计算机视觉领域顶级会议 European Conference on Computer Vision(ECCV 2024)将于9月29日至10月4日在意大利米兰召开,快手音视频技术部联合清华大学所发表的题为《XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution》------基于扩散模型和跨模态先验信息的图像修复模型的最新研究成果被会议收录。

ECCV是计算机视觉领域的顶级国际会议,与CVPR、ICCV共同被称为三大顶会。其收录的论文代表了计算机视觉和模式识别领域的创新技术与重大成果,是该领域学术研究与行业发展的风向标。ECCV 2024共收到8,585篇有效投稿,其中有2,395篇论文被接收,接收率为27.9%。
「 01 背景 」
视频技术在生活中各种场景的作用日益凸显,其相关服务在多领域发挥了重要作用,短视频、直播等新模式新业态快速涌现。围绕流媒体视频展开的相关技术,如视频增强、视频压缩、视频修复以及虚拟现实等,也成为了学术界和工业界共同的研究热点。
近年来,基于深度学习尤其是GAN-based(Generative Adversarial Network)的处理算法取得了较好的修复增强效果 1,2,但是在细节纹理和主观画质上仍有较大提升空间。随着AIGC的发展,基于扩散模型 3(Diffusion Model)的文生图和文生视频模型(如可图、可灵)在生成能力上取得了令人惊艳的效果。如何将这种生成能力与视频处理进行结合,增强视频细节纹理、修复低质损伤,进一步改善画质为用户提供更好的观看体验,是一个亟待解决的问题。

图1:引入生成能力进行处理的效果对比,左边为低质图,右边为处理后
「 02 方法 」
在这篇论文中,快手提出了一种基于扩散模型和跨模态先验信息的图像修复增强算法XPSR(Cross-modal Priors for Super Resolution),结合丰富且准确的语义信息,生成模型在处理任务上展现了巨大的潜力,生成了相较于原图具有较高保真度、细节纹理丰富的高分辨率图像。
算法的框架如图1所示,包含两个阶段:
(1)使用多模态大语言模型生成待修复图像的语义信息;
(2)将待修复低分辨率图像和语义信息输入到生成模型中进行修复增强。具体来说,低分辨率低质图像(Low Resolution,LR)首先经过图像编码送入ControNet 4 分支,与第一阶段产生的语义描述作为状态信息送入生成模型的UNet结构中,经过多步迭代的特征经过VAE解码重建得到修复后的高分辨率高质图像(High Resolution,HR)。以下是具体的算法细节,包括语义描述的产生、扩散模型的状态信息融合、退化消除约束和训练优化目标。
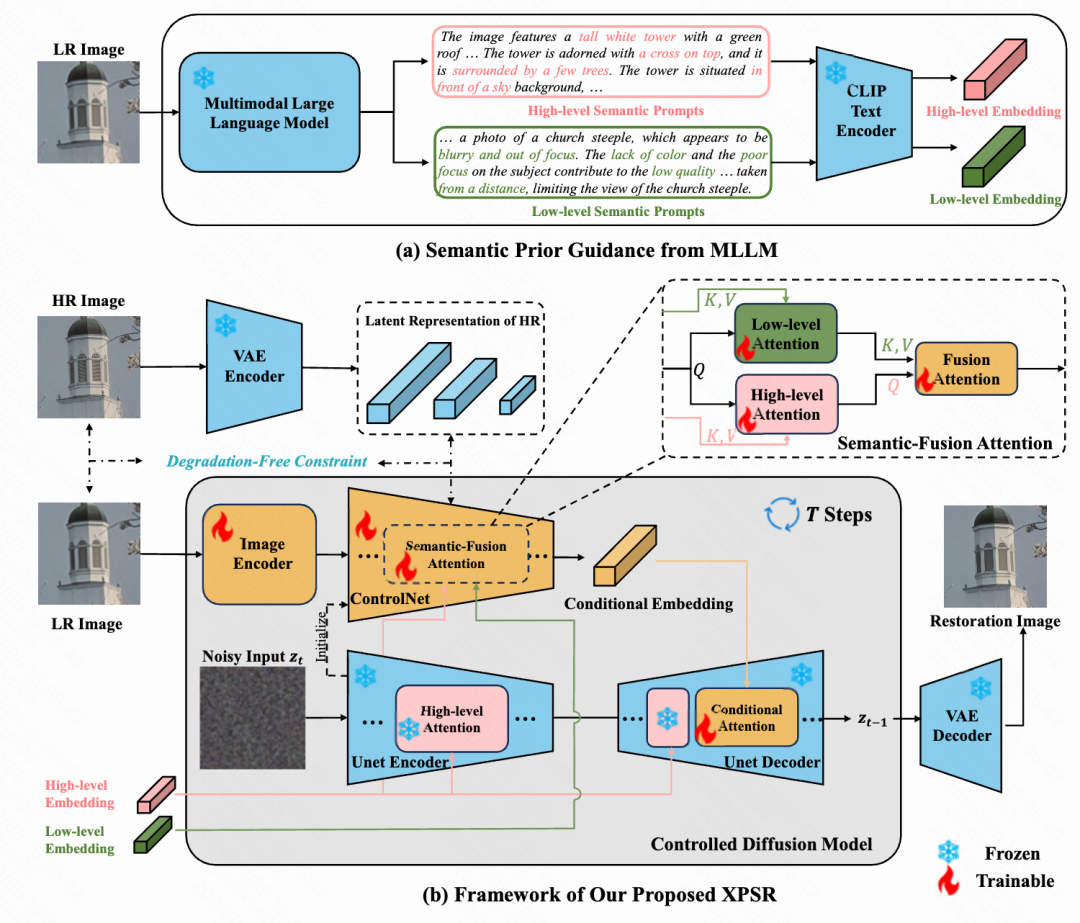
图2:XPSR的算法框架
语义描述的产生

图3:不同类型语义信息对修复效果的影响
如图2所示,在使用文本到图像(Text2Image,T2I)的扩散模型作为基础模型进行修复任务时,文本状态信息对修复的效果产生了较大的影响:针对原始低分辨率图像,给定准确的内容描述有助于生成细节纹理更加丰富的物体,结合详细的画质信息描述有助于去除对应的低质损伤。
为此,我们引入了当前业界SOTA的多模态大语言模型LLaVA 5,如图3所示,通过这种方式产生的内容语义信息包含物体描述、位置关系、场景等其他相关信息;产生的画质语义信息包含整体的观感质量、清晰度、噪声、色彩等其他维度的信息,能够有效描述图片在拍摄或者编码阶段引入的退化损失。

图4:针对待修复图像,使用多模态大语言模型产生的语义描述
扩散模型的状态信息融合
为了将不同语义信息与扩散模型进行结合,一种直观的做法是采用顺序的方式将Cross-Attention串联起来,计算形式如下:
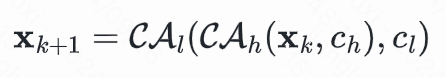
但是由于两类语义信息不同,串行处理会导致一部分信息被覆盖而获得次优解。因此我们设计了一种新的语义融合注意力机制(Semantic-Fusion Attention,SFA),它采用两个并行的Cross-Attention,然后从两个分支中分别获得QK和V特征进行融合,计算形式如下:
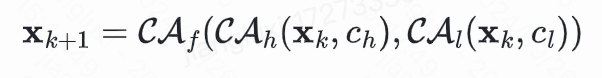
通过这种方式,SFA可以在不同语义之间取得平衡,进行状态信息的自适应选择。
退化消除约束
现实世界中的图像可能会经历各种退化,例如噪声、块效应等,从而导致像素空间和隐空间中高频和低频信息的失真,为了减轻退化的影响从图像中提取稳健的信息,进而提升重建的保真度与画质,在训练过程中,我们提出了一种退化消除约束(Degradation-Free Constraint)。如图1所示,我们在像素空间与隐空间约束LR与HR在多尺度下的相似度:
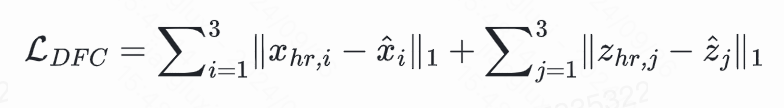
通过这种约束,LR特征表示更多关注于内容本身,避免了生成模型将低质与内容混淆。
优化目标
在训练过程中,XPSR依赖于LR图像x_{\textit{lr}},噪声隐空间特征z_{\textit{hr}}^t,内容语义特征c_h和画质语义特征c_l去预测第t步的噪声分布:
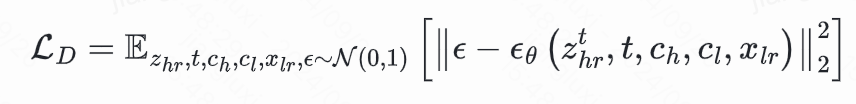
结合退化消除约束,整体的优化目标可以表示为:
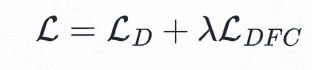
在推理过程中,我们引入了Classifier-free Guidance策略,通过引入负面提示词来提升扩散模型的生成画质。在实践过程中,我们采用了"blurry, dotted, noise, unclear, low-res, over-smoothed"。
「 03 实验结果 」
我们选择了有参考(PSNR、SSIM、LPIPS、DISTS、FID)和无参考(MANIQA、CLIPIQA、MUSIQ)的评价指标来衡量修复的画质。如表1所示,在人工构建的测试场景下,XPSR在无参考质指标上超越了以往GAN-based和Diffusion-based的算法。
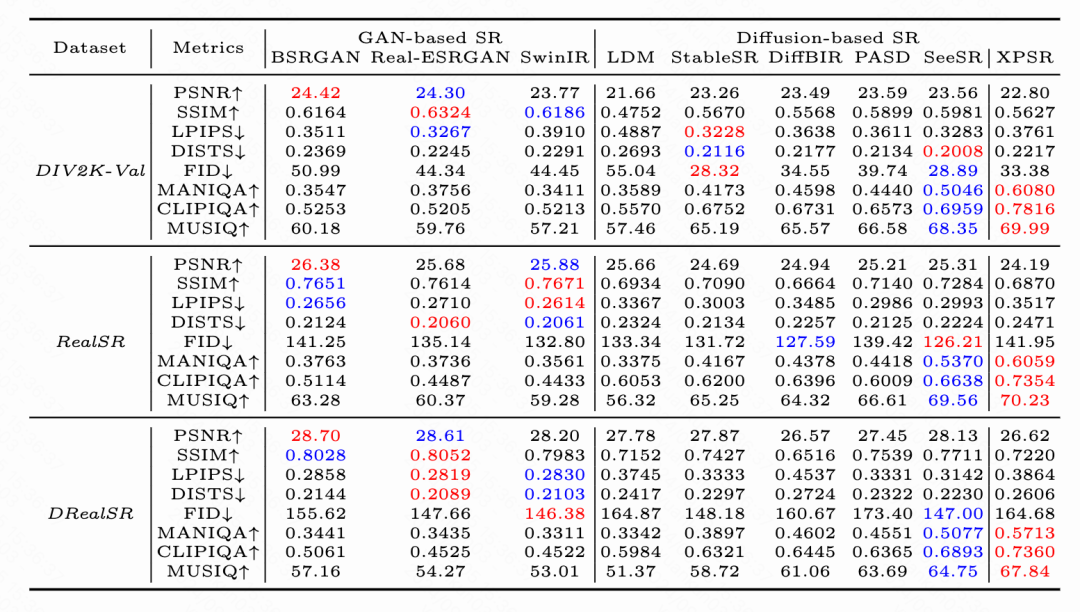
表1:XPSR与GAN-based和Diffusion-based算法效果对比
如表2所示,在真实场景的数据下XPSR在主观指标和user study的被选择概率均能够胜出。


表2:基于真实场景的测试结果和User Study报告
如图4所示,在主观画质的提升、细节纹理的生成、主体信息的保持上也取得了优秀的效果。

图5:XPSR与其他处理算法的主观画质对比
相较于GAN-based方法,Diffusion-based方法在有参考指标上存在一些差距,这表明Diffusion-based方法在保真度上仍有较大的提升空间。同时,如图5所示,这些指标也存在一些问题(更好的主观画质却更低的有参指标),希望未来有更多与主观一致的指标被探索和使用。

图6:现有有参考指标的局限性
「 04 总结与展望 」
在本篇论文中,我们提出了一种基于扩散模型和跨模态先验信息的图像处理算法。通过引入基于多模态大语言模型的语义先验,设计适合扩散模型的状态信息融合机制,以及适合处理场景的退化消除约束,XPSR在主客观指标上取得了业界领先的效果,持续为快手视频处理体系(Kuaishou Enhancement Processing,KEP & Large Processing Model,LPM)提供算法支持。
目前,快手视频处理体系已经应用在内部多个业务场景,如快手视频清晰度提升、基于内容的自适应处理和编码、电商/商业化赋能等。未来,快手音视频技术团队将持续推动视频处理算法的提升,探索更为广泛的应用场景。
参考文献:
1 Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data, ICCV Workshop 2021.
2 SwinIR: Image Restoration Using Swin Transformer, ICCV Workshop 2021.
3 Denoising Diffusion Probabilistic Models, NeurIPS 2020.
4 Adding Conditional Control to Text-to-image Diffusion Models, ICCV 2023.
5 Visual Instruction Tuning, NeurIPS 2024.