看到某项目有类似这样的一段代码
go
leaves := make([]int, 10)
leaves = leaves[:0]没理解这样的连续两行,有何作用? 初始化一个长度和容量都为10的切片,接着把切片长度设置为0
即如下demo: (在线地址)
go
package main
import "fmt"
func main() {
leaves := make([]int, 10)
fmt.Println(leaves)
leaves = leaves[:0]
fmt.Println(leaves)
leaves2 := make([]int, 0, 10)
fmt.Println(leaves2)
}输出为:
output
[0 0 0 0 0 0 0 0 0 0]
[]
[]为什么不直接leaves := make([]int, 0, 10)? 况且直觉来说,先申请长度为10的,再设置为0, 比直接申请长度为0的,要多一些性能开销吧...
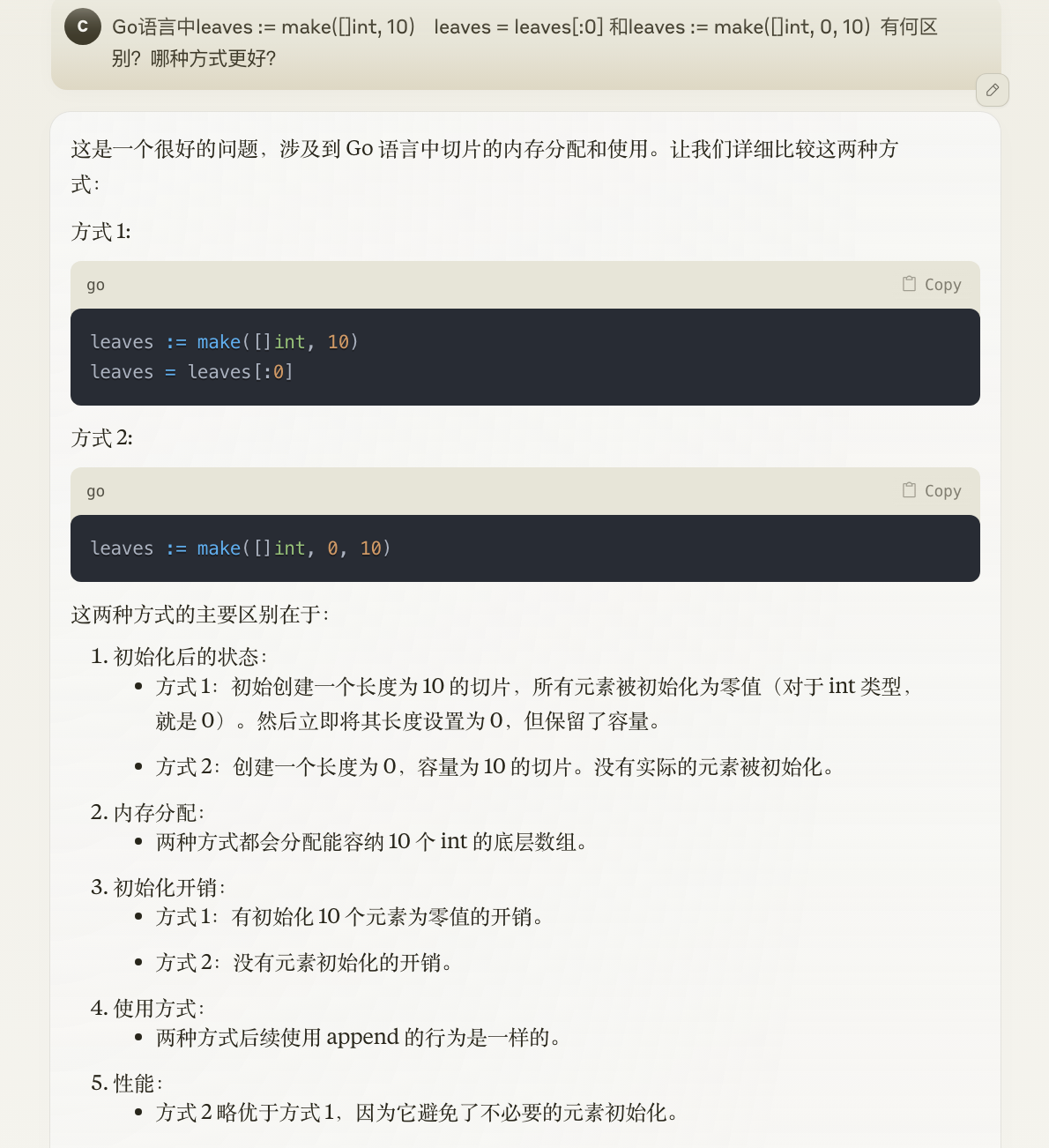
Go语言中leaves := make(\[\]int, 10) leaves = leaves:0 和leaves := make(\[\]int, 0, 10) 有何区别?哪种方式更好?
这是一个很好的问题,涉及到 Go 语言中切片的内存分配和使用。让我们详细比较这两种方式:
方式 1:
go
leaves := make([]int, 10)
leaves = leaves[:0]方式 2:
go
leaves := make([]int, 0, 10)这两种方式的主要区别在于:
-
初始化后的状态:
- 方式 1:初始创建一个长度为 10 的切片,所有元素被初始化为零值(对于 int 类型,就是 0)。然后立即将其长度设置为 0,但保留了容量。
- 方式 2:创建一个长度为 0,容量为 10 的切片。没有实际的元素被初始化。
-
内存分配:
- 两种方式都会分配能容纳 10 个 int 的底层数组。
-
初始化开销:
- 方式 1:有初始化 10 个元素为零值的开销。
- 方式 2:没有元素初始化的开销。
-
使用方式:
- 两种方式后续使用 append 的行为是一样的。
-
性能:
- 方式 2 略优于方式 1,因为它避免了不必要的元素初始化。
哪种方式更好?
总的来说,方式 2 leaves := make([]int, 0, 10) 通常被认为是更好的做法,原因如下:
-
效率:避免了不必要的元素初始化,特别是当元素类型比 int 更复杂时,这种差异会更明显。
-
清晰性:直接表达了"我想要一个空的切片,但预留了 10 个元素的空间"这一意图。
-
一致性:与后续使用 append 来添加元素的方式更加一致。
-
安全性:避免了可能出现的、使用未被有意义初始化的元素的错误。
示例代码来说明这两种方式的行为:
go
package main
import "fmt"
func main() {
// 方式 1
leaves1 := make([]int, 10)
fmt.Printf("方式 1 初始: 长度=%d, 容量=%d\n", len(leaves1), cap(leaves1))
leaves1 = leaves1[:0]
fmt.Printf("方式 1 重置后: 长度=%d, 容量=%d\n", len(leaves1), cap(leaves1))
// 方式 2
leaves2 := make([]int, 0, 10)
fmt.Printf("方式 2: 长度=%d, 容量=%d\n", len(leaves2), cap(leaves2))
// 添加元素
leaves1 = append(leaves1, 1, 2, 3)
leaves2 = append(leaves2, 1, 2, 3)
fmt.Printf("方式 1 添加元素后: %v\n", leaves1)
fmt.Printf("方式 2 添加元素后: %v\n", leaves2)
}输出将会是:
方式 1 初始: 长度=10, 容量=10
方式 1 重置后: 长度=0, 容量=10
方式 2: 长度=0, 容量=10
方式 1 添加元素后: [1 2 3]
方式 2 添加元素后: [1 2 3]这个例子展示了两种方式在实际使用中的相似性,但方式 2 避免了初始的元素初始化步骤。
因此,在大多数情况下,leaves := make([]int, 0, 10) 是更好的选择。
看着Claude.ai的回答,"第一种方式有内存分配", 于是信心满满提了个pr,结果维护这个项目的丹麦老哥回复:
It literally does the same - it doesn't save any "memory overhead". Sorry. This is too pointless of a change to take.
决定做个性能测试加以佐证。
go
package main
import (
"testing"
)
func BenchmarkMakeWithLength(b *testing.B) {
for i := 0; i < b.N; i++ {
leaves := make([]int, 10)
leaves = leaves[:0]
}
}
func BenchmarkMakeWithCapacity(b *testing.B) {
for i := 0; i < b.N; i++ {
leaves := make([]int, 0, 10)
_ = leaves
}
}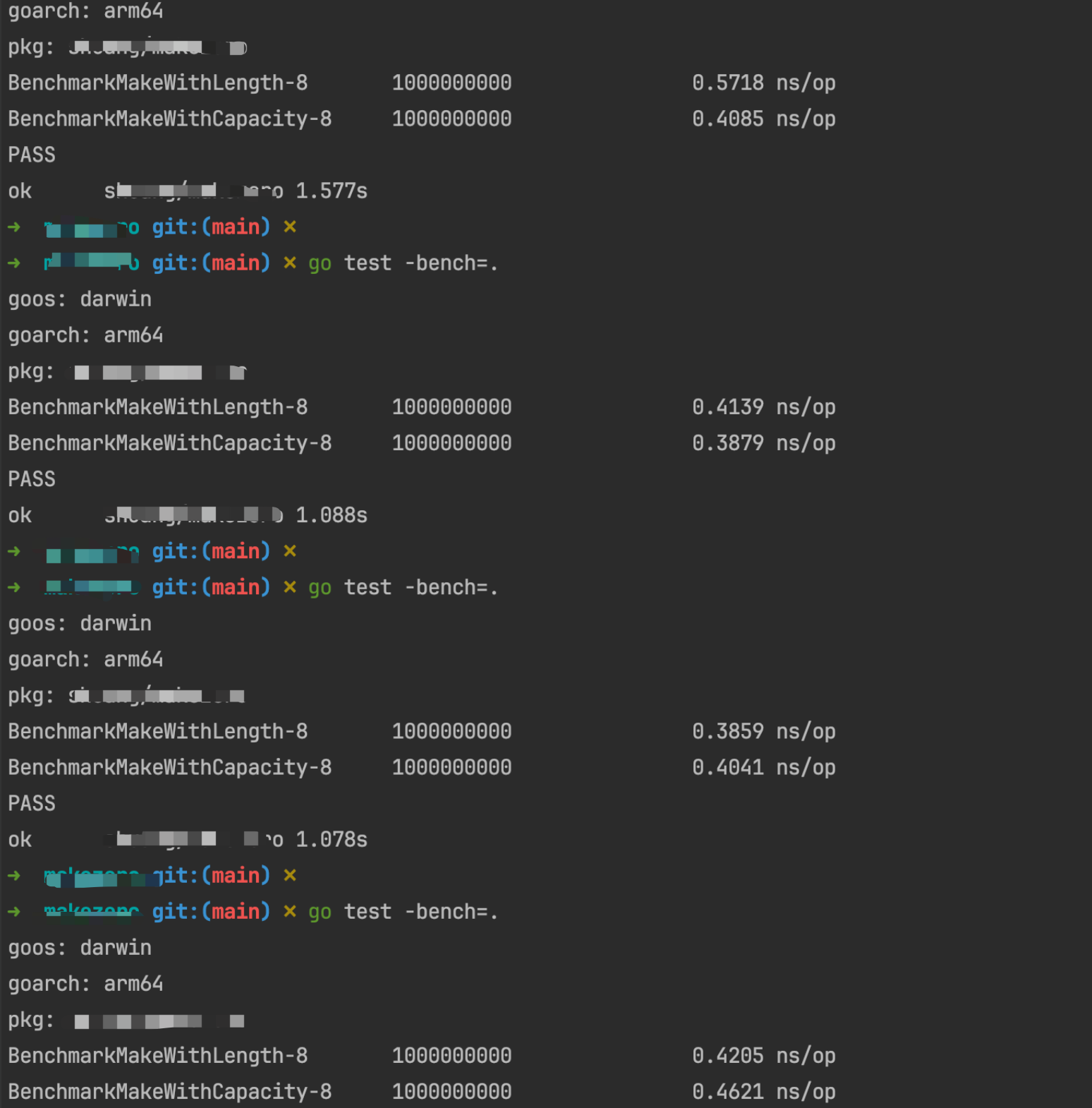
尴尬的是,测试结果,却恰恰并不支持Ai给的这个结论。。
写demo然后查看两者相对应的汇编,好吧,其实两种写法汇编代码是完全一样的。唯一差异也就在于个人习惯和可读性了