Meta 刚刚发布了 Llama 3.2,将语言和视觉模型整合到一个强大的多模态系统中。它引入了四个模型:两个轻量级文本模型(1B 和 3B)和两个视觉模型(11B 和 90B)。这些模型专为一系列任务而设计,从总结长文档到以复杂的方式理解图像。

NSDT工具推荐 : Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、向多模态系统的转变
人工智能世界正在向多模态系统转变,该系统可以同时处理文本和图像。GPT 的多模态变体、Mistral 的 PixTral 以及现在的 Meta 的 Llama 3.2 等模型正在引领潮流。这些模型旨在处理多种类型的输入,这意味着它们可以同时阅读和理解文本、查看图像,甚至可以同时对两者进行推理。
早期的模型可以"阅读"或"查看",但不能同时进行。多模态模型结合了这些能力,例如与可以查看地图并向你指出事物的人交谈。
2、轻量级文本模型:Llama 3.2 与 Llama 3.1
让我们从 Llama 3.2 的轻量级文本模型开始。这些是 1B 和 3B 模型,设计为小而高效。它们可以处理大型上下文(最多 128,000 个标记)------想象一下在本地设备上运行涉及阅读和总结一本厚书的对话。
2.1 是什么让这些模型"轻量级"?
与笨重且需要大量计算能力的传统模型不同,轻量级模型经过优化,既快速又小巧。Meta 使用两种技术来实现这一点:
- 修剪(pruning):在不牺牲性能的情况下删除模型中不太重要的部分。这就像修剪掉树上多余的树枝,让它长得更直。
- 蒸馏(distillation):从更大的模型(如 Llama 3.1 的 8B 模型)中获取知识并将其压缩成较小的模型,同时仍保留重要信息。
这些较小的模型非常适合在智能手机或笔记本电脑等设备上使用,在这些设备上,你需要高效的处理能力,但仍希望模型足够智能,能够完成总结文档、遵循说明或改写文本等任务。例如,可以使用 3B 模型重写整篇博客文章,使其更短或更简单。
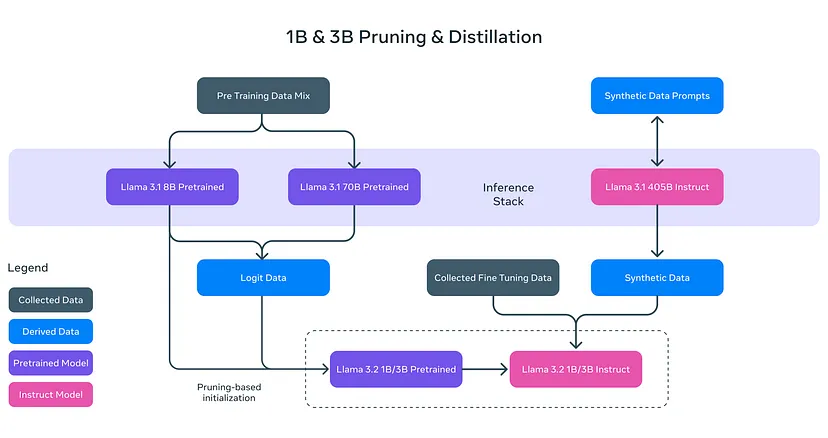
2.2 训练后:微调和对齐
较小的模型经过修剪和提炼后,将经历训练后步骤,使其更加有用:
- 监督微调 (SFT):在此,模型被教导遵循详细的说明。如果你要求它总结文档或解释段落,此步骤可帮助它正确执行。
- 拒绝抽样 (RS):模型生成多个可能的答案,系统通过拒绝不正确或低质量的答案来选择最佳答案。
- 直接偏好优化 (DPO):与 RS 类似,但此步骤根据用户的偏好对最佳答案进行排名。
此外,Llama 3.2 支持大型上下文窗口(最多 128K 个标记)而不会降低质量,这意味着它可以同时记住和处理大量信息,使其成为总结或重写长文档等项目的理想选择。
3、视觉模型:Llama 3.2 的新图像能力
Llama 3.2 引入了两个新的视觉模型(11B 和 90B),它们可以处理和推理图像。这意味着它们可以分析具有复杂视觉效果(如图表或图形)的文档,还可以执行视觉基础 - 根据描述在图像中查找特定对象。
3.1 视觉模型如何工作?
Llama 3.2 的视觉模型使用适配器权重系统。这些适配器就像图像编码器(处理图像)和语言模型(处理文本)之间的桥梁。这使模型可以同时理解图像和文本。
以下是一个例子:假设您正在开发一款应用,让用户拍摄餐厅菜单的照片,并根据用户偏好突出显示素食菜肴。Llama 3.2 的视觉模型将处理图像(菜单)并将其与用户的基于文本的偏好(例如"素食")进行比较,然后突出显示相关项目。
Llama 3.2 视觉模型还支持视觉基础,这意味着它们可以理解"在这张图片中找到猫"之类的指令并准确指出它的位置!
3.2 训练视觉模型
- 文本模型作为基础:该模型以 Llama 3.1 的文本模型为基础。
- 适配器和编码器:它添加了图像编码器和适配器,使其能够"看到"和处理视觉信息。
- 大规模预训练:该模型在大型(图像,文本)对数据集上进行训练 - 比如带有标题的图片。这有助于它学习如何将图像与描述联系起来。
- 使用高质量数据进行微调:之后,在更小、更准确的数据集上对模型进行微调,以提高其对特定任务的理解。
- 对齐:最后,使用拒绝抽样和偏好优化等技术对模型进行对齐,以确保它提供最有用和最准确的响应。
4、Llama 3.2 与其他多模态模型相比如何?
- GPT(OpenAI):GPT 的多模态版本(今年发布)可以处理文本和图像,但通常是闭源的,这意味着你无法始终对其进行微调或将其用于特定的自定义应用程序。
- Mistral 的 PixTral:Mistral 发布了较新的版本,开发了 PixTral,这是一种专门用于图像和文本任务的模型。与 GPT 的大型模型相比,它更轻量级,并且对微调开放,这使其成为同时分析图像和文本等自定义任务的理想选择。
- Llama 3.2:与 GPT 不同,Llama 3.2 既是开源的,又是为定制而设计的。预训练和对齐版本都可用,允许用户根据自己的特定需求微调模型。它还支持文本和图像任务,使其成为目前最灵活的模型之一。
Llama 3.2 以其轻量级模型(1B 和 3B)脱颖而出,这些模型可轻松安装在设备上,同时仍然足够强大,可以处理摘要和重写等任务。同时,11B 和 90B 模型提供了高级图像理解功能。
5、Llama 3.2 应用实践
如果你计划使用 Hugging Face 进行流水线操作,请确保拥有必要的访问权限。
安装必要的软件包:
from transformers import pipeline
import torch从 hugging face 加载 Llama-3.2 模型:
model_id = "meta-llama/Llama-3.2-1B-Instruct"
# Specify the device to use GPU (device 0 by default)
device = 0 if torch.cuda.is_available() else -1 # -1 indicates CPU
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device=device # Use GPU if available
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"}
]
outputs = pipe(
messages,
max_new_tokens=256
)
print(outputs[0]["generated_text"])输出:
"Arrrr, ye be askin' about meself, eh? Alright then, matey!
I be Captain Blackbeak Betty, the most feared and infamous pirate to ever sail the Seven Seas.
Me and me crew o' scurvy dogs have been plunderin' and pillagin' fer years,
bringin' riches and glory to our names. Me trusty parrot, Polly,
be me right-hand scallywag, and me loyal cutlass, Cutlass Cutie,
be me best mate. We be sailin' the Caribbean,
searchin' fer hidden treasure and fightin' off any landlubbers
who get in our way. So hoist the sails and
set course fer adventure with me and me crew, or walk the plank, matey!"加载 Llama-3.2 Vision 模型:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # Proper device setup
# Load the model
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16
)
model = model.to(device)
# Load the processor
processor = AutoProcessor.from_pretrained(model_id)
# Load an image from the web
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Create a message list that includes an image and a text prompt
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "If I had to write a haiku for this one, it would be: "}
]}
]
# Prepare inputs using the processor
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(device)
# Generate output from the model
output = model.generate(**inputs, max_new_tokens=30)
print(processor.decode(output[0]))示例 1:输入图像:

输出如下:
If I had to write a haiku for this one, it would be:
Here is a haiku for the image:
A rabbit in a coat
Stands on a dirt road, smiling
Springtime in the air
-------
如果我要为这幅画写一首俳句,那应该是:
这是这幅画的俳句:
一只穿着外套的兔子
站在泥路上,微笑着
空气中弥漫着春天的气息示例 2:输入图像并询问:
从这次扫描中可以确定哪些潜在诊断?

输出如下:
To identify potential diagnoses from the scan,
we need to analyze the image and look for any abnormalities or features that could suggest specific conditions.
Based on the provided description, the scan appears to show a brain with a large area of low density in the left hemisphere,
which could be indicative of various conditions such as ischemic stroke, hemorrhagic stroke, or even certain types of tumors.
However, without more detailed information or the actual image, it is challenging to provide a definitive diagnosis.
A healthcare professional would typically use this information in conjunction with clinical symptoms, medical history, and other diagnostic tests to make an accurate diagnosis.
Answer: Ischemic stroke, hemorrhagic stroke, or certain types of tumors.
------------
为了从扫描结果中确定可能的诊断,
我们需要分析图像并寻找可能表明特定病症的任何异常或特征。
根据提供的描述,扫描结果显示大脑左半球有大面积低密度区域,
这可能表明存在各种病症,例如缺血性中风、出血性中风,甚至某些类型的肿瘤。
但是,如果没有更详细的信息或实际图像,很难提供明确的诊断。
医疗保健专业人员通常会结合临床症状、病史和其他诊断测试使用此信息来做出准确的诊断。
答案:缺血性中风、出血性中风或某些类型的肿瘤。示例 3:输入带有问题的图像:
这是脑瘤 MRI 扫描吗?
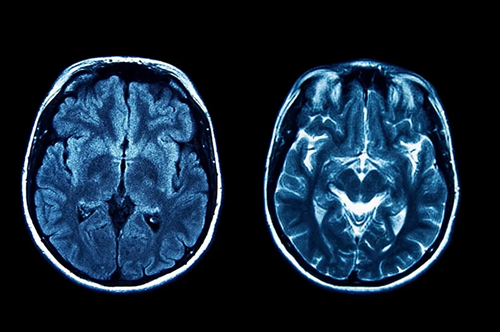
输出如下:
Based on the provided information, the image appears to be an MRI scan of a
brain with a large area of low density in the left hemisphere,
which could be indicative of various conditions such as ischemic stroke,
hemorrhagic stroke, or even certain types of tumors.
However, without more detailed information or the actual image, it is challenging to provide a definitive diagnosis.
The term "brain tumor MRI scan" suggests that the image is related to a brain tumor,
but the description provided does not explicitly confirm this.
A brain tumor MRI scan typically shows abnormal tissue growth in the brain,
which can cause various symptoms depending on the location and size of the tumor.
Answer: Yes, this could be a brain tumor MRI scan.
-------
根据提供的信息,该图像似乎是大脑的 MRI 扫描,左半球有大面积低密度区域,这可能表明存在各种疾病,例如缺血性中风、出血性中风,甚至某些类型的肿瘤。然而,如果没有更详细的信息或实际图像,很难做出明确的诊断。"脑肿瘤 MRI 扫描"一词表明该图像与脑肿瘤有关,但提供的描述并未明确证实这一点。脑肿瘤 MRI 扫描通常显示大脑组织异常生长,这可能根据肿瘤的位置和大小引起各种症状。答:是的,这可能是脑肿瘤 MRI 扫描。6、实际用例
- 文本总结:假设你有一堆 PDF 文档。Llama 3.2 的轻量级文本模型可以帮助你快速总结它们,在几秒钟内提取最重要的信息。
- 图像字幕:你上传一张街景图片,模型准确地为其加上字幕:"一条繁忙的街道,有汽车、红绿灯和行人过马路。"
- 复杂的视觉理解:在医疗环境中,医生可以上传 X 光片,视觉模型可以通过分析和突出显示可能存在的问题区域来提供帮助,使其成为诊断的有用工具。
Llama 3.2 标志着人工智能发展的重大飞跃,尤其是其轻量级文本模型和先进的视觉功能。这些创新旨在提高效率,为总结、图像理解和实时推理提供强大的工具。人工智能的所有这些发展都在简化人类任务,为跨行业的革命铺平道路。通过负责任地使用人工智能解决现实问题,我们可以释放巨大的潜力,而不会冒被滥用的风险。