之后并没有返回确认通知)会导致消息重复发送,从而出现一些比较严重的问题;对于最多一次来说,则会因为网络宕机等故障导致消息丢失。
一般在比较重要的业务下,我们都是以最少一次这种方式,但是如果出现消息重复传输的话,就会导致消息多次消费,因此我们为了保证幂等性,就需要一些解决方案。常见的解决方案有:
- 使用唯一标识符来标识每一条消息
- 使用业务逻辑判断来确认消息是否消费
具体介绍见【RabbitMQ】幂等性、顺序性一文。
RabbitMQ有哪些特性
- 消息可靠性传输
- 发送方确认
- 持久化
- 消息确认
- 死信队列
- 延迟队列
- 重试机制
- TTL
具体介绍见【RabbitMQ】系列。
介绍下RabbitMQ的死信队列
死信表示一系列无法被消费的消息。存在死信,就存在死信队列。当一个消息在队列中变成死信之后,就会通过死信交换机进入死信队列,这就是死信队列的由来。
例如队列中的消息超过最大长度、消息的TTL超时、手动确认机制下拒绝并且不予重新入队等等,都会被路由到死信队列中。
死信队列的应用场景有:消息重试(将错误的消息放入死信队列中进行重试)、日志分析(将死信队列中的消息进行收集,用户日志分析)、消息丢弃(将死信队列中的消息丢弃,避免占用资源)。
具体介绍见【RabbitMQ】死信队列、延迟队列一文。
介绍下RabbitMQ的延迟队列
延迟队列表示消息从生产者到达RabbitMQ Server之后,并不是立即到达消费者进行消费,而是经过一段时间之后再推送到消费者。
延迟队列的实现方式有两种:
- TTL + 死信队列(注意这里的TTL必须要设置队列的,而不是消息的)。
- 使用延迟队列插件。
延迟队列的应用场景有:
- 十五分钟未支付订单取消
- 预定会议开始前十五分钟进行通知
- 手机遥控两个小时之后家电开始工作
- 用户注册成功之后,三天后发送通知,提供用户活跃度
- 用户发起退款,24小时之后商家没有行动,自动退款
具体介绍见【RabbitMQ】死信队列、延迟队列一文。
介绍下RabbitMQ的工作模式
RabbitMQ有七种工作模式,分别是:
- 简单模式(Simple)
- 工作队列模式(Work Queue)
- 发布订阅模式(Publish / Subscribe)
- 路由模式(Routing)
- 通配符模式(Topics)
- RPC模式(RPC)
- 发布确认模式(Publisher Confirms)
具体介绍见【RabbitMQ】工作模式一文。
消息积压
消息积压指的是生产者生产消息的速度已经远远超过了消费者消费消息的速度,从而导致了消息在队列中发生了积压。
导致消息积压的原因无非就是软件和硬件的原因。对于软件来说,就是生产者生产速度太快、而消费者消费速度太慢;对于硬件来说,就是网络延迟、RabbitMQ服务器配置太低等原因。
想要解决消息积压,就是针对产生的问题进行分别解决。对于软件来说,就是提高消费者消费速率、降低生产者生产速率;对于硬件来说,就是增加服务器配置、优化参数等方案。
具体介绍见【RabbitMQ】消息积压、推拉模式一文。
推拉模式
推拉模式是RabbitMQ中向消费者发送消息的两种模式。推模式表示的是消息到达服务器之后,根据消费者监听的队列将消息推送给消费者进行消费。拉模式表示的是消息到达服务器之后,消费者主动去服务器拉取消息进行消费。
对于一般的业务来说,采取的都是推模式进行工作,其适合数据实时性要求较高的场景。拉模式则是适合消费消息时需要大量资源的的任务,拉模式允许消费者准备好之后再去进行消费,可以减少资源的浪费。
具体介绍见【RabbitMQ】消息积压、推拉模式一文。
到这里,RabbitMQ的介绍就基本结束了,其中缺的一个内容就是分布式部署,有机会的话后续进行介绍。
总的来说,在RabbitMQ这个系列中,先进行了一个概述,然后对工作模式简单介绍,后续是对高级特性(可靠性保证、TTL、重试机制、延迟队列、死信队列、事务、消息分发、幂等性、顺序性、消息积压)以及推拉模式进行了介绍,最后对一些场景面试题进行了概述。
下一个系列文章是微服务组件,欢迎大家给出修改意见,共同进步。